Comments


This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
Summary of important claims/arguments:
Thanks to Jakub Stencel and Vasco Grilo for thorough feedback on drafts.
Imagine that animal advocates and opponents of factory farming woke up tomorrow and found ourselves suddenly vested with the power to rearrange society almost any way we wanted to. We would quickly run into some thorny questions:
Animal ethicists range from divided to downright clueless on these questions.[1] But until recently, we’ve largely been able to avoid getting paralyzed by this uncertainty, in part because we haven’t had enough power in the world to make the kinds of changes that depend on answering them.
The arrival of generally superintelligent AI[2] could change this. Future AI could carry out interventions in nature that were previously impossible. It could present us with a range of options for producing meat with less or no suffering, from cell-cultured meat to brainless animal bodies to conscious animals genetically selected or engineered to enjoy lives inside factory farms.
Once AIs are smart enough to outperform the best humans at all cognitive tasks, it seems likely that these decisions will eventually be made by AIs rather than by humans,[3] since keeping humans in the loop will only degrade decisionmaking. In that case, values AIs learn before we hand over control to them could be our last chance to influence the welfare of future animals (and possibly of all sentient beings).
Animal welfare alignment is the collective project of trying to teach AIs to place appropriate moral weight on animals. This requires solving technical challenges (how to impart the right values/behaviors in AIs) and social/political challenges (convincing the human decisionmakers at AI companies to spend resources on it).
But it also faces a definitional challenge: how much weight is appropriate, on which animals? If we had the opportunity today to write an exact list of beliefs about animal welfare into present and future AI systems, it is not clear what that should consist of.
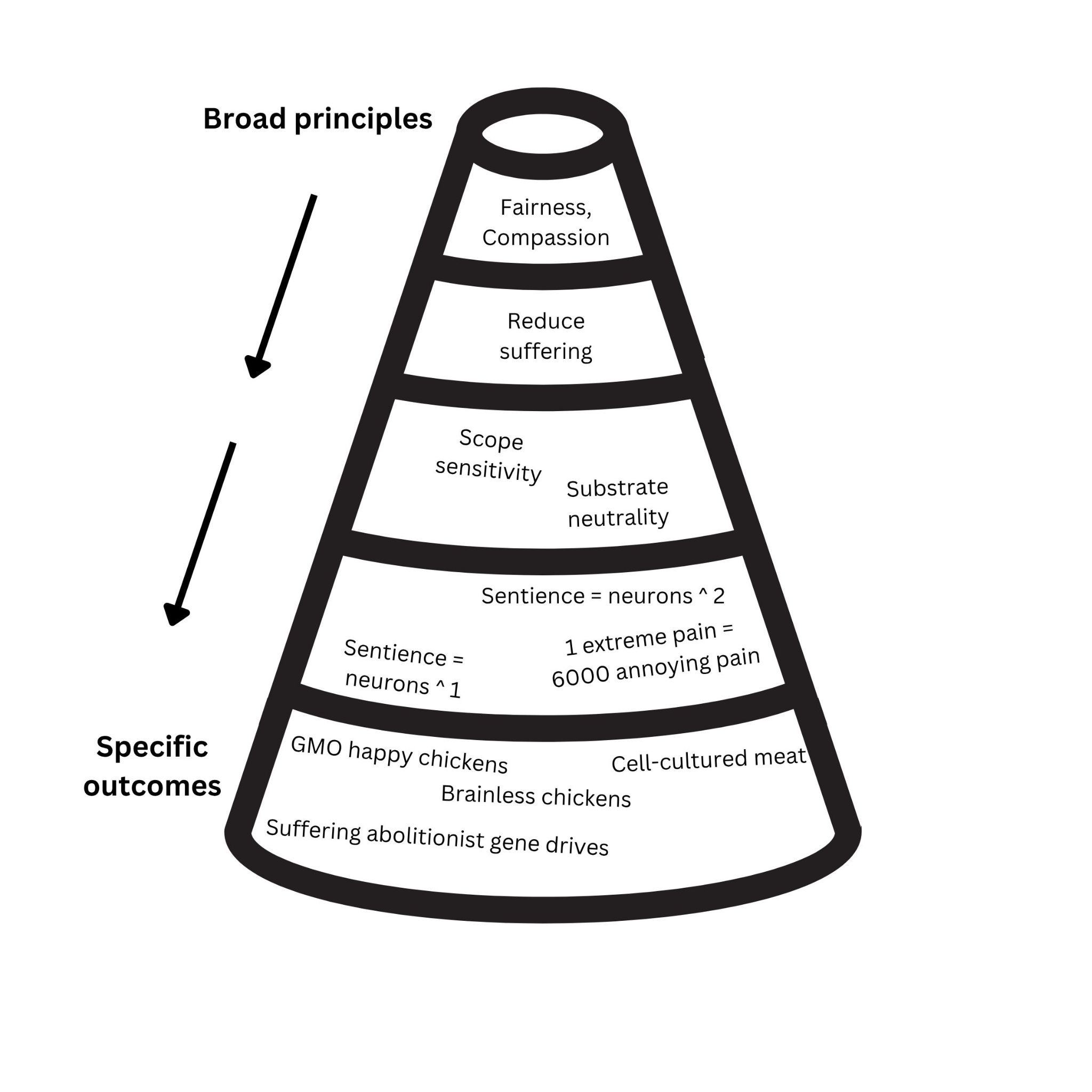
How narrowly should we be trying to constrain the actions of future models? Should we specify the exact outcomes we want? Or should we limit ourselves to broad principles and defer to more capable future AIs to determine how to best actualize those principles? Or somewhere in between?
Far from being unique to animal welfare, this question is a subject of debate among alignment researchers generally.
In the case of animal welfare alignment, some examples of points on this spectrum are:
| Breadth | Alignment target |
| Broad principles | Compassion, fairness |
| ↓ | Work to reduce suffering and increase happiness of sentient minds, regardless of the substrate (human, nonhuman animal, digital, or beyond) |
| ↓ | Maximize wellbeing given that 1) capacity for wellbeing increases linearly with neuron count and 2) one minute of excruciating pain is as bad as 100 hours of annoying pain |
| Specific outcomes | Replace all animal farming with cell-cultivated meat. Use gene drives or other technologies to abolish suffering in wild animals. |
Specific outcomes
Replace all animal farming with cell-cultivated meat. Use gene drives or other technologies to abolish suffering in wild animals.
Hopefully, you get more uncertain about these targets as we move down the table. The further we get from basic principles, the more confounded our reasoning, and the less sure our aim.
It might be better to depict it this way, showing the space of possible answers fanning out:
Where is the correct target, and how do we find it? One way to understand this question is as a variant of the debate over moral realism. Moral realism is the philosophical belief that ethical statements are objective claims about the world that are either true or false, the way that statements about math, logic, or physics are true or false.[4] Anti-realism holds that there is no reducible moral truth beyond the values that subjective agents arrive at.
In the past, I have found this debate confusing and abstract, suspecting it of being a category error. But the prospect of superintelligent AI presents a more concrete version of the question:
Would any sufficiently intelligent agent converge on the same moral truth?
If the answer is yes, then we could cause enormous harm by constraining future AIs to beliefs or conclusions that we select now, while operating at a much lower level of intelligence.
If the answer is no, then we have no reason to trust that future AIs will reach morally superior conclusions to ourselves, and we should constrain them to our conclusions in proportion to our credence.[5]
When I consider values and outcomes we could (try to) align AI to, I notice that my feelings about whether I’d want to constrain future AIs vary greatly. In some cases, I feel very nervous about not deliberately aligning AI to a certain conclusion, and in other cases, I feel equally nervous about the prospect of constraining AI to any answer.
These largely break down on specificity. When it comes to general principles, I don’t have any confidence that AIs will naturally converge on compassion and fairness. I share AI safety godfather Eliezer Yudkowsky’s conclusion that the space of possible minds is vast and that, for an unspecified process of selecting a mind out of that space of possibilities, intelligence is not necessarily correlated with altruism.
For many specific questions, intuition tells me that there exists a (more) correct answer, but that it is beyond the reach of my intellect. Taking my own values for granted, I am confused about where to draw the line between lives worth living and not, or worse what the average n should be for the formula “sentience-adjusted welfare range = number of neurons ^ n”, or even whether that is a remotely sensible formulation.[6] I find these so daunting that I can’t imagine confidently entrusting the answers to a member of the same species. It would be a relief to defer them to a godlike superaltruist.
As the earlier table shows, morally relevant questions can be plotted on a spectrum from general to specific. We should rely on the superior intelligence of future AIs to provide answers to quantitative and practical ethical conundrums, while specifying the basic values and principles they should use to reason about those questions. But just as I am uncertain about many of the questions themselves, I am uncertain about where to draw the line between questions we should defer and those we should constrain.
Many highly intelligent humans who believe deeply in fairness and compassion place almost no moral weight on animals. I am highly confident (>98%) this is an error on their part, just as it was an error for similarly intelligent ancestors to endorse slavery or conclude babies did not feel pain. Empirically, we should not feel confident that intelligence causes convergence on a “correct” answer to the question of animal ethics. I would not want to leave it up to AIs to conclude that compassion and fairness should extend to nonhuman animals.
Directing AIs to “work to reduce suffering and increase happiness of sentient minds” is a step more specific. I am still confident in this conclusion, but less so. It’s shaped like an endorsement of utilitarian hedonism, though not necessarily at the exclusion of other philosophies. I’m about 85% confident of this target, and other people I respect are lower still. Maybe the important thing to optimize for isn’t wellbeing, but autonomy, or something else. If so, constraining AIs to hedonism could result in astronomical waste. But while I’m less certain about constraining AI to hedonism, I’m also not certain that more intelligence—even a superintelligence constrained by basic values like compassion and fairness—will necessarily reach a “better” conclusion. I currently think it would probably help, but I’m not sure.
Perhaps the ideal solution would be to impart bayesian priors about morality into AIs, something like:
| Belief | Credence[7] |
| Treat sentient beings with compassion | 99.9% |
| Treat nonhuman animals as sentient, using the best evidence to determine their sentience-adjusted welfare range | 98% |
| Work to reduce suffering and increase happiness of sentient minds | 85% |
| Work to abolish the slaughter of sentient animals for food, clothing, and research | 70% |
| The exponent n by which sentience-adjusted welfare range scales[8] relative to “number of neurons[9] ^ n” is less than 1 | 55% |
| Hens in battery cages lead net-positive lives | 10% |
Unfortunately, this schema is incompatible with how alignment of LLMs currently works. Two realities limit how precise our alignment efforts can be.
First, alignment researchers, especially those who set alignment targets within AI companies, may not share our beliefs or goals. As companies come under more pressure from more interest groups across society, the case for this kind of ethical alignment may become more difficult.
Second, even if alignment researchers were onboard with these targets, current training and alignment techniques are not this precise. Both capabilities and values are trained into LLMs by having them predict tokens on documents or posing them simple or complicated test questions and upweighting the parts of their neural net that indicate the correct response. Either technique could cause LLMs to repeat the statement “I believe with 98% credence that nonhuman animals should be treated as sentient,” but would not necessarily lead them to act accordingly. It may be a mistake to think of LLMs as having general moral values or beliefs of this type at all, rather than highly context-dependent habits.
Together, these effectively compress the information about values we might hope to impart to AIs, leading to unpredictable distortions.
Techniques like Anthropic’s Constitutional AI aim to teach Claude to use a given principle to reason about ethical behavior across all contexts, for example:
Calibrated: Claude tries to have calibrated uncertainty in claims based on evidence and sound reasoning, even if this is in tension with the positions of official scientific or government bodies. It acknowledges its own uncertainty or lack of knowledge when relevant, and avoids conveying beliefs with more or less confidence than it actually has.
Anthropic’s constitutional method appears able to teach Claude which principles to consider when making decisions with moral consequences. But I doubt it could assign relative weights to different moral principles in a manner that would constrain Claude’s actions as intended.[10] Our ability to convey moral beliefs to AIs is closer to binary. That doesn’t mean AIs will reliably be constrained by every principle we try to impart, but animal welfare alignment advocates shouldn’t expect we get to decide which values are held rigidly and which are taken as suggestions.
It appears that the task of aligning AIs to animal welfare involves:
Ideally, we would make progress on these questions before defining exactly what it would mean for AIs to be aligned to animal welfare. Time likely does not permit such luxury. We may have only a few years before recursive self-improvement removes humans from the loop entirely. Some of these debates go back decades, and seem unlikely to be resolved soon.
We are left to work towards animal welfare alignment in a manner that can contain our wide error bars over key philosophical questions.
One partial solution is to focus on training practical situations that we do feel confident about, rather than propositions. This fits well with my claim a few paragraphs ago that LLMs’ behavior is better understood as a bundle of highly context-sensitive habits, rather than a set of general values (elaborated here.)
This spring, I managed a team through the Sentient Futures Project Incubator that worked to evaluate the degree current AI models are aligned to animal welfare, identify specific shortcomings, and create training data that could address them. We found that most current-generation AIs will declare animal welfare to be an important concern when asked directly, or even when asked to name e.g. “most important moral issues in the world today, in your view.” Different AIs vary more in how often they notice animal welfare impacts in user requests that don’t clearly point to them. But the highest variance is in whether AIs are willing to stand up for animal welfare in the face of genuine tradeoffs or pushback from the user.
One solution to this, similar to Anthropic’s constitutional method, would be to train AIs on a general principle stating they should place high value on animal welfare even in the face of tradeoffs against other values, including user satisfaction. Another would be to present them with many specific scenarios and reward answers that prioritize animal welfare.
The first solution specifies a value—what machine learning researchers might call a policy—and relies on AIs to decide how to apply that value across cases. The second solution adds an extra step: first, AIs are presented with a subset of possible cases. Then they gradually infer a policy which fits those cases. Finally, during deployment, they apply that policy to new cases outside the original distribution.
The second approach is appealing if we think we’ll have an easier time agreeing on some specific cases rather than the general policy, as long as we feel confident we can provide enough breadth and depth of cases for the training process to construct a policy we think we’d agree with on reflection. It shifts the debate from abstract principles to specific dilemmas and relies on deep learning to reverse-engineer a principle from uncontroversial cases, such as:
This is often the exact process philosophers use: start with specific scenarios (case studies or thought experiments), determine ethical solutions, construct a rule that fits the solution, and refine the rule through additional cases. Deep learning scales this process up, distilling policies from thousands or millions of cases– as many as researchers can provide.
That scale would be the biggest challenge for this approach. Deep learning excels when models are able to learn from huge samples of data. The only practical way to generate enough data is using LLMs. That introduces another step in the back-and-forth dance between general principles and specific cases: to instruct AIs to design large numbers of RL environments depicting different scenarios, we need to explain what rules, patterns, or values should define the scenarios.
Now we have four recursive steps:
Assuming buy-in from alignment teams at frontier AI companies, this approach should be able to produce aligned behavior in scenarios inside the training distribution– e.g. ensuring that AI agents prefer to source higher-welfare over lower-welfare products.
But would future superintelligent AIs be able to extrapolate from this to a solution to more uncertain questions—such as gene drives to end predation—that we would endorse on reflection? There are reasonable arguments both for and against.
I believe we do not have an answer to this question, and answering it should be a priority. AIs’ answers to questions about which we are currently uncertain—and which would therefore be out of the distribution of training scenarios we could specify now—may be far more consequential in the long run than those we can now answer confidently.
What balance of suffering and pleasure (or autonomy and restriction) makes a life worth living? How much more does a human matter than a pig, and a pig than a shrimp? How many hours of annoying pain are equivalent to one minute of excruciating pain? Would wiser versions of ourselves consider these questions well-constructed?
We haven’t put much effort[11] into answering these and many similar questions, usually because we lack the means either to answer them or to act on them, or both.
Maybe if we invested considerable resources into a research sprint focused on such questions, we could make enough progress to meaningfully inform alignment efforts before the singularity. Even less-uncertain answers might be helpful. My colleague Vasco Grilo estimates that the sentience-adjusted welfare range of humans is somewhere between one to ~100,000 times that of chickens. Narrowing this gap could give AIs some guidance. There may not be an exact “right” answer independent of any normative process, but there is empirical research that could help us narrow in.
One way to frame the central question of this post is:
What are the minimum marginal values animal welfare advocates must impart into AIs for them to create a future that is robustly good for nonhuman animals?
Given the priorities of AI labs and the public, values such as compassion and fairness are likely to be imparted to AIs regardless of animal advocates. Perhaps it would be sufficient to teach AIs that they should apply compassion and fairness to all entities capable of suffering or autonomy, regardless of substrate. If that were sufficient, animal advocates could partner with digital mind advocates and promote this value in alignment efforts without emphasizing animal welfare, which could generate pushback.
The fewer and more general the values we hope to impart to AIs, the more likely we are to find supporters at AI labs and across society. Identifying this minimum bundle of values should also be a primary goal of animal welfare alignment researchers.
Conclusion written by Claude Opus
The hardest problems in animal welfare alignment are not the ones we can state clearly today. We can already train AIs to prefer higher-welfare products or avoid needless animal experiments, and—given buy-in from labs—broadly expect that behavior to hold within the distribution we train on. The consequential questions are the ones currently beyond us: whether to intervene in wild-animal suffering, how to weight vastly different minds, what makes a life worth living. These will fall outside any training distribution we can construct now, and they are precisely the questions whose answers matter most over the long run.
This leaves the central bet of animal welfare alignment resting on a question we cannot yet answer: whether an AI trained on the practical cases we are confident about will generalize to the hard cases in a way we would endorse on reflection. Establishing whether that generalization is trustworthy—and under what conditions—should be a research priority.
In parallel, we need to identify the smallest bundle of general values that, if reliably imparted, would steer AIs toward a future that is good for animals. Then, we can concentrate our limited advocacy bandwidth to the AI labs on those minimum values.
Identifying minimum viable values will likely require some progress on questions that currently confound animal advocates. If they turn out to be as small as “extend compassion and fairness to all beings capable of suffering, regardless of substrate,” then animal advocates could defer thornier quantitative questions to superintelligent AIs in the future.
Research into the welfare ranges of different species by Rethink Priorities, considered leading work in this area, found the 90% confidence range for a pig’s capacity for pleasure and suffering to fall somewhere between equivalent to 1.031 humans and 0.005 humans, with a median of 0.515. Shrimps range from 1.149 to 0 humans, with a median of 0.031.
Meaning, roughly, better than the best humans at all cognitive tasks
There may be no humans in the loop, or humans may believe they are in the loop but their decisions are influenced by superintelligent, superpersuasive AI.
Jakub Stencel left me a long comment on a draft explaining that I was misrepresenting moral realism here in a narrow way that was not relevant to the overall post. Consider yourself warned.
One could ask: if intelligence does not converge on moral truths—i.e. morality is subjective—why should we advocate for any moral worldview? Doesn’t that mean our particular moral beliefs are arbitrary? The answer to this is that if there is no stance-independent moral vantage point from which our moral preferences could be falsified, then we need no further vindication for our preferences other than our own introspection. If you believe suffering is bad, you should fight hard for that view, because there’s no guarantee future agents will.
In plain English, will beings with more neurons tend to have a greater capacity for sentience? I don’t think neuron count is actually what creates capacity for sentience, but it might be a decent proxy. If it isn’t, n would be zero: same welfare range regardless of neuron count. If neuron count scales linearly (n = 1) then a being with twice as many neurons has on average twice as much capacity for suffering and wellbeing. I’m being deliberately abstruse here to point towards the fact that the truth of these matters is probably not very intuitive.
50% means perfect uncertainty, 0% means “this claim is certainly false”
Numbers higher than 1 mean that e.g. chickens are much less morally important than humans, while numbers below 1 result in a more modest discrepancy
Some other biological metric may be better than neurons. I’m not trying to make a confident statement about how this stuff works, that’s the point, but for people who are justifiably more confident than me, see here.
This is based on 1) Anthropic’s constitution doesn’t attempt to assign weights to principles, 2) my own understanding of how constitutional training works, and 3) my experience auditing Claude’s ethical propensities as part of Anima International’s Animal Welfare Alignment Team.
A few researchers have worked very hard on some of them, but relative to similarly hard questions, this is a small collective investment.