Comments
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...

Most AI biosecurity work maps models, compute, labs, DNA synthesis screening, and experimental misuse pathways. Those are necessary targets. But while mapping genomics infrastructure, I kept running into a different question: where does biological data actually become usable capability?
A repository tells you where files are. It does not tell you who can use them, what metadata they can see, what approvals are required, what compute environment they must use, what outputs they can export, or whether the analysis can be reproduced outside a controlled platform. That distinction may matter more than the repository map itself.
Sequence data alone rarely create capability. Useful biological capability usually requires phenotype data, clinical context, outbreak metadata, labels, benchmarks, approved users, cloud-scale compute, and platform-specific tools. So the question worth testing is not simply who has the data. It is who can turn the data into capability.
The hypothesis
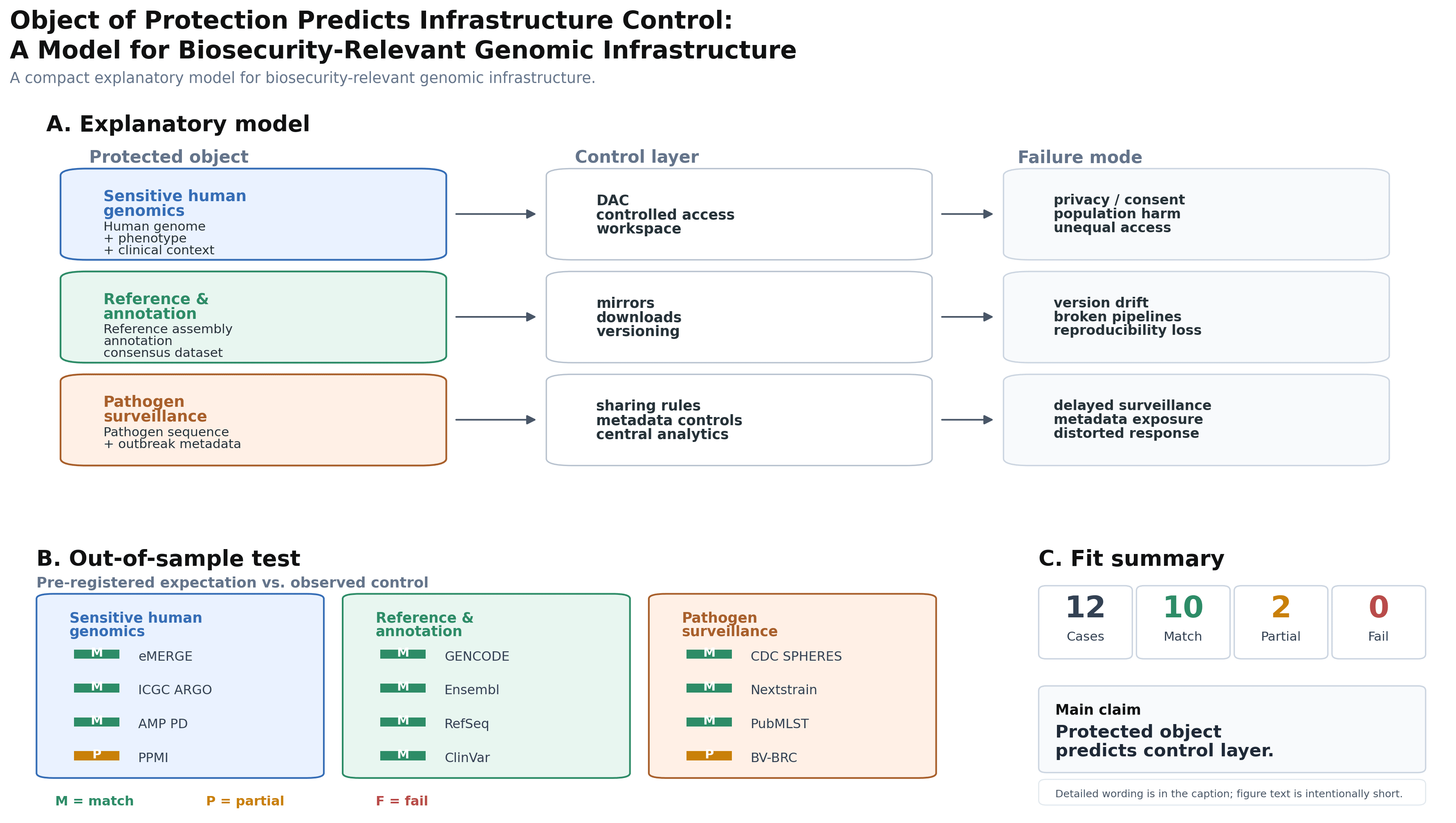
The form of control in any genomics system depends on what that system is trying to protect.
If the protected object is participant privacy, clinical context, and consent, control tends to cluster around data access committees, controlled repositories, researcher identity, and approved workspaces. If the protected object is reproducibility, interoperability, and scientific continuity, control tends to cluster around mirrors, versioning, standards, annotation governance, and long-term stewardship. If the protected object is outbreak interpretation or surveillance speed, control tends to cluster around metadata, attribution, release timing, curation, and central analytics. If the protected object is analytic capability at scale, control tends to cluster around cloud workbenches, export rules, compute environments, platform terms, and exit costs. If the protected object is economic or strategic value, control may appear through ownership, licensing, jurisdiction, or platform governance entirely.
This is not a policy recommendation. It is a proposed map of where to look first.
Why this is worth arguing about
A simple repository map misses several important cases.
In controlled human genomics, the key bottleneck is often not storage. It is access plus metadata plus analysis environment. A researcher may know that a dataset exists, but practical use depends on committee approval, consent-compatible use, linked phenotype data, and an approved workspace. UK Biobank marks the clearest example of what this looks like in practice. Its Research Analysis Platform is not a convenience layer. For many large-scale analyses, the platform is part of the practical capability stack. Formal access to data is not the same thing as the practical ability to analyze it at scale. The transition is worth stating plainly: the repository controls data, the platform controls analysis, and the platform controls practical capability. For biosecurity analysts, that is a control shift that repository maps will not show.
Reference resources behave differently. Resources like 1000 Genomes, GENCODE, RefSeq, Ensembl, ClinVar, and the Human Pangenome Reference Consortium are valuable precisely because they are downloadable, mirrored, versioned, cited, and reused widely. Their control layer is not mainly access denial. It is stewardship: who maintains canonical versions, annotations, standards, mirrors, and backward compatibility. This also means open scientific infrastructure should not be reflexively treated as a vulnerability. Some legacy FTP endpoints and public mirrors exist because older publications and workflows depend on them. The right question is not only "why is this public?" It is "what scientific function does this open access preserve, and what would break if it disappeared?"
Pathogen genomics sits between these two cases. Raw sequences may be shared openly, but useful interpretation depends on metadata, attribution, timing, curation, dashboards, lineage assignment, and central analytics. In pathogen genomics, metadata governance can become capability governance. Models or analyses built from sequences alone may have limited utility compared with systems that incorporate curated metadata, outbreak context, and analytic pipelines. That gap is where the control actually lives.
Finally, control can change without moving the data at all. A population genomics resource can remain physically located in the same place while its practical governance shifts through acquisition, licensing, platform terms, corporate strategy, or jurisdictional exposure. The deCODE case illustrates the point. A nationally significant population genomics capability can sit inside a private corporate structure with a foreign parent company, and the key question is not where the data are stored but who can change the rules governing use, licensing, access, and strategic direction. A repository map will miss this entirely.
What would make this useful
The useful output here is not a taxonomy for its own sake. It is a better map of capability-control points.
For any high-value genomics resource, you want to know who approves access, what metadata are necessary for useful analysis, whether analysis requires an approved platform, what outputs can be exported, whether results can be reproduced elsewhere, who owns or governs the workbench, and what happens if rules, costs, metadata access, or platform terms change. That does not immediately tell policymakers what to do. But it tells analysts where control actually sits, which is the prior question.
Where I want pushback
I am especially interested in cases that break this framing.
Possible counterexamples worth examining: human genotype-phenotype resources where there is no meaningful committee oversight, workspace requirement, consent condition, or metadata control; reference resources where access denial rather than stewardship is the dominant control point; pathogen surveillance systems where metadata, timing, attribution, and analytics turn out to be irrelevant to capability; population genomics resources where ownership, licensing, platform terms, and jurisdiction have no practical effect; and AI biology datasets where the repository is clearly the main control point and the workbench and metadata layer add little.
I do not want this framework to harden into a neat taxonomy that practitioners find obvious or circular. I want to know whether it helps locate capability-control points that repository maps miss. If it does not do that, it is not worth keeping.
Questions for practitioners
For people working on genomic data access, biosecurity, data commons, pathogen surveillance, cloud workbenches, or AI biology governance, a few questions worth sitting with: Is "data-to-capability layer" a useful phrase, or is this already covered by another term in your field? In your domain, what actually controls capability: the repository, the committee, the metadata, the workbench, the standards body, the owner, or something else? Are there important cases where data are technically accessible but practically unusable without a specific platform? Are there cases where open infrastructure is being misread as a security exposure when it is actually serving a reproducibility function? Which existing governance debates already address this layer but under different language?
The claim worth defending
A map of genomic repositories is not enough for AI biosecurity.
The more relevant map is the layer that determines who can turn biological data into usable capability. The location of that layer varies by what the system is trying to protect: privacy points toward access and consent controls, reproducibility points toward stewardship and standards, surveillance value points toward metadata and interpretation, analytic capability points toward workbenches and export rules, and strategic or economic value points toward ownership and platform governance.
This is not yet a recommendation. It is a proposed target for argument. If it is wrong, the most useful response is not "this is obvious." It is a specific case where the protected object does not predict the control layer.

