elifland
Bio
You can give me anonymous feedback here. I often change my mind and don't necessarily endorse past writings.
Posts 20
Comments155
Topic contributions6
I'm still confused by why they picked 2027 even in 2025. Back when they made it, Daniel's median forecast was 2028 and Eli's 2031. Surely you then pick 2029 or 2030 for your scenario? Picking the "most likely year for it to happen" still feels a bit disingenous to me.
I'm not sure why picking the mode feels disingenuous to you, it feels fine to me as long as it's between roughly 15th and 85th percentiles and you are transparent about it.
The causual history of why it was 2027 is that this was Daniel's median when we started writing it, and it would have been a lot of work to rewrite our near-final draft to make it 2028 after Daniel changed his view. The reason it was based off of Daniel's view and not other authors' is that AI 2027 was ultimately supposed to represent his view rather than amalgam that include others' views. Giving a single person final say seems better than design by committee. That said, we had few strong disagreements.
The other authors considered 2027 plausible enough and close enough to a modal scenario that they (including me) felt happy to help with the project.
Edit: Daniel discusses his perspective here
Edit 2: It probably would have been reasonable for me to push for the timelines to be in between our views rather than Daniel's. I didn't really consider it because I thought 2027 was plausible enough and Daniel was leading the project. I think I also gave some weight to Linch's point about it being important to communicate that things could get crazy very soon, but I'm not sure if this was cruxy. However, memetic fitness wasn't an (explici)t consideration.
Is the 1-3% x-risk from bio including bio catastrophes mediated by AI (via misuse and/or misalignment? Is it taking into account ASI timelines?
Also, just comparing % x-risk seems to miss out on the value of shaping AI upside / better futures, s-risks + acausal stuff, etc. (also are you counting ai-enabled coups / concentration of power?). And relatedly the general heuristic of working on the thing that will be the dominant determinant of the future once developed (and which might be developed soon).
There are virtually always domain experts who have spent their careers thinking about any given question, and yet superforecasters seem to systematically outperform them.
I don't think this has been established. See here
I would advise looking into plans that are robust to extreme uncertainty in how AI actually goes, and avoid actions that could blow up in your face if you turn out to be badly wrong.
Seeing you highlight this now it occurs to me that I basically agree with this w.r.t. AI timelines (at least on one plausible interpretation, my guess is that titotal could have a different meaning in mind). I mostly don't think people should take actions that blow up in their face if timelines are long (there are some exceptions, but overall I think long timelines are plausible and actions should be taken with that in mind).
A key thing that titotal doesn't mention is how much probability mass they put on short timelines like, say, AGI by 2030. This seems very important for weighing various actions, even though we both agree that we should also be prepared for longer timelines.
In general, I feel like executing plans that are robust to extreme uncertainty is a prescription that is hard to follow without having at least a vague idea of the distribution of likelihood of various possibilities.
(edit: here is a more comprehensive response)
Thanks titotal for taking the time to dig deep into our model and write up your thoughts, it's much appreciated. This comment speaks for Daniel Kokotajlo and me, not necessarily any of the other authors on the timelines forecast or AI 2027. It addresses most but not all of titotal’s post.
Overall view: titotal pointed out a few mistakes and communication issues which we will mostly fix. We are therefore going to give titotal a $500 bounty to represent our appreciation. However, we continue to disagree on the core points regarding whether the model’s takeaways are valid and whether it was reasonable to publish a model with this level of polish. We think titotal’s critiques aren’t strong enough to overturn the core conclusion that superhuman coders by 2027 are a serious possibility, nor to significantly move our overall median (edit: I now think it's plausible that changes made as a result of titotal's critique will move our median significantly). Moreover, we continue to think that AI 2027’s timelines forecast is (unfortunately) the world’s state-of-the-art, and challenge others to do better. If instead of surpassing us, people simply want to offer us critiques, that’s helpful too; we hope to surpass ourselves every year in part by incorporating and responding to such critiques.
Clarification regarding the updated model
My apologies about quietly updating the timelines forecast with an update without announcing it; we are aiming to announce it soon. I’m glad that titotal was able to see it.
A few clarifications:
- titotal says “it predicts years longer timescales than the AI2027 short story anyway.” While the medians are indeed 2029 and 2030, the models still give ~25-40% to superhuman coders by the end of 2027.
- Other team members (e.g. Daniel K) haven’t reviewed the updated model in depth, and have not integrated it into their overall views. Daniel is planning to do this soon, and will publish a blog post about it when he does.
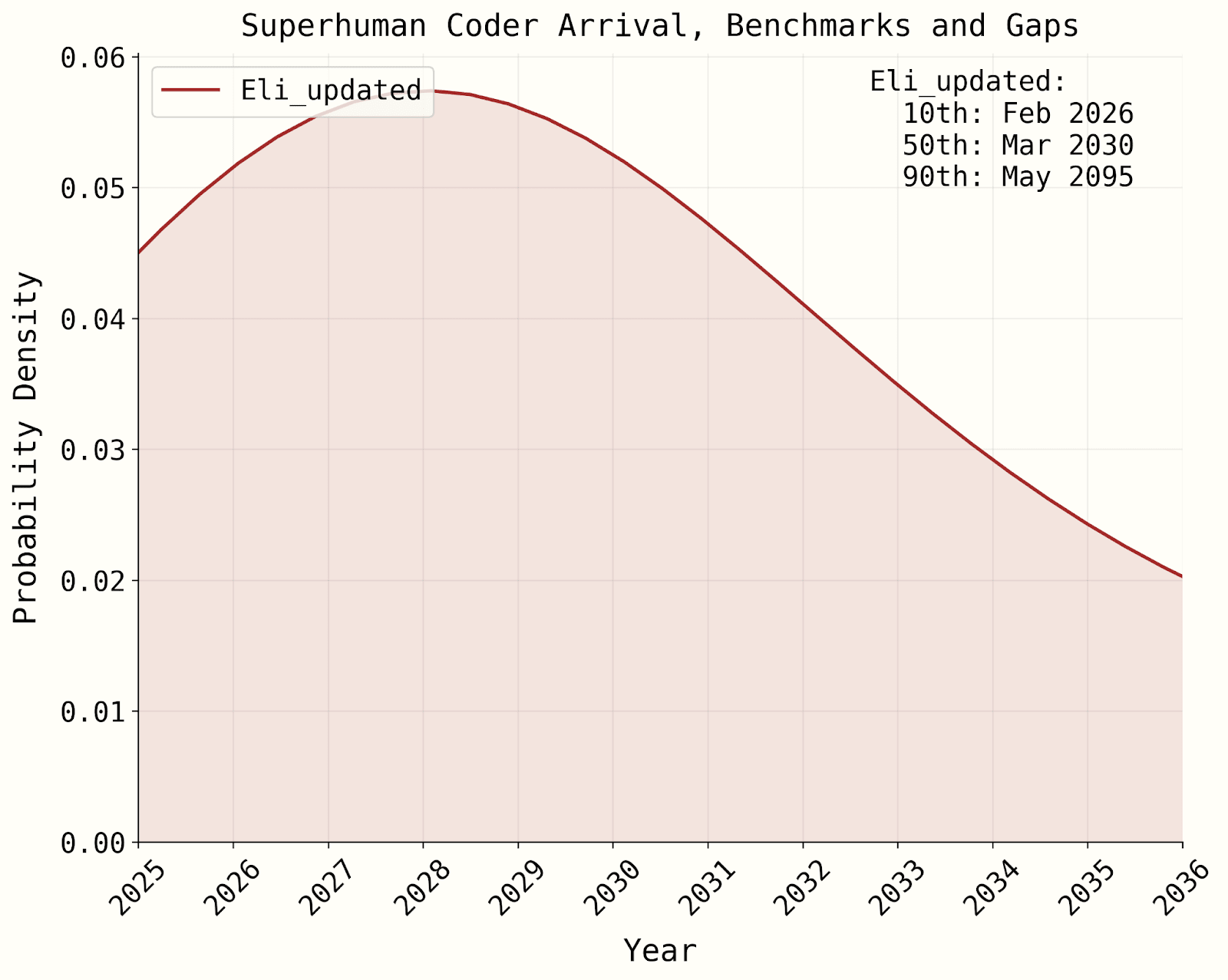
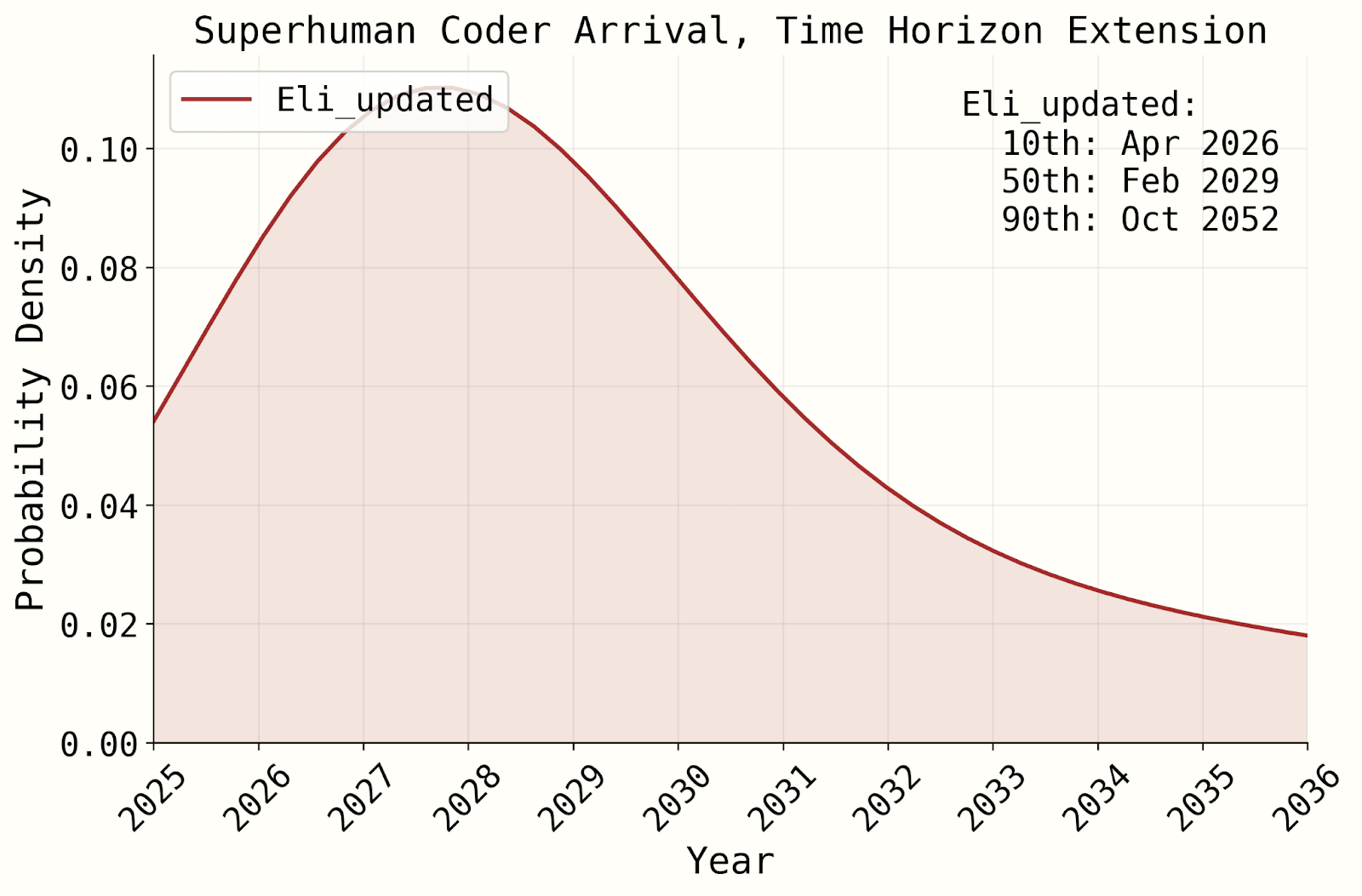
Most important disagreements
I'll let titotal correct us if we misrepresent them on any of this.
- Whether to estimate and model dynamics for which we don't have empirical data. e.g. titotal says there is "very little empirical validation of the model," and especially criticizes the modeling of superexponentiality as having no empirical backing. We agree that it would be great to have more empirical validation of more of the model components, but unfortunately that's not feasible at the moment while incorporating all of the highly relevant factors.[1]
- Whether to adjust our estimates based on factors outside the data. For example, titotal criticizes us for making judgmental forecasts for the date of RE-Bench saturation, rather than plugging in the logistic fit. I’m strongly in favor of allowing intuitive adjustments on top of quantitative modeling when estimating parameters.
- [Unsure about level of disagreement] The value of a "least bad" timelines model. While the model is certainly imperfect due to limited time and the inherent difficulties around forecasting AGI timelines, we still think overall it’s the “least bad” timelines model out there and it’s the model that features most prominently in my overall timelines views. I think titotal disagrees, though I’m not sure which one they consider least bad (perhaps METR’s simpler one in their time horizon paper?). But even if titotal agreed that ours was “least bad,” my sense is that they might still be much more negative on it than us. Some reasons I’m excited about publishing a least bad model:
- Reasoning transparency. We wanted to justify the timelines in AI 2027, given limited time. We think it’s valuable to be transparent about where our estimates come from even if the modeling is flawed in significant ways. Additionally, it allows others like titotal to critique it.
- Advancing the state of the art. Even if a model is flawed, it seems best to publish to inform others’ opinions and to allow others to build on top of it.
- The likelihood of time horizon growth being superexponential, before accounting for AI R&D automation. See this section for our arguments in favor of superexponentiallity being plausible, and titotal’s responses (I put it at 45% in our original model). This comment thread has further discussion. If you are very confident in no inherent superexponentiality, superhuman coders by end of 2027 become significantly less likely, though are still >10% if you agree with the rest of our modeling choices (see here for a side-by-side graph generated from my latest model).
- How strongly superexponential the progress would be. This section argues that our choice of superexponential function is arbitrary. While we agree that the choice is fairly arbitrary and ideally we would have uncertainty over the best function, my intuition is that titotal’s proposed alternative curve feels less plausible than the one we use in the report, conditional on some level of superexponentiality.
- Whether the argument for superexponentiality is stronger at higher time horizons. titotal is confused about why there would sometimes be a delayed superexponential rather than starting at the simulation starting point. The reasoning here is that the conceptual argument for superexponentiality is much stronger at higher time horizons (e.g. going from 100 to 1,000 years feels likely much easier than going from 1 to 10 days, while it’s less clear for 1 to 10 weeks vs. 1 to 10 days). It’s unclear that the delayed superexponential is the exact right way to model that, but it’s what I came up with for now.
Other disagreements
- Intermediate speedups: Unfortunately we haven’t had the chance to dig deeply into this section of titotal’s critique, and it’s mostly based on the original version of the model rather than the updated one so we probably will not get to this. The speedup from including AI R&D automation seems pretty reasonable intuitively at the moment (you can see a side-by-side here).
- RE-Bench logistic fit (section): We think it’s reasonable to set the ceiling of the logistic at wherever we think the maximum achievable performance would be. We don’t think it makes any sense to give weight to a fit that achieves a maximum of 0.5 when we know reference solutions achieve 1.0 and we also have reason to believe it’s possible to get substantially higher. We agree that we are making a guess (or with more positive connotation, “estimate”) about the maximum score, but it seems better than the alternative of doing no fit.
Mistakes that titotal pointed out
- We agree that the graph we’ve tweeted is not closely representative of the typical trajectory of our timelines model conditional on superhuman coders in March 2027. Sorry about that, we should have prioritized making it more precisely faithful to the model. We will fix this in future communications.
- They convinced us to remove the public vs. internal argument as a consideration in favor of superexponentiality (section).
- We like the analysis done regarding the inconsistency of the RE-Bench saturation forecasts with an interpolation of the time horizons progression. We agree that it’s plausible that we should just not have RE-Bench in the benchmarks and gaps model; this is partially an artifact of a version of the model that existed before the METR time horizons paper.
In accordance with our bounties program, we will award $500 to titotal for pointing these out.
Communication issues
There were several issues with communication that titotal pointed out which we agree should be clarified, and we will do so. These issues arose from lack of polish rather than malice. 2 of the most important ones:
- The “exponential” time horizon case still has superexponential growth once you account for automation of AI R&D.
- The forecasts for RE-Bench saturation were adjusted based on other factors on top of the logistic fit.
- ^
Relatedly, titotal thinks that we made our model too complicated, while I think it's important to make our best guess for how each relevant factor affects our forecast.
Centre for the Governance of AI does alignment research and policy research. It appears to focus primarily on the former, which, as I've discussed, I'm not as optimistic about. (And I don't like policy research as much as policy advocacy.)
I'm confused, the claim here is that GovAI does more technical alignment than policy research?
Want to discuss bot-building with other competitors? We’ve set up a Discord channel just for this series. Join it here.
I get "Invite Invalid"
Related comment I made 2 years ago and ensuing discussion: https://forum.effectivealtruism.org/posts/ziSEnEg4j8nFvhcni/new-open-philanthropy-grantmaking-program-forecasting?commentId=7cDWRrv57kivL5sCQ