I must admit that I’m quite confused about some of the key definitions employed in this series, and, in part for that reason, I’m often confused about which claims are being made. Specifically, I’m confused about the definitions of “transformative AI” and “PASTA”, and find them to be more vague and/or less well-chosen than what sometimes seems assumed here. I'll try to explain below.
1. Transformative AI (TAI)
1.1 The simple definition
The simple definition of TAI used here is "AI powerful enough to bring us into a new, qualitatively different future". This definition seems quite problematic given how vague it is. Not that it is entirely meaningless, of course, as it surely does give some indication as to what we are talking about, yet it is far from meeting the bar that someone like Tetlock would require for us to track predictions, as a lot of things could be argued to (not) count as “a new, qualitatively different future.”
1.2 The Industrial Revolution definition
A slightly more elaborate definition found elsewhere, and referred to in a footnote in this series, is “software (i.e. a computer program or collection of computer programs) that has at least as profound an impact on the world’s trajectory as the Industrial Revolution did.” Alternative version of this definition: “AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.”
This might be a bit more specific, but it again seems to fall short of the Tetlock bar: what exactly do we mean by the term “the world’s trajectory”, and how would we measure an impact on it that is “at least as profound” as that of the Industrial Revolution?
For example, the Industrial Revolution occurred (by some definitions) roughly from 1760 to 1840, about 80 years during which the world economy got almost three times bigger, and we began to see the emergence of a new superpower, the United States. This may be compared to the last 80 years, from 1940 to 2020, what we may call “The Age of the Computer”, during which the economy has doubled almost five times (i.e. it’s roughly 30 times bigger). (In fact, by DeLong’s estimates, the economy more than tripled, i.e. surpassed the relative economic growth of the IR, in just the 25 years from 1940 to 1965.) And we saw the fall of a superpower, the Soviet Union; the rise of a new one, China; and the emergence of international institutions such as the EU and the UN.
So doesn’t “The Age of the Computer” already have a plausible claim to having had “at least as profound an impact on the world’s trajectory as the Industrial Revolution did”, even if no further growth were to occur? And by extension, could one not argue that the software of this age already has a plausible claim to having “precipitated” a transition comparable to this revolution? (This hints at the difficulty of specifying what counts as sufficient “precipitation” relative to the definition above: after all, we could not have grown the economy as much as we have over the last 80 years were it not for software, so existing software has clearly been a necessary and even a major component; yet it has still just been one among a number of factors accounting for this growth.)
1.3 The growth definition
A definition that seems more precise, and which has been presented as an operationalization of the previous definition, is phrased in terms of growth of the world economy, namely as “software which causes a tenfold acceleration in the rate of growth of the world economy (assuming that it is used everywhere [and] that it would be economically profitable to use it).”
I think this definition is also problematic, in that it fails in significant ways to capture what people are often worried about in relation to AI.
First, there is the relatively minor point that it is unclear in what cases we could be justified in attributing a tenfold acceleration in the economy to software (were such an acceleration to occur), rather than to a number of different factors that may all be similarly important, as was arguably the case in the Industrial Revolution.
For instance, if the rate of economic growth were to increase tenfold without software coming to play a significantly larger role in the economy than it does today, i.e. if its share of the world economy were to remain roughly constant, yet with software still being a critical component for this growth, would this software qualify as TAI by the definition above? (Note that our software can get a lot more advanced in an absolute sense even as its relative role in the economy remains largely the same.) It’s not entirely clear. (Not even if we consult the more elaborate “Definition #2” of TAI provided here.) And it’s not entirely irrelevant either, since economic growth appears to have been driven by an interplay of many different factors historically, and so the same seems likely to be true in the future.
But more critical, I think, is that the growth definition seems to exclude a large class of scenarios that would appear to qualify as “transformative AI” in the qualitative sense mentioned above, and scenarios that many concerned about AI would consider “transformative” and important. It is, after all, entirely conceivable, and arguably plausible, that we could get software that “would bring us into a new, qualitatively different future" without growth rates changing much. Indeed, growth rates could decline significantly, such that the world economy only grows by, e.g., one percent a year, and we could still — if such growth were to play out for another, say, 150 years — end up with “transformative AI” in the sense(s) that people are most worried about, and which could in principle entail a “value drift” and “lock-in” just as much as more rapidly developed AI.
I guess a reply might be that these are just very rough definitions and operationalizations, and that one shouldn’t take them to be more than that. But it seems that they often are taken to be more than that; for instance, the earlier-cited document that provides the growth definition appears to say about it that it “best captures what we ultimately care about as philanthropists”.
I think it is worth being clear that the definitions discussed above are in fact very vague and/or that they diverge in large and important ways from the AI scenarios people often worry about, including many of the scenarios that seem most plausible.
2. PASTA
PASTA was defined as: “AI systems that can essentially automate all of the human activities needed to speed up scientific and technological advancement.”
This leaves open how much of a speed-up we are talking about. It could be just a marginal speed-up (relative to previous growth rates), or it could be a speed-up by orders of magnitude. But in some places it seems that the latter is implicitly assumed.
One might, of course, argue that automating all human activities related to scientific and technological progress would have to imply a rapid speed-up, but this is not necessarily the case. It is conceivable, and in my view quite likely, that such automation could happen very gradually, and that we could transition to fully or mostly automated science in a manner that implies growth rates that are similar to those we see today.
We have, after all, automated/outsourced much of science today, to such an extent that past scientists might say that we have, relative to their perspective, already automated the vast majority of science, with scientifically-related calculations, illustrations, simulations, manufacturing, etc. that are, by their standards, mostly done by computers and other machines. And this trend could well continue without being more explosive than the growth we have seen so far. In particular, the step from 90 percent to 99 percent automated science (or across any similar interval) could happen over years, at a familiar and fairly steady growth rate.
I think it’s worth being clear that the intuition that fully automated science is in some sense inevitable (assuming continued technological progress) does not imply that a growth explosion is inevitable, or even that such an explosion is more likely to happen than not.
On "transformative AI": I agree that this is quite vague and not as well-defined as it would ideally be, and is not the kind of thing I think we could just hand to superforecasters. But I think it is pointing at something important that I haven't seen a better way of pointing at.
I like the definition given in Bio Anchors (which you link to), which includes a footnote addressing the fact that AI could be transformative without literally causing GDP growth to behave as described. I'm sure there are imperfections remaining, and it remains vague, but I think most people can get a pretty good idea of what's being pointed at there, and I think it reasonably fleshes out the vaguer, simpler definition (which I think is also useful for giving a high-level impression).
In this series, I mostly stuck with the simple definition because I think the discussion of PASTA and digital people makes it fairly easy to see what kind of specific thing I'm pointing at, in a different way.
I am not aware of places where it's implied that "transformative AI" is a highly well-defined concept suitable for superforecasters (and I don't think the example you gave in fact implies this), but I'm happy to try to address them if you point them out.
On PASTA: my view is that there is a degree of automation that would in fact result in dramatically faster scientific progress than we've ever seen before. I don't think this is self-evident, or tightly proven by the series, but it is something I believe, and I think the series does a reasonable job pointing to the main intuitions behind why I believe it (in particular, the theoretical feedback loop this would create, the "modeling the human trajectory" projection of what we might expect if the "population bottleneck" were removed, and the enormous transformative potential of particular technologies that might result).
I'm sure there are imperfections remaining, and it remains vague, but I think most people can get a pretty good idea of what's being pointed at there, and I think it reasonably fleshes out the vaguer, simpler definition (which I think is also useful for giving a high-level impression).
I'd disagree that most people can get a good idea of what's being pointed at; not least for the reasons I outlined in Section 1.2 above, regarding how advanced software could already reasonably be claimed to have "precipitate[d] a transition comparable to (or more significant than) the agricultural or industrial revolution". :)
So I'd also disagree that it "reasonably fleshes out the vaguer, simpler definition". Indeed, I don't think "Transformative AI" is a much clearer term than, say, "Advanced AI" or "Powerful AI", but it often seems used as though it's much clearer (see e.g. below).
I am not aware of places where it's implied that "transformative AI" is a highly well-defined concept suitable for superforecasters (and I don't think the example you gave in fact implies this), but I'm happy to try to address them if you point them out.
My point wasn't about superforecasters in particular. Rather, my point was that the current definitions of TAI are so vague that it doesn't make much sense to talk about, say, "the year by which transformative AI will be developed". Again, it is highly unclear what would count and how one would resolve any forecast about it.
As for (super)forecasters, I wonder: if the concept/definition is not "suitable for superforecasters" — that is, for clearly resolvable forecasts — why is it suitable for attempts to forecast this "one number[i.e. the year by which transformative AI will be developed]"? If one doesn't think it allows for clearly resolvable forecasts, perhaps it would be good to note that from the outset, and when making estimates such as "more than a 10% chance of 'transformative AI' within 15 years".
sidenote: There has been an argument that 'radically transformative AI' is a better term for the Industrial Revolution definition, given the semantic bleaching already taking place with 'transformative AI'.
See also this piece for a bit of a more fleshed out argument along these lines, which I don't agree with fully as stated (I don't think it presents a strong case for transformative AI soon), but which I think gives a good sense of my intuitions about in-principle feasibility.
I'd be interested to hear your disagreements sometime! To clarify, the point of my post was not to present a strong case for transformative AI soon, but rather to undermine a class of common arguments against that hypothesis.
Hm, I may have simply misread or mis-recalled your piece w/r/t the parenthetical, apologies for that. I skimmed it again and didn't note any strong disagreements, except that "almost zero evidence" seems likely further than I would go (it would take me more time to figure out exactly where I stand on this).
What would a plausible capabilities timeline look like, such that we could mark off progress against it?
Rather than replacing jobs in order of the IQ of humans that typically end up doing them (the naive anthropocentric view of "robots getting smarter"), what actually seems to be happening is that AI and robotics develop capabilities for only part of a job at a time, but they do it cheap and fast, and so there's an incentive for companies/professions to restructure to take advantage of AI. Progressions of jobs eliminated is therefore going to be weird and sometimes ill-defined. So it's probably better to try to make a timeline of capabilities, rather than a timeline of doable jobs.
Actually, this probably requires brainstorming from people more in-touch with machine learning than me. But for starters, human-level performance on all current quantifiable benchmarks (from Allen Institute's benchmark of primary-school test questions [easy?] to Mine-RL BASALT [hard?]) would be very impressive.
I think it's useful to talk about job displacement as well, even if it's partial rather than full. We've talked about job displacement due to automation (most of which is unrelated to AI) for centuries, and it seems useful to me. It doesn't assume that machines (e.g. AI) are solving tasks in the same way as humans would do; only that they reduce the need for human labour. Though I guess it depends on what you want to do - for some purposes, it may be more useful to look at AI capabilities regarding more specific tasks.
That's a good point. I'm a little worried that coarse-grained metrics like "% unemployment" or "average productivity of labor vs. capital" could fail to track AI progress if AI increases the productivity of labor. But we could pick specific tasks like making a pencil, etc. and ask "how many hours of human labor did it take to make a pencil this year?" This might be hard for diverse task categories like writing a new piece of software though.
I think you have an acronym collision here between HLMI = "human-level machine intelligence" = "high-level machine intelligence". Your overall conclusion still seems right to me, but this collision made things confusing.
Details
I got confused because the evidence provided in footnote 11 didn't seem (to me) like it implied "that the researchers simply weren't thinking very hard about the questions". Why would "human-level machine intelligence" imply the ability to automate the labour of all humans?
My confusion was resolved by looking up the definition of HLMI in part 4 of Bio Anchors. There, HLMI is referring to "high-level machine intelligence". If you go back to Grace et al. 2017, they defined this as:
“High-level machine intelligence” (HLMI) is achieved when unaided machines can accomplish every task better and more cheaply than human workers.
This seems stronger to me than human-level! Even "AI systems that can essentially automate all of the human activities needed to speed up scientific and technological advancement" (the definition of PASTA above) could leave some labour out, but this definition does not.
I think your conclusion is still right. There shouldn't have been a discrepancy between the forecasts for HLMI and "full automation" (defined as "when for any occupation, machines could be built to carry out the task better and more cheaply than human workers"). Similarly, the expected date for the automation of AI research, a job done by human workers, should not be after the expected date for HLMI.
Still, I would change the acronym and maybe remove the section of the footnote about individual milestones; the milestones forecasting was a separate survey question from the forecasting of automation of specific human jobs, and it was more confusing to skim through Grace et al. 2017 expecting those data points to have come from the same question.
Thanks for the correction! I've corrected the term in the Cold Takes version. (I'm confining corrections to that version rather than correct there, here, LessWrong, the PDF, etc. every time; also, editing posts here can cause bugs.)
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Audio version available at Cold Takes (or search Stitcher, Spotify, Google Podcasts, etc. for "Cold Takes Audio")
This is one of 4 posts summarizing hundreds of pages of technical reports focused almost entirely on forecasting one number: the year by which transformative AI will be developed.1
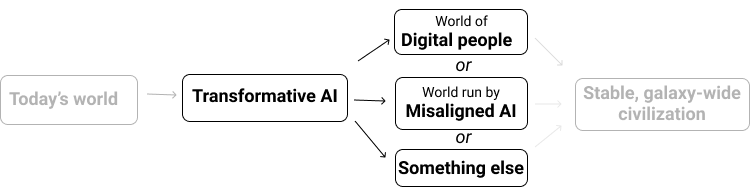
By "transformative AI," I mean "AI powerful enough to bring us into a new, qualitatively different future." I specifically focus on what I'm calling PASTA: AI systems that can essentially automate all of the human activities needed to speed up scientific and technological advancement.
The sooner PASTA might be developed, the sooner the world could change radically, and the more important it seems to be thinking today about how to make that change go well vs. poorly.
In this post and the next, I will talk about the forecasting methods underlying my current view: I believe there's more than a 10% chance we'll see something PASTA-like enough to qualify as "transformative AI" within 15 years (by 2036); a ~50% chance we'll see it within 40 years (by 2060); and a ~2/3 chance we'll see it this century (by 2100).
I'm not sure whether it will feel as though transformative AI is "on the way" long before it arrives. I'm hoping, instead, that we can use trends in key underlying facts about the world (such as AI capabilities, model size, etc.) to forecast a qualitatively unfamiliar future.
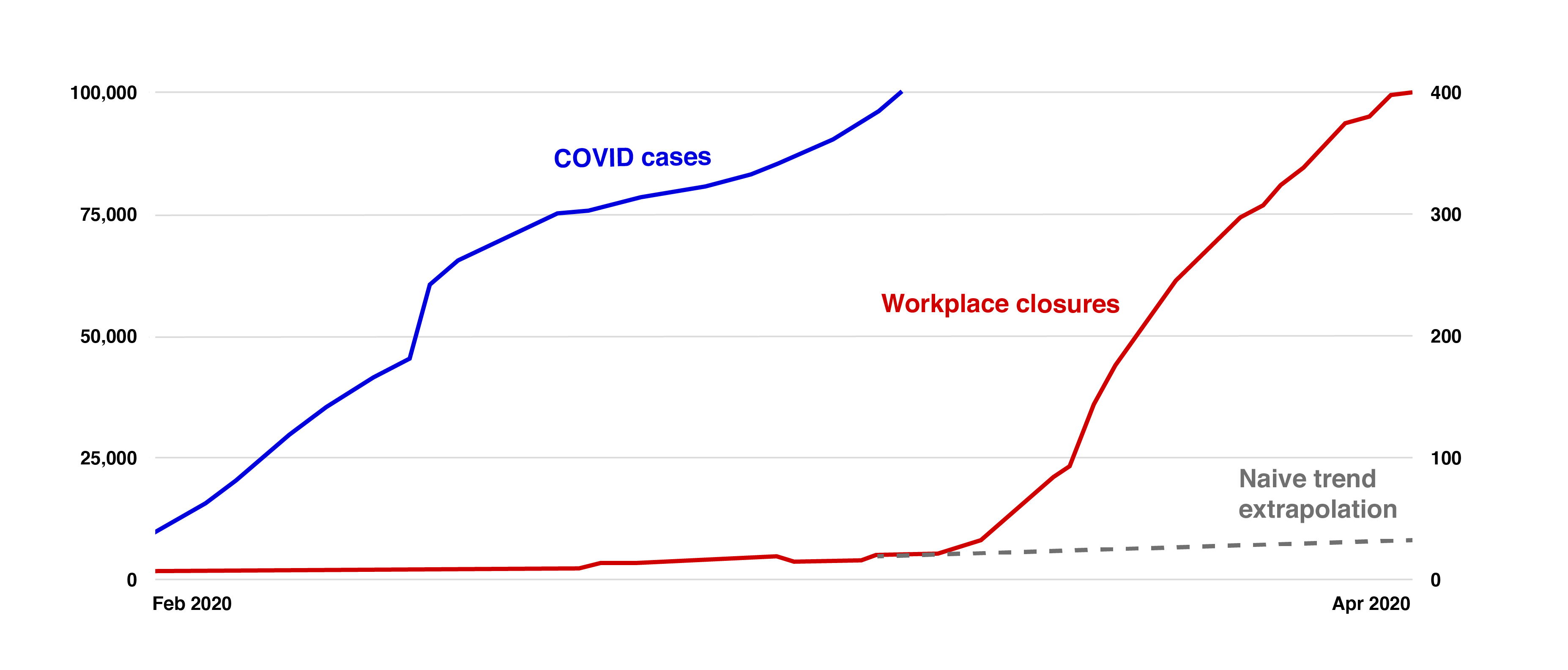
An analogy for this sort of forecasting would be something like: "This water isn't bubbling, and there are no signs of bubbling, but the temperature has gone from 70° Fahrenheit2 to 150°, and if it hits 212°, the water will bubble." Or: "It's like forecasting school closures and overbooked hospitals, when there aren't any yet, based on trends in reported infections."
Discuss whether we can look for trends in how "impressive" or "capable" AI systems are. I think this approach is unreliable: (a) AI progress may not "trend" in the way we expect; (b) in my experience, different AI researchers have radically different intuitions about which systems are impressive or capable, and how progress is going.
Briefly discuss Grace et al 2017, the best existing survey of AI researchers on transformative AI timelines. Its conclusions broadly seem in line with my own forecasts, though there are signs the researchers weren't thinking very hard about the questions.
There are a couple of ways in which forecasting transformative AI is different from the kind of forecasting we might be used to.
First, I'm forecasting over very long time horizons (decades), unlike e.g. a weather forecast (days) or an election forecast (months). This makes the task quite a bit harder,3 and harder for outsiders to evaluate since I don't have a clearly relevant track record of making forecasts on similar topics.
Second, I lack rich, clearly relevant data sources, and I can't look back through a bunch of similar forecasts from the past. FiveThirtyEight's election forecasts look at hundreds of polls, and they have a model of how well polls have predicted elections in the past. Forecasting transformative AI needs to rely more on intuition, guesswork and judgment, in terms of determining what data is most relevant and how it's relevant.
Finally, I'm trying to forecast a qualitatively unfamiliar future. Transformative AI - and the strange future it comes with - doesn't feel like something we're "trending toward" year to year.
If I were trying to forecast when the world population would hit 10 billion, I could simply extrapolate existing trends of world population. World population itself is known to be growing and can be directly estimated. In my view, extrapolating out a long-running trend is one of the better ways to make a forecast.
When FiveThirtyEight makes election forecasts, there's a background understanding that there's going to be an election on a certain date, and whoever wins will take office on another date. We all buy into that basic framework, and there's a general understanding that better polling means a better chance of winning.
By contrast, transformative AI - and the strange future it comes with - isn't something we're "headed for" in any clearly measurable way. There's no clear metric like "transformativeness of AI" or "weirdness of the world" that's going up regularly every year such that we can project it out into the future and get the date that something like PASTA will be developed.
Perhaps for some, these points gives enough reason to ignore the whole possibility of transformative AI, or assume it's very far away. But I don't think this is a good idea, for a couple of reasons.
First, I have a background view that something like PASTA is in a sense "inevitable," assuming continued advances in society and computing. The basic intuition here - which I could expand on if there's interest - is that human brains are numerous and don't seem to need particular rare materials to produce, so it should be possible at some point to synthetically replicate the key parts of their functionality.4
At the same time, I'm not confident that PASTA will feel qualitatively as though it's "on the way" well before it arrives. (More on this below.) So I'm inclined to look for ways to estimate when we can expect this development, despite the challenges, and despite the fact that it doesn't feel today as though it's around the corner.
I think there are plenty of example cases where a qualitatively unfamiliar future could be seen in advance by plotting the trend in some underlying, related facts about the world. A few that come to mind:
When COVID-19 first emerged, a lot of people had trouble taking it seriously because it didn't feel as though we were "trending toward" or "headed for" a world full of overflowing hospitals, office and school closures, etc. At the time (say, January 2020), there were a relatively small number of cases, an even smaller number of deaths, and no qualitative sense of a global emergency. The only thing alarming about COVID-19, at first, was that case counts were growing at a fast exponential rate (though the overall number of cases was still small). But it was possible to extrapolate from the fast growth in case counts to a risk of a global emergency, and some people did. (And some didn't.)
Climatologists forecast a global rise in temperatures that's significantly more than what we've seen over the past few decades, and could have major consequences far beyond what we're seeing today. They do this by forecasting trends in greenhouse gas emissions and extrapolating from there to temperature and consequences. If you simply tried to ask "How fast is the temperature rising?" or "Are hurricanes getting worse?", and based all your forecasts of the future on those, you probably wouldn't be forecasting the same kinds of extreme events around 2100.5
To give a more long-run example, we can project a date by which the sun will burn out, and conclude that the world will look very different by that date than it does now, even though there's no trend of things getting colder or darker today.
COVID-19 cases from WHO. Workplace closures are from this OWiD data, simply scored as 1 for "recommended," 2 for "required for some," 3 for "required for all but key workers" and summed across all countries.
An analogy for this sort of forecasting would be something like: "This water isn't bubbling, and there are no signs of bubbling, but the temperature has gone from 70° Fahrenheit6 to 150°, and if it hits 212°, the water will bubble."
Ideally, I can find some underlying factors that are changing regularly enough for us to predict them (such as growth in the size and cost of AI models), and then argue that if those factors reach a certain point, the odds of transformative AI will be high.
You can think of this approach as answering the question: "If I think something like PASTA is inevitable, and I'm trying to guess the timing of it using a few different analysis methods, what do I guess?" We can separately ask "And is there reason that this guess is implausible, untrustworthy, or too 'wild?'" — this was addressed in the previous piece in this series.
If we're looking for some underlying factors in the world that predict when transformative AI is coming, perhaps the first thing we should look for is trends in how "impressive" or "capable" AI systems are.
The easiest version of this would be if the world happened to shake out such that:
One day, for the first time, an AI system managed to get a passing grade on a 4th-grade science exam.
Then we saw the first AI passing (and then acing) a 5th grade exam, then 6th grade exam, etc.
Then we saw the first AI earning a PhD, then the first AI writing a published paper, etc. all the way up to the first AI that could do Nobel-Prize-worthy science work.
This all was spread out regularly over the decades, so we could clearly see the state of the art advancing from 4th grade to 5th grade to 6th grade, all the way up to "postdoc" and beyond. And all of this happened slowly and regularly enough that we could start putting a date on "full-blown scientist AI" several decades in advance.
It would be very convenient - I almost want to say "polite" - of AI systems to advance in this manner. It would also be "polite" if AI advanced in the way that some people seem to casually imagine it will: first taking over jobs like "truck driver" and "assembly line worker," then jobs like "teacher" and "IT support," and then jobs like "doctor" and "lawyer," before progressing to "scientist."
Either of these would give us plenty of lead time and a solid basis to project when science-automating AI is coming. Unfortunately, I don't think we can count on such a thing.
AI seems to progress very differently from humans. For example, there were superhuman AI chess players7 long before there was AI that could reliably tell apart pictures of dogs and cats.8
One possibility is that AI systems will be capable of the hardest intellectual tasks insects can do, then of the hardest tasks mice and other small mammals can do, then monkeys, then humans - effectively matching the abilities of larger and larger brains. If this happened, we wouldn't necessarily see many signs of AI being able to e.g. do science until we were very close. Matching a 4th-grader might not happen until the very end.
Another possibility is that AI systems will be able to do anything that a human can do within 1 second, then anything that a human can do within 10 seconds, etc. This could also be quite a confusing progression that makes it non-obvious how to forecast progress.
Actually, if we didn't already know how humans tend to mature, we might find a child's progress to be pretty confusing and hard to extrapolate. Watching someone progress from birth to age 8 wouldn't necessarily give you any idea that they were, say, 1/3 of the way to being able to start a business, make an important original scientific discovery, etc. (Even knowing the usual course of human development, it's hard to tell from observing an 8-year-old what professional-level capabilities they could/will end up with in adulthood.)
Overall, it's quite unclear how we should think about the spectrum from "not impressive/capable" to "very impressive/capable" for AI. And indeed, in my experience, different AI researchers have radically different intuitions about which systems are impressive or capable, and how progress is going. I've often had the experience of seeing one AI researcher friend point to some new result and say "This is huge, how can anyone not see how close we're getting to powerful AI?" while another says "This is a minor advance with little significance."9
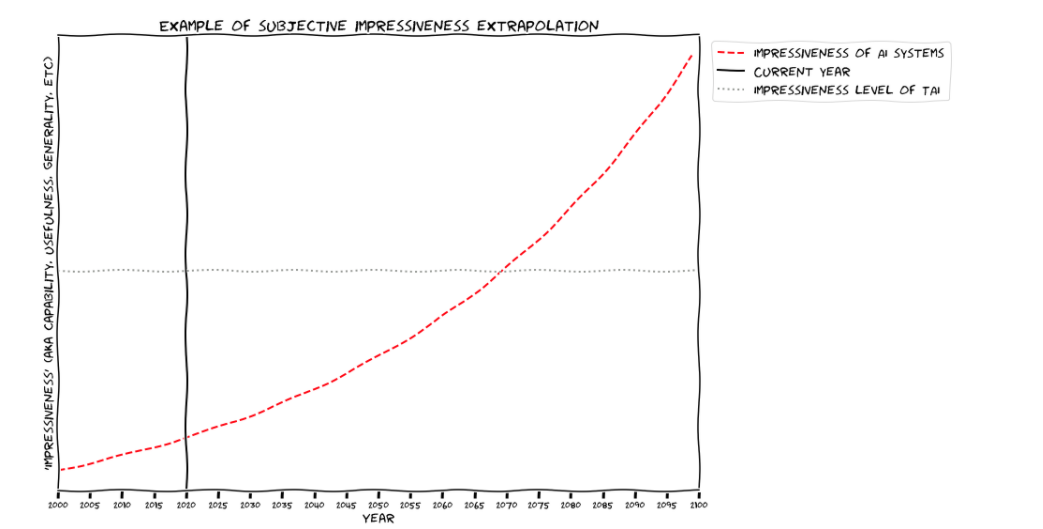
It would be great if we could forecast the year transformative AI will be developed, by using a chart like this (from Bio Anchors; "TAI" means "transformative AI"):
But as far as I can tell, there's no way to define the y-axis that wouldn't be fiercely debated between experts.
Surveying experts
One way to deal with this uncertainty and confusion would be to survey a large number of experts and simply ask them when they expect transformative AI to be developed. We might hope that each of the experts (or at least, many of them) is doing their own version of the "impressiveness extrapolation" above - or if not, that they're doing something else that can help them get a reasonable estimate. By averaging many estimates, we might get an aggregate that reflects the "wisdom of crowds."10
I think the best version of this exercise is Grace et al 2017, a survey of 352 AI researchers that included a question about “when unaided machines can accomplish every task better and more cheaply than human workers" (which would presumably include tasks that advance scientific and technological development, and hence would qualify as PASTA). The two big takeaways from this survey, according to Bio Anchors and me, are:
A ~20% probability of this sort of AI by 2036; a ~50% probability by 2060; a ~70% probability by 2100. These match the figures I give in the introduction.
Much later estimates for slightly differently phrased questions (posed to a smaller subset of respondents), implying (to me) that the researchers simply weren't thinking very hard about the questions.11
My bottom line: this evidence is consistent with my current probabilities, though potentially not very informative. The next piece in this series will be entirely focused on Ajeya Cotra's "Forecasting Transformative AI with Biological Anchors," the forecasting method I find most informative here.
Of course, the answer could be "A kajillion years from now" or "Never." ↩
Centigrade equivalents for this sentence: 21°, 66°, 100° ↩
See also this piece for a bit of a more fleshed out argument along these lines, which I don't agree with fully as stated (I don't think it presents a strong case for transformative AI soon), but which I think gives a good sense of my intuitions about in-principle feasibility. Also see On the Impossibility of Supersized Machines for some implicit (joking) responses to many common arguments for why transformative AI might be impossible to create. ↩
For example, see the temperature chart here - the lowest line seems like it would be a reasonable projection, if temperature were the only thing you were looking at. ↩
Centigrade equivalents for this sentence: 21°, 66°, 100° ↩
From Bio Anchors: "We have heard ML experts with relatively short timelines argue that AI systems today can essentially see as well as humans, understand written information, and beat humans at almost all strategy games, and the set of things they can do is expanding rapidly, leading them to expect that transformative AI would be attainable in the next decade or two by training larger models on a broader distribution of ML problems that are more targeted at generating economic value. Conversely, we have heard ML experts with relatively long timelines argue that ML systems require much more data to learn than humans do, are unable to transfer what they learn in one context to a slightly different context, and don’t seem capable of much structured logical and causal reasoning; this leads them to believe we would need to make multiple major breakthroughs to develop TAI. At least one Open Philanthropy technical advisor has advanced each of these perspectives." ↩
Wikipedia: "The classic wisdom-of-the-crowds finding ... At a 1906 country fair in Plymouth, 800 people participated in a contest to estimate the weight of a slaughtered and dressed ox. Statistician Francis Galton observed that the median guess, 1207 pounds, was accurate within 1% of the true weight of 1198 pounds." ↩
Some researchers were asked to forecast “HLMI” as defined above [human-level machine intelligence, which I would take to include something like PASTA], while a randomly-selected subset was instead asked to forecast “full automation of labor”, the time when “all occupations are fully automatable.” Despite the fact that achieving HLMI seems like it should quickly lead to full automation of labor, the median estimate for full automation of labor was ~2138 while the median estimate for HLMI was ~2061, almost 80 years earlier.
Random subsets of respondents were asked to forecast when individual milestones (e.g. laundry folding, human-level StarCraft, or human-level math research) would be achieved. The median year by which respondents expected machines to be able to automate AI research was ~2104, while the median estimate for HLMI was ~2061 -- another clear inconsistency because “AI research” is a task done by human workers.↩

I must admit that I’m quite confused about some of the key definitions employed in this series, and, in part for that reason, I’m often confused about which claims are being made. Specifically, I’m confused about the definitions of “transformative AI” and “PASTA”, and find them to be more vague and/or less well-chosen than what sometimes seems assumed here. I'll try to explain below.
1. Transformative AI (TAI)
1.1 The simple definition
The simple definition of TAI used here is "AI powerful enough to bring us into a new, qualitatively different future". This definition seems quite problematic given how vague it is. Not that it is entirely meaningless, of course, as it surely does give some indication as to what we are talking about, yet it is far from meeting the bar that someone like Tetlock would require for us to track predictions, as a lot of things could be argued to (not) count as “a new, qualitatively different future.”
1.2 The Industrial Revolution definition
A slightly more elaborate definition found elsewhere, and referred to in a footnote in this series, is “software (i.e. a computer program or collection of computer programs) that has at least as profound an impact on the world’s trajectory as the Industrial Revolution did.” Alternative version of this definition: “AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.”
This might be a bit more specific, but it again seems to fall short of the Tetlock bar: what exactly do we mean by the term “the world’s trajectory”, and how would we measure an impact on it that is “at least as profound” as that of the Industrial Revolution?
For example, the Industrial Revolution occurred (by some definitions) roughly from 1760 to 1840, about 80 years during which the world economy got almost three times bigger, and we began to see the emergence of a new superpower, the United States. This may be compared to the last 80 years, from 1940 to 2020, what we may call “The Age of the Computer”, during which the economy has doubled almost five times (i.e. it’s roughly 30 times bigger). (In fact, by DeLong’s estimates, the economy more than tripled, i.e. surpassed the relative economic growth of the IR, in just the 25 years from 1940 to 1965.) And we saw the fall of a superpower, the Soviet Union; the rise of a new one, China; and the emergence of international institutions such as the EU and the UN.
So doesn’t “The Age of the Computer” already have a plausible claim to having had “at least as profound an impact on the world’s trajectory as the Industrial Revolution did”, even if no further growth were to occur? And by extension, could one not argue that the software of this age already has a plausible claim to having “precipitated” a transition comparable to this revolution? (This hints at the difficulty of specifying what counts as sufficient “precipitation” relative to the definition above: after all, we could not have grown the economy as much as we have over the last 80 years were it not for software, so existing software has clearly been a necessary and even a major component; yet it has still just been one among a number of factors accounting for this growth.)
1.3 The growth definition
A definition that seems more precise, and which has been presented as an operationalization of the previous definition, is phrased in terms of growth of the world economy, namely as “software which causes a tenfold acceleration in the rate of growth of the world economy (assuming that it is used everywhere [and] that it would be economically profitable to use it).”
I think this definition is also problematic, in that it fails in significant ways to capture what people are often worried about in relation to AI.
First, there is the relatively minor point that it is unclear in what cases we could be justified in attributing a tenfold acceleration in the economy to software (were such an acceleration to occur), rather than to a number of different factors that may all be similarly important, as was arguably the case in the Industrial Revolution.
For instance, if the rate of economic growth were to increase tenfold without software coming to play a significantly larger role in the economy than it does today, i.e. if its share of the world economy were to remain roughly constant, yet with software still being a critical component for this growth, would this software qualify as TAI by the definition above? (Note that our software can get a lot more advanced in an absolute sense even as its relative role in the economy remains largely the same.) It’s not entirely clear. (Not even if we consult the more elaborate “Definition #2” of TAI provided here.) And it’s not entirely irrelevant either, since economic growth appears to have been driven by an interplay of many different factors historically, and so the same seems likely to be true in the future.
But more critical, I think, is that the growth definition seems to exclude a large class of scenarios that would appear to qualify as “transformative AI” in the qualitative sense mentioned above, and scenarios that many concerned about AI would consider “transformative” and important. It is, after all, entirely conceivable, and arguably plausible, that we could get software that “would bring us into a new, qualitatively different future" without growth rates changing much. Indeed, growth rates could decline significantly, such that the world economy only grows by, e.g., one percent a year, and we could still — if such growth were to play out for another, say, 150 years — end up with “transformative AI” in the sense(s) that people are most worried about, and which could in principle entail a “value drift” and “lock-in” just as much as more rapidly developed AI.
I guess a reply might be that these are just very rough definitions and operationalizations, and that one shouldn’t take them to be more than that. But it seems that they often are taken to be more than that; for instance, the earlier-cited document that provides the growth definition appears to say about it that it “best captures what we ultimately care about as philanthropists”.
I think it is worth being clear that the definitions discussed above are in fact very vague and/or that they diverge in large and important ways from the AI scenarios people often worry about, including many of the scenarios that seem most plausible.
2. PASTA
PASTA was defined as: “AI systems that can essentially automate all of the human activities needed to speed up scientific and technological advancement.”
This leaves open how much of a speed-up we are talking about. It could be just a marginal speed-up (relative to previous growth rates), or it could be a speed-up by orders of magnitude. But in some places it seems that the latter is implicitly assumed.
One might, of course, argue that automating all human activities related to scientific and technological progress would have to imply a rapid speed-up, but this is not necessarily the case. It is conceivable, and in my view quite likely, that such automation could happen very gradually, and that we could transition to fully or mostly automated science in a manner that implies growth rates that are similar to those we see today.
We have, after all, automated/outsourced much of science today, to such an extent that past scientists might say that we have, relative to their perspective, already automated the vast majority of science, with scientifically-related calculations, illustrations, simulations, manufacturing, etc. that are, by their standards, mostly done by computers and other machines. And this trend could well continue without being more explosive than the growth we have seen so far. In particular, the step from 90 percent to 99 percent automated science (or across any similar interval) could happen over years, at a familiar and fairly steady growth rate.
I think it’s worth being clear that the intuition that fully automated science is in some sense inevitable (assuming continued technological progress) does not imply that a growth explosion is inevitable, or even that such an explosion is more likely to happen than not.
On "transformative AI": I agree that this is quite vague and not as well-defined as it would ideally be, and is not the kind of thing I think we could just hand to superforecasters. But I think it is pointing at something important that I haven't seen a better way of pointing at.
I like the definition given in Bio Anchors (which you link to), which includes a footnote addressing the fact that AI could be transformative without literally causing GDP growth to behave as described. I'm sure there are imperfections remaining, and it remains vague, but I think most people can get a pretty good idea of what's being pointed at there, and I think it reasonably fleshes out the vaguer, simpler definition (which I think is also useful for giving a high-level impression).
In this series, I mostly stuck with the simple definition because I think the discussion of PASTA and digital people makes it fairly easy to see what kind of specific thing I'm pointing at, in a different way.
I am not aware of places where it's implied that "transformative AI" is a highly well-defined concept suitable for superforecasters (and I don't think the example you gave in fact implies this), but I'm happy to try to address them if you point them out.
On PASTA: my view is that there is a degree of automation that would in fact result in dramatically faster scientific progress than we've ever seen before. I don't think this is self-evident, or tightly proven by the series, but it is something I believe, and I think the series does a reasonable job pointing to the main intuitions behind why I believe it (in particular, the theoretical feedback loop this would create, the "modeling the human trajectory" projection of what we might expect if the "population bottleneck" were removed, and the enormous transformative potential of particular technologies that might result).
I'd disagree that most people can get a good idea of what's being pointed at; not least for the reasons I outlined in Section 1.2 above, regarding how advanced software could already reasonably be claimed to have "precipitate[d] a transition comparable to (or more significant than) the agricultural or industrial revolution". :)
So I'd also disagree that it "reasonably fleshes out the vaguer, simpler definition". Indeed, I don't think "Transformative AI" is a much clearer term than, say, "Advanced AI" or "Powerful AI", but it often seems used as though it's much clearer (see e.g. below).
My point wasn't about superforecasters in particular. Rather, my point was that the current definitions of TAI are so vague that it doesn't make much sense to talk about, say, "the year by which transformative AI will be developed". Again, it is highly unclear what would count and how one would resolve any forecast about it.
As for (super)forecasters, I wonder: if the concept/definition is not "suitable for superforecasters" — that is, for clearly resolvable forecasts — why is it suitable for attempts to forecast this "one number[i.e. the year by which transformative AI will be developed]"? If one doesn't think it allows for clearly resolvable forecasts, perhaps it would be good to note that from the outset, and when making estimates such as "more than a 10% chance of 'transformative AI' within 15 years".
sidenote: There has been an argument that 'radically transformative AI' is a better term for the Industrial Revolution definition, given the semantic bleaching already taking place with 'transformative AI'.