Comments
More from the author
Curated and popular this week
61
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...

Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...

I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...
Recent opportunities to take action

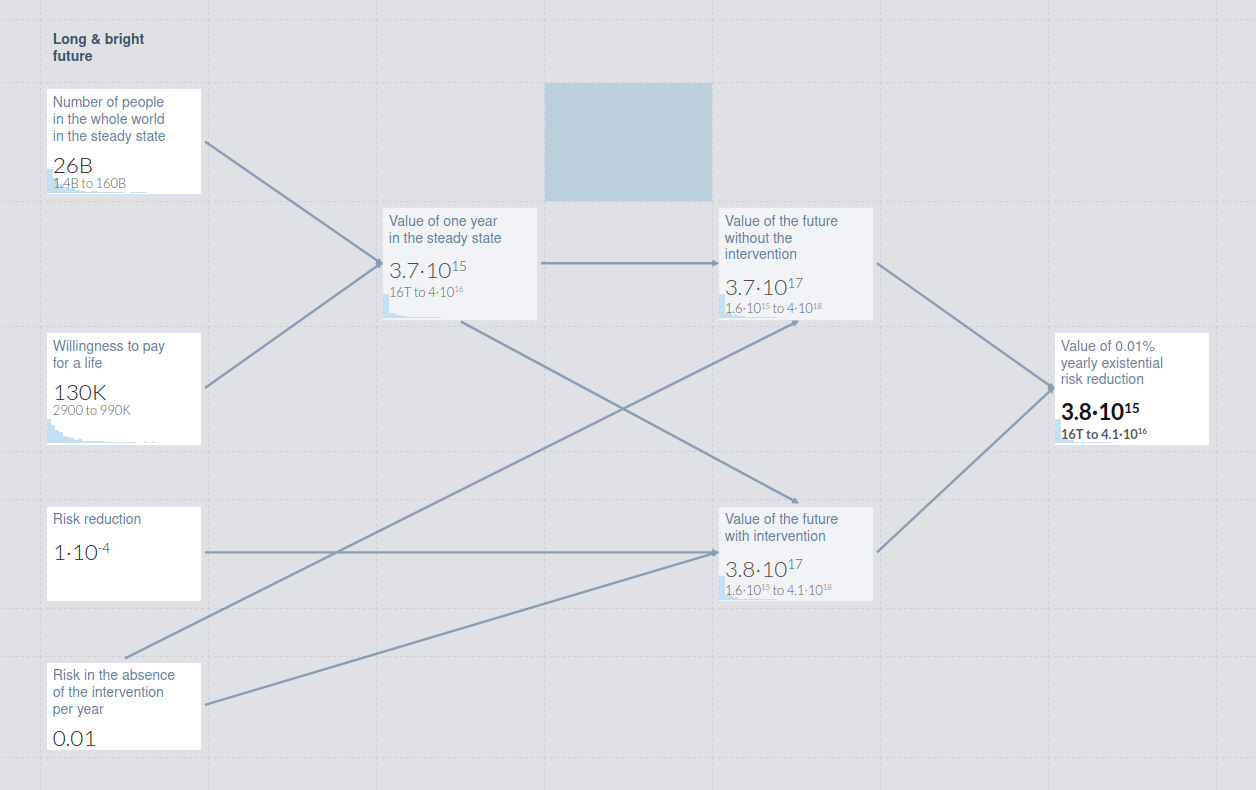
Here are my very fragile thoughts as of 2021/11/27:
Speaking for myself, I feel pretty bullish and comfortable saying that we should fund interventions that we have resilient estimates of reducing x-risk ~0.01% at a cost of ~$100M.
I think for time-sensitive grants of an otherwise similar nature, I'd also lean optimistic about grants costing ~$300M/0.01% of xrisk, but if it's not time-sensitive I'd like to see more estimates and research done first.
For work where we currently estimate ~$1B/0.01% of xrisk, I'd weakly lean against funding them right now, but think research and seed funding into those interventions is warranted, both for value of information reasons and also because we may have reasonable probability on more money flowing into the movement in the future, suggesting we can lower the bar for future funding. I especially believe this for interventions that are relatively clear-cut and the arguments are simple, or otherwise may be especially attractive to non(currently)-EA billionaires and governments, as we may have future access to non-aligned (or semi-aligned) sources of funding, with either additional research or early-stage infrastructure work that can then leverage more funding.
For work where we currently estimate >>$10B/0.01% of xrisk, I'd be against funding them and weakly lean against deep research into them, with important caveats including a) value of information and b) extremely high scale and/or clarity. For example, the "100T guaranteed plan to solve AI risk" seems like a research project worth doing and laying the foundations of, but not a project worth us directly funding, and I'd be bearish on EA researchers spending significant time on doing research for interventions at similar levels of cost-effectiveness for significantly smaller risks.
One update that has probably not propagated enough for me is a (fairly recent, to me) belief that longtermist EA has a much higher stock of human capital than financial capital. To the extent this is true, we may expect a lot of money to flow in in the future. So as long as we're not institutionally liquidity constrained, we/I may be systematically underestimating how many $s we should be willing to trade off against existential risk.
*How* are you getting these numbers? At this point, I think I'm more interested in the methodologies of how to arrive at an estimate than about the estimates themselves
For the top number, I'm aware of at least one intervention* where people's ideas of whether it's a good idea to fund moved from "no" to "yes" in the last few years, without (AFAIK) particularly important new empirical or conceptual information. So I did a backwards extrapolation from that. For the next numbers, I a) considered that maybe I'm biased in favor of this intervention, so I'm rosier on the xrisk reduced here than others (cf optimizer's curse), and grantmakers probably have lower numbers on xrisks reduced and b) considered my own conception of how much capital may come to longtermist EA in the future, and decided that I'm probably rosier on our capital than these implied numbers will entail. Put another way, I started with a conservative-ish estimate, then updated down on how much xrisk we can realistically buy off for $X at current margins (which increases $/xrisk), then updated upwards on how much $s we can have access to (which also increases $/xrisk).
My friend started with all the funds available in EA, divided by the estimated remaining xrisk, and then applied some discount factor for marginal vs average interventions, and got some similar if slightly smaller numbers.
*apologies for the vagueness
You said 'I'm aware of at least one intervention* where people's ideas of whether it's a good idea to fund moved from "no" to "yes" in the last few years'. Would you be able to provide the source of this please?
No, sorry!
Do you similarly think we should fund interventions that we have resilient estimates of reducing x-risk ~0.00001% at a cost of ~$100,000? (i.e. the same cost-effectiveness)
Yep, though I think "resilient" is doing a lot of the work. In particular:
The most concrete thing I can think of is in asteroid risk, like if we take Ord's estimates of 1/1,000,000 risk this century literally, and we identify a cheap intervention that we think can a) avert 10% of asteroid risks, b) costs only $100,000 , c) can be implemented by a non-EA with relatively little oversight, and d) has negligible downside risks, then I'd consider this a pretty good deal.
An LTFF grantmaker I informally talked to gave similar numbers
Could you say whether this was Habryka or not? (Since Habryka has now given an answer in a separate comment here, and it seems a bit good to know whether those are the same data point twice or not. Habryka's number seems a factor of 3-10 off of yours, but I'd call that "similar" in this context.)
(It was not)
To what degree do you think the x-risk research community (of ~~100 people) collectively decreases x-risk? If I knew this, then you would have roughly estimated the value of an average x-risk researcher.
To make that question more precise, we're trying to estimate xrisk_{counterfactual world without those people} - xrisk_{our world}, with xrisk_{our world}~1/6 if we stick to The Precipice's estimate.
Let's assume that the x-risk research community completely vanishes right now (including the past outputs, and all the research it would have created). It's hard to quantify, but I would personally be at least twice as worried about AI risk that I am right now (I am unsure about how much it would affect nuclear/climate change/natural disasters/engineered pandemics risk and other risks).
Now, how much of the "community" was actually funded by "EA $"? How much of those researchers would not be capable of the same level of output without the funding we currently have? How much of the x-risk reduction is actually done by our impact in the past (e.g. new sub-fields of x-risk research being created, where progress is now (indirectly) being made by people outside of the x-risk community) vs. researcher hours today? What fraction of those researchers would still be working on x-risk on the side even if their work wasn't fully funded by "EA $"?
EDIT 2022/09/21: The 100M-1B estimates are relatively off-the-cuff and very not robust, I think there are good arguments to go higher or lower. I think the numbers aren't crazy, partially because others independently come to similar numbers (but some people I respect have different numbers). I don't think it's crazy to make decisions/defer roughly based on these numbers given limited time and attention. However, I'm worried about having too much secondary literature/large decisions based on my numbers, since it will likely result in information cascades. My current tentative guess as of 2022/09/21 is that there are more reasons to go higher (think averting x-risk is more expensive) than lower. However, overspending on marginal interventions is more -EV than underspending, which pushes us to bias towards conservatism.
I assume those estimates are for current margins? So if I were considering whether to do earning to give, I should use lower estimates for how much risk reduction my money could buy, given that EA has billions to be spent already and due to diminishing returns your estimates would look much worse after those had been spent?
Yes it's about marginal willingness to spend, not an assessment of absolute impact so far.