I just wanted to give major kudos for evaluating a prediction you made and very publicly sharing the results even though they were not fully in line with your prediction.
What follows are some reflections on similarities or differences between these survey results and the other estimates I've collected in that database. But really most estimates aren't directly comparable, since people use different operationalisations, have different caveats, etc. I'll mostly fail to mention these issues and just compare the numbers anyway. Take this with oodles of salt, and check the database for details.
These estimates seem notably higher than:
Carlsmith's estimate (though he's only talking about before 2070 and about one type of AI x-risk scenario)
Ord's estimate (though he was focusing on the next 100 years and thought TAI/AGI has a substantial chance of coming later)
my estimate
the GCR conference's estimate (that focused just on extinction and just on "superintelligent AI", but I'm guessing they would've at that time thought that was >50% of the risk, so their full x-risk number would be similar)
the Grace et al. survey estimate
Pamlin & Armstrong's estimate
Garfinkel's estimate
Shah's estimate (though that's only for "adversarial optimization against humans")
Fodor's estimate
Christiano's estimate (though that focuses on only one type of alignment failure)
These numbers seem a little higher than Cotra's estimate
These numbers are similar to or a little lower than with Armstrong's estimate
These numbers are lower than Shlegeris's estimate and Tallinn's estimate
I find it surprising that this survey's results are not near the middle of the distribution of previous estimates. (Specifically, they're approximately the fourth highest out of approximately 15 estimates - but I would've been similarly surprised by them being approximately the fourth lowest.)
(This surprise is reflected in my predicted survey results being substantially lower than the real results, though I did at least correctly predict that the estimates from MIRI people would be much higher than other people's estimates.)
Part of why I find this surprising is the facts that:
This was a survey of 44 people, not just one new person giving their estimate, so you'd think the mean and median results would be similar to the mean and median from previous estimates
Most of the previous estimates are from people working at the same orgs this survey was sent to, so you'd think this is sampling from a similar population
Do you have any thoughts on where this difference might come from?
Some possibilities:
Different operationalisations
Things like the fact that many of the previous estimates were about the next 100 years or things like that, and maybe the people just thought TAI was unlikely to be developed in that time (but in some cases, I know the people don't think that's very unlikely)
Random noise
Your survey for some reason attracting unusually "pessimistic" people
Unusually "optimistic" people being for some reason unusually likely to have given public, quantitative estimates before
None of those thing seem likely to explain this size and direction of difference, though, so I currently still feel confused.
I find it plausible that there's some perceived pressure to not give unreasonably-high-seeming probabilities in public, so as to not seem weird (as Rob hypothesized in the discussion here, which inspired this survey). This could manifest both as "unusually 'optimistic' people being unusually likely to give public, quantitative estimates" and "people being prone to downplay their estimates when they're put into the spotlight."
Personally, I've noticed the latter effect a couple of times when I was talking to people who I thought would be turned off by high probabilities for TAI. I didn't do it on purpose, but after two conversations I noticed that the probabilities I gave for TAI in 10 years, or things similar to that, seemed uncharacteristically low for me. (I think it's natural for probabilities estimates to fluctuate between elicitation attempts, but if the trend is quite strong and systematically goes in one direction, then that's an indicator of some type of bias.)
I also remember that I felt a little uneasy about giving my genuine probabilities in a survey of alignment- and longtermist-strategy researchers in August 2020 (by an FHI research scholar), out of concerns of making myself or the community seem a bit weird. I gave my true probabilities anyway (I think it was anonymized), but I felt a bit odd for thinking that I was giving 65% to things that I expected a bunch of reputable EAs to only give 10% to. (IIRC, the survey questions were quite similar to the wording in this post.)
(By the way, I find the "less than maximum potential" operationalizations to call for especially high probability estimates, since it's just a priori unlikely that humans set things up in perfect ways, and I do think that small differences in the setup can have huge effects on the future. Maybe that's an underappreciated crux between researchers – which could also include some normative subcruxes.)
But I think these explanations would predict "public, attributed estimates will tend to be lower than estimates from anonymised surveys (e.g., this one) and/or nonpublic estimates". But that's actually not the data we're observing. There were 3 previous anonymised surveys (from the 2008 GCR conference, Grace et al., and that 2020 survey you mention), and each had notably lower mean/median estimates for somewhat similar questions than this survey does.[1]
Maybe the theory could be "well, that part was just random noise - it's just 4 surveys, so it's not that surprising for this one to just happen to give the highest estimate - and then the rest is because people are inclined against giving high estimates when it'll be public and attributed to them".
But that has a slightepicycle/post-hoc-reasoning flavour. Especially because, similar to the points I raised above:
each survey had a decent number of participants (so you'd think the mean/medians would be close to the means/medians the relevant populations as a whole would give)
the surveys were sampling from somewhat similar populations (most clearly for the 2020 survey and this one, and less so for the 2008 one - due to a big time gap - and the Grace et al. one)
So this still seems pretty confusing to me.
I'm inclined to think the best explanation would be that there's something distinctive about this survey that meant either people with high estimates were overrepresented or people were more inclined than they'd usually be to give high estimates.[2] But I'm not sure what that something would be, aside from Rob's suggestions that "respondents who were following the forum discussion might have been anchored in some way by that discussion, or might have had a social desirability effect from knowing that the survey-writer puts high probability on AI risk. It might also have made a difference that I work at MIRI." But I wouldn't have predicted in advance that those things would have as big an effect as seems to be happening here.
I guess it could just be a combination of three sets of small effects (noise, publicity/attribution selecting for lower estimates, and people being influenced by knowing this survey was from Rob).
[1] One notable difference is that the GCR conference attendees were just estimating human extinction by 2100 as a result of “superintelligent AI”. Maybe they thought that only accounted for less than 25% of total x-risk from AI (because there could also be later, non-extinction, or non-superintelligence x-risks from AI). But that seems unlikely to me, based on my rough impression of what GCR researchers around 2008 tended to focus on.
[2] I don't think the reason I'm inclined to think this is trying to defend my previous prediction about the survey results or wanting a more optimistic picture of the future. That's of course possible, but seems unlikely, and there are similarly plausibly biases that could push me in the opposite direction (e.g., I've done some AI-related work in the past and will likely do more in future, so higher estimates make my work seem more important.)
the surveys were sampling from somewhat similar populations (most clearly for the FHI research scholar's survey and this one, and less so for the 2008 one - due to a big time gap - and the Grace et al. one)
I mostly just consider the FHI research scholar survey to be relevant counter evidence here because 2008 is indeed really far away and because I think EA researchers reason quite differently than the domain experts in the Grace et al survey.
When I posted my above comment I realized that I hadn't seen the results of the FHI survey! I'd have to look it up to say more, but one hypothesis I already have could be: The FHI research scholars survey was sent to a broader audience than the one by Rob now (e.g., it was sent to me,and some of my former colleagues), and people with lower levels of expertise tend to defer more to what they consider to be the expert consensus , which might itself be affected by the possibility of public-facing biases.
Of course, I'm also just trying to defend my initial intuition here. :)
Edit: Actually I can't find the results of that FHI RS survey. I only find this announcement. I'd be curious if anyone knows more about the results of that survey – when I filled it out I thought it was well designed and I felt quite curious about people's answers!
I helped run the other survey mentioned , so I'll jump in here with the relevant results and my explanation for the difference. The full results will be coming out this week.
Results
We asked participants to estimate the probability of an existential catastrophe due to AI (see definitions below). We got:
mean: 0.23
median: 0.1
Our question isn't directly comparable with Rob's, because we don't condition on the catastrophe being "as a result of humanity not doing enough technical AI safety research" or "as a result of AI systems not doing/optimizing what the people deploying them wanted/intended". However, that means that our results should be even higher than Rob's.
Also, we operationalise existential catastophe/risk differently, though I think the operationalisations are similar to the point that they wouldn't effect my estimate. Nonetheless:
it's possible that some respondents mistook "existential catastrophe" for "extinction" in our survey, despite our clarifications (survey respondents often don't read the clarifications!)
while "the overall value of the future will be drastically less than it could have been" and "existential catastrophe" are intended to be basically the same, the former intuitively "sounds" more likely than the latter, which might have affected some responses.
My explanation
I think it's probably a combination of things, including this difference in operationalisation, random noise, and Rob's suggestion that "respondents who were following the forum discussion might have been anchored in some way by that discussion, or might have had a social desirability effect from knowing that the survey-writer puts high probability on AI risk. It might also have made a difference that I work at MIRI."
I can add a bit more detail to how it might have made a difference that Rob works at MIRI:
In Rob's survey, 5/27 of respondents who specified an affiliation said they work at MIRI (~19%)
In our survey, 1/43 respondents who specified an affiliation said they work at MIRI (~2%)
(Rob's survey had 44 respondents in total, ours had 75)
Definitions from our survey
Define an existential catastrophe as the premature extinction of Earth-originating intelligent life or the permanent and drastic destruction of its potential for desirable future development (Bostrom, 2013).
Define an existential catastrophe due to AI as an existential catastrophe that could have been avoided had humanity's development, deployment or governance of AI been otherwise. This includes cases where:
AI directly causes the catastrophe.
AI is a significant risk factor in the catastrophe, such that no catastrophe would have occurred without the involvement of AI.
Humanity survives but its suboptimal use of AI means that we fall permanently and drastically short of our full potential.
Other results from our survey
We also asked participants to estimate the probability of an existential catastrophe due to AI under two other conditions.
Within the next 50 years
mean: 0.12
median: 0.05
In a counterfactual world where AI safety and governance receive no further investment or work from people aligned with the ideas of “longtermism”, “effective altruism” or “rationality” (but there are no other important changes between this counterfactual world and our world, e.g. changes in our beliefs about the importance and tractability of AI risk issues).
Excited to have the full results of your survey released soon! :) I read a few paragraphs of it when you sent me a copy, though I haven't read the full paper.
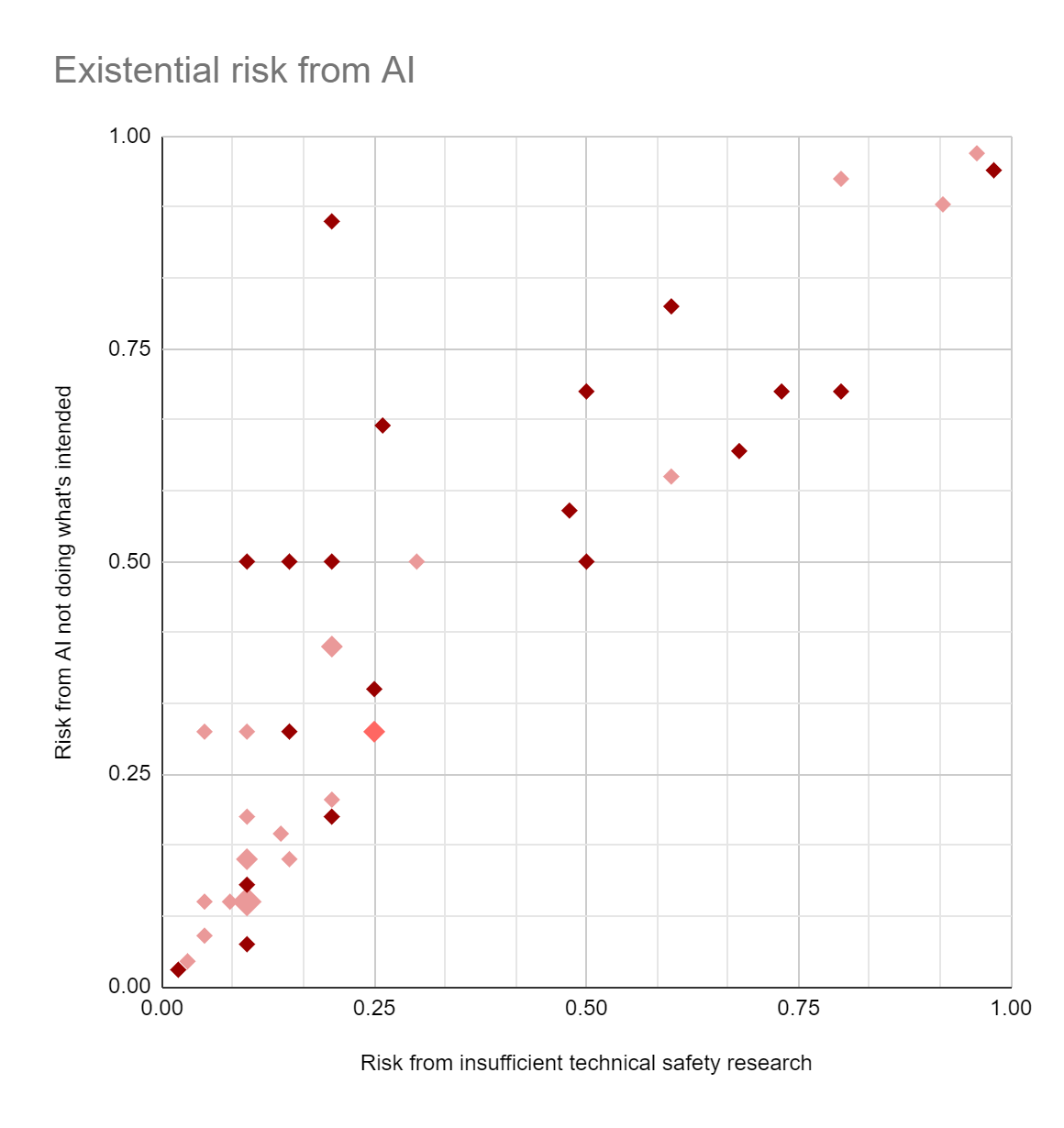
Your "probability of an existential catastrophe due to AI" got mean 0.23 and median 0.1. Notably, this includes misuse risk along with accident risk, so it's especially striking that it's lower than my survey's Q2, "[risk from] AI systems not doing/optimizing what the people deploying them wanted/intended", which got mean ~0.401 and median 0.3.
Looking at different subgroups' answers to Q2:
MIRI: mean 0.8, median 0.7.
OpenAI: mean ~0.207, median 0.26. (A group that wasn't in your survey.)
No affiliation specified: mean ~0.446, median 0.35. (Might or might not include MIRI people.)
All respondents other than 'MIRI' and 'no affiliation specified': mean 0.278, median 0.26.
Even the latter group is surprisingly high. A priori, I'd have expected that MIRI on its own would matter less than 'the overall (non-MIRI) target populations are very different for the two surveys':
My survey was sent to FHI, MIRI, DeepMind, CHAI, Open Phil, OpenAI, and 'recent OpenAI'.
Your survey was sent to four of those groups (FHI, MIRI, CHAI, Open Phil), subtracting OpenAI, 'recent OpenAI', and DeepMind. Yours was also sent to CSER, Mila, Partnership on AI, CSET, CLR, FLI, AI Impacts, GCRI, and various independent researchers recommended by these groups. So your survey has fewer AI researchers, more small groups, and more groups that don't have AGI/TAI as their top focus.
You attempted to restrict your survey to people "who have taken time to form their own views about existential risk from AI", whereas I attempted to restrict to anyone "who researches long-term AI topics, or who has done a lot of past work on such topics". So I'd naively expect my population to include more people who (e.g.) work on AI alignment but haven't thought a bunch about risk forecasting; and I'd naively expect your population to include more people who have spent a day carefully crafting an AI x-risk prediction, but primarily work in biosecurity or some other area. That's just a guess on my part, though.
Overall, your methods for choosing who to include seem super reasonable to me -- perhaps more natural than mine, even. Part of why I ran my survey was just the suspicion that there's a lot of disagreement between orgs and between different types of AI safety researcher, such that it makes a large difference which groups we include. I'd be interested in an analysis of that question; eyeballing my chart, it looks to me like there is a fair amount of disagreement like that (even if we ignore MIRI).
Oh, your survey also frames the questions very differently, in a way that seems important to me. You give multiple-choice questions like :
Which of these is closest to your estimate of the probability that there will be an existential catastrophe due to AI (at any point in time)?
0.0001%
0.001%
0.01%
0.1%
0.5%
1%
2%
3%
4%
5%
6%
7%
8%
9%
10%
15%
20%
25%
30%
35%
40%
45%
50%
55%
60%
65%
70%
75%
80%
85%
90%
95%
100%
... whereas I just asked for a probability.
Overall, you give fourteen options for probabilities below 10%, and two options above 90%. (One of which is the dreaded-by-rationalists "100%".)
By giving many fine gradations of 'AI x-risk is low probability' without giving as many gradations of 'AI x-risk is high probability', you're communicating that low-probability answers are more normal/natural/expected.
The low probabilities are also listed first, which is a natural choice but could still have a priming effect. (Anchoring to 0.0001% and adjusting from that point, versus anchoring to 95%.) On my screen's resolution, you have to scroll down three pages to even see numbers as high as 65% or 80%. I lean toward thinking 'low probabilities listed first' wasn't a big factor, though.
My survey's also a lot shorter than yours, so I could imagine it filtering for respondents who are busier, lazier, less interested in the topic, less interested in helping produce good survey data, etc.
By the way, I find the "less than maximum potential" operationalizations to call for especially high probability estimates
Yeah, I deliberately steered clear of 'less than maximum potential' in the survey (with help from others' feedback on my survey phrasing). Losing a galaxy is not, on its own, an existential catastrophe, because one galaxy is such a small portion of the cosmic endowment (even though it's enormously important in absolute terms). In contrast, losing 10% of all reachable galaxies would be a clear existential catastrophe.
I don't know the answer, though my initial guess would have been that (within the x-risk ecosystem) "Unusually 'optimistic' people being for some reason unusually likely to have given public, quantitative estimates before" is a large factor. I talked about this here. I'd guess the cause is some combination of:
There just aren't many people giving public quantitative estimates, so noise can dominate.
Noise can also be magnified by social precedent; e.g., if the first person to give a public estimate happened to be an optimist by pure coincidence, that on its own might encourage other optimists to speak up more and pessimists less, which could then cascade.
For a variety of dangerous and novel things, if you say 'this risk is low-probability, but still high enough to warrant concern', you're likelier to sound like a sober, skeptical scientist, while if you say 'this risk is high-probability', you're likelier to sound like a doomsday-prophet crackpot. I think this is an important part of the social forces that caused many scientists and institutions to understate the risk of COVID in Jan/Feb 2020.
Causing an AI panic could have a lot of bad effects, such as (paradoxically) encouraging racing, or (less paradoxically) inspiring poorly-thought-out regulatory interventions. So there's more reason to keep quiet if your estimates are likelier to panic others. (Again, this may have COVID parallels: I think people were super worried about causing panics at the outset of the pandemic, though I think this made a lot less sense in the case of COVID.)
This bullet point would also skew the survey optimistic, unless people give a lot of weight to 'it's much less of a big deal for me to give my pessimistic view here, since there will be a lot of other estimates in the mix'.
Alternatively, maybe pessimists mostly aren't worried about starting a panic, but are worried about other people accusing them of starting a panic, so they're more inclined to share their views when they can be anonymous?
Intellectuals in the world at large tend to assume a "default" view along the lines of 'the status quo continues; things are pretty safe and stable; to the extent things aren't safe or stable, it's because of widely known risks with lots of precedent'. If you have a view that's further from the default, you might be more reluctant to assert that view in public, because you expect more people to disagree, ask for elaborations and justifications, etc. Even if you're happy to have others criticize and challenge your view, you might not want to put in the extra effort of responding to such criticisms or preemptively elaborating on your reasoning.
For various reasons, optimism about AI seems to correlate with optimism about public AI discourse. E.g., some people are optimists about AI outcomes in part because they think the world is more competent/coordinated/efficient/etc. overall; which could then make you expect fewer downsides and more upside from public discourse.
Of course, this is all looking at only one of several possible explanations for 'the survey results here look more pessimistic than past public predictions by the x-risk community'. I focus on these to explain one of the reasons I expected to see an effect like this. (The bigger reason is just 'I talked to people at various orgs over the years and kept getting this impression'.)
In retrospect, my forecast that the median response to the first question would be as low as 10% was too ambitious. That would have been surprisingly low for a median.
I think my other forecasts were good. My 18% mean on Q1 was so low only because my median was low. Interestingly my own answer for Q1 was 20%, which was exactly the median response. I forget why I thought the mean and median answer would be lower than mine.
Thanks very much for sharing this! Very interesting. I'm sure I will refer back to this article in the future.
One quick question: when you have the two charts - "Separating out the technical safety researchers and the strategy researchers" - could you make explicit which is which? It's possible to work it out based on the colour of the dots if you try of course.
You're very welcome! I was relying on the shapes to make things clear (circle = technical safety researcher in all charts, square = strategy researcher), but I've now added text to clarify.
The wide spread in responses is surprising to me. Perhaps future surveys like this should ask people what their inside view is and what their all-things-considered view is. My suspicion/prediction would be that doing that would yield all-things-considered views closer together.
How likely do you think it is that the overall value of the future will be drastically less than it could have been
It was unclear to me upon several rereads whether "drastically less" is meant to be interpreted in relative terms (intuitive notions of goodness that looks more like a ratio) or absolute terms (fully taking into account astronomical waste arguments). If the former, this means that eg. 99.9% as good as it could've been is still a pretty solid future, and would resolve "no." If the later, 0.1% of approximately infinity is still approximately infinity.
Would be interested if other people had the same confusion, or if I'm somehow uniquely confused here.
I'd also be interested in hearing if others found this confusing. The intent was a large relative change in the future's value -- hence the word "overall", and the mirroring of some language from Bostrom's definition of existential risk. I also figured that this would be clear from the fact that the survey was called "Existential risk from AI" (and this title was visible to all survey respondents).
None of the respondents (and none of the people who looked at my drafts of the survey) expressed confusion about this, though someone could potentially misunderstand without commenting on it (e.g., because they didn't notice there was another possible interpretation).
Example of why this is important: given the rate at which galaxies are receding from us, my understanding is that every day we delay colonizing the universe loses us hundreds of thousands of stars. Thinking on those scales, almost any tiny effect today can have enormous consequences in absolute terms. But the concept of existential risk correctly focuses our attention on the things that threaten a large fraction of the future's value.
Example of why this is important: given the rate at which galaxies are receding from us, my understanding is that every day we delay colonizing the universe loses us hundreds of thousands of stars. Thinking on those scales, almost any tiny effect today can have enormous consequences in absolute terms. But the concept of existential risk correctly focuses our attention on the things that threaten a large fraction of the future's value.
Sure but how large is large? You said in a different comment that losing 10% of the future is too high/an existential catastrophe, which I think is already debatable (I can imagine some longtermists thinking that getting 90% of the possible value is basically an existential win, and some of the survey respondents thinking that drastic reduction actually means more like 30%+ or 50%+). I think you're implicitly agreeing with my comment that losing 0.1% of the future is acceptable, but I'm unsure if this is endorsed.
If you were to redo the survey for people like me, I'd have preferred a phrasing that says more like
a drastic reduction (>X%) of the future's value.
Or alternatively, instead of asking for probabilities,
> What's the expected fraction of the future's value that would be lost?
Though since a) nobody else raised the same issue I did, and b) I'm not a technical AI safety or strategy researcher, and thus outside of your target audience, so this might all be a moot point.
I can imagine some longtermists thinking that getting 90% of the possible value is basically an existential win
What's the definition of an "existential win"? I agree that this would be a win, and would involve us beating some existential risks that currently loom large. But I also think this would be an existential catastrophe. So if "win" means "zero x-catastrophes", I wouldn't call this a win.
Bostrom's original definition of existential risk talked about things that "drastically curtail [the] potential" of "Earth-originating intelligent life". Under that phrasing, I think losing 10% of our total potential qualifies.
I think you're implicitly agreeing with my comment that losing 0.1% of the future is acceptable, but I'm unsure if this is endorsed.
?!? What does "acceptable" mean? Obviously losing 0.1% of the future's value is very bad, and should be avoided if possible!!! But I'd be fine with saying that this isn't quite an existential risk, by Bostrom's original phrasing.
If you were to redo the survey for people like me, I'd have preferred a phrasing that says more like
"a drastic reduction (>X%) of the future's value."
Agreed, I'd probably have gone with a phrasing like that.
?!? What does "acceptable" mean? Obviously losing 0.1% of the future's value is very bad, and should be avoided if possible!!! But I'd be fine with saying that this isn't quite an existential risk, by Bostrom's original phrasing.
So I reskimmed the paper, and FWIW, Bostrom's original phrasing doesn't seem obviously sensitive to 2 orders of magnitude by my reading of it. "drastically curtail" feels more like poetic language than setting up clear boundaries.
He does have some lower bounds:
> However, the true lesson is a different one. If what we are concerned with is (something like) maximizing the expected number of worthwhile lives that we will create, then in addition to the opportunity cost of delayed colonization, we have to take into account the risk of failure to colonize at all. We might fall victim to an existential risk, one where an adverse outcome would either annihilate Earth-originating intelligent life or permanently and drastically curtail its potential.[8] Because the lifespan of galaxies is measured in billions of years, whereas the time-scale of any delays that we could realistically affect would rather be measured in years or decades, the consideration of risk trumps the consideration of opportunity cost. For example, a single percentage point of reduction of existential risks would be worth (from a utilitarian expected utility point-of-view) a delay of over 10 million years. (LZ: I was unable to make this section quote-text)
Taking "decades" conservatively to mean "at most ten decades", this would suggest that something equivalent to a delay of ten decade (100 years) probably does not count as an existential catastrophe. However, this is a lower bound of 100/10 million * 1%, or 10^-7, far smaller than the 10^-3 I mentioned upthread.
(I agree that "acceptable" is sloppy language on my end, and losing 0.1% of the future's value is very bad.)
(I considered just saying "existential risk" without defining the term, but I worried that people sometimes conflate existential risk with things like "extinction risk" or "risk that we'll lose the entire cosmic endowment".)
I agree that "existential risk" without defining the term would be much worse. It might have a technical definition within longtermism philosophy, but I don't think the term has the exact same meaning as broadly understood by EAs.
Unfortunately, even the technical definition relies on the words "destroys" or "drastically curtails", which leaves room for interpretation. I would guess that most people interpret those things as "destroys the vast majority [of our potential]", e.g. reduces the EV of the future to 10% of what it could've been or lower. But it sounds like Rob interprets it as reduces the EV by at least 10%, which I would've called an example of a non-existential trajectory change.
I leave the thresholds vague, but it should be understood that in any existential catastrophe the greater part of our potential is gone and very little remains.
So I think Rob's "at least 10% is lost" interpretation would indeed be either unusual or out of step with Ord (less sure about Bostrom).
Then perhaps it's good that I didn't include my nonstandard definition of x-risk, and we can expect the respondents to be at least somewhat closer to Ord's definition.
I do find it odd to say that '40% of the future's value is lost' isn't an x-catastrophe, and in my own experience it's much more common that I've wanted to draw a clear line between '40% of the future is lost' and '0.4% of the future is lost', than between 90% and 40%. I'd be interested to hear about cases where Toby or others found it illuminating to sharply distinguish 90% and 40%.
I have sometimes wanted to draw a sharp distinction between scenarios where 90% of humans die vs. ones where 40% of humans die; but that's largely because the risk of subsequent extinction or permanent civilizational collapse seems much higher to me in the 90% case. I don't currently see a similar discontinuity in '90% of the future lost vs. 40% of the future lost', either in 'the practical upshot of such loss' or in 'the kinds of scenarios that tend to cause such loss'. But I've also spent a lot less time about Toby thinking about the full range of x-risk scenarios.
FWIW, I personally don't necessarily think we should focus more on 90+% loss scenarios than 1-90% loss scenarios, or even than <1% loss scenarios (though I'd currently lean against that final focus). I see this as essentially an open question (i.e., the question of which kinds of trajectory changes to prioritise increasing/decreasing the likelihood).
I do think Ord thinks we should focus more on 90+% loss scenarios, though I'm not certain why. I think people like Beckstead and MacAskill are less confident about that. (I'm lazily not including links, but can add them on request.)
I have some messy, longwinded drafts on something like this topic from a year ago that I could share, if anyone is interested.
I was just talking about what people take x-risk to mean, rather than what I believe we should prioritise.
Some reasons I can imagine for focusing on 90+% loss scenarios:
You might just have the empirical view that very few things would cause 'medium-sized' losses of a lot of the future's value. It could then be useful to define 'existential risk' to exclude medium-sized losses, so that when you talk about 'x-risks' people fully appreciate just how bad you think these outcomes would be.
'Existential' suggests a threat to the 'existence' of humanity, i.e., an outcome about as bad as human extinction. (Certainly a lot of EAs -- myself included, when I first joined the community! -- misunderstand x-risk and think it's equivalent to extinction risk.)
After googling a bit, I now think Nick Bostrom's conception of existential risk (at least as of 2012) is similar to Toby's. In https://www.existential-risk.org/concept.html, Nick divides up x-risks into the categories "human extinction, permanent stagnation, flawed realization, and subsequent ruination", and says that in a "flawed realization", "humanity reaches technological maturity" but "the amount of value realized is but a small fraction of what could have been achieved". This only makes sense as a partition of x-risks if all x-risks reduce value to "a small fraction of what could have been achieved" (or reduce the future's value to zero).
I still think that the definition of x-risk I proposed is a bit more useful, and I think it's a more natural interpretation of phrasings like "drastically curtail [Earth-originating intelligent life's] potential" and "reduce its quality of life (compared to what would otherwise have been possible) permanently and drastically". Perhaps I should use a new term, like hyperastronomical catastrophe, when I want to refer to something like 'catastrophes that would reduce the total value of the future by 5% or more'.
On the final paragraph, I don't strongly disagree, but:
I think to me "drastically curtail" more naturally means "reduces to much less than 50%" (though that may be biased by me having also heard Ord's operationalisation for the same term).
At first glance, I feel averse to introducing a new term for something like "reduces by 5-90%"
I think "non-existential trajectory change", or just "trajectory change", maybe does an ok job for what you want to say
Technically those things would also cover 0.0001% losses or the like. But it seems like you could just say "trajectory change" and then also talk about roughly how much loss you mean?
It seems like if we come up with a new term for the 5-90% bucket, we would also want a new term for other buckets?
I also mentally noted that "drastically less" was ambiguous, though for the sake of my quick forecasts I decided that whether you meant (or whether others would interpret you as meaning) "5% less" or "90% less" didn't really matter to my forecasts, so I didn't bother commenting.
Yeah, a big part of why I left the term vague is because I didn't want people to get hung up on those details when many AGI catastrophe scenarios are extreme enough to swamp those details. E.g., focusing on whether the astronomical loss threshold is 80% vs. 50% is besides the point if you think AGI failure almost always means losing 98+% of the future's value.
I might still do it differently if I could re-run the survey, however. It would be nice to have a number, so we could more easily do EV calculations.
I'd be interested in seeing operationalizations at some subset of {1%, 10%, 50%, 90, 99%}.* I can imagine that most safety researchers will give nearly identical answers to all of them, but I can also imagine that large divergences, so decent value of information here.
*Probably can't do all 5, at least not at once, because of priming effects.
I sent a two-question survey to ~117 people working on long-term AI risk, asking about the level of existential risk from "humanity not doing enough technical AI safety research" and from "AI systems not doing/optimizing what the people deploying them wanted/intended".
44 people responded (~38% response rate). In all cases, these represent the views of specific individuals, not an official view of any organization. Since some people's views may have made them more/less likely to respond, I suggest caution in drawing strong conclusions from the results below. Another reason for caution is that respondents added a lot of caveats to their responses (see the anonymized spreadsheet),1 which the aggregate numbers don't capture.
I don’t plan to do any analysis on this data, just share it; anyone who wants to analyze it is of course welcome to.
You can find a copy of the survey here. The main questions (including clarifying notes) were:2
1. How likely do you think it is that the overall value of the future will be drastically less than it could have been, as a result of humanity not doing enough technical AI safety research?
2. How likely do you think it is that the overall value of the future will be drastically less than it could have been, as a result of AI systems not doing/optimizing what the people deploying them wanted/intended?
_________________________________________
Note A: "Technical AI safety research" here means good-quality technical research aimed at figuring out how to get highly capable AI systems to produce long-term outcomes that are reliably beneficial.
Note B: The intent of question 1 is something like "How likely is it that our future will be drastically worse than the future of an (otherwise maximally similar) world where we put a huge civilizational effort into technical AI safety?" (For concreteness, we might imagine that human whole-brain emulation tech lets you gather ten thousand well-managed/coordinated top researchers to collaborate on technical AI safety for 200 subjective years well before the advent of AGI; and somehow this tech doesn't cause any other changes to the world.)
The intent of question 1 *isn't* "How likely is it that our future will be astronomically worse than the future of a world where God suddenly handed us the Optimal, Inhumanly Perfect Program?". (Though it's fine if you think the former has the same practical upshot as the latter.)
Note C: We're asking both 1 and 2 in case they end up getting very different answers. E.g., someone might give a lower answer to 1 than to 2 if they think there's significant existential risk from AI misalignment even in worlds where humanity put a major civilizational effort (like the thousands-of-emulations scenario) into technical safety research.
I also included optional fields for "Comments / questions / objections to the framing / etc." and "Your affiliation", and asked respondents to
Check all that apply:
☐ I'm doing (or have done) a lot of technical AI safety research.
☐ I'm doing (or have done) a lot of governance research or strategy analysis related to AGI or transformative AI.
I sent the survey out to two groups directly: MIRI's research team, and people who recently left OpenAI (mostly people suggested by Beth Barnes of OpenAI). I sent it to five other groups through org representatives (who I asked to send it to everyone at the org "who researches long-term AI topics, or who has done a lot of past work on such topics"): OpenAI, the Future of Humanity Institute (FHI), DeepMind, the Center for Human-Compatible AI (CHAI), and Open Philanthropy.2,3
The survey ran for 23 days (May 3–26), though it took time to circulate and some people didn't receive it until May 17.4
Results
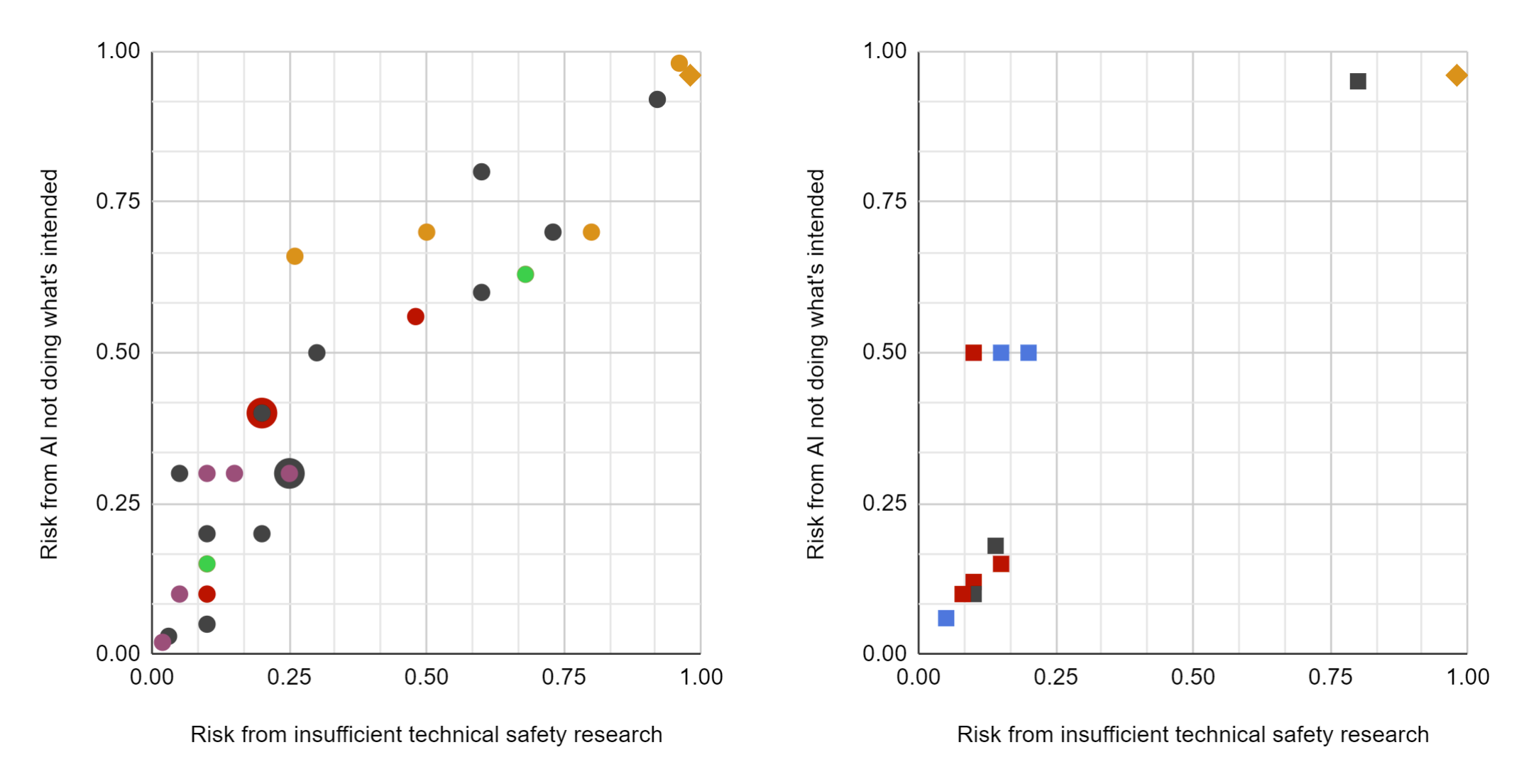
Each point is a response to Q1 (on the horizontal axis) and Q2 (on the vertical axis). Circles denote (pure) technical safety researchers, squares (pure) strategy researchers; diamonds marked themselves as both, triangles as neither. In four cases, shapes are superimposed because 2–3 respondents gave the same pair of answers to Q1 and Q2.5 One respondent (a "both" with no affiliation specified) was left off the chart because they gave interval answers: [0.1, 0.5] and [0.1, 0.9].
Purple represents OpenAI, red FHI, green CHAI or UC Berkeley, orange MIRI, blue Open Philanthropy, and black "no affiliation specified". No respondents marked DeepMind as their affiliation.
Separating out the technical safety researchers (left) and the strategy researchers (right):
Overall, the mean answer of survey respondents was (~0.3, ~0.4), and the median answer was (0.2, 0.3).
Background and predictions
I'd been considering running a survey like this for a little while, and decided to pull the trigger after a conversation on the EA Forum in which I criticized an analysis that assigned low probability to a class of AI risk scenarios. In the EA Forum conversation, I quoted a prediction of mine (generated in 2017 via discussion with a non-MIRI researcher I trust):
I think that at least 80% of the AI safety researchers at MIRI, FHI, CHAI, OpenAI, and DeepMind would currently assign a >10% probability to this claim: "The research community will fail to solve one or more technical AI safety problems, and as a consequence there will be a permanent and drastic reduction in the amount of value in our future."
This is (I think) reasonably close to Q1 in the survey. Looking only at people who identified themselves as MIRI/FHI/CHAI/OpenAI/DM (so, excluding Open Phil and ‘no affiliation specified’) and as technical safety or strategy researchers, 11 / 19 = ~58% gave >10% probability to question 1, which is a far cry from my predicted 80+%. I expect this at least partly reflects shifts in the field since 2017, though I think it also casts some doubt on my original claim (and certainly suggests I should have hedged more in repeating it today). Restricting to technical safety researchers, the number is 10 / 15 = ~67%.
Note that respondents who were following the forum discussion might have been anchored in some way by that discussion, or might have had a social desirability effect from knowing that the survey-writer puts high probability on AI risk. It might also have made a difference that I work at MIRI.6
Respondents' comments
A large number of respondents noted that their probability assignments were uncertain or unstable, or noted that they might give a different probability if they spent more time on the question. More specific comments included...
(Caveat: I'm choosing the bins below arbitrarily, and I'm editing out meta statements and uncertainty-flagging statements; see the spreadsheet for full answers.)
... from respondents whose highest probability was < 25%:
0.1, 0.05: "[...] The first is higher than the second because we're thinking a really truly massive research effort -- it seems quite plausible that (a) coordination failures could cause astronomical disvalue relative to coordination successes and (b) with a truly massive research effort, we could fix coordination failures, even when constrained to do it just via technical AI research. I don't really know what probability to assign to this (it could include e.g. nuclear war via MAD dynamics, climate change, production web, robust resistance to authoritarianism, etc and it's hard to assign a probability to all of those things, and that a massive research effort could fix them when constrained to work via technical AI research)."
0.1, 0.12: "(2) is a bit higher than (1) because even if we 'solve' the necessary technical problems, people who build AGI might not follow what the technical research says to do"
0.2, 0.2: "'Drastically less than it could have been' is confusing, because it could be 'the future is great, far better than the present, but could have been drastically better still' or alternatively 'we destroy the world / the future seems to have very negative utility'. I'm sort of trying to split the difference in my answer. If it was only the latter, my probability would be lower, if the former, it would be higher. Also, a world where there was tremendous effort directed at technical AI safety seems like a world where there would be far more effort devoted to governance/ethics, and I'm not sure how practically to view this as a confounder."
0.019, 0.02: "Low answers to the above should not be taken to reflect a low base rate of P(humans achieve AGI); P(humans achieve AGI) is hovering at around 0.94 for me. [...]"
... from respondents whose highest probability was 25–49%:
0.25, 0.3: "`1` and `2` seem like they should be close together for me, because in your brain emulation scenario it implies that our civ has a large amount of willingness to sacrifice competitiveness/efficiency of AI systems (by pausing everything and doing this massive up-front research project). This slack seems like it would let us remove the vast majority of AI x-risk."
0.15, 0.3: "I think my answer to (1) changes quite a lot based on whether 'technical AI safety research' is referring only to research that happens before the advent of AGI, separate from the process of actually building it.
In the world where the first AGI system is built over 200 years by 10,000 top technical researchers thinking carefully about how to make it safe, I feel a lot more optimistic about our chances than the world where 10,000 researchers do research for 200 years, then hand some kind of blueprint to the people who are actually building AGI, who may or may not actually follow the blueprint.
I'm interpreting this question as asking about the latter scenario (hand over blueprint). If I interpreted it as the former, my probability would be basically the same as for Q2."
... from respondents whose highest probability was 50–74%:
0.2, 0.5: "[...] Deployment-related work seems really important to me, and I take that to be excluded from technical research, hence the large gap."
0.68, 0.63: "It's a bit ambiguous whether Q1 covers failures to apply technical AI safety research. Given the elaboration, I'm taking 1 to include the probability that some people do enough AI safety research but others don't know/care/apply it correctly. [...]"
0.15, 0.5: "On the answer to 2, I'm counting stuff like 'Human prefs are so inherently incoherent and path-dependent that there was never any robust win available and the only thing any AI could possibly do is shape human prefs into something arbitrary and satisfy those new preferences, resulting in a world that humans wouldn't like if they had taken a slightly different path to reflection and cognitive enhancement than the one the AI happened to lead them down.' I guess that's not quite a central example of 'the value of the future [being] drastically less than it could have been'? [...]"
0.1, 0.5: "[...] I think there is some concern that a lot of ways in which 2 is true might be somewhat vacuous: to get to close-to-optimal futures we might need advanced AI capabilities, and these might only get us there if AI systems broadly optimize what we want. So this includes e.g. scenarios in which we never develop sufficiently advanced AI. Even if we read 'AI systems not doing/optimizing what the people deploying them wanted' as presupposing the existence of AI systems, there may be vacuous ways in which non-advanced AI systems don't do what people want, but the key reason is not their 'misalignment' but simply their lack of sufficiently advanced capabilities.
I think on the most plausible narrow reading of 2, maybe my answer is more like 15%."
0.26, 0.66: "The difference between the numbers is because (i) maybe we will solve alignment but the actor to build TAI will implement the solution poorly or not at all (ii) maybe alignment always comes at the cost of capability and competition will lead to doom (iii) maybe solving alignment is impossible"
0.5, 0.5: "[...] My general thoughts: might be more useful to discuss concrete trajectories AI development could follow, and then concrete problems to solve re safety. Here's one trajectory:
1. AI tech gets to the point where it's useful enough to emulate smart humans with little resource costs: AI doesn't look like an 'optimised function for a loss function', rather it behaves like a human who's just very interested in a particular topic (e.g. someone who's obsessed with mathematics, some human interaction, and nothing else).
2. Governments use this to replicate many researchers in research fields, resulting in a massive acceleration of science development.
3. We develop technology which drastically changes the human condition and scarcity of resources: e.g. completely realistic VR worlds, drugs which make people feel happy doing whatever they're doing while still functioning normally, technology to remove the need to sleep and ageing, depending on what is empirically possible.
Dangers from this trajectory: 1. the initial phase of when AI is powerful, but we haven't reached (3), and so there's a chance individual actors could do bad things. 2. Some may think that certain variations of how (3) ends up may be bad for humanity; for example, if we make a 'happiness drug', it might be unavoidable that everyone will take it, but it might also make humanity content by living as monks."
0.5, 0.7: "For my 0.5 answer to question 1, I'm not imagining an ideal civilizational effort, but am picturing things being 'much better' in the way of alignment research. [...]"
0.48, 0.56: "I’m interpreting 'not doing what the people deploying them wanted/intended' as intended to mean 'doing things that are systematically bad for the overall value of the future', but this is very different from what it literally says. The intentions of people deploying AI systems may very well be at odds with the overall value of the future, so the latter could actually benefit from the AI systems not doing what the people deploying them wanted. If I take this phrase at its literal meaning then my answer to question 2 is more like 0.38."
0.73, 0.7: "2 is less likely than 1 because I put some weight on x-risk from AI issues other than alignment that have technical solutions."
... from respondents whose highest probability was > 74%:
0.6, 0.8: "What are the worlds being compared in question 2? One in which AI systems (somehow manage to) do what the people deploying them wanted/intended vs the default? Or <the former> vs one in which humanity makes a serious effort to solve AI alignment? I answered under the first comparison.
My answer to question 1 might increase if I lean more on allowing 'technical' to include philosophy (e.g., decision theory, ethics, metaphysics, content) and social science (e.g., sociology, economics)."
0.8, 0.7: "I think that there's a lot riding on how you interpret 'what the people deploying them wanted/intended' in the second question—e.g. does it refer to current values or values after some reflection process?"
0.98, 0.96: "I think there's a large chance that the deployers will take an attitude of 'lol we don't care whatevs', but I'm still counting this as 'not doing what they intended' because I expect that the back of their brains will still have expected something other than instant death and empty optimizers producing paperclips. If we don't count this fatality as 'unintended', the answer to question 2 might be more like 0.85.
The lower probability to 2 reflects the remote possibility of deliberately and successfully salvaging a small amount of utility that is still orders of magnitude less than could have been obtained by full alignment, in which possible worlds case 1 would be true and case 2 would be false."
0.2, 0.9: "[...] I think the basket of things we need a major effort on in order to clear this hurdle is way way broader than technical AI safety research (and inclusive of a massive effort into technical AI safety research), so 1 is a lot lower than 2 because I think 'doing enough technical AI safety research' is necessary but not sufficient [...]"
After collecting most of the comments above, I realized that people who gave high x-risk probabilities in this survey tended to leave a lot more non-meta comments; I'm not sure why. Maroon below is "left a non-meta comment", pink is "didn't", red is a {pink, maroon} pair:
Thank you to everyone who participated in the survey or helped distribute it. Additional thanks to Paul Christiano, Evan Hubinger, Rohin Shah, and Carl Shulman for feedback on my question phrasing, though I didn't take all of their suggestions and I'm sure their ideal version of the survey would have looked different.
Footnotes
1 Changes to the spreadsheet: I redacted respondents’ names, standardized their affiliation input, and randomized their order. I interpreted ‘80’ and ‘70’ in one response, and ‘15’ and ‘15’ in another, as percentages.
2 I’d originally intended to only survey technical safety researchers and only send the survey to CHAI/DeepMind/FHI/MIRI/OpenAI, but Rohin Shah suggested adding Open Philanthropy and including strategy and forecasting researchers. I’d also originally intended to only ask question #1, but Carl Shulman proposed that I include something like question #2 as well. I think both recommendations were good ones.
3 The "117 recipients" number is quite approximate, because:
(a) CHAI's representative gave me a number from memory, which they thought might be off by 1 or 2 people.
(b) FHI's representative erred on the side of sharing it with a relatively large group, of whom he thought "5-8 people might either self-select into not counting or are people you would not want to count. (Though I would guess that there is decent correlation between the two, which was one reason why I erred on being broad.)"
(c) Beth from OpenAI shared it in a much larger (85-person) Slack channel; but she told people to only reply if they met my description. OpenAI's contribution to my "117 recipients" number is based on Beth's guess about how many people in the channel fit the description.
4 Response rates were ~identical for people who received the survey at different times (ignoring any who might have responded but didn't specify an affiliation):
May 3–4: ~30%
May 10: ~29%
May 15–17: ~28%
5 Overlapping answers:
(0.2, 0.4) from an FHI technical safety researcher and an affiliation-unspecified technical safety researcher.
(0.25, 0.3) OpenAI tech safety and affiliation-unspecified tech safety.
(0.1, 0.15) CHAI tech safety and FHI general staff.
(0.1, 0.1) FHI tech safety, affiliation-unspecified strategy, FHI general staff.
In case it's visually unclear, I'll note that in the latter case, there are also two FHI strategy researchers who gave numbers very close to (0.1, 0.1).
6 I checked whether this might have caused MIRI people to respond at a higher rate. 17/117 people I gave the survey to work at MIRI (~15%), whereas 5/27 of respondents who specified an affiliation said they work at MIRI (~19%).
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...



I just wanted to give major kudos for evaluating a prediction you made and very publicly sharing the results even though they were not fully in line with your prediction.