Can you quantify how much work recency weighting is doing here? I could imagine it explaining all (or even more than all) of the effect (e.g. if many "best" forecasters have stale predictions relative to the community prediction often).
Suggestion: pre-commit to a ranking method for forecasters. Chuck out questions which go to <5%/>95% within a week. Take the pairs (question, time) with 10n+ updates within the last m days for some n,m, and no overlap (for questions with overlap pick the time which maximises number of predictions). Take the n best forecasters per your ranking method in the sample and compare them to the full sample and the "without them" sample.
Quick question about reputation scores: "Every time a question resolves, the reputation is updated depending on how many Metaculus points a user got relative to other users (with a mean of zero and a standard deviation of 10)" -- does this mean that predicting on questions late in the life of a question is harmful for one's reputation? Because predicting late means that you'll typically get fewer points than an early predictor.
In principle yes. In practice also usually yes, but the specifics depend on whether the average user who predicted on a question gets a positive amount of points. So if you predicted very late and your points are close to zero, but the mean number of points forecasters on that question received is positive, then you will end up with a negative update to your reputation score. Completely agree that a lot hinges on that reputation score. It seems to work decent for the Metaculus Prediction, but it would be good to see what results look like for a different metric of past performance.
Presumably, when choosing your X, there is a trade-off between "having better forecasters" and "having more forecasters" (see this and this analysis on why more forecasters might be good).
FWIW, here, I found a correlation of -0.0776 between number of forecasters and Brier score. So more forecasters does seem to help, but not that much.
If you have the choice to ask a large crowd OR a small group of accomplished forecasters, you should maybe consider the crowd. This is especially true if you have access to past performance and can do something more sophisticated than Metaculus' Community Prediction.
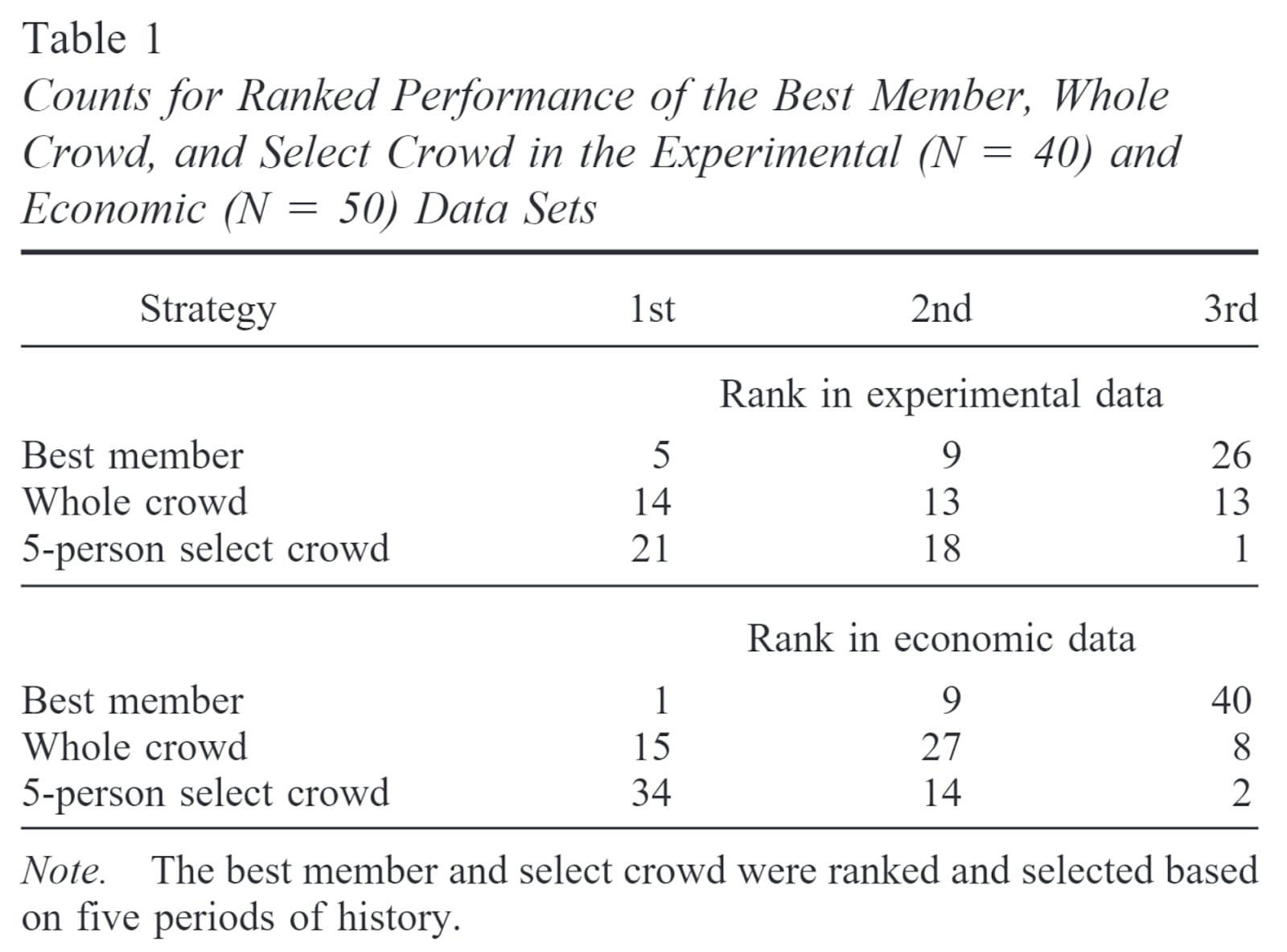
Mannes 2014 found a select crowd to be better, although not by much, looking into 90 data sets:
Note they scored performance in terms of the mean absolute error, which is not proper, but I guess they would get qualitatively similar results in they had used a proper rule.
I used the Metaculus reputation scores for my analysis to select the top forecasters. Reputation scores are used internally to compute the Metaculus Prediction and track performance relative to other forecasters. Using average Brier scores or log scores might yield very different results. Really: this entire analysis hinges on whether or not you think the reputation score is a good proxy for past performance. And it may be, but it might also be flawed.
I think it makes more sense to measure reputation according to the metric being used for performance, i.e. with the Brier/log score, as Mannes 2014 did (but using mean absolute error). You could also try measuring reputation based on performance on questions of the same category, such that you get the best of each category.
Interesting, thanks for sharing the paper. Yeah agree that using the Brier score / log score might change results and it would definitely be good to check that as well.
I don't know man, Metaculus forecasters are generally unpaid. Maybe "the best" would be the best monetary prediction market forecasters, or the best hedge-fundies?
Glad you brought up real money markets because the real choice here isn't "5 unpaid superforecasters" vs "200 unpaid average forecasters" but "5 really good people who charge $200/h" vs "200 internet anons that'll do it for peanuts". Once you notice the difference in unit labor costs, the question becomes: for a fixed budget, what's the optimal trade-off between crowd size and skill? I'm really uncertain about that myself and have never seen good data on it.
This post asks whether we can improve forecasts for binary questions merely by selecting a few accomplished forecasters from a larger pool.
Using Metaculus data, it compares
the Community Prediction (a recency-weighted median of all forecasts) with
a counterfactual Community Prediction that combines forecasts from only the best 5, 10, ..., 30 forecasters based on past performance (the "Best") and
a counterfactual Community Prediction with all other forecasters (the "Rest") and
the Metaculus Prediction, Metaculus' proprietary aggregation algorithm that weighs forecasters based on past performance and extremises forecasts (i.e. pushes them towards either 0 or 1)
The ensemble of the "Best" almost always performs worse on average than the Community Prediction with all forecasters
The "Best" outperforms the ensemble of all other forecaster (the "Rest") in some instances.
the "Best" never outperform the "Rest" on average for questions with more than 200 forecasters
performance of the "Best" improves as their size increases. They never outperform the "Rest" on average at size 5, sometimes outperform it at size 10-20 and reliably outperform it for size 20+ (but only for questions with fewer than 200 forecasters)
The Metaculus Prediction on average outperforms all other approaches in most instances, but may have less of an advantage against the Community Prediction for questions with more forecasters
Conflict of interest note I am an employee of Metaculus. I think this didn't influence my analysis, but then of course I'd think that, and there may be things I haven't thought about.
Introduction
Let's say you had access to a large number of forecasters and you were interested in getting the best possible forecast for something. Maybe you're running a prediction platform (good job!). Or you're the head of an important organisation that needs to make an important decision. Or you just really really really want to correctly guess the weight of an ox.
What are you going to do? Most likely, you would ask everyone for their forecast, throw the individual predictions together, stir a bit, and pull out some combined forecast. The easiest way to do this is to just take the mean or median of all individual forecasts, or, probably better for binary forecasts, the geometric mean of odds. If you stir a bit harder, you could get a weighted, rather than an unweighted combination of forecasts. That is, when combining predictions you give forecasters different weights based on their past performance. This seems like an obvious idea, but in reality it is really hard to pull off. This is called the forecast combination puzzle: estimating weights from past data is often noisy or biased and therefore a simple unweighted ensemble often performs best.
Instead of estimating precise weights, you could just decide to take the X best forecasters based on past performance and use only their forecasts to form a smaller ensemble. (Effectively, this would just give those forecasters a weight of 1 and everyone else a weight of 0). Presumably, when choosing your X, there is a trade-off between "having better forecasters" and "having more forecasters" (see this and this analysis on why more forecasters might be good).
(Note that what I'm analysing here is not actually a selection of the best available forecasters. The selection process is quite distinct from the one used for say Superforecasters, or Metaculus Pro Forecasters, who are identified using a variety of criteria. And see the Discussion section for additional factors not studied here that would likely affect the performance of such a forecasting group.)
Methods
To get some insights, I analysed data from Metaculus on binary questions. For every single question, I
ordered all users by their performance prior to the beginning of the question. I tracked performance based on a "reputation" score, which represents participation and performance over time relative to the performance of other forecasters. The reputation score is broadly computed as follows: All new forecasters start at -0.5 and their reputation is an average of their performance relative to other users over time. Every time a question resolves, the reputation is updated depending on how many Metaculus points a user got relative to other users (with a mean of zero and a standard deviation of 10. This reputation score is also what Metaculus uses internally for their Metaculus Prediction.
selected a number of 5, 10, 15, 20, 25, or 30 of the best users according to that reputation (the "Best") and calculated a counterfactual ensemble prediction for these (using the recency-weighted median that Metaculus uses for their Community Prediction)
calculated a counterfactual ensemble prediction including all those that were not among the top forecasters (the "Rest")
calculated another counterfactual ensemble, this time excluding the worst 5, 10, ..., 30 forecasters according to the reputation score (the "Not the worst")
randomly drew 10 forecasters (repeated 10 times and averaged) and computed an ensemble for these (the "Random").
The ensemble forecasts were computed the same way the Metaculus Community Prediction (CP) is computed: as a recency weighted median of all forecasts.
I calculated Brier scores (a proper scoring rule, lower is better) for
the "Best" (CP (best))
the "Rest" (CP (rest))
the "Not the worst" (CP (not worst))
the "Random" (CP (random))
the normal Metaculus Community Prediction (CP (all)), which includes forecasts from the "Best" and the "Rest"
the Metaculus Prediction (MP), i.e. the ensemble created using Metaculus' proprietary aggregation algorithm. This combines forecasts weighted by the past performance of the forecaster and extremises predictions, i.e. pushes them towards 0 or 1.
I then took the average of all those Brier scores across questions, filtering for different minimum numbers of forecasters (50, 100, 150, ..., 600).
Results (and some discussion)
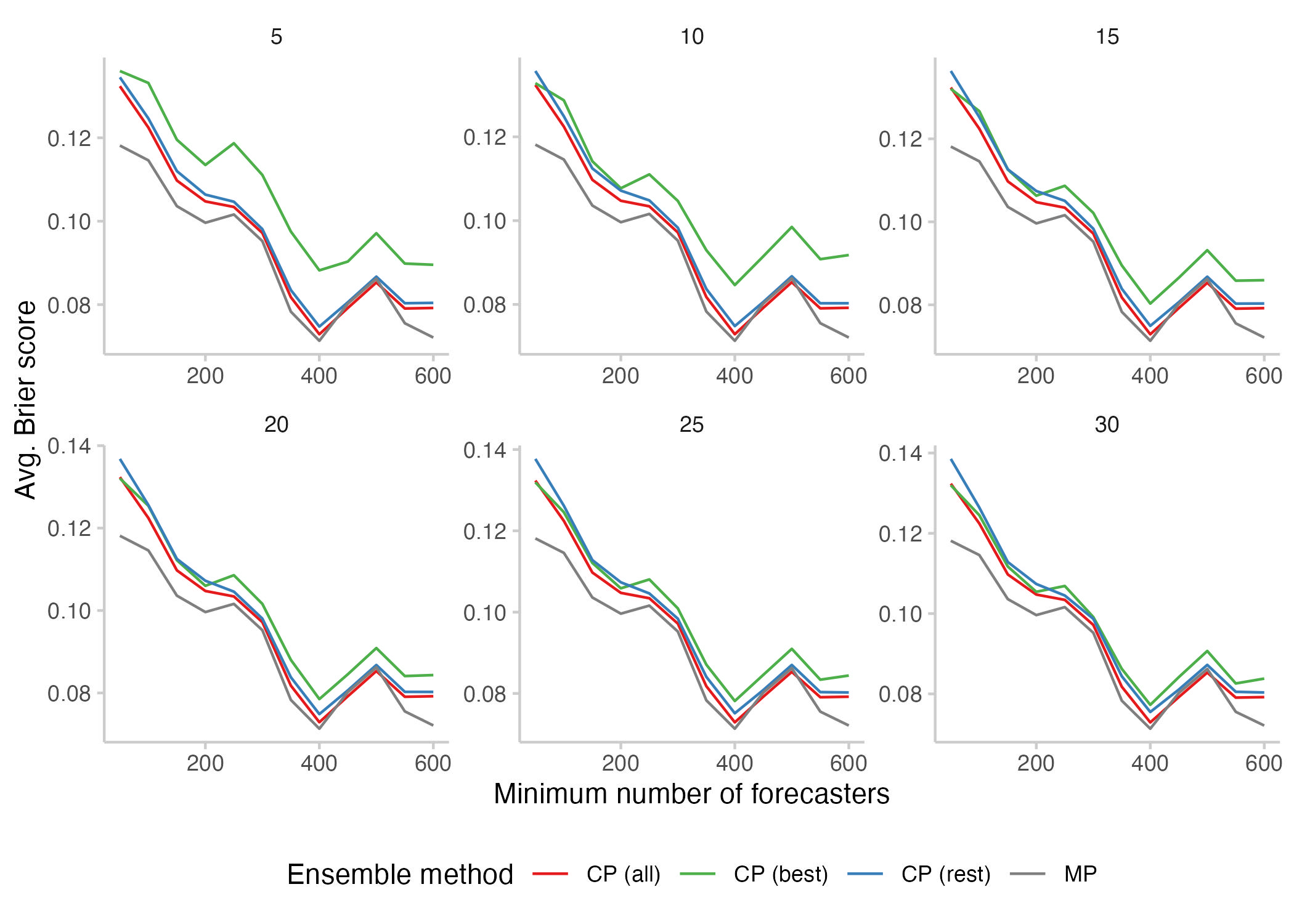
Here is the Brier Score for the different ensemble methods. The individual panels show how many forecasters were included in the ensemble of the "Best".
Figure 1: Average Brier score of different forecast ensembles, with questions filtered based on an increasing minimum number of forecasters (shown on the x-axis). Shown are the regular community prediction (red), a counterfactual community prediction computed for only the best 5, 10, ..., 30 forecasters (green), a counterfactual community prediction including all remaining forecasters (blue), and the Metaculus Prediction (dark grey), a trained forecast aggregation algorithm.
A general trend
We can see a general trend for scores to be lower (i.e. better) for questions with a larger number of forecasters. I think some combination of the following three things is happening:
ensemble forecasts might be getting better as more forecasters join and the ensemble size increases
the ensemble of just the best forecasters might be improving as, with a greater overall number of forecasters, the average quality of the best 5, 10, ..., 30 forecasters improves
questions with higher number of forecasters might be easier and therefore questions with a large number of forecasters on average get a better score. For example, certain question domains or topics might be easier and also attract a larger number of forecasters.
ad 1.: We have some evidence that increasing the number of forecasters improves predictions on Metaculus (e.g. see here and here), although the size of the effect is hard to quantify exactly.
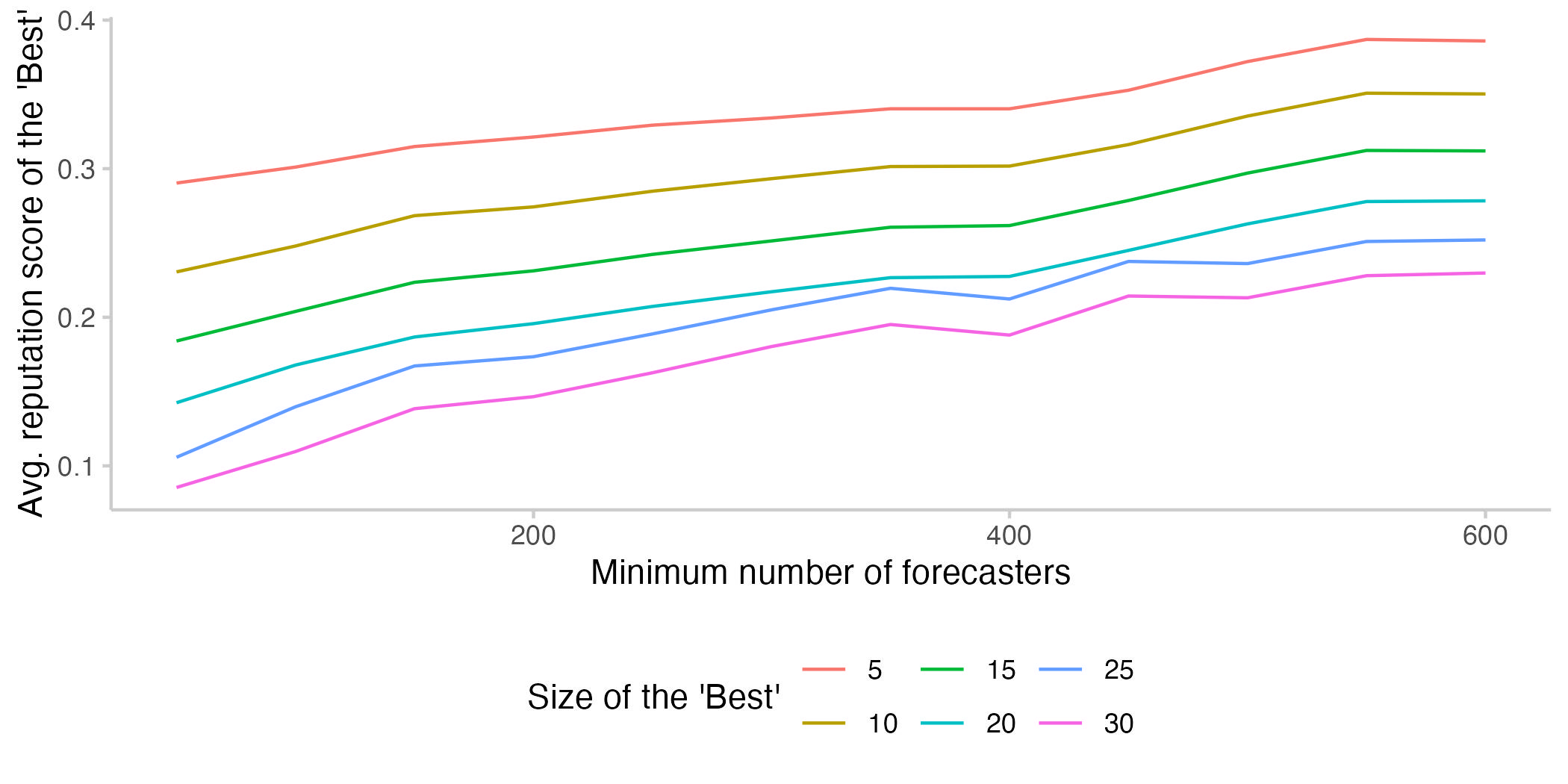
ad 2.: We can definitely see that the average reputation score of the "Best" improves once we grow the overall pool of forecasters from which we draw the "Best". I find it plausible that better reputation scores translate into better forecast accuracy, but the analysis at hand doesn't prove it. The alternative hypothesis would be some kind of mean reversion: forecasters who did well in the past might have been lucky and are expected to revert back to average forecast quality in the future.
Figure 2: Average reputation scores for the forecasters included in the ensemble of the "Best". Reputation scores reflect a user's participation and performance relative to others.
ad 3.: I suspect that question difficulty plays a large role: Why else should all those curves in Figure 1 be so similar? The only other explanation I could come up with is that the performance boost you get from increasing the number of forecasters is pretty much exactly the performance boost you gain from increasing the average skill of the "Best". But if that were the main explanation, why would all curves show the same little uptick around a minimum number of 500 forecasters?
It's also important to highlight that the sample size decreases notably once we increase the minimum number of forecasters - results may therefore become less reliable.
Min. num. forecasters
50
100
150
200
250
300
350
400
450
500
550
600
Num. of available questions
1033
507
276
175
127
90
72
59
39
35
30
27
Table 1: Number of questions for different minimum numbers of forecasters that were used to compute the average Brier scores in Figure 1
Ensemble comparisons
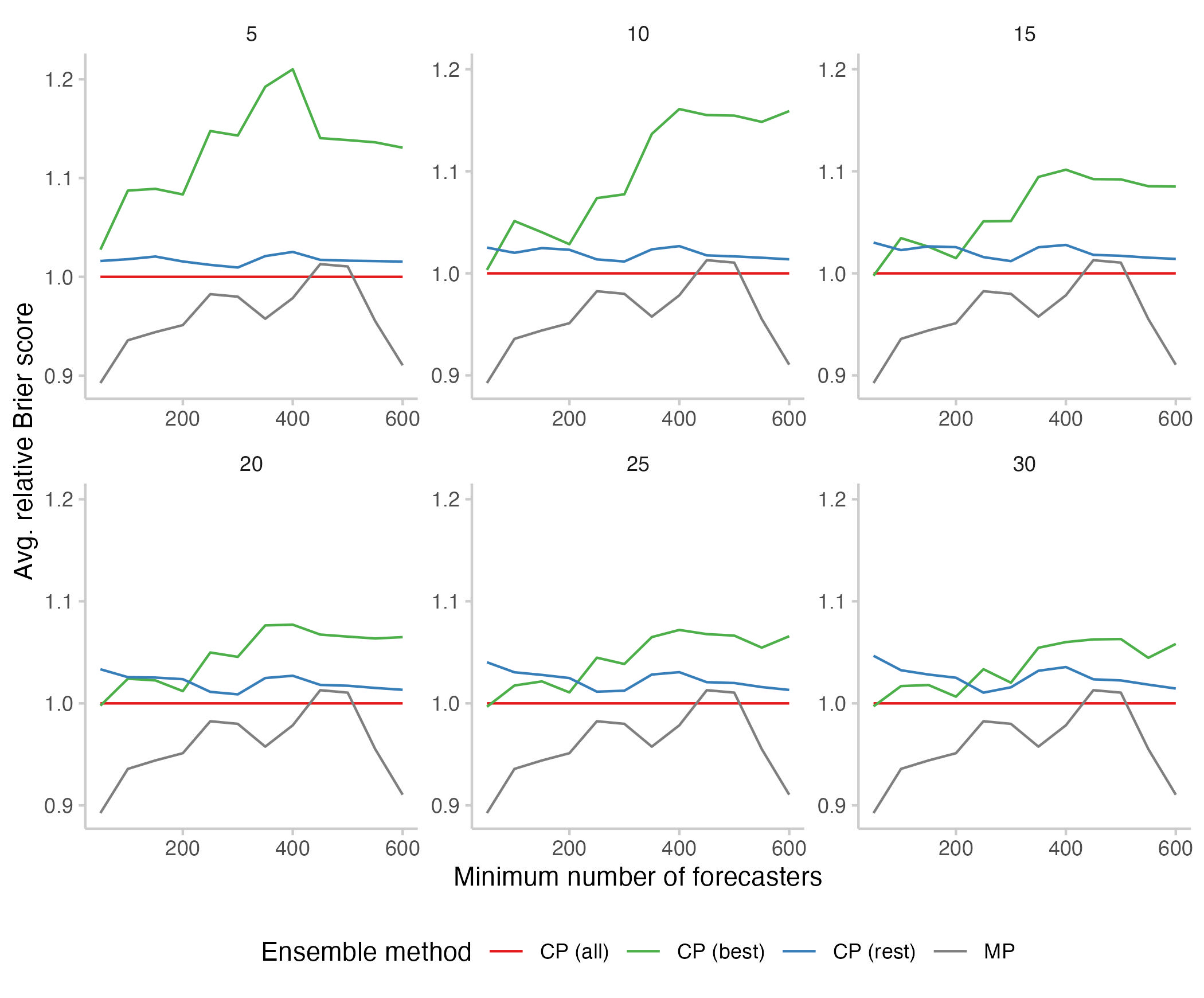
The main thing that stood out so far was a general improvement in performance as we increased the minimum number of forecasters. Let's now look at differences in performance between the different aggregation methods. To make things a bit easier to interpret, I've divided all scores by the score for the regular Community Prediction to obtain relative scores. This is the result:
Figure 3: Relative Brier scores for the different aggregation methods. Lower scores are better. Relative scores were obtained by dividing all scores by the score for the Community Prediction that includes all forecasters (so the red line corresponds to the score of the Community Prediction, and a score below it beats the CP). The Metaculus Prediction is shown in black.
A few things stand out:
The overall CP is always and in all scenarios better than the CP for the "Rest" without the top forecasters
The "Rest" becomes worse as we increase the number of forecasters included in the "Best". That makes sense, as we drain the pool of forecasters in the "Rest".
The "Best" get better when we increase their number:
An ensemble of five top forecasters performed strictly worse than the ensemble of the "Rest"
An ensemble of the top 10 forecasters performs better than the ensemble of the "Rest" for questions with few forecasters, and worse for questions with many forecasters
An ensemble of the top 30 forecasters performs better than an ensemble of the rest for questions with fewer than 200 participants
The "Best" never clearly beat the Community Prediction with all forecasters included. If we only look at questions with a minimum of 100 forecasters or more, the "Best" on average perform worse than the Community Prediction.
The Metaculus Prediction mostly outperforms the other methods.
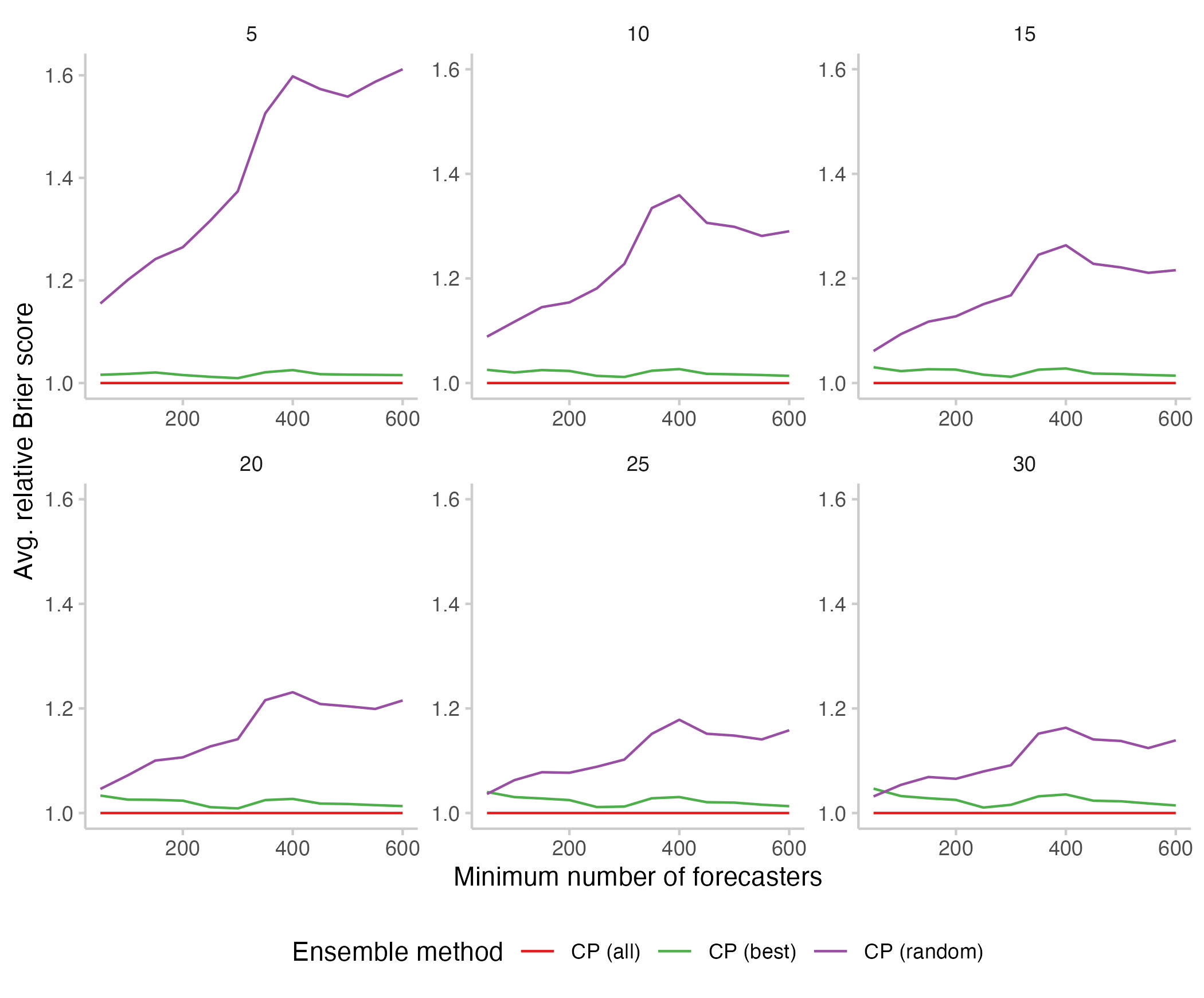
To sense check the results, I ran two additional analyses. For the first one, I randomly drew a set of n forecasters and computed their ensemble forecast and score (the "Random"). For computational reasons (= I'm a terrible programmer and my code took to long to run) I only collected 10 samples for every random selection of forecasters, so don't expect results to be super precise. The general picture is pretty clear though and looks pretty much as expected: the "Random" have all the disadvantages that the "Best" have with none of the advantages and consequently do a lot worse.
Figure 4: Relative Brier scores for different aggregation methods. In purple shown are scores for n randomly selected forecasters (drawn iteratively and averaged across 10 samples). In green are again the "Best"
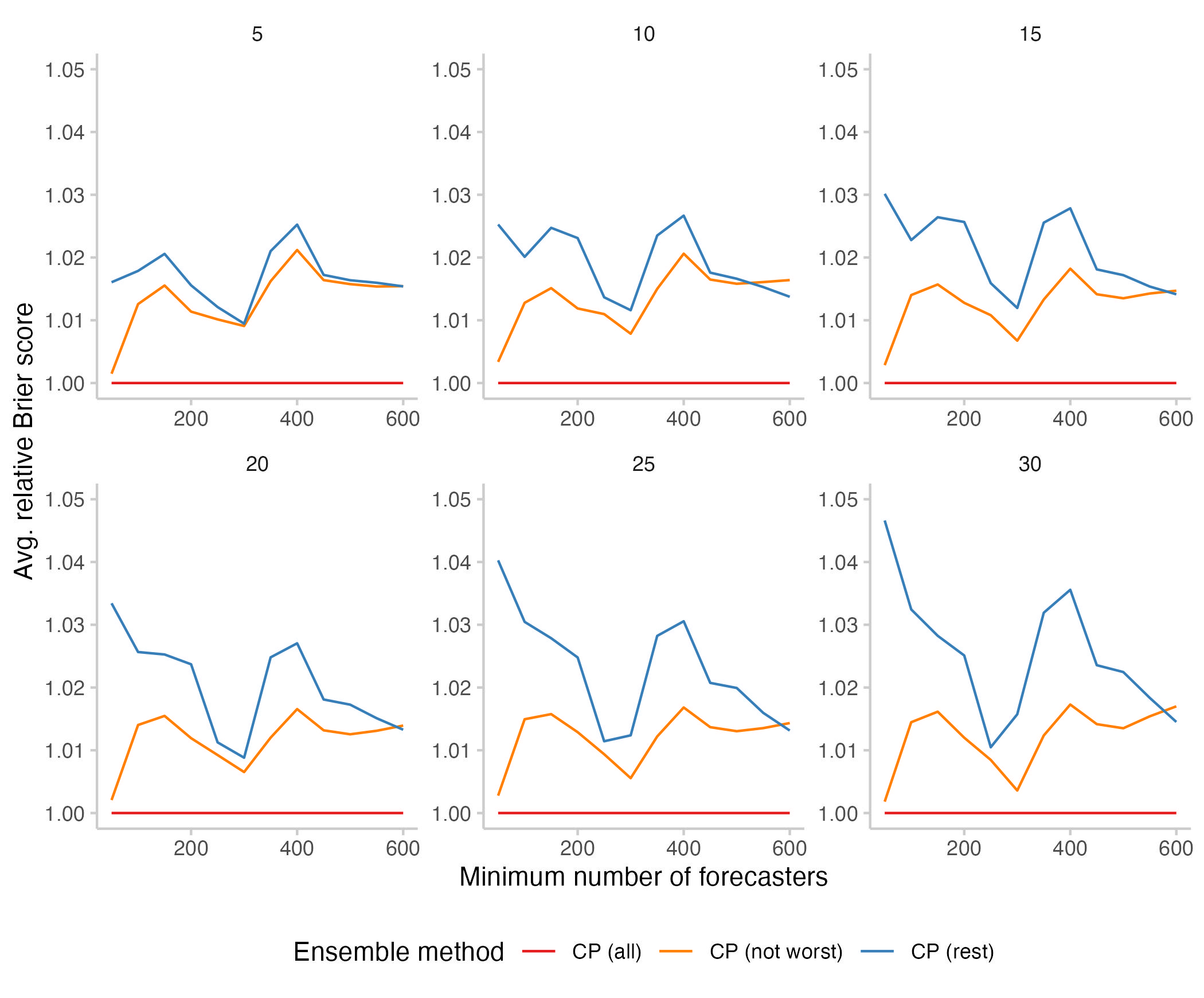
In addition, I looked at a version of the Community Prediction for which we take away the n worst forecasters (according to the Metaculus reputation score). This was a mild surprise to me:
Figure 5: Relative Brier scores for different aggregation methods. In orange is an ensemble that was created by removing the n participants with the lowest reputation score. In blue are again scores for the "Rest".
I was also expecting for the "Not the worst" to do a a bit better than the Community Prediction or at least equally well. The "Not the worst" performed better than the "Rest" most of the time, but on average strictly worse than the Community Prediction. Overall, differences are pretty small, but still.
Some hypotheses for why the "Not the worst" perform worse than the Community Prediction:
The reputation doesn't measure performance well. Or at least, it doesn't really measure performance well for low reputation values. New Metaculus forecasters start with a reputation of -0.5, and so it might be that filtering by reputation mostly removes new forecasters, rather than bad forecasters.
the effect of "more forecasters" is stronger than the effect of "removing bad forecasters"
There might also be something that new forecasters (or worse forecasters) predict differently in a way that is bad in isolation, but may be helpful information to include in an ensemble.
Discussion
Overall the Community Prediction is not easy to beat, but we can do better. The fact that the Metaculus Prediction outperformed the Community Prediction suggests that at least some learning based on past performance is possible. Simply looking at the few top forecasters based on past performance won't cut it though.
(My personal theory for why the Metaculus Prediction works as well as it does is due to a combination of the following factors:
It does extremising, i.e. it pushes forecasts slightly towards either 0 or 1, which empirically improves scores
It is giving higher weight to better forecasters, but also doesn't completely discard the information provided by the rest. This might give us a more favourable trade-off between "better forecasters" and "more forecasters"
It aggregates predictions more cleverly than just using the median
Taking away the past best-performing forecasters from the Community prediction led to poorer performance of the "Rest". Maybe adding more good forecasters to the existing community prediction could help improve it? This seems of course likely, but also isn't entirely self-evident [1] and the analysis at hand doesn't exactly prove it.
The overall Community Prediction (i.e. the "Best" plus the "Rest") quite consistently performed better than the "Best" alone. The "Best" started to become noticeably better than the "Rest" for at least 10 - 15 members of the "Best" and questions that had fewer than 200 forecasters. For questions that had more than 200 forecasters, the "Rest" always outperformed the "Best" on average.
This has potentially important implications if you're thinking about running a project that involves a crowd of forecasters or selecting a small number of highly accomplished forecasters.
If you have the choice to ask a large crowd OR a small group of accomplished forecasters, you should maybe consider the crowd. This is especially true if you have access to past performance and can do something more sophisticated than Metaculus' Community Prediction. (If you can do things like have forecasters collaborate extensively etc, that's another story)
If you can only get a small group of accomplished forecasters, then more is probably (maybe?) better.
The analysis here suggests that an ensemble of the "Best" of larger size performs better.
However, based on this data we can't really say whether it would be better to have twice as many people, rather than having the same people put in twice as much effort
Adding more good forecasters to your crowd might be beneficial.
If you have both a crowd and a group of accomplished forecasters, combining their forecasts might be helpful.
Limitations
All results and conclusions are subject to a range of important limitations.
Firstly, any conclusions are only valid for the current Community Prediction. Using a different aggregation mechanism, e.g. a geometric mean of odds instead could also change all results discussed here. More generally: all analyses I did are based on Metaculus data - things might look very different on other platforms or in other settings.
The current Community Prediction algorithm is a recency-weighted median of past predictions. Recency-weighting in particular might influence results, as it might have different effects on large crowds and small crowds. Also, the recency decay that Metaculus uses depends on the number of forecasts, not the timing of the forecast (i.e. it's relevant whether your forecast is the last or second-to-last, not when it was actually made), which can have very different effects in situations with lots of forecasters or a lot of updating.
I only looked at binary questions. Things might look a lot different for continuous forecasts (and I personally suspect they do).
All results reflect overall performance and ignores the fact that there is a broad range of question categories which may be very different from each other. Performance may vary across question categories in a way that is not reflected here. This is true in particular if a certain category only attracts a few forecasters, or a very special set of forecasters.
I used the Metaculus reputation scores for my analysis to select the top forecasters. Reputation scores are used internally to compute the Metaculus Prediction and track performance relative to other forecasters. Using average Brier scores or log scores might yield very different results. Really: this entire analysis hinges on whether or not you think the reputation score is a good proxy for past performance. And it may be, but it might also be flawed.
Note that there may be some confounding of reputation scores with time, given that as the platform grows we would expect newer questions to attract more forecasters on average and also forecasters would have more time to earn a good skill score just by participating a lot.
There is a different, quite interesting time effect. Forecasts are scored over the whole time period, however individual forecasts are made at discrete time points and can become stale over time. Having a large crowd is an advantage, because it means you get frequent updates. Imagine you managed to get 10 very good forecasters together to make a forecast on one single afternoon. That forecast might be better than a comparable forecast from a crowd of 200. However, if the task is to be as accurate as possible over the span of 2 years, the 200 may be at an advantage.
For this analysis I only looked at relative performance, i.e. whether one approach was better than another. This isn't meant to tell you anything about the absolute level of forecast quality. Whether a forecast is 'good' or 'bad' very much depends on what you believe a reasonable baseline is. And for anything more complicated than a probability for binary yes / no questions, I'm not even entirely sure what a "good" forecast is.
Lastly, this analysis, of course, doesn't directly transfer to a real-world application in which you would think about gathering a group of "Superforecasters" or "Pro Forecasters" to forecast on a set of questions. In reality, many other factors that we haven't studied here would likely affect performance:
Selecting forecasters and giving them a specific task (especially if that involves payment and personal accountability) likely means that forecasters will put more effort into forecasting than they would have done when casually predicting on Metaculus. Or it could mean that forecasters make a prediction at all, which may be relevant to ensure minimum participation on niche topics
Giving someone the title "Superforecaster" or "Pro Forecaster" alone could make a strong difference in their motivation.
Fostering communication, debate and collaboration between a small group of forecasters might affect motivation and performance.
You might be able to attract or select forecasters that otherwise would not have made a prediction.
Being able to communicate your reasoning and rationale is a big part of what contributes to the usefulness of forecasts
Further work
There is a lot of work that could and should be done in the future.
First, a more comprehensive review of the literature. Nothing I did here was really 'new' and I think it would be important to contrast findings to what researchers found in other domains and settings.
Recomputing the Metaculus Prediction for the "Best" and the "Rest" might be useful to obtain a more comprehensive picture. In particular, this could give us some insight as to whether the Metaculus Prediction performs equally well for different numbers of forecasters and for different average forecaster skills.
Similarly, the same analysis could be repeated with a different aggregation method - for example, the geometric mean of odds instead of the Metaculus Community Prediction. In addition, I would quite like to see some kind of analysis of how much different parts of an overall aggregation approach yield. For the Metaculus Prediction in particular, how much of the performance gain is due to the performance-based weighting, and how much is due to the specific aggregation function, and how much is due to extremising?
More research (and again, more comprehensive literature) is needed to obtain a clearer picture of how different factors affect the performance of a selected team of forecasters. This could e.g. involve experimental designs that study which role factors like communication, remuneration, time spent on a particular question, subject matter expertise, etc. play. Similarly, more research would be needed to study the effect of offering cash prizes in forecast competitions. This research could help inform the way forecasting projects are designed in the future.
Next year we will likely have more data on the performance of paid Metaculus Pro Forecasters vs. the Metaculus Community in the Forecasting Our World in Data tournament. Analysing that data should give us some insight into the real-life performance of a selected group of accomplished forecasters.
Imagine a scenario in which the true probability for an event was 0.6. All forecasters are somewhat terrible, but they manage to be terrible in a way that the average of all forecasts is exactly 0.6 (e.g. some predict 0.3, others 0.9 etc.). If you know add a bunch of very good forecasters that predict between 0.58 and 0.62 that still doesn't improve your average, even though those forecasters individually were clearly better.
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...


Can you quantify how much work recency weighting is doing here? I could imagine it explaining all (or even more than all) of the effect (e.g. if many "best" forecasters have stale predictions relative to the community prediction often).
Not sure how to quantify that (open for ideas). But intuitively I agree with you and would suspect it's at least a sizable part
Suggestion: pre-commit to a ranking method for forecasters. Chuck out questions which go to <5%/>95% within a week. Take the pairs (question, time) with 10n+ updates within the last m days for some n,m, and no overlap (for questions with overlap pick the time which maximises number of predictions). Take the n best forecasters per your ranking method in the sample and compare them to the full sample and the "without them" sample.