Tldr;
- (Longtermist) EAs seem more focused on non-extinction risks from AI than they used to be
- I haven’t seen much discussion of why, making reference to the very longrun
- Changes in the world this might be responding to are: alignment seeming more promising than it used to, the speed of AI progress, and concerns around US governance.
- There are also plausible sociological reasons for the shift, so I feel unsure how far to update
What’s the change and why care about it?
My sense is that there’s been a significant shift in how much longtermists prioritise non-extinction risks over the last few years. A decade ago people who were trying to ensure the flourishing of the universe trillions of years from now were very often focused on avoiding events that would kill all humans. My sense is that now they’re much more often focused on situations which they don’t think pose a risk of human extinction, such as extreme power concentration.
This change has felt confusing to me for a couple of reasons:
- There’s reasonably little written about why longtermists should change their prioritisation in this direction. The notable exception is this paper by Will MacAskill.
- To my mind, there’s a clear reason for longtermists to focus on extinction risks:
- It seems extremely hard for any of our actions now to predictably affect what the world looks like in trillions of years time. (Events which predictably affect the very longrun future are often called ‘lock-in’ events.)
- Preventing humans from going extinct in the next decade continues to affect the future indefinitely - human extinction seems like a clear ‘lock-in’ event.
You might think that our actual actions won’t be affected much by whether the risks we should prioritise most are totalitarianism or human extinction. There are indeed many actions which are useful for both of these. Pausing AI development will give us more time to allow the world to prepare itself for all sorts of risks that transformative AI might bring. Frontier AI companies having good whistleblower provisions gives us a better hope of finding out about many of the largest of those risks before they come about.
But there are ways in which you could disproportionately affect extinction risks compared to other risks. One is working directly to mitigate the ways humans could all plausibly be killed, such as AI enabled biorisks. Another is to focus more on the risk of misaligned AI risk than the risk of AI misuse by humans. The reason is that AI may be inherently alien to humans and therefore likely to have goals which are far reaching and extremely different to ours, and therefore cause a future which doesn’t include us. "The AI does not hate you, nor does it love you, but you are made out of atoms which it can use for something else". By comparison, humans tend to have goals for which it’s useful to have other humans surviving.
I wanted to get a sense of why there’s been a shift in favour of longtermists prioritising extreme power concentration amongst humans compared to AI takeover, in order to understand better what’s highest priority for me to focus on. Below are the reasons I came across when talking to people about what has caused this trend.
Differences in the world that motivate the change
Alignment is more promising than some people expected.
For many longtermists, by far the most likely cause of human extinction is a misaligned AI. The reason is that humanity is actually reasonably resilient to large shocks, even ones that kill the vast majority of the population. That means natural disasters are reasonably unlikely to wipe everyone out. Whereas a misaligned AI for whom humans were in the way might take a more intentional approach to wiping us out.
Ten years ago, it seemed plausible that AI wouldn’t be able to understand human goals at all, so the idea of AI pursuing totally alien goals seemed more likely. We now have empirical evidence of AI understanding humans reasonably well - being able to get a fairly brief and vague prompt and accurately determine what we’d like it to do and how. To the extent their goals diverge from ours, they’re often very intelligible do us (such as wanting to complete the task and therefore cheating on it). There are some structural reasons for that - using large language models extensively imports a lot of human concepts into models.
Even aside from alignment being less challenging than some expected, the fact that there are now more people working on it provides some reason for thinking that marginal work on it might be less useful than it was in the past.
AI progress has been continuous, and medium-fast
In a world where AI progressed from largely useless to superintelligent in the course of days, there’s little opportunity for humans to figure out how to control it or wield it to their ends. In a world where AI progress is very slow, we have time to adjust our governance mechanisms to the existence of ASI. But where progress is continuous and medium-fast, some humans have enough time to notice it would likely be useful to control super-intelligence and make plans to do so, without there being time for things like governments
US governance is in a worse state than we might have expected for the point at which we hit transformative AI.
The federal government seems unusually opposed to safety-focused AI legislation (making it more likely than it might have been that AI company execs could amass unusual levels of power), and less respectful of separation of powers. It’s possible that the people running AI companies also seem more power-seeking / less safety conscious than we would have expected (though that seems less compelling to me).
How much of an update should we make?
The above all seem like solid reasons to shift some prioritisation from avoiding AI takeover to avoiding extreme human power concentration.
I’m still not sure if I buy that these risks are in the same ballpark, even if they’re now closer. My hesitation stems from a strong intuition that it’s extremely hard to predictably affect anything over the long-term. Our actions have a very strong tendency to ‘wash-out’ - often over mere years, but particularly after centuries, millennia and onwards.
There are reasons to think that AGI will make it less likely that actions wash out - for example, it will plausibly enable immortality (perhaps by uploading rather than biologically). Dictatorships have often historically been brought down by the natural death of the dictator, so the impossibility of that could really increase the chance of lock in over the very long run. (For more on how AGI might enable authoritarian lock in, see the MacAskill and Finnveden et al papers linked about.) On the other hand, technological breakthroughs have historically swung the balances of power and otherwise washed out previous actions, and transformative AI will precipitate a time of unusually rapid technological progress.
There are also various things which might have causally led to a shift in views without epistemically justifying them:
- When OpenAI and DeepMind were set up, their comms about their aims were heavily focused on keeping the world safe. Things like the OpenAI board turning over has made salient how much some of the key players seem squarely focused on amassing power, and how scary that is. Being viscerally aware of that (even if the extent to which it’s the case is within the bounds of what you would have theoretically expected) makes it harder to look away from risks from human power concentration.
- The US has become more divided and tribal, making it feel more urgent and important to work on preserving democracy
- As AI progress is discussed more in the mainstream, there’s a larger coalition working on ensuring that the transition to superintelligent AI proceeds safely, many of whose values don’t extend to the extremely longrun future. Preventing extreme concentration of power is a unifying issue in the sense that lots of people find it more plausible than extinction, so this provides a (perhaps unconscious) incentive to emphasise it more.
The existence of causal reasons like those above make me wary of over updating in towards prioritising extreme power concentration. On the other hand, I think it’s plausible that I previously focused too hard on human extinction compared to other plausible lock-in events. A couple of the reasons I might have done that:
- I have a strong intuition about it being very hard to affect things over the longrun. And there is plenty of evidence about people trying to cause lasting change and totally failing. But I think it might be a mistake to trust my intuitions about this question at all. We should expect the world to be unrecognisable after a transition to ASI, so why would we expect it it to be similarly easy/hard to lock things in for the future?
- It does seem right to me that there is a chance of us being able to lock particular values or governance structures for the extremely long run, and also a chance that preventing human extinction does not lock in a change in value of the universe (for example, if humans went extinct decades later it would wash out the effect of saving them this decade). I think it’s easy to round the former off to ‘basically not lock in’ and the latter to ‘basically lock in’ in a way I don’t endorse.
All this mostly leaves me still feeling pretty unclear about how to prioritise between risks that might and might not plausibly cause human extinction. I’m inclined to prioritise those that won’t somewhat higher than I have historically. I still feel nervous that I’m partly doing that for bad reasons. Those reasons are less the explicit causal ones I listed, and more deferring to the ‘general zeitgeist’ without fully understanding its reasoning. I’d be very keen to hear other people’s views on this question.
Thanks to Arden Koehler for making this post (and so many of the things I write) much better, and to various people for the ideas behind the post, including Alex Lawsen and Nick Beckstead.


A couple of quick thoughts:
1/
- A big thing, in my view, is that AI safety isn't about preventing "extinction" in the relevant sense. In most worlds where AI disempowers humanity, the human species continues. And in essentially all worlds where AI disempowers humanity, AI still takes to the stars. So, AI safety is about who we want to guide the future, not about whether there's a long-term future or not.
- And, even if humanity does go extinct in (say) a bio-catastrophe, probably technologically-capable life evolves in the remaining time that Earth remains habitable.
- So, the probability of "an event occurs by 2100 that prevents Earth-originating life from ever spreading to the stars" is really low, I'd say <1%.
- Which is a lot less, in my view, than "an event occurs by 2100 that meaningfully affects the long-term value of Earth-originating civilisation" where I'm >50%. Cluelessness pushes this down, so "an event occurs that meaningfully and predictably in expectation" is lower, but not by enough.
2/
- There's still WAY more quality-adjusted $$ and labour going to AI safety than there is to AI-enabled extreme human power concentration, from the EA / AI safety communities. I'd say 1-2 OOMs more? So, I think one thing that's going on is a correction because that ratio is out of whack.
3/
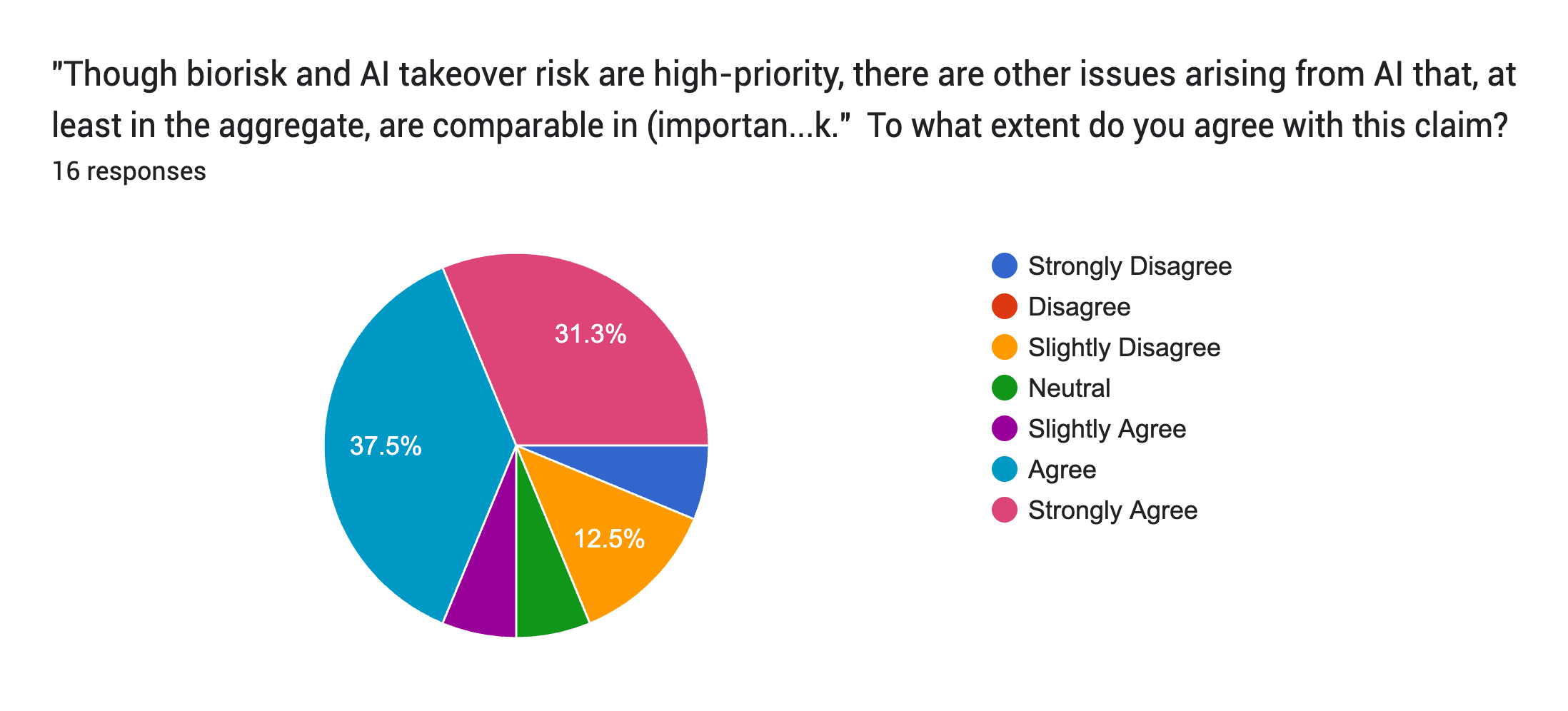
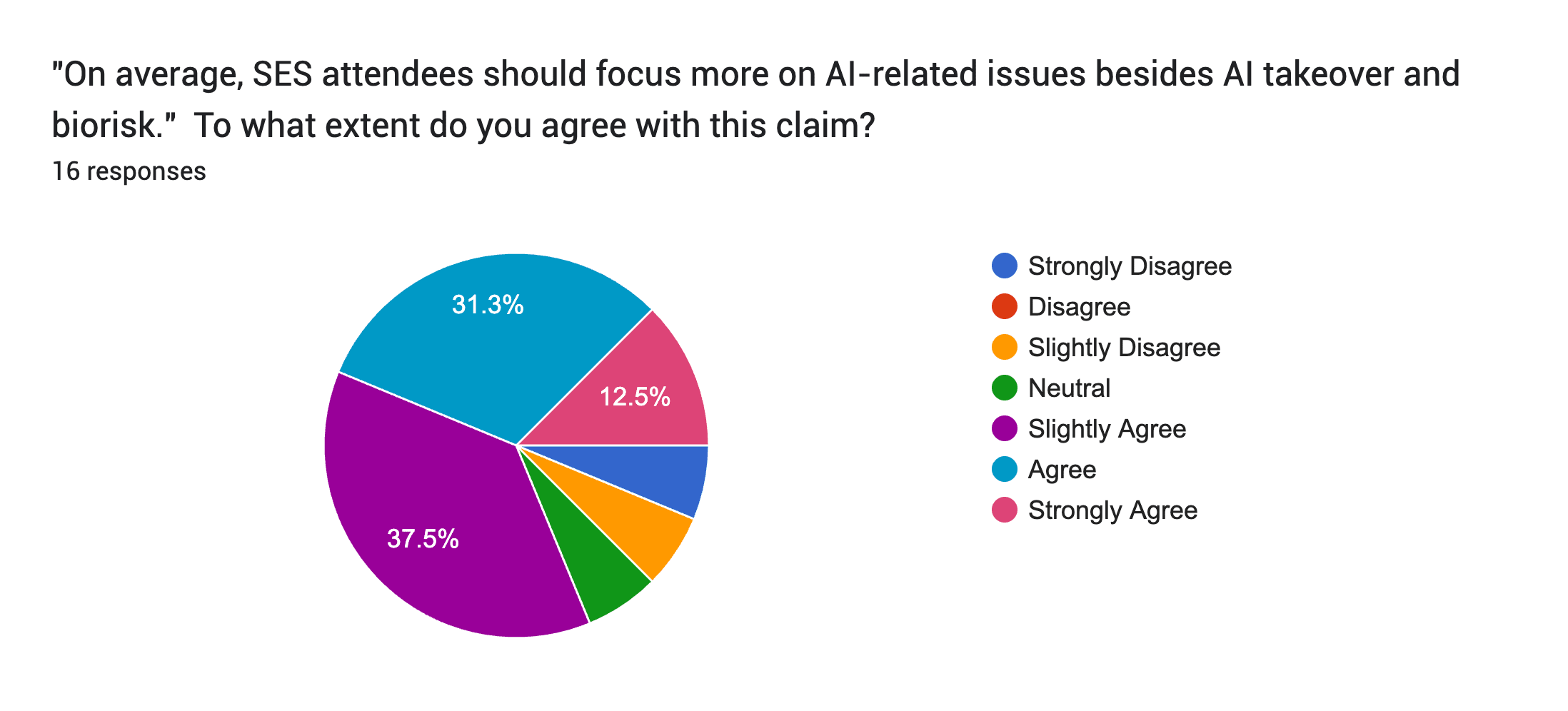
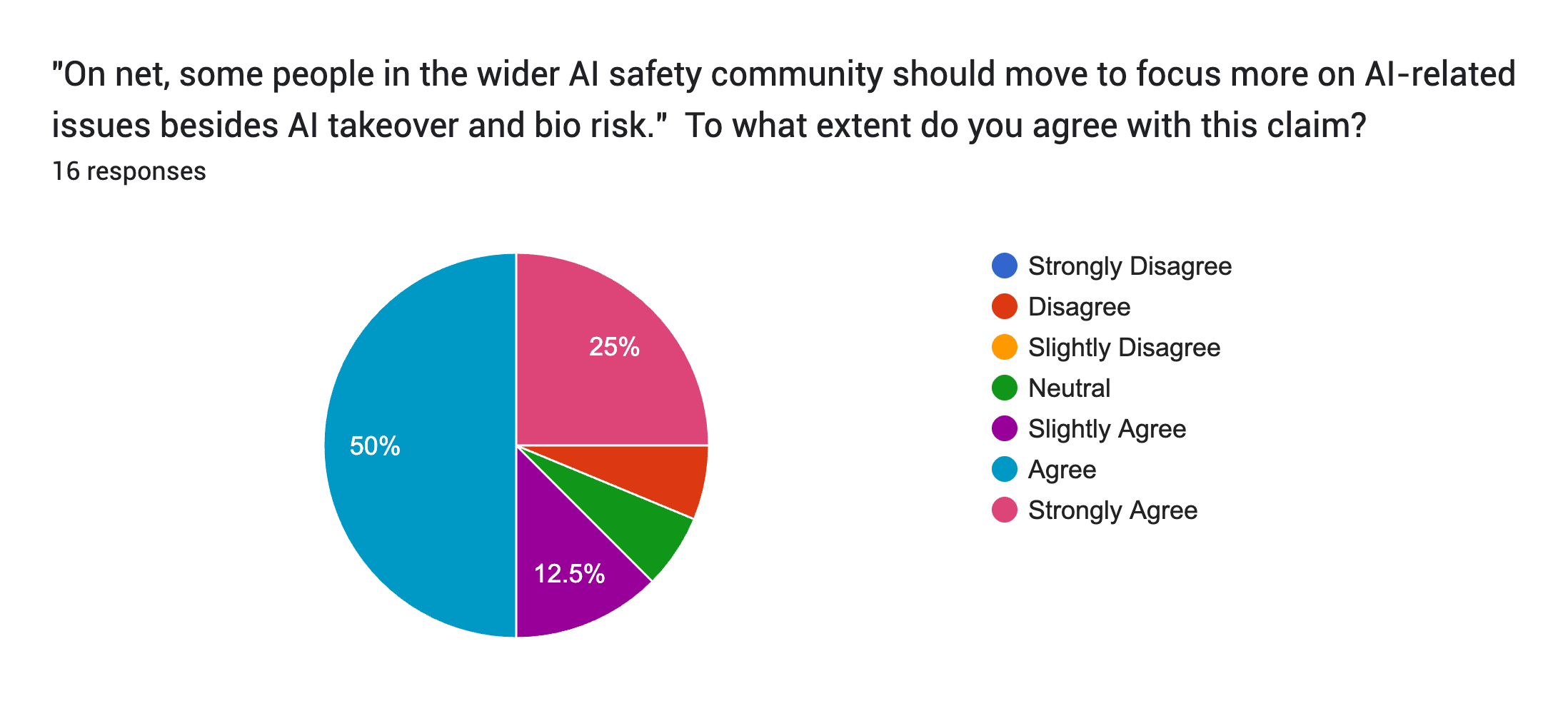
Some evidence you are right, though, about shifting priorities, comes from the February Existential Security Summit. I ran a survey there (massive caveats: tiny sample size of 16, and probably with selection bias from who filed out the form).
Here are the results (note the shades of colours are a little confusing):
(Should say: ""Though biorisk and AI takeover risk are high-priority, there are other issues arising from AI that, at least in the aggregate, are comparable in (importance * tractability * neglectedness) to biorisk and/or AI takeover risk.")
Then, here is an aggregate ranking and Borda scores, in response to:
"How would you rank each of these cause areas, in terms of priority?
Imagine you are allocating a highly capable person who could productively work on any area they put their mind to.
(Rank 1 is highest, and put each rank only once.)"
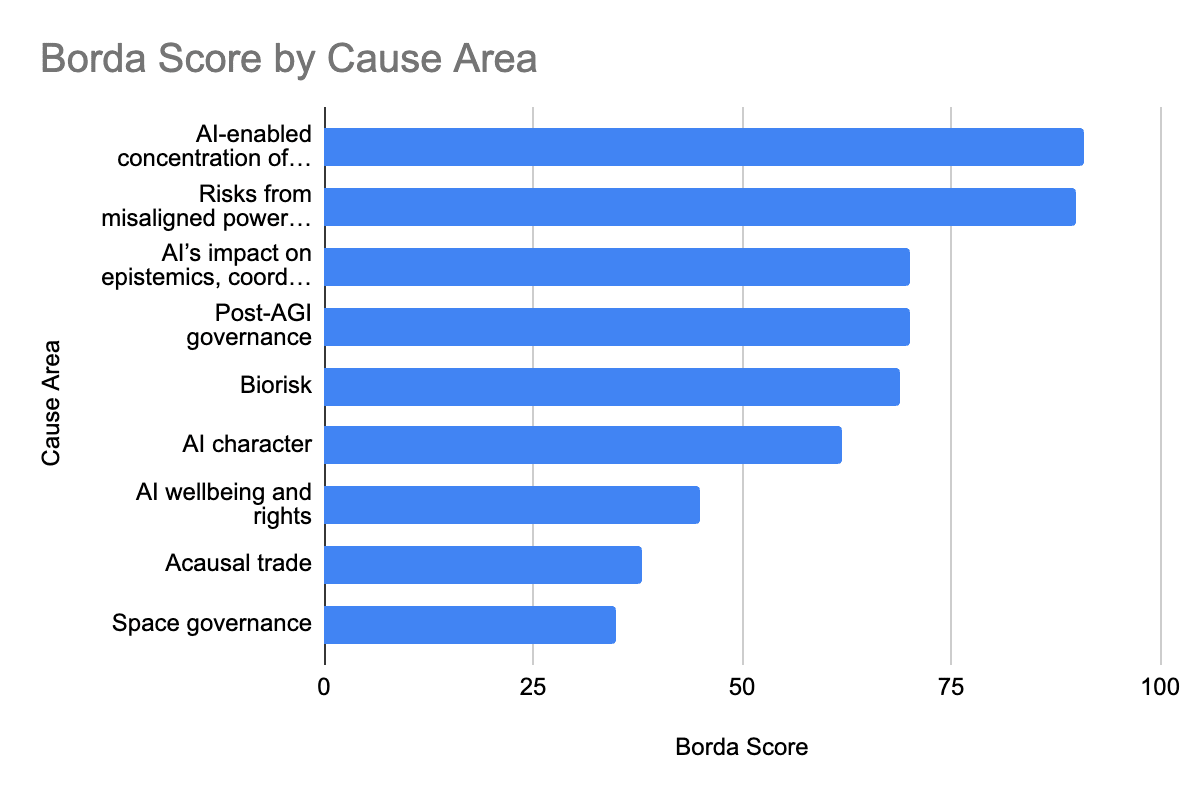
1 AI-enabled concentration of human power
2 Risks from misaligned powerseeking AI
3 AI’s impact on epistemics, coordination and decision-making
3 Post-AGI governance
5 Biorisk
6 AI character
7 AI wellbeing and rights
8 Acausal trade
9 Space governance
Do you mean most likely worlds? The difference seems incredibly important - there are, in my view, quite compelling arguments that the most likely outcome given disempowerment is human extinction, but of course I can imagine worlds in which that doens't happen.
I mostly agree with this though I think there's more extremization[1]: https://www.lesswrong.com/posts/4fqwBmmqi2ZGn9o7j/notes-on-fatalities-from-ai-takeover
Anything like 35% death rate seems implausible to me if I think through the mechanics of a takeover, both <5% and >95% seem more plausible to me, including in very violent takeovers.
I mean, conditional on human disempowerment, >50% that the human species continues till after 2100. Maybe I'm at 80% or more on this.
"So, the probability of "an event occurs by 2100 that prevents Earth-originating life from ever spreading to the stars" is really low, I'd say <1%."
Maybe this is obvious (I'm pretty new here) but if that's the case then is AI safety more about empowering the right people than it is about aligning any individual technology? When (if at all) do these priorities flip?
@William_MacAskill can you say more about this claim?
This is probably the best thing written on expected fatalities.
But the main point is:
- The resources needed to sustain the human species are tiny compared even to the resources just in the solar system (1 part in 10 trillion for all of current civilisation, and the human species could be sustained with a tiny fraction of that)
- If misaligned ASI wants power, it doesn't need to kill everybody in order to do so (and deliberately killing everybody would actively be wasteful).
- So in order to keep some humans around, it only needs to be the case that a tiny fraction of AIs care a tiny amount about keeping some humans around. Could be for intrinsic concern, nostalgia, fulfilling commitments they made (in order to get some humans on-side), acausal reasons (trade with human-like creatures elsewhere in the universe or multiverse), reasoning with potential human simulators, or instrumental reasons (they want to do experiments on humans for science). But the main point is just any tiny motivation is enough. Yes, we're atoms that could be used for something else, but we're really not many atoms at all.
(I also think most human disempowerment scenarios are ones where the humans in general feel pretty fine with it, but I think the above even putting that to the side.)