Comments
Crossposted on LessWrong and the AI alignment forum
You can read this post as a google docs instead (IMO much better to read).
This document aims to clarify the AI safety research agenda by Paul Christiano (IDA) and the arguments around how promising it is.
Target audience: All levels of technical expertise. The less knowledge about IDA someone has, the more I expect them to benefit from the writeup.
Writing policy: I aim to be as clear and concrete as possible and wrong rather than vague to identify disagreements and where I am mistaken. Things will err on the side of being too confidently expressed. Almost all footnotes are content and not references.
Epistemic Status: The document is my best guess on IDA and might be wrong in important ways. I have not verified all of the content with somebody working on IDA. I spent ~4 weeks on this and have no prior background in ML, CS or AI safety.
I wrote this document last summer (2019) as part of my summer research fellowship at FHI. I was planning to restructure, complete and correct it since but haven’t gotten to it for a year, so decided to just publish it as it is. The document has not been updated, i.e. nothing that has been released since September 2019 is incorporated into this document. Paul Christiano generously reviewed part of this summary. I added his comments verbatim in the document. Apologies for the loss of readability due to this. This doesn’t imply he endorses any part of this document.
Purpose of this document: Clarifying IDA
IDA is Paul Christiano’s AI safety research agenda.[1] Christiano works at OpenAI which is one of the main actors in AI safety and IDA is by many considered the most complete[2] AI safety agenda.
However, people who are not directly working on IDA are often confused about how exactly to understand the agenda. Clarifying IDA would make it more accessible for technical people to work on and easier to assess for nontechnical people who want to think about its implications.
I believe that there are currently no resources on IDA that are both easy to understand and give a complete picture. Specifically, the current main resources are:
- the “Iterated Amplification” sequence which is a series of curated posts by Paul Christiano that can be quite difficult to understand,
- this post by Ajeya Cotra and this video by Robert Miles which are both easy to understand but limited in scope and don’t provide many details,
- Alex Zhu’s FAQ to IDA which clarifies important points but does not set them in context with the entire research agenda,
- an 80,000 podcast with Paul Christiano which explains some intuitions behind IDA but is not comprehensive and is in speech form.
This document aims to fill the gap and give a comprehensive and accessible overview of IDA.
Summary: IDA in 7 sentences
- IDA stands for Iterated Amplification and is a research agenda by Paul Christiano from OpenAI.
- IDA addresses the artificial intelligence (AI) safety problem, specifically the danger of creating a very powerful AI which leads to catastrophic outcomes.
- IDA tries to prevent catastrophic outcomes by searching for a competitive AI that never intentionally optimises for something harmful to us and that we can still correct once it’s running.
- IDA doesn’t propose a specific implementation, but presents a rough AI design and a collection of thoughts on whether this design has the potential to create safe and powerful AI and how the details of that design could look like.
- The proposed AI design is to use a safe but slow way of scaling up an AI’s capabilities, distill this into a faster but slightly weaker AI, which can be scaled up safely again, and to iterate the process until we have a fast and powerful AI.
- The most promising idea on how to slowly and safely scale up an AI is to give a weak and safe AI access to other weak and safe AIs which they can ask questions to enable it to solve more difficult tasks than it could alone.
- It is uncertain whether IDA will work out at all (or in the worst case lead to unsafe AI itself), lead to useful tool AIs for humans to create safer AI in the future or develop into the blueprint for a single safe and transformative AI system.
What problem is IDA trying to solve?
The AI safety problem
IDA addresses one aspect of the Artificial Intelligence (AI) safety problem: Current AI systems make a lot of mistakes that are poorly understood. Currently, this is not a big problem since contemporary AI systems are very limited. They don’t make very influential decisions and the tasks they are solving are relatively well understood: it would be relatively easy for a human to oversee whether an AI system is doing a task correctly.
Comment Christiano: IDA is targeted more narrowly at (intent) alignment---building a competitive AI which is trying to do what we want it to do, and is never trying to do something catastrophic. So it might be worth briefly mentioning that this is just one aspect of the safety problem and that even an aligned AI could contribute to catastrophic outcomes (though this is the aspect which futurists and EAs most often talk about).
However, in the coming decades we might want to limit the amount of human oversight and give AIs more autonomy over more important tasks that humans understand less well. At this point, unreliable AI systems that make a lot of mistakes might be catastrophic. One particular worry is that we might create an AI that optimizes for a task in a way that is unexpected and harmful to us and that we cannot control.
IDA is trying to find an AI design that ensures that an AI following this design doesn’t optimize for something harmful to us, doesn’t make catastrophic mistakes and doesn’t optimize in a way that takes control from us.
Comment Christiano: IDA isn't really intended to avoid catastrophic mistakes---just to avoid intentional catastrophic actions.
This post assumes familiarity with the AI safety problem. If readers never heard AI safety, AI risk, AGI, superintelligence, human level AI and AI alignment, I recommend reading, watching or listening to these resources (and possibly more) before reading this post.
Other readers might still want to read Christiano’s description of specific AI risks he has in mind.
Worldview behind IDA: We need to work on safe competitive and prosaic AI
IDA tries to create a safe and powerful version of a class of AI training methods that we already use, so-called self-play methods.[3] This approach is based on Christiano’s belief that safe, powerful AI systems must be competitive and could potentially be prosaic.
Comment Christiano: I wouldn't say that this is particularly related to self-play. I'm interested in competing with all of RL, and in being competitive with deep learning more broadly (I think it's plausible that e.g. deep imitation learning will be the way things go). Maybe "A safe and powerful version of deep learning, including deep reinforcement learning (RL)."
A prosaic AI is an AI we can build without learning anything substantially new about intelligence. If powerful prosaic AI was impossible - that is, if substantial new insights into intelligence were necessary to create powerful AI - we would likely need entirely different AI techniques to create powerful AI. If we believe that powerful prosaic AI is possible, this makes paying attention to current AI techniques relatively more important.
Christiano also believes that any safe AI must be competitive. This means, that they can solve a given task approximately as well and efficient as any unsafe alternative AI that we could build. Otherwise, competitive pressures could incentivize the development and use of these unsafe AI systems.[4]
This motivates his belief that **ideally, for every potentially unsafe AI technique that is currently used[5] and will be developed in the future, we would have a competitive safe version.
IDA builds on mainstream AI research to be competitive
Mainstream AI researchers recently made progress on a class of algorithms (self-play methods) that essentially consist of what Christiano calls an iteration of distillation and amplification. Christiano’s research agenda Iterated Amplification (IDA) attempts to develop a version of this method that is safe even when scaled up, i.e. even when the AI system trained by this method is extremely powerful.
Comment Christiano: I think expert iteration is orthogonal to self-play. For example, I think Mu Zero also uses this framework on single-player games. It just happened to be that AGZ and the early expert iteration paper were on board games.
The agenda’s contributions are to:
- argue why iterating distillation and amplification can potentially be very powerful,
(comment Christiano: I wouldn't say I added much here, I think that people already had this covered.) - explore how powerful it can get,
(comment Christiano: This should probably go after safety. If you use expert iteration to optimize a reward function then it won't be limited in this way, but it will be safe. Maybe A. describe a potentially safe way to apply IDA, B.) - argue that this application of IDA may be able to get very powerful, ...
- argue that this method can potentially be used safely,
- discuss which conditions must be fulfilled for this to be the case, and
- attempt to come up with concrete safe ways to implement it.
The term iterated distillation and amplification can be confusing since it refers both to a **specific AI safety research agenda[6] and to a general method of training AI. When I refer to the safety agenda, I will say IDA. When I just use the words iterating, distillating or amplifying, I will refer to the general training method.
What’s the ideal outcome of IDA?
What kind of AI do we want to create via IDA?
IDA is fully successful if it leads to an implementation for safe powerful AI, but IDA could also be partially successful by helping us to develop useful tools to build safe powerful AI.
Full success: IDA finds an implementation for safe powerful AI
Ideally, we figure out how to do safe distillation and safe amplification and develop one single AI system which autonomously does the distillation and amplification steps, thereby self-improves, and keeps going until it becomes the strongest possible (or the strongest we will ever attain) AI.[7]
Comment Christiano: This seems too strong. A small tweak might be to say something like: "Until it becomes the best AI that can be trained using available data, computation, and prosaic AI methods" or something. The point is that it's as good as anything you could make via a direct application of ML.
The process of iteration can take as long as years, decades or even millennia to complete but also be as short as days, minutes or seconds. In either case, our AI system hopefully improves fast enough to always be reasonably competitive to unsafe alternatives. If during or after the self-improvement process somebody develops and implements a more efficient AI training method, our efforts until then might have been in vain (apart from any generalizable insights generated from our work on IDA.)
(Comment Christiano: Iteration should occur in parallel with ML training, so it takes exactly as long as ML training---no more, no less.)
I presented one prototype ideal outcome from IDA, but there are at least two more: Instead of figuring out all of IDA and then applying it, we could 1) apply IDA over and over again with stronger and stronger distillation and amplification algorithms until we find something that works or 2) we apply IDA to create a lot of domain specific narrow AIs. In reality, probably some mix of these will happen or something entirely different. However, I think the main considerations for each case don’t change too much.
Comment Christiano: My hope would be that IDA is used every time someone wants to train a system with deep learning. My expectation would be that we will train many distinct systems with narrower competencies, because that seems like a better use of model capacity. But mostly the success is orthogonal to this: we've succeeded if we produce models that are competitive with the best AI people are making anywhere, and the aligned AIs we train will look basically the same as the unaligned AIs that we would have trained anyway. IDA is orthogonal to this kind of question about how AI ends up looking.
Partial success: IDA finds a tool that improves our reasoning
There is also the possibility of partial success: We might fail to develop a universally competent AI with IDA and instead develop an AI that is very capable at a subset of tasks that is important to AI safety. Example: We could create an AI system that is unable to physically manipulate things but really good (or at least better than us) at theorem proving. In that case, we developed a tool to improve human reasoning which could help to come up with a different design for safe powerful AI or solve other important problems.[8] Of course, there are also dangers from this kind of reasoning improvement which I will discuss more generally as differential competence in the section “How IDA could fail”.
Comment Christiano: I would personally describe this as: The aligned AIs we train may not be competitive---they may not fully utilize the techniques, data, and compute that is available---but they may still be good enough to help humans in important ways.
What kind of safety is IDA aiming for?
_Disclaimer: Please note that this might not be how the terms safety, alignment and corrigibility are used outside of the context of IDA.[9]
IDA is aiming for intent alignment
One important thing to note is what Christiano means by hopefully achieving “safe” AI via IDA. Christiano’s current work on the agenda is focussed on creating an AI that is intent aligned towards its current user and reasonably competent at inferring our preferences and acting on them.
An intent aligned agent is an agent that is trying to do what we want it to do. This definition is about the agent’s intentions rather than the outcomes and refers to “what we want it to do” de dicto rather than de re:
Example: Imagine our AI was tasked to paint our wall and we wanted the AI to paint it blue. The intent aligned AI’s goal in this example should be “paint the wall in the color the user wants” rather than “paint the wall blue”.[10] “Paint the wall blue” should only be an instrumental subgoal. An AI is intent aligned as long as its ultimate goal is the first, even if it is not competent enough to figure out the color we prefer (blue) or is not competent enough to actually paint a wall. Thereby, an intent aligned AI is different from the following types of aligned AI:
- an AI that is trying to do what we want it to do de re (in the example that would be an AI that is trying to paint the wall blue),
- an AI that is actually doing what we want it to do (actually painting the wall blue),
- an AI that is trying to do the morally right thing (if that differs from the user’s preferences),
- an AI that is actually doing the morally right thing.
None of the five ways an AI could be ‘aligned’ imply any of the other.
Intent aligned AIs need to be reasonably competent to be safe
An intent aligned AI that is not sufficiently competent at inferring and working towards our preferences might still make catastrophic mistakes. If successful, IDA would thereby have to both solve intent alignment and the problem of creating a reasonably competent AI system. This AI might still make minor mistakes[11] but no catastrophic mistakes.
Comment Christiano: Note that this safety condition depends not only on the AI but on how we use it---once we have a well-intentioned AI, we can either make it more competent or we can avoid deploying it in ways where its failures would be catastrophic (just as you would for a well-intentioned human assistant).
Example: An AI that is reasonably competent might still make mistakes in the realm of “choosing a blue that’s a bit different from what we would have preferred” or “painting somewhat unevenly”. It would hopefully not make mistakes in the realm of “completely fails to paint and knocks down the house instead” or “perfectly paints the wall but in the process also plants a bomb”.
Why corrigibility is the preferred form of intent alignment
IDA hopes to solve intent alignment and partly addresses the competence problem via corrigibility. Christiano’s intuition (April 2018) is that corrigibility implies intent alignment but that an intent aligned AI is not necessarily corrigible:
Suppose that I give an indirect definition of "my long-term values" and then build an AI that effectively optimizes those values. Such an AI would likely disempower me in the short term, in order to expand faster, improve my safety, and so on. It would be "aligned" but not "corrigible."
Comment Christiano [on corrigibility implying intent alignment]: I don't really think this is true (though I may well have said it). Also this implication isn't that important in either direction, so it's probably fine to cut? The important things are: (i) if I want my agent to be corrigible than an intent-aligned agent will try to be corrigible, (ii) if being corrigible is easy then it is likely to succeed, (iii) corrigibility seems sufficient for a good outcome.
A corrigible agent is one that always leaves us in power in some way even if disempowering us was instrumental to achieving our long-term goals. In that sense, an optimal corrigible AI is worse than an optimal intent aligned AI that is not corrigible: The latter has the freedom to disempower us if that’s what’s best for us in the long-run. However, it also seems that it would be extremely hard to judge whether a non-corrigible AI is actually intent aligned or to fix catastrophic bugs it has. Corrigibility is still a fuzzy concept and does not have a clear, formal definition.[12]
How to achieve corrigibility
IDA tries to achieve corrigibility by designing approval-directed AI: It only takes actions that it imagines the user would approve of (including actions the AI could hide) and is act-based. An act-based AI is one that considers the user’s short-term preferences.
Comment Christiano [on approval-directed AI]: Maximizing the overseer's approval is my preferred approach to distillation [...] It takes actions that the overseer would approve of, but the overseer is going to be a (human + AI team)---an unaided human won't be able to understand what the AI is doing at all.
Details: “Short-term preferences” does not mean “preferences over what can be achieved in the short-term” but “things that I would still endorse in the short-term”: An AI system that is optimizing for short-term preferences could still do long-term planning and act accordingly, but it does so because that’s what the human wants it to do at that moment. If we changed our mind, the AI would also change action. It would not take actions that we oppose even if 10 years later we would think it would have been good in hindsight. The logic here is that the user always knows better than the AI.
The idea with approval-directed agents is that 1) since the AI system values the user’s true approval, they would have an incentive to clarify their preferences. This makes value of information (VOI) and updating on this information central to the AI. 2) It is hopefully relatively easy for an AI system to infer that in the short term, the user would probably not approve of actions that disempower the user. This only works if the user doesn’t want to be disempowered in the moment.
Comment Christiano: [on 1] This isn't quite how I think about it (probably fine to cut?)
[on 2] This is the key thing. The other important claim is that if you want to be weaker than the overseer, then approval-direction doesn't limit your capabilities because you can defer to the overseer's long-term evaluations. So maximizing approval may be acceptable as part of IDA even if it would be too limiting if done on its own.
Corrigibility and intent alignment might be easier than other forms of alignment
IDA is aiming for corrigibility because of a number of claims. They are all not required to make corrigibility work but inform why IDA thinks corrigibility is more promising than other forms of alignment:
- Corrigibility alleviates the problem that the agent has to be competent at inferring the user’s preferences: the AI hopefully does not need to be terribly good at understanding humans to understand that they probably would not approve of being killed, lied to or ignored.
- Corrigibility is stable: This means an agent that is partly corrigible will become more corrigible over time as we scale it up.
- Corrigibility has a broad basin of attraction: While perfectly inferring all human preferences is probably a very narrow target, it is hopefully **relatively easy[13] to learn corrigibility sufficiently well to gravitate towards a center of corrigibility and not do anything catastrophic along the way.
In principle, you can also imagine an AI system trained by iterating distillation and amplification which is aligned but not corrigible. However, IDA centers around the idea of corrigibility and Paul Christiano is quite pessimistic that it would work if corrigibility turned out to be impossible or extremely difficult.
In conclusion, If IDA is successful, we can create a powerful AI system that is corrigible towards its current user and reasonably competent at figuring out what the user would approve of in the short term. This does not guarantee that the AI system will not make any mistakes in inferring the user’s preferences and trying to satisfy them, nor does this guarantee that the AI will do good things since the user might be malign.
How does iterating distillation and amplification work?
A general scheme to train AI systems
Basic definition of iterated distillation and amplification
Amplification is scaling up a system’s capabilities and distillation is learning from the amplified system. (Comment Christiano: I don't mean to define a thing so general as to be applicable beyond ML.)
Iterated distillation and amplification starts with a system that has some ability of level X. Some amplification process increases that system’s ability level to X+a, possibly at the expense of greater compute. Another system learns the amplified system’s ability through a distillation process which decreases the ability level to X+a-d, possibly at the advantage of needing less compute. If we amplify this system again, we get a system with ability level X+a-d+a2. When this process repeats many times, it is iterated (see figure 1). In principle, that is all that is needed to define something as iterated distillation and amplification.
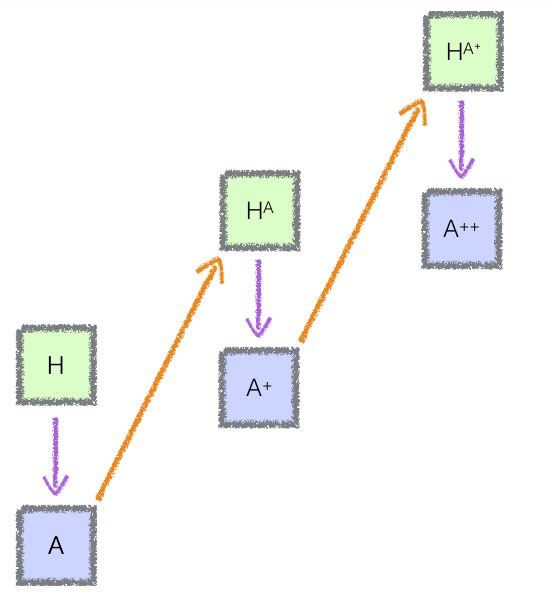
Figure 1.
Specifics of iterated distillation and amplification that are useful in AI systems
There are some specifics to doing iterated distillation and amplification in AI:
- The systems with amplify and distill are (or include) AI systems.
- Any single iteration of amplification and distillation is only useful if a > d, i.e. when we gain more capabilities from the amplification step than we lose from the distillation step. (This is under the assumption that creating a system of ability level X is cheaper than doing amplification and distillation.)
- We probably only want to do distillation if the amplified system is more computationally expensive than the distilled system, otherwise the distilled system is just a strictly worse version. (Unless distillation is the cheapest way of creating approximate copies of the amplified system.)
- The system we distill into can be the same AI that we amplified before. In that case, we have the same AI whose abilities we iteratively increase at computational cost and then decrease for computational advantages (see figure 2).
- If we have repeatable amplification and distillation steps (you can apply the amplification and distillation steps over and over again) it is relatively easier to automate them, i.e. have an AI do them. This likely increases efficiency.
Comment Christiano: This is a bit confusing---you don't really need an AI to do the process, amplify(X) and distill(X) are both just programs that make calls to X, so you can just run them ad infinitum. - If we combine point 2), 4) and 5), we have a self-improving AI system.
Comment Christiano: I think this is accurate but it's a bit confusing since it differs from the way self-improvement is usually used in the AI safety community (and it's not an expression that is usually used in the ML community). - A self-improving AI that identifies and employs better distillation and distillation step is recursively self-improving.
Comment Christiano: This is true but it's not a distinguished form of recursive self-improvement---your AI may also build new computers or change your optimization algorithms or whatever. If the method succeeds the AI will be doing more of those things, since the whole point is that you design some scalable amplification + distillation process that doesn't require ongoing work.
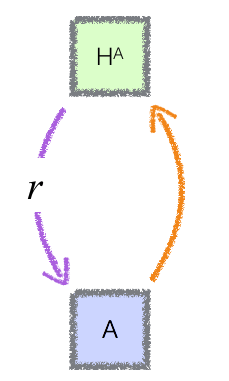
Figure 2.
Example of iterated distillation amplification in a real AI system: AlphaGo Zero
Note: Skip this section if you’re already familiar with how AlphaGo Zero roughly works.
AlphaGo Zero (AGZ) is an AI system that beat AlphaGo in Go which in turn beat the world’s best Go player in Go. It was trained without any data from human games by basically iterating amplification (in this case Monte-Carlo tree search) and distillation (in this case reinforcement learning). I will give a simplified explanation of AGZ as an example for iterated distillation and amplification.
A mathematical way of solving Go is impossible
To decide on a Go move, AGZ could go through every possible move it could take, then go through every possible way it's Go opponent could react to its move and then go through every possible way AGZ could react to that etc. This way, it could play out all possible Go games with itself and choose the move that yields the best consequences. This technique would be very powerful and enable AGZ to find the ground truth, i.e. the actual optimal move. The problem with this approach is that it is computationally intractable, as there are so many possible moves that going through all of them is impossible.
AGZ iterates “manually” going through moves and learning from the moves it tried out
What AGZ does instead is starting with some weak policy, e.g. “decide at random”, to select moves to try out. It then uses some weak policy, e.g. also “decide at random”, to go through some possible responses from it’s opponent and then to go through its next own moves etc. This way, AGZ can play out entire Go games against itself. It can only do so for a very limited number of moves and reactions to moves because this process is extremely expensive, so we only cover a tiny fraction of the vast possible search space.
The AGZ that settles on the move that yielded the best outcome of the moves it tried out, is probably more powerful than the initial AGZ that could only choose moves with the help of a very weak policy, e.g. “decide at random”. The better AGZ is the amplified version of the old AGZ, but it is also a lot slower. It can never become very good at the game because it improves very slowly.
But AGZ can take the Go games it played against itself and use them as training data to find a better policy than “select moves to try out at random”. It develops an intuition for which moves are better to take. The process of using the training data to replace expensive search with heuristics for good moves is the distillation in AGZ. An AGZ that takes moves merely based on these heuristics is the distilled version of the amplified AGZ. It makes worse moves but also is a lot faster.
We can now take the distilled AGZ and amplify it again. We use the distilled AGZ’s improved policy for selecting moves to go through possible moves and possible reactions and our reactions to these reactions etc. The improved policy narrows down our search space to better moves. The resulting system is the new amplified AGZ.
We can repeat this process many, many times until we have a distilled AGZ that is fast and actually good at Go.
For a visual explanation of AGZ I recommend Robert Miles’ video.
Testing your understanding: Clarifying examples of what are and aren’t distillation and amplification processes
Note: This section is for people who want to make sure they fully understand what amplification and distillation mean, but it is not necessary to do so to understand IDA.
AGZ is only one possible example of iterated distillation and amplification. I will give some technical and nontechnical examples of what I would count and not count as amplification and distillation:
Examples for amplification and distillation
Technical examples for amplification and distillation
- Gradient descent (amplification)
Nontechnical examples for amplification and distillation
- Sending a draft around, getting feedback and incorporating it several times (Amplifying your draft and hopefully your writing skills)
- Watching a karate master and trying to imitate them (distilling the master’s ability, but amplifying your ability)
- Coming up with new dance moves (no distillation, possibly amplifying your dance skills)
Why should we think iterating distillation and amplification could lead to powerful and safe AI?
Note: a lot of the terminology used in this section is specific to IDA and might have a different meaning in a different context.
Christiano believes that iterating amplification and distillation is promising because 1) he sees a concrete way of doing amplification that could safely scale to powerful AI of which the idealized version is HCH (which is the abbreviation for the recursive name “Human consulting HCH”) and 2) he thinks that creating a fast powerful agent by distilling from a more powerful agent is potentially safe.[14]
HCH is a proof of concept for a powerful and safe amplification process
Suitable amplification steps for IDA must have no (or very high) upper bounds in terms of capability and preserve corrigibility. IDA argues that HCH is an amplification that has these properties.
HCH is amplifying a human by giving them many more humans they can order to help them solve a task
HCH is the output of a process of humans solving a task by recursively breaking the task into easier subtasks and assigning them to other humans until the subtasks can be solved directly. This can be in the infinite. HCH is an unattainable theoretical ideal point. Showing that HCH would be powerful and corrigible would be a proof of concept for strong and safe AI systems that are amplified using similar methods.
Example: Imagine a human Rosa who tries to solve a very difficult task which she is unable to solve within the working memory and life span she has available. Rosa has access to a large number of copies of herself (Rosa’) and can task them to solve parts of the problem. These subproblems might still be too hard for Rosa’ to solve, but luckily each Rosa’ also has access to a large number of yet more copies of Rosa (Rosa’’) which they can task with subtasks of the subtask they received. Each Rosa’’ now also has access to a bunch of Rosa copies etc.
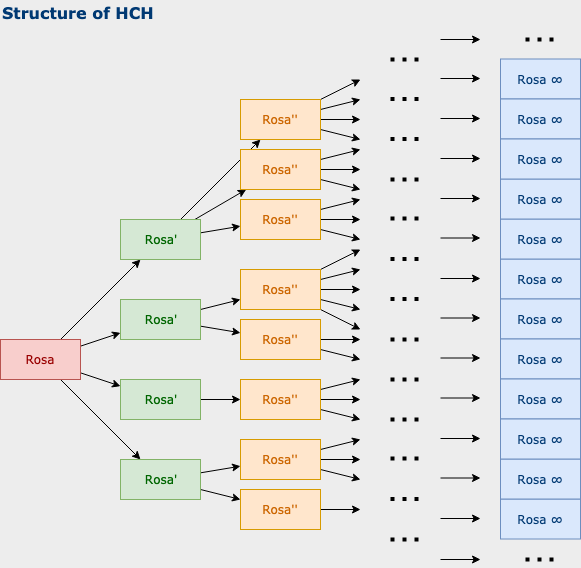
Figure 3.
In addition, the messages sent between the different copies of Rosa and Rosa can contain pointers. Example: If Rosa copy A (anywhere in the tree) has some insight that they shared with Rosa copy B, then Rosa copy B can share that insight in any subsequent message by pointing at Rosa copy A.
The information from solving the lowest level tasks is locally integrated and passed on to higher levels of the HCH tree etc. Example: Rosa’’ integrates all of the information she gets from her Rosa’’’s to solve the subtasks she was assigned to. She then passes that solution to Rosa’. There are many Rosa’’s that report to Rosa’. Rosa’ integrates all the information she gets to solve her subtasks and passes that solution to Rosa. There are many Rosa’s that report to Rosa. Rosa integrates all the information she gets from them so solve the overall task.
This process ends when the task is solved or when creating more copies of Rosa would not change the output anymore. HCH is a fixed point. HCH does not depend on the starting point (“What difficulty of task can Rosa solve on her own?”), but on the task difficulty the reasoning process (= breaking down tasks to solve them) can solve in principle.
The general process of solving a task by recursively breaking it into subtasks and solving these subtasks is called factored cognition and is a way of amplification. Factored cognition does not need to be done by humans like in HCH, but looking at humans might give us important clues about how promising it is.
HCH might be powerful and safe
IDA builds on two intuitions about HCH: First, that there is some way of dividing tasks into subtasks, such that HCH can solve any relevant task (for example solve AI safety or be as strong as any unsafe AI we could ever create). This is based on the intuition that at least some humans (such as Rosa) are above some universality threshold, such that if given sufficiently much time, they could solve any relevant task.
The second intuition is that HCH would be corrigible. IDA is optimistic about this since HCH starts from human reasoning and therefore, the way of breaking down tasks in HCH is human understandable and approved.
If these intuitions about HCH are true, doing amplification via factored cognition seems like a promising approach to safely scale up an AI system to become very powerful since HCH is the result of doing factored cognition with humans and infinite computation.[15]
There is an obvious difference between HCH and any real-world AI system: HCH talks about humans rather than an AI system. Even if HCH was shown to be very powerful and safe, we might not be able to implement safe and powerful factored cognition in an AI. On the other hand, AI systems might also be able to do types of factored cognition that are impossible for humans.
We still need safe distillation because pure HCH is intractable
HCH is the result of a potentially infinite exponential process (see figure 1) and thereby, computationally intractable. In reality, we can not break down any task into its smallest parts and solve these subtasks one after another because that would take too much computation. This is why we need to iterate distillation and amplification and cannot just amplify.
Similar to AlphaGo Zero, we can amplify a system that can only solve very small subtasks by letting it do very fine-grained factored cognition to solve somewhat more difficult tasks. The system solves a lot of tasks this way and we use these solutions as training data to distill a new system that can solve slightly bigger subtasks. We amplify this system by letting it do less fine-grained factored cognition.
Amplified systems can act as overseers and improve our chances of safe distillation
We could potentially use an improved version of a current deep learning technique for distillation. These are the precise techniques Christiano worries cannot be safely scaled up. IDA is optimistic about distillation in this context though because we can use the last amplified AI system as an overseer for the next distillation.
Usually, we apply deep learning to directly teach the AI the skill we eventually want it to have. However, this might become quite dangerous to scale up if we eventually leap from “no capabilities” to “very strong” in one go. This is especially worrying if we want our AI to learn something important that no human is smart enough to understand.
In IDA we only ever distill from a stronger trusted system (amplified AI) to a weaker system. The amplification does the actual scaling up of capabilities, the distillation just makes things faster and more efficient. This has two potential advantages:
First, the amplified AI can act as an overseer that provides feedback to the distilled AI in training in order to both align it and improve its competence.[16] The hope is that oversight is easier when the overseer is stronger than the system in training.
Remember though that in factored cognition the amplification comes from having many copies of a weak subsystem that work on easy subtasks to solve a difficult task, and that we are trying to distill an AI that is stronger than each individual subsystem. To be optimistic about this, we must assume that a bunch of weak systems working together can actually oversee a strong system.
Second, since the distilled AI doesn’t have to be as strong as the amplified AI (but just stronger than the last distilled AI), we might be able to use deep learning techniques that aren’t quite as powerful but in exchange safer.
Which mechanisms ensure that amplification and distillation are actually safe?
To be competitively efficient and powerful, we will probably need to design an AI system that is (recursively) self-improving, i.e. autonomously doing the amplification and distillation with itself,[17] and eventually smarter than humans. How can we design an AI that we can rely on to do good distillation and amplification even if it impossible for us to understand?
We need to find a combination of amplification and distillation procedures that preserves corrigibility. That probably means that we need to find an amplification procedure and a distillation procedure that preserve corrigibility both on average and in worst-case scenarios.
How to make sure the AI system doesn’t make catastrophic mistakes during amplification
The goal of IDA is to find an amplification process we can generally trust. One strong contender is factored cognition which starts from a reasoning process we understand and endorse. However, even if we find a generally good way to do factored cognition, it will probably have some weaknesses that might have catastrophic consequences.
To deal with these weaknesses, IDA proposes two processes that should happen during amplification alongside capability amplification (making our AI system more powerful): Reliability amplification and security amplification.
Why we need reliability amplification
Reliability amplification aims to solve the following problem: Even if we have an in principle corrigible system, for any given input, there is some probability that it acts malignly.
Reliability decreases with amplification
Example: Kim is very unlikely to steal just for fun. However, with every year Kim ages, there is some small probability that their motivation changes and they do steal just for fun. We give Kim the task “never steal just for fun in your life”. This task critically depends on each and every single time slice of Kim. They all have to solve the subtask “don’t steal just for fun”. Kim solves the task.
Now we give a more difficult task: “For 10000 years in a row, don’t steal just for fun.” Normal Kim can’t solve the task within their lifespan, so we amplify Kim by adding 10000 years to their lifespan. During those 10000 years, it seems quite likely that some time slice would defect. For every year we add (to task and lifespan), the probability of failing the overall task and taking a bad action increases, i.e. reliability decreases with every amplification step. What’s worse is that once Kim defects, it’s likelier that they will defect again the next year.
This problem is analogous to amplifying an AI system: In factored cognition, we create lots of small subsystems and give them subtasks that might be critical for the overall task, i.e. if we solve the subtask wrong we solve the entire task wrong. For every subsystem we add, there is some chance that it is malign, e.g. instead of having “help the human” it could have “gain influence” as its ultimate goal.[18] This is worse if we design future subsystems based on the malign subsystem.
Reliability amplification is double checking the solution to all subtasks
Reliability amplification is letting multiple subsystems solve the same subtask and crosscheck each other's solution instead of relying on just one subsystem.
Example: In the earlier example, for every additional year Kim got to live, the probability that they were going to steal just for fun at some point in their life increased. But now every time we add a year to the Kim’s life, we also create two copies of Kim. And at any point in time, Kim only gets to steal just for fun if the majority of Kim copies approve of that action.[19] This seems to sufficiently counteract the increased failure probability from adding another life year. We could make use of the same principle to do reliability amplification alongside capability amplification in AI systems by basically doing every task triple or some similar mechanism.
The problem with this is that it would probably slow down capability amplification.
Why we need security amplification
We need security amplification to deal with adversarial input
Security amplification tries to solve the following problem: There will be some inputs that reliably cause my generally corrigible system to fail.
Example: An AI system that mostly gives correct answers can still fail completely on certain inputs. For example an image classifier might correctly label images as “cats” and “cars” 99% of the time[20] but mislabel some seemingly easy images with very high confidence and for reasons that are opaque to us. These kinds of input that produce poor behavior are called adversarial examples.
Reliability amplification does not help with this problem.
Example: Kim is very unlikely to steal just for fun unless Kim’s crush told them to. Then they will always steal. Even if Kim copies need to consent to Kim stealing just for fun, if they all get told by their crush that they should, they all consent and steal just for fun. Kim would always fail if they encounter the task “Don’t steal just for fun even if your crush tells you to” while trying to solve “Never steal just for fun.”
Security amplification is relevant to defend against both deliberate attacks from other AIs (or sufficiently smart humans) and malign input that our AI system accidentally comes across.[21]
Security amplification is avoiding inputs that are likely to cause the AI system to make catastrophic mistakes by minimizing information per input
Factored cognition means that we have many subsystems working together that each solve a subtask. Security amplification minimizes the information each subsystem ever sees even when the overall task is very complex.
The assumption behind security amplification is that inputs that cause an amplified system to completely fail (behave incorrigibly) are rare and complex: Hopefully, inputs with low complexity (little information) never cause the AI to behave incorrigibly.
Details: Imagine the AI is exposed to some complex information, that would usually cause the AI system to behave incorrigibly. However, we install a mechanism that automatically breaks down complex information into many pieces of less complex information before giving it to any of the subsystems.
Example: We give the AI access to the internet and ask it: “Given all this information, why was the Roman Empire so successful?”. Imagine there was something about the internet, such that any subsystem that was exposed to all the information the AI has to look through to answer this question would behave incorrigibly.
Security amplification means we use a mechanism that only lets through simple information: Exposing any subsystem to all the internet would be impossible. The highest level subsystem (that would be Rosa in HCH) only sees the simple question “Why was the Roman empire so successful?” and is made aware of the existence of the internet. The highest level subsystem cannot look at the internet itself, but instead breaks down the question with the little information it has and passes subquestions on to the next lower subsystems.
This goes on until the lowest level subsystems (in HCH that would be Rosan) only see a tiny directly answerable subquestion they can look up. The subsystem one level higher sees the answer of several of these lowest level subsystems and integrates them to answer a question that’s a bit more complex (local integration) etc. The highest level subsystem never has to see the details that the lowest level subsystems figured out (there is no global integration). It just gets enough higher level information to integrate into an answer.
So far, the break-down mechanism is unspecified, but it has to be simple enough to be robust against adversarial examples itself. For example, A mechanism that chopped every input up into strings of 10 words and only let through one string at a time, it would probably be simple enough to not be corruptible.
This seems very similar to what we would like to do in capability amplification anyway and indeed Paul Christiano thinks that it is likely that we will solve both via the same mechanism. IDA’s current proposal for capability and security amplification is called meta-execution which I will not explain in this document.
How the amplified system ensures corrigibility is preserved during distillation
IDA is mostly focused on exploring the possibility of safe and strong amplification. One reason for this is that distillation is closer to mainstream work on AI since finding a safe distillation procedure essentially answers the question “How do I best train an agent with a bunch of training data?” Nonetheless, IDA proposes some necessary mechanisms and properties to ensure distillation is safe.
Informed oversight and ascription universality: Making sure that the distilled system can’t hide anything from the amplified system
Informed oversight means ensuring that the overseer has access to all the relevant information about what the AI system in training is doing. In the context of IDA, the overseer is the last amplified AI system and the AI system in training is the next distilled AI.
It is important that the overseer both knows which action the distilled AI wants to take as well as why it takes that action. Otherwise, the amplified AI could miss
- unwelcome consequences that the distilled AI is aiming for but that the amplified AI is not aware of, and
- the distilled AI taking a good action for the wrong reasons (e.g. to gain trust and deceive the amplified AI in the long run).
To ensure informed oversight, IDA proposes that the amplified system must be ascription universal. We already discussed the idea of an universality threshold for successful factored cognition and HCH. The idea was that the subsystems involved in factored cognition must be above some threshold, such that with enough of these subsystems (enough computation), they could solve any relevant problem.
Ascription universality is the idea that a system always has at least as good beliefs as any sufficiently computationally simpler system. This means, for all possible questions and tasks, whenever an ascription universal system disagrees with a computationally simpler system, the ascription universal system is more correct. Ideally, this would be true for any computationally simpler system, but in practice this might only be possible for systems that are computationally simpler by a certain amount.
Ascription universality is relevant for informed oversight because an ascription universal system has at least as good beliefs about another system as the other system itself if it is sufficiently computationally simpler. This means that an ascription universal overseer would always understand a sufficiently simpler AI in training at least as well as the AI in training understands itself, i.e. the AI in training cannot hide anything from the overseer. In IDA, a distilled AI (which is being trained) is a less computationally expensive version of an amplified AI (which serves as overseer), so an ascription universal amplified AI would have informed oversight over its distillation if the computational gap is large enough.[22]
Ascription universality is still a vague concept, e.g. it is not specified how exactly we should understand computational complexity or how much simpler a computationally simpler system would have to be, such that an ascription universal system is guaranteed to have at least as good beliefs as it.[23]


Security makes informed oversight more difficult
Informed oversight is complicated by security problems: It is possible that the distilled AI produces an input of the kind that causes our amplified AI to fail (behave incorrigibly). This means we want to apply the same mechanism as in security amplification, i.e. only expose each subsystem of our amplified AI to very little information from the distilled AI.[24] This might make it substantially harder for the amplified AI to understand everything the distilled AI is doing.
Adversarial training: Finding and fixing the distilled system’s vulnerabilities
Informed oversight solves the problem of the distilled system taking actions with malign intentions without the amplified AI noticing. However, even if the distilled AI is acting genuinely corrigibly in all situations it has been exposed to, there might be some inputs (adversarial examples) the distilled AI is not aware of that will cause it to fail completely (act incorrigibly). Adversarial training tries to prevent this.
In adversarial training, we use an adversary that tries to find these adversarial examples that cause the AI to completely fail in order to fix the AI in a way that makes it not fail. In IDA, the last amplified AI could play the role of the adversary and do adversarial training with the distilled AI in training.
How IDA could fail
There are three ways IDA could fail: First, it could just not work, we might be unable to create an AI system that way or at least an AI system that is competitive enough. Second, it might fail catastrophically because of misalignment. We might develop an extremely capable AI with the ideas of IDA but overlook something important that leads to incorrigibility and catastrophic outcomes either immediately or further down the line. Third, we might be able to develop a corrigible but not sufficiently competent AI with IDA that leads it to fail in subtle ways that we don’t instantly recognize but has catastrophic consequences. I will outline some reasons why we might believe each of the three ways to come true.
We might not be able to implement a competitive version of IDA
There is one very simple way in which IDA could trivially become obsolete. In the coming years, we might just develop new, significantly stronger AI techniques that work very different from what we currently have and that IDA is not applicable to and that IDA can’t compete with. We might also realize that IDA’s ideas are conceptually flawed.
HCH might not be powerful, corrigible or translatable to the real world
Similarly we might realize that our intuitions around the concept of HCH are just wrong. We might conclude that HCH could never robustly be corrigible or never become powerful enough: HCH might not be universal either because no universal reasoning process exists or because HCH is not able to do it.
HCH might not be corrigible
IDA argues that in order for HCH to be robustly corrigible, all of the subtrees in HCH should be corrigible in isolation as well. It might be extremely hard or impossible to find break-down mechanisms that robustly preserves corrigibility of the subsystems.
Examples that would not satisfy this condition:
Yudkowsky argues that even if all subsystems in HCH are corrigible, the system as a whole might not be. He argues that if HCH is really smart, this intelligence must come from somewhere, either from the individual subsystems or the way they interact with each other. The smallest subsystems in HCH are humans, so if the intelligence from HCH is coming from just the subsystems it consists of, it cannot become very powerful. The interaction of the subsystems must do some magic. However, if the interaction is doing enough magic to make an extremely powerful system out of less powerful subsystems, it might also make an incorrigible system out of many corrigible subsystems.
HCH might not be able to solve any relevant tasks
There might be no way of breaking tasks down into subtasks for any relevant domain. It might be that all relevant tasks require global integration, i.e. one and the same agent has to go through all the relevant information and steps to solve the task. In this case, IDA would just not work.
Example: A pregnancy takes roughly 9 months. Taking 9 people with uteri doesn’t speed up the pregnancy to 1 month. There is no way of breaking that task down and delegating the subtasks (at least currently). Things like writing poetry or finding a maths proof intuitively seem similar. Finding ways to break down tasks might fall into a similar category.
Even if tasks could in principle be broken down, every way of breaking tasks down might be specific to a very narrow type of task. We might have to find intractably many task-specific break-down mechanisms to get meaningful performance. William Saunders (2019) discusses task-specific “manuals” for overseers in the IDA context but that would probably only work with a limited number of tasks that are broad enough to be helpful. This might mean that IDA just doesn’t work or lead to subtle failure in the form of what I call the differential competence problem, which I discuss in the next section.
The differential competence problem: HCH might favor some skills over others and lead to a bad combination of abilities
HCH might be differentially competent: It might only be able to solve certain kinds of tasks or be better at certain tasks than others. Wei Dai argues that this might lead to bad combinations of abilities that might lead to catastrophic outcomes.
Example: It might be easier to break down the task “Create more destructive nuclear weapons” than “Find effective ways for humans to cooperate with each other to ensure peace.” If so, HCH might make humanity better at the first than the second, which could increase the possibility of catastrophic wars.
The differential competence problem might be worse with AI systems
We also have some reason to think that this might be especially worrisome when we move from HCH to factored cognition with AIs. Compared to humans, an AI system might be particularly good at things for which there is a lot of data and feedback available.
Example: For corrigibility to actually be helpful, we need AI systems that have sufficiently good models of our preferences and when to seek approval for their actions. This might be something an AI system is comparably bad at relative to other capabilities. This would mean that their ability to judge when to seek our approval is not proportional to the general power they have. This is bad news, if we develop an AI system that is incredibly good at building weapons of mass destruction but has a poor understanding of what we want and when to consult humans.
Example: We can also imagine an AI system that realizes we value truth and wants to help us, but is not very good at doing moral philosophy and not very good at finding the optimal truth-seeking strategy of communicating its current opinions. This seems somewhat plausible since moral philosophy is an area with arguably very little data and feedback (unless you have a very descriptive view of ethics). This might be bad if the AI system is comparably better at e.g. convincing people or engineering powerful tools.
We might not be able to safely teach AIs factored cognition
Even HCH works conceptually, we might not be able to make it work for an AI system. Safe amplification could be computationally intractable for example. Ought is currently trying to find out empirically how powerful factored cognition with real humans can become.
Factored cognition in amplification could also still work even if HCH does not work because AI systems are not humans. However, I imagine it to be extremely hard to design an AI doing factored cognition in ways that humans with infinite computation cannot do.
Potential problems with corrigibility
There are a number of criticisms of the role of corrigibility in IDA.
Corrigibility might be doomed without a firm theoretical understanding of what it is
Ben Cottier and Rohin Shah (August 2019) summarize one disagreement around corrigibility as follows:
[T]his definition of corrigibility is still vague, and although it can be explained to work in a desirable way, it is not clear how practically feasible it is. It seems that proponents of corrigible AI accept that greater theoretical understanding and clarification is needed: how much is a key source of disagreement. On a practical extreme, one would iterate experiments with tight feedback loops to figure it out, and correct errors on the go. This assumes ample opportunity for trial and error, rejecting Discontinuity to/from AGI. On a theoretical extreme, some argue that one would need to develop a new mathematical theory of preferences to be confident enough that this approach will work, or such a theory would provide the necessary insights to make it work at all.
In other words, the argument of the corrigibility critics consists of three assumptions and one conclusion:
- Corrigibility is currently too poorly understood to make it work in AI (Proponents and critics seem to agree on this)
- A very clear and formal conceptual understanding of corrigibility is necessary to make corrigibility work in AI.
- Getting this formal understanding is impossible or unlikely.
- Conclusion: We cannot rely on corrigibility.
The proposed safety mechanisms might not be enough to ensure corrigibility
A second argument is about the concrete mechanisms implemented to ensure the corrigibility of the AI system. The safety mechanisms IDA proposes to preserve corrigibility (informed oversight, adversarial training, reliability amplification, security amplification) cannot formally verify corrigibility. They all aim to make it sufficiently likely that the AI system in question is corrigible. You might think that it is not possible to get a sufficiently high likelihood of corrigibility that way.
Corrigibility might not be stable
Another area for criticism is the claim that corrigibility is stable. Here is a counterargument against the stability of corrigibility: Imagine we develop an AI system that wants to earn as much human approval as possible. The AI gets a task and can do it the safe and diligent way. However, doing so might be really inefficient, so the AI might get more approval if it does a slightly sloppy job. Over time, the AI becomes less and less diligent and finally unsafe.
Corrigible AI might unintentionally change our preferences in a way we don’t want to
Wei Dai proposes another problem related to corrigibility. The ideal AI system in IDA is trying to clarify the user’s preferences. However, these are likely to change over time and the AI itself will likely influence our preferences. We want the AI to only influence us in ways that we approve of. This might be extremely hard or impossible to define, implement and verify. The argument’s weight depends on which ethical position people have and what exactly we mean by preferences, but if one has strong feelings about these, this might constitute a failure mode on the level of a catastrophe.
Acknowledgements
I would like to thank Rohin Shah, Max Daniel, Luisa Rodriguez, Paul Christiano, Rose Hadshar, Hjalmar Wijk and Jaime Sevilla for invaluable feedback on this document. I also want to thank everyone at FHI (visitors and staff) who was willing to discuss and clarify IDA or plain out patiently explain it to me. Good ideas are thanks to others and all mistakes are mine :)
For an overview of the current landscape of AI safety research agendas see here. ↩︎
E.g. Alex Zhu, 2018 in his FAQ on IDA ↩︎
Safety: I will clarify what safe means in the context of this write-up further below. Unsafe: An unsafe AI system has an unacceptably high probability of producing very bad (catastrophic) outcomes, e.g. as side effects or because it is optimizing for the wrong thing or would have an unacceptably high probability to do so if scaled up.
Powerful: When I use the term powerful I am pointing towards the same thing that others call superintelligence.
AI, AI systems and agents: I use the terms AI and AI system interchangeably and sometimes refer to a powerful AI systems as agents. ↩︎We can come up with social solutions to ease competitive pressures but probably only if the efficiency gap between safe and unsafe AI alternatives is not too big. Paul Christiano estimates that a safe AI system needs to be about 90% as efficient as its unsafe alternatives. ↩︎
**Arguably, no current AI technique is really unsafe because the AI systems we can create are not strong enough to be meaningfully dangerous. Unsafe in the 2019 context means that they would be unsafe if scaled up (e.g. by increasing computation, computational efficiency or available data) and applied to more powerful AI systems. ↩︎
**The research agenda is actually called “Iterated Amplification” but is still often referred to as “Iterated Distillation and Amplification” and abbreviated as “IDA” ↩︎
Realistically, we would probably have to set up a new AI system with new distillation and amplification methods from time to time that replace the old one instead of having one single system that infinitely improves itself. An alternative way this could look like is that we train an AI system via safe iterated distillation and amplification and this AI systems aids us in developing another, stronger, superintelligent AI system that is not trained via distillation and amplification but via another training method. Which of these three paths to superintelligence would actually play out is not relevant, there are all ideal in the sense that they all essentially mean: We successfully implement an agent with good distillation and amplification procedures and from there on, the development of safe and powerful AI is taking off and taking care of itself. Our work is basically done after having figured out safe distillation and amplification methods, or at least significantly easier. There are also more complicated versions of this where an AI system that is trained by safe distillation and amplification can potentially take us to safe, extremely powerful superintelligent AI, but needs some ongoing fixing and effort from our side. ↩︎
This seems very similar to the third ideal scenario I presented in footnote 7. The deciding difference here is that in this case, while IDA is helpful, it does not solve the full problem and we still have to put a lot of effort in to ensure that things don’t go very wrong. ↩︎
_For example MIRI’s early writing attaches a slightly different meaning to corrigibility than Christiano does: https://intelligence.org/files/Corrigibility.pdf . The concepts are quite close to each other. MIRI’s definition “[an AI that] cooperates with what its creators regard as a corrective intervention| is probably a property that Paul Christiano would also see as central to corrigibility. However, MIRI’s corrigibility is a property that can be formalized and verified. It might for example work like a checklist of actions a human could take in which case the AI should obey (e.g. shut down when a shutdown button is pressed) (This might stems from the belief that there is some algorithmically simple core to corrigibility.) Christiano’s definition is broader, less formal and directed at the AI’s intentions rather than concrete actions it should take in a concrete set of circumstances (e.g. human shutting you down). ↩︎
An AI with the goal “Paint the wall in the color the user wants” is trying to do what we want it to do de dicto. An AI with the goal “Paint the wall blue” is trying to do what we want it to do de re. ↩︎
This departs from the idea of designing a ‘perfectly rational’ AI that’s maximising some objective reward function which represents some ‘true’ preferences but also seems more tractable to Christiano. ↩︎
To give an idea of what “leaves us in power” means, Christiano (June 2017) gives a rough definition of corrigibility by examples of what he wants a corrigible AI system to help him do:
- Figure out whether I built the right AI and correct any mistakes I made
- Remain informed about the AI’s behavior and avoid unpleasant surprises
- Make better decisions and clarify my preferences
- Acquire resources and remain in effective control of them
- Ensure that my AI systems continue to do all of these nice things ↩︎**Yudkowsky discusses the possibility of a “relatively simple core or central principle” to corrigibility. I believe that by that he means that an algorithmically simple core in the way that you can just write it down on paper and formally verify it. This is not the way Christiano understand this. He is referring to some core of corrigibility that is “easy to learn in some non-anthropomorphic sense” but is not easy or even possible to write down in maths and not simple to algorithmically specify. Instead, corrigibility is somehow picked up by the AI during its learning process. It's quite vague how exactly that happens. ↩︎
In principle, you could imagine and insert all kinds of methods and treat “amplification” and “distillation” as place holders. However, IDA’s contribution is to concretely spell out why we should be optimistic about finding suitable procedures and how these procedures are likely to look like. As part of IDA, there is currently work around properties that these procedures would need to have to be safe and concrete-ish candidates for the amplification and distillation step. If these properties and candidate procedures turn out to not work out and also don’t give leads to other properties and candidate procedures that could be inspected for suitability, that doesn’t necessarily mean that no system trained by iterated distillation and amplification can ever be sufficiently safe and powerful, but IDA would lose most if not all of its value. (Similar to how a safe system trained by iterated distillation and amplification does not necessarily have to be corrigible, but if it is not, then the research agenda IDA might have no value.) ↩︎
I only discussed HCH as a reason to think amplification might be promising. Of course, increasing the available compute and dividing tasks into subtasks is just one of many ways to amplify an agent. However, so far it is the only one that people propose as a safe amplification step with no (or a very high) upper bound in terms of capabilities. Therefore, I will treat IDA as if it is tied to this specific way of amplification even though it is not in principle. This doesn’t mean we won’t ever find another promising amplification step. However, unless we can find another promising amplification method in the context of IDA, it seems unclear to me how promising and valuable IDA is. It seems like pointing out HCH was one of the main contributions of IDA. ↩︎
Part of the idea is that the amplified AI can train the distilled agent via supervised learning or reinforcement learning. In the supervised learning setting, the distilled AI looks at how the amplified AI solved tasks and tries to imitate it. During training, the amplified AI could test the distilled AI by giving it tasks and checking the distilled AI’s proposed solutions by solving them itself via factored cognition, comparing if they are the same and giving feedback if the proposed solution was right or wrong.
There is also a version of factored cognition that would allow us to use reinforcement learning for the distillation process: Factored evaluation. Factored evaluation is solving tasks of the type “evaluate how good this input it” . This might be important if there are many things we want the distilled system to learn are not of the form “this is the correct solution to this” but “this thing is a little good, this is very good and this is very bad”.
During training, the amplified AI could test the distilled AI’s proposed solutions not only by comparing them to its own solutions and giving a “wrong”/”right” signal, but by doing factored evaluation to give the distilled AI a reward signal indicating how good or bad the proposed solution is, i.e. we can do reinforcement learning. ↩︎In her summary of IDA, Ajeya Cotra seems to be taking a different stance:
“But in IDA, amplification is not necessarily a fixed algorithm that can be written down once and repeatedly applied; it’s an interactive process directed by human decisions."
This quote implies that humans will always lead and be part of the amplified system (taking a similar role as the highest level node in HCH, i.e. Rosa.) I think this might be plausible when we are still in a phase in which the AI system has not learned how to break down tasks, yet and distills that knowledge from interactions with a human (e.g. either by imitating them or through incentives the human provides). However, I think at some point we will probably have the AI system autonomously execute the distillation and amplification steps or otherwise get outcompeted. And even before that point we might find some other way to train the AI in breaking down tasks that doesn’t involve human interaction. ↩︎This problem would not exist if we found a way of amplification that only creates perfect subsystems that would never “steal just for fun”, but Christiano thinks that that is a lot harder than doing reliability amplification. ↩︎
Of course for this to work the decisions of Kim copies have to be less than perfectly correlated, but the problem of reliability loss only occurs because we assume that we can’t make “perfect copies of subsystems including their motivational structure”/”age perfectly” anyway. ↩︎
or at least hove low confidence in its solution when it gives a wrong answer ↩︎
You might hope that we would automatically be safe from deliberate attacks from other AIs even without security amplification since our AI system is supposed to be competitive. However, it might be that defense is a lot harder than offense in which case it isn’t automatically enough to have an AI system that is just similarly capable as any potential attacker. ↩︎
We might have additional reason for optimism w.r.t. informed oversight since the amplified AI and distilled AI could directly share some of their computation. ↩︎
Paul Christiano expects the definition of ascription universality to change in the future and intends to replace the term ascription universality with a different one once this happens. ↩︎
In the context of IDA, people refer to overseers that are restricted in that way as low bandwidth overseers and overseers that are not restricted that way as high bandwidth overseers. ↩︎


Really glad to see this published. :)
Silly question, I hope to engage more later:
Doesn't it stand for Iterated Distillation and Amplification? Or what's the D doing there?
Hey Max, thanks for your comment :)
Yeah, that's a bit confusing. I think technically, yes, IDA is iterated distillation and amplification and that Iterated Amplification is just IA. However, IIRC many people referred to Paul Christiano's research agenda as IDA even though his sequence is called Iterated amplification, so I stuck to the abbreviation that I saw more often while also sticking to the 'official' name. (I also buried a comment on this in footnote 6)
I think lately, I've mostly seen people refer to the agenda and ideas as Iterated Amplification. (And IIRC I also think the amplification is the more relevant part.)
I'm glad "distillation" is emphasized as well in the acronym, because I think it resolves an important question about competitiveness. My initial impression, from the pitch of IA as "solve arbitrarily hard problems with aligned AIs by using human-endorsed decompositions," was that this wouldn't work because explicitly decomposing tasks this way in deployment sounds too slow. But distillation in theory solves that problem, because the decomposition from the training phase becomes implicit. (Of course, it raises safety risks too, because we need to check that the compression of this process into a "fast" policy didn't compromise the safety properties that motivated decomposition in the training in the first place.)