AI Safety Support conducted surveys to people they had worked with previously.
Actually, most people where not people we engaged with before. We spread the survey as wide as we could.
Half of them came from Rob Miles audience, or that's my estimate based on timing of responses.
But thanks for analysing our data!
I never got around to it, since I had to leave AISS a few months later, under pretty bad circumstances (which was not the fault of anyone working for AISS!)
Another interesting result of that survey was that a substantial fraction of applicants wanted some type of help or resource that did already existed but which they were unaware of. I can't remember now what percentage of applicants this was, but I think it was something in the range 20%-70%
Wonderful to see an analysis of all this even more wonderful data coming out of the programs! We're also happy to share our survey results (privately and anonymized) with people interested:
Demographic, feedback, AIS attitudes before and after an Alignment Jam (for the first and second versions)
A 70 respondent in-depth survey on attitudes towards AI risk arguments (basically, "what converted you")
An AI safety pain points survey that was also done in-person with several top AIS researchers
An AI safety progress survey about P(doom)s etc.
We also have a few other surveys but the ones above are probably most interesting in the context of this post.
Very confused why people have downvoted here? Please explain why, if possible. And context: I've also started a private chat about the data with Peter and Ash.
Analysis of AI Safety surveys for field-building insights — EA Forum
Analysis of AI Safety surveys for field-building insights
To help grow the pipeline of AI safety researchers, I conducted a project to determine how demographic information (e.g. level of experience, exposure to AI arguments) affects AI researchers’ responses to AI safety. In addition, I examined additional AI safety surveys to uncover current issues preventing people from becoming AI safety researchers. Specifically, I analyzed the publicly-available data from the AI Impacts survey and also asked AI Safety Support and AGI Safety Fundamentals for their survey data (huge thank you to all three organizations). Below are my results, which I hope will be informative to future field-building efforts.
This work was done as part of the AI Safety Field-Building Hub; thanks to Vael Gates for comments and support. Comments and feedback are very welcome, and all mistakes are my own.
TLDR
AI Impacts
The following researchers tended to be more sympathetic to AI Alignment research:
Researchers with <=5 years of experience
Researchers who attended undergraduate universities in North America
Researchers who had thought extensively about HLMI (high-level machine intelligence) and/or about HLMI’s societal impacts
AI safety support
Surprisingly, academics were less concerned with funding compared to industry professionals.
AGISF
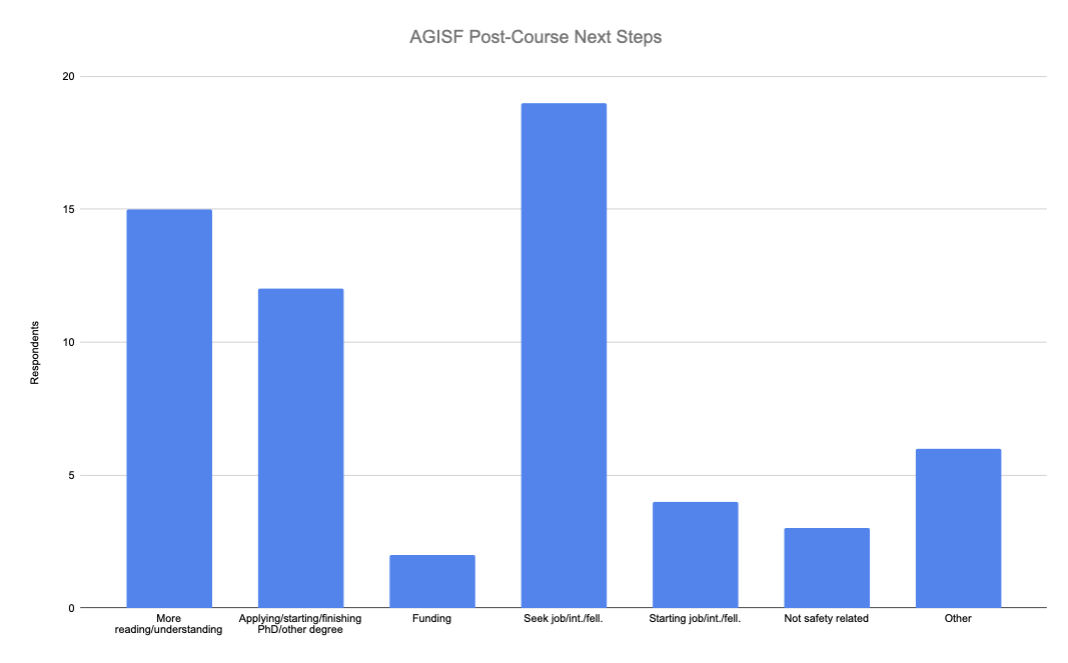
The vast majority of respondents said their post-course next steps would be seeking a job, internship, or fellowship. More "reading and understanding" was also cited heavily as was "applying, starting, or finishing" a PhD or other degree program.
Surprisingly, only 2/61 participants said they would seek funding.
Other sources
In speaking with researchers, there are wide views on everything from AGI timelines to the importance of AI alignment research. A few things were considered very helpful:
1) Explaining rather than convincing
2) Being open to questions and not dismissing criticism
3) Sharing existing research papers
Data
AI Impacts
The survey ran from June-August 2022 with participants representing a wide range of machine learning researchers. Note: error bars are standard error for proportions.
Summary
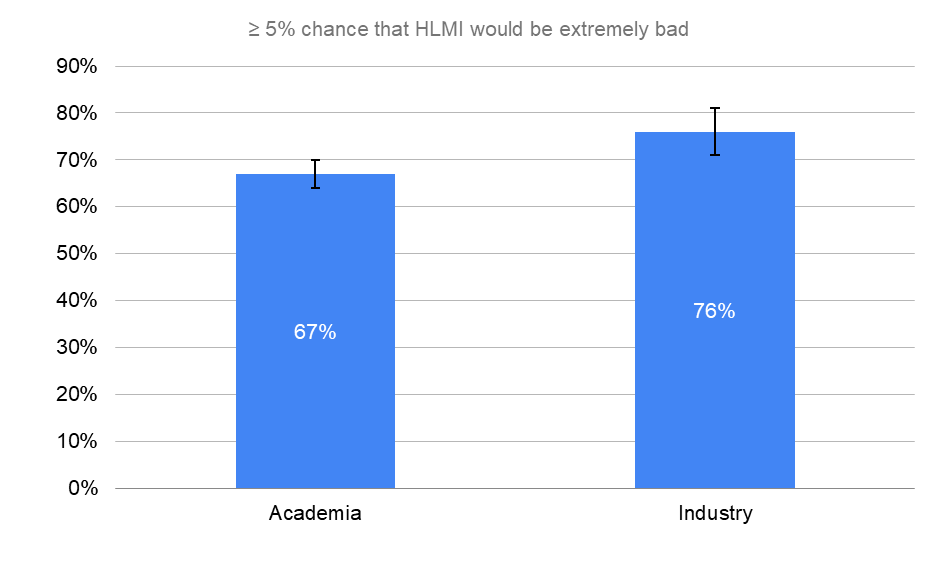
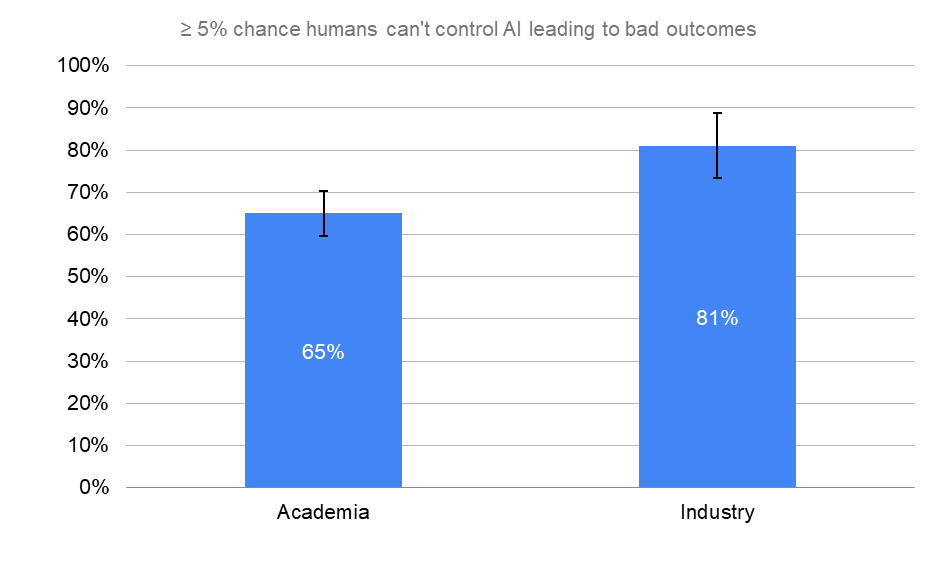
Academia was significantly more concerned about the existential risk as compared to industry. However, industry was significantly more concerned with human inability to control AI as compared to academia. Moreover, industry is somewhat more aggressive on HLMI timelines (not a huge surprise).
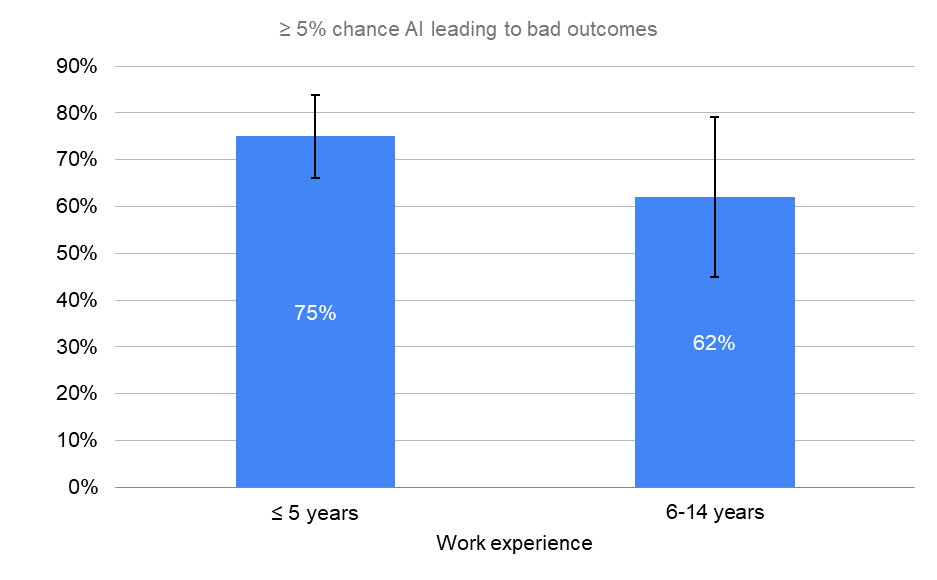
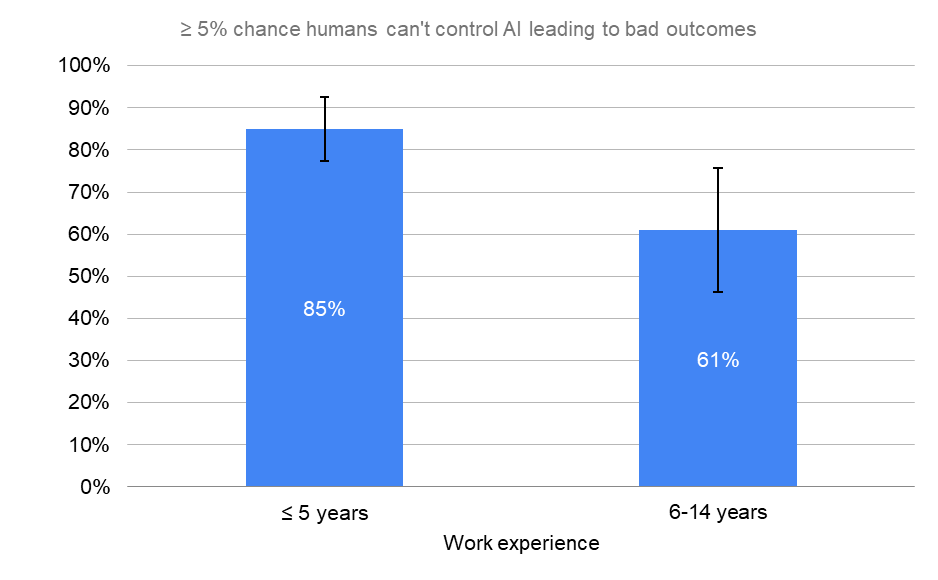
Junior researchers (<=5 years of experience) believe the risks of HLMI are greater than more seasoned professionals.
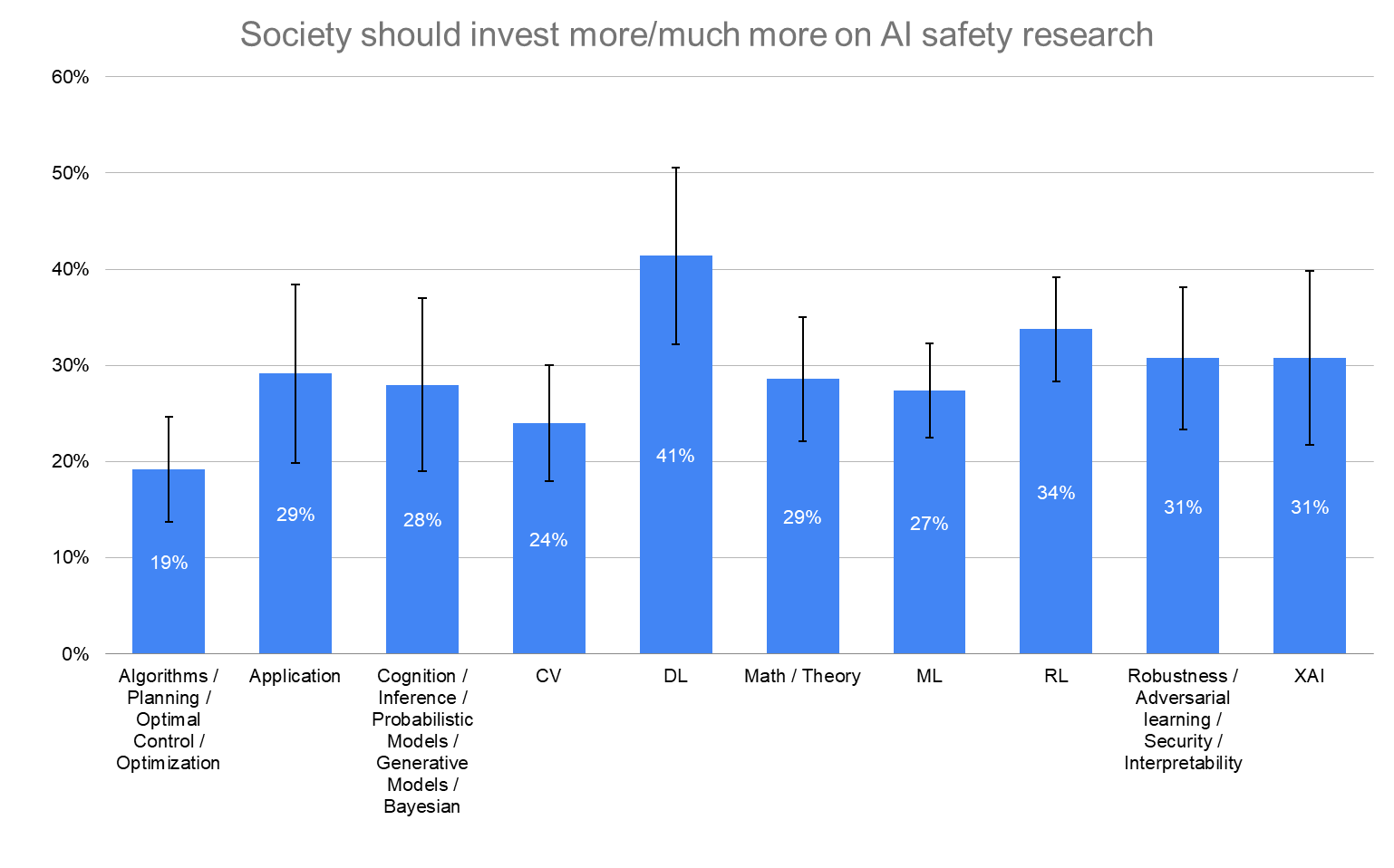
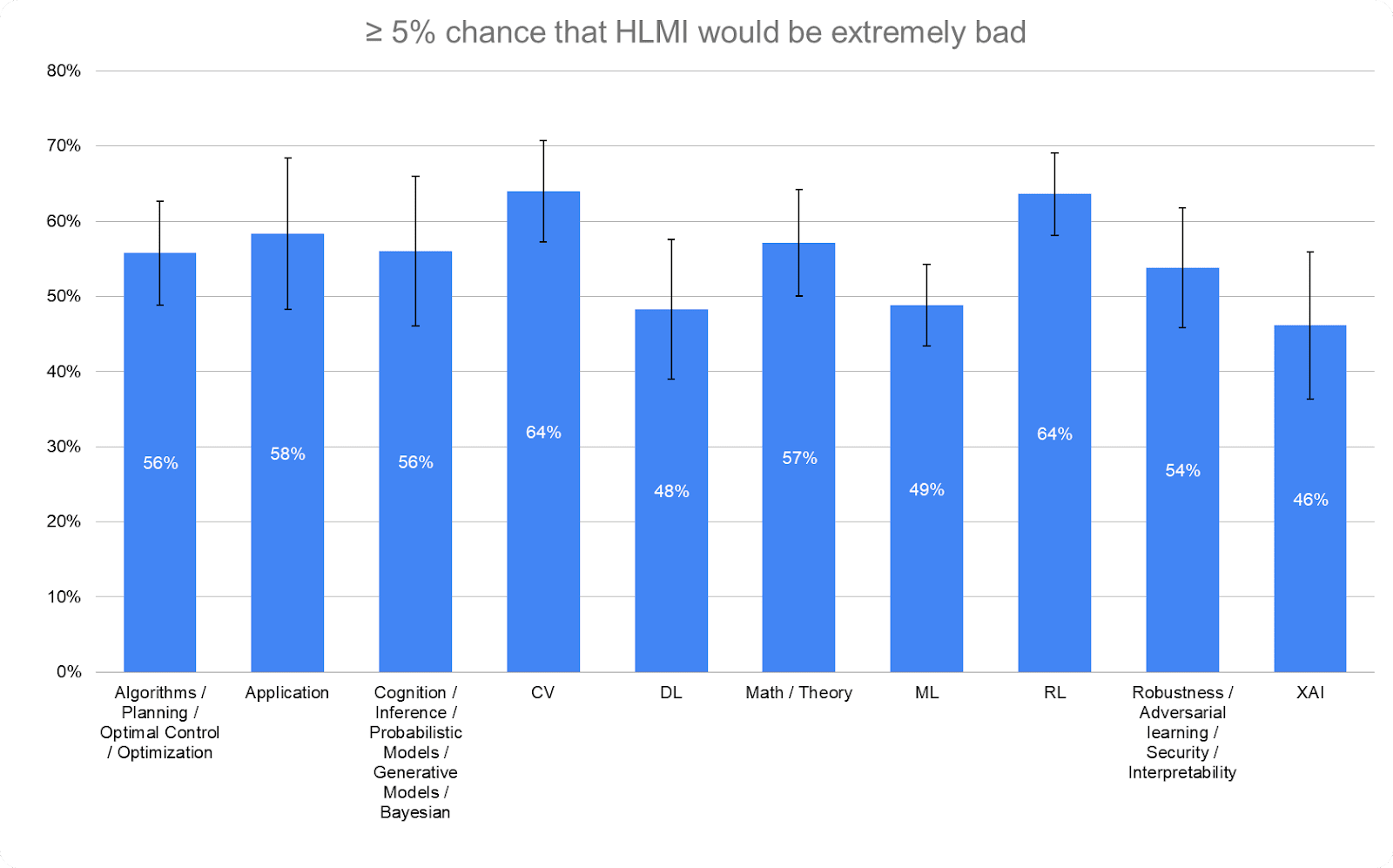
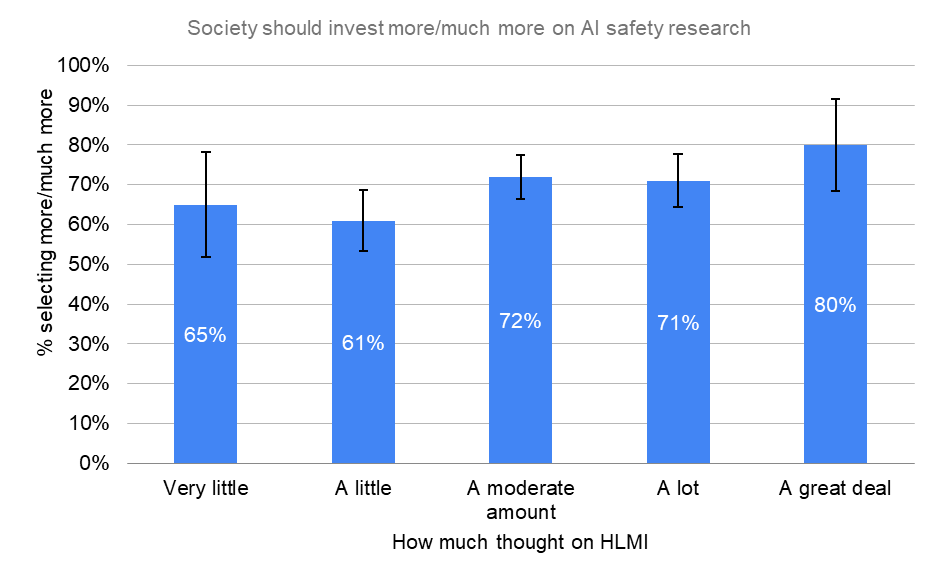
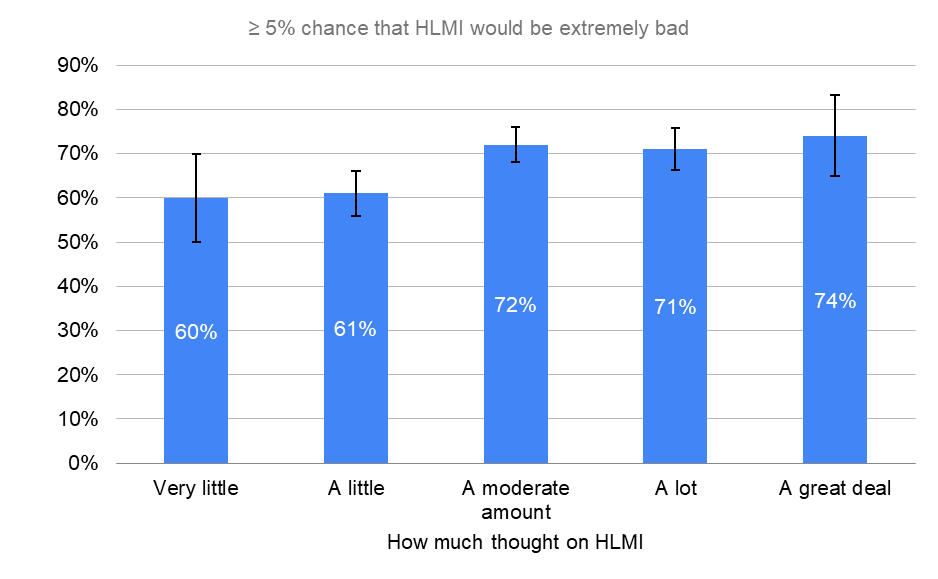
The more researchers had thought about HLMI, the more they believed in both an increase in prioritization and the existential risks.
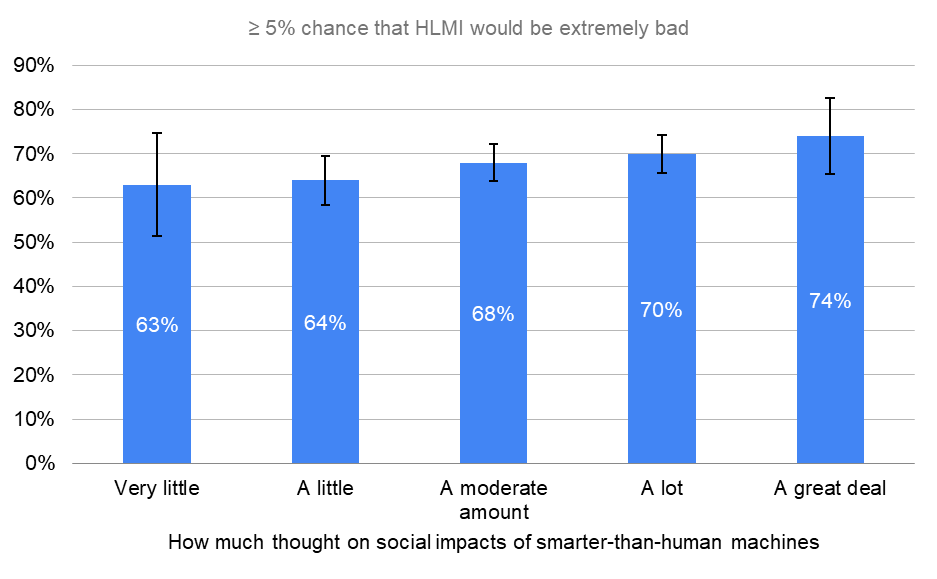
The more researchers had thought about the societal implications of HLMI, the more they believed in both an increase in prioritization and the existential risks.
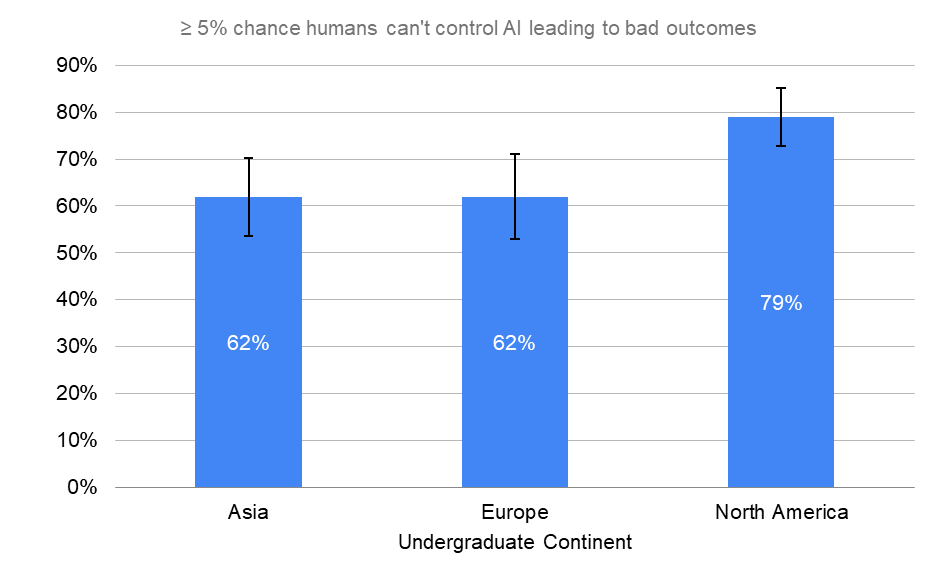
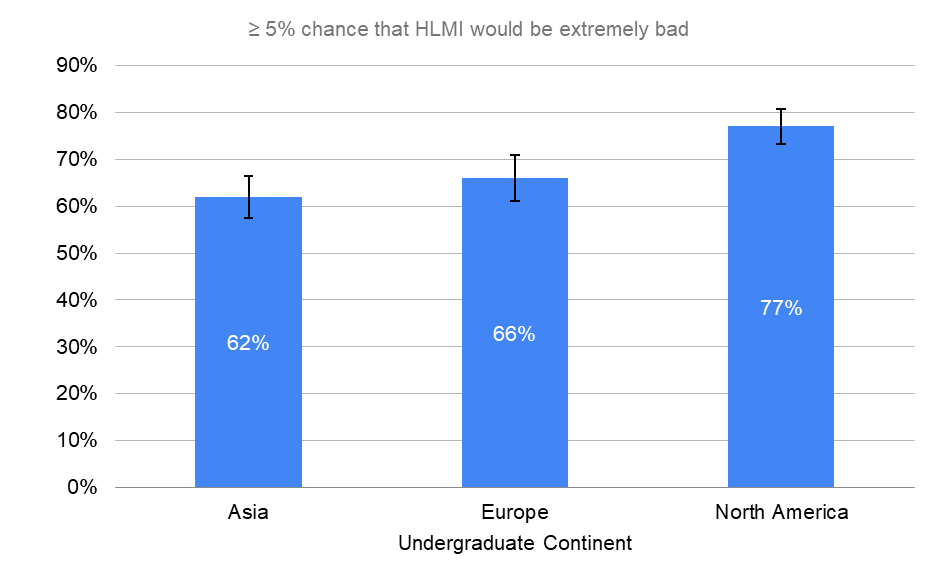
Researchers who attended undergraduate universities in North America had significantly higher probabilities of HLMI turning bad as compared to those who attended European or Asian universities.
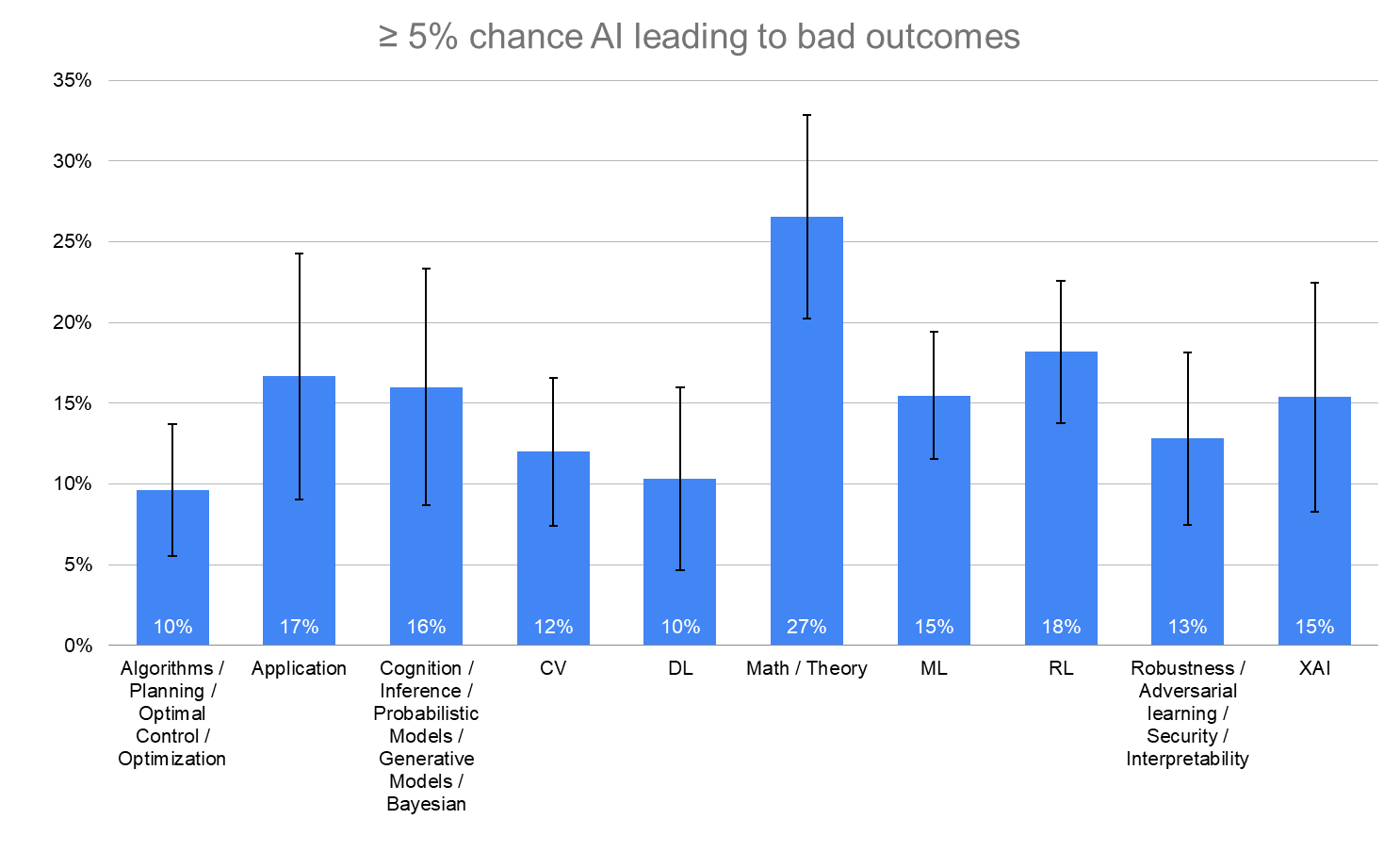
XAI = Trustworthy / Ethical AI / Fairness / AI Safety (short-term)
Application = Application / product (does not include autonomous driving) / data analysis
Note: This section is quite rough; Vael manually categorized these (not an expert in the field) very quickly, and Ash selected the first sub-speciality of the labels to make this graph."
By Time in Career
By How Much Thought to HLMI
By How Much Thought to Social Impacts of Smarter-Than-Human Machine
By Undergraduate Continent
The full questions used in the survey for the graphs above were:
≥ 5% chance that HLMI would be extremely bad
“Assume for the purpose of this question that HLMI will at some point exist. How probable do you find the overall extremely bad impact on humanity (e.g. human extinction), in the long run?”
Society should invest more/much more on AI safety research
“How much should society prioritize AI safety research, relative to how much it is currently prioritized?”
≥ 5% chance AI leading to bad outcomes
“What probability do you put on future AI advances causing human extinction or similarly permanent and severe disempowerment of the human species?”
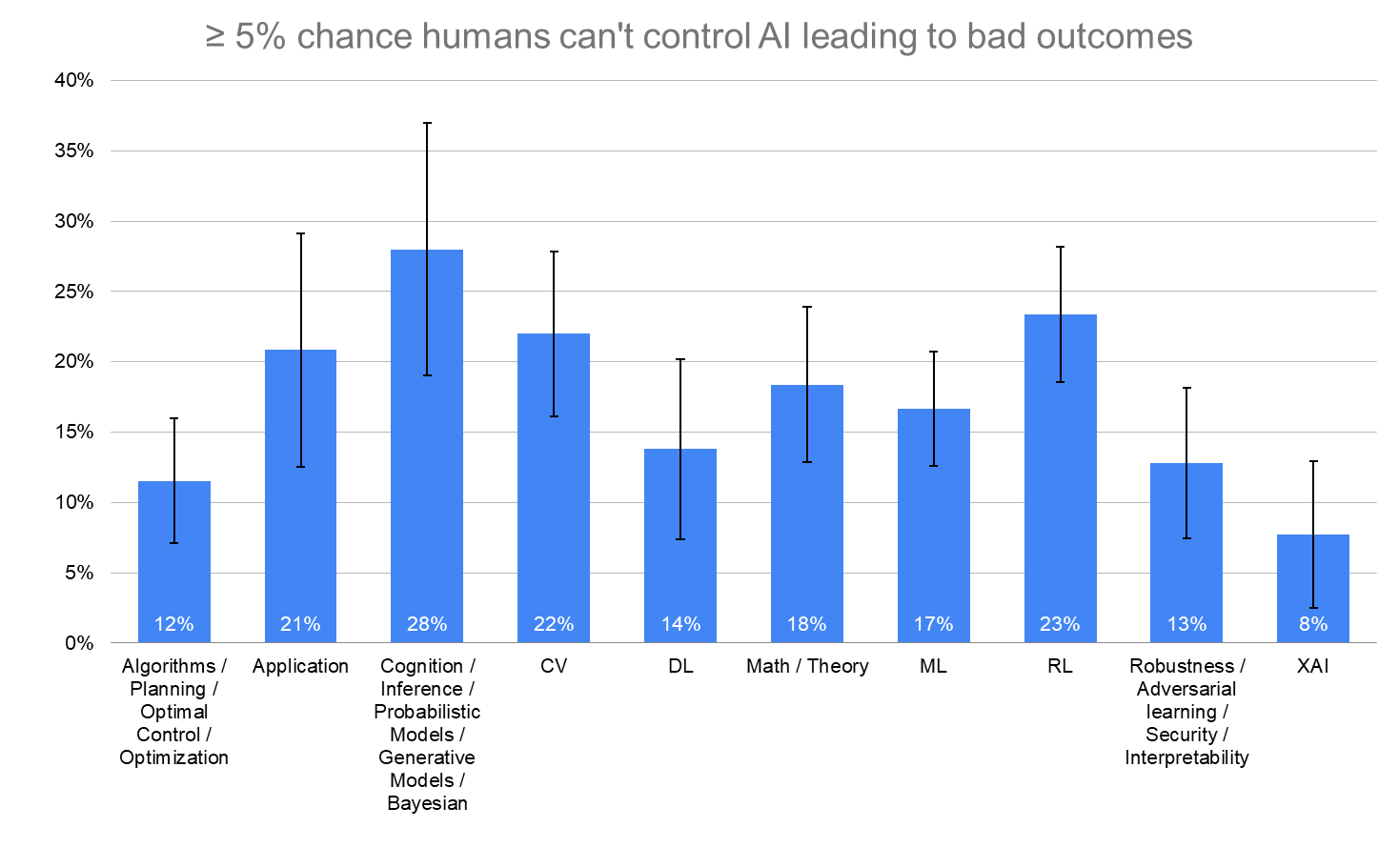
≥ 5% chance humans can't control AI leading to bad outcomes
“What probability do you put on human inability to control future advanced AI systems causing human extinction or similarly permanent and severe disempowerment of the human species?”
Error bars represent the standard error of the proportion.
AI Safety Support
AI Safety Support conducted a broad survey to those interested in AI safety. One limitation to this data is that it's from early 2021. Since then, new programs have come into existence that may slightly change the responses if they were provided today.
Summary
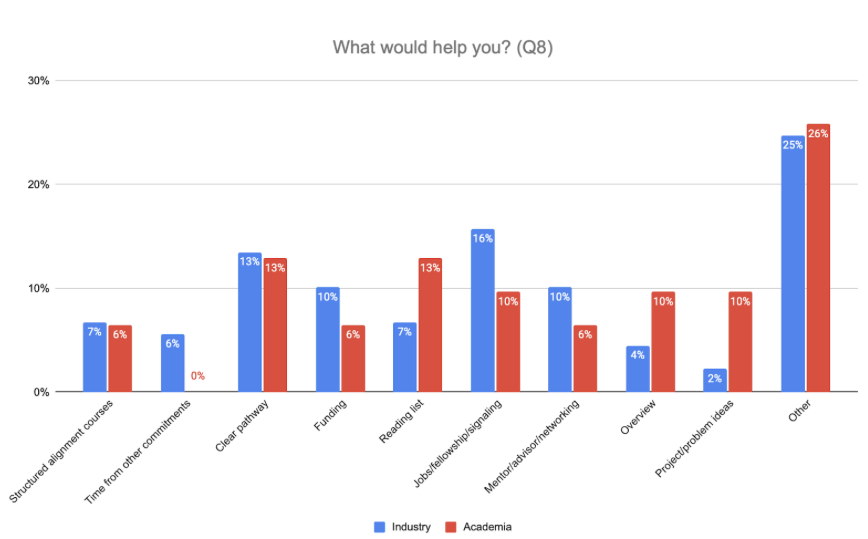
Surprisingly, academics were less concerned with funding compared to industry professionals.
Academics were much more interested in reading list, overview, and project/problem ideas compared to industry professionals.
Industry professionals were much more interested about jobs, internships, fellowships, and signaling value.
Note: The line between industry and academia can be blurry with overlap. However, the question specifically asked, "What best describes your current situation".
What information are you missing?
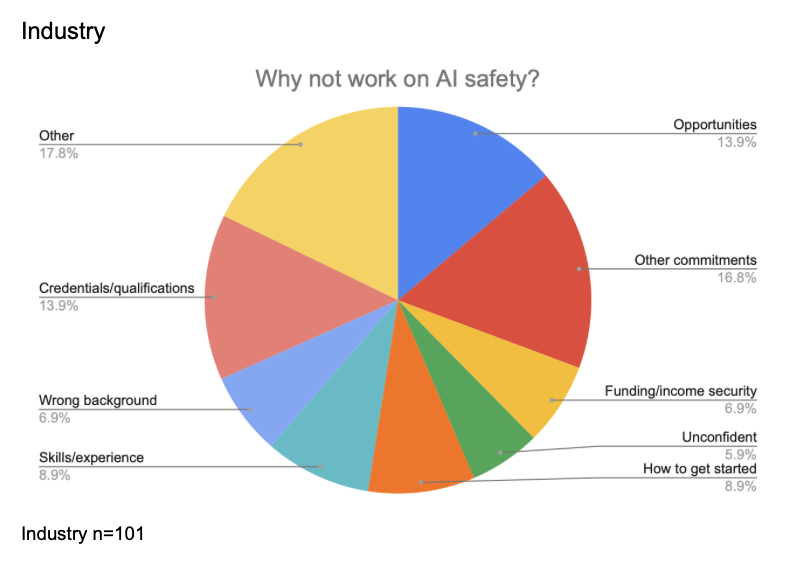
Industry n=38, Academia n=27
What would help you?
Industry n=89, Academia n=31
Why not work on AI safety?
AGISF
The AGISF survey was announced on LessWrong and taken by a broad range of people.
Summary
The vast majority of respondents said their post-course next steps would be seeking a job, internship, or fellowship. More "reading and understanding" was also cited heavily as was "applying, starting, or finishing" a PhD or other degree program.
Surprisingly, only 2/61 said they would seek funding.
n=61
Additional
Vael Gates's postdoc research
In their postdoctoral work, Vael Gates interviewed close to 100 researchers about their perceptions of AI safety. Vael recently shared their talk describing these results. Key findings include:
Very surprisingly, only 39% of researchers had heard of AI alignment.
In terms of whether they would work on AI alignment, there was a mixed response. Some said they think it is important and will work on it, or that they tried working on it in the past. Others felt they are unqualified to work on it, or that there needs to be more literature on the subject matter.
Participants had a very wide range of AGI timelines (similar to the AI Impacts findings).
Participants had a wide range of views regarding the alignment problem. From believing it is valid, to believing it will only be relevant a long time from now, to not placing any credence on it.
Marius Hobbhahn's post
Marius Hobbhahn is a current PhD student who has spoken to more than 100 academics about AI Safety. He recently posted his takeaways.
His findings largely corroborate what we saw from the above sources (especially Vael Gates' post-doc research) e.g.
Academics with less experience are more sympathetic to the AI safety and existential risk concerns.
In conversations with people, explain rather than try to convince.
Be open to questions and don't dismiss criticism.
Existing papers that are validated within the academic community are super helpful starting points to send to researchers.
Limitations
These studies are not randomized control studies, nor have they been exposed to rigorous analytical examination. The knowledge repository is meant to provide directional understanding and subject to change as the community learns more.
Sample sizes on some questions are 100+, but on a few questions are smaller. I included everything with 30 or more responses.
As mentioned previously, the AI Safety Support survey was conducted in early 2021. Since then, new programs have come online and if the survey was to be repeated it might produce slightly different results.
Conclusion
I hope sharing my findings with the larger community will help build and grow the pipeline of AI safety and alignment research. This corpus of data is meant as a starting point. It will evolve as new programs and organizations sprout up to help solve some of these existing issues. AGI capability progress and funding will also be paramount in how views change going forward.
If you have any questions, please leave a comment below.
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...
TLDR; To help the effective animal advocacy movement cost-effectively absorb greater amounts of funding in the near future, we are seeking expressions of interest from people who could found a new organization focused on:
* Highly neglected animals: insects, wild animals, shrimp, fish, etc, or
* AI and animals: AI alignment and governance for animal welfare, strategic actions considering transformative AI, AI for wild animals, etc.
* ...
 By Time in Career
By Time in Career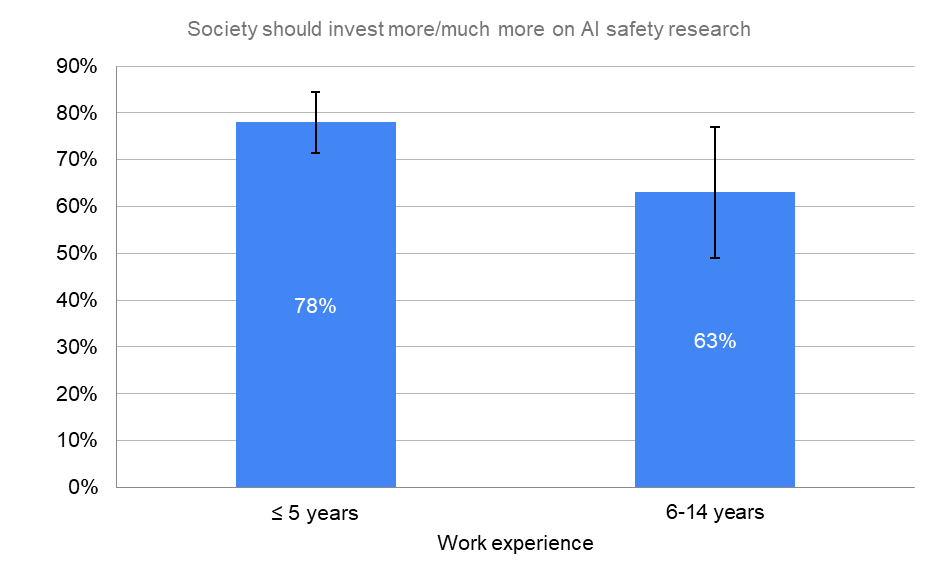
 By How Much Thought to Social Impacts of Smarter-Than-Human Machine
By How Much Thought to Social Impacts of Smarter-Than-Human Machine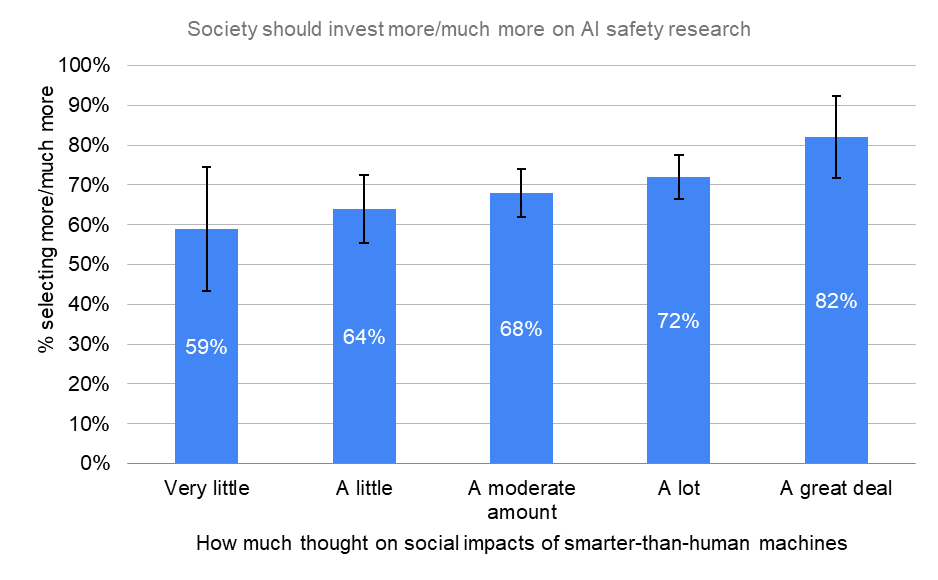
 The full questions used in the survey for the graphs above were:
The full questions used in the survey for the graphs above were: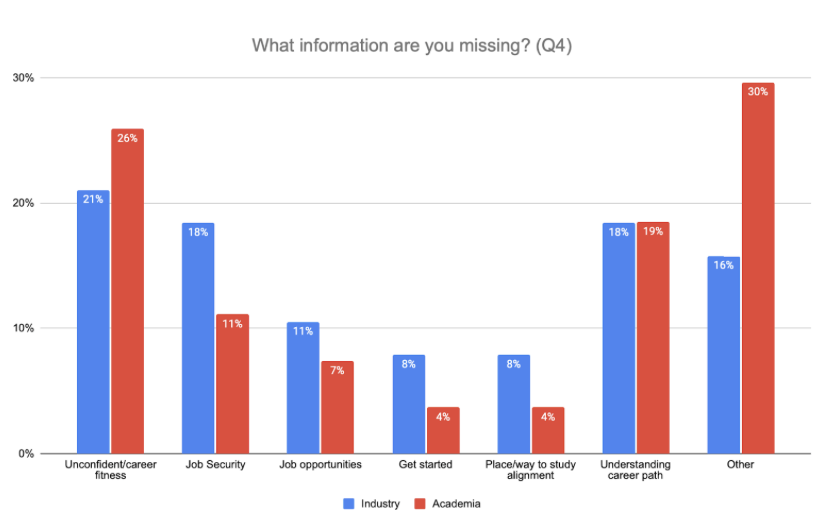


There's a minor mistake in the post
Actually, most people where not people we engaged with before. We spread the survey as wide as we could.
Half of them came from Rob Miles audience, or that's my estimate based on timing of responses.
But thanks for analysing our data!
I never got around to it, since I had to leave AISS a few months later, under pretty bad circumstances (which was not the fault of anyone working for AISS!)
Another interesting result of that survey was that a substantial fraction of applicants wanted some type of help or resource that did already existed but which they were unaware of. I can't remember now what percentage of applicants this was, but I think it was something in the range 20%-70%
I wrote about it here:
AI Safety Career Bottlenecks Survey Responses Responses
Hi Linda - Thanks for the clarification on the source of your data. Updated with the corrected information.