Supported by Rethink Priorities
This is part of a weekly series summarizing the top (40+ karma) posts on the EA and LW forums - you can see the full collection here. The first post includes some details on purpose and methodology.
If you'd like to receive these summaries via email, you can subscribe here.
Podcast version: prefer your summaries in podcast form? A big thanks to Coleman Snell for producing these! Subscribe on your favorite podcast app by searching for 'Effective Altruism Forum Podcast'.
Top / Curated Readings
Designed for those without the time to read all the summaries. Everything here is also within the relevant sections later on so feel free to skip if you’re planning to read it all.
The Challenges with Measuring the Impact of Lobbying
by Animal Ask, Ren Springlea
Summary of a report by Animal Ask assessing if academic literature contains quantitative estimates that could be useful in gauging the counterfactual impact of lobbying. This requires breaking policy success into a baseline rate and counterfactual increase from lobbying.
They found the answer is no - lobbying literature contains many well-known weaknesses, a systematic review found a strange result (narrow range around 50% success, possibly because there are often lobbyists on both sides of an issue), and only one study attempted to identify counterfactual impact (and only for one policy).
The authors instead suggest using expert judgment and superforecasters.
What matters to shrimps? Factors affecting shrimp welfare in aquaculture
by Lucas Lewit-Mendes, Aaron Boddy
Report by Shrimp Welfare Project on the importance of various factors for the welfare of farmed shrimps. Welfare can be measured via biological markers (eg. chemicals associated with immune or stress responses), behavior (eg. avoidance, aggression), physical condition and survival rates.
The strongest evidence for harm to shrimp welfare was with eyestalk ablation, disease, stunning / slaughter, and insufficient dissolved oxygen or high un-ionized ammonia in the water. The authors have very high confidence that small to medium improvements in these would reduce harm to shrimp.
An Introduction to the Moral Weight Project
by Bob Fischer
In 2020, Rethink Priorities published the Moral Weight Series—a collection of five reports addressing questions around interspecies cause prioritization. This research was expanded in May 2021 - Oct 2022, and this is the first in a sequence of posts that will overview that research.
Author’s summary (lightly edited): “Our objective is to provide moral weights for 11 farmed species, under assumptions of utilitarianism, hedonism, valence symmetry, and unitarianism. The moral weight is the capacity for welfare - calculated as the welfare range (the difference between the best and worst welfare states the individual can realize at a time) × lifespan. Given welfare ranges, we can convert welfare improvements into DALY-equivalents averted, making cross-species cost-effectiveness analyses possible.”
EA Forum
Philosophy and Methodologies
An Introduction to the Moral Weight Project
by Bob Fischer
In 2020, Rethink Priorities published the Moral Weight Series—a collection of five reports addressing questions around interspecies cause prioritization. This research was expanded in May 2021 - Oct 2022, and this is the first in a sequence of posts that will overview that research.
Author’s summary (lightly edited): “Our objective is to provide moral weights for 11 farmed species, under assumptions of utilitarianism, hedonism, valence symmetry, and unitarianism. The moral weight is the capacity for welfare - calculated as the welfare range (the difference between the best and worst welfare states the individual can realize at a time) × lifespan. Given welfare ranges, we can convert welfare improvements into DALY-equivalents averted, making cross-species cost-effectiveness analyses possible.”
A dozen doubts about GiveWell’s numbers
by JoelMcGuire, MichaelPlant, Samuel Dupret
Twelve critiques of GiveWell’s cost-effectiveness analyses (CEAs). Ten apply to specific inputs for malaria prevention, cash transfers, or deworming, and two are relevant for more than one intervention. These include potentially relevant studies not included in the CEAs, lack of granularity in terms of country, age and gender differences in analysis, and questioning some of Givewell’s assumptions around income improvements from malaria prevention. They also include a spreadsheet with their modified CEAs.
Quantifying Uncertainty in GiveWell CEAs
by Hazelfire, Hannah Rokebrand, Tanae
The authors have quantified the uncertainty in GiveWell CEAs by translating them into Squiggle, which allows putting a number to uncertainty on each parameter. This in turn allows calculation of the value of further research, in comparison to donating directly to current expected top charities. They find that the value of perfect information (on each of Givewell’s existing charity recommendations) would be ~11.25% of Givewell’s budget.
They also discuss specific parameters that, if we were able to pinpoint them, would have the most impact on reducing uncertainty (eg. average number of midwives trained per year is key to reducing uncertainty on Catherine Hamlin Fistula Foundation cost effectiveness). Possible improvements to this analysis are discussed, and notebooks with code for each of the top charities are provided.
A Theologian's Response to Anthropogenic Existential Risk
by Fr Peter Wyg
A report by a Catholic priest on how the Catholic Church can engage with longtermism and play its part in advocating existential security. It was written for a Catholic publication, so introduces many of the basic ideas from that angle.
The author argues that technology (eg. nuclear tech) has equivalence to ‘eating the fruit of the tree of knowledge’, and is one example of an anthropogenic existential risk (AXR) threatening the death of mankind. By failing to mitigate AXRs, humanity could fail to live the fullness of life God would otherwise will for it - many biblical references suggest a promise of a large future. In this way Christian motivations make a great contribution to mitigating AXRs by providing reasons for costly action toward that goal.
Object Level Interventions / Reviews
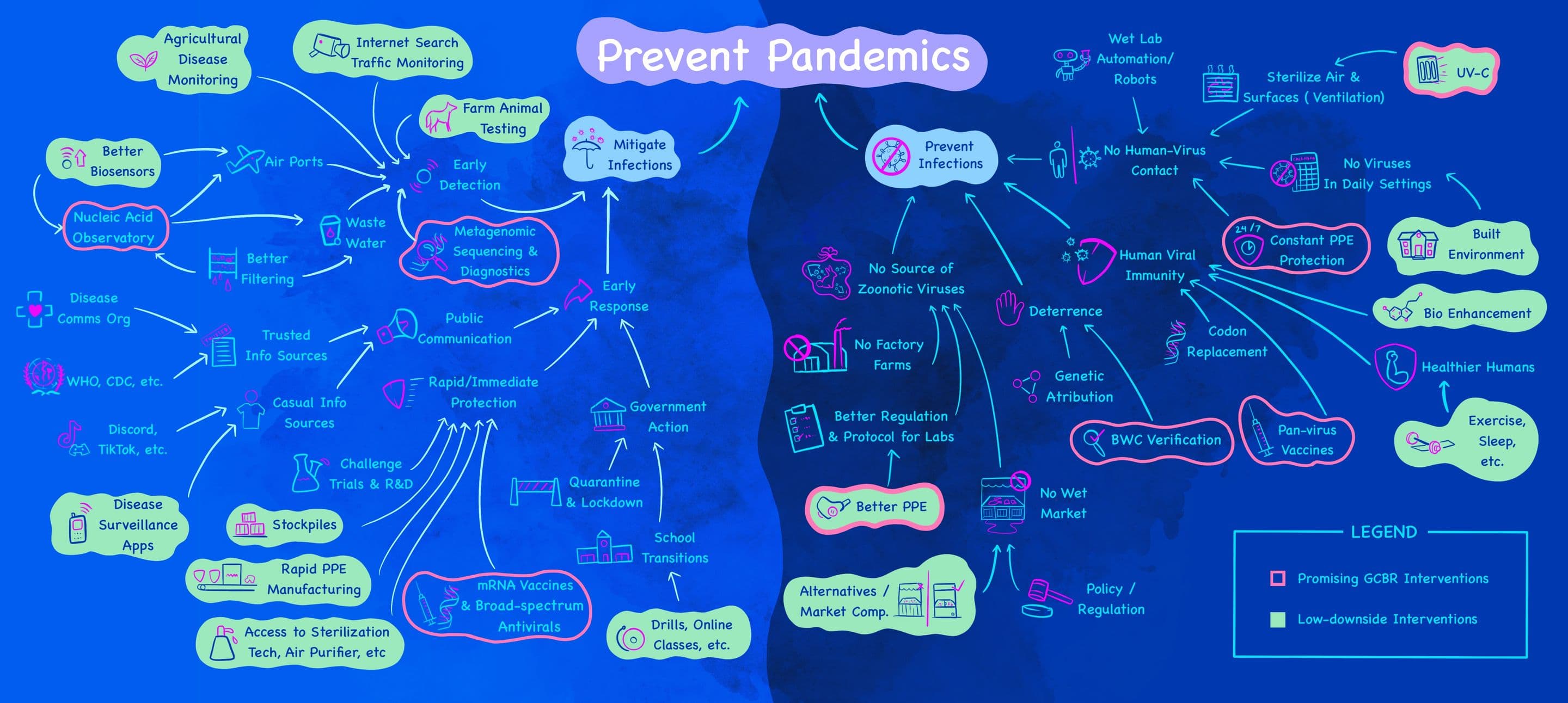
Map of Biosecurity Interventions
by James Lin
A visual map of what people in biosecurity are working on, with some accompanying notes. Covers both interventions on global catastrophic biological risks, and interventions targeted at covid-level pandemics (which can affect existential risk by destabilizing international cooperation, creating institutional distrust etc.)
How effective are prizes at spurring innovation?
by Rachel Norman, Tom Hird, jenny_kudymowa, bruce
Literature review by Rethink Priorities on the effectiveness of prizes in spurring innovation and what design features of prizes are most effective in doing so. Mainly focused on inducement prizes.
Inducement prizes (clear award criteria defined ahead of time) comprised ~78% of all prize money in 2007. They had little evidence on counterfactual effects in the literature, with most articles focused on historical case-studies. Two studies found positive effects on intermediate outcomes eg. number of patents, direction of research.
Recognition prizes (awarded ex post eg. the Nobel Prize) had surprisingly large positive effects on the number of publications, citations, entrants, and incumbents for prizewinning. However there is also evidence they might be concentrating scientific attention on a narrow range of scientists and ideas.
There was little evidence / consensus on how to design prizes. Cash amounts had only weak relationships to output, prestige provided a stronger incentive. Diverse participants helped. Economic theory suggests inducement prizes are most helpful when the goal is clear but path is not, and the market is failing to provide incentives.
A closer review of recognition prizes, AMCs (advance market commitments), and grand challenges (funding grant proposals, with additional support if successful) are suggested.
The Challenges with Measuring the Impact of Lobbying
by Animal Ask, Ren Springlea
Summary of a report by Animal Ask assessing if academic literature contains quantitative estimates that could be useful in gauging the counterfactual impact of lobbying. This requires breaking policy success into a baseline rate and counterfactual increase from lobbying.
They found the answer is no - lobbying literature contains many well-known weaknesses, a systematic review found a strange result (narrow range around 50% success, possibly because there are often lobbyists on both sides of an issue), and only one study attempted to identify counterfactual impact (and only for one policy).
The authors instead suggest using expert judgment and superforecasters.
What matters to shrimps? Factors affecting shrimp welfare in aquaculture
by Lucas Lewit-Mendes, Aaron Boddy
Report by Shrimp Welfare Project on the importance of various factors for the welfare of farmed shrimps. Welfare can be measured via biological markers (eg. chemicals associated with immune or stress responses), behavior (eg. avoidance, aggression), physical condition and survival rates.
The strongest evidence for harm to shrimp welfare was with eyestalk ablation, disease, stunning / slaughter, and insufficient dissolved oxygen or high un-ionized ammonia in the water. The authors have very high confidence that small to medium improvements in these would reduce harm to shrimps.
How bad could a war get?
by Stephen Clare, rani_martin
This post attempts to find the likelihood of extinction-level wars, by a) examining whether the distribution of battle deaths follow a power law, and b) what would this look like in the extreme tails? Eg. if a war has already killed 90% of humans, is it plausible it could continue?
They find that power law is a plausible fit to the distribution of battle deaths across wars, but other distributions like lognormal fit just as well. We also have little information on the upper tail because we haven’t had extinction-level wars, and have few examples of world wars.
Theoretical reasons for extinction-level wars to be less likely than a power law suggests include:
- Increasing pressure from the public to end the war as it grows
- Increased logistical complexity hampering the very largest of potential wars
However, the authors argue that with new technologies (nuclear weapons, bio weapons, AI, other emerging technology) this removes these barriers and means there is no upper limit on how bad a war could get.
Mini summaries of GPI papers
by Jack Malde
Summaries of five Global Priorities Institute Papers, including “On the desire to make a difference”, “The unexpected value of the future” and “Longtermism, aggregation, and catastrophic risk”. Includes single-paragraph bottom lines and bulleted lists of key points.
Should we be doing politics at all? Some (very rough) thoughts
by Holly_Elmore
Engaging in political campaigns has risks to EA, including:
- Incentives to lie and misrepresent / corruption risks
- Political interventions aging poorly or locking EA / EA orgs into particular positions
- High leverage (big impact for few resources) campaigns are likely less democratic and risk blowback against EA or the cause area in question
- High leverage methods used previously (eg. ballot measures) are now under question because of the ease of use for special interest groups.
However, EAs might also overstate the threat to epistemics. Usually we bucket ‘theory of change / selecting interventions’ separately to ‘doing the intervention’ and allow more leeway in the latter (eg. some charities need to use bribes to operate in certain countries). Political campaigning is more ‘doing’ than ‘prioritizing’. It’s also a straightforward public demonstration of commitment to our goals, and could have high expected value.
Insect farming might cause more suffering than other animal farming
by ishankhire
The edible insect market has been growing and is projected to continue increasing rapidly in the future. The author made a guesstimate model to approximate cricket suffering per kg of insects consumed, and found the insect sentience multiplier would have to be 10^-4 for the days of suffering / kg to be around the same as a broiler chicken. Based on this, they argue insect welfare deserves a higher priority.
Modelling civilisation after a catastrophe
by Arepo
The author presents three models for expected loss of value in a global catastrophe that doesn’t cause extinction. These are:
‘The Cyclical Model’: once we have technology that can destroy us, we can either go extinct, chain back to an earlier level of technology (eg. preindustrial) or eventually progress to being multiplanetary and then interstellar (in >1 star system and therefore have existential security). At any earlier stage than interstellar we still have a risk of extinction.
‘The Decay Model’: similar to above, but every time we chain back to an earlier level of technology due to a global catastrophe, our chance of extinction before getting back up to the previous level rises. The model allows for different ‘decay rates’ ie. how much that chance rises.
‘The Perils Model’: similar to above, but within any given stage, the risk of extinction is related to factors other than just time in that stage. For instance, the number of planets we inhabit, or the state of relevant technologies.
After feedback, the author intends to make these models into a calculator, where parameters can be plugged in to see the probability of humanity making it to the safe (interstellar) stage.
Opportunities
Rethink Priorities’ Special Projects Team is hiring
by Rachel Norman, CristinaSchmidtIbáñez, merilalama
Rethink Priorities Special Projects team provides fiscal sponsorship and operational support to (for the most part, longtermist) megaprojects. They’re hiring for managers and associates and welcome applicants anywhere in the world. Apply by November 13th, or join the AMA in the comment section to learn more.
Every.org Donation Matching for Monthly Donations by Cullen_OKeefe & Make a $50 donation into $100 (6x) by WilliamKiely
From Nov. 1 - Nov. 30, or until funds run out, any donor who sets up a monthly donation to a nonprofit will be matched up to $50.00 of their monthly donation for the first two months - this can be done for up to 3 non-profits. The process takes ~5m. More detail on their website here.
Major update to EA Giving Tuesday
by Giving What We Can, GraceAdams
Meta announced a significant change to their annual Giving Tuesday donation matching scheme. Now only recurring donations will be matched, and only up to $100 per user x charity combination. Because of this, both competition and payoff is likely to be lower, and the previous level of coordination between EAs seems unnecessary.
The giving starts Nov 15th, and the EA Giving Tuesday team suggests those interested look through participating effective charities and donate directly via facebook. Further instructions here.
CE: Who underrates their likelihood of success. Why applying is worthwhile.
by SteveThompson, Kylie Abel
Applications for Charity Entrepreneurship's early 2023 incubation program have been extended to November 10th. If they don’t find more potential founders they may not be able to launch charities in Tobacco Taxation and Fish Welfare.
While they received ~3K applicants, ~80% are from outside the EA community and lack understanding of what they do. Those without all the relevant skills (eg. business, research, interpersonal), professional experience, or who are new to EA often underestimate their chances. The best way to test fit and build skills is through the program. Founders also take a wide range of salaries, so that doesn’t need to be a barrier.
AI Safety Needs Great Product Builders
by goodgravy
Product builders (web devs, product managers, designers, founders, devops, software engineers etc.) can contribute to AI Safety in tangible ways, without ML / AI expertise. Ought gives some examples from their use cases:
- ICE, an interactive visualiser to understand factored cognition, needs both back-end devs (to instrument the cognition ‘recipes’) and front-end or UI / UX devs (to better visually represent it).
- Elicit, the AI research assistant, needs product managers to make day-to-day decisions balancing proving the usefulness of the app and proving a safer approach than other companies.
- Infrastructure engineers are needed to insert abstraction between code and ML models, to help with iterated distillation and amplification.
Ought currently has several open roles across these areas.
Announcing The Most Important Century Writing Prize
by michel, Drew Spartz
Superlinear is offering $500 each to write-ups that meaningfully critique, comment on, or build on the Most Important Century series. They expect to award most good-faith submissions and there is currently no submission deadline.
Announcing EA Survey 2022
by David_Moss, WillemSleegers
The EA Survey is an annual survey of the effective altruism community, and is now live at this link until Dec 1st. The results inform the decisions of a number of different orgs and help to understand how the community is changing over time. This year’s survey is substantially shorter than 2021, and should take <10 minutes. If you’re reading this, you fit the target audience and your response is valuable. Sharing widely with other EAs is also appreciated.
Supporting online connections: what I learned after trying to find impactful opportunities
by Clifford, Sarah Cheng
The authors - both from CEA - spent 4+ months exploring how the forum could help people make valuable connections. No ideas met their bar (facilitating ~1 EAGs worth of connections per year).
12 ideas were investigated, including services to get advice from experts, connect with those nearby or with similar interests, advertise / recruit for / find / assess impact of jobs, or target pain points for community builders or regrantors. The most promising was ‘advertising jobs’.
Off the back of this work they are now more excited about high value outcomes (jobs, collaborations) than number of connections.
Draft Amnesty Day: an event we might run on the Forum
by Lizka
Author’s tl;dr: “We’re considering making an official “Draft Amnesty Day” on the Forum when users will be encouraged to share unfinished posts, unpolished writing, butterfly ideas, thoughts they’re not sure they endorse, etc. We’re looking for feedback on this idea.”
Request for input: how has 80,000 Hours influenced the direction of the EA community over the past 2 years?
by Ardenlk
A request for input on how 80K has influenced the direction of the EA community, positively or negatively. Eg. changing what ideas became prominent, or what community members are interested in. Submit thoughts on this form.
Dark mode (Forum update November 2022)
by Lizka
The EA forum now has dark mode - turn it on via ‘Account Settings’ -> ‘Site Customization’ -> ‘Theme’.
A Critique of Longtermism by Popular YouTube Science Channel, Sabine Hossenfelder: "Elon Musk & The Longtermists: What Is Their Plan?"
by Ram Aditya
A popular science channel host, Sabine Hossenfelder posted a video critique of longtermism. The author agrees with some points (eg. key philosophers are mainly located at Oxford or related institutes, and population ethics being a key part of the argument) but disagrees with many others - which primarily paint longtermists as not caring about current issues / deaths, being over-optimistic about technology, and allowing tech / finance / philosophy elites to disregard human welfare.
They suggest discussion in the comment section on how best to respond to these types of critiques.
Longtermist terminology has biasing assumptions
by Arepo
Longtermist terminology can have issues such as:
- Biasing toward certain population ethics
- ‘Existential catastrophe’ including failed continuation risks alongside extinction, implies a reduction in total population over long timeframes is very bad.
- ‘Suffering catastrophes’ is dependent on population ethics - some people claim any suffering on scale is a catastrophe, even in an otherwise great world.
- Lacking precision / being vague
- ‘Global catastrophe’ is defined by the UN and Bostrom & Cirkovic as ‘‘a catastrophe that caused 10 million fatalities or 10 trillion dollars worth of economic loss”. Covid meets this definition but isn’t considered a global catastrophe by most longtermists.
- ‘Recovery’ can sometimes mean recovering current tech levels, sometimes retaining potential to be a space-faring civilization.
The author argues we should aim to make longtermist terminology more formally defined, intuitive, precise, and ensure there are categorical distinctions only for qualitatively different states (not different places on the same scale).
EA orgs should accept Summer 2023 interns by January
by Abby Hoskin
Author’s tl;dr: “EA organizations hiring graduating seniors or hosting undergraduates as 2023 summer interns should send program acceptances by January 2023 so that students don't have to accept a corporate offer before they apply to EA programs.” eg. internships for Google, JP Morgan and Bain often have application deadlines in October / November.
How CEA approaches applications to our programs
by Amy Labenz
CEA runs a range of programs designed to have a positive impact on the world, rather than to serve the EA community as an end goal. Some, such as EAGs, aren’t a good fit for even all those really dedicated to doing good. This has caused some confusion and disappointment recently.
In future, CEA intends to post publicly when there are significant updates to their programs and / or misunderstandings about them. However they will be less involved in comments, responding to feedback, and public back-and-forth due to resource costs. They encourage giving feedback eg. via this form and recommend public criticisms be sent to them for fact-checking before publishing.
The "Inside-Out" Model for pitching EA
by Nick Corvino
When pitching EA to those unfamiliar, start out by applying it within the cause they care about (eg. comparing effectiveness of different climate change interventions). Later you can transition to comparing across cause areas. This creates a more welcoming feeling.
ML Safety Scholars Summer 2022 Retrospective
by ThomasW
The 2022 Machine Learning Safety Scholars program (MLSS) was an intense 9-week summer program. The full curriculum is available here. 63 students graduated, and all filled out an anonymous survey. Key results:
- It went well - all found it useful / very useful and >70% have either already recommended it to a friend or are 90%+ likely to.
- Most graduates are actively exploring AI safety careers, and ~55% are more confident in fit after the program. ~17% learnt they weren’t good fits for AI safety research.
- The stipend was important: ~half of graduates couldn’t have attended otherwise.
- The highest-rated aspects were paper readings and assignments (both written and programming). Unfacilitated breakout room discussions rated the worst.
- There was approximately ~40% attrition (41/104), mainly due to personal reasons or not expecting it was truly a 30-40 hour per week time commitment.
The post goes into a lot more detail on potential improvements, and detailed analysis on what went well and not for each aspect of the program.
Intro Fellowship as Retreat: Reasons, Retrospective, and Resources
by Rachel Weinberg
Introductory EA fellowships (8-week long discussion groups) are a common way to introduce students to EA. However only ~10% continue engaging with EA after the program, based on comments from other university organizers. The author ran a 4-day retreat to see if that would have better results.
Retreat advantages included speed, energy, being more interesting and facilitating social bonds. However they have a higher time (to organizers) and monetary cost, cover less material, can be harder to get sign-ups, and can be seen as wasteful. If doing a retreat, reaching out 1-1 encourages sign-ups more than broad outreach. The post-retreat feedback form showed similar results as that of intro fellowships.
Mildly Against Donor Lotteries
by Jeff Kaufman
Donor lotteries are where everyone puts in $X dollars, a random person is chosen to donate the lot, and they therefore do in-depth research on where to donate because it’s worth it for the larger amount.
However, it has some downsides. If describing these decisions to others (eg. a friend interested in where to donate), you are less able to give object-level advice and it could look to them like you gambled away your donation. It’s also unlikely the chosen donor is able to beat existing research like Givewell or EA Funds via individual effort, even with the extra motivation of a larger money pot.
Didn’t Summarize
All AGI Safety questions welcome (especially basic ones) [~monthly thread] by robertskmiles
LW Forum
Clarifying AI X-risk
by zac_kenton, Rohin Shah, David Lindner, Vikrant Varma, Vika, Mary Phuong, Ramana Kumar, Elliot Catt
A threat model literature review that proposes a categorization and describes a consensus threat model from some of DeepMind's AGI safety team.
Most existing threat models have a technical cause of either or both of:
a) Specification gaming (bad feedback on training data)
b) Goal misgeneralization (the AI’s competencies generalize, but it’s goal doesn’t ie. in scenarios unlike it’s training data, it pursues the wrong goal)
Which then leads to x-risk via either complex interactions between different AI systems, or misaligned power-seeking behavior. The most common model found, and the one shared by the authors, was for both technical causes to occur and lead to x-risk via misaligned power-seeking. The authors also had agreement between them that one of the most likely paths would be reinforcement learning human feedback (RLHF) models seek power because of goal misgeneralization, and we don’t catch it because they are deceptively aligned, interpretability is hard, and important people don’t understand the issue.
Caution when interpreting Deepmind's In-context RL paper
by Sam Marks
Author’s summary (lightly edited): “A recent Deepmind paper claims to have gotten a transformer to learn an RL algorithm by training it on an RL agent's training trajectories. This was shocking, and many people they know had strong reactions - it seemed like evidence of a mesa-optimizer. However, after digging into the paper, they don’t think in-context RL is the correct interpretation of what the authors did.” This is mainly because the training tasks in the paper were all very similar to both each other and the deployment task, so could be achieved without in-context RL.
"Normal" is the equilibrium state of past optimization processes
by Alex_Altair
Future possibilities involved with AI x-risk can feel extreme and far-mode, regardless if we agree they are plausible. The author finds it useful to remember there is no ‘normal’, and our current state is also the result of implausible and powerful optimization processes.
Eg. Humans (evolution), life starting at all (random chance -> evolution), planets (dust accumulating into concentrated areas), Earth getting oxygen (thought to be a sudden global optimization process to do with single-celled photosynthesis). All of these were major paradigm shifts, and driven by an optimization process seeking equilibrium.
Superintelligent AI is necessary for an amazing future, but far from sufficient
by So8res
The author thinks friendly AGI would be amazing, even if it didn’t have values they recognized. However, “if humanity creates superintelligences without understanding much about how our creations reason, then our creations will kill literally everyone and do something boring with the universe instead.”
They believe that in terms of outcomes on the whole universe - humanity building AGI will do worse than a random alien species (based on gut feel), random aliens would do worse than unassisted humans not building AGI, and a friendly AGI would do best of all.
In the post, they lay out their guesses at the odds of different levels of goodness / badness for the universe, depending on various pathways we and alien species - if they exist - might take (eg. misaligned AGI, humans develop friendly AGI, aliens develop friendly AGI, no AGI just humans).
"Cars and Elephants": a handwavy argument/analogy against mechanistic interpretability
by David Scott Krueger (formerly: capybaralet)
Author’s tl;dr: “If we can build competitive AI systems that are interpretable, then I argue via analogy that trying to extract them from messy deep learning systems seems less promising than directly engineering them.”
publishing alignment research and infohazards
by carado
The author finds sharing thoughts on AI in written form helpful to clarify thinking, solicit feedback, and allow building on each other’s ideas. However they’ve noted in retrospect some were infohazards. They suggest having a feature where you can share a forum post only with selected ‘trusted’ users.
Real-Time Research Recording: Can a Transformer Re-Derive Positional Info?
by Neel Nanda
The author records themselves doing mechanistic interpretability research. This is an experiment, so they chose a small, self-contained question that would make for a good example of the process. You can watch the recording here and follow along with the code here.
Am I secretly excited for AI getting weird?
by porby
Posts on new AI developments sometimes have an excited tone, even when written by those with short AGI timelines and high probabilities on AGI x-risk. Eg. a quote from one article: ‘This is crazy! I'm raising my eyebrows right now to emphasize it! Consider also doing so!’ This tone can make people question if the authors truly believe their x-risk arguments, or are instead excited for AGI.
The author argues that the excitement is similar to the weird, darkly attractive novelty of seeing a natural disaster or covid coming but not landed in your city yet. They absolutely want to be wrong about it, want it not to happen. But the edge of your seat feeling can create that excited tone.
K-types vs T-types — what priors do you have?
by strawberry calm
The author suggests a classification of people into K-type and T-types. K-types prefer theories that are short (in words), regardless of the number of inferential steps. T-types prefer theories that have few inferential steps, regardless of length in words.
Eg. Bayesian statistics is simple to describe (one rule) but slower to derive (more calculations to get results). So K-types would prefer Bayes, T-types frequentist.
The author claims this classification predicts a number of different beliefs and behaviors, from moral circle size to views on the mind-body problem, and that using this knowledge we can choose more convincing arguments for a given person.
World Modeling and Other
The Social Recession: By the Numbers
by antonomon
One of the most discussed topics online recently has been friendships and loneliness. The author presents various studies that investigate aspects of this:
Community and social activities: ~31% of Americans claim to be online ‘almost constantly’ ie. in person activities have substantially declined.
Friendships: The number of Americans who claim to have no close friends has quadrupled to 12% in the last 30 years. The average number of friends has also declined rapidly.
Life milestones & relationships: the percentage of 12th graders reaching milestones like driving, working, or regularly going out without parents is dropping fast. This ‘delayed adulthood’ is linked to less risky behavior as well as less sociability, fewer sexual relationships and higher depression rates.
Trust: Trust in US institutions continues to drop, at 27% in 2022 vs. ~50% in 1979. There is also declining trust in legislative branches and the American people.
The author suggests remedies to this social recession involve rethinking internet infrastructure with pro-social ends in mind.
Far-UVC Light Update: No, LEDs are not around the corner (tweetstorm)
by Davidmanheim
222nm light to kill pathogens would be great for biorisk, however the author argues it’s probably a decade+ from widespread usage. This is because of two issues:
1. Safety trials and regulatory approval are slow
2. Current lamps are inefficient - they get hot quickly, and emit a spectrum where some needs to be filtered to be safe.
#2 could be solved via finding better materials that can make efficient LED versions, but this would likely change the spectrum of light emitted, requiring further safety testing.
My resentful story of becoming a medical miracle
by Elizabeth
Summary copied from last week’s as context for the next post
The author tried many things to deal with a medical problem on the advice of doctors, was eventually suggested a treatment for a different issue, tried it, and it solved the original problem (in this case - a particular antihistamine taken for rash dealt with difficulty digesting protein). They also ran studies on self help books and found no correlation between helpfulness and rigor / theoretical backing, and ran an RCT on ketone esters and found no benefits despite them and friends getting insane gains from them.
They conclude that “once you have exhausted the reliable part of medicine without solving your problem, looking for a mechanistic understanding or empirical validation of potential solutions is a waste of time. The best use of energy is to try shit until you get lucky.”
Follow up to medical miracle
by Elizabeth
Some conditions that make luck-based medicine more viable include:
- The ability to reliably identify things with noticeable risk.
- A well-functioning liver (a lot more substances are harmful otherwise).
- Ability to weather the bumps (ie. if you feel off for a while, it’s okay - you have the work and personal flexibility).
- A system for recognizing when things are helping and hurting. Pinning your doctor down on what to expect when, and when to give up if you don’t see it, helps here.
They also give more detail on Ketone Esters and the minimal potato diet, which were mentioned in the previous post as interventions that were helpful to them.
Why Aren't There More Schelling Holidays?
by johnswentworth
One person being out on vacation can have a disproportionate effect on a team, particularly if they have unique knowledge / access / skills and this blocks others. The author suggests companies encourage staff to take leave at the same time eg. via team / company holiday weeks.
Didn’t Summarize
«Boundaries», Part 3a: Definitions by Andrew_Critch
A Mystery About High Dimensional Concept Encoding by Fabien Roger
Boundaries vs Frames by Scott Garrabrant
AI
OpenAI launched a DALLE API so devs can integrate it into their own apps and products. (tweet)
National Security
Russia rejoined the grain deal, after leaving it last week. Ukraine accuses Russia of energy terrorism after attacks on infrastructure leaves 4 million without power. (article summarizing this week’s developments)


Just commenting to make explicit that I read and share these and find them to be very useful for staying on top of insights and content. Just to quantify how much I value it, I think that I would probably pay a small amount to subscribe to it if that was required (say 50usd annually). I say all this because I think that often many people benefit from 'synthesis' work like this but relatively few communicate the benefit. I think that being explicit about benefits can help to motivate and empower the content producer and help them get funding to continue their work.