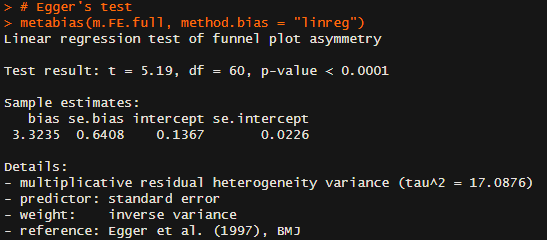
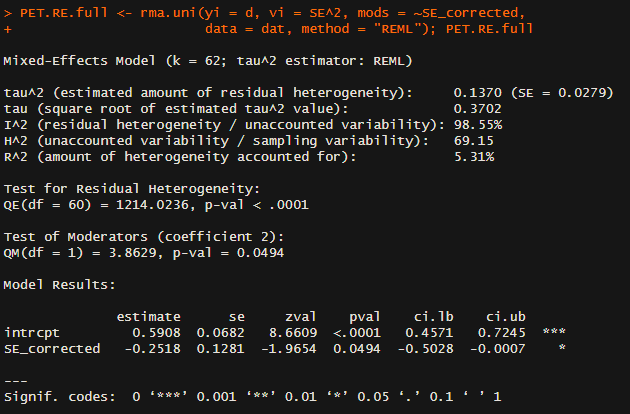
A recent post by Simon_M argued that StrongMinds should not be a top recommended charity (yet), and many people seemed to agree. While I think Simon raised several useful points regarding StrongMinds, he didn't engage with the cost-effectiveness analysis of StrongMinds that I conducted for the Happier Lives Institute (HLI) in 2021 and justified this decision on the following grounds:
“Whilst I think they have some of the deepest analysis of StrongMinds, I am still confused by some of their methodology, it’s not clear to me what their relationship to StrongMinds is.”.
By failing to discuss HLI’s analysis, Simon’s post presented an incomplete and potentially misleading picture of the evidence base for StrongMinds. In addition, some of the comments seemed to call into question the independence of HLI’s research. I’m publishing this post to clarify the strength of the evidence for StrongMinds, HLI’s independence, and to acknowledge what we’ve learned from this discussion.
I raise concerns with several of Simon’s specific points in a comment on the original post. In the rest of this post, I’ll respond to four general questions raised by Simon’s post that were too long to include in my comment. I briefly summarise the issues below and then discuss them in more detail in the rest of the post
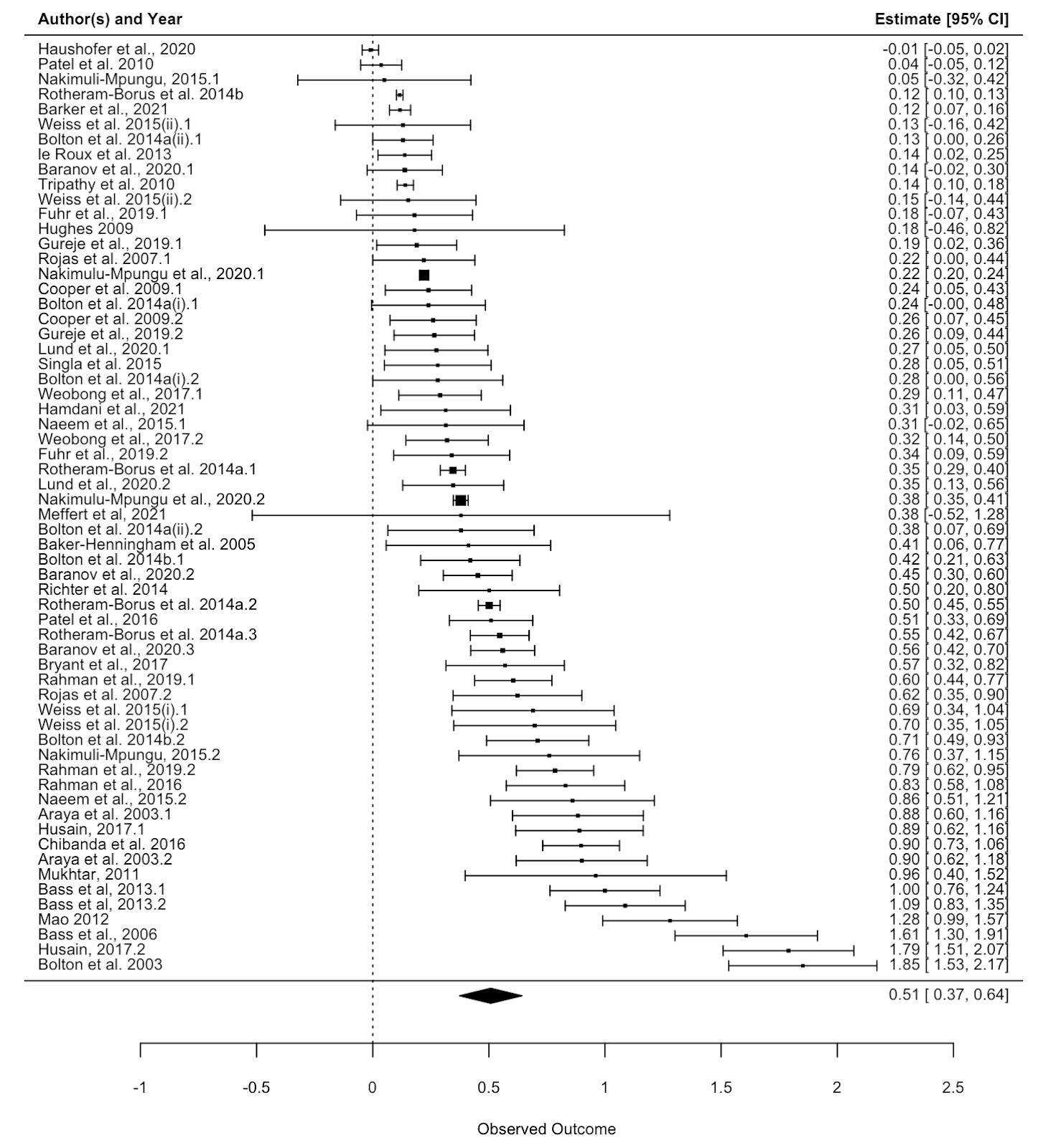
1. Should StrongMinds be a top-rated charity? In my view, yes. Simon claims the conclusion is not warranted because StrongMinds’ specific evidence is weak and implies implausibly large results. I agree these results are overly optimistic, so my analysis doesn’t rely on StrongMind’s evidence alone. Instead, the analysis is based mainly on evidence synthesised from 39 RCTs of primarily group psychotherapy deployed in low-income countries.
2. When should a charity be classed as “top-rated”? I think that a charity could be considered top-rated when there is strong general evidence OR charity-specific evidence that the intervention is more cost-effective than cash transfers. StrongMinds clears this bar, despite the uncertainties in the data.
3. Is HLI an independent research institute? Yes. HLI’s mission is to find the most cost-effective giving opportunities to increase wellbeing. Our research has found that treating depression is very cost-effective, but we’re not committed to it as a matter of principle. Our work has just begun, and we plan to publish reports on lead regulation, pain relief, and immigration reform in the coming months. Our giving recommendations will follow the evidence.
4. What can HLI do better in the future? Communicate better and update our analyses. We didn’t explicitly discuss the implausibility of StrongMinds’ data in our work. Nor did we push StrongMinds to make more reasonable claims when we could have done so. We acknowledge that we could have done better, and we will try to do better in the future. We also plan to revise and update our analysis of StrongMinds before Giving Season 2023.
1. Should StrongMinds be a top-rated charity?
I agree that StrongMinds’ claims of curing 90+% of depression are overly optimistic, and I don’t rely on them in my analysis. This figure mainly comes from StrongMinds’ pre-post data rather than a comparison between a treatment group and a control. These data will overstate the effect because depression scores tend to decline over time due to a natural recovery rate. If you monitored a group of depressed people and provided no treatment, some would recover anyway.
My analysis of StrongMinds is based on a meta-analysis of 39 RCTS of group psychotherapy in low-income countries. I didn’t rely solely on StrongMinds’ own evidence alone, I incorporated the broader evidence base from other similar interventions too. This strikes me, in a Bayesian sense, as the sensible thing to do. In the end, StrongMinds' controlled trials only make up 21% of the effect of the estimate (see Section 4 of the report for a discussion of the evidence base). It's possible to quibble with the appropriate weight of this evidence, but the key point is that it is much less than the 100% Simon seems to suggest.
2. When should a charity be classed as “top-rated”?
At HLI, we think the relevant factors for recommending a charity are:
(1) cost-effectiveness is substantially better than our chosen benchmark (GiveDirectly cash transfers); and
(2) strong evidence of effectiveness.
I think Simon would agree with these factors, but we define “strong evidence” differently.
I think Simon would define “strong evidence” as recent, high-quality, and charity-specific. If that’s the case, I think that’s too stringent. That standard would imply that GiveWell should not recommend bednets, deworming, or vitamin-A supplementation. Like us, GiveWell also relies on meta-analyses of the general evidence (not charity-specific data) to estimate the impact of malaria prevention (AMF, row 36) and vitamin-A supplementation (HKI, row 24) on mortality, and they use historical evidence for the impact of malaria prevention on income (AMF, row 109). Their deworming CEA infamously relies on a single RCT (DtW, row 7) of a programme quite different from the one deployed by the deworming charities they support.
In an ideal world, all charities would have the same quality of evidence that GiveDirectly does (i.e., multiple, high-quality RCTs). In the world we live in, I think GiveWell’s approach is sensible: use high-quality, charity-specific evidence if you have it. Otherwise, look at a broad base of relevant evidence.
As a community, I think that we should put some weight on a recommendation if it fits the two standards I listed above, according to a plausible worldview (i.e., GiveWell’s moral weights or HLI’s subjective wellbeing approach). All that being said, we’re still developing our charity evaluation methodology, and I expect our views to evolve in the future.
3. Is HLI an independent research institute?
In the original post, Simon said:
I’m going to leave aside discussing HLI here. Whilst I think they have some of the deepest analysis of StrongMinds, I am still confused by some of their methodology, it’s not clear to me what their relationship to StrongMinds is (emphasis added).
The implication, which others endorsed in the comments, seems to be that HLI’s analysis is biased because of a perceived relationship with StrongMinds or an entrenched commitment to mental health as a cause area which compromises the integrity of our research. While I don’t assume that Simon thinks we’ve been paid to reach these conclusions, I think the concern is that we’ve already decided what we think is true, and we aim to prove it.
To be clear, the Happier Lives Institute is an independent, non-profit research institute. We do not, and will not, take money from anyone we do or might recommend. Like every organisation in the effective altruism community, we’re trying to work out how to do the most good, guided by our beliefs and views about the world.
That said, I can see how this confusion may have arisen. We are advocating for a new approach (evaluating impact in terms of subjective wellbeing), we have been exploring a new cause area (mental health), and we currently only recommend one charity (StrongMinds).
While this may seem suspicious to some, the reason is simple: we’re a new organisation that started with a single full-time researcher in 2020 and has only recently expanded to three researchers. We started by comparing psychotherapy to GiveWell’s top charities, but it’s not the limit of our ambitions. It just seemed like the most promising place to test our hypothesis that taking happiness seriously would indicate different priorities. We think StrongMinds is the best giving option, given our research to date, but we are actively looking for other charities that might be as good or better.
In the next few weeks, we will publish cause area exploration reports for reducing lead exposure, increasing immigration, and providing pain relief. We plan to continue looking for neglected causes and cost-effective interventions within and beyond mental health.
4. What can HLI do better in the future?
There are a few things I think HLI could learn from and do better due to Simon’s post and the ensuing discussion around it.
We didn’t explicitly discuss the implausibility of StrongMinds’ headline figures in our work, and, in retrospect, that was an error. We should also have raised these concerns with StrongMinds and asked them to clarify what causal evidence they are relying on. We have done this now and will provide them with more guidance on how they can improve their evidence base and communicate more clearly about their impact.
I also think we can do better at highlighting our key uncertainties, the quality of the evidence we are using in our analysis, and pointing out the places where different priors would lead a reader to update less on our analysis.
Furthermore, I think we can improve how we present our research regarding the cost-effectiveness of psychotherapy and StrongMinds in particular. This is something that we were already considering, but after this giving season, I’ve realised that there are some consistent sources of confusion we need to address.
Despite the limitations of their charity-specific data, we still think StrongMinds should be top-rated. It is the most cost-effective, evidence-backed organisation we’ve assessed so far, even when we compare it to some very plausible alternatives that are currently considered top-rated. That being said, we’ve learned a lot since we published our StrongMinds report in 2021, and there is room for improvement. This year, we plan to update our meta-analysis and cost-effectiveness analysis of psychotherapy and StrongMinds with new evidence and more robustness checks for Giving Season 2023.
If you think there are other ways we can improve, then please respond to our annual impact survey which closes at 8 am GMT on Monday 30 January. We look forward to refining our approach in response to valuable, constructive feedback.








Thanks for this, Joel. I look forward to reviewing the analysis more fully over the weekend, but I have three major concerns with what you have presented here.
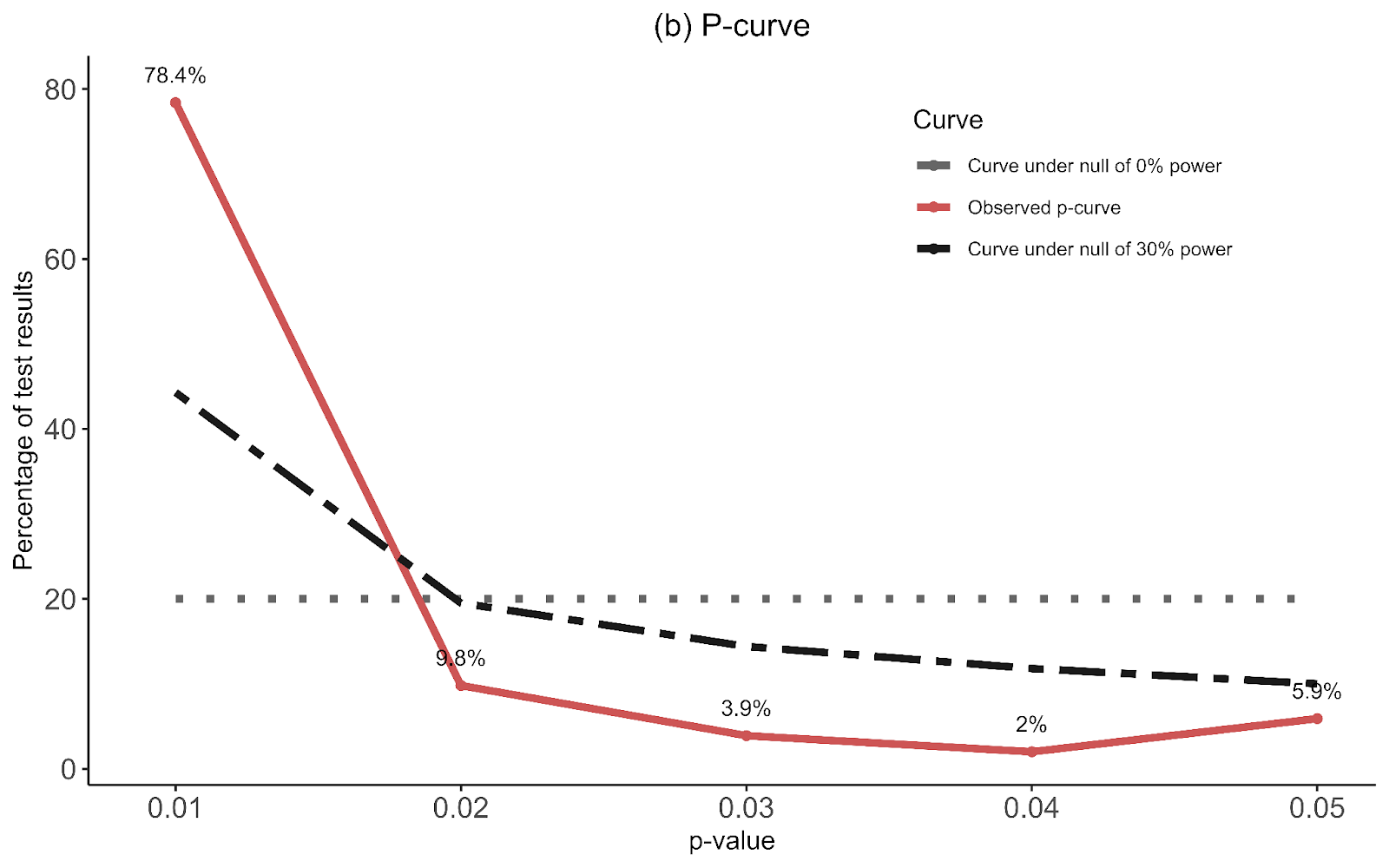
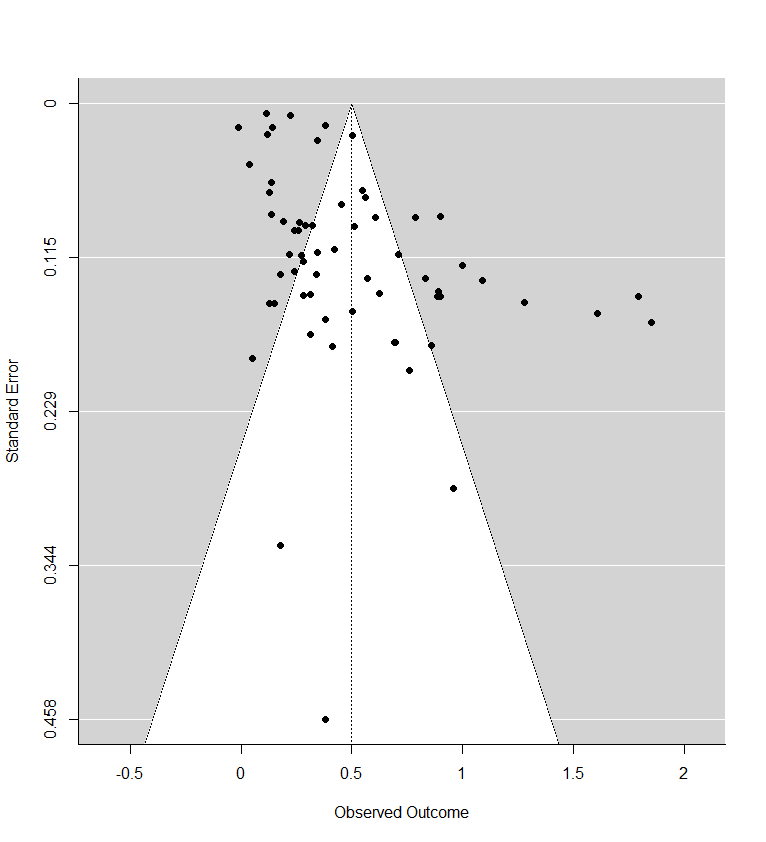
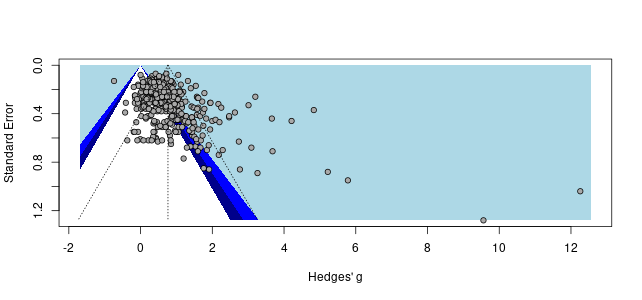
1. A lot of these publication bias results look like nonsense to the naked eye.
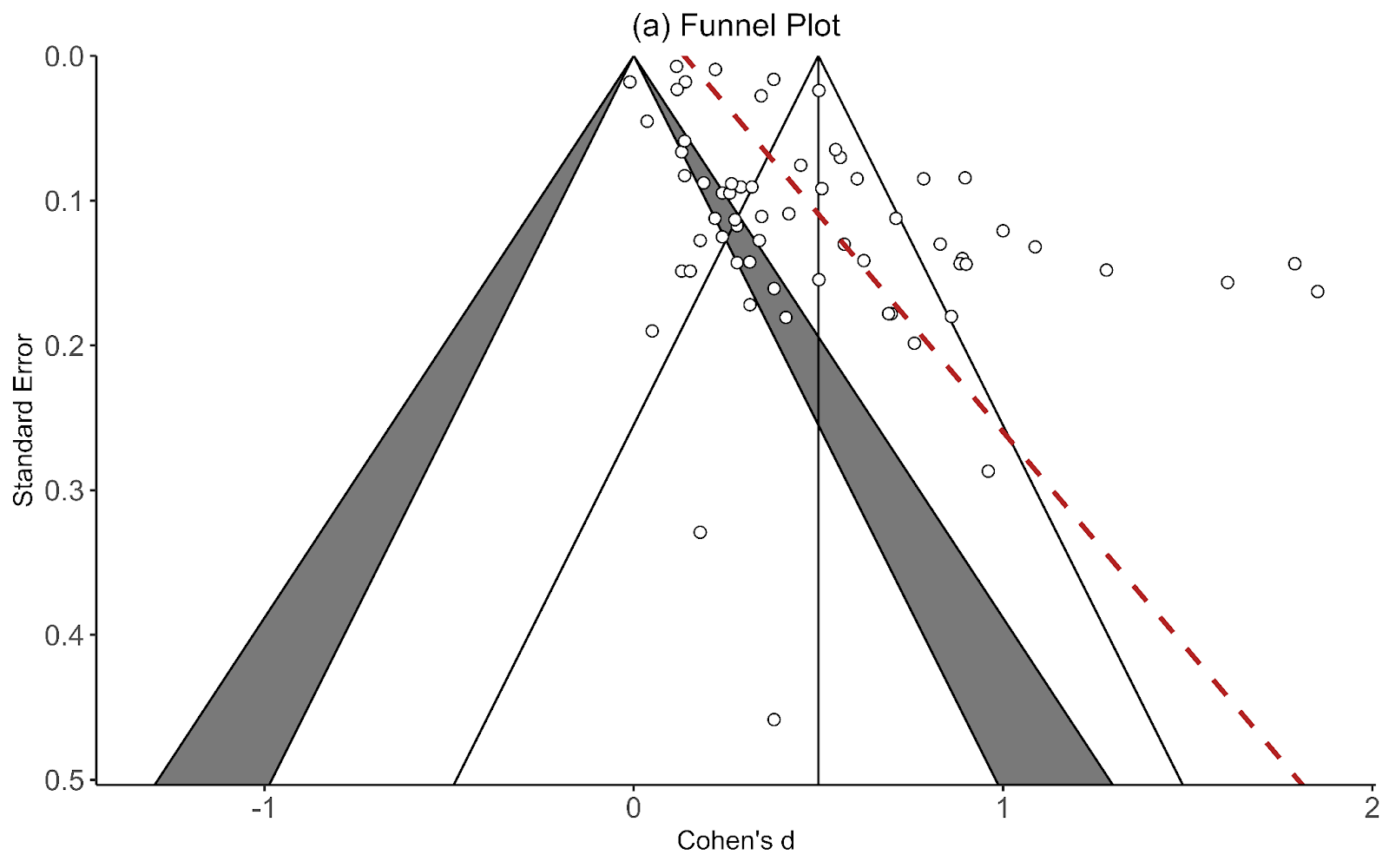
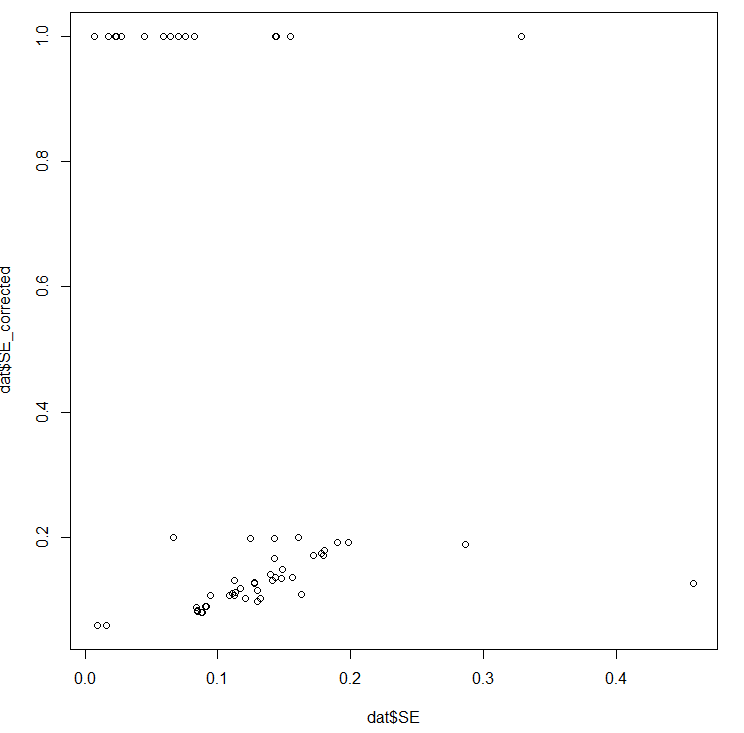
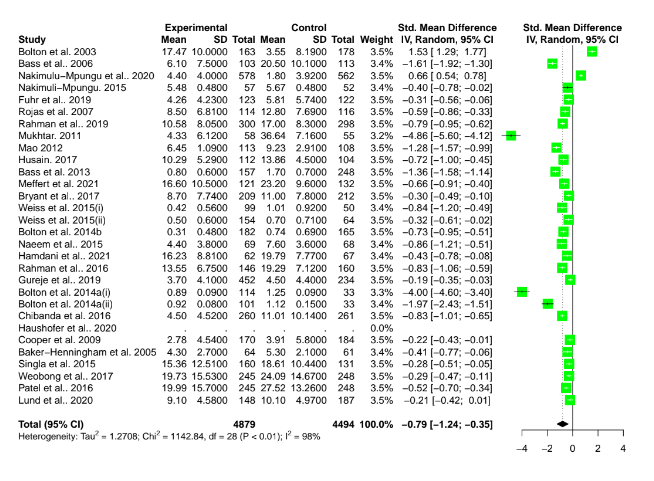
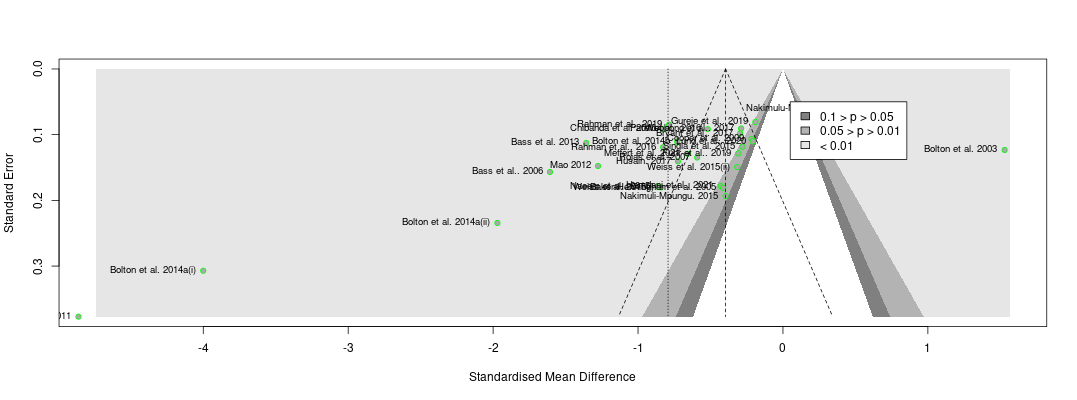
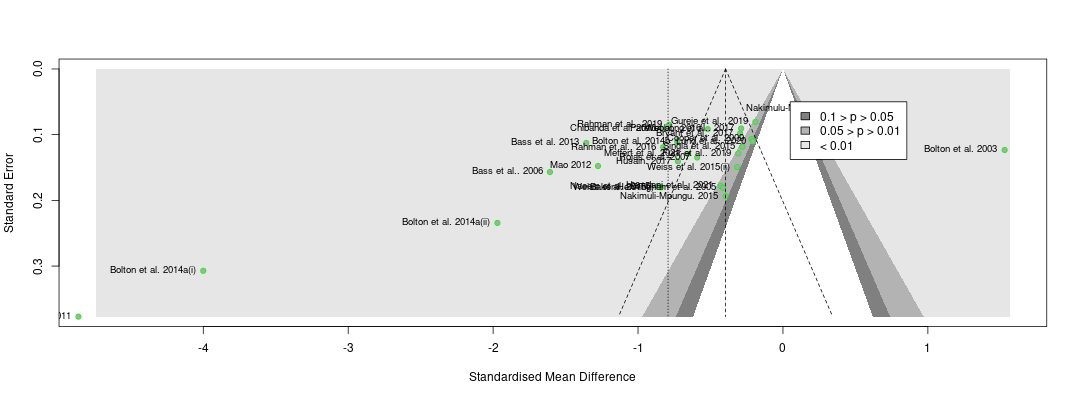
Recall the two funnel plots for PT and CT (respectively):
I think we're all seeing the same important differences: the PT plot has markers of publication bias (asymmetry) and P hacking (clustering at the P<0.05 contour, also the p curve) visible to the naked eye; the CT studies do not really show this at all. So heuristically, we should expect statistical correction for small study effects to result in:
If a statistical correction does the opposite of these things, I think we should say its results are not just 'surprising' but 'unbelievable': it just cannot be true that, given the data we see being fed into the method it should lead us to conclude this CT literature is more prone to small-study effects than this PT one; nor (contra the regression slope in the first plot), the effect size for PT should be corrected upwards.
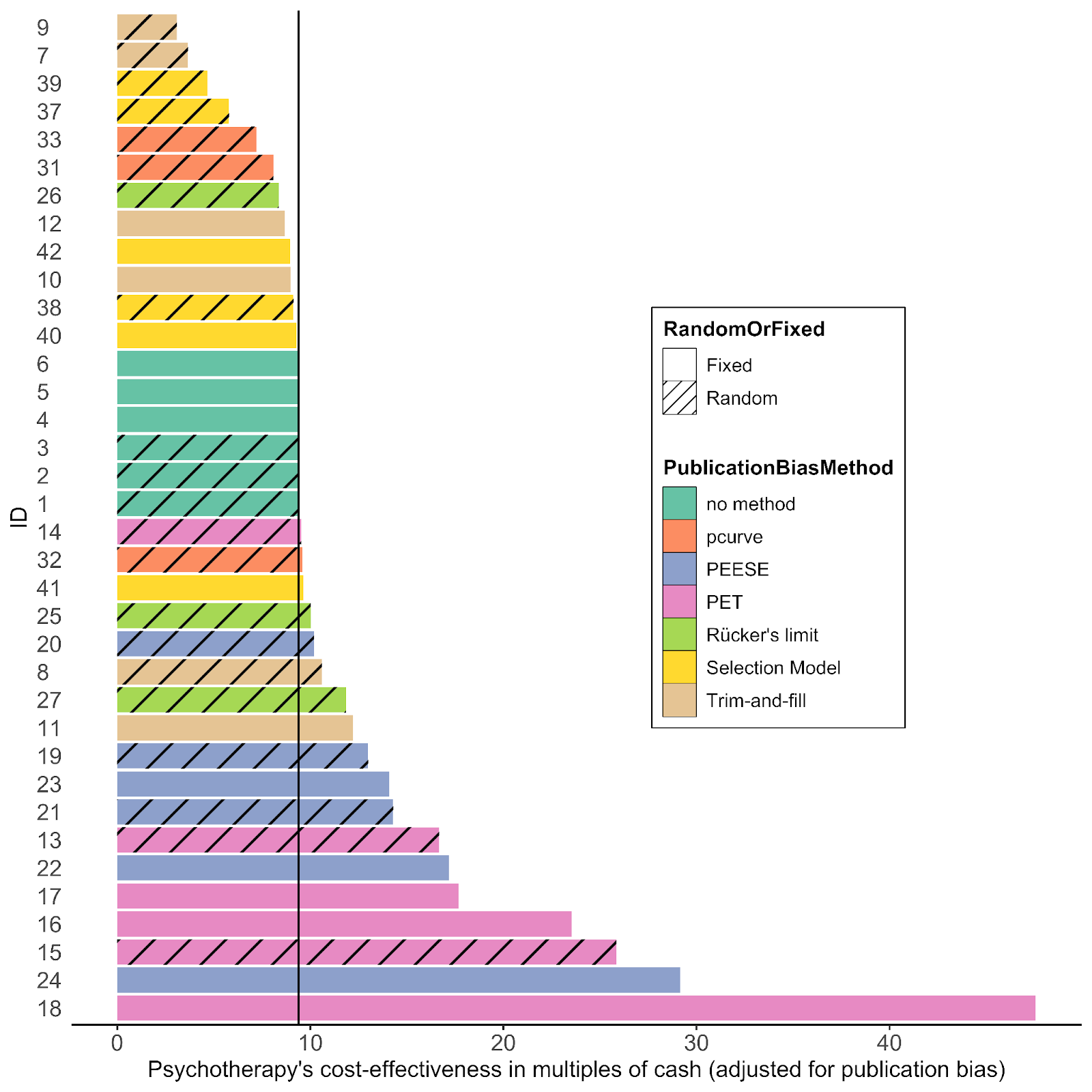
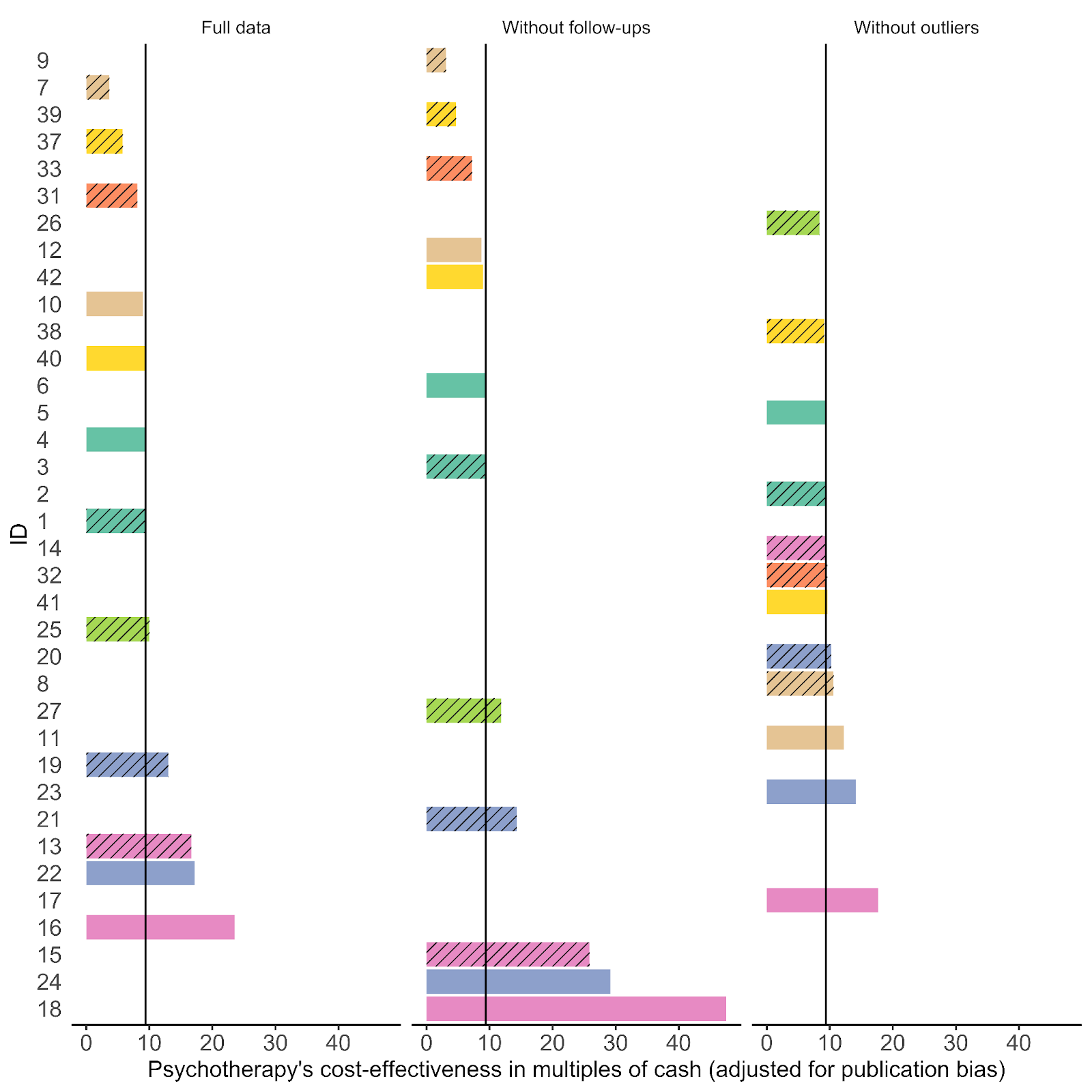
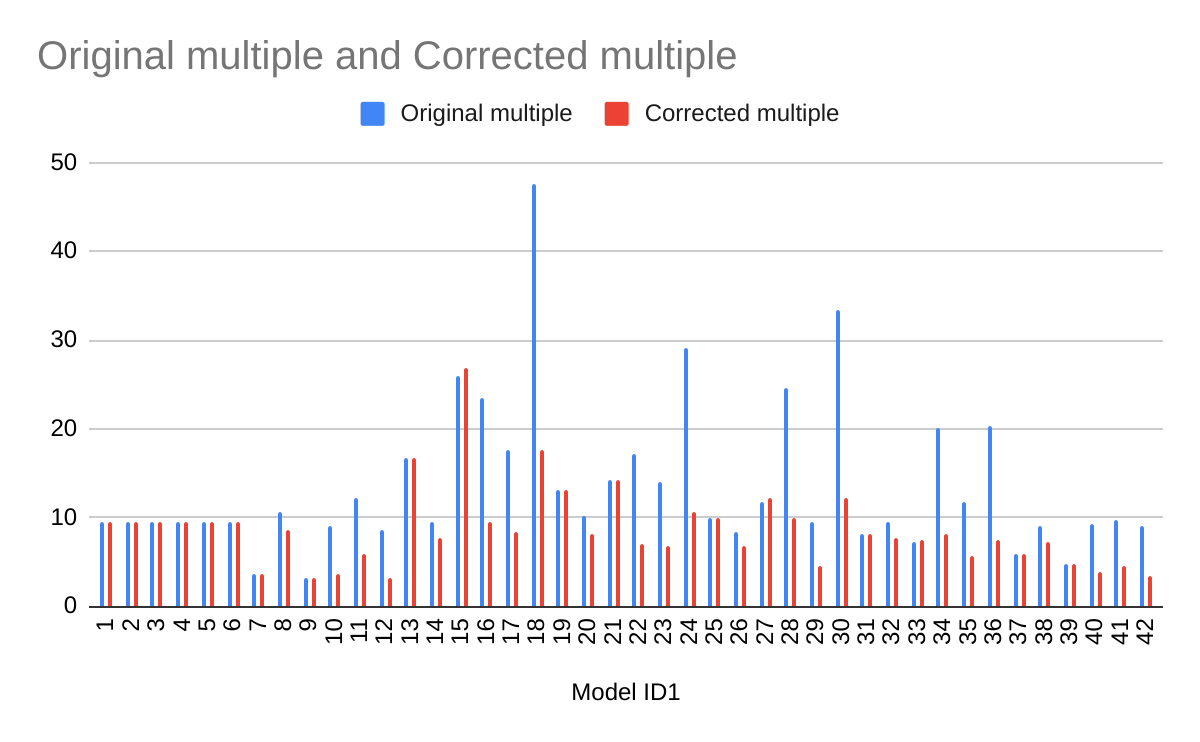
Yet many of the statistical corrections you have done tend to fail one or both of these basically-diagnostic tests of face validity. Across all the different corrections for PT, on average the result is a 30% increase in PT effect size (only trim and fill and selection methods give families of results where the PT effect size is reduced). Although (mostly) redundant, these are also the only methods which give a larger drop to PT than CT effect size.
As comments everywhere on this post have indicated, heterogeneity is tricky. If (generally) different methods all gave discounts, but they were relatively small (with the exception of one method like a Trim and Fill which gave a much steeper one), I think the conclusions you drew above would be reasonable. However, for these results, the ones that don't make qualitative sense should be discarded, and the the key upshot should be: "Although a lot of statistical corrections give bizarre results, the ones which do make sense also tend to show significant discounts to the PT effect size".
2. The comparisons made (and the order of operations to get to them) are misleading
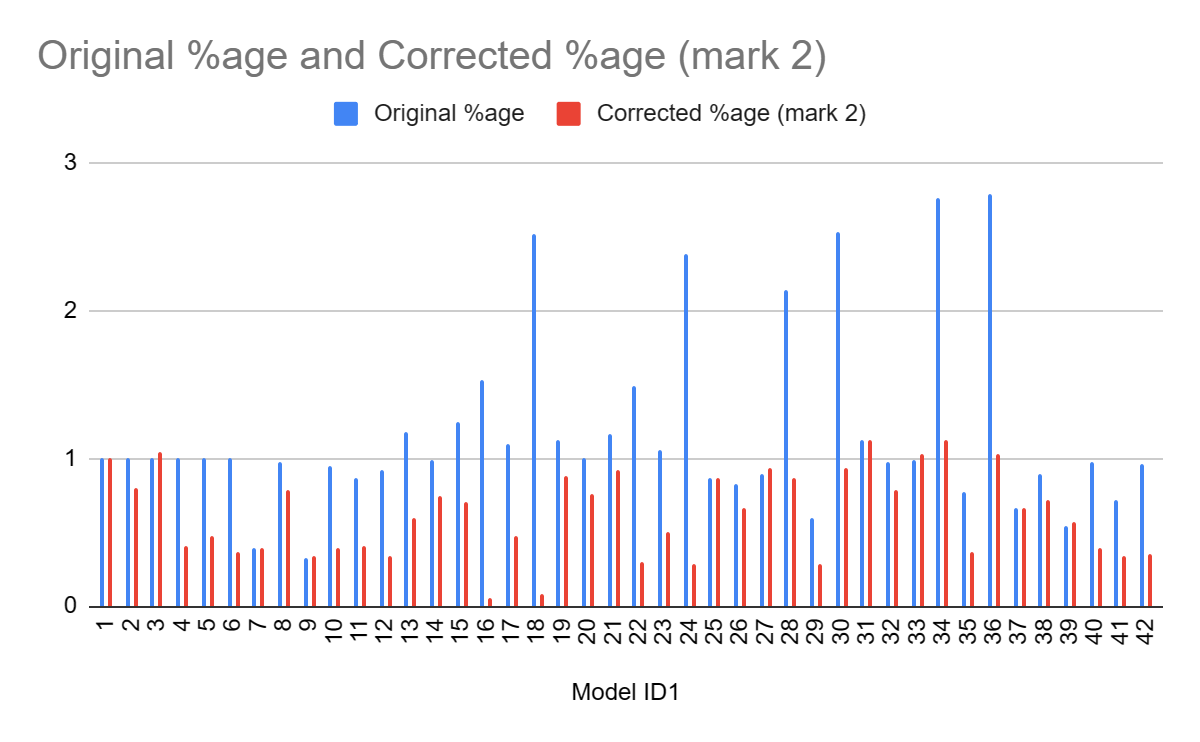
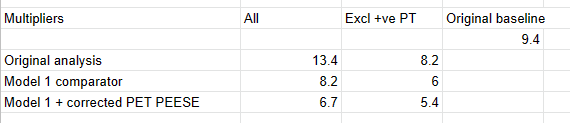
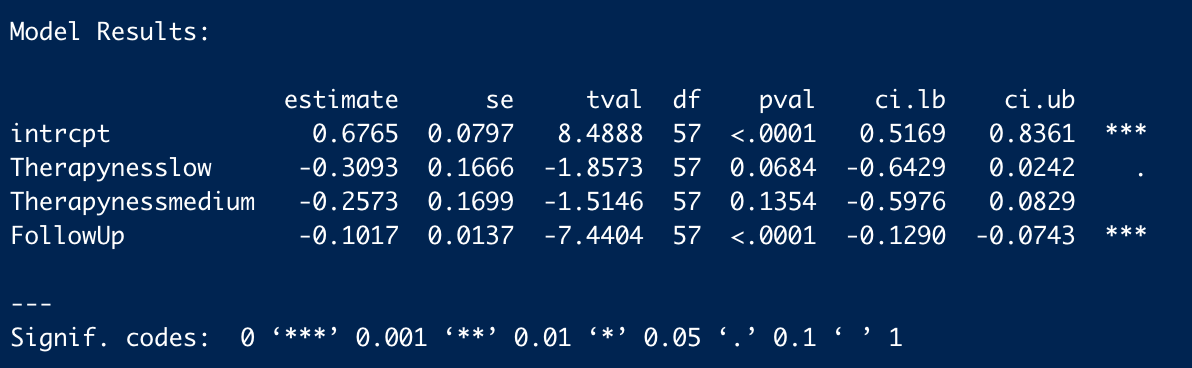
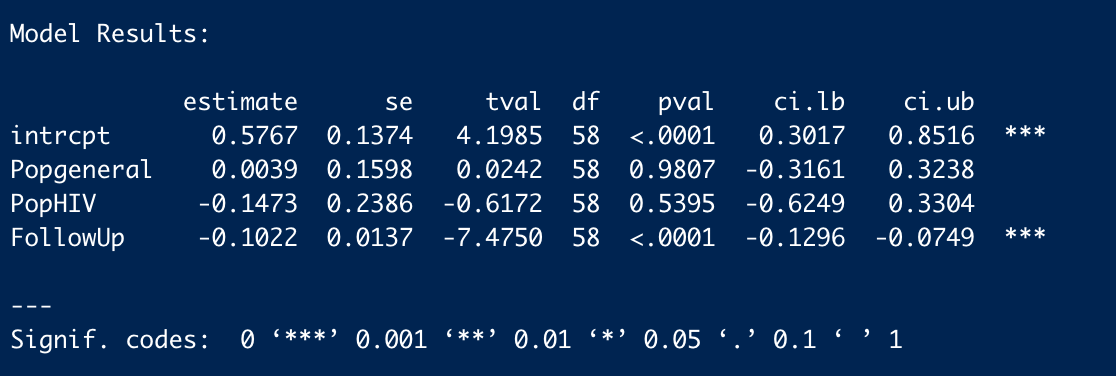
What is interesting though, is although in % changes correction methods tend to give an increase to PT effect size, the effect sizes themselves tend to be lower: the average effect size across analyses is 0.36, ~30% lower than the pooled estimate of 0.5 in the funnel plot (in contrast, this is 0.09 - versus 0.1, for CT effect size).
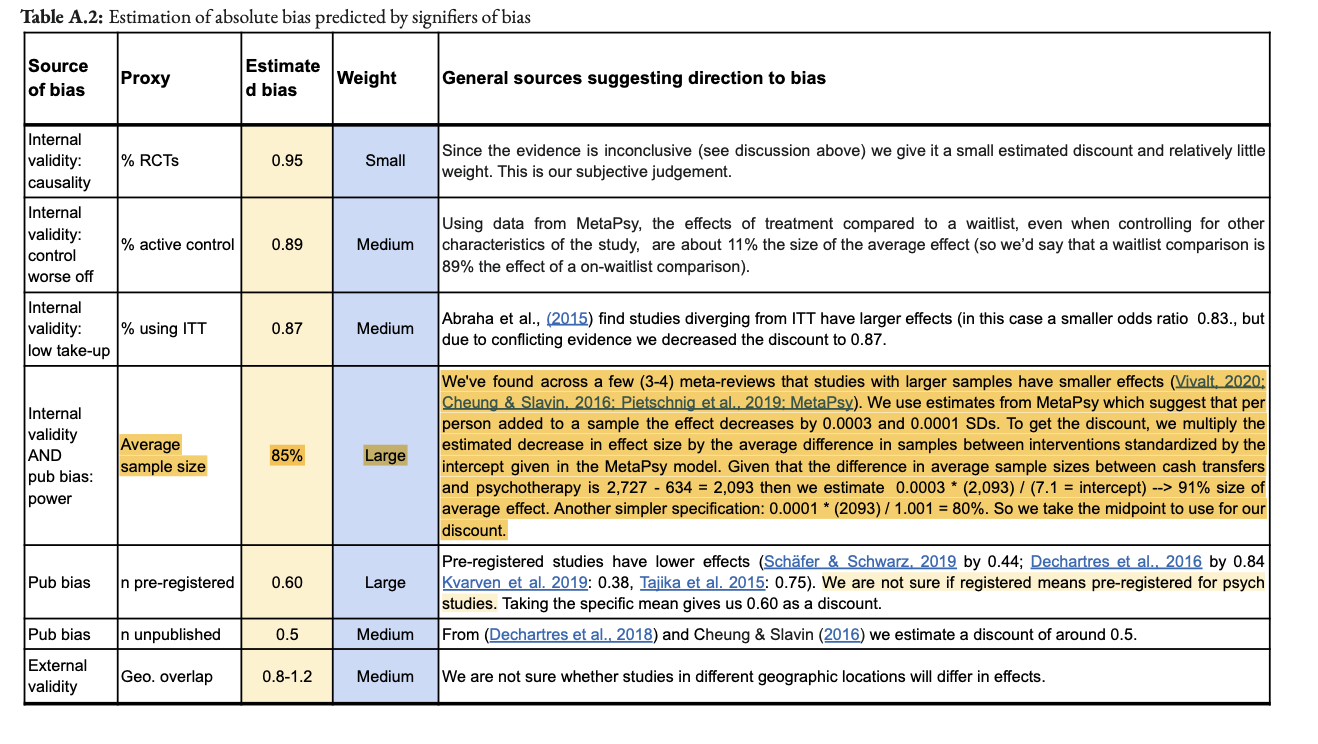
This is the case because the % changes are being measured, not against the single reference value of 0.5 in the original model, but the equivalent model in terms of random/fixed, outliers/not, etc. but without any statistical correction technique. For example: row 13 (Model 10) is Trim-and-Fill correction for a fixed effect model using the full data. For PT, this effect size is 0.19. The % difference is calculated versus row 7 (Model 4), a fixed effect model without Trim-and-Fill (effect = 0.2) not the original random effects analysis (effect = 0.5). Thus the % of reference effect is 95% not 40%. In general, comparing effect sizes to row 4 (Model ID 1) generally gets more sensible findings, and also generally more adverse ones. re. PT pub bias correction:
In terms of (e.g.) assessing the impact of Trim and Fill in particular, it makes sense to compare like with like. Yet presumably what we care about to ballparking the estimate of publication bias in general - and for the comparisons made in the spreadsheet mislead. Fixed effect models (ditto outlier exclusion, but maybe not follow-ups) are already an (~improvised) means of correcting for small study effects, as they weigh them in the pooled estimate much less than random effects models. So noting Trim-and-Fill only gives a 5% additional correction in this case buries the lede: you already halved the effect by moving to a fixed effect model from a random effect model, and the most plausible explanation why fixed effect modelling limits distortion by small study effects.
This goes some way to explaining the odd findings for statistical correction above: similar to collider/collinearity issues in regression, you might get weird answers of the impact of statistical techniques when you are already partly 'controlling for' small study effects. The easiest example of this is combining outlier removal with trim and fill - the outlier removal is basically doing the 'trim' part already.
It also indicates an important point your summary misses. One of the key stories in this data is: "Generally speaking, when you start using techniques - alone or in combination - which reduce the impact of publication bias, you cut around 30% of the effect size on average for PT (versus 10%-ish for CT)".
3. Cost effectiveness calculation, again
'Cost effectiveness versus CT' is a unhelpful measure to use when presenting these results: we would first like to get a handle on the size of the small study effect in the overall literature, and then see what ramifications it has for the assessment and recommendations of strongminds in particular. Another issue is these results doesn't really join up with the earlier cost effectiveness assessment in ways which complicate interpretation. Two examples:
More important than this, though, is the 'percentage of what?' issue crops up again: the spreadsheet uses relative percentage change to get a relative discount vs. CT, but it uses the wrong comparator to calculate the percentages.
Lets look at row 13 again, where we are conducting a fixed effects analysis with trim-and-fill correction. Now we want to compare PT and CT: does PT get discounted more than CT? As mentioned before, for PT, the original random effects model gives an effect size of 0.5, and with T'n'F+Fixed effects the effect size is 0.19. For CT, the original effect size is 0.1, and with T'n'F +FE, it is still 0.1. In relative terms, as PT only has 40% of the previous effect size (and CT 100% of the effect size), this would amount to 40% of the previous 'multiple' (i.e. 3.6x).
Instead of comparing them to the original estimate (row 4), it calculates the percentages versus a fixed effect but not T'n'F analysis for PT (row 7). Although CT here is also 0.1, PT in this row has an effect size of 0.2, so the PT percentage is (0.19/0.2) 95% versus (0.1/0.1) 100%, and so the calculated multiple of CT is not 3.6 but 9.0.
The spreadsheet is using the wrong comparison, as we care about whether the multiple between PT and CT is sensitive to different analyses, relative sensitivity to one variation (T'n'F) conditioned on another (fixed effect modelling). Especially when we're interested in small study effects and the conditioned on effect likely already reduces those.
If one recalculates the bottom line multiples using the first model as the comparator, the results are a bit less weird, but also more adverse to PT. Note the effect is particularly reliable for T'n'F (ID 7-12) and selection measures (ID 37-42), which as already mentioned are the analysis methods which give qualitatively believable findings.
Of interest, the spreadsheet only makes this comparator error for PT: for CT, whether all or lumped (column I and L) makes all of its percentage comparisons versus the original model (ID 1). I hope (and mostly expect) this is a click-and-drag spreadsheet error (or perhaps one of my understanding), rather than my unwittingly recovering an earlier version of this analysis.
Summing up
I may say more next week, but my impressions are