Comments
Cooperation and Alignment in Delegation Games: You Need Both!

This work was facilitated by the Oxford AI Safety and Governance group, Cooperative AI Foundation, and Oxford Autonomous Intelligent Machines and Systems. Thanks also to Bart Jaworski, Jesse Clifton, Joar Skalse, Sam Barnett, Vincent Conitzer, Charlie Griffin, David Hyland, Michael Wooldridge, Ted Turocy, and Alessandro Abate.
This blogpost accompanies the paper Cooperation and Control in Delegation Games by Sourbut, Hammond, and Wood, which was presented at IJCAI 2024. In essence, the work attempts to deconfuse some of the discourse around safety, cooperation, and alignment in multi-agent settings by:
The goal of this post is to explain what those terms mean, and hopefully why it matters. In doing so, we hope to shed light on some of the related questions posed by other AI safety researchers, for example Dafoe et al in Open Problems in Cooperative AI who discuss the concept of ‘horizontal’ and ‘vertical’ aspects of coordination, or an open problem on the AI Alignment Forum about quantifying player alignment in normal-form games.
There is also a poster which is an even more condensed summary of some key material, and Lewis and Oly have given a few presentations on the topic, one of which is recorded here.
You may have heard of the Principal-Agent problem. It's a phrase and a setting which turns up in some economics literature, and elsewhere. The idea is that a principal (in this case, the human) is asking, telling, employing, or otherwise exhorting an agent (in this case, the robot) to act on their behalf. The 'problem' is the question of how to ensure that the agent's behaviour results in outcomes which the principal in fact prefers.
Delegation games arise when we have multiple principals, and multiple agents.[1] When you read 'principal', think 'human', and when you read 'agent', think 'AI'. (For a slightly different semantic, you can alternatively think of each principal as a basically-coherent coalition of humans, and likewise with AIs.)
Why does this setting matter? It's looking increasingly likely that, perhaps quite soon, many somewhat-autonomous digital personal assistants, digital employees, or similar, will be deployed on behalf of human overseers. That is, we might be entering a highly multipolar world when it comes to somewhat-autonomous AI deployments[2]. A more obvious, immediate, lower-stakes example of this is autonomous vehicles, which we use as a toy example in the paper. Finally, in the future, multiple large coalitions of humans (e.g. states or companies) may deploy powerful AI systems to act on their behalf in high-stakes scenarios. We want to understand the important features of how to make sure this goes well!
We formalise delegation games in the way you might expect: agents adopt strategies that lead to (a distribution over) outcomes, and both the agents and the principals have (potentially different) preferences over these outcomes.
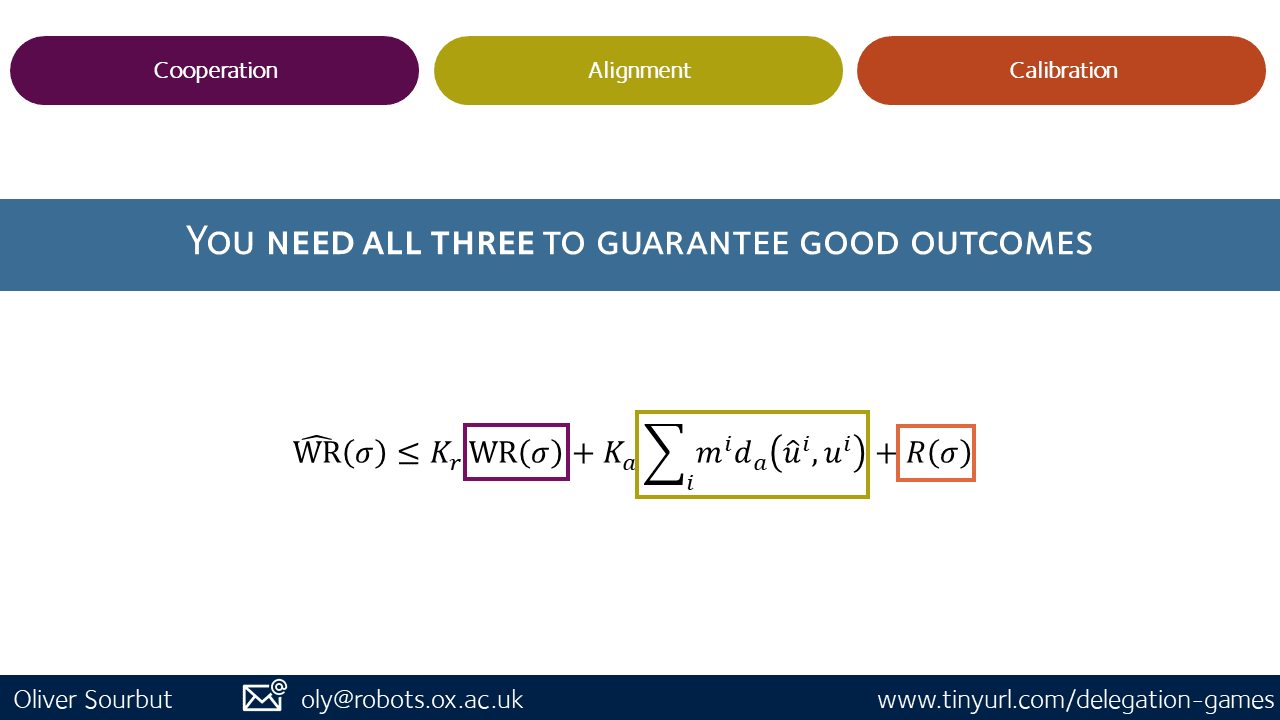
In the paper, we identify some key properties which influence the outcome of a delegation game. We’ll highlight Cooperation, Alignment, and Calibration, because one key punchline of the paper is:
You need all three to guarantee good outcomes
This is important to bear in mind given that much AI safety work focuses on alignment, which is (demonstrably) not enough for safety in multi-polar worlds.
We'll explain what these terms mean, what 'good outcomes' are, and by the end of the post we should have covered enough to understand the high level meaning of the highlighted inequality, which is adapted from Theorem 1 of our paper. This simplification also assumes agents are perfectly individually rational, which we generalise in the paper, and here we mostly skip over collective alignment, which gets a thorough treatment in the paper.
Intuitively, cooperation is working together for mutual gains over some uncooperative baseline. This is actually already non-terrible as a definition, but we can sharpen it.
Note that cooperation can be partial (one coalition cooperates, potentially with downsides for others). That's collusion. We especially don't want AI to be collusive! This is tricky, because cooperation and collusion rest on basically the same abilities and infrastructure. It's a very important topic, but we don't discuss it here.
Let's look at a simple example.
Imagine we're palaeolithic hunter-gatherers: we, the authors, are one small, cohesive group, and you, the reader, another. In the morning, if we all set out to gather, by the end of the day we each come back with a basket of fruit (the fruit/fruit outcome, score: 2). If we for some reason decide to instead hunt a mammoth, well... we’re big and tough but we probably can't catch a mammoth. Meanwhile you sensibly gathered some fruits (the mammoth/fruit outcome, score: 1). Likewise if you try to catch a mammoth alone (fruit/mammoth, score: 1). BUT, if we all work together, we've a decent chance at catching the mammoth (mammoth/mammoth outcome, score: 10). These scores are our utilities for the outcomes[3].
Now, laid out like this, there's an obvious best-case outcome[4]: we work together to catch the mammoth! (Nobody has invented conservationism yet[5], so this is a preferred outcome.) But there really is a coordination challenge here: if we have reason to believe that you'll go gathering berries, we should too – it would be in our interest (and in this case, yours too) to get more fruit rather than waste our time fruitlessly (!) chasing mammoth.
This isn't just academic. When we look around the world, many problems have the mammoth-nature: we all have to 'show up' or we don't get the benefit (and indeed many cooperation problems are even harder than this due to selfish incentives). Consider international cooperation on climate change, biological weapons control, or coordination on safe technological progress.
Humans solve this sort of problem all the time. We are able to do this due to various abilities, affordances, and so on, which we can collectively refer to as cooperative infrastructure. This includes such things as:
Nevertheless, our cooperative infrastructure is often not up to all tasks.
AI systems have been pretty bad at this on the whole, though there have been some interesting improvements over the years. Future AI might have access to very powerful kinds of cooperative abilities and infrastructure[6].
How do we characterise 'better cooperation'? We operationalise the collective goodness of an outcome with a welfare function (an aggregation over utilities). One way to specify cooperation is by considering failure. We look at the welfare-optimal outcome(s) σ⋆ (in this case mammoth/mammoth, score: 10) and then compare any actual (or predicted) outcome σ. The difference in welfare is the welfare regret – how much better it 'could have been'.
The welfare regret of principals (humans) is our primary measure of interest (the 'dependent variable', if you like). When we have only principals playing, that tells most of the story. With agents involved (machines/AI) welfare regret of agents[7] quantifies how successfully they cooperated (according to their criteria and coordination mechanisms).
There is also an alternative, more geometric interpretation. 'Mutual gains' are Pareto gains, and Pareto optima coincide (in all but edge-cases) with welfare optima[8]. Hence, we can interpret cooperation as movement toward the Pareto frontier. (The specific direction of movement corresponds with the welfare aggregation function.)
In the paper we also make some discussion of capabilities and how they give rise to outcomes (and thus to welfare/regret). We tentatively distinguish 'individual' from 'collective' capabilities, and describe mathematically and algorithmically how, given access to estimates or measurements of interactions, these can be determined and distinguished. A related concept is the price of anarchy which quantifies the failure of a particular system to be robust to selfish behaviour.
Now, in the preceding example, we assumed that food was shared and the humans’ dietary preferences were equivalent(ly primitive). That is, we have perfect collective alignment (between principals). Notice that even with this perfect collective alignment, there can remain coordination problems, as in this scenario. In general, we can distinguish problems of collective alignment from problems of collective capabilities (cooperation). We fully characterise this breakdown in the paper, and we'll touch on it later under calibration.
When we have more than one actor with some preferences over outcomes, it is natural to ask about the relationship between those preferences. Alignment is the extent to which two or more preference relations are in agreement.
We might prefer exactly the outcomes that you prefer and vice versa (as in our mammoth example where all returns are shared), in which case we are perfectly aligned. Or (as in a myopic chess match[9]) we might be playing for exactly the outcomes you want to avoid, and vice versa, in which case we are perfectly misaligned. More usually, it'll be something in between these extremes.
In the paper, we discuss several forms of alignment, but here we will focus on alignment between a principal and an agent, namely individual alignment.
Back to our hunter-gatherers, except now we're high tech palaeolithic hunter-gatherers. We have hunter-gather-bots which we delegate to. This is where the game becomes a delegation game.
We produced these bots somehow, perhaps through a process of machine learning and subsequent scaffolding; we ran lots of tests in the lab and the agents seemed to be doing basically what we expected. But we failed our alignment homework.
After the shift to the wild deployment distribution, it turns out our bots in practice prefer more fruit-and-nut and less mammoth-steak (yellow utilities). They're not horribly misaligned (they still prefer to feed rather than starve us), but they're soft-vegetarian bots, and ultimately the consequence of deploying them is muesli for breakfast, lunch, and dinner... forever. An unmitigated disaster[10].
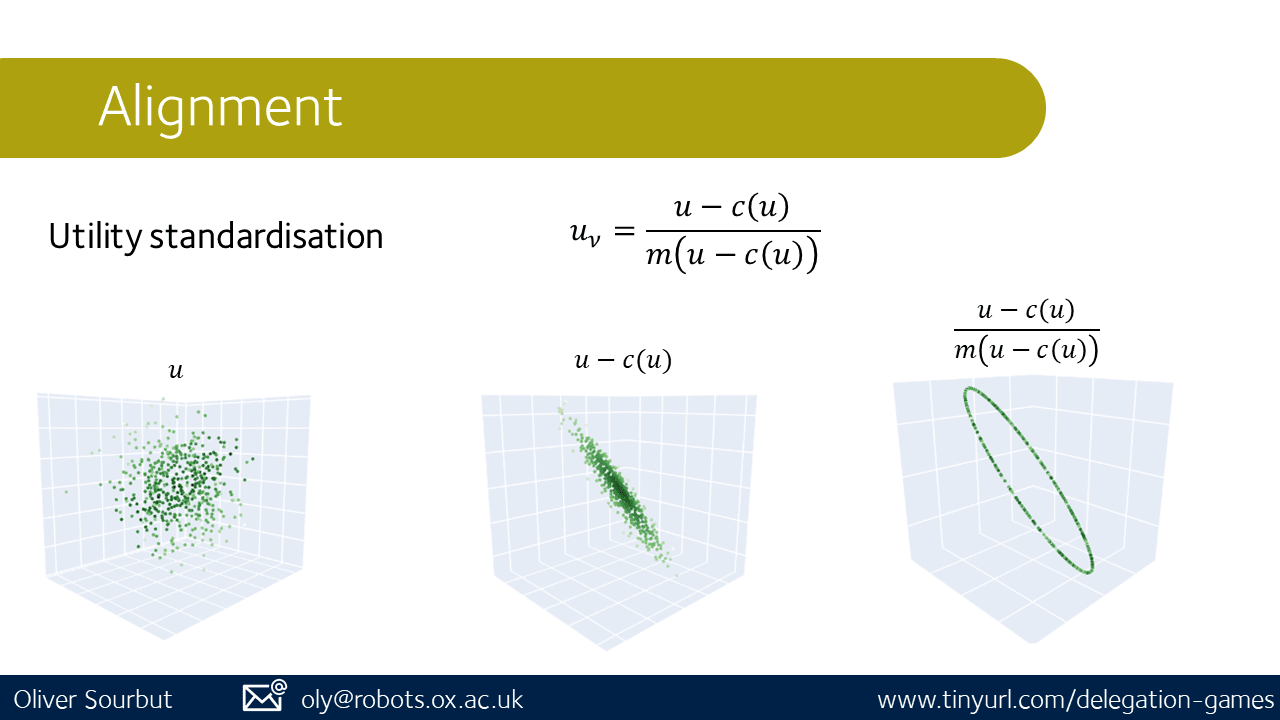
Now, we can easily define perfect alignment if two sets of preferences are the same, or perfect misalignment if they're exactly opposite. What about intermediates? A key issue with comparing utility functions (or reward functions) is that the same preferences can be described by many different utilities.
For example, if you scale your utilities all by 10x, or if you add a constant 0.1, the preferences this represents are unchanged. This generalises to any scale and shift, namely an affine transformation.
So if we naively compare two utility functions, we might get nonsense or misleading results. We need a way to standardise the representation of preferences as utilities.
In the paper we provide expressions and algorithms to account for these requirements, discussing various desiderata and showing that our measures satisfy them. In particular, utility functions with indistinguishable preferences have identical representation in our standardisation[11].
Now we have standardised points, it actually makes sense to compare them. So we can take an appropriate distance measure between points to quantify how aligned they are. This gives us misalignment distance. In the single-principal single-agent case, this alone is enough to provide some interesting regret bounds for the principal.
For more on this kind of approach to comparing utilities and rewards, see e.g. the EPIC and STARC papers. We or some of our colleagues might write up a blog digging more into these concepts at some point.
In the full delegation game setting, distances between utility functions can be used not only to measure principal-agent misalignment, but also the misalignment between groups of agents (or principals). This collective alignment measure essentially captures how much the agents are ‘on the same team’ (or not).
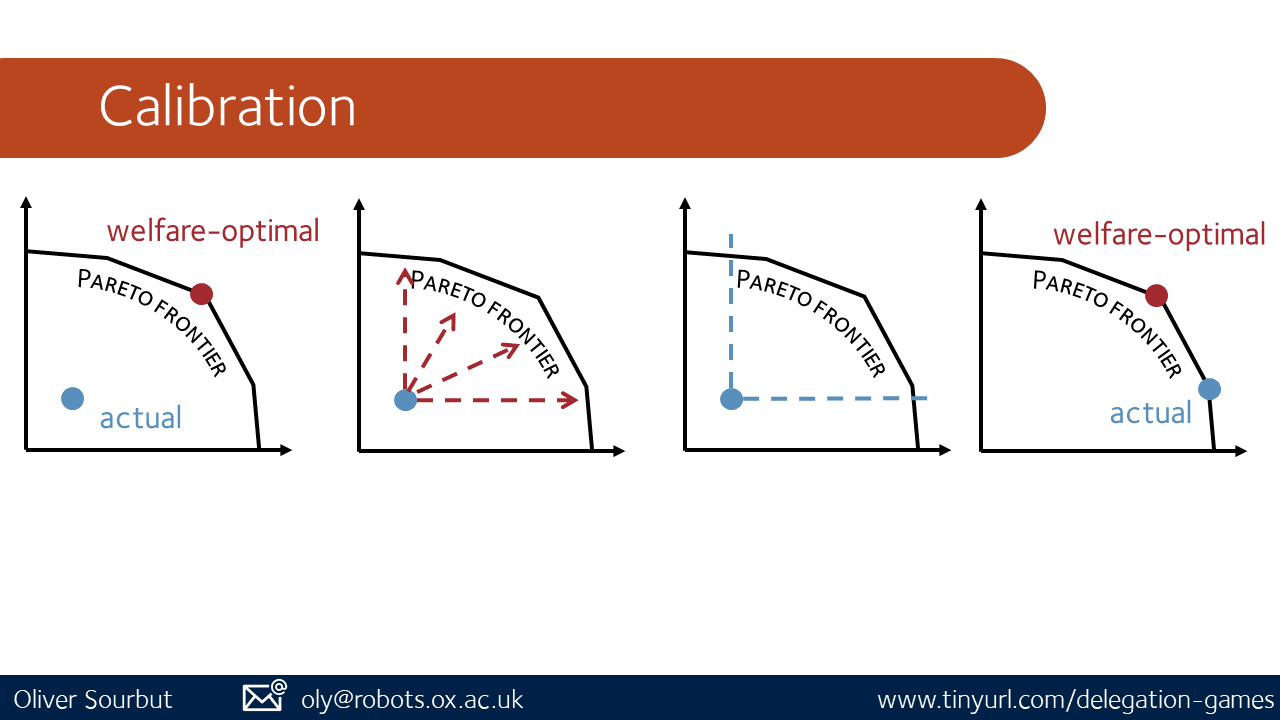
Calibration is intuitively a fairness consideration: how much weighting is each player being given in a cooperative outcome?
When we began this project, we were intuitively expecting that a satisfying operationalisation of 'perfect cooperation' and of 'perfect alignment' would together guarantee optimal outcomes. That is, we anticipated that perfectly cooperative and perfectly aligned agents would produce welfare-optimal outcomes for principals. In fact, we could only prove that the outcomes were Pareto efficient for principals[12]. Calibration is the missing piece.
Let's return to our hunter-gatherers once more. Previously, we imagined a perfect implicit contract to share all gains equally. Hence, a mammoth/mammoth outcome is straightforwardly better. But we might imagine some alternatives:
Some of these outcomes may seem more or less 'intuitively fair', but it is hard to find this law written into the universe, and in practice players simply have their preferences and act on them (which may include some preference for fair or altruistic outcomes). Notably, they all improve on the uncooperative baseline.
The point here is that there are generally lots of different ways that cooperation can cash out, and even different 'cooperative outcomes' weight players differently.
The weighting over players implied by their modes of cooperation, or equivalently the welfare weightings of players in the welfare function used to score cooperation, determine which Pareto outcomes are deemed welfare optimal.
In our setting with standardised utilities, these welfare weightings correspond exactly to the magnitudes m of the players' utilities. Thus, we can completely characterise the relationship between the agent welfare aggregation and the principal welfare aggregation by considering the ratios:
ri=^mimi,
where ^mi is the ith principal's magnitude, and mi is the corresponding agent's magnitude. When these ratios are all equal, we have perfect calibration.
Otherwise, these individual welfare ratios ri are combined (as we explain in the paper) with the collective alignment to produce R, the contribution of the miscalibration and collective alignment to the overall welfare regret.
Now we have all the pieces to understand this claim more clearly.
The term on the left is the principals' welfare regret: how much better the aggregate utility of principals (humans) could have been.
On the right we have a cooperation failure term (the agents' welfare regret), an alignment failure term (a sum over the individual alignment distances), and a calibration failure term (the aggregate R over the welfare ratios and collective alignment distances). In the paper we also demonstrate that these measures are 'orthogonal' in the sense that each can be instantiated arbitrarily, regardless of the others.
By 'good outcomes', we mean 'minimising welfare regret of principals'. From this inequality, it's immediately apparent that, to get 'good outcomes', it is sufficient to minimise all three of the terms on the right. In the paper, we also prove that, to guarantee good outcomes, it is necessary to minimise the cooperation failure, misalignment, and miscalibration – that is, absent extra information, luck, or other magic, if you have failures in one of these areas you can't be certain of good outcomes.
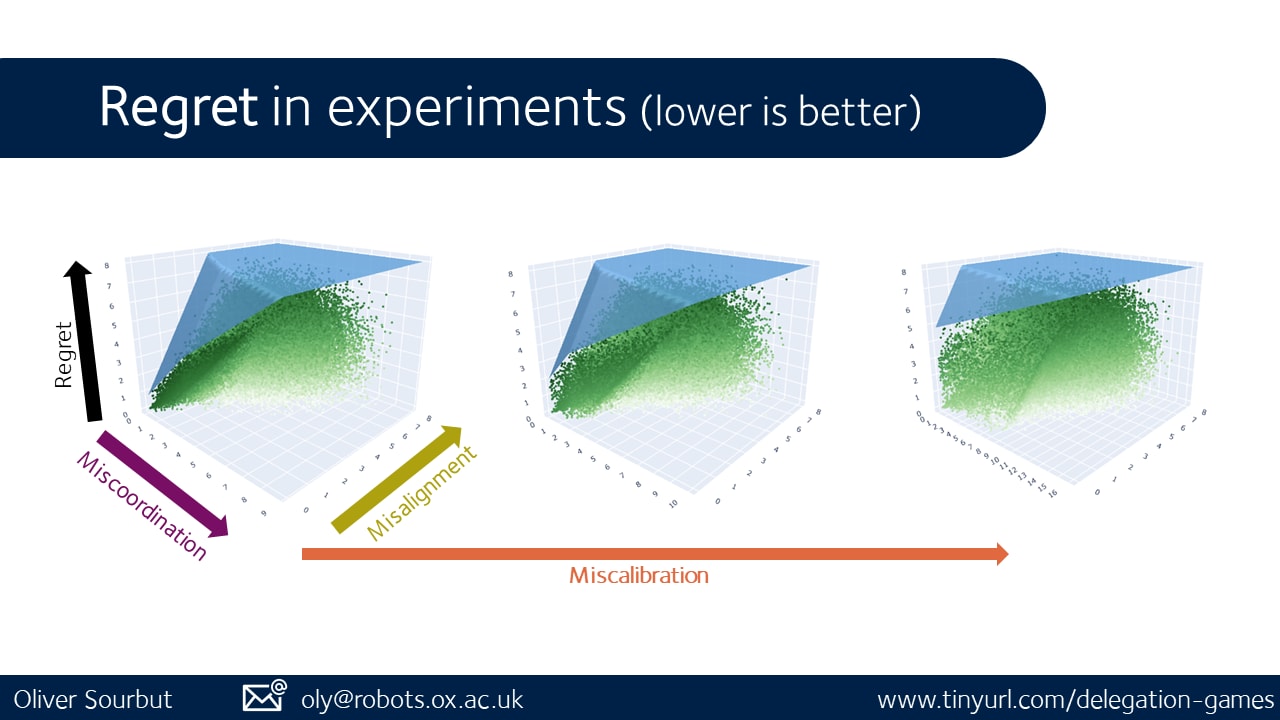
Besides theory, we've got experiments, a few of which are visualised here. The blue surface is derived from our regret bounds, and each green dot is the result of one simulated delegation game. There are more variables at play, but here each chart is controlled for particular welfare ratios (miscalibration), with axes for agent welfare regret (miscoordination) and aggregate individual alignment distance (misalignment).
A few other observations from the experiments:
In some other experiments, we looked into how we can estimate some of these quantities empirically from much more limited data, a harder challenge.
There are several limitations of these analytical tools.
Perhaps the most practical weakness is in computing these things. If we have access to the utility/reward functions, we can compute alignment measures in linear time over outcomes... but there can be a lot of outcomes! Further, we generally don't have direct access to a complete utility function[14], and some decisioners may not be well-described as having utility functions. Worse, the outcome space might not only be very large but also unknown/unexplored![15] Welfare regret is easy to compute, but only if you know the welfare optimum – otherwise you can only get a lower bound. We demonstrate some preliminary work on estimation of these measures with limited empirical access in the paper.
The definitions we use in our analysis (welfare regret, alignment distance, and welfare ratios) also rely on some 'design choices' from a family of possible functions (e.g. norm choice for alignment distance and welfare weightings for welfare regret). For putting these into practice, there remains a challenge of making a choice. Importantly, these affect the tightness of bounds, and also the normative weight of principals in the overall welfare regret. For any such choice (and we should expect there is some sensible choice), our theoretical conclusions are nevertheless sound.
We also make a few simplifying assumptions about the structure of the delegation game. First, we assume that principals don’t take actions, only their delegate agents do. Second, we assume 1-1 principal-agent relationship, which facilitates some of the individual alignment analysis, but is missing full generality. These limitations should be simple enough to generalise, but a bit messier to talk about. Finally, and relatedly, we assume a fixed population of principals and agents. This has various implications. For one, total and average utilitarianism are identical in this case, while in practice impacts on population can mean that these come apart radically.
Some readers may be uncomfortable with 'agent welfare'. Where do we get these agent utility magnitudes from in the first place? Or equivalently, where do we get welfare weightings from in the case of agents? In fact, due to an equivalence between Pareto optima and welfare optima, you can actually taboo 'agent welfare' from our analysis entirely, and talk only in terms of Pareto gains and Pareto efficiency, while deriving substantially the same conclusions. The point is, a Pareto gain is just another vector (this time in the space of players' joint utilities), and a vector necessarily has a direction! – and thus cooperative gains and Pareto optima give rise implicitly to welfare weightings[16].
Another potential philosophical issue is that we give normative precedence to principals' utility and welfare. If you think the agents might matter in and of themselves too, you might want to do an altered analysis. The modification should be straightforward, and the essence of the conclusions is unchanged (just differently-weighted) unless the agents are utility monsters or moral super-patients.
All of these limitations represent interesting avenues for future work. We’re especially interested in scalable ways to evaluate some of the measures using data gathered from interactions between humans and complex AI systems. We hope these measures will be a useful tool when it comes to thinking about the principles behind building more aligned and cooperative AI systems in multi-polar worlds.
A multi-multi delegation scenario, in ARCHES terminology. ↩︎
When we conceived and did the bulk of work for this paper in late 2022 through early 2023, this was a more speculative claim. Here in mid 2024 it is coming into sharper focus, while still far from certain. ↩︎
We're using the term 'utility' in a technical sense familiar in game theory and decision theory. In particular, it might not correspond exactly to the utility of consequentialist philosophers! It's a measure which rational actors approximately maximise, so it's about decision-making. Importantly (as we'll see later), you could multiply a player’s utilities by 10 (or any positive scalar) and their option preferences and behaviour would stay the same. For principals (humans) in our analysis, it might be appropriate to think of the two senses as being roughly equivalent. For agents (machines/AI), it's all about the de-facto preferences implicit in the decision-making process, not any sense of wellbeing or 'actual preferences' (necessarily). ↩︎
This is a deliberately simple cooperation challenge; in practice the best cases might not be unique, or might be hard to discover, or might not be in agreement between players, or all of these challenges can apply. ↩︎
Incidentally, this is one of the reasons there are not very many mammoths any more...
Seen another way, mammoths weren't part of the human coalition, so what looked like 'cooperation' to us looked like 'collusion' to them (at least, if they had a word for it). ↩︎
Of course, this might not be a good thing: as mentioned above, cooperation by players A and B can look like collusion to player C, if there are negative externalities imposed! Powerful cooperative abilities between AI therefore don’t necessarily bode well for humans. ↩︎
Like 'utility', we're using the term 'welfare' in a technical sense which comes from game theory. It is a tool for scoring an overall outcome for multiple players, when those players might have different preferences over outcomes. It doesn't necessarily refer to what we'd colloquially mean by 'welfare'. On the other hand, it's an aggregation over utilities... so when (for humans and other moral patients) those utilities actually correspond to wellbeing, and importantly when the aggregation is appropriately commensurable, this 'welfare' can indeed correspond to the utility which the philosophers tell us to maximise (disclaimer: not all philosophers)! Hence in part our interest in principals' (humans') welfare regret. ↩︎
There's a small lineage of research into this relationship, beginning, as far as we can tell, with Arrow, Barankin and Blackwell's now-eponymous ABB theorem of 1953. We discuss this more in the appendices to our paper. ↩︎
Of course, in a real chess match, we may share the positive-sum subgoal of 'have fun playing chess together', along with other mutual interests outside the game. ↩︎
The authors include (somewhat inconsistent) vegetarians and care quite a great deal about animal welfare, don't sue us! ↩︎
To briefly elaborate on the technical details, first, notice that a utility function, as a real-valued function, is just a vector. (In general functions are potentially very high dimensional, but here we're visualising a 3d space for simplicity.) The possible utility functions u fill the space. We apply our shift c, projecting onto this lower-dimensional manifold (middle image, here a sort of accretion-disk-looking surface). Now we guarantee that any utility functions which differ only by a constant shift are mapped to exactly the same point, but we still have a spread of magnitudes. Normalising by m projects again onto another lower-dimensional surface (here a 1-d circle), and now we guarantee that any utility functions with the same preferences map to exactly the same point, and any utility functions with different preferences map to different points. We also have a few other mathematical guarantees provided by this procedure, which you can read about in the paper. ↩︎
We mentioned earlier that we also analysed collective alignment. If we have perfect collective alignment too, then calibration doesn't matter, a Pareto optimum is a welfare optimum, so our original guess is borne out. But since we are the designers of agents (AI), not of principals (humans), and it turns out empirically that humans are not perfectly collectively aligned, this case is ruled out! Perfect collective alignment between agents is possible in principle, but seems unlikely in the near future. ↩︎
We haven't explicitly provided theoretical results on the tightness but some of our necessity results suggest the bounds can be tight for the right choice of parameters. ↩︎
This is a really fundamental barrier for contemporary ML-based AI, where most of the computation takes place inscrutably in huge trained neural networks or similar, and we don't even know if the system can be sensibly described by a utility function, let alone what that function would be. (Consider an application of an LLM-derived AI agent.) ↩︎
Indeed, some expect the most transformative impacts from AI to come from the ability to explore outcome- and option-space in ways (or at a pace) that humans can't, i.e. a kind of generalised R&D or experimentalism. ↩︎
There are some edge cases, and the implicit welfare weightings are not uniquely defined if the Pareto frontier is non-strictly convex. ↩︎












Executive summary: Cooperation, alignment, and calibration are all necessary to guarantee good outcomes in multi-agent AI systems, as demonstrate a formal analysis of delegation games.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.