It was a pleasure to discuss my approach to forecasting with Jungwon and Amanda. I'd be happy to clarify anything that I failed to explain properly during our conversation, or to answer any questions related to the implementation or reasoning behind my "system" (if one may call it that).
The most trivial one, and I guess the less glamorous one, is to defer to the community
Hmm one issue I have with deferring to the community is that even in situations where it's individually epistemically valid, it seems to me to be bad for group epistemics to not form your own position. An analogy I use is a stock market where everybody only invests in index funds.
In the meantime, a few random thoughts. First, the index fund analogy suggests a self-correcting mechanism. Players defer to the community only to the degree that they expect it to track the truth more reliably than their individual judgment, given their time and ability constraints. As the reliability of the community prediction changes, in response to changes in the degree to which individual players defer to it, so will these players's willingness to defer to the community.
Second, other things equal, I think it's a desirable property of a prediction platform that it makes it rational for players to sometimes defer to the community. This could be seen as embodying the important and neglected truth that in many areas of life one can generally do better by deferring to society's collective wisdom than by going with one's individual opinion. Furthermore, it requires considerable ability to determine when and to what degree one should defer to others in any given case. In fact, this metacognitive skill of knowing how much more (or less) reliable other opinions are relative to one's own seems like a core epistemic virtue, and one that can be assessed only if users are allowed to defer to others.
Finally, insofar as there are reasons for wanting players not to defer to the community, I think the appropriate response is to change the scoring function rather than to ask players to exercise self-restraint. As fellow forecaster Tom Adamczewski reminded me, the Metaculus Scoring System page describes one such possible change:
It's easy to account for the average community prediction pc by adding a constant to each of these. For example, Slog(p,pc)=Slog(p)−Slog(pc). This way a player would get precisely zero points if they just go along with the community average.
Perhaps Metaculus could have two separate leaderboards: in addition to the current ranking, it could also display a ranking of players with the community component subtracted. These two rankings could be seen as measuring the quality of a player's "credences" and "impressions", respectively.
Then I go back to Emacs, position the cursor anywhere on the Metaculus section, and press a shortcut. A whole new question is created as a to-do task.
This is an aside, but you can generate org-mode entries from templates from anywhere in Emacs using org capture—you don't have to position your cursor in the correct section. This is one of my favorite features of org mode.
Yes, indeed. I was about to suggest an edit to the transcript to make that clear. When I created the Keyboard Maestro script, I was still relatively unfamiliar with Org mode so I didn't make use of org capture. But that's the proper way to do it.
My spacemacs config file is here. The main Keyboard Maestro macros I use are here. As noted, these macros were created back when I was beginning to use Emacs, so they don't make use of org capture or other native functionality (including Emacs own internal macros, or the even more powerful elmacro package). I plan to review these files at some point, but not in the immediate future. Happy to answer questions if anything is unclear.
My expectation is that in the long run, this might be somewhat helpful, but the main reason I actually built this system is not so much to improve my forecasting performance but more to improve my forecasting efficiency. Instead of spending 2 or three hours per day haphazardly back and forth between questions, here I have a systematic, deliberate approach that I can follow every day and that allows me to accomplish at least as much, perhaps even more, in just a fraction of the time.
This seems like a really good system/way of thinking about things. I feel like I'm much more driven by interest/excitement than systematic, deliberate approaches, and my vague intuition (hah!) is that interest/excitement generally outperforms systematization/deliberation in the short run but vastly underperforms it in the long run.
I use Emacs for my personal forecasts because it is convenient: the questions are in the todo-list, I can resolve the question with a few keystrokes, TODO-states make questions look beautiful, a small python script gives me a calibration chart…
To be honest, all major forecasting platforms have quite bad UX for small personal things, it always takes to many clicks to make forecasting question and so on. I wish they'd popularize personal predictions by having sort of "very quick capture" like many todo-list apps have [e.g. Amazing Marvin].
I forecast much fewer questions on GJ Open and found Tab Snooze to be an easy way to remind me that I wanted to make updates/take a look at new data.
This post contains an edited transcript of a conversation I had with Pablo Stafforini (kudos to Amanda Ngo for delightful editing). I wanted to learn how Pablo reasons about the future, what parts of his process seem most amenable to automation, and how tools might help scale up the work he’s doing. Pablo is a top forecaster ranked 14th on the Metaculus forecasting leaderboard.
I really enjoyed learning about Pablo’s forecasting system, and am excited to share it here for other people to learn from and build on. Here's an outline of what this post covers:
Highlights
Pablo and forecasting
A walkthrough of Pablo’s forecasting system
Scheduling
Notes and updates
Keyboard Maestro
Python integration
What matters most?
Reasoning about forecasting
Analyzing forecasts
How Elicit fits in
Highlights
Pablo has a “blitz chess” approach to forecasting: he only spends a few minutes per question, and forecasts on 5-10 questions a day.
Pablo’s system notifies him when a Metaculus question is released, creates an Emacs task for each question, prompts him to update regularly, and includes a notes section where he can track his thinking and updates.
When reasoning about forecasts, he asks himself:
How much should I defer to the community?
What should my priors be? Laplace's rule of succession and the Copernican principle are helpful tools for this.
Have people shared updates or models?
Is there an easy google search that will give me the data I need?
Jungwon: Pablo, thanks for taking the time to chat with us today. Maybe you can tell us a little bit about yourself and your background, and then we’ll talk about you as a forecaster and the awesome system you’ve built up.
Pablo: Sure. I’ve been involved with the Effective Altruism community for quite some time. I met both Will MacAskill and Toby Ord when I was a student at Oxford University over 10 years ago. Since then I’ve been involved with that community in one way or another: I worked at CEA for a number of years, and helped Will with his book “Doing Good Better”. Now I’m working on the preliminary stages of the process to create an encyclopedia of Effective Altruism. So that’s my general background.
I think I first became interested in forecasting after reading Tetlock’s book, Superforecasting. It’s a common experience for many people in this community. About a year and a half ago, I became active on Metaculus. Before that, I was intermittently using a very early, much more primitive site called PredictionBook, which people on LessWrong and people in the rationalist community generally have mentioned.
Jungwon: What do you find exciting about forecasting?
Pablo: The short answer is that I just find it intrinsically rewarding. I enjoy forecasting, pretty much in the same way other people enjoy video games, or stamp collecting. It’s also an activity broadly in line with my values.
I think the world would be a much better place if people approached predicting the future with the same level of rigor they have when explaining the past. Yet incalculably more books have been written about the past than about the future, and the fact that studying the past is more tractable than studying the future only partly explains this asymmetry. I think most people approach forecasting in what some authors call "far mode": as an exercise whose primary purpose is not to describe reality accurately, but to signal our aspirations, or something along those lines. However, as Robin Hanson likes to say, the future is just another point in time.
Jungwon: What does a week of Pablo’s forecasting look like? How frequently do you forecast and when do you do it?
Pablo: Everything I’m going to say in response to this, and presumably many of the other questions you'll ask me applies to the past couple of months. Before then I didn’t have my current system. Things have changed quite a bit in the last month or two.
With that caveat, here’s a typical week. I don't visit Metaculus at all or think about forecasting questions except in a window at night, maybe a couple of hours just before bedtime. At around 9pm I open up an Emacs file that lists all the questions that need to be updated for the day. I go one by one over those questions, read my notes if I have any notes, and process them as tasks. Then I look at the latest comments on Metaculus in case something relevant has occurred in the last 24 hours that should prompt me to update some of the predictions. Finally, I look at any questions that are closing in the next 24 hours and make sure that my prediction reflects my current beliefs. I also add any new questions to the Emacs list that were released in the last day.
Jungwon: What prompted you to set this system up?
Pablo: I felt that my spontaneous approach was very inefficient: I was not allocating my limited time in a sensible way, but was instead reacting to the questions the Metaculus algorithm decided to show me. Often I would notice that a prediction had become completely outdated due to the unfolding of some key event or the sheer passage of time.
A walkthrough of Pablo’s forecasting system
Jungwon: Cool, that seems like a great segue to get a walk through of your workflow system. Maybe it’s actually 9pm where you are, but if it’s not, let’s imagine it’s 9pm and you’re going through your flow.
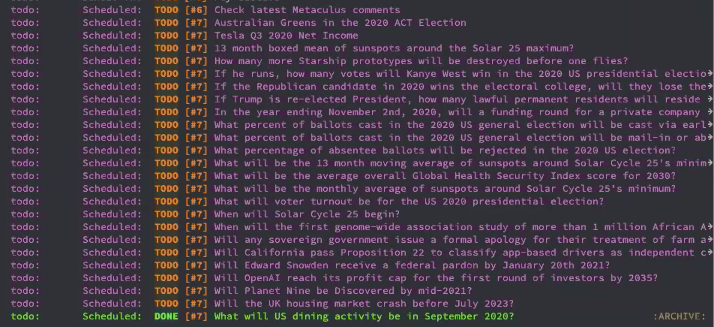
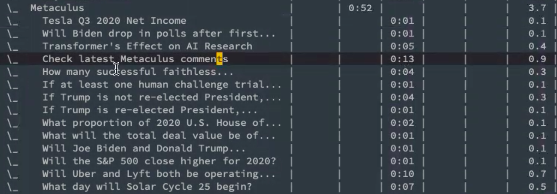
Pablo: It’s actually 4pm or so here but let’s pretend. So this is how the screen would look normally. On the right half I have the list of questions that I scheduled for today.
A list of questions scheduled for the day
Scheduling
Pablo: So I guess the first thing to talk about is how the scheduling works. I create a new question in Emacs every time a new Metaculus question is released.
1. IFTTT
First, I go to Gmail. I set up an If This Then That (IFTTT) integration to send me an email notification for every new Metaculus question released. For example, the question: “When will the first human head transplant occur?” was recently released. I open the question link in a new tab in my browser.
An IFTTT email system to notify Pablo whenever a new question is released
2. Emacs task
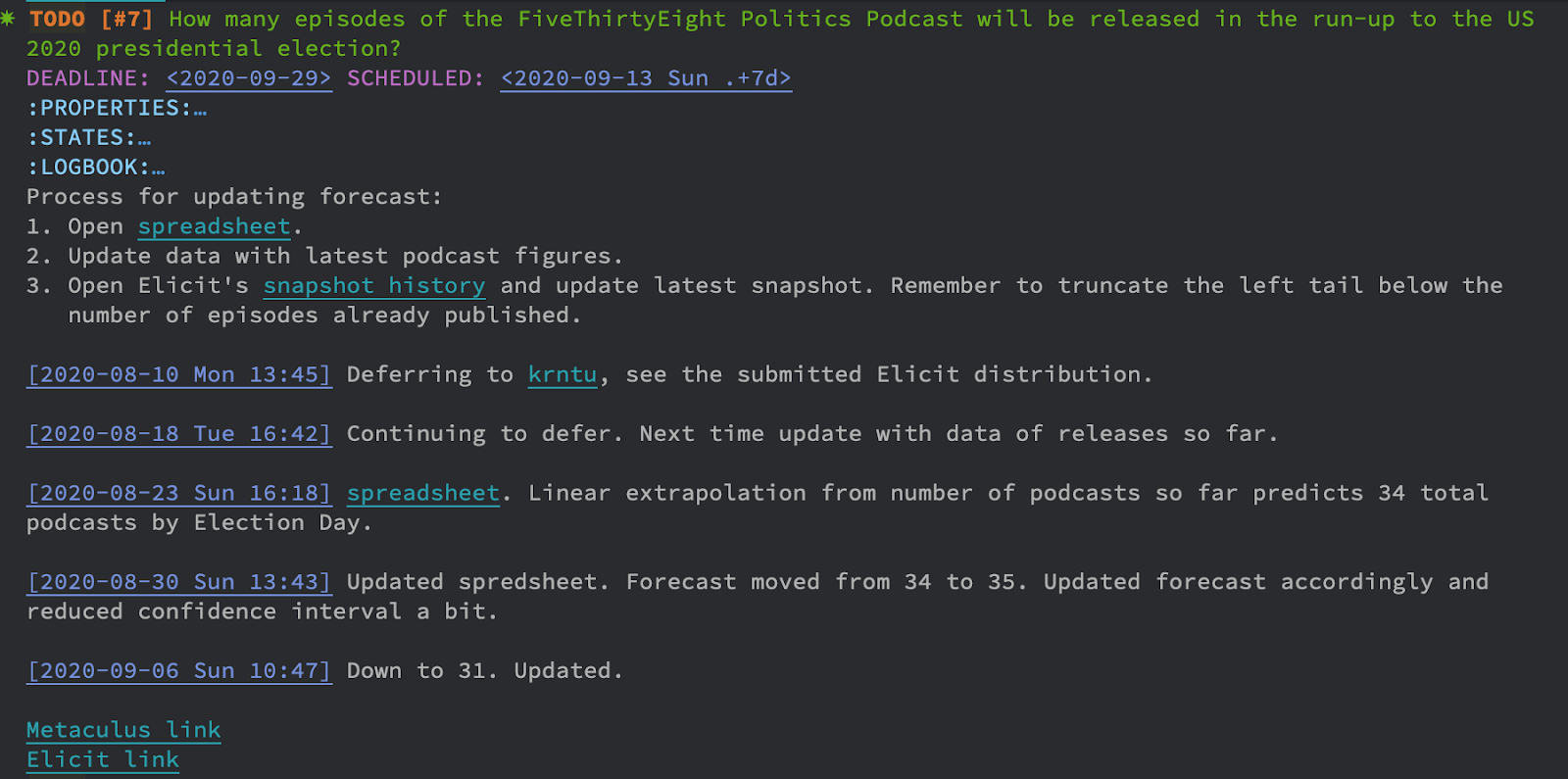
Then I go back to Emacs, position the cursor anywhere on the Metaculus section, and press a shortcut. A whole new question is created as a to-do task. It has a link to the Metaculus question itself, and a link to Elicit as well. There’s also the deadline; in this case it’s quite far into the future.
An Emacs task for a Metaculus question
The scheduling determines when the question next shows up in my Emacs task list for me to update my forecast. It’s relatively crude. I just calculate the number of days between the present and the deadline, and set the question to recur in my Emacs notifications a constant number of times within that window.
Notes and updates
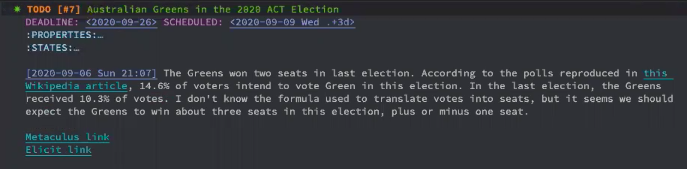
Once all the questions have been added in this way, each day they will show up, and it’s just a matter of processing them one by one. For some questions you might see that I have some notes. For instance, let’s take this one: Australian Greens in the 2020 ACT election.
An Emacs task for the Metaculus question on the Australian Green party
I take notes summarizing my thought process because my memory for these things isn’t very good. Usually the next time I go to a question, I forget what my reasons for assigning particular probabilities were. For this question, I’m trying to predict how many seats this party will win in the next election. I have no idea whatsoever about Australian politics, so I just go with the reference class. How did the Greens do in the previous election?
Reading the Wikipedia article tells me that in the 2016 election they had 10.3% of the votes. I don’t have a concrete forecast for how many seats they will have but at least I can compare how popular they were 4 years ago and how popular they are now and on that basis make an informed prediction. My prediction basically reflects what I wrote in the notes, with probability density given to values 1-5 to show my significant uncertainty about this.
The task page shows each update Pablo makes and an explanation
Keyboard Maestro
Jungwon: When you create a task, are you pulling information from the Metaculus API or are you scraping the page?
Pablo: I’m scraping the page. I don’t have any background in anything remotely related to computing. I’m just a philosopher, so everything I do is hacky and reflects my limited knowledge. But yeah, I used this tool called Keyboard Maestro. It obtains the title of the question and the dates, and does basic computations like calculate how many days remain until the question closes to determine how often the question should recur.
Python integration
Jungwon: Cool. Ok, let’s go back to the Emacs system. I think you were walking us through different notes you were keeping track of. Did you want to share more on that?
Pablo: Yeah sure. Here’s an interesting illustration of the power of the system. Sometimes I’m able to copy a Python script another Metaculus user has posted and run it directly from the Emacs task itself, which is quite handy. You don’t have to open any external app, you just press a shortcut key and the result will be outputted.
Running Python inline in Emacs
What matters most?
Jungwon: I’m noticing that your system has a few different features. One is notifications. Another is a record of your thoughts. Maybe another feature is the ability to run code inline, and maybe there are other features I haven’t identified yet either. If you were to rank them, let’s say some horrible person came and forced you to choose, which of those features do you think are most important to you?
Pablo: I think I would say the ability to record my thoughts with a timestamp so I can go back in time and see how I was approaching a particular question and reconstruct it. In my past system, I made spreadsheets for my forecasts. Looking back at them, it’s not immediately clear to me what exactly I should be looking at. By trying to put my thought process into words, that problem is avoided. I can just read what I wrote and that immediately tells me how I was thinking about my previous forecast.
Jungwon: It seems like you use Emacs for more than Metaculus, is that right?
Pablo: Yeah, as I said I only started using Emacs about 2 and a half months ago and I’m gradually using it more and more. My goal is to use it for everything.
Jungwon: Do you remember how much time it took you to set up your overall Emacs system and customize it for the Metaculus use case?
Pablo: I don’t remember, but one of the benefits of using Emacs is that, with a package called Org mode, you can keep track of how much time you spent on different tasks. Those records tell me that I have so far spent 43 hours and 21 minutes on activities broadly related to Emacs learning.
Reasoning process
Jungwon: So we’ve seen a few different types of approaches for reasoning you do for questions. One is the very common one, looking for base rates or historical comparisons. It also seems like you incorporate other predictions or comments a fair amount. Those are two different types of thinking that you do in your forecasting process. Can you think of other categories of approaches or reasoning that you engage with?
Pablo: So in general, given my time constraints, I approach this basically as a blitz chess analogue. I only have a few minutes to forecast each question if I want to answer every question.
1. Deferring to the community
The main decision is, how much will I defer to the community?Quite often I will defer to the community almost completely because I don’t have enough time to do the kind of research that would convince me that my opinion is more valuable than the community’s. If I had no constraints or my constraints were not so tight I would be less deferential to the community.
2. Generating priors
The second key question is, what’s going to be my prior? That’s where I think you can get the most bang for your buck. By spending just a couple of minutes on this, you can move from having no clue to making a decent guess. A tool I rely on constantly is Laplace's rule of succession. By simply knowing how many times an event has occurred I can estimate how many more times it is expected to occur before it fails once. Relatedly, what J. Richard Gott calls the Copernican principle can be surprisingly useful. Linch Zhang, another forecaster, has two useful posts [1] [2] listing many more "low information priors".
3. Shared information
The other low hanging fruit would be to see if anyone in the comments section has posted some updates or a link for a model. People often post Python models or updates about new developments. The way I learn about those things is mostly from Metaculus comments, because I don’t follow the news.
4. Google searches
Sometimes there’s an obvious google search that suggests itself from the way the question is phrased. So, going back to the Australian election, immediately the first thing that comes to mind when I see a question of that sort is, what do the polls say? Because we know that polls are as predictive as any other measure that we have about the outcome of an election. I also know that Wikipedia usually lists polling data. Quite often I just go to the Wikipedia article corresponding to a topic, if it’s related to politics, and find the kind of information I need.
Analyzing forecasts
Jungwon: How often do you go back and run analyses on time spent on questions, or review your reasoning and reflect on how you approached a question?
Pablo: At the end of the day I have this list in Emacs of how I spent the entire day. This information is also displayed in a table, so here, this shows you how I spent yesterday. I spent 52 minutes on Metaculus, and here are all the questions that I predicted. This illustrates the blitz analogy that I mentioned, because I’m spending only a couple of minutes per question.
Table of time spent on each task in a day
Jungwon: Am I correctly interpreting that this says you spent 52 minutes on something like 10 to 15 questions?
Pablo: Yeah, closer to 10. In the long run I predict between 5 and 10 questions per day.
Jungwon: So it seems like most of your reflection is happening on a daily basis, is that true? Do you ever go back and look at all the questions you predicted on?
Pablo: I should probably do something of that sort, it’s in the back of my mind. The only additional thing I do is whenever a question resolves I go to the task corresponding to that question and look at my reasoning to see if I can extract any obvious lessons. But I don’t have any systematic process for reflecting on this.
Jungwon: Have you noticed any patterns since doing that reflection?
Pablo: Not really, I think sort of on priors I would expect it to be helpful insofar as reflection is generally helpful. Given that I don’t usually remember my previous reasoning very well, having a record of things and being confronted with it when the question resolves is probably helpful in allowing me to draw lessons. For instance I might note that I decided to deviate from the community for some reason. If the community turns out to be right, I might make a slight update in the direction of not trusting that kind of reasoning in the future. Those sorts of things.
Jungwon: Do you feel like the way you’ve approached forecasting or the way you think about these questions has changed since you set up a new system?
Pablo: Yeah, I mean, as I told you before I only started using Metaculus a year and a half ago. Even before then I was sort of interested in forecasting on an intuitive, informal level. So I was always in the habit of making explicit forecasts about future events. I don’t generally expect to improve that much as a result of adopting this system in just a month or two.
My expectation is that in the long run, this might be somewhat helpful, but the main reason I actually built this system is not so much to improve my forecasting performance but more to improve my forecasting efficiency. Instead of spending 2 or three hours per day haphazardly back and forth between questions, here I have a systematic, deliberate approach that I can follow every day and that allows me to accomplish at least as much, perhaps even more, in just a fraction of the time.
How Elicit fits in
Jungwon: Ought has been working on the probability tool, Elicit, which you’ve been using to make forecasts. How do you use Elicit in your workflow?
Pablo: Yeah, there are a bunch of use cases.
1. Deferring to the community
The most trivial one, and I guess the less glamorous one, is to defer to the community. If I decide I should defer to the community and the community distribution is not a normal distribution, the easiest way to defer to it is to replicate that distribution in Elicit. I've actually been doing that quite a lot recently because I haven’t had time to process all the questions that have accumulated.
2. Truncating distributions
Another use case is to generate a truncated distribution. This can be very useful, especially where the passage of time should cause you to update because you don’t want to allocate any probability density to events in the past. Elicit can be very useful for doing that.
3. Integrating different intuitions
I think the more interesting use case is to integrate different intuitions that I have for approaching a question or a problem. I might have an intuition that the event will happen with 50% chance between this and that date, but I also have an intuition for the probability of a longer time interval, which might be partially overlapping. So I can just enter those credences into Elicit, and Elicit integrates those things and outputs a coherent distribution. That’s by far the most interesting use case that I’ve found, and that is not so easily replicable with other tools.
4. Expressing intuitions about specific ranges
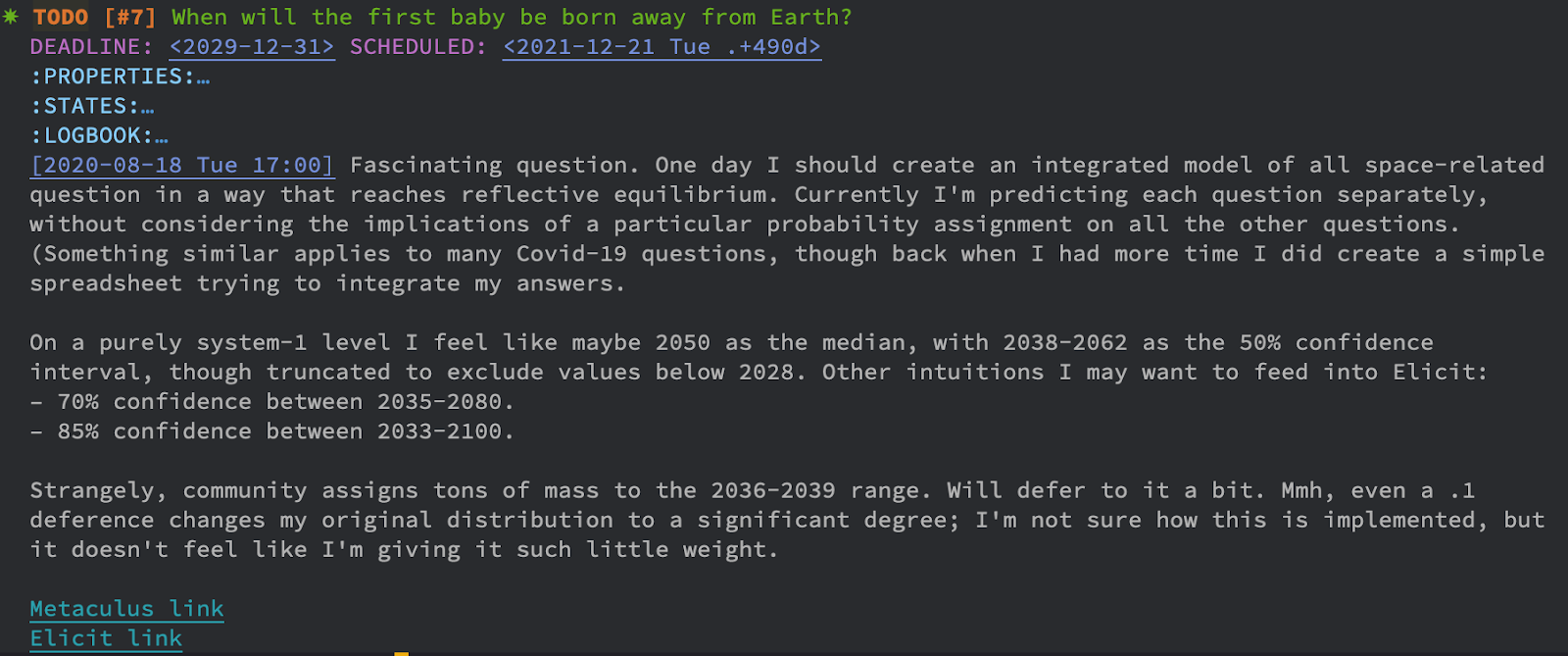
I also find it helpful when I have intuitions about specific ranges I want to plug into Elicit. Here’s an example where I had some intuitions about the probability that should be in certain date ranges.
Pablo's forecast, showing probabilities for date ranges he plugs into Elicit
Jungwon: Those are all the questions that I have today! Thanks so much for spending time with us on this Pablo, it was really awesome to get a peek into your extended brain.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
Why building and backing Welfare Tech companies may be one of the most promising things we can do for billions of animals.
I used AI to assist in writing this post, but I’ve rewritten it extensively and endorse it.
* Announcing the launch of Spring Innovation Fund, a not-for-profit venture philanthropy studio and fund built specifical...




It was a pleasure to discuss my approach to forecasting with Jungwon and Amanda. I'd be happy to clarify anything that I failed to explain properly during our conversation, or to answer any questions related to the implementation or reasoning behind my "system" (if one may call it that).