I think that the evidence you cite for "careening towards Venezuela" being a significant risk comes nowhere near to showing that, and that as someone with a lot of sway in the community you're being epistemically irresponsible in suggesting otherwise.
Of the links you cite as evidence:
The first is about the rate of advance slowing, which is not a collapse or regression scenario. At most it could contribute to such a scenario if we had reason to think one was otherwise likely.
The second is describing an all-ready existing phenomenon of cost disease which while concerning has been compatible with high rates of growth and progress over the past 200 years.
The third is just a blog post about how some definitions of "democratic" are theoretically totalitarian in principle, and contains 0 argument (even bad) that totalitarianism risk is high, or rising, or will become high.
The fourth is mostly just a piece that takes for granted that some powerful American liberals and some fraction of American liberals like to shut down dissenting opinion, and then discusses inconclusively how much this will continue and what can be done about it. But this seem obviously insufficient to cause the collapse of society, given that, as you admit, periods of liberalism where you could mostly say what you like without being cancelled have been the exception not the rule over the past 200 years, and yet growth and progress have occurred. Not to mention that they have also occurred in places like the Soviet Union, or China from the early 1980s onward, that have been pretty intolerant of ideological dissent.
The fifth is a highly abstract and inconclusive discussion of the possibility that having a bunch of governments that grow/shrink in power as their policies are successful/unsuccessful, might produce better policies than an (assumed) status quo where this doesn't happen*, combined with a discussion of the connection of this idea to an obscure far-right wing Bay Area movement of at most a few thousand people. It doesn't actually argue for the idea that dangerous popular ideas will eventually cause civilization regression at all; it's mostly about what would follow if popular ideas tended to be bad in some general sense, and you could get better ideas by having a "free market for governments" where only successful govs survived.
The last link on dysgenics and fertility collapse largely consist of you arguing that these are not as threatening as some people believe(!). In particular, you argue that world population will still be slightly growing by 2100 and it's just really hard to project current trends beyond then. And you argue that dysgenic trends are real but will only cause a very small reduction in average IQ, even absent a further Flynn effect (and "absent a further Flynn effect" strikes me as unlikely if we are talking about world IQ, and not US.) Nowhere does it argue these things will be bad enough to send progress into reverse.
This is an incredibly slender basis to be worrying about the idea that the general trend towards growth and progress of the last 200 years will reverse absent one particular transformative technology.
*It plausibly does happen to some degree. The US won the Cold War partly because it had better economic policies than the Soviet Union.
The second is describing an all-ready existing phenomenon of cost disease which while concerning has been compatible with high rates of growth and progress over the past 200 years.
I want to add further that cost disease is not only compatible with economic growth, cost disease itself is a result of economic growth, at least in the usual sense of the word. The Baumol effect -- which is what people usually mean when they say cost disease -- is simply a side effect of some industries becoming more productive more quickly than others. Essentially the only way to avoid cost disease is to have uniform growth across all industries, and that's basically never happened historically, except during times of total stagnation (in which growth is ~0% in every industry).
I think this is a good and useful post in many ways, in particular laying out a partial taxonomy of differing pause proposals and gesturing at their grounding and assumptions. What follows is a mildly heated response I had a few days ago, whose heatedness I don't necessarily endorse but whose content seems important to me.
Sadly this letter is full of thoughtless remarks about China and the US/West. Scott, you should know better. Words have power. I recently wrote an admonishment to CAIS for something similar.
The biggest disadvantage of pausing for a long time is that it gives bad actors (eg China) a chance to catch up.
There are literal misanthropic 'effective accelerationists' in San Francisco, some of whose stated purpose is to train/develop AI which can surpass and replace humanity. There's Facebook/Meta, whose leaders and executives have been publicly pooh-poohing discussion of AI-related risks as pseudoscience for years, and whose actual motto is 'move fast and break things'. There's OpenAI, which with great trumpeting announces its 'Superalignment' strategy without apparently pausing to think, 'But what if we can't align AGI in 5 years?'. We don't need to invoke bogeyman 'China' to make this sort of point. Note also that the CCP (along with EU and UK gov) has so far been more active in AI restraint and regulation than, say, the US government, or orgs like Facebook/Meta.
Suppose the West is right on the verge of creating dangerous AI, and China is two years away. It seems like the right length of pause is 1.9999 years, so that we get the benefit of maximum extra alignment research and social prep time, but the West still beats China.
Now, this was in the context of paraphrases of others' positions on a pause in AI development, so it's at least slightly mention-flavoured (as opposed to use). But as far as I can tell, the precise framing here has been introduced in Scott's retelling.
Whoever introduced this formulation, this is bonkers in at least two ways. First, who is 'the West' and who is 'China'? This hypothetical frames us as hivemind creatures in a two-player strategy game with a single lever. Reality is a lot more porous than that, in ways which matter (strategically and in terms of outcomes). I shouldn't have to point this out, so this is a little bewildering to read. Let me reiterate: governments are not currently pursuing advanced AI development, only companies. The companies are somewhat international, mainly headquartered in the US and UK but also to some extent China and EU, and the governments have thus far been unwitting passengers with respect to the outcomes. Of course, these things can change.
Second, actually think about the hypothetical where 'we'[1] are 'on the verge of creating dangerous AI'. For sufficient 'dangerous', the only winning option for humanity is to take the steps we can to prevent, or at least delay[2], that thing coming into being. This includes advocacy, diplomacy, 'aggressive diplomacy' and so on. I put forward that the right length of pause then is 'at least as long as it takes to make the thing not dangerous'. You don't win by capturing the dubious accolade of nominally belonging to the bloc which directly destroys everything! To be clear, I think Scott and I agree that 'dangerous AI' here is shorthand for, 'AI that could defeat/destroy/disempower all humans in something comparable to an extinction event'. We already have weak AI which is dangerous to lesser levels. Of course, if 'dangerous' is more qualified, then we can talk about the tradeoffs of risking destroying everything vs 'us' winning a supposed race with 'them'.
I'm increasingly running with the hypothesis that many anglophones are mind-killed on the inevitability of contemporary great power conflict in a way which I think wasn't the case even, say, 5 years ago. Maybe this is how thinking people felt in the run up to WWI, I don't know.
I wonder if a crux here is some kind of general factor of trustingness toward companies vs toward governments - I think extremising this factor would change the way I talk and think about such matters. I notice that a lot of American libertarians seem to have a warm glow around 'company/enterprise' that they don't have around 'government/regulation'.
[ In my post about this I outline some other possible cruxes and I'd love to hear takes on these ]
Separately, I've got increasingly close to the frontier of AI research and AI safety research, and the challenge of ensuring these systems are safe remains very daunting. I think some policy/people-minded discussions are missing this rather crucial observation. If you expect it to be easy (and expect others to expect that) to control AGI, I can see more why people would frame things around power struggles and racing. For this reason, I consider it worthwhile repeating: we don't know how to ensure these systems will be safe, and there are some good reasons to expect that they won't be by default.
I repeat that the post as a whole is doing a service and I'm excited to see more contributions to the conversation around pause and differential development and so on.
Who, me? You? No! Some development team at DeepMind or OpenAI, presumably, or one of the current small gaggle of other contenders, or a yet-to-be-founded lab. ↩︎
If it comes to it, extinction an hour later is better than an hour sooner. ↩︎
"eventually technology will advance to the point where you can train an AI on anything"
Assuming this means AGI, this is a very strong claim that doesn't get any justification. It may be theoretically true if "eventually" means "within 100 billion years", but it's not obvious to me that this will be true on more practical time scales (10-300 years).
There’s no easy way to enforce it once technology gets so good that you can train an AI on your laptop, and (absent much wider adoption of x-risk arguments) government’s won’t have the stomach for hard ways. [my emphasis]
I think that we can get that much wider adoption of x-risk arguments (indeed we are already seeing it), and a taboo on AGI / superhuman AI to go along with it, which will go a long way toward making enforcement of frontier model training run caps manageable.
Thanks for sharing, Scott! For reference, your post had already been linkposted, but it may be fine to have the whole post here as well. I think it makes sense to contact the author before linkposting.
(I suggested to Scott that he do this crosspost. I think it was nice of David to do the link post, but I like having the full text available on the forum, and under the original author's name.)
I think there’s a ~20% chance of AI destroying the world.
I'd like to see more fleshed out reasoning on where this number is coming from. Is it based on an aggregate of expert views from people you trust? Or is there an actual gears-level mechanism for why there is non-doom over ~80% of future worlds with AGI? (Also, 20% is more than enough to be shouting "fucking stop[!]"...)
But if we don’t get AI, I think there’s a 50%+ chance in the next 100 years we end up dead or careening towards Venezuela.
That doesn’t mean I have to support AI accelerationism because 20% is smaller than 50%. Short, carefully-tailored pauses could improve the chance of AI going well by a lot, without increasing the risk of social collapse too much.
Good that you don't support AI accelerationism, but I remain unconvinced by the reasoning for having carefully-tailored pauses. It seems far too risky to me.
I'm curating this post. This is a well-written summary of the AI Pause Debate, and I'm excited for our community to build on that conversation, through distillation and more back-and-forth.
Zach writes in an email: “Much/most of my concern about China isn't China has worse values than US or even Chinese labs are less safe than Western labs but rather it's better for leading labs to be friendly with each other (mostly to better coordinate and avoid racing near the end), so (a) it's better for there to be fewer leading labs and (b) given that there will be Western leading labs it's better for all leading labs to be in the West, and ideally in the US […]
I'm curious why Zach thinks that it would be ideal for leading AI labs to be in the US. I tried to consider this from the lens of regulation. I haven't read extensively on comparisons of what regulations there are for AI in various countries, but my impression is that the US federal government is sitting on their laurels with respect to regulation of AI, although state and municipal governments provide a somewhat different picture, and whilst the intentions of each are different, the EU and the UK have been moving much more swiftly than the US government.
My opinion would change if regulation doesn't play a large role in how successful an AI pause is, eg if industry players could voluntarily practice restraint. There are also other factors that I'm not considering.
Climate change is wrecking the planet, Putin is trying to start World War Three and the middle east is turning into a blood bath. Mean while some people hide from reality and worry about a perceived threat from the latest tools that humanity has invented.
Is their intelligent life on earth? I see little evidence to support that argument.
What is wrong with the reasoning here? Yes there's a lot of things wrong with the world, but the extinction (total - no survivors) we're actually likely to get is from AI, this decade, unless we do something to stop it.
Thanks for for reply. The only threat to humanity comes from humanity. AI, like any other tool such as atomic weapons or dynamite will be used for good or bad by humans. AI is powerful and because its a new technology, it's impact on the future debatable, but this has been the case ever since humans invented flint tools.
I say the fundamental problem is how to steer humanity away from improper use of technology, which can be achieved by first understanding human behaviors and motivations, then by the widespread dispersion of this knowledge and finally by exposing the futility of such behaviour in our globalised, interconnected and interdependent society.
If the end of humanity does happen, it will not be due to AI, pandemics or atomic weapons, it will because one group of humans, decided it wanted to get an advantage over another group of humans and ignored all other considerations. Understand why and we may be able to find a solution.
No. AGI is different. It will have it's own goals and agency. It's more akin to a new alien species than a "tool". What we are facing here is basically better thought of as a (digital) alien invasion, facilitated (or at the last accidentally unleashed) by the big AI companies. Less intelligent species don't typically fare well when faced with competing more intelligent species.
Thanks Greg, I'm sixty years old and grew up when every one said the world was going to be destroyed in a thermonuclear war, then it was acid rain, then it was nano technology (covering the world in a layer of scum!), then it was the millennium bug, currently its climate change and it looks like people are starting to worry about AI. Even the Prime minister is at it, perhaps as a cover for his failed short term policies. Humans are fundamentally neurotic - perhaps it gives us an evolutionary edge, always being on the lookout for new threats, but if you step back and take an overview of humanity, maybe you will see what the real problems are.
However, my point is, take care of today (with an eye on the mid term), the current problems and the future will look after itself. Who can predict the future with any degree of certainty anyway, so why worry? Its correct that long term thinking is needed to tackle climate change, but not problems like Palestine / Israel or Putin's and Xi Jinping's ideology that threatens Europe and Asia or Trumps attack on democracy, all of which are trying to drag us back to repeat past failures. Long term thinking should not be used to avoid tackling short term problems.
From what I've read of science, biology, neurology, psychology, politics, economics, history, philosophy we are on the verge of a breakthrough in new thought and maybe because AI can pull vast pools of knowledge together and perhaps eliminate our biases and prejudices, bring about great change for the better. This is not something to be afraid of, but something to embrace, but of course caution is needed and a simple fail safe button should be built in if we don't like the outputs.
Thanks for reading.
Regards and good luck with your endeavours. Never stop learning, but keep it real.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...
Last month, Ben West of the Center for Effective Altruism hosted a debate among long-termists, forecasters, and x-risk activists about pausing AI.
Everyone involved thought AI was dangerous and might even destroy the world, so you might expect a pause - maybe even a full stop - would be a no-brainer. It wasn’t. Participants couldn’t agree on basics of what they meant by “pause”, whether it was possible, or whether it would make things better or worse.
There was at least some agreement on what a successful pause would have to entail. Participating governments would ban “frontier AI models”, for example models using more training compute than GPT-4. Smaller models, or novel uses of new models would be fine, or else face an FDA-like regulatory agency. States would enforce the ban against domestic companies by monitoring high-performance microchips; they would enforce it against non-participating governments by banning export of such chips, plus the usual diplomatic levers for enforcing treaties (eg nuclear nonproliferation).
The main disagreements were:
Could such a pause possibly work?
If yes, would it be good or bad?
If good, when should we implement it? When should we lift it?
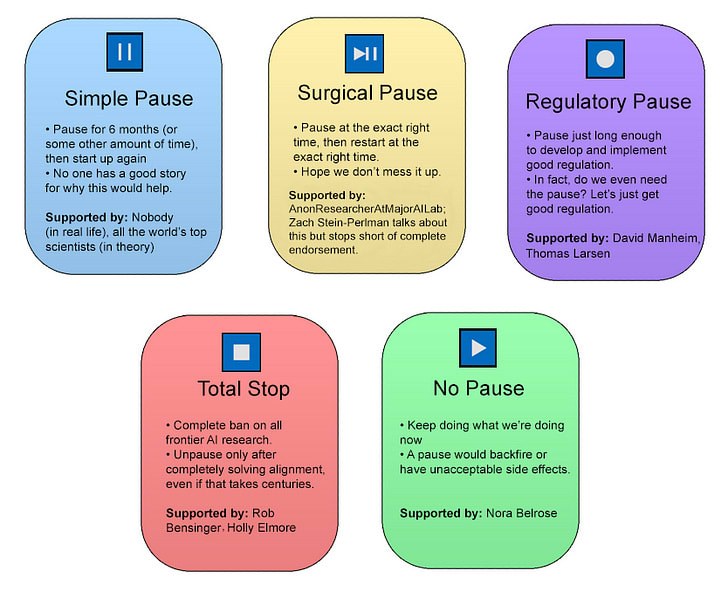
I’ve grouped opinions into five categories:
Simple Pause: What if we just asked AI companies to pause for six months? Or maybe some longer amount of time?
This was the request in the FLI Pause Giant AI Experiments open letter, signed by thousands of AI scientists, businesspeople, and thought leaders, including many participants in this debate. So you might think the debate organizers could find one person to argue for it. They couldn’t. The letter was such a watered-down compromise that nobody really supported it, even though everyone signed it to express support for one or another of the positions it compromised between.
Why don’t people want this? First, most people think it will take the AI companies more than six months of preliminary work before they start training their next big model anyway, so it’s useless. Second, even if we do it, six months from now the pause will end, and then we’re more or less where we are right now. Except worse, for two reasons:
COMPUTE OVERHANG. We expect AI technology to advance over time for two reasons. First, algorithmic progress - people learn how to make AIs in cleverer ways. Second, hardware progress - Moore’s Law produces faster, cheaper computers, so for a given budget, we can train/run the AI on more powerful hardware. A pause might slow algorithmic progress very slightly, with fewer big AIs to test new algorithms on. But it wouldn’t slow hardware progress at all. At the end of the pause, hardware would have progressed some amount, and instead of AIs progressing gradually over the next six months, they would progress in one giant jump when the pause ended, and all the companies rushed to build new AIs that took advantage of the past six months of progress. But gradual progress (which allows iteration and debugging in relatively simple AIs) seems safer than sudden progress (where all at once we have an AI much more powerful than anything we’ve ever seen before). Since a pause like this simply replaces gradual progress with sudden progress, it would be counterproductive.
BURNING TIMELINE IN A RACE. Suppose that we prefer America get strong AIs before China. If America pauses but China doesn’t, then after the pause we’d be exactly where we were before, except that China would have caught up relative to America. More generally, companies that care most about AI safety are most likely to obey the pause. So unless we’re very good at enforcing the pause even on non-cooperators, this just hurts the companies that care about safety the most, for no gain.
These are counterbalanced by one benefit:
MORE TIME FOR ALIGNMENT. Maybe we can use those six months to learn more about how to control AIs, or to prepare for them socially/politically.
This benefit is real, but this kind of pause doesn’t optimize it. Technical alignment research benefits from advanced models to experiment on; the Surgical Pause strategy takes this consideration more seriously. And social/political preparation depends on some kind of plan: this is what the Regulatory Pause strategy adds.
Surgical Pause: The Surgical Pause tweaks the Simple Pause to add two extra considerations:
WHEN TO PAUSE. If we’re going to pause for six months, which six months should it be? Right now? A few years from now? Just before dangerous AI is invented? The main benefit to a pause is to give alignment research time to catch up. But alignment research works better when researchers have more advanced AIs to experiment on. So probably we should have the six month pause right before dangerous AI is invented.
HOW LONG TO PAUSE. The biggest disadvantage of pausing for a long time is that it gives bad actors (eg China)[1] a chance to catch up. Suppose the West is right on the verge of creating dangerous AI, and China is two years away. It seems like the right length of pause is 1.9999 years, so that we get the benefit of maximum extra alignment research and social prep time, but the West still beats China.
Obviously the problem with the Surgical Pause is that we might not know when we’re on the verge of dangerous AI, and we might not know how much of a lead “the good guys” have. Surgical Pause proponents suggest being very conservative with both free variables. This is less of a well-thought-out plan and more saying “come on guys, let’s at least try to be strategic here”. At the limit, it suggests we probably shouldn’t pause for six months, starting right now.
Since this involves leading labs burning their lead time for safety, in theory it could be done unilaterally by the single leading lab, without international, governmental, or even inter-lab coordination. But you could buy more time if you got those things too. Some leading labs have promised to do this when the time is right - for example OpenAI and (a previous iteration of) DeepMind - with varying levels of believability.
Regulatory Pause: If one benefit of the Simple Pause is to use the time to prepare for AI socially and politically, maybe we should just pause until we’ve completed social and political preparations.
David Manheim suggests a monitoring agency like the FDA. It would “fast-track” small AIs and trivial re-applications of existing AIs, but carefully monitor new “frontier models” for signs of danger. Regulators might look for dangerous capabilities by asking AIs to hack computers or spread copies of themselves, or test whether they’ve been programmed against bias/misinformation/etc. We could pause only until we’ve set up the regulatory agency, and take hostile actions (like restrict chip exports) only to other countries that don’t cooperate with our regulators or set up domestic regulators of their own.
Many people in tech are regulation-skeptical libertarians, but proponents point out that regulation fails in a predictable direction: it usually does successfully prevent bad things, it just also prevents good things too. Since the creation of the Nuclear Regulatory Commission in 1975, there has never been a major nuclear accident in the US. And sure, this is because the NRC prevented any nuclear plants from being built in the United States at all from 1975 to 2023 (one was finally built in July). Still, they technically achieved their mandate. Likewise, most medications in the US are safe and relatively effective, at the cost of an FDA approval process being so expensive that we only get a tiny trickle of new medications each year and hundreds of thousands of people die from unnecessary delays. But medications are safe and effective. Or: San Francisco housing regulators almost never approve new housing, so housing costs millions of dollars and thousands of San Franciscans are homeless - but certainly there’s no epidemic of bad houses getting approved and then ruining someone’s view or something. If we extrapolate this track record to AI, AI regulators will be overcautious, progress will slow by orders of magnitude or stop completely - but AIs will be safe.
This is a depressing prospect if you think the problems from advanced AI would be limited to more spam or something. But if you worry about AI destroying the world, maybe you should accept a San-Francisco-housing-level of impediment and frustration.
A regulatory pause could be better than a total stop if you think it will be more stable (lots of industries stay heavily regulated forever, and only a few libertarians complain), or if you think maybe the regulator will occasionally let a tiny amount of safe AI progress happen.
But it could be worse than a total stop if you expect continued progress will eventually produce unsafe AIs regardless of regulation. You might expect this if you’re worried about deceptive alignment, eg superintelligent AIs that deliberately trick regulators into thinking they’re safe. Or you might think AIs will eventually be so powerful that they can endanger humanity from a walled-off test environment even before official approval. The classic Bostrom/Yudkowsky model of alignment implies both of these things.
Total Stop: If you expect AIs to exhibit deceptive alignment capable of fooling regulators, or to be so dangerous that even testing them on a regulator’s computer could be apocalyptic, maybe the only option is a total stop.
It’s tough to imagine a total stop that works for more than a few years. You have at least three problems:
NON-PARTICIPANTS. As with any pause proposal, unfriendly countries (eg China) can keep working on AI. You can refuse to export chips to them, which will slow them down a little, but their own chips will eventually be up to the task. You will either need a diplomatic miracle, or willingness to resort to less diplomatic forms of coercion. This doesn’t have to be immediate war: Israel has come up with “creative” ways to slow Iran’s nuclear program, and countries trying to frustrate China’s chip industry could do the same. But great powers playing these kinds of games against each other risks wider conflict.
ALGORITHMIC PROGRESS. Suppose the government banned anyone except heavily-regulated companies from having a computer bigger than a laptop. Right now you can’t train a good AI on a laptop, or even a cluster of laptops. But AI training methods get more efficient every year. If current research progress continues, then at some point - even if it’s decades from now - you will be able to train cutting-edge AIs on laptops.
HARDWARE PROGRESS. Also the laptops keep getting better, because of Moore’s Law.
Regulators can plausibly control the flow of supercomputers, at least domestically. But eventually technology will advance to the point where you can train an AI on anything. Then you either have to ban all computing, restrict it at gradually more extreme levels (1990 MS-DOS machines! No, punch cards!) or accept that AI is going to happen.
If we think alignment research is going well, and that a pause would mess it up, or cause a compute overhang leading to un-research-able fast takeoff, or cede the lead to China, maybe we should stick with the current rate of progress.
[A pause] would have several predictable negative effects:
Illegal AI labs develop inside pause countries, remotely using training hardware outsourced to non-pause countries to evade detection. Illegal labs would presumably put much less emphasis on safety than legal ones.
There is a brain drain of the least safety-conscious AI researchers to labs headquartered in non-pause countries. Because of remote work, they wouldn’t necessarily need to leave the comfort of their Western home.
Non-pause governments make opportunistic moves to encourage AI investment and R&D, in an attempt to leap ahead of pause countries while they have a chance. Again, these countries would be less safety-conscious than pause countries.
Safety research becomes subject to government approval to assess its potential capabilities externalities. This slows down progress in safety substantially, just as the FDA slows down medical research.
Legal labs exploit loopholes in the definition of a “frontier” model. Many projects are allowed on a technicality; e.g. they have fewer parameters than GPT-4, but use them more efficiently. This distorts the research landscape in hard-to-predict ways.
It becomes harder and harder to enforce the pause as time passes, since training hardware is increasingly cheap and miniaturized.
Whether, when, and how to lift the pause becomes a highly politicized culture war issue, almost totally divorced from the actual state of safety research. The public does not understand the key arguments on either side.
Relations between pause and non-pause countries are generally hostile. If domestic support for the pause is strong, there will be a temptation to wage war against non-pause countries before their research advances too far. “If intelligence says that a country outside the agreement is building a GPU cluster, be less scared of a shooting conflict between nations than of the moratorium being violated; be willing to destroy a rogue datacenter by airstrike.” — Eliezer Yudkowsky
There is intense conflict among pause countries about when the pause should be lifted, which may also lead to violent conflict.
AI progress in non-pause countries sets a deadline after which the pause must end, if it is to have its desired effect.[3] As non-pause countries start to catch up, political pressure mounts to lift the pause as soon as possible. This makes it hard to lift the pause gradually, increasing the risk of dangerous fast takeoff scenarios.
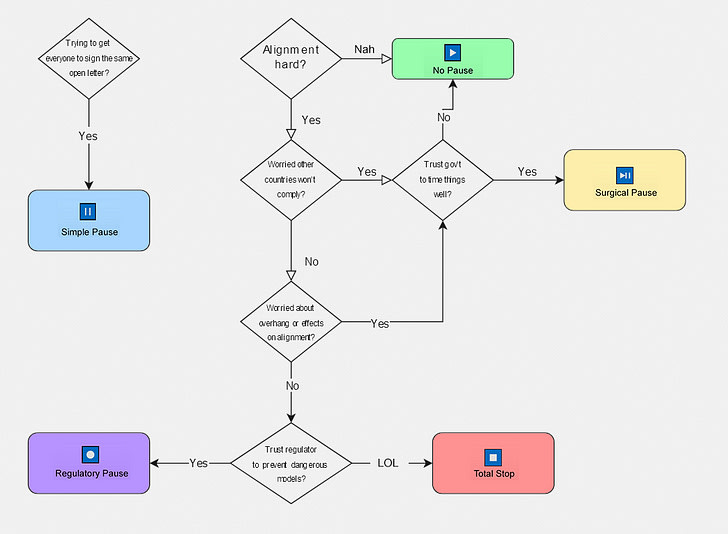
For every word like "trust" or "worried", assume I mean "...enough to outweigh other considerations"
Along with this overall arc, the debate included a few other points:
Holly Elmore argued in The Case For AI Advocacy To The Public that pro-pause activists should be more willing to take their case to the public. EA has a long history of trying to work with companies and regulators, and has been less confident in its ability to execute protests, ads, and campaigns. But in most Western countries, the public hates AI and wants to stop it. If you also want to stop it, the democratic system provides fertile soil. Holly is putting her money where her mouth is and leading anti-AI protests at the Meta office in San Francisco; the first one was last month, but there might be more later.
Source: AI Policy Institute and YouGov, h/t Holly
Matthew Barnett said in The Possibility Of An Indefinite AI Pause that it might be hard to control the length of a pause once started, and might drag on longer than people who expected a well-planned surgical pause might like. He points to supposedly temporary moratoria that later became permanent (eg aboveground nuclear test ban, various bans on genetic engineering) and regulatory agencies that became so strict they caused the subject of their regulation to essentially cease to happen (eg nuclear plant construction for several decades). Such an indefinite pause would either collapse in a disastrous actualization of compute overhang, or require increasingly draconian international pressure to sustain. He thinks of this as a strong argument against most forms of pause, although he is willing to consider a “licensing” system that looks sort of like regulation.
Quintin Pope said in AI Is Centralizing By Default, Let’s Not Make It Worse that the biggest threat from AI is centralizing power, either to dictators or corporations. AIs are potentially more loyal flunkies than humans, and let people convert power (including political power and money) into intelligence more efficiently than the usual methods. His interest is mostly in limiting the damage, putting him skew to most of the other people in this debate. He would support regulation that makes it easier for small labs to catch up to big ones, or that limits the power-centralizing uses of AI, but oppose regulation focused on centralizing AI power into a few big, supposedly-safer corporations.
Percent of population in each country saying AI has more benefits than drawbacks. Pope uses this table to suggest AI regulation would be decentralizing, since the furthest-ahead countries are the most eager to regulate. Source: Ipsos; h/t Quintin
II.
For a “debate”, this lacked much inter-participant engagement. Most people posted their manifesto and went home.
The exception was the comments section of Nora’s post, AI Pause Will Likely Backfire. As usual, a lot of the discussion was just clarifying what everyone was fighting about, but there were also a few real fights:
Gerald Monroe thought that the history of nuclear weapons suggested pauses like this were impossible (because many countries did build nuclear weapons). David Manheim thought it suggested pauses like this could work (because there were some successful arms limitation treaties, and less nuclear proliferation than would have happened without international cooperation). Manheim also brought up the successful bans on ozone-destroying CFCs and on human cloning.
Nora thought most treaties like this fail, and a successful one would have to involve some level of global tyranny. David Manheim thought most treaties sort of do some good, even if they don’t accomplish exactly what they wanted, and none of them so far have led to global tyranny. Cf. the Kellogg-Briand Pact for an example of a treaty that didn’t succeed perfectly but was probably net good.
Nora thought it was important to give alignment researchers advanced models to experiment with, because the sort of armchair alignment research before interesting AIs existed (eg Bostrom’s Superintelligence) wasn’t just wrong, but fostered dead-end worse-than-nothing paradigms that continue to confuse the field. Daniel Filan objected that Bostrom got some things right and even described something like the direction that modern alignment research is taking. There was a long argument about this, which I think reduces to “Bostrom said some useful theoretical things, speculated about practical direction, and a few of his speculations were right but most now seem outdated”.
Zach Stein-Perlman made some good points about the technical factors that made pauses better vs. worse, which I’ve tried to fold into the Surgical Pause section above.
Nora thought that success at making language models behave (eg refuse to say racist things even when asked) suggests alignment is going pretty well so far. Many other people (eg Rafael Harth, Steven Byrnes) suggested this would produce deceptive alignment, ie AI that says nice things to humans who have power over it, but secretly has different goals, and so success in this area says nothing about true alignment success and is even kind of worrying. The question remained unresolved.
My biggest surprise was how misleading the terms being used were, and think that many opponents were opposed to something different than what supporters were interested in suggesting. Even some supporters Second, I was very surprised to find opposition to the claim that AI might not be safe, and could pose serious future risks, largely because the systems would be aligned by default - i.e. without any enforced mechanisms for safety. I also found out that there was a non-trivial group that wants to roll back AI progress to before GPT-4 for safety reasons, as opposed to job displacement and copyright reasons. I was convinced by Gerald Monroe that getting a full moratorium was harder than I have previously argued based on an analogy to nuclear weapons. (I was not convinced that it “isn't going to happen without a series of extremely improbable events happening simultaneously” - largely because I think that countries will be motivated to preserve the status quo.) I am mostly convinced by Matthew Barnett’s claim that advanced AI could be delayed by a decade, if restrictions are put in place - I was less optimistic, or what he would claim is pessimistic. As explained above, I was very much not convinced that a policy which was agreed to be irrelevant would remain in place indefinitely. I also didn’t think that there’s any reason to expect a naive pause for a fixed period, but he convinced me that this is more plausible than I had previously thought - and I agree with him, and disagree with Rob Bensinger, about how bad this might be. Lastly, I have been convinced by Nora that the vast majority of the differences in positions is predictive, rather than about values. Those optimistic about alignment are against pausing, and in most cases, I think those pessimistic about alignment are open to evidence that specific systems are safe. This is greatly heartening, because I think that over time, we’ll continue to see evidence in one direction or another about what is likely, and if we can stay in a scout-mindset, we will (eventually) agree on the path forward.
III.
Some added thoughts of my own:
First, I think it’s silly to worry about world dictatorships here. The failure mode for global treaties is that the treaty doesn’t get signed or doesn’t work. Consider the various global warming treaties (eg Kyoto) or the United Nations. Even though many ordinary people (ie non-x-risk believers) dislike AI enough to agree to a ban, they’re not going to support it when it starts interfering with their laptops or gaming rigs, let alone if it requires ceding national sovereignty to the UN or something.
Second, if we never get AI, I expect the future to be short and grim. Most likely we kill ourselves with synthetic biology. If not, some combination of technological and economic stagnation, rising totalitarianism + illiberalism+ mobocracy, fertility collapse and dysgenics will impoverish the world and accelerate its decaying institutional quality. I don’t spend much time worrying about any of these, because I think they’ll take a few generations to reach crisis level, and I expect technology to flip the gameboard well before then. But if we ban all gameboard-flipping technologies (the only other one I know is genetic enhancement, which is even more bannable), then we do end up with bioweapon catastrophe or social collapse. I’ve said before I think there’s a ~20% chance of AI destroying the world. But if we don’t get AI, I think there’s a 50%+ chance in the next 100 years we end up dead or careening towards Venezuela. That doesn’t mean I have to support AI accelerationism because 20% is smaller than 50%. Short, carefully-tailored pauses could improve the chance of AI going well by a lot, without increasing the risk of social collapse too much. But it’s something on my mind.
Third, most participants agree that a pause would necessarily be temporary. There’s no easy way to enforce it once technology gets so good that you can train an AI on your laptop, and (absent much wider adoption of x-risk arguments) government’s won’t have the stomach for hard ways. The singularity prediction widget currently predicts 2040. If I make drastic changes to starve everybody of computational resources, the furthest I can push it back is 2070. This somewhat reassures me about my concerns above, but not completely. Matthew Barnett talks about whether a temporary pause could become permanent, and concludes probably not without a global police state. But I think people 100 years ago would be surprised that the state of California has managed to effectively ban building houses. I think if some anti-house radical had proposed this 100 years ago, people would have told her that would be impossible without a hypercompetent police state[4].
Fourth, there are many arguments that a pause would be impossible, but they mostly don’t argue against trying. We could start negotiating an international AI pause treaty, and only sign it if enough other countries agree that we don’t expect to be unilaterally-handicapping ourselves. So “China will never agree!” isn’t itself an argument against beginning diplomacy, unless you expect that just starting the negotiations would cause irresistible political momentum toward signing even if the end treaty was rigged against us.
Fifth, a lot hinges on whether alignment research would be easier with better models. I’ve only talked to a handful of alignment researchers about this, but they say they still have their hands full with GPT-4. I would like to see broader surveys about this (probably someone has done these, I just don’t know where).
I find myself willing to consider trying a Regulatory or Surgical Pause - a strong one if proponents can secure multilateral cooperation, otherwise a weaker one calculated not to put us behind hostile countries (this might not be as hard as it sounds; so far China has just copied US advances; it remains to be seen if they can do cutting-edge research). I don’t entirely trust the government to handle this correctly, but I’m willing to see what they come up with before rejecting it.
Thanks to Ben and everyone who participated. You can find all posts, including some unofficial late posts I didn’t cover, here.
Zach writes in an email: “Much/most of my concern about China isn't China has worse values than US or even Chinese labs are less safe than Western labs but rather it's better for leading labs to be friendly with each other (mostly to better coordinate and avoid racing near the end), so (a) it's better for there to be fewer leading labs and (b) given that there will be Western leading labs it's better for all leading labs to be in the West, and ideally in the US […] In addition to a pause causing e.g. China to catch up (with the above downsides), there's the risk that the US realizes that China is catching up and then ends the pause. (To some extent this is just a limitation of the pause, but it's actual-downside-risk-y if you were hoping that your 'pause' would last through AGI/whatever—with the final progress contributed by algorithmic progress or limited permitted compute scaling, so that labs never have an opportunity to exploit the compute overhang—but now your pause ends prematurely and the compute overhang is exploited.)”
Holly writes in an email: “I also think [you’re] taking the distinction between a mere pause and a regulatory pause too much from the opponents. The people who are out asking for a pause (like me and PauseAI) mostly want a long pause in which alignment research could either work, effective regulations could be put in place, or during which we don’t die if alignment isn’t going to be possible.I suppose I didn’t get into that in my entry but I would Iike to see [you] engage with the possibility that alignment doesn’t happen, especially since [you] seem to think civilization will decline for one reason or another without AI in the future. I think the assumption of [this] piece was too much AI development as the default. “
This does depend a bit on whether safety research in pause countries is openly shared or not, and on how likely non-pause actors are to use this research in their own models.
Matthew responds in an email: “I'd like to point out that the modern practice of restricting housing can be traced back to 1926 when the Supreme Court ruled that enforcing land-use regulation and zoning policy was a valid exercise of a state's police power. The idea that we could effectively ban housing would not have been inconceivable to people 100 years ago, and indeed many people (including the plaintiffs in the case) were worried about this type of outcome.I don't think people back then would have said that zoning would require a hypercompetent police state. It's more likely that they would say that zoning requires an intrusive expansion of government powers. I think they would have been correct in this assessment, and we got the expansion that they worried about.Unlike banning housing, banning AI requires that we can't have any exceptions. It's not enough to ban AI in the United States if AI can trained in Switzerland. This makes the proposal for an indefinite pause different from previous regulatory expansions, and in my opinion much more radical.To the extent you think that such crazy proposals simply aren't feasible, then you likely agree with me that we shouldn't push for an indefinite pause. That said, you also predicted that if current trends continued, "rising totalitarianism + illiberalism + mobocracy, fertility collapse and dysgenics will impoverish the world and accelerate its decaying institutional quality". This prediction doesn't seem significantly less crazy to me than the prediction that governments around the will attempt to ban AI globally (sloppily, and with severe negative consequences). I don't think it makes much sense to take one of these possibilities seriously and dismiss the other.”
My answer: I think there’s a difference between the regulatory framework for something existing vs. expecting it. It’s constitutional and legal for the US to raise the middle-class tax rate to 99%, but most people would still be surprised if it happened. I’m surprised how easy it is for governments to effectively ban things without even trying just by making them annoying. Could this create an AI pause that lasts decades? My Inside View answer is no; my Outside View answer has to be “maybe”. Maybe they could make hardware progress and algorithmic progress so slow that AI never quite reaches the laptop level before civilization loses its ability to do technological advance entirely? Even though this would be a surprising world, I have more probability on something like this than on a global police state. Possible exception if AI does something crazy (eg launches nukes) that makes all world governments over-react and shift towards the police state side, but at that point we’re not discussing policies in the main timeline anymore.



 For every word like "trust" or "worried", assume I mean "...enough to outweigh other considerations"
For every word like "trust" or "worried", assume I mean "...enough to outweigh other considerations"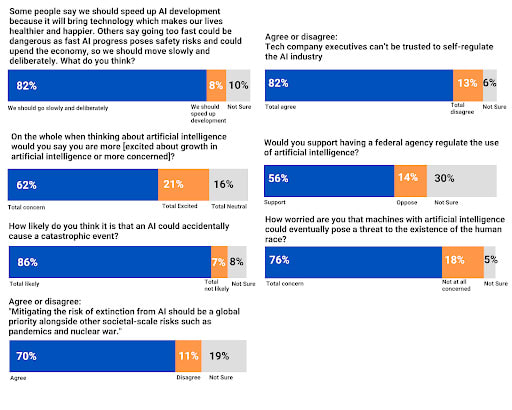 Source: AI Policy Institute and YouGov, h/t Holly
Source: AI Policy Institute and YouGov, h/t Holly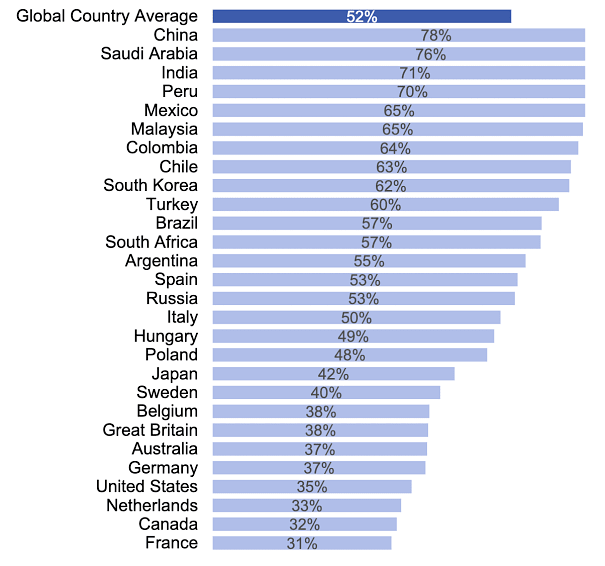
I think that the evidence you cite for "careening towards Venezuela" being a significant risk comes nowhere near to showing that, and that as someone with a lot of sway in the community you're being epistemically irresponsible in suggesting otherwise.
Of the links you cite as evidence:
The first is about the rate of advance slowing, which is not a collapse or regression scenario. At most it could contribute to such a scenario if we had reason to think one was otherwise likely.
The second is describing an all-ready existing phenomenon of cost disease which while concerning has been compatible with high rates of growth and progress over the past 200 years.
The third is just a blog post about how some definitions of "democratic" are theoretically totalitarian in principle, and contains 0 argument (even bad) that totalitarianism risk is high, or rising, or will become high.
The fourth is mostly just a piece that takes for granted that some powerful American liberals and some fraction of American liberals like to shut down dissenting opinion, and then discusses inconclusively how much this will continue and what can be done about it. But this seem obviously insufficient to cause the collapse of society, given that, as you admit, periods of liberalism where you could mostly say what you like without being cancelled have been the exception not the rule over the past 200 years, and yet growth and progress have occurred. Not to mention that they have also occurred in places like the Soviet Union, or China from the early 1980s onward, that have been pretty intolerant of ideological dissent.
The fifth is a highly abstract and inconclusive discussion of the possibility that having a bunch of governments that grow/shrink in power as their policies are successful/unsuccessful, might produce better policies than an (assumed) status quo where this doesn't happen*, combined with a discussion of the connection of this idea to an obscure far-right wing Bay Area movement of at most a few thousand people. It doesn't actually argue for the idea that dangerous popular ideas will eventually cause civilization regression at all; it's mostly about what would follow if popular ideas tended to be bad in some general sense, and you could get better ideas by having a "free market for governments" where only successful govs survived.
The last link on dysgenics and fertility collapse largely consist of you arguing that these are not as threatening as some people believe(!). In particular, you argue that world population will still be slightly growing by 2100 and it's just really hard to project current trends beyond then. And you argue that dysgenic trends are real but will only cause a very small reduction in average IQ, even absent a further Flynn effect (and "absent a further Flynn effect" strikes me as unlikely if we are talking about world IQ, and not US.) Nowhere does it argue these things will be bad enough to send progress into reverse.
This is an incredibly slender basis to be worrying about the idea that the general trend towards growth and progress of the last 200 years will reverse absent one particular transformative technology.
*It plausibly does happen to some degree. The US won the Cold War partly because it had better economic policies than the Soviet Union.
I want to add further that cost disease is not only compatible with economic growth, cost disease itself is a result of economic growth, at least in the usual sense of the word. The Baumol effect -- which is what people usually mean when they say cost disease -- is simply a side effect of some industries becoming more productive more quickly than others. Essentially the only way to avoid cost disease is to have uniform growth across all industries, and that's basically never happened historically, except during times of total stagnation (in which growth is ~0% in every industry).
Thanks for writing this up, I was skeptical about Scott‘s strong take but didn’t take the time to check the links he provided as proof.