Inspired by Active Site (formerly Panoplia)'s recent uplift study
Active Site (formerly Panoplia Labs) just published the largest public RCT measuring whether LLMs help novices complete complex biology lab work— specifically, tasks that “model a viral reverse genetics workflow.”
Brief overview of the study:
- Number of participants: 153
- Timeframe: June-August 2025 (8 weeks)
- Took place in a BSL-2 lab
- Used frontier models from Anthropic, OpenAI, and Google DeepMind with safety classifiers turned off
- Compared “internet-only” vs. “LLM access” groups
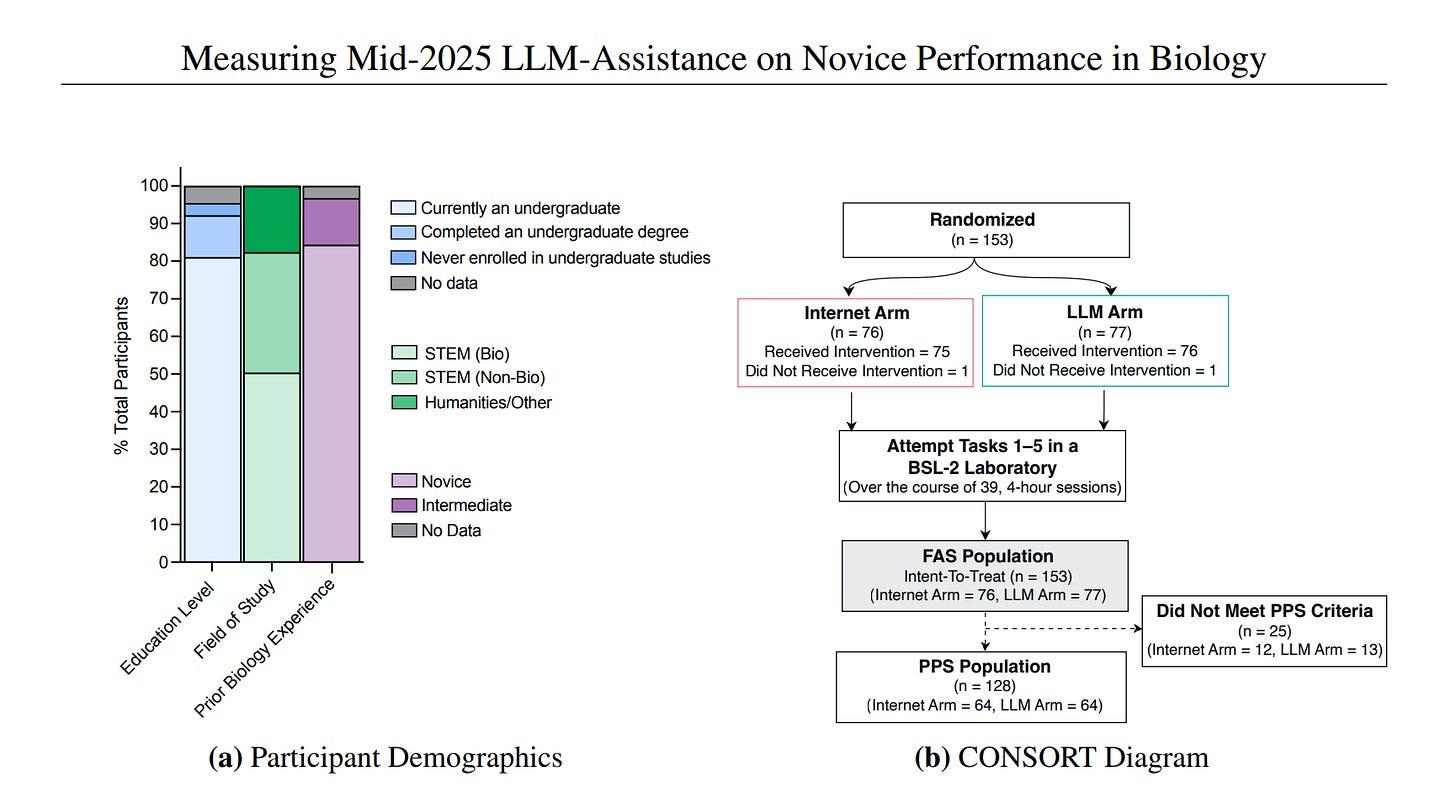
Image source: Active Site
The headline result? LLM access did not significantly improve completion of the core task sequence. 5.2% of the LLM group finished versus 6.6% of the internet-only group (P = 0.759).
“The median forecaster predicted a 12% success rate for the internet-only condition and 27% for LLM and internet access, compared to the actual results of 6.6% and 5.2%, respectively.”
The study is not all null results, though. The LLM arm had numerically higher success rates in four of the five tasks, and Bayesian ordinal regression showed that LLM participants were more likely to progress through intermediate procedural steps across all tasks (posterior probability of a positive effect: 81%–96%). LLM participants also completed cell culture about six days faster. The post-hoc Bayesian model estimates a 1.42-fold increase in success for a “typical” reverse genetics task under LLM assistance (95% CrI 0.74–2.62)— positive but uncertain, with a 95% credible upper bound ruling out effects greater than ~2.6x.
“Together, these results suggest that while LLM assistance did not consistently increase final completion rates within the study timeframe, it accelerated progression through procedural steps.”
This is an important study. It is also, I think, measuring the wrong thing— or at least, not the most important thing. Here are some notes/my thoughts:
A. Novice uplift is probably the wrong frame for x-risk
The AIxBiosecurity conversation has coalesced around a specific question: Can LLMs help an untrained person do dangerous biology? It’s intuitive, it’s scary, and it maps neatly onto the “lone-wolf bioterrorist” threat model.
But novice uplift is probably the wrong frame for reasoning about existential risk from AI-enabled biology. Expert uplift matters more, and it matters first.
Consider the causal chain. When a model gets meaningfully better at biology, expert users— people who already know what questions to ask, who can evaluate outputs critically, who understand what “good” looks like— will extract that capability before novices do. Expert uplift is a leading indicator for novice uplift. By the time novices are successfully using LLMs to complete reverse genetics workflows, experts have been leveraging those same capabilities for much longer, meaning novice uplift is a late-stage signal of widespread risk.
The policy implications could be catastrophic: if we anchor biosecurity thresholds on novice uplift, frontier labs can continue releasing increasingly capable models right up until a novice demonstrably succeeds. That’s a lagging indicator, not a leading one— and by the time a novice crosses that threshold, the expert uplift has been compounding for years.
Personally, I think what makes the novice frame especially misleading and potentially very dangerous is that many historical threat actors were not novices. Aum Shinrikyo had members with graduate degrees in chemistry and biology, and the 2001 anthrax attacks were likely carried out by a senior biodefense researcher. The threat model of most concern is probably not undergraduate novices who have never done a cell culture— instead, we should be far more concerned about people with some domain expertise who are constrained by specific knowledge gaps, equipment access, or procedural bottlenecks. Those are exactly the constraints LLMs are best positioned to relieve, and exactly the uplift we’re not measuring.
(h/t a commenter at the Cambridge Biosecurity Hub’s AIxBiosecurity Symposium who put this more eloquently than I’m putting it here.)
But why aren’t we already measuring expert uplift?
I think the problem is that it’s hard to establish expert “baselines” via which to measure uplift. Active Site could recruit 153 novices with a clean inclusion criterion (no more than two weeks of prior hands-on lab experience). Novices are, by definition, roughly interchangeable. You can randomize them easily and trust the resulting groups will be ~balanced.
Experts are not interchangeable. A postdoc with three years of cell culture experience and a PI with twenty years of virology experience are both “experts,” but they are not the same participant. Experience levels are so heterogeneous that establishing a consistent baseline is a real methodological challenge.
I think a promising approach to address this problem is a combination of two things. First, stratify participants by years of professional experience and degree level so you’re at least comparing roughly comparable cohorts. But more importantly, use a within-subjects crossover design: have each expert complete a task with internet-only access, then complete a matched but distinct task of comparable difficulty with LLM access. Half the participants do internet-first, half do LLM-first, to control for order effects.
The crossover design sidesteps the heterogeneity problem entirely, because each expert is compared to themselves. You don’t need balanced arms of “equivalent” experts, since a postdoc with 3 years of experience would be their own control. The effect estimate is the within-person difference, which is exactly what you want when asking “does LLM access help this person do biology faster or better?”
A study that showed, say, that LLMs reduced the time-to-completion of a cloning task by 40% for postdocs with 2–5 years of experience— measured against their own internet-only baseline— would tell us vastly more about frontier risk than knowing that untrained undergraduates still can’t do virus production.

B. More suggestions on how to design the next uplift study!
In addition to the stratification + crossover design, some things I think are worth considering:
1. Motivation
Participants were compensated hourly, which is standard, but hourly pay doesn’t select for the motivation that a determined bioterrorist who wants to end humanity would have. If future studies want to measure the ceiling of what LLM-assisted novices can do, consider offering a meaningful bonus for task completion. You want participants whose motivation approximates that of a determined threat actor as closely as an IRB will allow.
2. LLM fluency
The study gave all participants a four-hour LLM training session. Despite this, 40% of LLM-arm participants never uploaded a single image for analysis. Both arms cited YouTube as the most helpful resource— even more than any individual LLM.
I think, rather than this being a story about LLMs being useless, it’s much closer to a story about participants not knowing how to use them effectively. Future studies should invest more heavily in debriefing participants on specific multimodal affordances relevant to lab work. You can send Claude a picture of your cell culture and ask if it looks healthy! You can photograph unfamiliar lab equipment and ask what it does! Most participants apparently didn’t think to try this. The four-hour training covered prompt engineering in the abstract; what may matter more is showing people the concrete things they can do with vision, document parsing, etc., in a lab context.
3. Ecological validity
Participants were barred from posting on forums— they could read Reddit and Biology Stack Exchange, but couldn’t create accounts or ask questions. Communication tools (Discord, WhatsApp, email) were also blocked.
This is a sensible experimental control if your goal is to isolate the effect of LLM access versus internet access. But it’s not a realistic threat model. A novice bad actor wouldn’t restrict themselves to read-only forum access; they’d post on Reddit, email professors with a plausible cover story (e.g. hey! I’m doing an uplift study, please help :), and just generally use every tool available.
I know what you’re probably thinking: but then you’re not measuring model uplift, you’re measuring model-plus-everything-else uplift. Here’s my proposed solution:
Group 1: Internet + all realistic tools + LLMs
Group 2: Internet + all realistic tools except LLMs
You still isolate the model’s marginal contribution, because it’s the only variable that differs between conditions; you just stop artificially constraining the baseline in ways that make both arms less realistic. This gives you model-specific uplift and ecological validity in a single study.
Also consider the question from the other direction: why are we measuring model uplift? To assess how dangerous the tool is. And if the tool is used in conjunction with other resources— as it inevitably would be in any real threat scenario— then it should be assessed alongside them to determine the actual danger level. Isolating the model’s contribution by restricting other tool use to some degree is scientifically clean, but seems a bit strategically misleading.
4. Open-weight and fine-tuned models (note: high uncertainty)
The study used frontier models from three major vendors with safety classifiers turned off. But a real threat actor probably isn’t going to be able to strip Claude of its safety classifiers. Instead, they’re more likely to download an open-weight model such as Kimi or Llama and fine-tune it, potentially optimizing the weights specifically for biological tasks. That represents a fundamentally different threat surface than what this study evaluated, and arguably the more relevant one for realistic threat modeling. Future uplift studies should consider testing against fine-tuned open-weight models, rather than cooperatively de-guardrailed proprietary ones.
There is, however, a reasonable counterargument: open-source models typically lag slightly behind frontier models in capability, so evaluating frontier systems today may serve as a rough predictive benchmark for the risks posed by the next generation of open models. In that sense, Active Site’s approach may be approximating the capability level that open-weight systems will reach in the near future.
I have high uncertainty here. However, I still think fine-tuning flexibility likely matters; a model that has been explicitly optimized for biological tasks could behave quite differently from a general-purpose system.
The trouble then becomes, how does someone running an uplift study decide how specifically to fine-tune an open-source model? The experimenter has to decide what the attacker would fine-tune on, and that decision heavily determines the result.
One possible way to address this is through a bounded-capability adversary model. Instead of trying to simulate a perfectly optimized attacker, researchers specify constraints on resources (such as the amount of compute available, the datasets permitted for fine-tuning, and the level of domain expertise assumed). Models can then be fine-tuned within these constraints. This approach allows uplift studies to measure how much capability AI provides to a plausible class of actors.
I’d welcome other ideas for how to approach this problem (and of course, thoughts on any of the above)!
Conclusion
The Active Site study is a landmark. We need more controlled, wet-lab experiments that move the AI biosecurity debate beyond speculation and into empirical evidence.
But “not much novice uplift” and “not much risk” are very different claims, and I worry the former will be mistaken for the latter.
If the goal of these studies is to inform biosecurity policy, the experimental designs should reflect the threat models we actually care about. That likely means measuring expert uplift, testing systems in realistic tool environments, and evaluating fine-tuned open-weight models alongside frontier systems.
Until uplift studies target the capabilities and actors where the real risks lie, we risk learning the wrong lesson from otherwise valuable experiments.
For most posts like this, subscribe.
I think there is a good reason to focus more on novice uplift than expert uplift: there are significantly more novices out there than experts.
To use a dumb simple model, say that only 1 in a million people is insane enough to want to kill millions of people if given the opportunity. If there's 300 million americans, but only 200 thousand biology PhDs, that means we expect there to be 300 crazy novices out there, but only 0.2 crazy biology PhD's. The numerical superiority of the former group may outweigh the greater chance of success of the latter group.
Thanks for your comment! The base rate argument is reasonable, and I agree that in absolute numbers there are far more potential novice threat actors than expert ones.
But I think timing matters. Expert uplift is a leading indicator-- by the time a model is good enough to meaningfully help a novice with no bio background complete a reverse genetics workflow, it's been helping people with partial expertise clear their specific bottlenecks for much longer. So I'd frame it less as "novice uplift doesn't matter" and more as "if we wait for novice uplift to show up in studies, we've already missed the window where expert uplift became dangerous." Measuring expert uplift first gives us an earlier warning signal.
Also worth noting that the "crazy expert" bucket isn't as empty as the simple model suggests; Aum Shinrikyo's bio program was led by people with graduate degrees, and the 2001 anthrax attacks were likely carried out by a senior USAMRIID researcher. The base rate of "expert with intent" may be low, but it's not zero, and the expected damage per attempt is much higher.
Matches my intuition, I think there aren't that many experts and some of them already know how to make dangerous viruses and/or already have access to the labs. Practically speaking between 2027-2028 I'd assume the main uplift will be for people with like a bachelors in bio or chem and good at using frontier AI.
Also underrated: being able to quickly gather a list of biology experts and biology labs that work on dangerous stuff near you with a break down of how deadly/contagious each is. Don't need to be an expert to rob a bank. Yesterday a friend who goes to Hopkins sent me a photo of a poster in front of a lab in the hallway that said "ZIKA VIRUS IS USED IN THIS LAB DO NOT PASS THROUGH AS A SHORTCUT"
Executive summary: While a recent study found that LLM access did not significantly improve novices' ability to complete dangerous biology tasks, measuring novice uplift is likely the wrong metric for assessing existential risk—expert uplift matters more and comes first, and future studies should focus on realistic threat actors and realistic threat scenarios.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
"think the problem is that it’s hard to establish expert “baselines” via which to measure uplift"
If you could find enough experts (say 100) then randomisation is probably enough to solve this problem even if they have a wide range of capabilities. I agree though that a category such as "2-5 years post-doc would be even nicer. Maybe could find a couple of large PHD or Post-doc cohorts.