In short: There are many methods to pool forecasts. The most commonly used is the arithmetic mean of probabilities. However, there are empirical and theoretical reasons to prefer the geometric mean of the odds instead. This is particularly important when some of the predictions have extreme values. Therefore, I recommend defaulting to the geometric mean of odds to aggregate probabilities.
Epistemic status: My impression is that geometric mean of odds is the preferred pooling method among most researchers who have looked into the topic. That being said, I only cite one study with direct empirical evidence supporting my recommendation.
One key piece of advice I would give to people keen on forming better opinions of the world is to pay attention to many experts, and to reason things through a few times using different assumptions. In the context of quantitative forecasting, this results in many predictions, that together paint a more complete picture.
But, how can we aggregate the different predictions? Ideally, we would like a simple heuristic that pools the many experts and models we have considered and produce an aggregate prediction [1].
There are many possible choices for such a heuristic. A common one is to take the arithmetic mean of the individual predictions :
We see an example of this approach in this article from Luisa Rodriguez, where it is used to aggregate some predictions about the chances of a nuclear war in a year.
A different heuristic, which I will argue in favor of, is to take the geometric mean of the odds:
Whereas the arithmetic mean adds the values together and divides by the number of values, the geometric mean multiplies all the values and then takes the N-th root of the product (where N = number of values).
And the odds equal the probability of an event divided by its complement, .[2]
For example, in Rodriguez's article we have four predictions from different sources [3]:
| Probabilities | Odds |
|---|---|
| 1.40% | 1:70 |
| 2.21% | 1:44 |
| 0.39% | 1:255 |
| 0.40% | 1:249 |
Rodriguez takes as an aggregate the arithmetic mean of the probabilities , which corresponds to pooled odds of about .
If we take the geometric mean of the odds instead we will end with pooled odds of , which corresponds to a pooled probability of about .
In the remainder of the article I will argue that the geometric mean of odds is both empirically more accurate and has some compelling theoretical properties. In practice, I believe we should largely prefer to aggregate probabilities using the geometric mean of odds.
The (extremized) geometric mean of odds empirically results in more accurate predictions
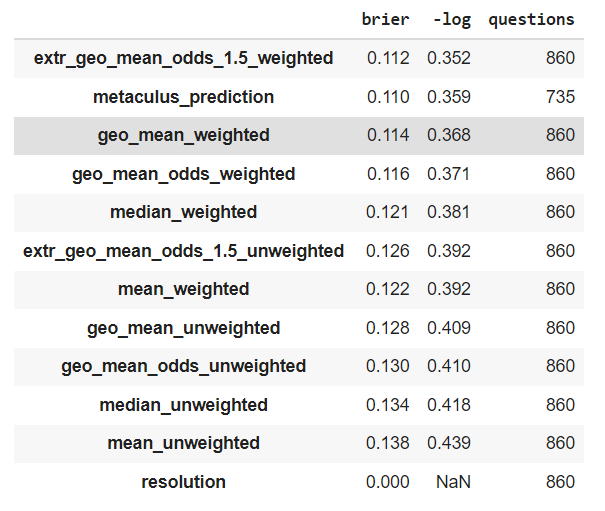
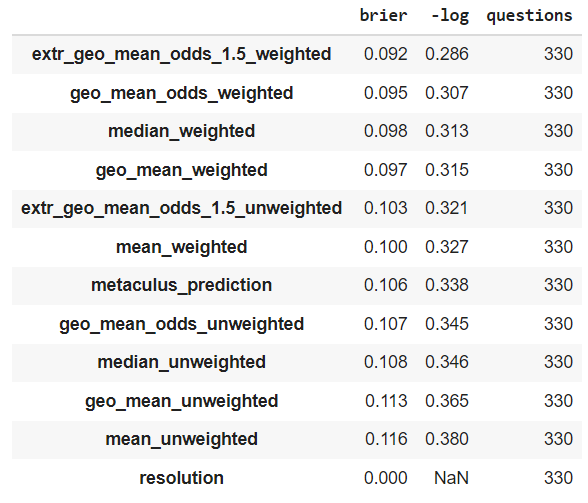
(Satopää et al, 2014) empirically explores different aggregation methods, including average probabilities, the median probability, and the geometric mean of the odds - as well as some more complex methods of aggregating forecasts like and extremized version of the geometric mean of the odds and the beta transformed linear opinion pool. They aggregate responses from 1300 forecasters over 69 questions on geopolitics [4].
In summary, they find that the extremized geometric mean of odds performs best in terms of the Brier score of its predictions. The non-extremized geometric mean of odds robustly outperforms the arithmetic mean of probabilities and the median, though it performs worse than some of the more complex methods.
We haven't quite explained what extremizing is, but it involves raising the pooled odds to a power [5]:
In their dataset, the extremizing parameter that attains the best Brier score falls between and . As a handy heuristic, when extremizing I suggest using a power of in practice. My intuition is that extremizing makes most sense when aggregating data from underconfident experts, and I would not use it when aggregating personal predictions derived from different approaches. This is because extremizing is meant to be a correction for forecaster underconfidence [6]. That being said, it is unclear to me when extremizing helps (eg see Simon_M's comment for an example where extremizing does not help improve the aggregate predictions).
What do other experiments comparing different pooling methods find? (Seaver, 1978) performs an experiment where the performance of the arithmetic mean of probabilities and the geometric mean of odds is similar (he studies 11 groups of 4 people each, on 100 general trivia questions). However, Seaver studies questions where the individual probabilities are in a range between 5% and 95%, where the difference between the two methods is small.
In my superficial exploration of the literature I haven't been able to find many more empirical studies (EDIT: see Simon_M's comment here for a comparison of pooling methods on Metaculus questions). There are plenty of simulation studies - for example (Allard et al, 2012) find better performance of the geometric mean of odds in simulations.
The geometric mean of odds satisfies external Bayesianity
(Allard et al, 2012) explore the theoretical properties of several aggregation methods, including the geometric average of odds.
They speak favorably of the geometric mean of odds, mainly because it is the only pooling method that satisfies external Bayesianity [7] This result was proved before in (Genest, 1984).
External Bayesianity means that if the experts all agree on the strength of the Bayesian updates of each available piece of evidence, it does not matter whether they aggregate their posteriors, or if they aggregate their priors first then apply the updates - the result is the same.
External Bayesianity is compelling because it means that, from the outside, the group of experts behaves like a Bayesian agent - it has a consistent set of priors that are updated according to Bayes rule.
For more discussion on external Bayesianity, see (Madanski, 1964).
While suggestive, I consider external Bayesianity a weaker argument than the empirical study of (Satopää et al, 2014). This is because the arithmetic mean of probabilities also has some good theoretical properties of its own, and it is unclear which properties are most important. I do however believe that external Bayesianity is more compelling than the other properties I have seen discussed in the literature [8].
The arithmetic mean of probabilities ignores information from extreme predictions
The arithmetic mean of probabilities ignores extreme predictions in favor of tamer results, to the extent that even large changes to individual predictions will barely be reflected in the aggregate prediction.
As an illustrative example, consider an outsider expert and an insider expert on a topic, who are eliciting predictions about an event. The outsider expert is reasonably uncertain about the event, and each of them assigns a probability of around 10% to the event. The insider has priviledged information about the event, and assigns to it a very low probability.
Ideally, we would like the aggregate probability to be reasonably sensitive to the strength of the evidence provided by the insider expert - if the insider assigns a probability of 1 in 1000 the outcome should be meaningfully different than if the insider assigns a probability of 1 in 10,000 [9].
The arithmetic mean of probabilities does not achieve this - in both cases the pooled probability is around . The uncertain prediction has effectively overwritten the information in the more precise prediction.
The geometric mean of odds works better in this situation. We have that , while . Those correspond respectively to probabilities of 1.04% and 0.33% - showing the greater sensitivity to the evidence the insider brings to the table.
See (Baron et al, 2014) for more discussion on the distortive effects of the arithmetic mean of probabilities and other aggregates.
Do the differences between geometric mean of odds and arithmetic mean of probabilities matter in practice?
Not often, but often enough. For example, we already saw that the geometric mean of odds outperforms all other simple methods in (Satopää et al, 2014), yet they perform similarly in (Seaver, 1978).
Indeed, the difference between one method or another in particular examples may be small. Case in point, the nuclear war example - the difference between the geometric mean of odds and arithmetic mean of probabilities was less than 3 in 1,000.
This is often the case. If the individual probabilities are in the 10% to 90% range, then the absolute difference in aggregated probabilities between these two methods will typically fall in the 0% to 3% range.
Though, even if the difference in probabilities is not large, the difference in odds might still be significant. In the nuclear war example above there was a factor of 1.3 between the odds implied by both methods. Depending on the application this might be important [10].
Furthermore, the choice of aggregation method starts making more of a difference as your probabilities become more extreme : if the individual probabilities are within the range 0.7% to 99.2% then the difference will typically fall between 0% to 18% [11].
Conclusion
If you face a situation where you have to pool together some predictions, use the geometric mean of odds. Compared to the arithmetic mean of probabilities, the geometric mean of odds is similarly complex*, one empirical study and many simulation studies found that it results in more accurate predictions, and it satisfies some appealing theoretical properties, like external Bayesianity and not overweighting uncertain predictions.
* Provided you are willing to to work with odds instead of probabilities, which you might not be comfortable with.
Acknowledgements
Ben Snodin helped me with detailed discussion and feedback, which helped me clarify my intuitions about the topic while we discussed some examples. Without his help I would have written a much poorer article.
I previously wrote about this topic on LessWrong, where UnexpectedValues and Nuño Sempere helped me clarify a few details I had wrong.
Spencer Greenberg wrote a Facebook post about aggregating forecasts that spurred discussion on the topic. I am particularly grateful to Spencer Greenberg, Gustavo Lacerda and Guy Srinivasan for their thoughts.
And thank you Luisa Rodriguez for the excellent post on nuclear war. Sorry for picking on your aggregation in the example!
Footnotes
[1] We will focus on prediction of binary events, summarized as a single number , the probability of the event. Prediction for multiple outcome events and continuous distributions fall outside of the scope of this post, though equivalent concepts to the geometric average of odds exist for those cases. For example, for multiple outcome events we may use the geometric mean of the vector odds, and for continuous distributions we may use as in (Genest, 1984).
[2] There are many equivalent formulations for the formula of geometric mean odds pooling in terms of probabilities .
One possibility is
That is, the pooled probability equals the geometric mean of the probabilities divided by the sum of the geometric mean of the probabilities and the geometric mean of the complementary probabilities.
Another possibile expression for the resulting pooled probability is:
[3] I used this calculator to compute nice approximations of the odds.
[4] (Satopää et al, 2014) also study simulations in their paper. The results of their simulations are similar to their empirical results.
[5] The method is hardly innovative - many others have proposed similar corrections to pooled aggregates, with similar proposals appearing as far back as (Karmarkar, 1978).
[6] Why use extremizing in the first place?
(Satopää et al, 2014) derive this correction from assuming that the predictions of the experts are individually underconfident, and need to be pushed towards an extreme. (Baron et al, 2014) derive the same correction from a toy scenario in which each forecaster regresses their forecast towards uncertainty, by assuming that calibrated forecasts tend to be distributed around 0.
Despite the wide usage of extremizing, I haven't yet read a theoretical justification for extremizing that fully convinces me. It does seem to get better results in practice, but there is a risk this is just overfitting from the choice of the extremizing parameter.
Because of this, I am more hesitant to outright recommend extremizing.
[7] Technically, any weighted geometric average of the odds satisfies external Bayesianity. Concretely, the family of aggregation methods according to the formula:
where and covers all externally Bayesian methods. Among them, the only one that does not privilege any of the experts is of course the traditional geometric average of odds where .
[8] The most discussed property of the arithmetic mean of probabilities is marginalization. We say that a pooling method respects marginalization if the marginal distribution of the pooled probabilities equals the pooled distribution of the marginals.
There is some discussion on marginalization in (Lindley, 1983), where the author argues that it is a flawed concept. More discussion and a summary of Lindley's results can be found here.
[9] There are some concievable scenarios where we might not want this behaviour. For example, if we are risk averse in a way such that we prefer to defer to the most uncertain experts, or if we expect the predictions to be noisy, and thus we would like to avoid outliers. But largely I think those are uncommon and somewhat contrived situations.
[10] The difference between the methods is probably not significant when using the aggregate in a cost-benefit analysis, since expected value depends linearly on the probability which does not change much. But it is probably significant when using the aggregate as a base-rate for further analysis, since the posterior odds depend linearly on the prior odds, which change moderately.
[11] To compute the ranges I took 100,000 samples of 10 probabilities whose log-odd expression was normally distributed and reported the 5% and 95% quantiles for both the individual probabilities sampled and the difference between the pooled probabilities implied by both methods on each sample. Here is the code I used to compute these results.
Bibliography
Allard, D., A. Comunian, and P. Renard. 2012. ‘Probability Aggregation Methods in Geoscience’. Mathematical Geosciences 44 (5): 545–81. https://doi.org/10.1007/s11004-012-9396-3.
Baron, Jonathan, Barb Mellers, Philip Tetlock, Eric Stone, and Lyle Ungar. 2014. ‘Two Reasons to Make Aggregated Probability Forecasts More Extreme’. Decision Analysis 11 (June): 133–45. https://doi.org/10.1287/deca.2014.0293.
Genest, Christian. 1984. ‘A Characterization Theorem for Externally Bayesian Groups’. The Annals of Statistics 12 (3): 1100–1105.
Lindley, Dennis. 1983. ‘Reconciliation of Probability Distributions’. Operations Research 31 (5): 866–80.
Karmarkar, Uday S. 1978. ‘Subjectively Weighted Utility: A Descriptive Extension of the Expected Utility Model’. Organizational Behavior and Human Performance 21 (1): 61–72. https://doi.org/10.1016/0030-5073(78)90039-9.
Madansky, Albert. 1964. ‘Externally Bayesian Groups’. RAND Corporation. https://www.rand.org/pubs/research_memoranda/RM4141.html.
Satopää, Ville A., Jonathan Baron, Dean P. Foster, Barbara A. Mellers, Philip E. Tetlock, and Lyle H. Ungar. 2014. ‘Combining Multiple Probability Predictions Using a Simple Logit Model’. International Journal of Forecasting 30 (2): 344–56. https://doi.org/10.1016/j.ijforecast.2013.09.009.
Seaver, David Arden. 1978. ‘Assessing Probability with Multiple Individuals: Group Interaction Versus Mathematical Aggregation.’ DECISIONS AND DESIGNS INC MCLEAN VA. https://apps.dtic.mil/sti/citations/ADA073363.
{kind=link}
Right, the evidence about the experts come from the new evidence that's being updated on, not the pooling procedure. Suppose we're pooling expert judgments, and we initially consider them all equally credible, so we use a symmetric pooling method. Then some evidence comes in. Our experts update on the evidence, and we also update on how credible each expert is, and pool their updated judgments together using an asymmetric pooling method, weighting experts by how well they anticipated evidence we've seen so far. This is clearest in the case where each expert is using some model, and we believe one of their models is correct but don't know which one (the case you already agreed arithmetic averages of probabilities are appropriate). If we were weighting them all equally, and then we get some evidence that expert 1 thought was twice as likely as expert 2, then now we should think that expert 1 is twice as likely to be the one with the correct model as expert 2 is, and take a weighted arithmetic mean of their new probabilities where we weight expert 1 twice as heavily as expert 1. When you do this, your pooled probabilities handle Bayesian updates correctly. My point was that, even outside of this particular situation, we should still be taking expert credibility into account in some way, and expert credibility should depend on how well the expert anticipated observed evidence. If two experts assign odds ratios r0 and s0 to some event before observing new evidence, and we pool these into the odds ratio r1/20s1/20, and then we receive some evidence causing the experts to update to r1 and s1, respectively, but expert r anticipated that evidence better than expert s did, then I'd think this should mean we would weight expert r more heavily, and pool their new odds ratios into r2/31s1/31, or something like that. But we won't handle Bayesian updates correctly if we do! The external Bayesianity property of the mean log odds pooling method means that to handle Bayesian updates correctly, we must update to the odds ratio r1/21s1/21, as if we learned nothing about the relative credibility of the two experts.
I suppose one reason not to see this as unfairly biased towards mean log odds is if you generally expect experts who give more extreme probabilities to actually be more knowledgeable in practice. I gave an example in my post illustrating why this isn't always true, but a couple commenters on my post gave models for why it's true under some assumptions, and I suppose it's probably true in the data you've been using that's been empirically supporting mean log odds.
I can see where you're coming from, but have an intuition that the geometric mean still trusts the information from outlying extreme predictions too much, which made a possible compromise solution occur to me, which to be clear, I'm not seriously endorsing.
I called it that because of its poor theoretical properties (I'm still not convinced they arise naturally in any circumstances), but in retrospect I don't really endorse this given the apparently good empirical performance of mean log odds.
My take on this is that multiplying odds ratios is indeed a natural operation that you should expect to be an appropriate thing to do in many circumstances, but that taking the nth root of an odds ratio is not a natural operation, and neither is taking geometric means of odds ratios, which combines both of those operations. On the other hand, while adding probabilities is not a natural operation, taking weighted averages of probabilities is.
Right, but I was talking about doing that backwards. If you've already worked out for which odds it's worth accepting bets in each direction at, recover the probability that you must currently be assigning to the event in question. Arithmetic means of the bounds on probabilities implied by the bets you'd accept is a rough approximation to this: If you would be on X at odds implying any probability less than 2%, and you'd bet against X at odds implying any probability greater than 50%, then this is consistent with you currently assigning probability 26% to X, with a 50% chance that an adversary has evidence against X (in which case X has a 2% chance of being true), and a 50% chance that an adversary has evidence for X (in which case X has a 50% chance of being true).
It isn't. My post was about pooling multiple probabilities of the same event. One source of multiple probabilities of the same event is the beliefs of different experts, which your post focused on exclusively. But a different possible source of multiple probabilities of the same event is the bounds in each direction on the probability of some event implied by the betting behavior of a single expert.