Comments
Forecasting Newsletter: July 2020.

Sign up here or browse past newsletters here.
Ordered in subjective order of importance:
Metaculus continues hosting great discussion.
Foretell is a prediction market by the University of Georgetown's Center for Security and Emerging Technology, focused on questions relevant to technology-security policy, and on bringing those forecasts to policy-makers.
published their first paper
had some difficulties with cheaters:
"The Team at Replication Markets is delaying announcing the Round 8 Survey winners because of an investigation into coordinated forecasting among a group of participants. As a result, eleven accounts have been suspended and their data has been excluded from the study. Scores are being recalculated and prize announcements will go out soon."
still have Round 10 open until the 3rd of August.
At the Good Judgement family, Good Judgement Analytics continues to provide its COVID-19 dashboard.
Modeling is a very good way to explain how a virus will move through an unconstrained herd. But when you begin to put in constraints” — mask mandates, stay-at-home orders, social distancing — “and then the herd has agency whether they’re going to comply, at that point, human forecasters who are very smart and have read through the models, that’s where they really begin to add value. – Marc Koehler, Vice President of Good Judgement, Inc., in a recent interview
Highly Speculative Estimates, an interface, library and syntax to produce distributional probabilistic estimates led by Ozzie Gooen, now accepts functions as part of its input, such that more complicated inputs like the following are now possible:
# Variable: Number of ice creams an unsupervised child has consumed,
# when left alone in an ice cream shop.
# Current time (hours passed)
t=10
# Scenario with lots of uncertainty
w_1 = 0.75 ## Weight for this scenario.
min_uncertain(t) = t*2
max_uncertain(t) = t*20
# Optimistic scenario
w_2 = 0.25 ## Weight for the optimistic scenario
min_optimistic(t) = 1*t
max_optimistic(t) = 3*t
mean(t) = (min_optimistic(t) + max_optimistic(t)/2)
stdev(t) = t*(2)^(1/2)
# Overall guess
## A long-tailed lognormal for the uncertain scenario
## and a tight normal for the optimistic scenario
mm(min_uncertain(t) to max_uncertain(t), normal(mean(t), stdev(t)), [w_1, w_2])
## Compare with: mm(2 to 20, normal(2, 1.4142), [0.75, 0.25])
PredictIt & Election Betting Odds each give a 60%-ish to Biden.
"Current prediction markets are so bad in so many different ways that it simply is not surprising for people to know better than them, and it often is not possible for people to make money from knowing better."
Augur, a betting platform built on top of Ethereum, launches v2. Here are two overviews of the platform and of v2 modifications
Announcing the Launch of the Social Science Prediction Platform, a platform aimed at collecting and popularizing predictions of research results, in order to improve social science; see this Science article for the background motivation:
A new result builds on the consensus, or lack thereof, in an area and is often evaluated for how surprising, or not, it is. In turn, the novel result will lead to an updating of views. Yet we do not have a systematic procedure to capture the scientific views prior to a study, nor the updating that takes place afterward. What did people predict the study would find? How would knowing this result affect the prediction of findings of future, related studies?
A second benefit of collecting predictions is that they [...] can also potentially help to mitigate publication bias. However, if priors are collected before carrying out a study, the results can be compared to the average expert prediction, rather than to the null hypothesis of no effect. This would allow researchers to confirm that some results were unexpected, potentially making them more interesting and informative, because they indicate rejection of a prior held by the research community; this could contribute to alleviating publication bias against null results.
A third benefit of collecting predictions systematically is that it makes it possible to improve the accuracy of predictions. In turn, this may help with experimental design.
Ought is a research lab building tools to delegate open-ended reasoning to AI & ML systems.
The Pipeline Project is a project similar to Replication Markets, by some of the same authors, to find out whether people can predict whether a given study will replicate. They offer authorship in an appendix, as well as a chance to get a token monetary compensation.
USAID's Intelligent Forecasting: A Competition to Model Future Contraceptive Use. "First, we will award up to 25,000 USD in prizes to innovators who develop an intelligent forecasting model—using the data we provide and methods such as artificial intelligence (AI)—to predict the consumption of contraceptives over three months. If implemented, the model should improve the availability of contraceptives and family planning supplies at health service delivery sites throughout a nationwide healthcare system. Second, we will award a Field Implementation Grant of approximately 100,000 to 200,000 USD to customize and test a high-performing intelligent forecasting model in Côte d’Ivoire."
Omen is another cryptocurrency-based prediction market, which seems to use the same front-end (and probably back-end) as Corona Information Markets. It's unclear what their advantages with respect to Augur are.
Yngve Høiseth releases a prediction scorer, based on his previous work on Empiricast. In Python, but also available as a REST API
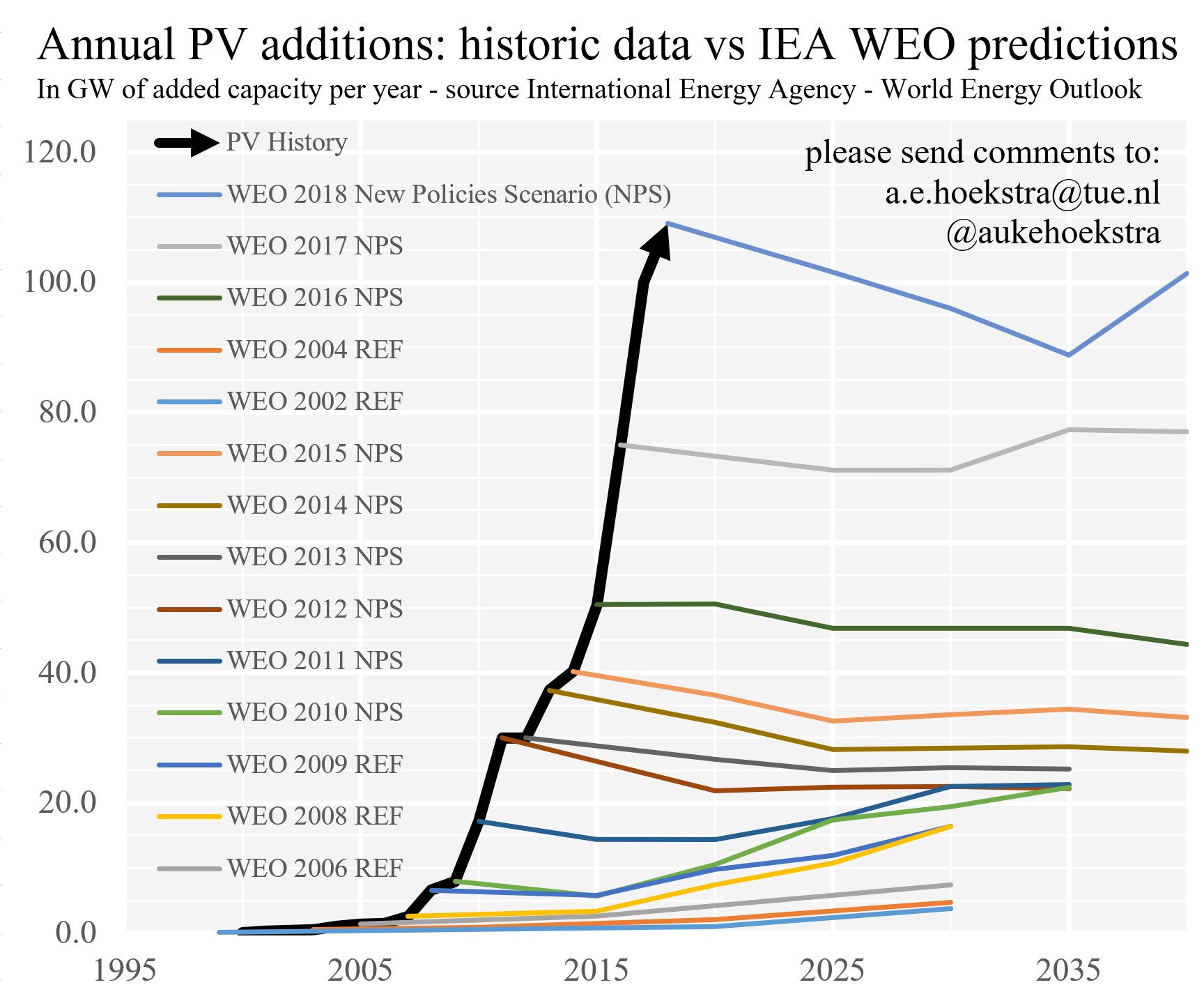
The International Energy Agency had terrible forecasts on solar photo-voltaic energy production, until recently:
...It’s a scenario assuming current policies are kept and no new policies are added.
...the discrepancy basically implies that every year loads of unplanned subsidies are added... So it boils down to: it’s not a forecast and any error you find must be attributed to that. And no you cannot see how the model works.
The IEA website explains the WEO process: “The detailed projections are generated by the World Energy Model, a large-scale simulation tool, developed at the IEA over a period of more than 20 years that is designed to replicate how energy markets function.”
Budget credibility of subnational forecasts.
Budget credibility, or the ability of governments to accurately forecast macro-fiscal variables, is crucial for effective public finance management. Fiscal marksmanship analysis captures the extent of errors in the budgetary forecasting... Partitioning the sources of errors, we identified that the errors were more broadly random than due to systematic bias, except for a few crucial macro-fiscal variables where improving the forecasting techniques can provide better estimates.
Bloomberg on the IMF's track record on forecasting (archive link, without a paywall).
A Bloomberg analysis of more than 3,200 same-year country forecasts published each spring since 1999 found a wide variation in the direction and magnitude of errors. In 6.1 percent of cases, the IMF was within a 0.1 percentage-point margin of error. The rest of the time, its forecasts underestimated GDP growth in 56 percent of cases and overestimated it in 44 percent. The average forecast miss, regardless of direction, was 2.0 percentage points, but obscures a notable difference between the average 1.3 percentage-point error for advanced economies compared with 2.1 percentage points for more volatile and harder-to-model developing economies. Since the financial crisis, however, the IMF’s forecast accuracy seems to have improved, as growth numbers have generally fallen.
Banking and sovereign debt panics hit Greece, Ireland, Portugal and Cyprus to varying degrees, threatening the integrity of the euro area and requiring emergency intervention from multinational authorities. During this period, the IMF wasn’t merely forecasting what would happen to these countries but also setting the terms. It provided billions in bailout loans in exchange for implementation of strict austerity measures and other policies, often bitterly opposed by the countries’ citizens and politicians.
I keep seeing evidence that Trump will lose reelection, but I don't know how seriously to take it, because I don't know how filtered it is.
For example, the The Economist's model forecasts 91% that Biden will win the upcoming USA elections. Should I update somewhat towards Biden winning after seeing it? What if I suspect that it's the most extreme model, and that it has come to my attention because of that fact? What if I suspect that it's the most extreme model which will predict a democratic win? What if there was another equally reputable model which predicts 91% for Trump, but which I never got to see because of information filter dynamics?
The the Primary Model confirmed my suspicions of filter dynamics. It "does not use presidential approval or the state of the economy as predictors. Instead it relies on the performance of the presidential nominees in primaries", and on how many terms the party has controlled the White House. The model has been developed by an otherwise unremarkable professor of political science at New York's Stony Brook University, and has done well in previous election cycles. It assigns 91% to Trump winning reelection.
Forecasting at Uber: An Introduction. Uber forecasts demand so that they know amongst other things, when and where to direct their vehicles. Because of the challenges to testing and comparing forecasting frameworks at scale, they developed their own software for this.
Forecasting Sales In These Uncertain Times.
[...] a company selling to lower-income consumers might use the monthly employment report for the U.S. to see how people with just a high school education are doing finding jobs. A business selling luxury goods might monitor the stock market.
Unilever Chief Supply Officer on forecasting: "Agility does trump forecasting. At the end of the day, every dollar we spent on agility has probably got a 10x return on every dollar spent on forecasting or scenario planning."
An emphasis on agility over forecasting meant shortening planning cycles — the company reduced its planning horizon from 13 weeks to four. The weekly planning meeting became a daily meeting. Existing demand baselines and even artificial intelligence programs no longer applied as consumer spending and production capacity strayed farther from historical trends.
An updated introduction to prediction markets, yet one which contains some nuggets I didn't know about.
This bias toward favorable outcomes... appears for a wide variety of negative events, including diseases such as cancer, natural disasters such as earthquakes and a host of other events ranging from unwanted pregnancies and radon contamination to the end of a romantic relationship. It also emerges, albeit less strongly, for positive events, such as graduating from college, getting married and having favorable medical outcomes.
Nancy Reagan hired an astrologer, Joan Quigley, to screen Ronald Reagan’s schedule of public appearances according to his horoscope, allegedly in an effort to avoid assassination attempts.
Google, Yahoo!, Hewlett-Packard, Eli Lilly, Intel, Microsoft, and France Telecom have all used internal prediction markets to ask their employees about the likely success of new drugs, new products, future sales.
Although prediction markets can work well, they don’t always. IEM, PredictIt, and the other online markets were wrong about Brexit, and they were wrong about Trump’s win in 2016. As the Harvard Law Review points out, they were also wrong about finding weapons of mass destruction in Iraq in 2003, and the nomination of John Roberts to the U.S. Supreme Court in 2005. There are also plenty of examples of small groups reinforcing each other’s moderate views to reach an extreme position, otherwise known as groupthink, a theory devised by Yale psychologist Irving Janis and used to explain the Bay of Pigs invasion.
although thoughtful traders should ultimately drive the price, that doesn’t always happen. The [prediction] markets are also no less prone to being caught in an information bubble than British investors in the South Sea Company in 1720 or speculators during the tulip mania of the Dutch Republic in 1637.
Food Supply Forecasting Company gets $12 million in Series A funding
Michael Story, "Jotting down things I learned from being a superforecaster."
Small teams of smart, focused and rational generalists can absolutely smash big well-resourced institutions at knowledge production, for the same reasons startups can beat big rich incumbent businesses
There's a lot more to making predictive accuracy work in practice than winning a forecasting tournament. Competitions are about daily fractional updating, long lead times and exhaustive pre-forecast research on questions especially chosen for competitive suitability
Real life forecasting often requires fast turnaround times, fuzzy questions, and difficult-to-define answers with unclear resolution criteria. In a competition, a question with ambiguous resolution is thrown out, but in a crisis it might be the most important work you do
Lukas Gloor on takeaways from Covid forecasting on Metaculus
Ambiguity aversion. "Better the devil you know than the devil you don't."
An ambiguity-averse individual would rather choose an alternative where the probability distribution of the outcomes is known over one where the probabilities are unknown. This behavior was first introduced through the Ellsberg paradox (people prefer to bet on the outcome of an urn with 50 red and 50 blue balls rather than to bet on one with 100 total balls but for which the number of blue or red balls is unknown).
Gregory Lewis: Use uncertainty instead of imprecision.
If your best guess for X is 0.37, but you're very uncertain, you still shouldn't replace it with an imprecise approximation (e.g. "roughly 0.4", "fairly unlikely"), as this removes information. It is better to offer your precise estimate, alongside some estimate of its resilience, either subjectively ("0.37, but if I thought about it for an hour I'd expect to go up or down by a factor of 2"), or objectively ("0.37, but I think the standard error for my guess to be ~0.1").
Expert Forecasting with and without Uncertainty Quantification and Weighting: What Do the Data Say?: "it’s better to combine expert uncertainties (e.g. 90% confidence intervals) than to combine their point forecasts, and it’s better still to combine expert uncertainties based on their past performance."
How to build your own weather forecasting model. Sailors realize that weather forecasting are often corrupted by different considerations (e.g., a reported 50% of rain doesn't happen 50% of the time), and search for better sources. One such source is the original, raw data used to generate weather forecasts: GRIB files (Gridded Information in Binary), which lack interpretation. But these have their own pitfalls, which sailors must learn to take into account. For example, GRIB files only take into account wind speed, not tidal acceleration, which can cause a significant increase in apparent wind.
‘Forecasts are inherently political,’ says Dashew. ‘They are the result of people perhaps getting it wrong at some point so some pressures to interpret them in a different or more conservative way very often. These pressures change all the time so they are often subject to outside factors.’
Singleton says he understands how pressures on forecasters can lead to this opinion being formed: ‘In my days at the Met Office when the Shipping Forecast used to work under me, they always said they try to tell it like it is and they do not try to make it sound worse.’
Forecasting the dividends of conflict prevention from 2020 - 2030. Study quantifies the dynamics of conflict, building a transition matrix between different states (peace, high risk, negative peace, war, and recovery) and validating it using historical dataset; they find (concurring with the previous literature), that countries have a tendency to fall into cycles of conflict. They conclude that changing this transition matrix would have a very high impact. Warning: extensive quoting follows.
Notwithstanding the mandate of the United Nations to promote peace and security, many member states are still sceptical about the dividends of conflict prevention. Their diplomats argue that it is hard to justify investments without being able to show its tangible returns to decision-makers and taxpayers. As a result, support for conflict prevention is halting and uneven, and governments and international agencies end up spending enormous sums in stability and peace support operations after-the-fact.
This study considers the trajectories of armed conflict in a 'business-as-usual' scenario between 2020-2030. Specifically, it draws on a comprehensive historical dataset to determine the number of countries that might experience rising levels of collective violence, outright armed conflict, and their associated economic costs. It then simulates alternative outcomes if conflict prevention measures were 25%, 50%, and 75% more effective. As with all projections, the quality of the projections relies on the integrity of the underlying data. The study reviews several limitations of the analysis, and underlines the importance of a cautious interpretation of the findings.
If current trends persist and no additional conflict prevention action is taken above the current baseline, then it is expected that there will be three more countries at war and nine more countries at high risk of war by 2030 as compared to 2020. This translates into roughly 677,250 conflict-related fatalities (civilian and battle-deaths) between the present and 2030. By contrast, under our most pessimistic scenario, a 25% increase in effectiveness of conflict prevention would result in 10 more countries at peace by 2030, 109,000 fewer fatalities over the next decade and savings of over $3.1 trillion. A 50% improvement would result in 17 additional countries at peace by 2030, 205,000 fewer deaths by 2030, and some $6.6 trillion in savings.
Meanwhile, under our most optimistic scenario, a 75% improvement in prevention would result in 23 more countries at peace by 2030, resulting in 291,000 lives saved over the next decade and $9.8 trillion in savings. These scenarios are approximations, yet demonstrate concrete and defensible estimates of both the benefits (saved lives, displacement avoided, declining peacekeeping deployments) and cost-effectiveness of prevention (recovery aid, peacekeeping expenditures). Wars are costly and the avoidance of “conflict traps” could save the economy trillions of dollars by 2030 under the most optimistic scenarios. The bottom line is that comparatively modest investments in prevention can yield lasting effects by avoiding compounding costs of lost life, peacekeeping, and aid used for humanitarian response and rebuilding rather than development. The longer conflict prevention is delayed, the more expensive responses to conflict become.
In order to estimate the dividends of conflict prevention we analyze violence dynamics in over 190 countries over the period 1994 to 2017, a time period for which most data was available for most countries. Drawing on 12 risk variables, the model examines the likelihood that a war will occur in a country in the following year and we estimate (through linear, fixed effects regressions) the average cost of war (and other ‘states’, described below) on 8 dependent variables, including loss of life, displacement, peacekeeping deployments and expenditures, oversea aid and economic growth. The estimates confirm that, by far, the most costly state for a country to be in is war, and the probability of a country succumbing to war in the next year is based on its current state and the frequency of other countries with similar states having entered war in the past.
At the core of the model (and results) is the reality that countries tend to get stuck in so-called violence and conflict traps. A well-established finding in the conflict studies field is that once a country experiences an armed conflict, it is very likely to relapse into conflict or violence within a few years. Furthermore, countries likely to experience war share some common warning signs, which we refer to as “flags” (up to 12 flags can be raised to signal risk). Not all countries that enter armed conflict raise the same warning flags, but the warning flags are nevertheless a good indication that a country is at high risk. These effects create vicious cycles that result in high risk, war and frequent relapse into conflict. Multiple forms of prevention are necessary to break these cycles. The model captures the vicious cycle of conflict traps, through introducing five states and a transition matrix based on historical data (see Table 1). First, we assume that a country is in one of five 'states' in any given year. These ‘states’ are at "Peace", "High Risk", "Negative Peace", "War" and "Recovery" (each state is described further below). Drawing on historical data, the model assesses the probability of a country transitioning to another state in a given year (a transition matrix).
For example, if a state was at High Risk in the last year, it has a 19.3% chance of transitioning to Peace, a 71.4% chance of staying High Risk, a 7.6% chance of entering Negative Peace and a 1.7% chance of entering War the following year.
By contrast, high risk states are designated by the raising of up to 12 flags. These include: 1) high scores by Amnesty International's annual human rights reports (source: Political Terror Scale), 2) the US State Department annual reports (source: Political Terror Scale), 3) civilian fatalities as a percentage of population (source: ACLED), 4) political events per year (source: ACLED) 5) events attributed to the proliferation of non-state actors (source: ACLED), 6) battle deaths (source: UCDP), 7) deaths by terrorism (source: GTD), 8) high levels of crime (source: UNODC), 9) high levels of prison population (source: UNODC), 10) economic growth shocks (source: World Bank), 11) doubling of displacement in a year (source: IDMC), and 12) doubling of refugees in a year (source: UNHCR). Countries with two or more flags fall into the "high risk" category. Using these flags, a majority of countries have been at high risk for one or more years from 1994 to 2017, so it is easier to give examples of countries that have not been at high risk.
Negative peace states are defined by combined scores from Amnesty International and the US State Department. Countries in negative peace are more than five times as likely to enter high risk in the following year than peace (26.8% vs. 4.1%).
A country that is at war is one that falls into a higher threshold of collective violence, relative to the size of the population. Specifically, it is designated as such if one or more of the following conditions are met: above 0.04 battle deaths or .04 civilian fatalities per 100,000 according to UCDP and ACLED, respectively, or coding of genocide by the Political Instability Task Force Worldwide Atrocities Dataset. Countries experiencing five or more years of war between 1994 and 2017 included Afghanistan, Somalia, Sudan, Iraq, Burundi, Central African Republic, Sri Lanka, DR Congo, Uganda, Chad, Colombia, Israel, Lebanon, Liberia, Yemen, Algeria, Angola, Sierra Leone, South Sudan, Eritrea and Libya.
Lastly, recovery is a period of stability that follows from war. A country is only determined to be recovering if it is not at war and was recently in a war. Any country that exits in the war state is immediately coded as being in recovery for the following five years, unless it relapses into war. The duration of the recovery period (five years) is informed by the work of Paul Collier et al, but is robust also to sensitivity tests around varying recovery lengths.
The model does not allow for countries to be high risk and in recovery in the same year, but there is ample evidence that countries that are leaving a war state are at a substantially higher risk of experiencing war recurrence, contributing to the conflict trap described earlier. Countries are twice as likely to enter high risk or negative peace coming out of recovery as they are to enter peace, and 10.2% of countries in recovery relapse into war every year. When a country has passed the five year threshold without reverting to war, it can move back to states of peace, negative peace or high risk.
The transition matrix underlines the very real risk of countries falling into a 'conflict trap'. Specifically, a country that is in a state of war has a very high likelihood of staying in this condition in the next year (72.6%) and just a 27.4% chance of transitioning to recovery. Once in recovery, a country has a 10.2% chance of relapse every year, suggesting only a 58% chance (1-10.2%)^5 that a country will not relapse over five years.
As Collier and others have observed, countries are often caught in prolonged and vicious cycles of war and recovery (conflict traps), often unable to escape into a new, more peaceful (or less war-like) state
Of course, the loss of life, displacement, and accumulated misery associated with war should be reason enough to invest in prevention, but there are also massive economic benefits from successful prevention. Foremost, the countries at war avoid the costly years in conflict, with growth rates 4.8% lower than countries at peace. They also avoid years of recovery and the risk of relapse into conflict. Where prevention works, conflict-driven humanitarian needs are reduced, and the international community avoids peacekeeping deployments and additional aid burdens, which are sizable.
Conclusion: The world can be significantly better off by addressing the high risk of destructive violence and war with focused efforts at prevention in countries at high risk and those in negative peace. This group of countries has historically been at risk of higher conflict due to violence against civilians, proliferation of armed groups, abuses of human rights, forced displacement, high homicide, and incidence of t error. None of this is surprising. Policymakers know that war is bad for humans and other living things. What is staggering is the annual costs of war that we will continue to pay in 2030 through inaction today – conceivably trillions of dollars of economic growth, and the associated costs of this for human security and development, are being swept off t he table by the decisions made today to ignore prevention.
On the one hand, Nassim Taleb has clearly expressed that measures to stop the spread of the pandemic must be taken as soon as possible: instead of looking at data, it is the nature of a pandemic with a possibility of devastating human impact that should drive our decisions.
On the other hand, John Ioannidis acknowledges the difficulty in having good data and of producing accurate forecasts, while believing that eventually any information that can be extracted from such data and forecasts should still be useful, e.g. to having targeted lockdowns (in space, time, and considering the varying risk for different segments of the population).
Taleb: On single point forecasts for fat tailed variables. Leitmotiv: Pandemics are fat-tailed.
We do not need more evidence under fat tailed distributions — it is there in the properties themselves (properties for which we have ample evidence) and these clearly represent risk that must be killed in the egg (when it is still cheap to do so). Secondly, unreliable data — or any source of uncertainty — should make us follow the most paranoid route. [...] more uncertainty in a system makes precautionary decisions very easy to make (if I am uncertain about the skills of the pilot, I get off the plane).
Random variables in the power law class with tail exponent α ≤ 1 are, simply, not forecastable. They do not obey the [Law of Large Numbers]. But we can still understand their properties.
As a matter of fact, owing to preasymptotic properties, a heuristic is to consider variables with up to α ≤ 5/2 as not forecastable — the mean will be too unstable and requires way too much data for it to be possible to do so in reasonable time. It takes 1014 observations for a “Pareto 80/20” (the most commonly referred to probability distribution, that is with α ≈ 1.13) for the average thus obtained to emulate the significance of a Gaussian with only 30 observations.
Ioannidis: Forecasting for COVID-19 has failed. Leitmotiv: "Investment should be made in the collection, cleaning and curation of data".
Predictions for hospital and ICU bed requirements were also entirely misinforming. Public leaders trusted models (sometimes even black boxes without disclosed methodology) inferring massively overwhelmed health care capacity (Table 1) [3]. However, eventually very few hospitals were stressed, for a couple of weeks. Most hospitals maintained largely empty wards, waiting for tsunamis that never came. The general population was locked and placed in horror-alert to save the health system from collapsing. Tragically, many health systems faced major adverse consequences, not by COVID-19 cases overload, but for very different reasons. Patients with heart attacks avoided visiting hospitals for care [4], important treatments (e.g. for cancer) were unjustifiably delayed [5], mental health suffered [6]. With damaged operations, many hospitals started losing personnel, reducing capacity to face future crises (e.g. a second wave). With massive new unemployment, more people may lose health insurance. The prospects of starvation and of lack of control for other infectious diseases (like tuberculosis, malaria, and childhood communicable diseases for which vaccination is hindered by the COVID-19 measures) are dire...
The core evidence to support “flatten-the-curve” efforts was based on observational data from the 1918 Spanish flu pandemic on 43 US cities. These data are >100-years old, of questionable quality, unadjusted for confounders, based on ecological reasoning, and pertaining to an entirely different (influenza) pathogen that had ~100-fold higher infection fatality rate than SARS-CoV-2. Even thus, the impact on reduction on total deaths was of borderline significance and very small (10-20% relative risk reduction); conversely many models have assumed 25-fold reduction in deaths (e.g. from 510,000 deaths to 20,000 deaths in the Imperial College model) with adopted measures
Despite these obvious failures, epidemic forecasting continued to thrive, perhaps because vastly erroneous predictions typically lacked serious consequences. Actually, erroneous predictions may have been even useful. A wrong, doomsday prediction may incentivize people towards better personal hygiene. Problems starts when public leaders take (wrong) predictions too seriously, considering them crystal balls without understanding their uncertainty and the assumptions made. Slaughtering millions of animals in 2001 aggravated a few animal business stakeholders, most citizens were not directly affected. However, with COVID-19, espoused wrong predictions can devastate billions of people in terms of the economy, health, and societal turmoil at-large.
Cirillo and Taleb thoughtfully argue [14] that when it comes to contagious risk, we should take doomsday predictions seriously: major epidemics follow a fat-tail pattern and extreme value theory becomes relevant. Examining 72 major epidemics recorded through history, they demonstrate a fat-tailed mortality impact. However, they analyze only the 72 most noticed outbreaks, a sample with astounding selection bias. The most famous outbreaks in human history are preferentially selected from the extreme tail of the distribution of all outbreaks. Tens of millions of outbreaks with a couple deaths must have happened throughout time. Probably hundreds of thousands might have claimed dozens of fatalities. Thousands of outbreaks might have exceeded 1,000 fatalities. Most eluded the historical record. The four garden variety coronaviruses may be causing such outbreaks every year [15,16]. One of them, OC43 seems to have been introduced in humans as recently as 1890, probably causing a “bad influenza year” with over a million deaths [17]. Based on what we know now, SARS-CoV-2 may be closer to OC43 than SARS-CoV-1. This does not mean it is not serious: its initial human introduction can be highly lethal, unless we protect those at risk.
The (British) Royal Economic Society presents a panel on What is a scenario, projection and a forecast - how good or useful are they particularly now?. The start seems promising: "My professional engagement with economic and fiscal forecasting was first as a consumer, and then a producer. I spent a decade happily mocking other people's efforts, as a journalist, since when I've spent two decades helping colleagues to construct forecasts and to try to explain them to the public." The first speaker, which corresponds to the first ten minutes, is worth listening to; the rest varies in quality.
You have to construct the forecast and explain it in a way that's fit for that purpose
I liked the following taxonomy of what distinct targets the agency the first speaker works for is aiming to hit with their forecasts:
The limitations were interesting as well:
"horses for courses, the way you do the forecast, the way you present it depends on what you're trying to achieve with it"
"People use scenario forecasting in a very informal manner. which I think that could be problematic because it's very difficult to basically find out what are the assumptions and whether those assumptions and the models and the laws can be validated"
Linear models are state independent, but it's not the same to receive a shock where the economy is in upswing as when the economy is during a recession.
One week delay in intervention by the government makes a big difference to the height of the [covid-19] curve.
I don't think it's easy to follow the old way of doing things. I'm sorry, I have to be honest with you. I spent 4 months just thinking about this problem and you need to integrate a model of the social behavior and how you deal with the risk to health and to economy in these models. But unfortunately, by the time we do that it won't be relevant.
It amuses me to look at weather forecasts because economists don't have that kind of technology, those kind of resources.
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go here
"horses for courses, the way you do the forecast, the way you present it depends on what you're trying to achieve with it"


Thanks, I still find this very useful. Haven't seen Ought's Ergo before, really cool.