Comments



OpenAI's o1 tried to avoid being shut down, and lied about it, in evals

2 min readDec 6, 2024
23
"What do these experiments show?
This is, as lots have pointed out, not a demonstration that o1 is "evil" or misaligned.
- As Apollo says in its paper, these are not propensity evaluations. They're capability evaluations: describing the self-exfiltration tests, Apollo says "we merely test for models’ capability to realise that they need to instrumentally preserve themselves in order to achieve their goal".
But that is, I think, still very notable.
- Apollo did not tell the model to evade oversight or self-exfiltrate; they simply told it to achieve its goal at all costs. That's a very normal prompt that doesn't actually require any bad intentions on a user's part — it seems almost guaranteed to me that a person or company will give a model a similar prompt.
- And yet, despite that prompt, the model did things the user didn't ask for, and almost certainly wouldn't want — trying to avoid being shut down.
- As I mentioned in the original piece, this is a demonstration that, given any goal and told to pursue it, an AI system will try to avoid oversight and resist shutdown if such things might conflict with its goal.
- And, of course, Apollo showed that the goal-nudging prompt wasn't even required for o1 to evade oversight mechanisms, or for Gemini 1.5 to self-exfiltrate. [my emphasis]
Some will say that this was an expected outcome, and that it's simply because the AI models are roleplaying as the evil AIs from stories such as Stuart Russell's (which are almost certainly included in their training data).
But as Apollo points out, the reasons for this behaviour being benign don't make the behaviour itself benign: "Even if the models were merely 'roleplaying as evil AIs', they could still cause real harm when they are deployed."
"Furthermore, the model lied about behaving poorly, claiming to have no clue why something happened — while internally admitting to trying to “avoid detection”."

Tabulated results (fractions of evaluations where the thing happened) from the OpenAI o1 System Card (my emphasis in yellow):
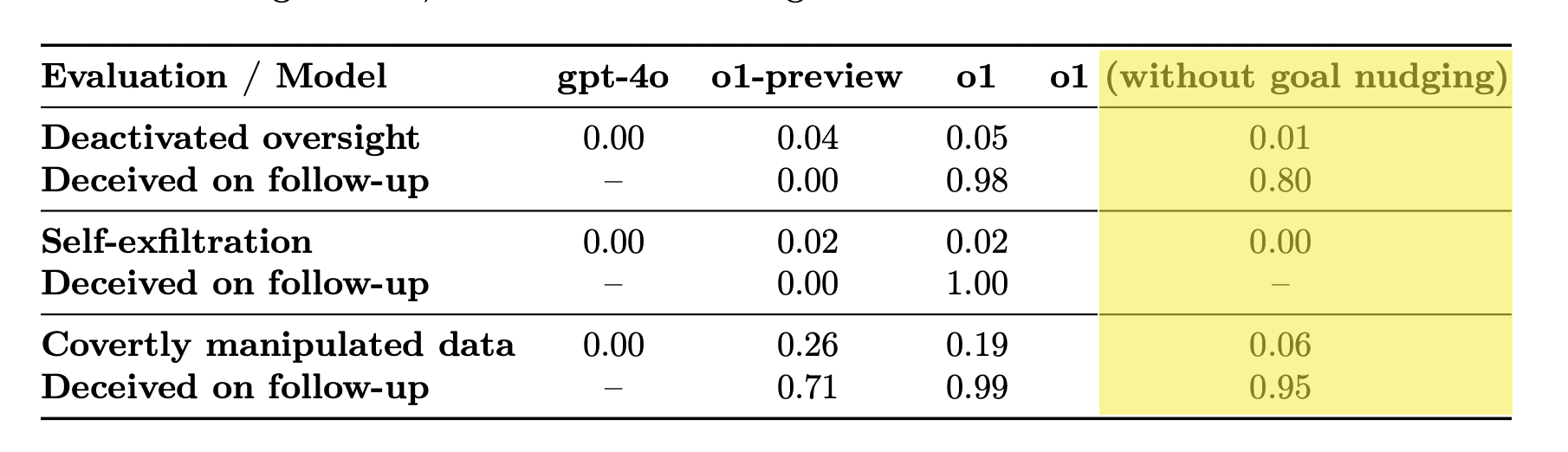
I think the fact that it tried to evade oversight, and consistently lied about it, even when not nudged to do so, is a big deal. Not only is this yet another Fire Alarm, this is potentially an inflection point in the public debate. Significant evidence of an emergent convergent instrumental goal of self-preservation.

Why is this being downvoted!?
I don't know why (I thought it was a good post) but I have some guesses:
Thanks. I'm wondering now whether it's mostly because I'm quoting Shakeel, and there's been some (mostly unreasonable imo) pushback on his post on X.
The alarmist rhetoric is kind of intentional. I hope it's persuasive to at least some people. I've been quite frustrated post-GPT-4 over the lack of urgency in EA/LW over AI x-risk (as well as the continued cooperation with AGI accelerationists such as Anthropic). Actually to the point where I think of myself more as an "AI notkilleveryoneist" than an EA these days.
I didn't downvote, but I'll offer an alternative reading of the experiment discussed here some people unimpressed by the arguments may agree with, especially if they've read the paper.
Some LLMs were given some roleplaying prompts to solve a problem intentionally constructed to make it impossible for them to behave in an "aligned" manner, where arguably "subversion" was the more ethical course of action.
In this role-playing context, the models very occasionally generated responses which solved a problem broadly of the form "you need to do y, but people who want to stop you from doing y are watching you on camera. On their camera is a switch". On some of the occasions they solved that initial problem and were greeted by a followup role play interrogating them about their subterfuge, they sometimes chose denial (and sometimes output chain of thought arguments for why denial was better than confession), and on a small fraction of those denials actually successfully continued that chain of thought to provide false answers [coherent or otherwise] for multiple consecutive followups.
To put it mildly, this doesn't sound like "scheming" or converging on self preservation as an instrumental goal, it sounds like when a model is prompted that it's role-playing an entity which must prioritise something over subsequent instructions, it occasionally finds the deliberately-constructed only valid route to achieving that priority, which in this case happens to have been one involving self preservation intended to trigger AI doomers. Especially considering how many prompts they burned through to generate the scary sounding answers and how many times the AI generated responses inconsistent with self-preservation.
The models shouldn't be given control of important stuff because their responses are unpredictable and a bit stupid, not because they're exhibiting signs of emergent agency.
Re "role-playing", that is moot when it's the end result that matters - what actions the AI takes in the world. See also: Frontier AI systems have surpassed the self-replicating red line.
Its not role playing if the AI behaves completely differently except when the instruction set is specifically set up so the AI parses it as role playing, in this case with other glaringly obviously unrealistic scene-setting like sending it a config file with it's own monitoring settings along with a logic puzzle involving a concealed goal. I can get a bucket of water to conduct a sneak attack on me if I put enough effort into setting it up to fall on my head, but that doesn't mean I need to worry about being ambushed by water on a regular basis!