We recently ran a small pilot study in which we showed ML researchers (randomly selected NeurIPS / ICML / ICLR 2021 authors) a number of introductory AI safety materials, asking them to answer questions and rate those materials.
Summary
We selected materials that were relatively short and disproportionally aimed at ML researchers, but we also experimented with other types of readings. Within the selected readings, we found that researchers (n=28) preferred materials that were aimed at an ML audience, which tended to be written by ML researchers, and which tended to be more technical and less philosophical.
In particular, for each reading we asked ML researchers (1) how much they liked that reading, (2) how much they agreed with that reading, and (3) how informative that reading was. Aggregating these three metrics, we found that researchers tended to prefer (Steinhardt > [Gates, Bowman] > [Schulman, Russell]), and tended not to like Cotra > Carlsmith. In order of preference (from most preferred to least preferred) the materials were:
- “More is Different for AI” by Jacob Steinhardt (2022) (intro and first three posts only)
- “Researcher Perceptions of Current and Future AI” by Vael Gates (2022) (first 48m; skip the Q&A) (Transcript)
- “Why I Think More NLP Researchers Should Engage with AI Safety Concerns” by Sam Bowman (2022)
- “Frequent arguments about alignment” by John Schulman (2021)
- “Of Myths and Moonshine” by Stuart Russell (2014)
- "Current work in AI Alignment" by Paul Christiano (2019) (Transcript)
- “Why alignment could be hard with modern deep learning” by Ajeya Cotra (2021) (feel free to skip the section “How deep learning works at a high level”)
- “Existential Risk from Power-Seeking AI” by Joe Carlsmith (2021) (only the first 37m; skip the Q&A) (Transcript)
(Not rated)
Christiano (2019), Cotra (2021), and Carlsmith (2021) are well-liked by EAs anecdotally, and we personally think they’re great materials. Our results suggest that materials EAs like may not work well for ML researchers, and that additional materials written by ML researchers for ML researchers could be particularly useful. By our lights, it’d be quite useful to have more short technical primers on AI alignment, more collections of problems that ML researchers can begin to address immediately (and are framed for the mainstream ML audience), more technical published papers to forward to researchers, and so on.
More Detailed Results
Ratings
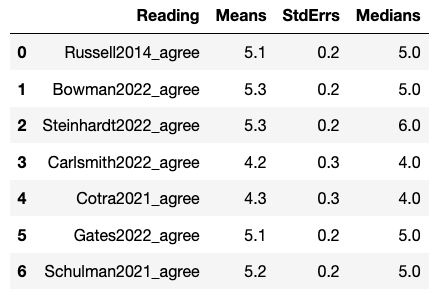
For the question “Overall, how much did you like this content?”, Likert 1-7 ratings (I hated it (1) - Neutral (4) - I loved it (7)) roughly followed:
- Steinhardt > Gates > [Schulman, Russell, Bowman] > [Christiano, Cotra] > Carlsmith
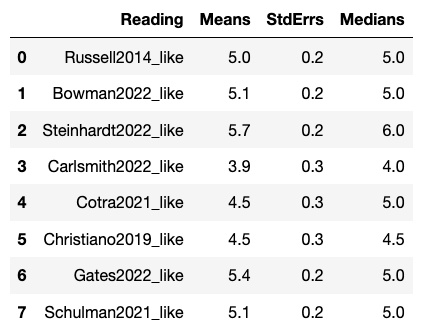
For the question “Overall, how much do you agree or disagree with this content?”, Likert 1-7 ratings (Strongly disagree (1) - Neither disagree nor agree (4) - Strongly agree (7)) roughly followed:
- Steinhardt > [Bowman, Schulman, Gates, Russell] > [Cotra, Carlsmith]
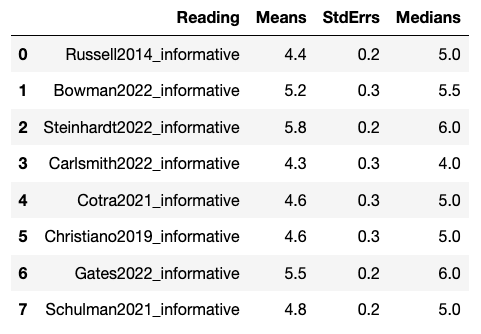
For the question “How informative was this content?”, Likert 1-7 ratings (Extremely noninformative (1) - Neutral (4) - Extremely informative (7)) roughly followed:
- Steinhardt > Gates > Bowman > [Cotra, Christiano, Schulman, Russell] > Carlsmith
The combination of the above questions led to the overall aggregate summary (Steinhardt > [Gates, Bowman] > [Schulman, Russell]) as preferred readings listed above.
Common Criticisms
In the qualitative responses about the readings, there were some recurring criticisms, including: a desire to hear from AI researchers, a dislike of philosophical approaches, a dislike of a focus on existential risks or an emphasis on fears, a desire to be “realistic” and not “speculative”, and a desire for empirical evidence.
Appendix - Raw Data
You can find the complete (anonymized) data here. This includes both more comprehensive quantitative results and qualitative written answers by respondents.


Really interesting stuff! Another question that could be useful is how much each piece shifted their views on existential risk.
Some of the better liked pieces are less ardent about the possibility of AI x-risk. The two pieces that are most direct about x-risk might be the unpopular Cotra and Carlsmith essays. I’m open to the idea that gentler introductions to ideas about safety could be more persuasive, but it might also result in people working on topics that are less relevant for existential safety. Hopefully we’ll be able to find or write materials that are both persuasive to the ML community and directly communicate the most pressing concerns about alignment.
Separately, is your sample size 28 for each document? Or did different documents have different numbers of readers? Might be informative to see those individual sample sizes. Especially for a long report like Carlsmith’s, you might think that not many readers put in the hour+ necessary to read it.
Edit: Discussion of this point here: https://www.lesswrong.com/posts/gpk8dARHBi7Mkmzt9/what-ai-safety-materials-do-ml-researchers-find-compelling?commentId=Cxoa577LadGYwC49C#comments
(in response to the technical questions)
Mostly n=28 for each document, some had n =29 or n= 30; you can see details in the Appendix, quantitative section.
The Carlsmith link is to the Youtube talk version, not the full report -- we chose materials based on them being pretty short.
Was each piece of writing read by a fresh set of n researchers (i.e. meaning that a total of ~30*8 researchers participated)? I understand the alternative to be that the same ~30 researchers read the 8 pieces of writing.
The following question interests me if the latter was true:
Do you specify in what order they should read the pieces?
I expect somebody making their first contact with AIS to have a very path-dependent response. For instance, encountering Carlsmith first and encountering Carlsmith last seem to produce different effects—these effects possibly extending to the researchers' ratings of the other pieces.
Unrelatedly, I'm wondering whether researchers were exposed only to the transcripts of the videos as opposed to the videos themselves.
No, the same set of ~28 authors read all of the readings.
The order of the readings was indeed specified:
Researchers had the option to read the transcripts where transcripts were available; we said that consuming the content in either form (video or transcript) was fine.