Comments
Forecasting Newsletter: April 2022



You can sign up for this newsletter on substack, or browse past newsletters here.
At the high level, various new startups have been exploring different parts of the forecasting and prediction market space. Most recently, Manifold Markets allows anyone to easily instantly create a market, which comes at the cost of these markets having to use play money. And Polymarket or Insight Prediction have set up real-money prediction markets on some topics of real interest.
Our hope is that with time, a new project might stumble upon a winning combination, one that is able to produce large amounts of value by allowing people to pay for more accurate probabilities, even when these are unflattering.
Putting on my Scott Alexander hat, prediction markets or forecasting systems have the potential to be a powerful asymmetric weapon (a): a sword of good that systematically favours the side which seeks the truth. A channel which is able to transmit accurate information even when the evil forces of Moloch (a) would seek to prevent this.
In Linux circles, there is the meme of "the year of the Linux desktop": a magical year in which people realize that Windows adds little value, and that Linux is based. A year in which people would together switch to Linux (a) and sing John Lennon. Instead, Linux, much like prediction markets, remains a powerful yet obscure tool which only a few cognoscenti can wield. So although I may wax poetically about the potential of prediction markets, "the year of the prediction market" has yet to come, much like "the year of the Linux desktop".
To get there, there needs to be investment in accessibility and popularization. And so I am happy to see things like the Forecasting Wiki (a), simpler apps (a), popular writers introducing prediction markets to their audiences, or platforms experimenting with simplifying some of the complexity of prediction markets, or with combining the ideas behind prediction markets in new ways and exploring the space of prediction market-like things. It might also be wise for prediction markets to take a more confrontational stance (a), by challenging powerful people who spout bullshit.
The CDC has a new (a), $200M center (a) for pandemic forecasting.
When Walensky tapped outside experts to head the new outfit, the move was widely viewed as an acknowledgment of long-standing and systemic failures regarding surveillance, data collection and preparedness that were put into high relief by the pandemic.
Scientists will also look at who is infecting whom, how well vaccines protect against infection and severe illness, and how that depends on the vaccine, variants and the time since vaccination, said Marc Lipsitch, an epidemiologist and the center’s science director.
The center will be based in D.C. and will eventually have about 100 staff members, including some at CDC’s Atlanta headquarters. It will report to Walensky.
This is, broadly speaking, good. But it also seems like too little, too late. It seems suboptimal to have this center report to the CDC director, given that the CDC's leadership wasn't particularly shining during the pandemic. And the center is playing defence against the last black swan, whereas I would prefer to see measures which could defend against unknown unknowns, such as this one (a).
I recently stumbled upon a few prediction markets previously not on my radar: TradeX (a) and Better Opinions (a). In India, gambling games are categorized (a) either as games of skill or games of chance, with games of skill being much less regulated.
And these new Indian platforms are making a calculated bet that they will be categorized as games of skill. It is also possible that there was a recent ruling to that effect, though I couldn't find it after some brief Googling. Given India's 1B+ population, this could be a big deal. h/t Vishal Maini.
Tetlock's forecasting team is recruiting for a "Hybrid forecasting-persuasion tournament" on x-risk topics (announcement here (a), more details here (a)). I think that the impact pathway of participating in this looks like: better forecasters produce better probabilities in the tournament, which are then cited in reports by the UN and other large organizations, for which having a legible source to cite when justifying why they may work on preventing existential risks.
That said, I am not a fan of the reward scheme, which resembles a Keynesian beauty contest, which means that the forecasters are not incentivized to directly predict reality, but instead to predict the opinion which will be mainstream among forecasters. In any case, the deadline for applying is May 13th, and rewards are $2k to $10k for at least 40 hours over three months, so a minimum compensation of $50/hour.
Kalshi matches PredictIt's 538's approval markets. This seems like a "take more of the pie" action instead of a "make the pie bigger" action, which might be informative about latent variables.
According to Manifold Markets' own estimations (a), the platform will likely create some sort of significant social drama in 2022. They are also bestowing their play money with some monetary value by allowing users to donate their Manifold dollars to a selection of charities (a).
Manifold itself is rapidly increasing their team. It seems that they are aiming to make forecasting simple and streamlined, so that many people can use it and benefit from it. This is an uneasy combination with their current userbase, which is made out of power users. As a power move, they made their webpage open-source (a).
Basil Halperin writes Monetary policy in 2050: evidence from Metaculus (a).
Polymarket asked the UMA DAO (a) for $2-3M worth of funds to continue subsidizing their rewards programme. The request will be denied.
INFER is hosting a discussion tomorrow under the ominous headline “Reasserting U.S. Leadership in Microelectronics” (a).
Good Judgment Open adds a few new features (a), chiefly, a neat slider for visualizing probabilities.
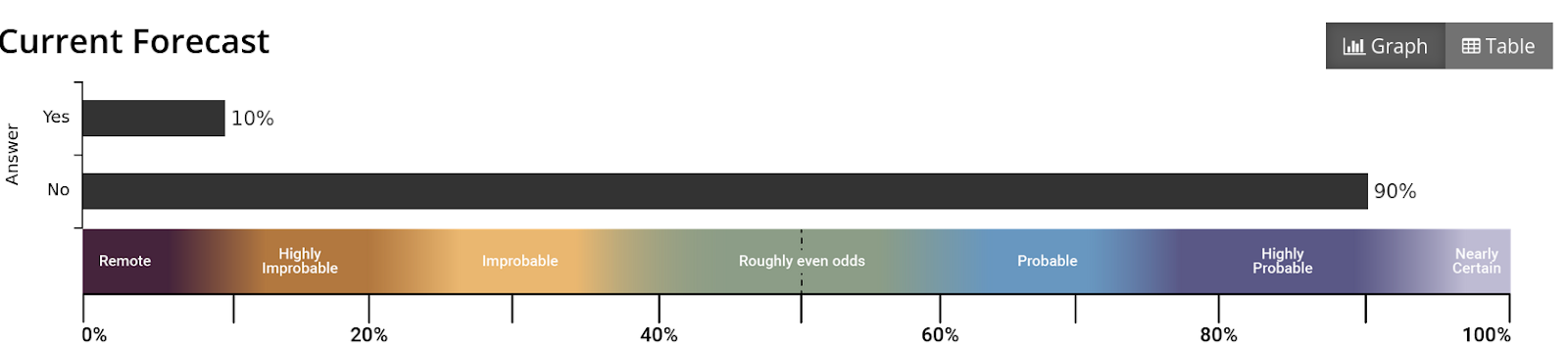
PredictIt bettor refuses to pay (a) $15k worth of over-the-counter bets.
In the previous issue of this newsletter, I mentioned that Polymarket was incentivizing wash-trading. Later on, on Twitter, I mentioned that this meant that their current volume levels "mean nothing".

Although I do still think that Polymarket is incentivizing wash-trading, the claim that Polymarket's volume numbers "mean nothing" was an exaggeration: Polymarket would in all likelihood still see significant volume in the absence of their trading incentives. But it does mean that comparing Polymarket's volume to that of, for instance, Kalshi, is now nontrivial.
Robin Hanson considers the pressures shaping the accuracy of authorities (a):
The best estimates of a maximally accurate source would be very frequently updated and follow a random walk, which implies a large amount of backtracking. And authoritative sources like WHO are often said to be our most accurate sources. Even so, such sources do not tend to act this way. They instead update their estimates rarely, and are especially reluctant to issue estimates that seem to backtrack. Why?
Hanson also comes back to Intellectual Prestige Futures (a). The idea is to predict what people really want according to Hanson: prestige, instead of "impact" or some such.
Jan Kirchner (a) writes a popularization of "Infrabayesianism" (a), a theory of how to make pseudo-Bayesian updates in the presence of intelligent adversaries. I appreciated the effort, but I thought this could have been much better. If anyone writes a better introduction I'll give them a forecasting microgrant proportionate to my estimate of its quality.
Andrew Gelman (a) answers to someone seeking to do a PhD in Bayesian clinical trials after a lifetime of living in a state of frequentist sin, and reports on a cool Bayesian framework for interpreting fings from impact evaluations (a)
Zvi Mowshowitz (a) writes about the probability he assigns to nuclear war, following up on my forecasting group's forecasts and its criticisms by a nuclear expert. I really appreciated the detail and the good faith.
The European Centre for Medium-Range Weather Forecasts scores its performance in 2021 (a).
Justin Shovelain writes about Goodhart's Law Causal Diagrams (a).
Eric Neyman grades his 2021 predictions (a)
The Boltzmann Policy Distribution: Accounting for Systematic Suboptimality in Human Models (a) proposes a neat Bayesian way of modelling humans: Assume that humans have a probability p of choosing a policy P proportional to exp(ExpectedValue(P)). Then update on human actions. This is obviously very hard to do, because one has to iterate through all policies, but the authors use some neural network witchcraft that I don't understand to make this more feasible. The authors then use this kind of Bayesian model of human irrationality to predict human actions in a simple cooperative game. One could also use it to predict values given actions.
Overall, their method performs worse than current machine techniques. It is also unclear whether it might be generalizable to more complex setups, in which approximating a large policy space would be even more difficult.
Aggregating human judgment probabilistic predictions of COVID-19 transmission, burden, and preventative measures (a). The authors compare Good Judgment Open and Metaculus data, and find that they do "similarly well" to computational models.
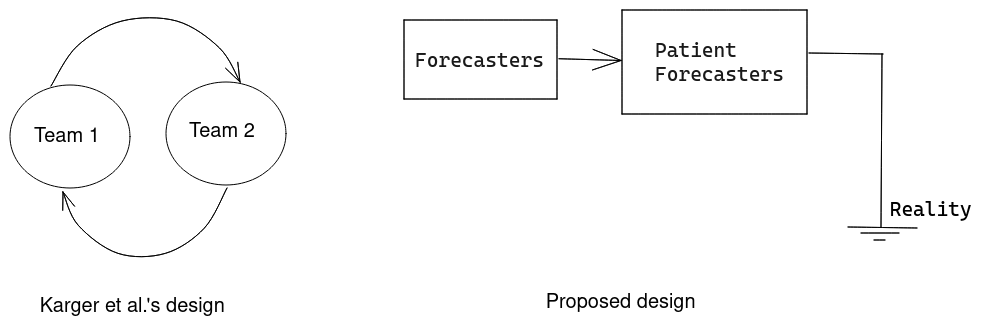
I released three papers on scoring rules (a). The motivation behind them is my frustration with scoring rules as used in current forecasting platforms. I was also frustrated with the "reciprocal scoring" method recently proposed in Karger et al (a) and now used in Tetlock's Hybrid Forecasting-Persuasion tournament (see above). These new scoring rules incentivize collaboration, and although not quite ready for production (a), I hope they could eventually provide a better incentive scheme for the forecasting ecosystem.
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman (a), and Alexey Guzey (a).
In other words, I'm right. I'm always right, but sometimes I'm more right than other times. And dammit, [this time], I'm really really Right(tm).
I still like my summary, if you haven't seen that yet. (Tbc I'm not looking for a microgrant, just informing you of the existence of the summary.)
Cheers!