Thanks for publishing this + your code, I found this approach interesting :) and in general I am excited at people trying different approaches to impact measurement within field building.
I had some model qs (fair if you don't get around to these given that it's been a while since publication):
We define a QARY as:
A year of research labor (40 hours * 50 weeks),
Conducted by a research scientist (other researcher types will be inflated or deflated),
Of average ability relative to the ML research community (other cohorts will be inflated or deflated),
Working on a research avenue as relevant as adversarial robustness (alternative research avenues will be inflated or deflated),
[...]
I feel confused by the mechanics of especially adjustments 2-4:
On 2: I think you're estimating these adjustments based on researcher type — what is this based on?
Here, scientists, professors, engineers, and PhD students are assigned ‘scientist-equivalence’ of 1, 10, 0.1, and 0.1 respectively.
On 3: I feel a bit lost at how you're estimating average ability differences — how did you come up with these numbers?
Given the number of pre-PhD participants each program enrolls, Atlas participants have a mean ability of ~1.1x, Student Group and Undergraduate Stipends ~1x, and MLSS ~0.9x. Student Group PhD students have mean ability ~1.5x.
On 4:
Am I right that this is the place where you adjust for improvements in research agendas (i.e. maybe some people shift from less -> more useful agendas as per CAIS's opinion, but CAIS still considers their former agenda as useful)?
Is that why Atlas gets such a big boost here, because you think it's more likely that people who go on to do useful AI work via Atlas wouldn't have done any useful AI work but for Atlas?
I feel confused explicitly how to parse what you're saying here re: which programs are leading to the biggest improvements in research agendas, and why.
The shaded area indicates research avenue relevance for the average participant with (solid line) and without (dashed line) the program. Note that, after finishing their PhD, some pre-PhD students shift away from high-relevance research avenues, represented as vertical drops in the plot.
In general, I'd find it easier to work with this model if I understood better, for each of your core results, which critical inputs were based on CAIS's inside views v.s. evidence gathered by the program (feedback surveys, etc.) v.s. something else :)
I'd be interested to know whether CAIS has changed its field building portfolio based on these results / still relies on this approach!
Pretty ambitious, thanks for attempting to quantify this!
Having only quickly skimmed this and not looked into your code (so could be my fault), I find myself a bit confused about the baselines: funding a single research scientist (I'm assuming this means at a lab?) or Ph.D. student for even 5 years seems to unclearly equivalent to 87 or 8 adjusted counterfactual years of research--I'd imagine it's much less than that. Could you provide some intuition for how the baseline figures are calculated (maybe you are assuming second-order effects, like funded individuals getting interested in safety and doing more or it or mentoring others under them)?
I was initially confused about this too. But I think I understood some of what was going on on a second skim:
Recall that their metric for "quality-adjusted research year" assumes a year of research "of average ability relative to the ML research community," and "Working on a research avenue as relevant as adversarial robustness."
I think their baselines are assuming a) much higher competency than the ML research community average and b) that the research avenues in question are considerably more impactful than the standard unit of analysis.
"Scientist Trojans" and "PhD Trojans" are hypothetical programs, wherein a research scientist or a PhD student is funded for 1 or 5 years, respectively. This funding causes the scientist or PhD student to work on trojans research (a research avenue that CAIS believes is 10x the relevance of adversarial robustness) rather than a research avenue that CAIS considers to have limited relevance to AI safety (0x). Unlike participants considered previously in this post, the scientist or PhD student has ability 10x the ML research community average — akin to assuming that the program reliably selects unusually productive researchers. The benefits of these programs cease after the funding period.
This will naively get you to 100x. Presumably adjusting for counterfactuals means you go a little lower than that. That said, I'm still not sure how they ended up with 84x and 8.7x, or why the two numbers are so different from each other.
I'm still not sure how they ended up with 84x and 8.7x
the answer is discounting for time and productivity. Consider the 84x for research scientists. With a 20% annual research discount rate, the average value of otherwise-identical research relative to the present is a bit less than 0.9. And productivity relative to peak is very slightly less than 1. These forces move the 100 to 84.
Regarding
why the two numbers [84x and 8.7x] are so different from each other
the answer is mainly differences in productivity relative to peak and scientist-equivalence. As in the plots in this section, PhD students midway through their PhD are ~0.5x as productive as they will be at their career peak. And, as in this section, we value PhD student research labor at 0.1x that of research scientists. The other important force is the length of a PhD -- the research scientist is assumed to be working for 1 year whilst the PhD student is funded for 5 years, which increases the duration of the treatment effect and decreases the average time value of research.
Very roughly: 100x baseline you identified * ~0.5x productivity * 0.1x scientist-equivalence * 5 years * ~0.5 average research discount rate = 12.5. (Correcting errors in these rough numbers takes us to 8.4.)
That makes sense, thanks for the explanation! Yeah still a bit confused why they chose different numbers of years for the scientist and PhD, how those particular numbers arise, and why they're so different (I'm assuming it's 1 year of scientist funding or 5 years of PhD funding).
Yup, wanted to confirm here the ~100x in efficacy comes from getting 10x in relevance and 10x in ability (from selecting someone 10x better than the average research scientist).
Regarding the relative value of PhD vs scientist: the model currently values the average scientist at ~10x the average PhD at graduation (which seem broadly consistent with the selectivity of becoming a scientist and likely underrepresents the research impact as measured by citations—the average scientist likely has more than 10x the citation count as the average PhD). Then, the 5 years includes the PhD growing significantly as they gain more research experience, so the earlier years will not be as productive as their final year.
I'm confused where these assumptions are stored. All of the parameter files I see in GitHub have all of the `ability_at_*` variables set equal to one. And when I print out the average of `qa.mean_ability_piecewise` for all the models that also appears to be one. Where is the 10x coming from?
Cost-effectiveness of student programs for AI safety research
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
This post explores the cost-effectiveness of field-building programs for students, specifically the Atlas Fellowship (a rationality program, with some AI safety programming), MLSS (an ML safety course for undergraduates), a top-tier university student group, and undergraduate research stipends.
We estimate the benefit of these programs in ‘Quality-Adjusted Research Years’, using cost-effectiveness models built for the Center for AI Safety (introduction post here, full code here). Since our framework focuses on benefits for technical AI safety research exclusively, we will not account for other benefits of programs with broader objectives, such as the Atlas Fellowship.
We intend for these models to support — not determine — strategic decisions. We do not believe, for instance, that programs which a model rates as lower cost-effectiveness are necessarily not worthwhile as part of a portfolio of programs.
The models’ tentative results, summarized below, suggest that student groups and undergraduate research stipends are considerably more cost-effective than Atlas and MLSS. (With many important caveats and uncertainties, discussed in the post.) Additionally, student groups and undergraduate research stipends compare favorably to ‘baseline’ programs — directly funding a talented research scientist or PhD student working on trojans research for 1 year or 5 years respectively.
Program
Cost (USD)
Benefit (counterfactual expected QARYs)
Cost-effectiveness (QARYs per $1M)
Atlas
9,000,000
43
4.7
MLSS
330,000
6.4
19
Student Group
350,000
50
140
Undergraduate Stipends
50,000
17
340
Baseline: Scientist Trojans
500,000
84
170
Baseline: PhD Trojans
250,000
8.7
35
For readers who are after high-level takeaways, including which factors are driving these results, skip ahead to the cost-effectiveness in context section. For those keen on understanding the model and results in more detail, read on as we:
This analysis is a starting point for discussion, not a final verdict. The most critical reasons for this are that:
These models are reductionist. Even if we have avoided other pitfalls associated with cost-effectiveness analyses, the models might ignore factors that turn out to be crucial in practice, including (but not limited to) interactions between programs, threshold effects, and diffuse effects.
The models’ assumptions are first-pass guesses, not truths set in stone. Most assumptions are imputed second-hand following a short moment of thought, before being adjusted ad-hoc for internal consistency and differences of beliefs between Center for AI Safety (CAIS) staff and external practitioners. In some cases, parameters have been redefined since initial practitioner input.
This caveat is particularly important for the Atlas Fellowship, where we have not discussed parameter values with key organizers[1].
Instead, the analyses in this post represent an initial effort in explicitly laying out assumptions, in order to take a more systematic approach towards AI safety field-building.
Background
For an introduction to our approach to modeling – including motivations for using models, the benefits and limitations of our key metric, guidance for adopting or adapting the models for your own work, comparisons between programs for students and professionals, and more – refer to the introduction post.
The models’ default parameters are based on practitioner surveys and the expertise of CAIS staff. Detailed information on the values and definitions of these parameters, and comments on parameters with delicate definitions or contestable views, can be found in the parameter documentation sheet.
The full code for this project is in this repository. The `examples` folder includes documentation that demonstrates the repository’s use.
We have also published an evaluation of field-building programs for professionals, which you can find here.
The model
Programs
This analysis includes the following programs:
1. The Atlas Fellowship: A 10-day in-person program providing a scholarship and networking opportunities for select high school students.
2. MLSS: CAIS’s discontinued summer course, designed to teach undergraduates ML safety. (This program has been superseded by Intro to ML Safety, which we expect to be more cost-effective.)
3. Student Group: A high-cost, high-engagement student group at a top university, similar to HAIST, MAIA, or SAIA[2].
4. Undergraduate Stipends: Specifically, the ML Safety Student Scholarship, which provides stipends to undergraduates connected with ML safety research opportunities.
In the cost-effectiveness in context section, we will compare these programs to directly funding a talented research scientist or PhD student working on trojans research for 1 year or 5 years respectively.
Throughout, we will evaluate the programs as if they had not been conducted yet, hence we are uncertain about parameters that are ex-post realized (e.g. costs, number of participants). At the same time, parameter values often reflect our current best understanding from recent program implementations[3].
Definitions
Our key metric is the Quality-Adjusted Research Year (QARY)[4]. We define a QARY as:
A year of research labor (40 hours * 50 weeks),
Conducted by a research scientist (other researcher types will be inflated or deflated),
Of average ability relative to the ML research community (other cohorts will be inflated or deflated),
Working on a research avenue as relevant as adversarial robustness (alternative research avenues will be inflated or deflated),
Working at their peak productivity (earlier-in-career research will be discounted),
Conducting all of their research in the present (later-in-time research will be time discounted),
Who stays in the AI profession (later-in-time research will be discounted by the probability that the researcher switches).
In order to operationalize the QARY, we need some way of defining relative weights for different researcher types, researcher abilities, and the relevance of different research avenues.
Define the ‘scientist-equivalence’ of a researcher type as the rate at which we would trade off an hour of labor from this researcher type with an hour of otherwise-similar labor from a research scientist.
Similarly, the ‘ability’ level of a researcher is the rate at which we would trade off an hour of labor from a researcher of this ability level with an hour of otherwise-similar labor from a researcher of ability level 1.
Finally, the ‘relevance’ of a research avenue is the rate at which we would trade off an hour of labor from a researcher pursuing this avenue with an hour of otherwise-similar labor from a researcher pursuing adversarial robustness research.
The expected number of QARYs per participant is given by the integral of the product of these functions over a career:
QARYs-per-participant = (integral from 0 to 60 of: research-labor x scientist-equivalence x ability x relevance x productivity x time-discount x probability-stay-in-AI dt)
or, since scientist-equivalence and ability are constant in time,
QARYs-per-participant = scientist-equivalence x ability x (integral from 0 to 60 of: research-labor x research-avenue-relevance x relative-productivity x time-discount x probability-stay-in-AI dt).
The benefit of the program is given by the difference between expected QARYs with and without the program. Cost-effectiveness is calculated by dividing this benefit by the expected cost in millions of US dollars.
Building the model piece-by-piece
Let's gradually build up the model, starting with the simplest possible scenario.
The simple example program
The simple example program has a budget of $200k, sufficient to support 10 undergraduates.
Each participant produces the same QARYs over the course of their career. In particular, if the program is implemented, each participant:
Works on research from their graduation (2 years from now) until retirement (60 years hence),
Has a 2% chance of becoming a professional research scientist (0.02x scientist-equivalence),
Is of average ability relative to the ML research community,
Works on adversarial robustness research,
Always maintains their peak productivity,
Does not have their work time-discounted, and
Remains within the AI profession throughout their career.
In the absence of the program, each of the identical participants:
4. Works on a research avenue that CAIS considers to have limited relevance to AI safety (0x adversarial robustness research),
with all other factors remaining constant.
Integrating over time, each participant produces, with and without the program taking place respectively,
0.02 x 1 x (integral from 2 to 60 of: 1 x 1 x 1 x 1 x 1 dt) = 1.16
0.02 x 1 x (integral from 2 to 60 of: 1 x 0 x 1 x 1 x 1 dt) = 0
QARYs over their career respectively. Multiplying by the number of participants, the program generates
10 * (1.16 - 0) = 11.6
QARYs, at a cost-effectiveness (in QARYs per $1m) of
11.6 / ($200k / $1m) = 58.
Cost and number of participants
Now, let's consider the expected costs for each program:
Parameter
Atlas
MLSS
Student Group
Undergraduate Stipends
Target Budget
$9,000,000
$330,000
$350,000
$50,000
Fixed Cost
$1,360,000
$4800
$68,000
$1900
Variable Cost
$7,640,000
$325,000
$282,000
$48,000
Fixed costs refer to expenses that remain constant regardless of the number of participants (e.g., property purchase, program ideation). Variable costs, which are costs proportional to the number of participants (e.g., stipends, advertising), make up the rest of the budget (at least, in expectation[5]).
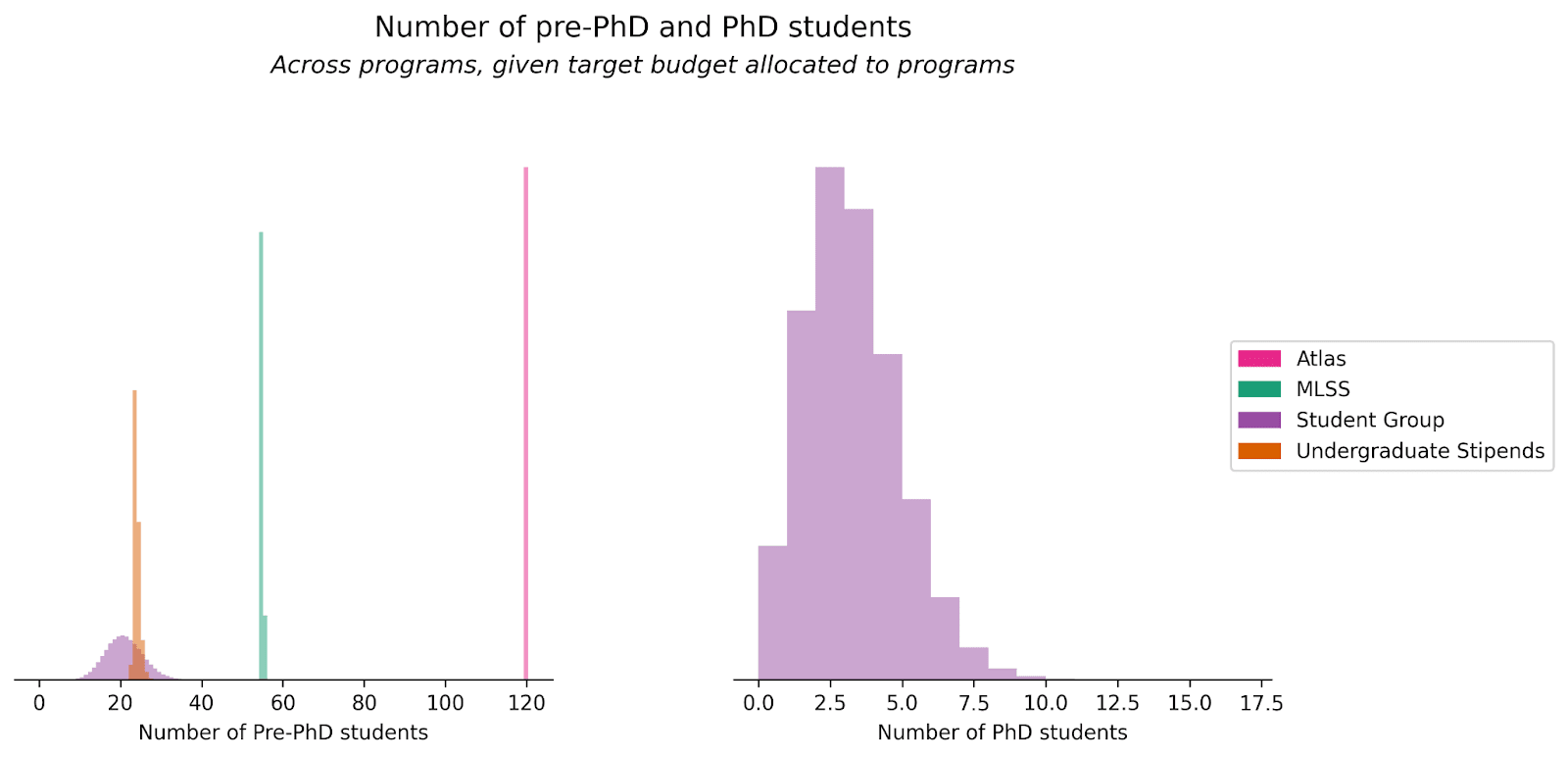
Given these budgets, each program can support some number of students[6][7]. (In the plot below we use “pre-PhD students” to refer to undergraduates and high school students.)
Maintaining earlier assumptions about QARYs per participant, the cost-effectiveness of these programs is as follows:
Program
Build-up stage
Cost (USD)
Benefit (counterfactual expected QARYs)
Cost-effectiveness (QARYs per $1M)
Simple example program
Simple Example Program
200,000
12
58
Atlas
Cost and Participants
9,000,000
130
15
MLSS
Cost and Participants
330,000
64
190
Student Group
Cost and Participants
350,000
180
520
Undergraduate Stipends
Cost and Participants
50,000
28
560
Pipeline probabilities and scientist-equivalence
Not every participant in these programs will transform into a professional researcher. The journey involves several potential hurdles:
‘Serious’ pursuit of technical ML safety paths, such as obtaining a relevant research internship.
Admission into top-tier PhD programs.
Securing a position at a renowned research institution, with or without a PhD.
The probability of becoming a researcher involves the combined probability of these steps.
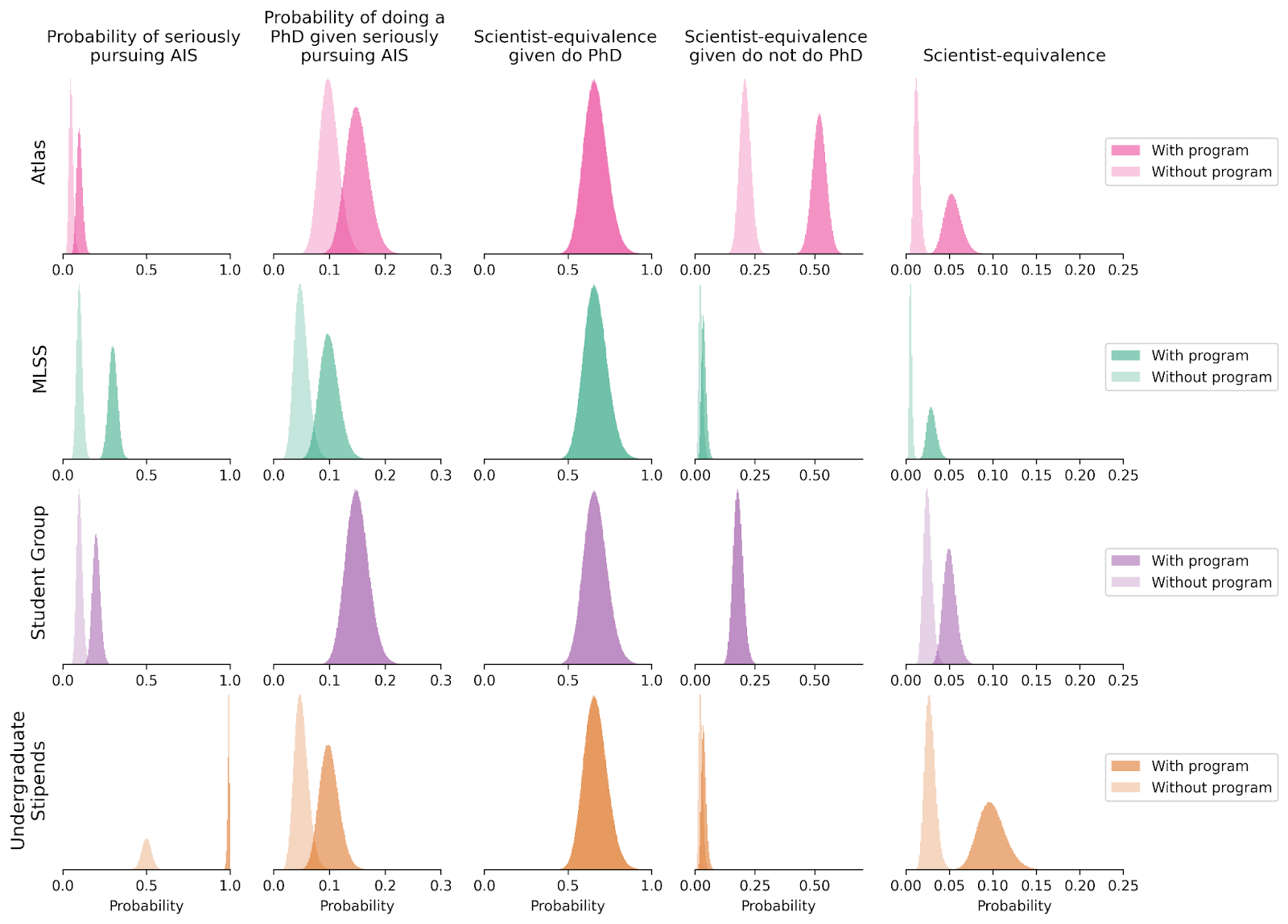
For purposes of impact evaluation, we might not value the impact of different roles equally. Here, scientists, professors, engineers, and PhD students are assigned ‘scientist-equivalence’ of 1, 10, 0.1, and 0.1 respectively.
We calculate the expected impact of each participant by combining the likelihood of their professional path and the scientist-equivalence of their potential roles. This gives us the 'unconditional' scientist-equivalence, which we will later multiply by the number of participants to estimate the number of scientist-equivalent participants.
Steps 1, 2, scientist-equivalence conditional on doing a PhD, scientist-equivalence conditional on not doing a PhD, and (unconditional) scientist-equivalence are specified as follows:
Multiplying scientist-equivalence by the number of participants in the program, we get the number of scientist-equivalents with and without the program.
Note that the number of scientist-equivalent participants is higher after than during the PhD period. This is because (current or future) PhD students are valued at 0.1 scientist-equivalents, but we expect them to be valued at
Let's see how these factors affect cost-effectiveness. In the table below, bolded rows incorporate pipeline probabilities and scientist-equivalence.
Program
Build-up stage
Cost (USD)
Benefit (counterfactual expected QARYs)
Cost-effectiveness (QARYs per $1M)
Simple example program
Simple Example Program
200,000
12
58
Atlas
Cost and Participants
9,000,000
130
15
Atlas
Pipeline and Equivalence
9,000,000
350
39
MLSS
Cost and Participants
330,000
64
190
MLSS
Pipeline and Equivalence
330,000
90
270
Student Group
Cost and Participants
350,000
180
520
Student Group
Pipeline and Equivalence
350,000
170
470
Undergraduate Stipends
Cost and Participants
50,000
28
560
Undergraduate Stipends
Pipeline and Equivalence
50,000
130
2600
Factoring in pipeline probabilities and scientist-equivalence dramatically increases the estimated cost-effectiveness of Atlas and especially Undergraduate Stipends. MLSS also sees some improvement, while the Student Group experiences a slight dip. These changes reflect the above gaps between distributions of unconditional scientist-equivalence with and without the program.
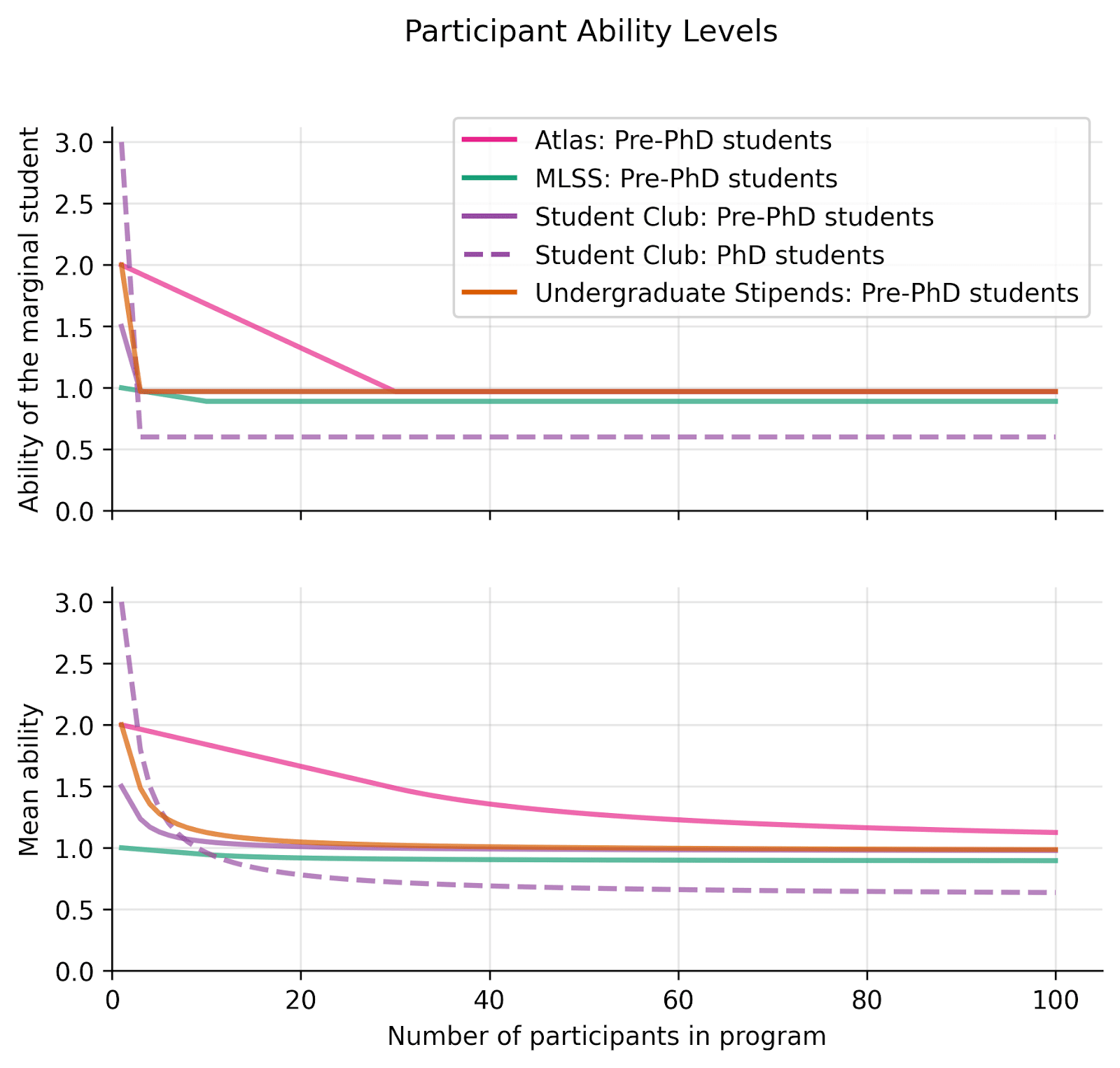
The following plot illustrates the ability of marginal students and average ability as a function of the number of students the program is able to support:
Given the number of pre-PhD participants each program enrolls, Atlas participants have a mean ability of ~1.1x, Student Group and Undergraduate Stipends ~1x, and MLSS ~0.9x. Student Group PhD students have mean ability ~1.5x.
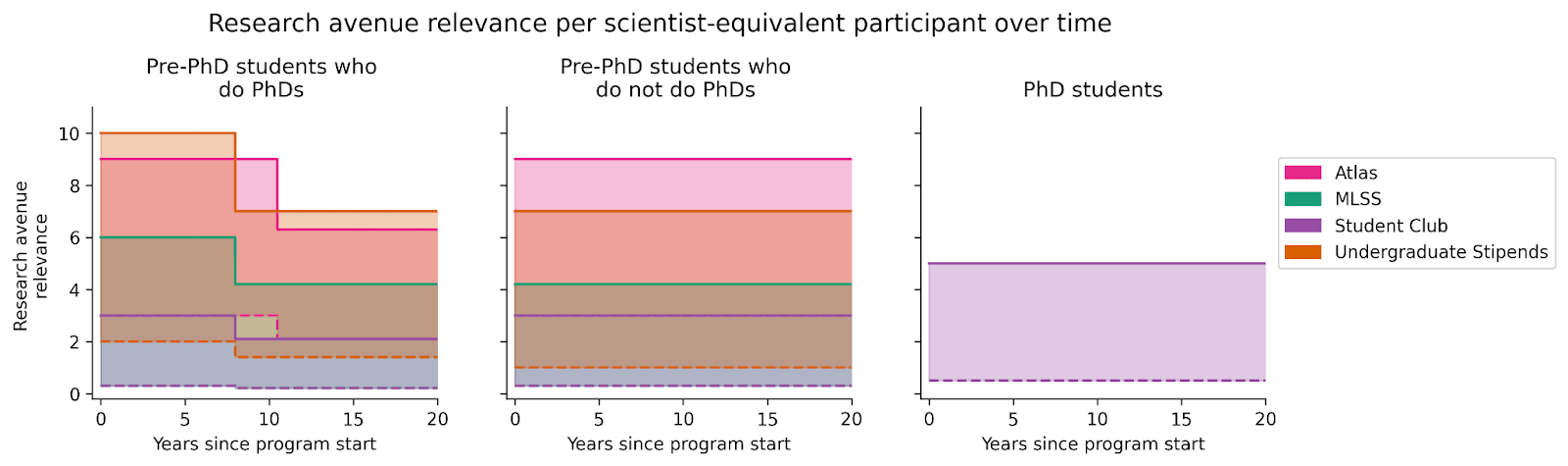
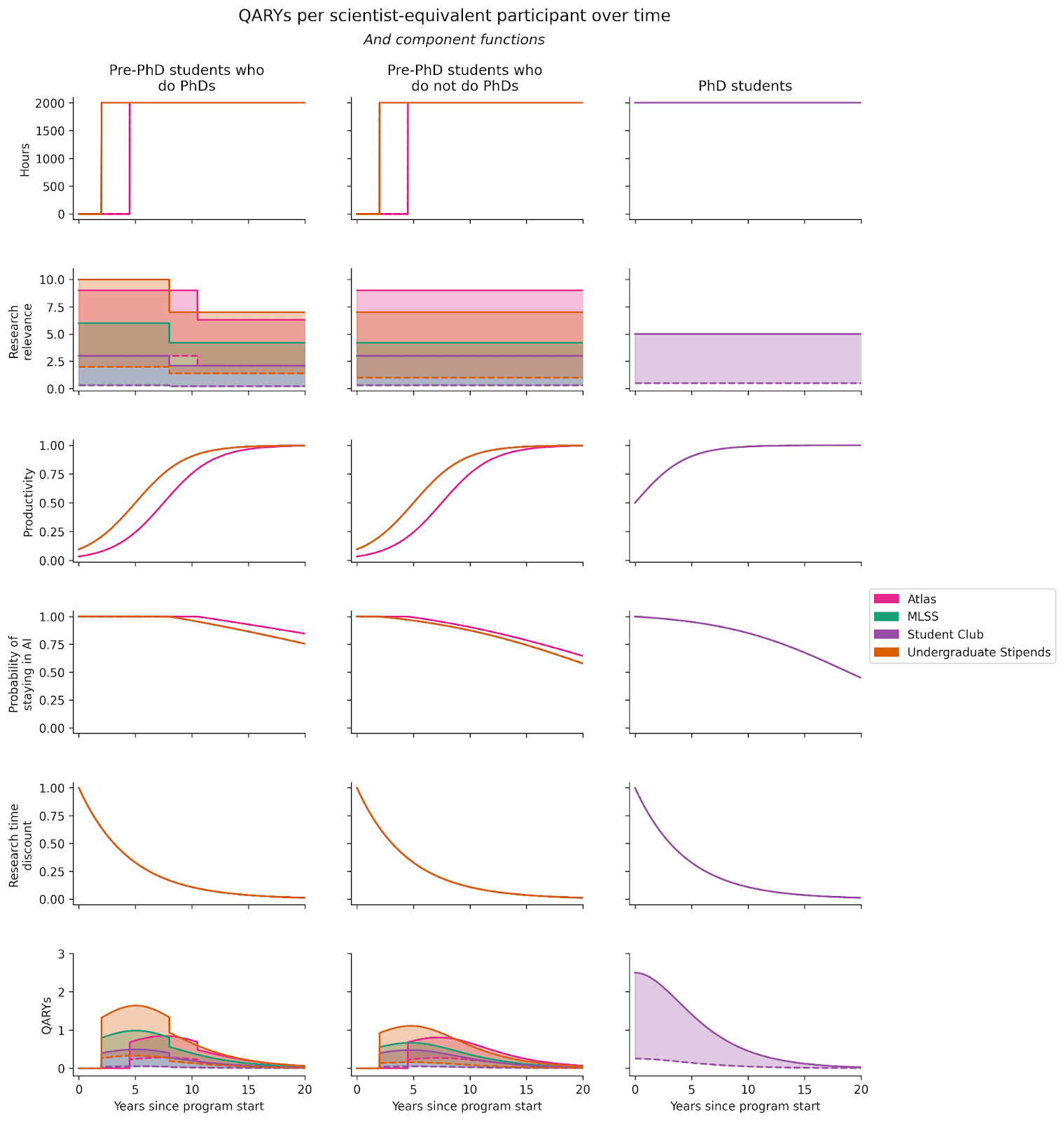
Separate from their ability, participants might work on varying research avenues that we value differently. The research avenue relevance of each participant in each program over time is specified as follows:
The shaded area indicates research avenue relevance for the average participant with (solid line) and without (dashed line) the program. Note that, after finishing their PhD, some pre-PhD students shift away from high-relevance research avenues, represented as vertical drops in the plot. Note also that the dashed lines for MLSS and student group are overlapping.
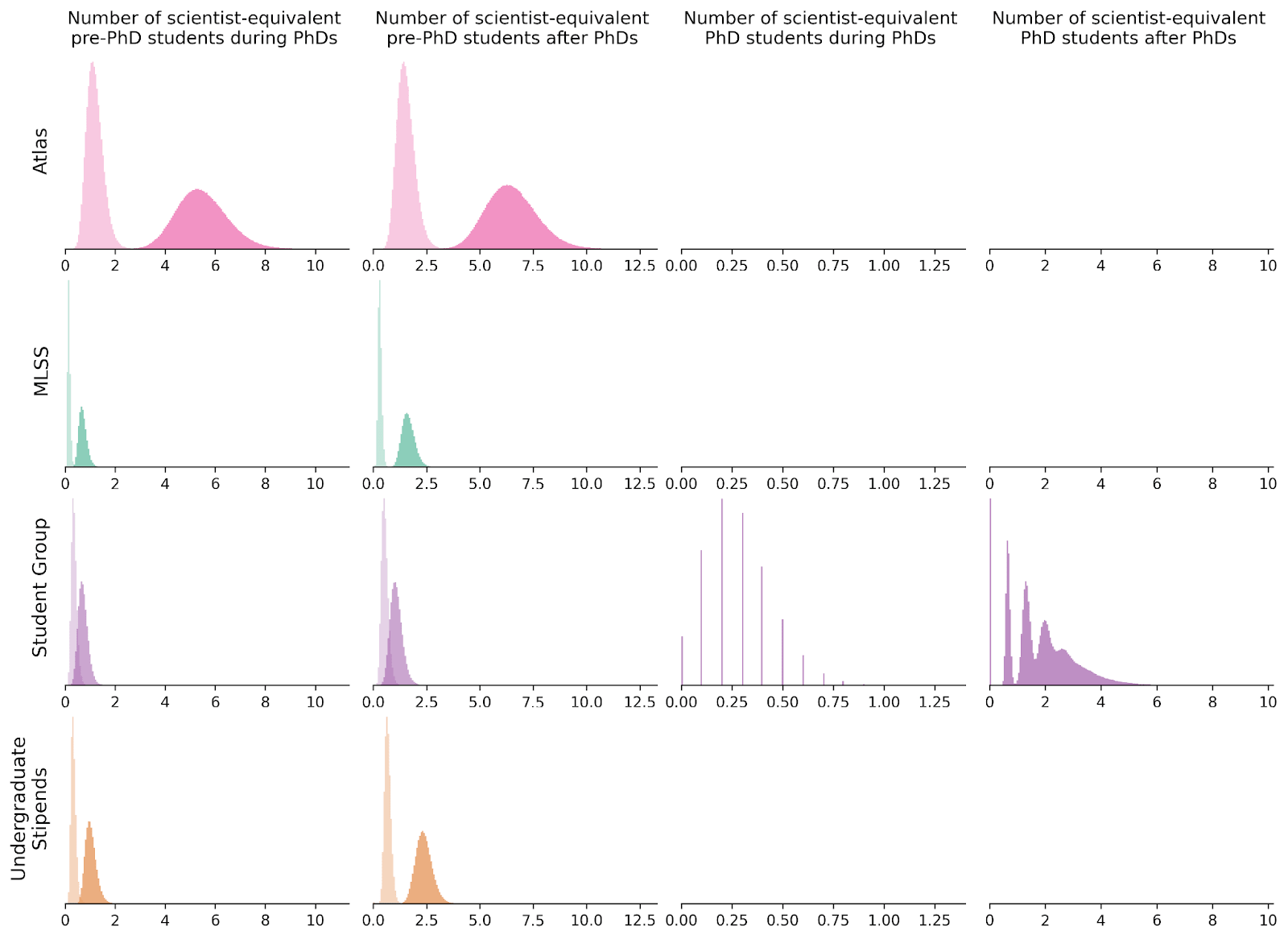
Multiplying time spent on research by research avenue relevance gives us QARYs per scientist-equivalent participant as a function of time:
The shaded area in the bottom row equals QARYs per scientist-equivalent participant for each program. Combining this with the number of scientist-equivalent participants, we get an estimate for the QARYs produced by the program.
After incorporating differences in ability and research avenue relevance, the cost-effectiveness of different programs is given by:
Program
Build-up stage
Cost (USD)
Benefit (counterfactual expected QARYs)
Cost-effectiveness (QARYs per $1M)
Simple example program
Simple Example Program
200,000
12
58
Atlas
Cost and Participants
9,000,000
130
15
Atlas
Pipeline and Equivalence
9,000,000
350
39
Atlas
Ability and Relevance
9,000,000
3100
340
MLSS
Cost and Participants
330,000
64
190
MLSS
Pipeline and Equivalence
330,000
90
270
MLSS
Ability and Relevance
330,000
340
1000
Student Group
Cost and Participants
350,000
180
520
Student Group
Pipeline and Equivalence
350,000
170
470
Student Group
Ability and Relevance
350,000
980
2800
Undergraduate Stipends
Cost and Participants
50,000
28
560
Undergraduate Stipends
Pipeline and Equivalence
50,000
130
2600
Undergraduate Stipends
Ability and Relevance
50,000
900
18,000
The outlook for every program benefits from incorporating ability and research avenue relevance. The effect is especially great for Atlas. Research avenue relevance is the more important factor explaining this pattern.
Productivity, staying in AI research, and time discounting
Researchers' productivity can vary throughout their careers. Additionally, some may choose to leave the field of AI research, and, from the perspective of today, the value of research might change over time. We will now make adjustments for these factors.
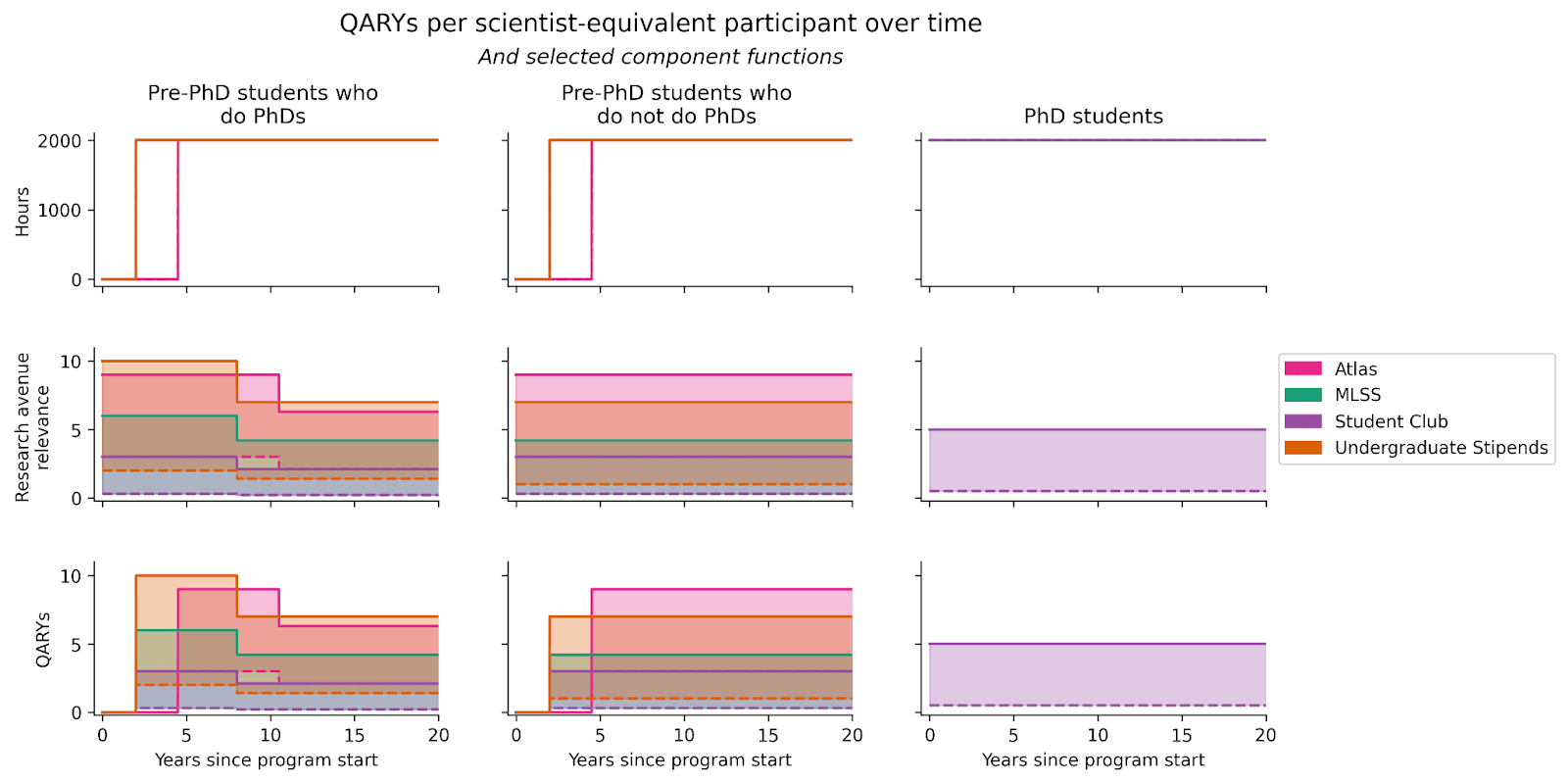
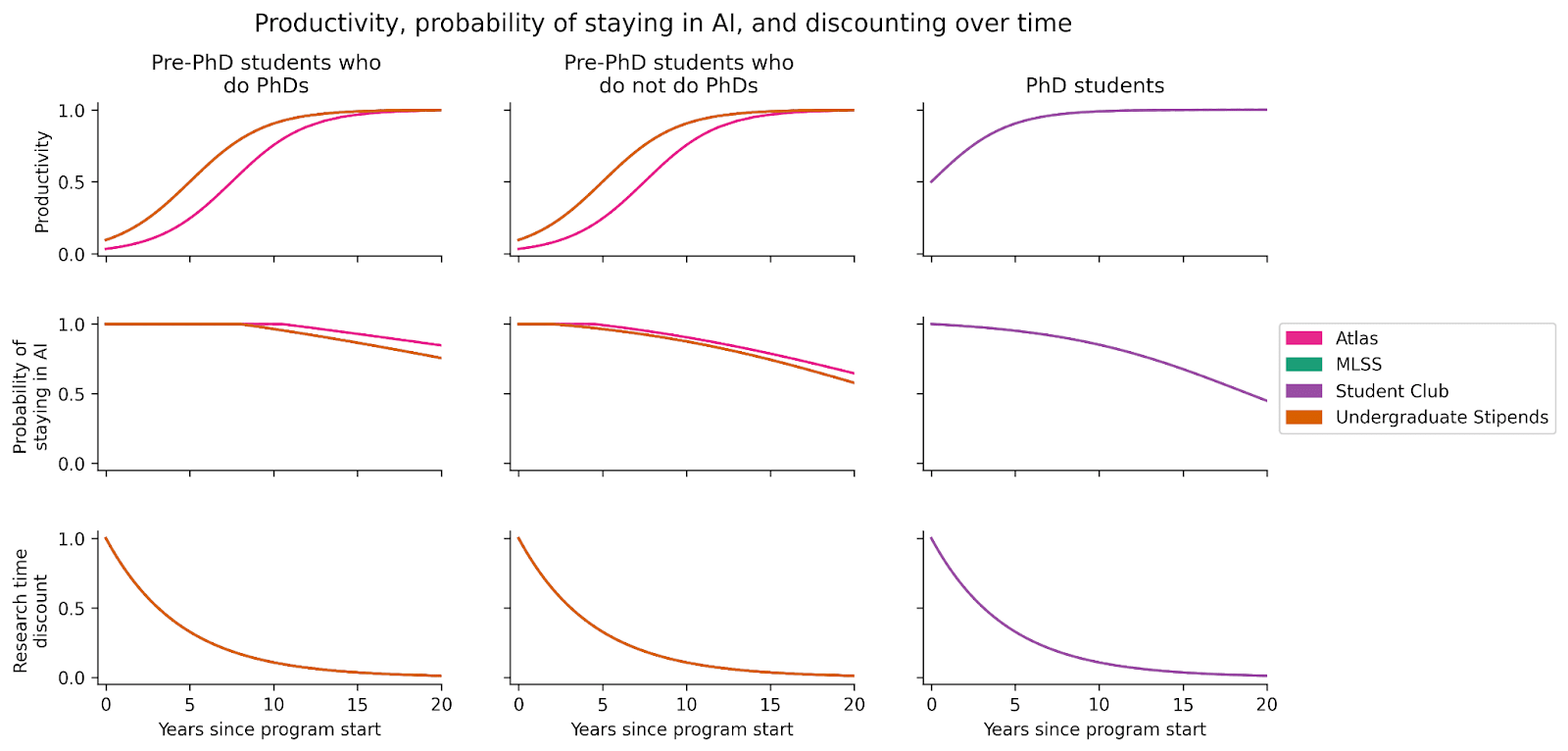
Productivity relative to peak, probability of staying in the AI field, and time discounting are specified as the following functions over time[9]:
These functions are nearly identical across programs, except for Atlas, which targets younger participants.
Multiplying these functions with the hours and research avenue relevance functions, we get the updated function for QARYs per scientist-equivalent over time:
The updated cost-effectiveness of each program is as follows:
Program
Build-up stage
Cost (USD)
Benefit (counterfactual expected QARYs)
Cost-effectiveness (QARYs per $1M)
Simple example program
Simple example program
200,000
12
58
Atlas
Cost and Participants
9,000,000
130
15
Atlas
Pipeline and Equivalence
9,000,000
350
39
Atlas
Ability and Relevance
9,000,000
3100
340
Atlas
Productivity, Staying in AI, and Time Discounting
9,000,000
43
4.7
MLSS
Cost and Participants
330,000
64
190
MLSS
Pipeline and Equivalence
330,000
90
270
MLSS
Ability and Relevance
330,000
340
1000
MLSS
Productivity, Staying in AI, and Time Discounting
330,000
6.4
19
Student Group
Cost and Participants
350,000
180
520
Student Group
Pipeline and Equivalence
350,000
170
470
Student Group
Ability and Relevance
350,000
980
2800
Student Group
Productivity, Staying in AI, and Time Discounting
350,000
50
140
Undergraduate Stipends
Cost and Participants
50,000
28
560
Undergraduate Stipends
Pipeline and Equivalence
50,000
130
2600
Undergraduate Stipends
Ability and Relevance
50,000
900
18,000
Undergraduate Stipends
Productivity, Staying in AI, and Time Discounting
50,000
17
340
The adjustments for productivity, remaining in AI research, and time discounting have a dramatic effect on estimated (absolute) cost-effectiveness. This is expected: the bulk of research time for program participants happens years after graduation, whilst discounting future research reduces its present value considerably.
However, these adjustments do not have nearly as dramatic an impact on the ratios of estimated cost-effectiveness between programs (relative cost-effectiveness). MLSS and Undergraduate Stipends experience a nearly identical ~50x decrease in cost-effectiveness. Atlas sees a ~70x decline, due to its participants beginning research relatively late; the Student Group sees only a ~20x decline, due to PhD students' research beginning relatively soon.
Cost-effectiveness in context
The table below compares the cost-effectiveness of the programs considered above with ‘baseline’ programs — directly funding a talented research scientist or PhD student working on trojans research for 1 year or 5 years respectively.
Program
Cost (USD)
Benefit (counterfactual expected QARYs)
Cost-effectiveness (QARYs per $1M)
Atlas
9,000,000
43
4.7
MLSS
330,000
6.4
19
Student Group
350,000
50
140
Undergraduate Stipends
50,000
17
340
Baseline: Scientist Trojans
500,000
84
170
Baseline: PhD Trojans
250,000
8.7
35
"Scientist Trojans" and "PhD Trojans" are hypothetical programs, wherein a research scientist or a PhD student is funded for 1 or 5 years, respectively. This funding causes the scientist or PhD student to work on trojans research (a research avenue that CAIS believes is 10x the relevance of adversarial robustness) rather than a research avenue that CAIS considers to have limited relevance to AI safety (0x). Unlike participants considered previously in this post, the scientist or PhD student has ability 10x the ML research community average — akin to assuming that the program reliably selects unusually productive researchers. The benefits of these programs cease after the funding period.
The Student Group and Undergraduate Stipends programs are competitive with programs that fund researchers directly. However, Atlas and MLSS lag behind in terms of cost-effectiveness.
What factors contribute to this pattern across student programs?
There is no single explanatory factor. A lower cost per participant mechanically increases cost-effectiveness. Having a greater expected number of professional researchers among participants (via improved pipeline probabilities, or a larger fraction of participants who are currently PhD students) naturally multiplies the quantity of future research produced as a result of the program. Similarly, participant ability and research avenue relevance multiply the quality of future research.
Despite its strengths in some areas, the Atlas Fellowship’s very high cost per participant brought down its overall cost-effectiveness. MLSS was most affected by the relatively small change it caused to the relevance of participants’ future research. The Student Group benefited from having a larger number of participants (per cost), and from involving PhD students. And Undergraduate Stipends performed well across all areas.
Robustness
Research discount rate
We saw earlier that the research discount rate – the degree to which a research year starting next year is less valuable than one starting now – had an especially large effect on (absolute) cost-effectiveness estimates.
For purposes of this post, research one year from now is considered to be 20% less valuable than research today. The justification for this figure begins with the observation that, in ML, research subfields often begin their growth in an exponential fashion. This means that research topics are often dramatically more neglected in earlier stages (i.e. good research is much more counterfactually impactful), and that those who are early can have an outsized impact in influencing the direction of the field — imagine a field of 3 researchers vs. one of 300 researchers. If, for instance, mechanistic interpretability arose as a research agenda one year earlier than it did, it seems reasonable to imagine that the field would have 20% more researchers than it currently does. In fact, we think that these forces are powerful enough to make a discount rate of 30% seem plausible. (Shorter timelines would also be a force in this direction.)
This view does not reflect a consensus. Others might argue that the most impactful safety work requires access to more advanced models and conceptual frameworks, which will only be available in the future[10].
The plot above shows how cost-effectiveness changes with the research discount rate. 0.2 is our default; negative values represent a preference for research conducted in the future.
For the programs considered in this post, research time discounting strongly affects conclusions about absolute impact, but typically does not significantly affect conclusions about relative impact. The one exception is the Student Group, which is the first-ranked program assuming very high discount rates and the joint-last-ranked program assuming very low discount rates.
It is hardly surprising that the research discount rate does not typically affect the relative impact of student field-building programs: these are all programs that aim to produce researchers at an approximately similar point in time. Neither is it surprising that the Student Group performs relatively better when assuming high discount rates (perhaps corresponding to very short timelines). If research feels more urgent, programs with older students are a better bet, because older students are likely to produce research sooner. (For similar reasons, relative cost-effectiveness might be less robust when comparing professional programs with student programs. The research discount rate section of our introduction post explores this comparison.)
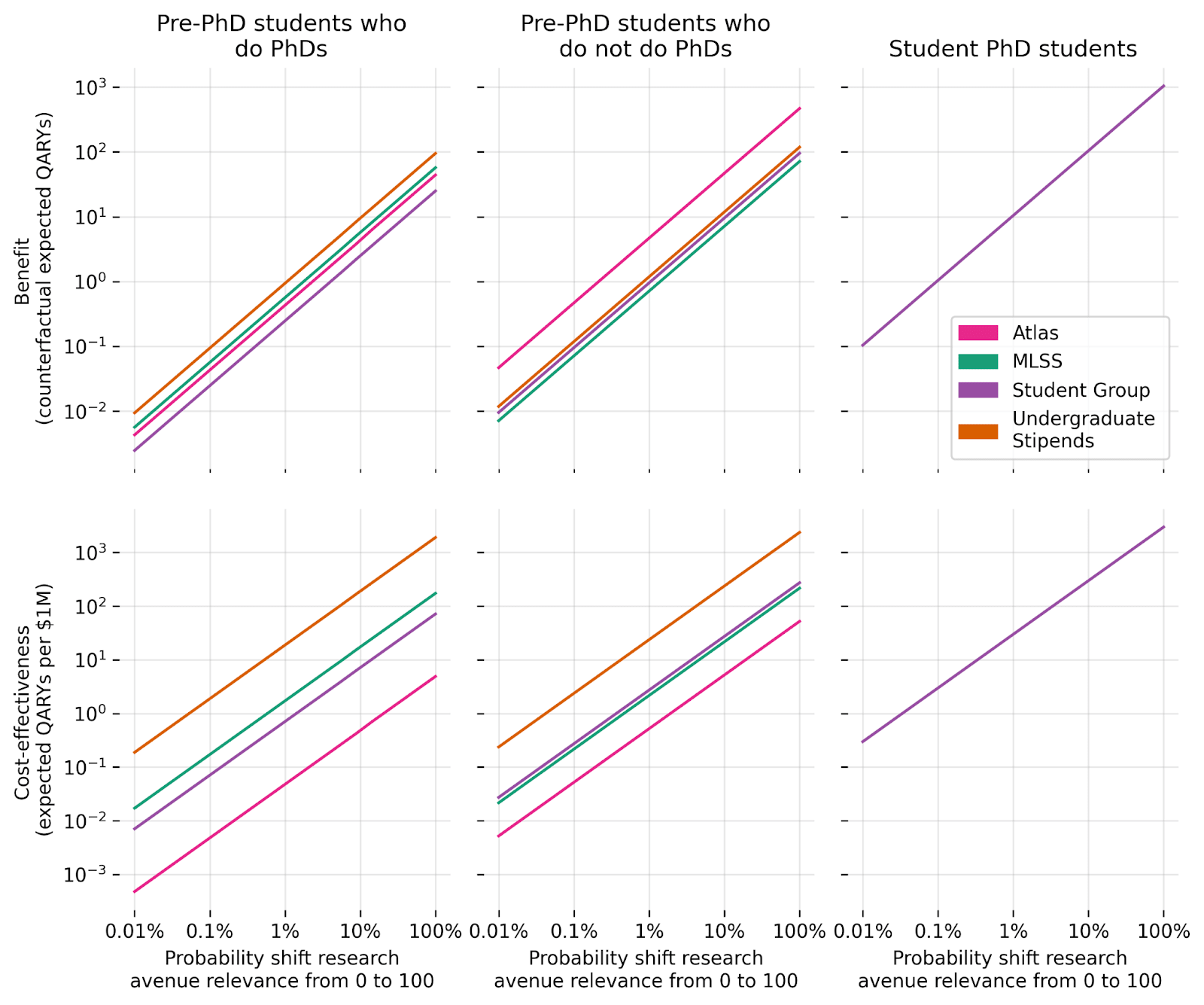
Research avenue relevance
Consider this illustrative scenario. All participants begin the programs considered above pursuing research avenues that CAIS considers to have limited relevance to AI safety (0x adversarial robustness). Once a program ends, participants shift from research avenues with 0x relevance to research avenues with 100x relevance with some probability. (This could also be viewed as a proportion of research being redirected towards more relevant avenues.)
The above plot shows how program benefit and cost-effectiveness vary in response to changes in the probability that different types of students alter their research avenues (with other student types remaining unchanged).
Notice that differences in research avenue relevance matter a lot for program outcomes. Two alternative, plausible views on research avenue relevance could imply 3 orders of magnitude difference in final impact. (To see this from the chart, note that, for the purposes of these models, a 10% chance of moving from 0 to 100 is equivalent to a 1% chance of moving from 0 to 1000 — and that research avenue relevance is unsettled and might be thought to vary by orders of magnitude.)
Although the models’ results will strongly depend on contentious research avenue relevance parameters, we are heartened that these models clarify the effect of alternative views on benefit and cost-effectiveness.
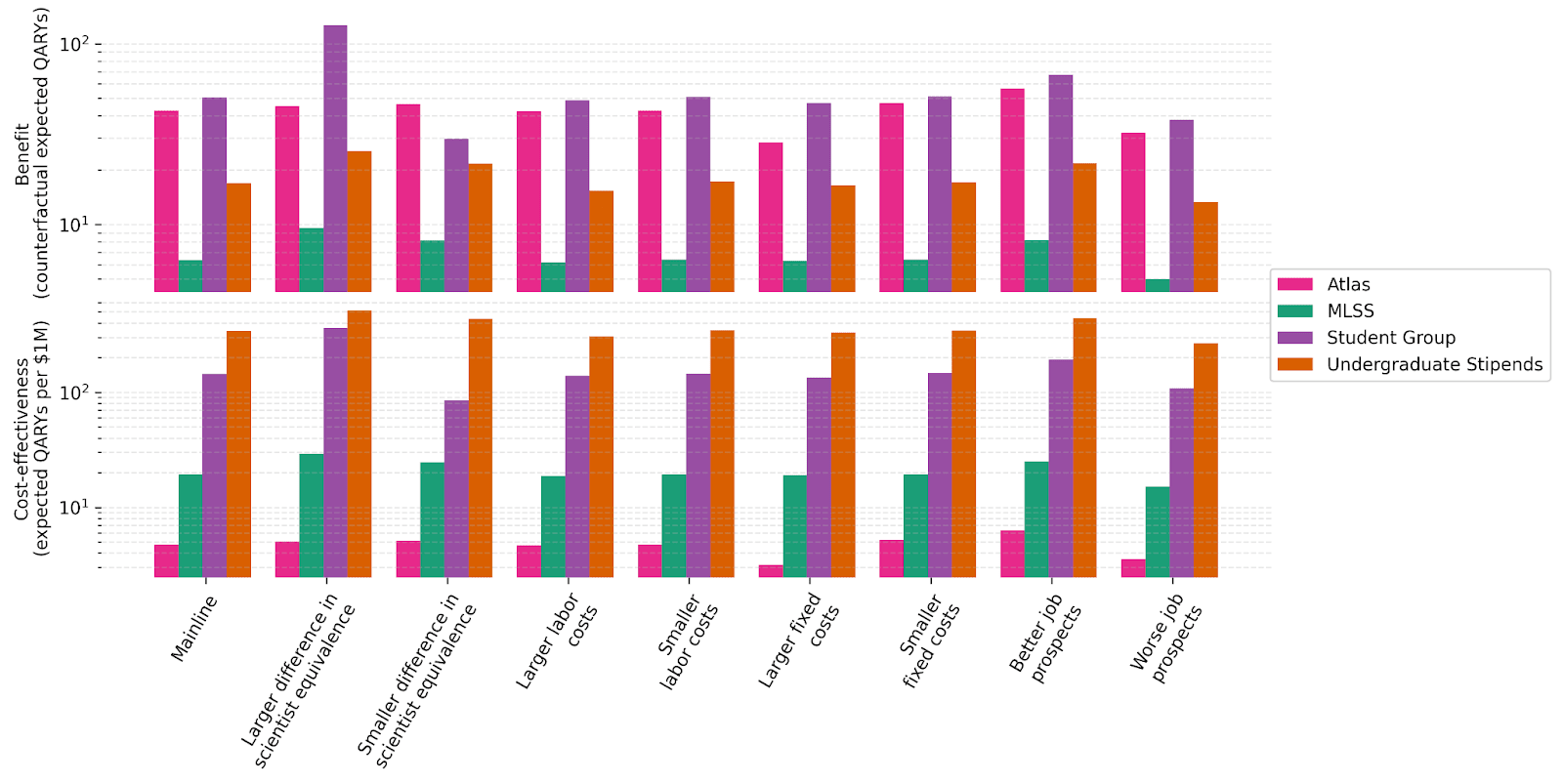
Less contentious background parameters
The above plot visualizes the robustness of our benefit and cost-effectiveness results to various scenarios. These scenarios simulate sizeable shocks to default beliefs or empirical parameters:
“Difference in scientist-equivalence” inflates or deflates the scientist-equivalence gap between research scientists and other research professionals by a factor of 10^0.5.
“Labor costs” inflates or deflates fixed hours (i.e. labor hours that are constant in the number of participants) spent working on the program by 10^0.25, and wages by 10^0.125.
“Fixed costs” inflates or deflates non-labor fixed costs by 10^0.5.
“Job prospects” inflates or deflates the probabilities that a graduating student (from PhD or without PhD) becomes a scientist, professor, or engineer at a strong research institution by 10^0.125.
Results are surprisingly stable (on log scale). The only shock that affects cost-effectiveness by 0.5 orders of magnitude or more is differences in scientist-equivalence for the Student Group, likely due to the adjustment in the value attributed to current PhD students.
Invitation to propose explicit models
This work represents a first step toward explicitly modeling the cost-effectiveness of AI safety programs, taking inspiration from cost-effectiveness models from other causes. To hold each other to a more objective and higher standard, we strongly suggest that people with different views or suggested AI safety interventions propose quantitative models going forward.
Acknowledgements
Thank you to:
Dan Hendrycks and Oliver Zhang for high-level guidance,
Aron Lajko for excellent research assistance,
Anonymized practitioners for help with parameters assumptions,
Miti Saksena, Steven Basart, Aidan O’Gara, Michael Townsend, Chana Messinger, Will Hodgkins, Jonas Vollmer, and Basil Halperin for feedback, and
The Quantified Uncertainty Research Institute team for creating squiggle, and Peter Wildeford for creating squigglepy.
We reached out to key organizers but they were too busy. To compensate for errors this could introduce into the analysis, we have tried to lean towards optimism whenever we are deeply uncertain about parameters for external programs. For example, scientist-equivalence given a non-PhD path is much higher for the Atlas Fellowship than for other programs.
Note that the number of students that the Atlas Fellowship, Undergraduate Stipends, and MLSS programs can support is deterministic given some budget – students cost (variable) resources if and only if they participate in the program. (The small degree of uncertainty arises because we are plotting results for different possibilities of ‘actual’ budget given the ‘target’ budget.) In contrast, the number of students that interact with the Student Group is uncertain even conditional on a certain budget.
For the Student Group, we are most interested in students who are new to the group in the year the program is implemented. The number of students considered in this post is approximately 3x smaller than the total number of students we would expect to meaningfully interact with the program in a given year.
By ability, we mean research ability. For the purposes of the model, we are interested in participants’ expected ability conditional on becoming a scientist-equivalent. This suggests caution when estimating the ability of students who are not yet professional researchers. We do not believe that IQ is highly predictive after conditioning on becoming a professional researcher. Given this, although after the fact – having observed publication records – it might be reasonable for ability levels to vary by several orders of magnitude, we might not be nearly this confident ahead of time.
In the model, all functions over time are specified over a 60-year period from the program’s start. We have truncated the x-axis in our plots for ease of reading. This could only mislead for the probability of staying in AI subplots, where the other side of the sigmoid function is not visible.
The extent to which current research will apply to more advanced models is a useful topic of discussion. Given that it seems increasingly likely that AGI will be built using deep learning systems, and in particular LLMs, we believe that studying existing systems can provide useful microcosms for AI safety. For instance, LLMs already exhibit forms of deception and power-seeking. Moreover, it seems likely that current work on AI honesty, transparency, proxy gaming, evaluating dangerous capabilities, and so on will apply to a significant extent to future systems based on LLMs. Finally, note that research on benchmarks and evals is robust to changes in architecture or even to the paradigm of future AI systems. As such, building benchmarks and evals are even more likely to apply to future AI systems.
Of course, it is true that more advanced models and conceptual frameworks do increase the relevance of AI safety research. For instance, we anticipate that once the LLM-agent paradigm gets established, research into AI power-seeking and deception will become even more relevant. Notwithstanding, we believe that, all things considered, AI safety research is currently tractable enough, and that the subfields are growing exponentially such that a 20% or even 30% discount rate is justified.

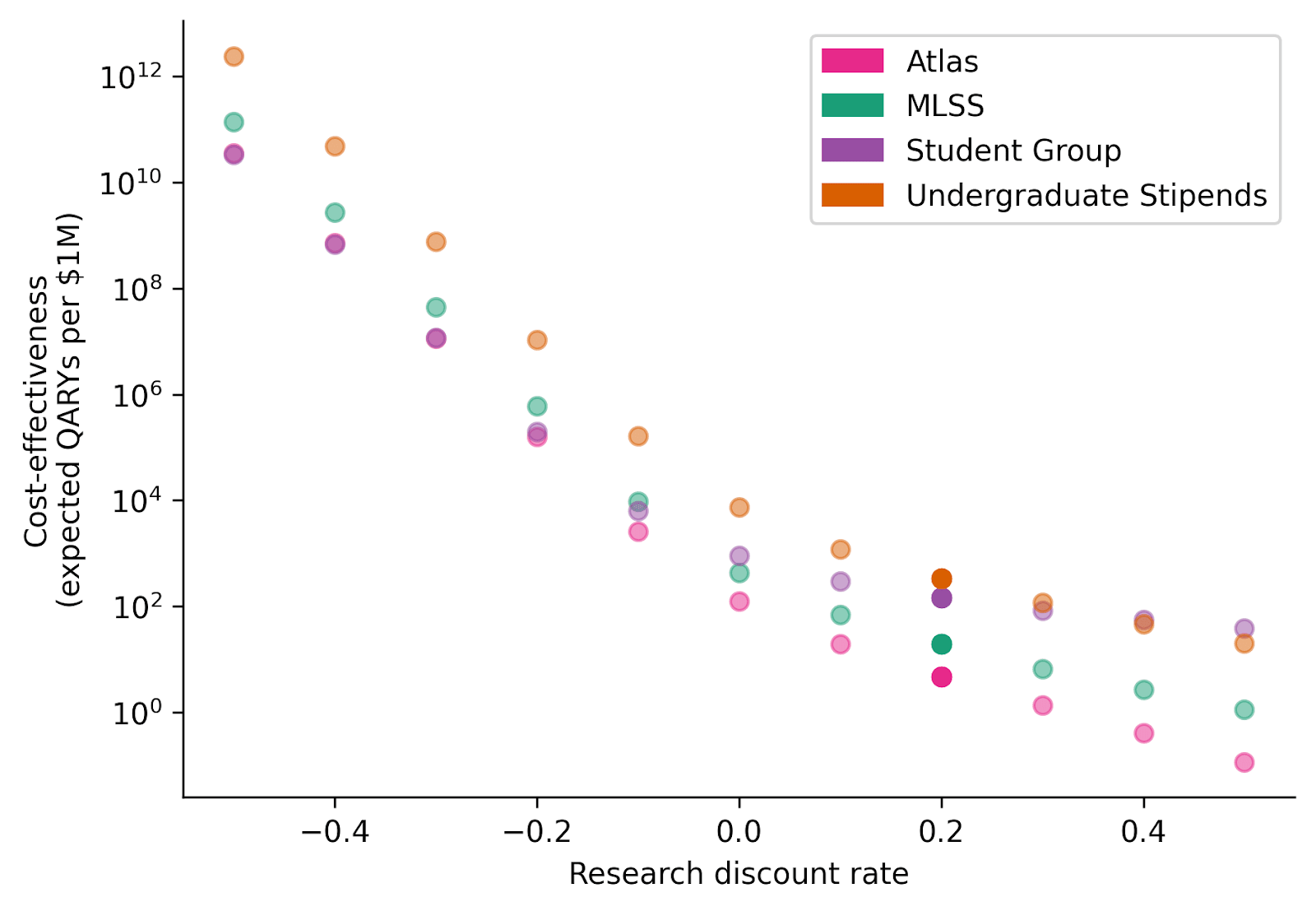
Thanks for publishing this + your code, I found this approach interesting :) and in general I am excited at people trying different approaches to impact measurement within field building.
I had some model qs (fair if you don't get around to these given that it's been a while since publication):
I feel confused by the mechanics of especially adjustments 2-4:
In general, I'd find it easier to work with this model if I understood better, for each of your core results, which critical inputs were based on CAIS's inside views v.s. evidence gathered by the program (feedback surveys, etc.) v.s. something else :)
I'd be interested to know whether CAIS has changed its field building portfolio based on these results / still relies on this approach!