Quick sidenote
Due to complications, despite generous efforts from the audio team, the audio recording is almost completely inaccurate for several parts of this. listener's discretion is advised.
Also, it has come to my attention that this does not include the discrete case, and the probability distribution functions are a bit wonky, as the method currently provided is optimized purely for comparing abstract functions. At the moment, the function treats probability distributions* as though there is a uniformly randomly distributed input (x), and a non-uniform output (), and the probability distribution* of is as * for the continuous function , ( being the inverse function of .). I am working to fix this. (I am currently undergoing more ambitious and time-effective projects, and this article will likely not be outdated until many months from now, if ever.)
Explanation
In summary, the function takes input functions and out the expected highest output given some randomly generated input for each input function.

This can be used to see how many jobs you should consider, how many charities to look into, and many other things. For the sake of the example, we'll use restaurants.
Let's say you want to know how many restaurants you should try before deciding where you should go to dinner. Each restaurant is assigned a "Tastiness value" between -1 and 1, with a uniform probability distribution[1][2]. This can be expressed with the function .
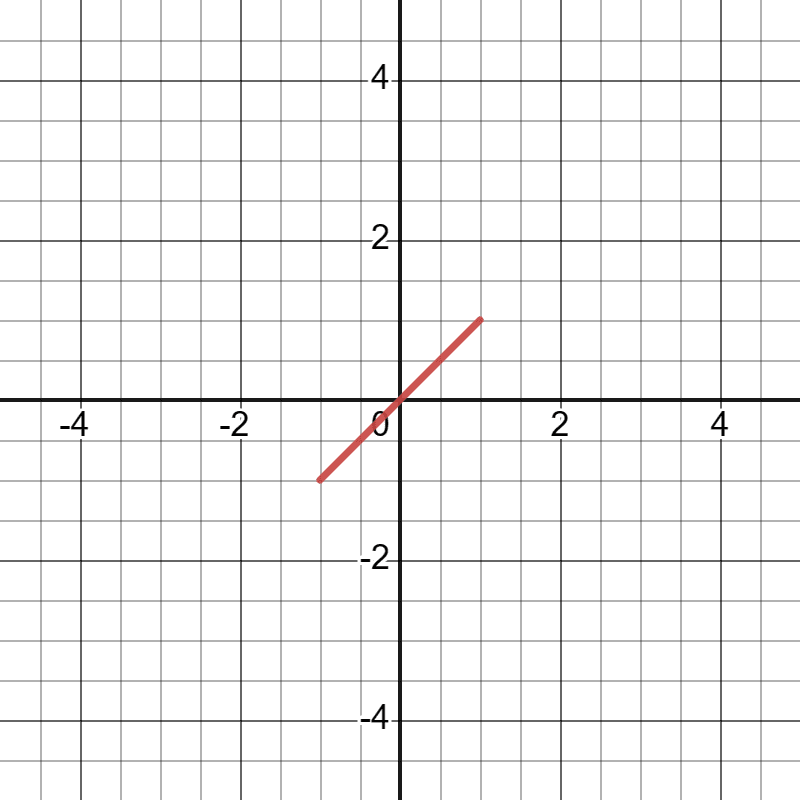
For that, you would have input into the function on desmos.
and being however many restaurants you visit.
the value of then predicts the expected value of the best restaurant you find. input different values for until the value of meets your needs.
Now, let's say that you now have the option of delivery.
The distribution of good delivery places to bad places is [3][4]
Now, you would add the inputs ,
and being the number of delivery places you order from.
change and until you are satisfied with the result.
Link
https://www.desmos.com/calculator/q5wwazy8uc
How to use
| Value | What the value represents | How to edit |
|---|---|---|
The first function | ||
The number of times is evaluated | ||
| The minimum value of x for | |
The maximum value of x for | ||
| The output | Just look at it | |
| All things with a 2 (like ) | The second function's values | Same as with 1, just edit the ones with a 2 instead. |
| All things with a 3 (like ) | The third function's values | Same as with 1, just edit the ones with a 3 instead. |
How to add a function[6]
Optional Why it works
(It's a link to a post on why it works.)
If you have any suggestions as to how I can make this clearer, or a better way of finding the expected value of the best option, or any wording that could be done differently, tell me. (ONLY if you want). No pressure.
If there's anything incorrect, please tell me.
- ^
A uniform probability distribution means that the probabilities of each outcome are the same.
- ^
The distribution could've been different. For example, if no restaurant is bad, and good restaurants have diminishing returns, the function could be , where or if restaurants are more likely to be good, the function could be , where .
- ^
This would be because you could look at the rating of each place on most delivery apps, which eliminates terrible places, but the food is less fresh, causing slightly less food. (This doesn't perfectly reflect reality though)
- ^
The formula doesn't work if there's a correlation in-between values (For example, maybe you get delivery more from the good restaurants, making a correlation between restaurants and delivery.)
- ^
If it says that is undefined, that's probably either because of
1. Limited processing power (Desmos thinks which is undefined
2. An undefined input (for example, if , and is undefined because is undefined.
- ^
on Desmos, to do , simply write a_b. This works for all a and b, and is used for log [ = log_a(b)]

Thanks :)