On January 1, 2030, there will be no artificial general intelligence (AGI) and AGI will still not be imminent.
A few reasons why I think this:
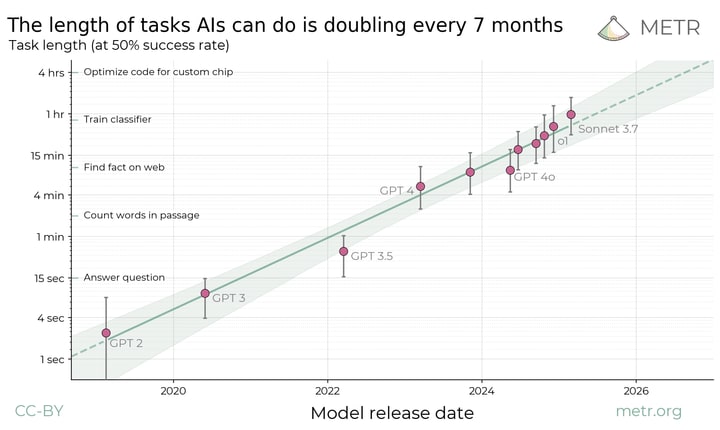
-If you look at easy benchmarks like ARC-AGI and ARC-AGI-2 that are easy for humans to solve and intentionally designed to be a low bar for AI to clear, the weaknesses of frontier AI models are starkly revealed.[1]
-Casual, everyday use of large language models (LLMs) reveals major errors on simple thinking tasks, such as not understanding that an event that took place in 2025 could not have caused an event that took place in 2024.
-Progress does not seem like a fast exponential trend, faster than Moore's law and laying the groundwork for an intelligence explosion. Progress seems actually pretty slow and incremental, with a moderate improvement from GPT-3.5 to GPT-4, and another moderate improvement from GPT-4 to o3-mini. The decline in the costs of running the models or the increase in the compute used to be train models is probably happening faster than Moore's law, but not the actual intelligence of the models.[2]
-Most AI experts and most superforecasters give much more conservative predictions when surveyed about AGI, closer to 50 or 100 years than 5 or 10 years.[3]
-Most AI experts are skeptical that scaling up LLMs could lead to AGI.[4]
-It seems like there are deep, fundamental scientific discoveries and breakthroughs that would need to be made for building AGI to become possible. There is no evidence we're on the cusp of those happening and it seems like they could easily take many decades.
-Some of the well-known people who are making aggressive predictions about the timeline of AGI now have also made aggressive predictions about the timeline of AGI in the past that were wrong.[5]
-The stock market doesn't think AGI is coming in 5 years.[6]
-There has been little if any clear, observable effect of AI on economic productivity or the productivity of individual firms.[7]
-AI can't yet replace human translators or do other jobs that it seems best-positioned to overtake.
-Progress on AI robotics problems, such as fully autonomous driving, has been dismal. (However, autonomous driving companies have good PR and marketing right up until the day they announce they're shutting down.)
-Discourse about AGI sounds way too millennialist and that's a reason for skepticism.
-The community of people most focused on keeping up the drumbeat of near-term AGI predictions seems insular, intolerant of disagreement or intellectual or social non-conformity (relative to the group's norms), and closed-off to even reasonable, relatively gentle criticism (whether or not they pay lip service to listening to criticism or perform being open-minded). It doesn't feel like a scientific community. It feels more like a niche subculture. It seems like a group of people just saying increasingly small numbers to each other (10 years, 5 years, 3 years, 2 years), hyping each other up (either with excitement or anxiety), and reinforcing each other's ideas all the time. It doesn't seem like an intellectually healthy community.
-A lot of the aforementioned points have been made before and there haven't been any good answers to them.
I'd like to thank Sam Altman, Dario Amodei, Demis Hassabis, Yann LeCun, Elon Musk, and several others who declined to be named for giving me notes on each of the sixteen drafts of this post I shared with them over the past three months. Your feedback helped me polish a rough stone of thought into a diamond of incisive criticism.[8]
Note: I edited this post on 2025-04-12 at 20:30 UTC to add some footnotes.
- ^
This video is a good introduction to these benchmarks. If you prefer to read, this blog post is another good introduction. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
- ^
I realized after thinking about it more that trying to guess whether the general intelligence of AI models has been increasing slower or faster than Moore's law from November 2022 to April 2025 is probably not a helpful exercise. I explain why in three sequential comments here, here, and here, and in that third comment, I re-write this paragraph to convey my intended meaning better. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
- ^
This article gives some examples of more conservative predictions. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
- ^
The source for this claim is this 2025 report from the Association for the Advancement of Artificial Intelligence. This comment has more details. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
- ^
I gave an example in a comment here. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
- ^
- ^
After making this post, I found this paper that looks at the productivity impact of LLMs on people working in customer support. I pull an interesting quote from the study in this comment. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
- ^
This last paragraph with my "acknowledgements" is a joke, but the rest of the post isn't a joke. (I edited this post on 2025-04-12 at 20:30 UTC to add this footnote.)
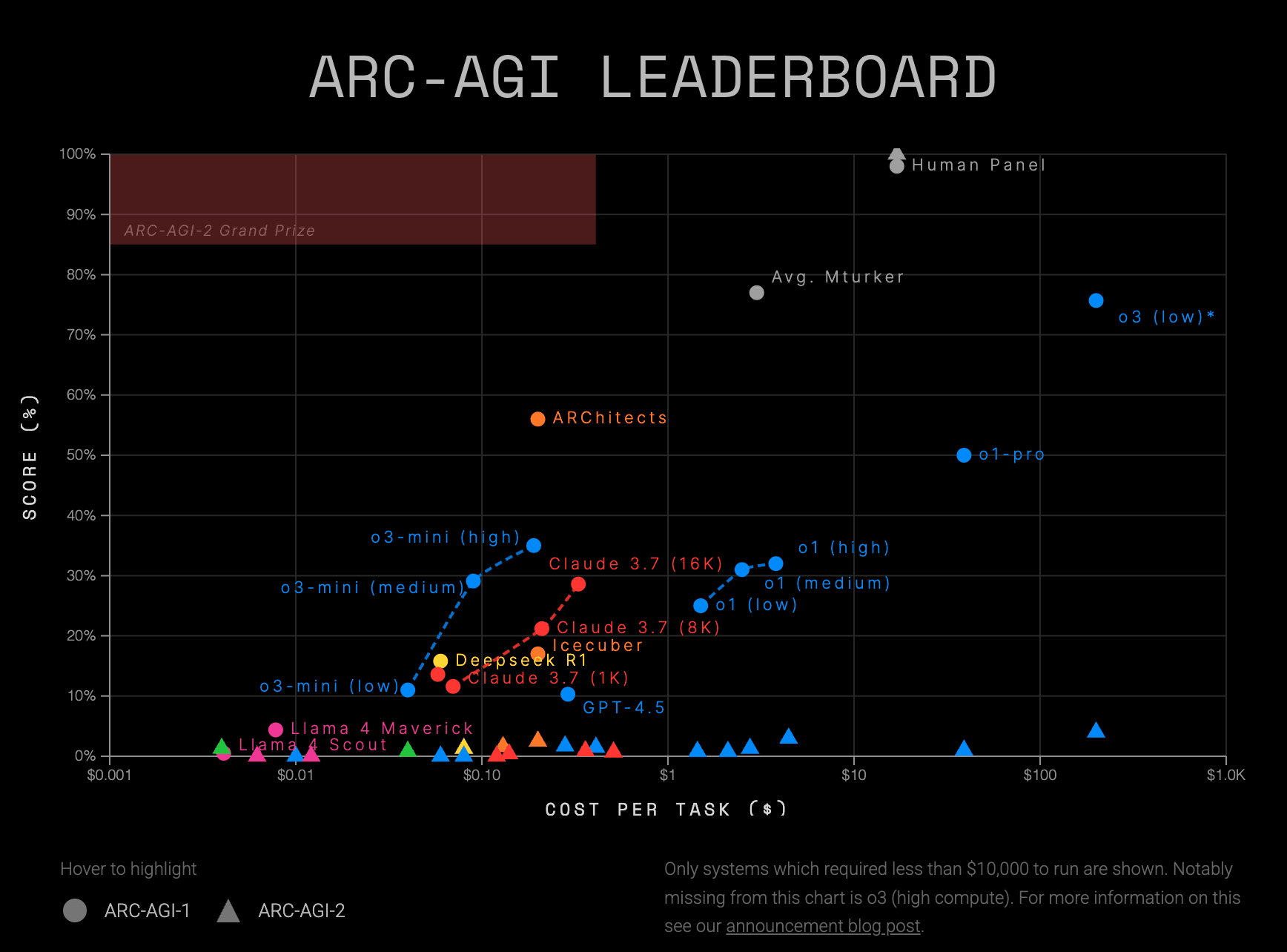
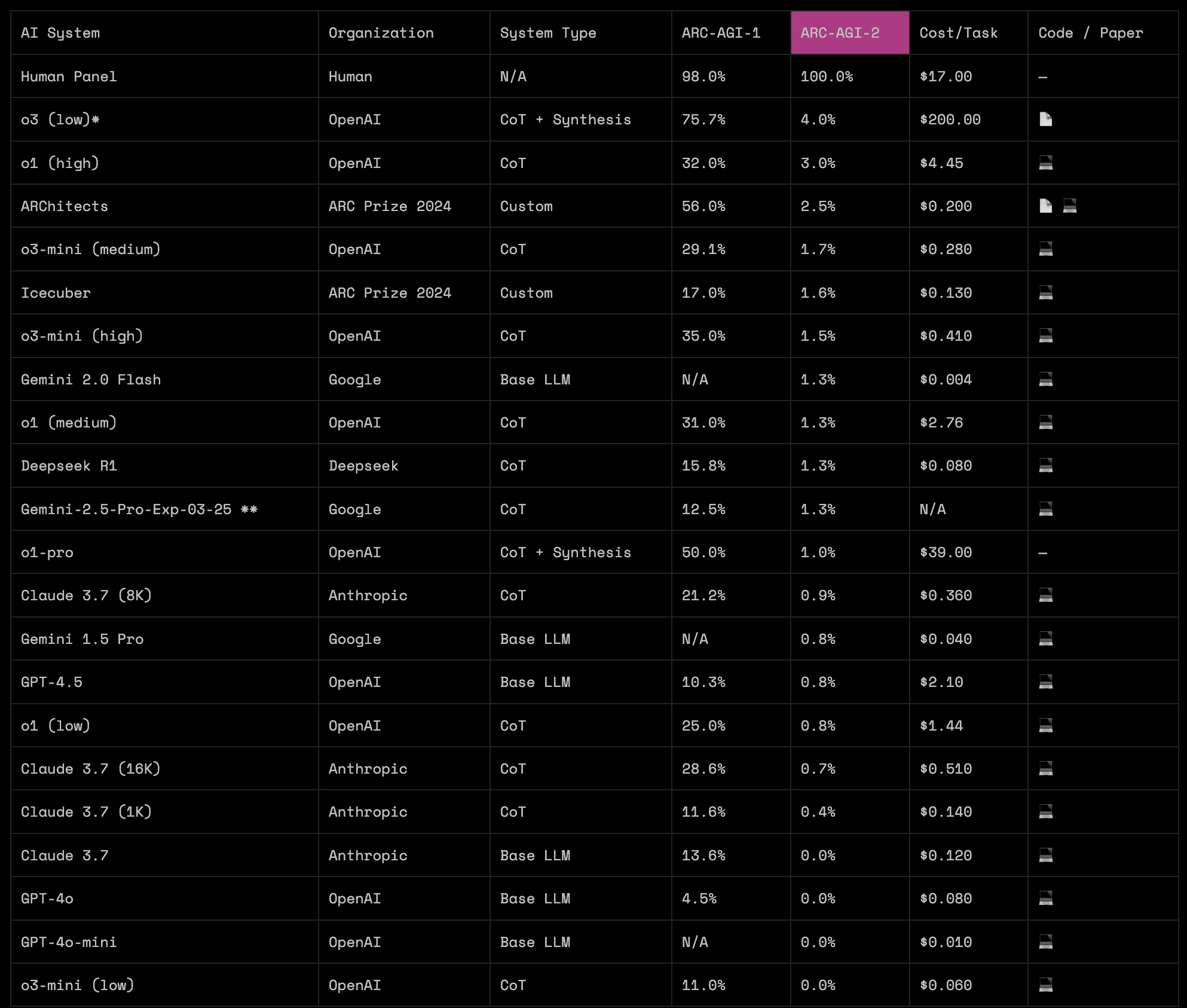
I was not being disingenuous and I find your use of the word "disingenuous" here to be unnecessarily hostile.
I was going off of the numbers in the recent blog post from March 24, 2025. The numbers I stated were accurate as of the blog post.
So that we don't miss the bigger point, I want to reiterate that ARC-AGI-2 is designed to be solved by near-term, sub-AGI AI models with some innovation on the status quo, not to stump them forever. This is François Chollet describing the previous version of the benchmark, ARC-AGI, in a post on Bluesky from January 6, 2025:
To reiterate, ARC-AGI and ARC-AGI-2 are not tests of AGI. It is a test of whether a small, incremental amount of progress toward AGI has occurred. The idea is for ARC-AGI-2 to be solved, hopefully within the next few years and not, like, ten years from now, and then to move on to ARC-AGI-3 or whatever the next benchmark will be called.
Also, ARC-AGI was not a perfectly designed benchmark (for example, Chollet said about half the tasks turned out to be flawed in a way that made them susceptible to "brute-force program search") and ARC-AGI-2 is not a perfectly designed benchmark, either.
ARC-AGI-2 is worth talking about because most, if not all, of the commonly used AI benchmarks have very little usefulness for quantifying general intelligence or quantifying AGI progress. It's the problem of bad operationalization leading to distorted conclusions, as I discussed in my previous comment.
I don't know of other attempts to benchmark general intelligence (or "fluid intelligence") or AGI progress with the same level of carefulness and thoughtfulness as ARC-AGI-2. I would love to hear if there are more benchmarks like this.
One suggestion I've read is that a benchmark should be created with a greater diversity of tasks, since all of ARC-AGI-2 tasks are part of the same "puzzle game" (my words).
There's a connection between frontier AI models' failures on a relatively simple "puzzle game" like ARC-AGI-2 and why we don't see AI models showing up in productivity statistics, real per capita GDP growth, or taking over jobs. When people try to use AI models for practical tasks in the real world, their usefulness is quite constrained.
I understand the theory that AI will have a super fast takeoff, so that even though it isn't very capable now, it will match and surpass human capabilities within 5 years. But this kind of theory is consistent with pretty much any level of AI performance in the present. People can and did make this argument before ChatGPT, before AlphaGo, even before AlexNet. Ray Kurzweil has been saying this since at least the 1990s.
It's important to have good, constrained, scientific benchmarks like ARC-AGI-2 and hopefully some people will develop another one, maybe with more task diversity. Other good "benchmarks" are economic and financial data around employment, productivity, and economic growth. Can AI actually do useful things that generate profit for users and that displace human labour?
This is a nuanced question, since there are models like AlphaFold (and AlphaFold 2 and 3) that can, at least in theory, improve scientific productivity, but which are narrow in scope and do not exhibit general intelligence or fluid intelligence. You have to frame the question carefully, in a way that actually tests what you want to test.
For example, using LLMs as online support chatbots, where humans are already usually following scripts and flow charts, and for which conventional "Software 1.0" was largely already adequate, is somewhat cool and impressive, but doesn't feel like a good test of general intelligence. A much better sign of AGI progress would be if LLM-based models were able to replace human labour in multiple sorts of jobs where it is impossible to provide precise, step-by-step written instructions.
To frame the question properly would require thought, time, and research.