Introduction
The last few years have seen a proliferation of forecasting platforms. These platforms differ in many ways, and provide different experiences, filters, and incentives for forecasters. Some platforms like Metaculus and Hypermind use volunteers with prizes, others, like PredictIt and Smarkets are formal betting markets.
Forecasting is a public good, providing information to the public. While the diversity among platforms has been great for experimentation, it also fragments information, making the outputs of forecasting far less useful. For instance, different platforms ask similar questions using different wordings. The questions may or may not be organized, and the outputs may be distributions, odds, or probabilities.
Fortunately, most of these platforms either have APIs or can be scraped. We’ve experimented with pulling their data to put together a listing of most of the active forecasting questions and most of their current estimates in a coherent and more easily accessible platform.
Metaforecast
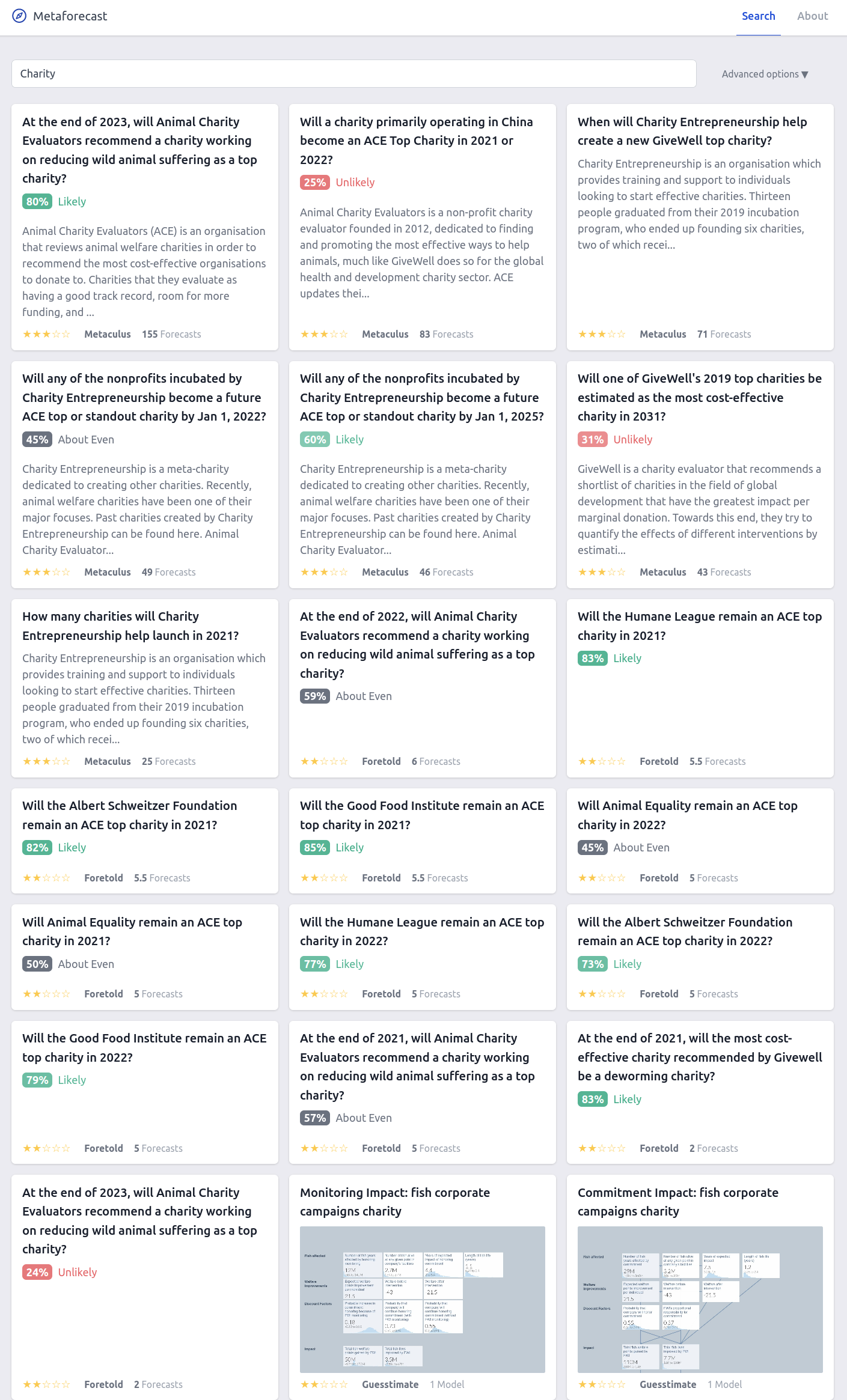
Metaforecast is a free & simple app that shows predictions and summaries from 10+ forecasting platforms. It shows simple summaries of the key information; just the immediate forecasts, no history. Data is fetched daily. There’s a simple string search, and you can open the advanced options for some configurability. Currently between all of the indexed platforms we track ~2100 active forecasting questions, ~1200 (~55%) of which are on Metaculus. There are also 17,000 public models from Guesstimate.
One obvious issue that arose was the challenge of comparing questions among platforms. Some questions have results that seem more reputable than others. Obviously a Metaculus question with 2000 predictions seems more robust than one with 3 predictions, but less obvious is how a Metaculus question with 3 predictions compares to one from Good Judgement Superforecasters where the number of forecasters is not clear, or to estimates from a Smarkets question with £1,000 traded. We believe that this is an area that deserves substantial research and design experimentation. In the meantime we use a star rating system. We created a function that estimates reputability as “stars” on a 1-5 system using the forecasting platform, forecast count, and liquidity for prediction markets. The estimation came from volunteers acquainted with the various forecasting platforms. We’re very curious for feedback here, both on what the function should be, and how to best explain and show the results.
Metaforecast is being treated as an experimental endeavor of QURI. We spent a few weeks on it so far, after developing technologies and skill sets that made it fairly straightforward. We're currently expecting to support it for at least a year and provide minor updates. We’re curious to see what interest is like and respond accordingly.
Metaforecast is being led by Nuño Sempere, with support from Ozzie Gooen, who also wrote much of this post.
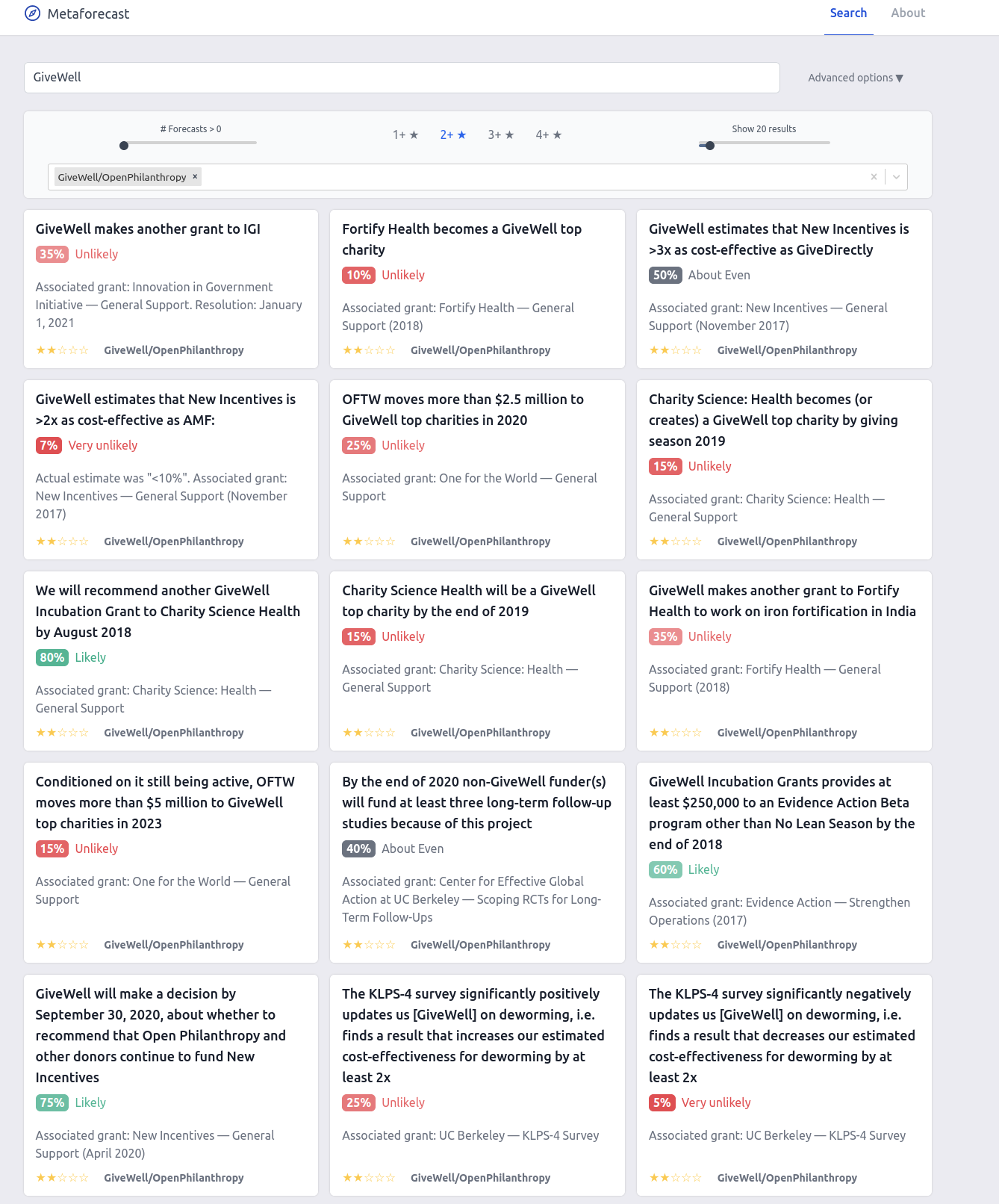
Select Search Screenshots
Charity
GiveWell
Data Sources
| Platform | Url | Information used in Metaforecast | Robustness |
| Metaculus | https://www.metaculus.com | Active questions only. The current aggregate is shown for binary questions, but not for continuous questions. | 2 stars if it has fewer than 100 forecasts, 3 stars when between 101 and 300, 4 stars if over 300 |
| Foretell (CSET) | https://www.cset-foretell.com/ | All active questions | 1 star if a question has fewer than 100 forecasts, 2 stars if it has more |
| Hypermind | https://www.hypermind.com | Questions on various dashboards | 3 stars |
| Good Judgement | https://goodjudgment.io/ | We use various superforecaster dashboards. You can see them here and here | 4 stars |
| Good Judgement Open | https://www.gjopen.com/ | All active questions | 2 stars if a question has fewer than 100 forecasts, 3 stars if it has more |
| Smarkets | https://smarkets.com/ | Only take the political markets, not sports or others. | 2 stars |
| PredictIt | https://www.predictit.org/ | All active questions | 2 stars |
| PolyMarket | https://polymarket.com/ | All active questions | 3 stars if they have more than $1000 of liquidity, 2 stars otherwise |
| Elicit | https://elicit.org/ | All active questions | 1 star |
| Foretold | https://www.foretold.io/ | Selected communities | 2 stars |
| Omen | https://www.fsu.gr/en/fss/omen | All active questions | 1 star |
| Guesstimate | https://www.getguesstimate.com/ | All public models. These aren’t exactly forecasts, but some of them are, and many are useful for forecasts. | 1 star |
| GiveWell | https://www.givewell.org/ | Publicly listed forecasts | 2 stars |
| Open Philanthropy Project | https://www.openphilanthropy.org/ | Publicly listed forecasts | 2 stars |
Since the initial version, the star rating has been improved by aggregating the judgment of multiple people, which mostly just increased Polymarket’s rating. However, the fact that we are aggregating different perspectives makes the star rating more difficult to summarize, and the numbers shown on the table are just those of my (Nuño’s) perspective.
Future work
- There are several more platforms to include. These include Augur, various non-crypto betting houses such as Betfair and William Hill, and Facebook’s Forecast. Perhaps we also want to include the sources of statistics, or hunt for probabilistic claims in books, Twitter, and other places.
- The ratings should reflect accuracy over time, and as data becomes available on prediction track records, aggregation and scoring can become less subjective.
- Metaforecast doesn’t support showing continuous numbers or forecasts over dates yet.
- Search and discovery could be improved, perhaps with the addition of formal categorization systems on top of the existing ones.
- It would be neat to have importance or interest scores to help order and discover questions.
- We could have an API for Metaforecast, providing a unified way to fetch forecasts among many different platforms. As of now, we have a json endpoint here.
- Metaforecast currently focuses on search, but it could make the data more available in nice table forms. This is a bit of a challenge now because it's all so disorganized.
- It could be nice to allow users to create accounts, star and track questions they care about, and perhaps vote (indicating interest) and comment on some of them.
- This is unlikely, but one could imagine a browser extension that tries to guess what forecasts are relevant to any news article one might be reading and show that to users.
- There could be a big difference between forecasting dashboards optimized for different groups of people. For instance, sophisticated users may want power and details, while most people would be better suited to curated and simplified workflows.
Challenges
Doing this project exposed just how many platforms and questions there are. At this point there are thousands of questions and it's almost impossible to keep track of all of them. Almost all of the question names are rather ad-hoc. Metaforecast helps, but is limited.
Most public forecasting platforms seem optimized for questions and user interfaces for forecasters and narrow interest groups, not public onlookers. There are a few public dashboards, but these are rather few compared to all of the existing forecasting questions, and these often aren’t particularly well done. It seems like there's a lot of design and figuring out to both reveal and organize information for intelligent consumers, and also doing so for more public groups.
Overall, this is early work for what seems like a fairly obvious and important area. We encourage others to either contribute to Metaforecast, or make other websites using this as inspiration.
Source code
The source code for the webpage is here, and the source code for the library used to fetch the probabilities is here. Pull requests or new issues with complaints or feature suggestions are welcome.
Thanks to David Manheim, Jaime Sevilla, @meerpirat, Pablo Melchor, and Tamay Besiroglu for various comments, to Luke Muehlhauser for feature suggestions, and to Metaculus for graciously allowing us to use their forecasts.
To check I understand, are the following statements roughly accurate:
"Ideally, you'd want the star ratings to be based on the calibration and resolution that now-resolved questions from that platform (or of that type, or similar) have tended to have in the past. But there's not yet enough data to allow that. So you asked people who know about each platform to give their best guess as to how each platform has historically compared in calibration and resolution."
Or maybe people gave their best guess as to how the platforms will compare on those fronts, based on who uses each platform, what incentives it has, etc.?
Yes. Note that I actually didn't ask them about their guess, I asked them to guess a function from various parameters to stars (e.g. "3 stars, but 2 stars when the probability is higher than 90% or less than 10%".
Also yes, past performance is highly indicative of future performance.
Also, unlike some other uses for platform comparison, if one platform systematically had much easier questions which they got almost always right, I'd want to give them a higher score (but perhaps show them afterwards in the search, because they might be somewhat trivial).
This whole thing is a somewhat tricky issue and one I'm surprised hasn't been discussed much before, to my knowledge.
One issue here is that measurement is very tricky, because the questions are all over the place. Different platforms have very different questions of different difficulties. We don't yet really have metrics that compare forecasts among different sets of questions. I imagine historical data will be very useful, but extra assumptions would be needed.
We're trying to get at some question-general stat of basically, "expected score (which includes calibration + accuracy) adjusted for question difficulty."
One question this would be answering is, "If Question A is on two platforms, you should trust the one with more stars"
Ah, that makes sense, thanks.
I guess now, given that, I'm a bit confused by the statement "as data becomes available on prediction track records, aggregation and scoring can become less subjective." Do you think data will naturally become available on the issue of differences in question difficulty across platforms? Or is it that you think that (a) there'll at least be more data on calibration + accuracy, and (b) people will think more (though without much new data) about how to deal with the question difficult issue, and together (a) and (b) will reduce this issue?
Great idea and excellent work, thanks for doing this!
This gets me wondering what other kinds of data sources could be integrated (on some other platform, perhaps). And, I guess you could fairly easily do statistics to see big picture differences between the data on the different sites.
Just circled back to this post to upgrade my weak upvote to a strong upvote, since I've started using the site, it seems quite helpful, and I think it's great that you noticed there was this gap and then just actually built something to fill it!
Hey thanks. Feel free to spread it around :)
At first glance, it seems to me like that might not be too hard to create an ok version of, which would be used by at least let's say 100 people. Do you mean that this being used by (say) millions of people is unlikely?
Also, I think somewhat related ideas were proposed and discussed in the post Incentivizing forecasting via social media. (Though I've only read the summary.)
For what it's worth, I had the same initial impression as you (that making a browser extension wouldn't be that hard), but came to think more like Ozzie on reflection.
It's possible we have different definitions of ok.
I have worked with browser extensions before and found them to be a bit of a pain. You often have to do custom work for Safari, Firefox, and Google Chrome. Browsers change the standards, so you have to maintain them and update them in annoying ways at different times.
Perhaps more important, the process of trying to figure out what text is important text of different webpages, and then finding some semantic similarities to match questions, seems tricky to do well enough to be worthwhile. I can imagine a lot of very hacky approaches that would just be annoying most of the time.
I was thinking of something that would be used by, say, 30 to 300 people who are doing important work.
I've never really thought about making browser extensions or trying to automate the process of working out what forecasts will be relevant to a given page, so I wouldn't be especially surprised if it was indeed quite hard.
But maybe the following approach could be relatively easy:
(This is just spitballing from someone who knows very little about how any of this works, so I wouldn't be surprised if implementing ideas like those would be very hard or not very useful anyway.)
Thanks for this project and this post! It does seem to me that something along these lines could clearly be valuable and (in retrospect) obviously should've been done already. I feel the same way about Guesstimate as well, so it seems QURI staff have a good track record here. (Though I guess I should add the disclaimer that I haven't actively checked what alternatives were/are available to fill similar roles to the roles Metaforecast and Guesstimate aim to fill.)
I look forward to seeing what Metaforecast evolves into, and/or what related things it inspires.
The closest alternative I've found to Metaforecast would be The Odds API, which aggregates various APIs from betting houses, and is centered on sports.
More distantly and speculatively, I guess that Wikidata or fanfiction.net/archiveofourown (which are bigger and better, but just thinking of it conceptually) also delimit metaforecast, the one on the known-to-be-true part of the spectrum, the other on the known-to-be-fictional side.
Thanks! If you have requests for Metaforecast, do let us know!
To check I understand, is the main thing you have in mind as a problem here that a similar topic might be asked about in a very different way by two different questions, such that it's hard for an aggregator/search tool to pick up both questions together? Or just that it can be hard to actually tell what a question is about from the name itself, without reading the details in the description? Or something else?
And could you say a bit about what sort of norms or guidelines you'd prefer to see followed by the writers of forecasting questions?
I'm not sure I know what you mean by "public dashboards" in this context. Do you mean other aggregators and search tools, similar but inferior to Metaforecast?
On the first part:
The main problem that I'm worried about it's not that the terminology is different (most of these questions use fairly basic terminology so far), but rather that there is no order to all the questions. This means that readers have very little clue what kinds of things are forecasted.
Wikidata does a good job of having a semantic structure where if you want any type of fact, you could know where to look. Compare this page of Barack Obama, to a long list of facts, some about Obama, some about Obama and one or two other people, all somewhat randomly written and ordered. See the semantic web or discussion on web ontologies for more on this subject.
I expect that questions will eventually follow a much more semantic structure, and correspondingly, there will be far more questions at some points in the future.
On the second part:
By public dashboards, I mean a rather static webpage that shows one set of questions, but includes the most recent data about them. There's been a few of these done so far. These are typically optimized for readers, not forecasters.
See:
https://goodjudgment.io/superforecasts/#1464
https://pandemic.metaculus.com/dashboard#/global-epidemiology
These are very different from Metaforecast because they have different features. Metaforecast has thousands of different questions, and allows one to search by them, but it doesn't show historic data and it doesn't have curated lists. The dashboards, in comparison, have these features, but are typically limited to a very specific set of questions.