Comments
On January 14th 2021, Effective Altruism Philadelphia hosted Jeremy Blackburn and Aviv Ovadya for an event about infodemics as a potential cause area. The following is the transcript of Jeremy's talk followed by my interview.
Jeremy: I’m Jeremy Blackburn i’m an assistant professor at Binghamton University, and I run something called the iDRAMA Lab. Before I go any further, the type of work I do involves some disturbing subjects, and though this talk is relatively clean I wanted to give you a heads up that it is talking about some bad stuff.
In a sentence to give you an idea of what I do, myself and the iDRAMA Lab, we’re the International Data-driven Research for Advanced Modeling and Analysis Lab and we focus on sociotechnical problems. What do we mean by sociotechnical problems? Well, they’re sociological issues; how individuals, communities, institutions interact with each other and engage with each other. They’re technical; so we’re talking about sociological concerns that effect and are effected by technology. And problems; we are interested in looking at questions that have a real world impact, not necessarily theoretical stuff but stuff that all of us are encountering on a daily basis.
If you want to look at it another way; we study assholes on the web.
So what do I mean by this type of sociotechnical problem that we deal with? We deal with a lot of racism and harassment online, so like networked harassment where people gang up and attack people, celebrities or whoever. We deal with pizzagate-like misinformation, how fringe communities are causing problems, we look at how fringe communities and racism effect the real world. and also how social media platforms, specifically outside of twitter and facebook and the different affordances they provide, how those effect things. And finally we do a lot obviously on disinformation [i.e. russia] and things like that because all these things are intertwined.
With the type of problems we’re looking at in mind, what can we do? Like i said, we’re computer scientists, most of our background in my group is systems, security, cryptography, that type of thing, and we have a fair bit of experience dealing with types of unwanted activity on social media. So, bots, right, bots are still a problem online, but there’s been a lot of research and progress made. These are large-scale, synchronized, bots work together, and we can build classifiers based on recognizable patterns, there are some of them out there, some work better some work worse [SynchroTrap, EvilCohort, Botometer] but we have something we can build on. But the type of stuff we deal with is not quite like that, we’re dealing with human activity. Sure, bots are involved to some extent, but human activity is the real kicker here. And it’s less coordinated, the characteristic traits stand out less, people are different from each other they’re not similar like bots are. And we also can’t use some of the mitigation solutions for dealing with bots that [the fight against] spam has done, which is to make them expensive. E.g. put a delay in creating accounts or making posts, or banning spam and stuff like that, because state actors have deep pockets; so if they get involved, economic concern is not that big a deal. And also a lot of this stuff is individual people; even though in aggregate it may cost a lot, it may cost 10 minutes of one person’s time, if you have a million people doing it it’s not that expensive .
Finally online services do not exist in a vacuum, we have to look at things a little bit differently. We have lots of social media platforms and content is shared between them, and then it’s also shared with other types of social media platforms that’s maybe not just discussion; maybe pictures or video based or live streaming or email. And then of course we have news services, and they all report on different services and share content with one another. It’s a big ecosystem. So looking at a single service at a time (like twitter) is not enough. And in fact there’s anecdotal evidence, it’s more than anecdotal it turns out we all know now, that fringe communities play a really important role in terms of weaponizing information.
So, what do we do [at iDRAMA Lab]? We take computational methods and we try and use them to understand and mitigate information weaponization at large scale. We use data-driven analysis of complex and intertwined communities, and then our goal is to build proactive and preventative systems to counter this type of stuff. Some of the stuff that we do that we’re known for, that we specialize in, is data collection. We have a large data collection operation grabbing stuff from all sorts of social media platforms. Then we have this huge box of interesting statistical tools, machine learning, all this kind of stuff, so that we can process that data and draw insights. And finally because this is important not just for us, we release this data, we release open source code, to help those that aren’t computer scientists study these same types of problems.
So real quickly i’m going to go over three concrete examples of the type of research that we do.
Raids from 4chan
This one right here we had a paper that was taking a look at 4chan’s politically incorrect board, there’s a lot of stuff in there. If you don’t know what 4chan is, quite honestly you can google it you’ll find it very quickly, but it’s a bad place on the web, it’s one of these anonymous message boards. What’s interesting on 4chan, the results I want to share with you, is that there’s this phenomenon there called raids. Raids are an attempt to disrupt another site, and this is not like a typical security thing like a DDoS attack where you try to knock a server offline, but instead it’s you go there and you’re disrupting the people, the community. So this is a sociotechnical problem, so this is something that’s at least new to computer science, to some extent new to the whole world, where technology is being used to exploit some fundamental aspects of human nature. So youtube is the most commonly linked domain on /pol/, and we have observed them being raided ourselves anecdotally, and we set out to find quantitative evidence of it. So you sit back and you think to yourself “how can a raid happen?”, and as it turns out someone posts a youtube link maybe with a prompt like “you know what to do”. And then the thread becomes an aggregation point for raiders, so they go and post something terrible in the youtube comments and then they come back to the thread on 4chan and talk about how great it is. So if this is taking place then we might expect a degree of synchronization between the activity in the /pol/ thread and the youtube comments, because we have the same set of users at the same period of time talking in both of those places. And after we pulled out our statistical toolbox, and we found a tool, we measured this synchronization.
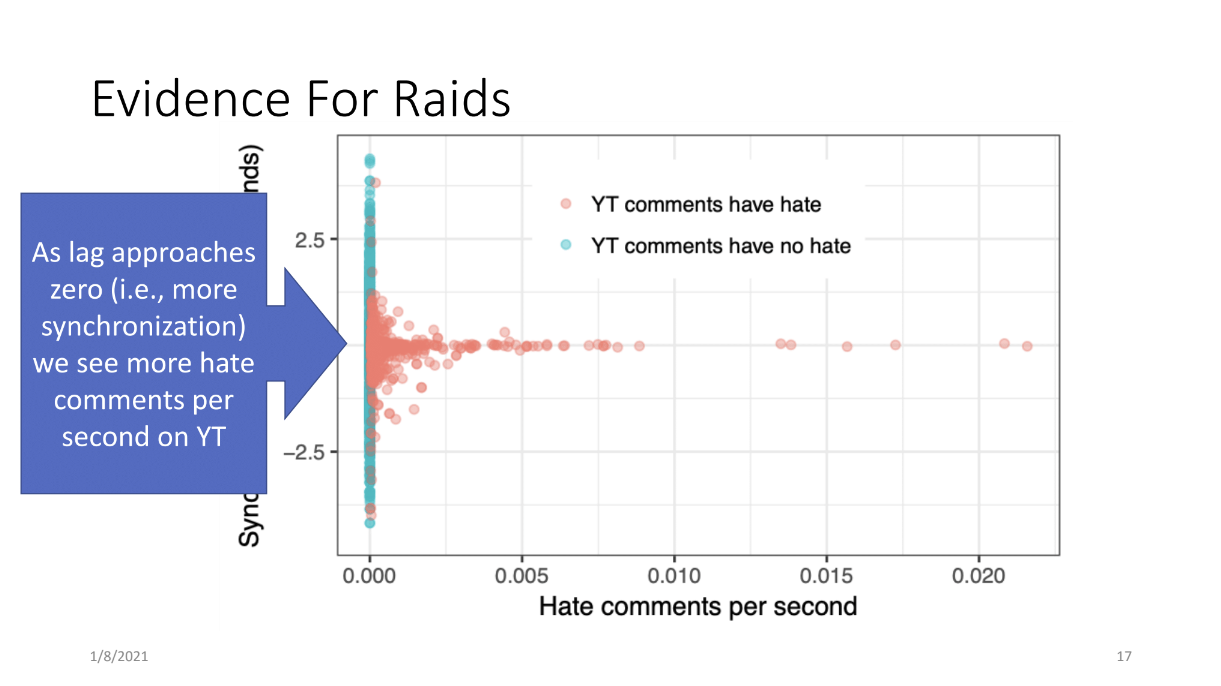
So here I have a plot where on the y axis is the synchronization (0 is perfectly synchronized) and on the x axis I have hate comments per second that show up in youtube videos that we believe might have been raided. So these are youtube videos that have shown up on 4chan, a link. And this is the synchronization level between the 4chan thread and the youtube comments. And as you can see, the tighter/more synchronized they are we do see evidence of increased hate, so this is a way to quantitatively measure and find raids. So that’s a nice little finding there, but the bottom line, what this means, is that fringe communities on the web are not self-contained, they effect other web communities. We can’t just look at twitter, twitter is huge, or youtube or whatever, but these fringe communities are causing problems on other platforms.
On the Origins of Memes by Means of Fringe Web Communities
[In] another paper we did, we were exploring memes. Everybody I assume knows what a meme is, you’re in a zoom call so you’ve probably seen at least one or two in your life, so memes are everywhere. And a big problem with memes is that they’re not always fun and entertaining, but there’s hateful and racist memes. And they’ve been updated, there’s variants of these different memes. And memes have, at least in some part, been directly linked to violent action. So memes have become a popular, and seemingly effective, method to transmit ideology. Memes have been weaponized. So you sit back and think to yourself what do we really know about memes? How can we track meme propagation on the web? How can we characterize variants of the same meme? Can we characterize web communities through the lens of memes? And as it turns out, you can. What we had to do was build a big complicated system that processed hundreds of millions of images to produce clusters of similar memes. And then doing that we could make a lot of findings, but basically we came up with an ecosystem of memes, different clusters of memes. But the point is we can look at this stuff at scale.

Sinophobia and Covid19
And finally I want to show a recent work that’s dealing with the emergence of sinophobic behavior in the face of COVID-19. As you all know, clearly, things went crazy last year. We had the president and many other people saying “the China flu” and how everything’s from China, so we wanted to take a look at, “hey, has there been an increase in sinophobic behavior? How does it show up?” And here I have a plot; in as simplified fashion as possible, we’re extracting word embeddings which is a way for us to understand how similar words are, if they’re used in similar contexts, and we are creating word embeddings from 4chan every week.
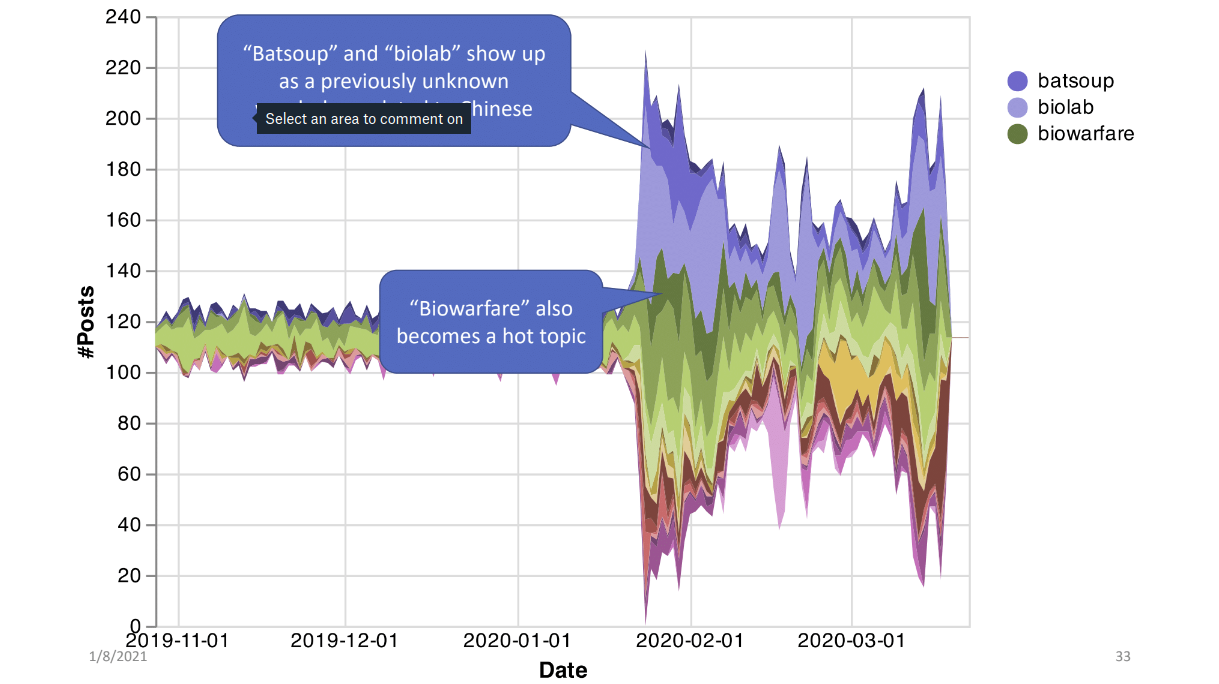
And then, at the end of the week, we’re looking at the previous week and asking “hey, what words that /pol/ is using this week that are becoming more and more similar to, or used in the same context as, the word 'Chinese'?” And this is shown over time. So what happened is we found some interesting things, we found new words, words that had never really showed up on 4chan before right around the time that Wuhan got locked down. So like “batsoup” and “biolab”, some conspiracies related to Covid-19, but specifically these are things that are similar contextually in the language to “China/Chinese”. Also you see a specific type of conspiracy showing up; biowarfare, which didn’t ever really appear. There was other kind of conspiratorial stuff that appeared, but then as soon as Wuhan went into lockdown, we see this specific biowarfare thing. So that’s showing that these conspiracies spawn new languages and things like that.
So in quick summary, there’s a lot of messed up things going on online, they threaten society in a variety of ways, and data-driven approaches can help us gain a new kind of insight. Ok, so that’s my talk to give you all an idea of what it is and the kind of work I do, I hope it was useful.
Quinn: Thank you Jeremy. So I have quite a few questions, then I’m going to take one or two from the audience, then we’re going to go to Aviv’s talk, then we’re going to have a larger opportunity for audience questions after Aviv’s talk.
Jeremy: sounds good.
Importance
Quinn: So I really want to get into what it would take to get a measure of the importance of this, in a way that we could compare it to other causes. The two big things I see are cyberbullying and physical violence. Cyberbullying isn’t a term you used, but I just mean having to log into the internet and see a hateful meme about a demographic you’re a part of, that’s a problem. I have this intuition that physical violence is worse than cyberbullying, but that there’s more cyberbullying than there is physical violence.
Jeremy: I’ve done a fair amount of work on cyberbullying in the past as well, it’s a good question, and it’s difficult to say. Cyberbullying can be some serious stuff; people kill themselves over it, it can be bad. So i don’t know if I feel comfortable weighing them. But I can say that the large scale violence, social upheaval, attempts to overthrow democracy, those are definitely larger scale, and wars tend to be worse than individuals being targeted. However, interestingly enough, there’s a crossover in strategies: The same type of content that can be used to cyberbully somebody is the same strategies that can be used to incite other people to maybe take other kinds of actions.
Quinn: Have you tried estimating a proportion; if you look at all the hateful memes, take ones that bleed over into the real world and are associated with physical violence as a percentage of hateful memes in general?
Jeremy: I don’t think we’ll ever be able to say “this specific meme was necessarily an influence”, however more recently i think that it may be a little more possible, because memes are showing up on tshirts, flags, etc. so we may be able to have a better idea of what at least category of memes let’s say have enough of an impact for people to go do something and at least wear them, show them off. We have, though, been able to show which platforms are more effective in disseminating certain types of memes, which is also perhaps related to this type of thing of real world action because certain communities are better known to initiate real world action. 4chan is generally speaking a bunch of LARPers though they obviously have their people that mess stuff up, whereas you have larger groups like thedonald.win which was actively, allegedly, planning the coup [Jan 6 2021].
Tractability
Quinn: I want to move on to tractability here. What are the main points of leverage that take us the step from analysis to prevention?
Jeremy: So this is unfortunately one of the questions that most computer scientists in the security field, it’s easy for them to answer; “you detect, you block”, this sort of thing. But for these types of issues you’re running up into issues of policy, questions of freedom of speech, content moderation, fairness and balance, this type of stuff. It’s a huge challenge, we have a long way to go. Whenever you get ML [machine learning] involved that’s great because you can work at the scale of the web, but whenever you get ML involved there’s a bunch of edge cases at best and bias at worst. I don’t think that AI is going to get to the point where it’s as good as a human, but there has to be outside stuff. It can’t just be a content moderation policy, there have to be active measures to try to educate people better, to counter-message, coming not from twitter or facebook or even the government, but from positive actors.
And if you’ll let me follow up, we actually do have some work that is an attempt to kind of go from the computer security angle of building detection and blocking it: for those raids i talked about, we built a classifier that when you upload a video to youtube, before the attack happens, we can say “hey, there’s a 90% chance that 4chan is going to come raid this video” and that is kind of flipping the problem, so a lot of times you’re looking for content that’s bad, instead if you can perhaps provide people when they post something with “hey, not saying you shouldn’t post this, but it might attract some bad people so maybe you can implement some additional moderation tools”, this sort of thing. That’s the kind of type of thing that may work eventually, flipping the script.
Quinn: I have one more question on tractability before I get into neglectedness. My understanding of bot detection is that it’s a bit of a cat & mouse game. Where you can train a bot army with respect to the current bot detection paradigm, and bot armies can easily learn to outsmart the detection algorithm. If this is basically accurate, have you had any ideas how to break out of this and make it not in this cat & mouse mode?
Jeremy: Yeah, bot detection is absolutely that. It’s like malware. It’s an arms race. And i don’t think there will ever be a way to eliminate it completely, again I think that the mechanisms are to somehow make it less useful. But the fact of the matter is social media’s major usefulness is being able to broadcast and increase your reach. So if bots are able to abuse that, they’re going to abuse it. I don’t see there’s any way, because every single thing you can think of, if there’s money to be made people will find a way. It’s more about updating things as fast as possible, trying to respond as fast as possible.
Neglectedness
Quinn: On neglectedness, I just have one question. Why does the responsibility fall to computer science departments and social science departments? Is that a bug or a feature, the fact that iDRAMA Lab has to step up?
Jeremy: I can speak from a computer science side. This isn’t the work I wanted to go into, or even thought about going into, or even started with when I was working on my PhD. I was doing distributed systems, making peer-to-peer social networks and this type of thing. But the bottom line is I was sitting there creating systems that were being exploited. And I was creating systems that were censorship resistant let’s say, or at least resilient, then you see that nazis or whoever are using it. In peer-to-peer protocols for social media, obviously encryption, I believe that it’s all important, but on the other hand most computer scientists (nearly all of them) never think about the negative risk. So I believe that I personally have a responsibility to society to make sure at least somebody is paying attention and trying to fix these problems. But, it shouldn’t be my responsibility only. Obviously social media companies and industry need to step up to the game.
Quinn: So social media companies and industry need to have departments opened up to step up and worry about this, like you just said
Jeremy: and to some extent they have, facebook and twitter have their content moderation policy teams, but clearly things are not under control. I haven’t worked with one of these, I’ve interacted with them to some extent, but i’m sure they need to increase budget and all this kind of stuff. It’s their responsibility too.
Quinn: And what’s your opinion about governments and states?
Jeremy: *sigh* my opinion is that ideally I would love for no government or state actor to have to get involved in this at all. That would be great. But also i mean, countries exist. I don’t know, my gut instinct is that more regulation here is dangerous, because it can be abused. Again, just like the tools computer scientists build, any regulation here can perhaps be exploited later. And also social media companies haven’t taken action and I’m concerned. Something has to happen, but I imagine any time regulation here gets involved it’s going to be a double edged sword.
Quinn: So where can people donate to put money into this problem?
Jeremy: I’m in academia, to support research in academia it’s a whole different ball game. The best way to do it is to have an institution or a fund that’s specifically focused on this type of stuff. In terms of research, for me, $300 is not that much but $10000 is a meaningful amount for academics to some extent. But it’s difficult for me to directly take money. That’s the problem though, you have NGOs, you have academic institutions, and again, there’s not really anyone focused on funding this. NSF, the National Science Foundation, doesn't have a separate program for people that are trying to deal with these problems. They have stuff for people trying to deal with cryptography, let’s say, but not this type of thing. So really there needs to be some kind of organizations focused specifically on funding this body of work.

