I've often wished for something like this when doing cost-effectiveness analyses or back-of-the-envelope calculations for grantmaking. (I have perhaps more programming background than the average grantmaker.)
Something like "Guesstimate but with typechecking" would, at first blush, seem to be the most useful version. But perhaps you shouldn't trust my feedback until I've actually used it!
In my communications with GiveWell and others about Pedant, the most prominent message I have is that the tool is too technical and complicated for someone interested in starting out.
This seems like a significant concern that might seriously impede adoption. I'd like to see more iteration to try to identify an MVP that is approachable for users to use. You write that you hope that the barrier to entry will be lowered in the third stage of the project, which involves making a web interface. I assume the web interface would let people skip the process of installing Pedant and knowing how to build files. But what would the web interface look like, and to what extent do potential users find the design intuitive?
The language seems quite straightforward to use, so I think it's feasible to have people write directly in Pedant, but many people may be intimidated by the idea of writing in a programming language. Would friendlier syntax documentation help make Pedant more approachable? (The current syntax documentation assumes familiarity with programming languages.) Maybe a tutorial video on how to write a Pedant file?
I think the current documentation is too technical, or at least, it would be good to write a non-technical guide to the key features of Pedant. I also don't understand power units.
I think some of the syntax could be more intuitive. For example,
Yes, I agree. I can very much add tuple style function application, and it will probably be more intuitive if I do so. It's just that the theory works out a lot easier if I do Haskell style functions.
It seems to be a priority however. I've added an issue for it.
The web interface should be able to write pedant code without actually installing Pedant. Needing to install custom software is definitely a barrier.
Have you looked into Idris? It has at least some of the capabilities that you'd want in a CEA language.
I still haven't looked much at Pedant, but I'm inclined to favor a DSL on top of a pre-existing language rather than a new language that requires its own compiler, largely because the former will be much easier to maintain and should be more portable—you're offloading all the work of writing the compiler to someone else. A custom language will indeed have a much simpler compiler, but the problem is you have to write and maintain the compiler yourself.
Also, possibly of interest to you: About five years ago I wrote a CEA DSL on top of C++. It's definitely not optimal—it's hard to use and only supports certain types of probability distributions—but it works for limited purposes. (I originally wrote it in Excel using VBA, but it was intolerably slow so I rewrote it in C++.)
Yes, I've heard of Idris (I don't know it, but I'm a fan, I'm looking into Coq for this project). I'm also already a massive fan of your work on CEAs, I believe I emailed you about it a while back.
I'm not sure I agree with you about the DSL implementation issue. You seem to be mainly citing development difficulties, whereas I would think that doing this may put a stop to some interesting features. It would definitely restrict the amount of applications. For instance, I'm fully considering Pedant to be simply a serialization format for Causal. Which would be difficult to do if it was embedded within an existing language.
Making a language server that checks for dimensional errors would be very difficult to do in a non-custom language. It may just be possible in a language like Coq or Idris, but I think Coq and Idris are not particularly user friendly, in the sense that someone with no programming background could just "pick them up".
I may be interested in writing your CEAs into Pedant in the future, because I find them very impressive!
Although it doesn’t do the type checking afaik, it seems a good interface for incorporating and enabling
Explicitly modelled uncertainty (montecarlo)
Easy user input of moral and epistemic parameters, and easy to see sensitivity to this
Clear presentation of the (probability distribution) results?
I suspect something like Causal would be better at bringing Givewell and the community on board, but I agree that the formal coding and type checking involved in your approach is also very important.
Maybe some way to integrate these? (DM me, I’m having conversations with a few ppl in this space)
Causal is amazing, and if I could introduce Causal into this mix, this would save a lot of my time in developing, and I would be massively appreciative. It would likely help enable many of the things I'm trying to do.
Hopefully Pedant ends up pretty much being a continuation and completion of Squiggle, that's the dream anyway. Basically Squiggle plus more abstraction features, and more development time poured into it.
When do you think a tool that combines the strengths of Squiggle and Guesstimate will become available? Given where you are at now, what do you think would be the fastest way to integrate the dimensional analysis capabilities of Pedant with the probabilistic modelling capabilities of Squiggle? How long would it take?
Thanks for checking out this post! This is an old one, and I'm no longer as interested in dimensional checking in models. However, I may come back to this project because I have a feeling it could be used to optimize Squiggle code as well as offer dimensional checking.
What do you mean by "Combines the strengths of"? To me, Squiggle is the successor of Guesstimate, and the strengths of Squiggle + the strengths of Guesstimate = the strengths of Squiggle? What features are you looking for?
When I started this project, Squiggle was not in a state where Pedant code could be translated into Squiggle. This is no longer the case, so if there was sufficient interest, I could finish my project to get Pedant to compile to Squiggle for execution. This would likely take a week of work or so.
However, as much as I love this project, I don't want to do that until I've exhausted any easier option of doing the research I want to do + worked out the theory required to create optimizations. There's a possibility that this need will arise once I try to run more Value of Perfect Partial Information analysis for my GiveWell work which is quite slow in Squiggle, or possibly if I could work with the much larger models funders run.
I made a typo. I meant to ask you about integrating the type-checking functionality of Pedant with the probabilistic modeling functionality of Squiggle. I think a version of Squiggle where each value has units that are propagated through the calculations would be very useful. This would allow the user to see whether the final result has the right units.
This sadly, will likely never happen, or at least not for a few years. This was never within Squiggle's scope. Squiggle currently has much more critical issues before adding such a feature!
I’m not very programming-oriented so I can’t really engage with the technical side of things, but I am curious whether/to what extent you think that a quantitatively oriented tool like Pedant would be complemented by a conceptually-oriented framework like the [TUILS framework] (https://forum.effectivealtruism.org/posts/SyWCmqtPsi4PsxnW8/the-tuils-framework-for-improving-pro-con-analysis-1) ? The latter is not so (inherently) focused on specific calculations or parameter harmonization, but it does try to highlight bigger picture conceptual steps/assumptions (e.g. counterfactual effects, the normative value of a given change).
However, I don't fully understand your project. Is it possible to refine a Cost Effectiveness Analysis from this? I'd probably need to see a worked example of your methodology before being convinced it could work.
The purpose of the TUILS framework is to break down advantages and disadvantages into smaller but still collectively exhaustive pieces/questions (e.g., are the supposed benefits counterfactual, how likely will does the desired state materialize).
I’m not sure if you have a very particular definition for “Cost Effectiveness Analysis,” but if you just mean calculating costs and benefits then yes: the whole point of the framework is to guide your reasoning through the major components of an advantage or disadvantage. There is a spectrum of formality in applying the TUILS framework, but the informal version basically treats the relationship between the factors as roughly multiplicative (e.g., anything times zero is zero, if you only solve half the problem you may only get half the originally claimed benefit—assuming there is a linear relationship).
I haven’t fully sketched out a truly formal/rigorous version since I’m not a mathematician and I don’t see that as the main value of the framework (which tends to more about assumption checking, intuition pumping, concept grouping/harmonizing, and a few other things). However, if you’re actually interested in the more-formal application, I could write out some of my rough thoughts thus far. (It’s basically “imagine an n-dimensional graph, with one of the dimensions representing utility and everything else representing input variables/measure…”)
In terms of example applications, I gave some simplified example applications in the post (see the subsection “ Examples of the TUILS framework being applied”), but I haven’t done any written, deep, formal analyses yet since I haven’t seen that as a valuable use of time since organic interest/attention didn’t seem very high even in the simpler version. That being said, I’ve also used a less refined/generalized version of the framework many times orally in competitive policy debate (where it’s referred to as the stock issues)—in fact, probably more than 90% of policy debate rounds I watched/participated in make reference to it. (All of this just to say that a version of it is pretty widely used in the policy debate community)
I agree, as it stands, for the uninitiated, google sheets is much easier to get started with than Pedant. Further, when an analysis is complete, excel is probably more understandable and shareable than the code that Pedant provides.
i suppose it should be possible to add features for exporting to various formats (spreadsheet formats, visual/text representations etc.) which should solve the sharing concern.
I definitely was considering adding some form of exporting feature to Pedant at some point. I'm not sure that it's within the current scope/roadmap of Pedant, but maybe at some point in the future!
Pedant, a type checker for Cost Effectiveness Analysis
Effort: About 80+ hours of dev work, and a little bit of writing.
This project was done under a grant from EA Funds. I would like to give thanks to Ozzie Gooen, Nuño Sempere, Chris Dirkis, Quinn Dougherty and Evelyn Fitzgerald for their comments and support on this work.
Intended Audience: This work is interesting for:
People who do evaluate interventions, or want to get into evaluating interventions, as well as people looking for ambitious software engineering projects in the EA space.
People looking to evaluate whether projects similar to Pedant are worth funding.
Conflict of Interest: This report is intended as a fair reporting on the work I’ve currently done with Pedant, including its advantages and disadvantages. However, I would love to be funded to work on projects similar to Pedant in the future, with a bias to the fact that it’s what I’m good at. So as much as I will try to be unbiased in my approach, I would like to declare that this report may have you see Pedant through rose coloured glasses.
Tldr: I am building a computer language called Pedant. Which is designed to write cost effectiveness calculations. It can check for missing assumptions and errors within your calculations, and is statically typed and comes with a dimensional checker within its type checker.
State of Cost Effectiveness Analysis
When we decide what intervention to choose over another, one of the gold standards is to be handed a cost effectiveness analysis to look over, showing that your dollar goes further on intervention A rather than B.
A cost effectiveness analysis also offers the opportunity to disagree with a calculation, to critique the values of parameters, and incorporate and adjust other considerations.
However, when looking at EA’s CEAs in the wild, there are many things that are lacking. I’m going to detail what I see as problems, and introduce my solution that could help improve the quality and quantity of CEAs.
The Ceiling of CEAs
When taking a look at the CEAs that founded EA, particularly GiveWell’s CEAs, as much as they are incredible and miles ahead from anything else we have, I can identify a collection of improvements that would be lovely to see.
Before going further, I need to add the disclaimer that I’m not claiming that GiveWell’s work is of low quality. What GiveWell has done is well and truly miles ahead of its time, and honestly still is, but that doesn’t mean that there are some possible improvements that I can identify. Furthermore, I may have a different philosophy than GiveWell, as I would definitely consider myself more of a Sequence Thinker rather than a Cluster Thinker.
The first and most clear need for improvement is that of formally considering uncertainty. GiveWell calculations do not consider uncertainty in their parameters, and therefore do not consider uncertainty in their final results. GiveWell’s discussion of uncertainty is often qualitative, saying that deworming is “very uncertain”, and not going much further than that.
This issue has been identified, and Cole Haus did an incredible job of quantifying the uncertainty in GiveWell CEAs. This work hasn’t yet been incorporated into GiveWell’s research.
Considering uncertainty in calculations can be done within Excel and spreadsheets, and some (particularly expensive) industrial options such as Oracle Crystal Ball and @RISK are available. Currently, Guestimate is a great option for considering uncertainties in a spreadsheet like fashion, created by our own Ozzie Gooen.
The next few issues are smaller and much more pedantic. When working with classical tools, it’s very easy to make possible errors in calculations. Particularly, looking through GiveDirectly’s Cost Effectiveness Analysis, I was able to identify two implicit assumptions about the calculation. Particularly, I found that:
The period of time the payment was initially consumed was implicitly assumed to be 1 year
The period of time where the recipient got some investment back was implicitly assumed to be 1 year.
These assumptions are included within the calculation without explicitly declaring that they exist. I was able to identify that these hidden assumptions existed because they are both in the unit “year”, and the calculations weren’t dimensionally valid unless I included them.
I would prefer these to be parameters, and not implicit assumptions. That way they can be questioned and the model refined.
Further, there was also a couple of what I would call errors, notably:
In the first year of the transfer, the increase in welfare due to money transferred is actually slightly larger than it should be.[1]
This is what I’ve identified so far for GiveDirectly. I’m not sure how many of these types of issues exist in the other CEAs, but after some initial investigations I think GiveDirectly might be an outlier.
Finally, the analysis is presented to you in an enormous spreadsheet. This is often difficult for readers to parse and understand it’s logic. As such, many EAs don’t ever really consult or explore it, and just accept GiveWell’s analysis as gospel.
Again, I’m far from saying it’s on GiveWell to fix this. Their work is incredible, and most of the consequential decisions needed to do good CEAs are parameter estimations, not necessarily addressing these more technical issues. However, I’m very much a Pedantic when it comes to my math and theory, so it would be nice to see if there was a way to lift the ceiling of CEAs in that area.
The Floor of CEAs
That being said, in practice, the quality of GiveWell’s work is a clear outlier. In the rest of the EA space, quantitative CEAs seem to be rarely if not even done. ACE has retracted their numerical cost effectiveness analysis since 2019, citing difficulties in modeling, and numbers that were interpreted as too certain, and have turned to qualitative cost effectiveness models.
By “The floor of CEAs”, I’m referring to initial numerical evaluations done by organizations that have not yet been evaluated, or little evaluation has been done. This however, is not difficult to find, and for all practical purposes might as well be “not GiveWell”.
Talking to Nuño on creating these evaluations, he claims any “software that automates or allows for scaling any part of evaluations” would be useful in making these evaluations. He also would be appreciative of tooling that can create sophisticated probabilistic estimates and visualise them.
Thankfully, as you may have guessed from the title. I’ve attempted to do some ground work on lifting both the floor and ceiling of Cost Effectiveness Analysis.
Introducing Pedant
Pedant is a language for Cost-Effectiveness Analysis, and other important calculations.
It’s good to think of Pedant as a replacement for Excel or Guesstimate, rather than a programming language. The motivation of Pedant is threefold:
Enable the creation of higher quality cost effectiveness analysis
Make it easier to start making cost effectiveness analysis
Allow comparisons and reuse of cost effectiveness analysis by presenting them in a similar form.
It’s being built in three stages. The first stage is to create a basic language that can identify dimensional errors and missing assumptions. The second is to consider uncertainty, and the third to consider accessibility. Each step has been budgeted a month, with the second stage due for late January, and the third for late February
I have come to the end of the first stage of this project, so I’ll keep the discussion of the project to only this first stage. But hopefully what’s to come is just as interesting as what I have to present with this first stage.
The description and motivations of Pedant are outlined in the following sections. In type checking calculations, I talk about the dimensional analysis checker, and catching assumptions. In the abstraction section, I cover methods of abstraction available in Pedant.
Type checking calculations
One of the most important elements of any analysis is whether it’s actually correct. Whatever system I make, I would like to make it difficult to write, or at least easy to see, errors like the ones I found in GiveDirectly’s CEAs. This is in a similar spirit to strongly typed languages, and particularly functional languages, where the type system makes it difficult to write certain types of errors into them.
I identified the errors that were made in GiveDirectly’s CEAs through the use of dimensional analysis. Dimensional analysis is simply checking for the consistent use of units through the calculations, you can look through my past post for an introduction.
In the spirit of Haskell, Pedant investigates whether it would be possible to create a type system with inbuilt dimensions. Type systems allow you to write some code out, and have the problem with your code immediately described and pointed out to you, with red underline and a detailed description, where you went wrong and how to fix it. This way, the user can quickly identify flaws in their reasoning and modeling and other important considerations.
Due to the success of identifying errors/assumptions in GiveDirectly’s CEAs, I decided to create a language that does this type of checking automatically.
Identifying GiveDirectly’s implicit assumptions with Pedant
And I succeeded in doing that. Let’s take a look at some Pedant in action.
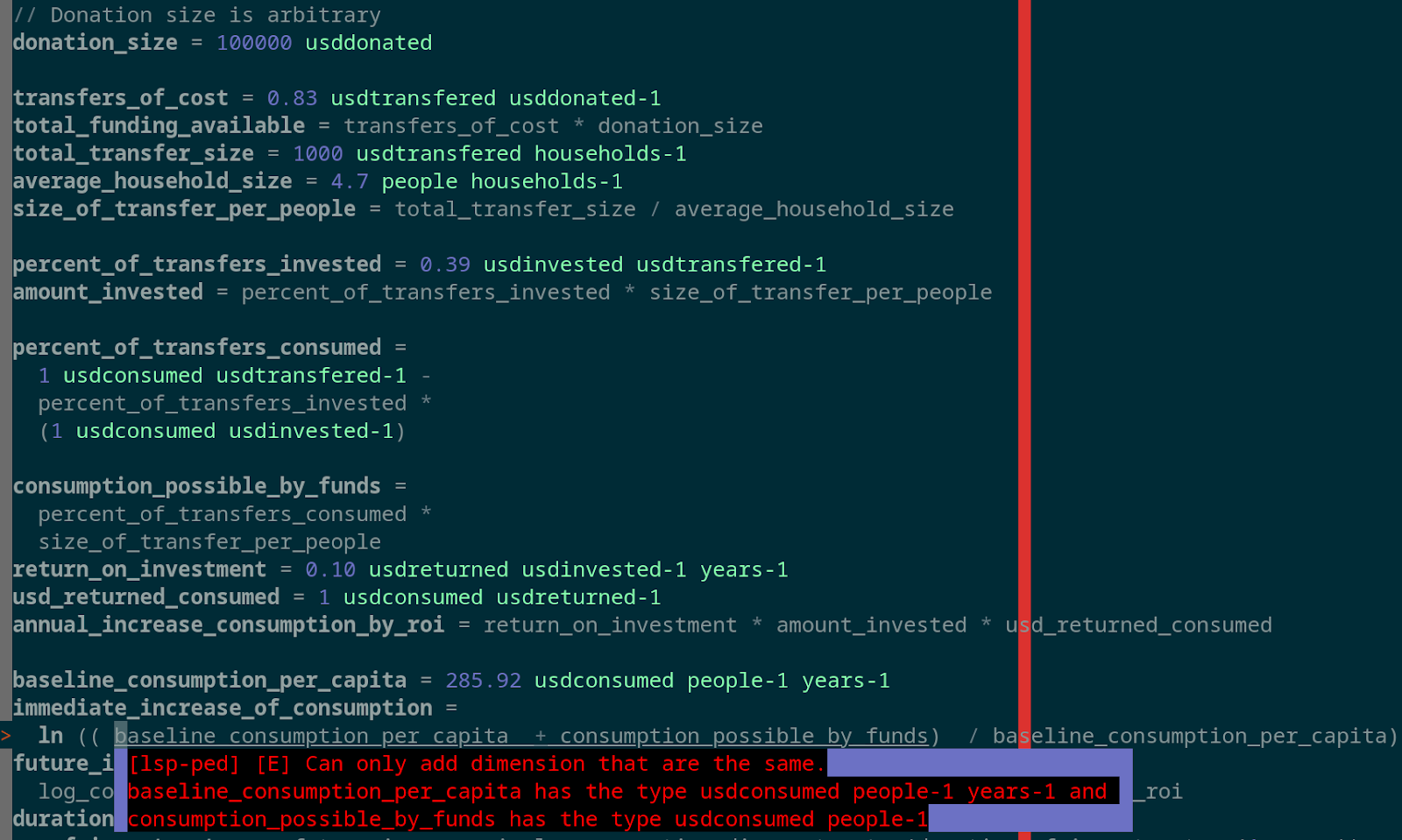
GiveDirectly's CEA written in Pedant displayed in NeoVim. Uses an coc.nvim and a language server to serve errors.
This is the cost effectiveness calculation of GiveDirectly written into Pedant. There’s a lot of interesting things to take in here, we’ll start with the basics.
The first thing to notice is that the syntax makes a lot of sense. It’s just a list of assignments, with a variable name on the left and a value on the right. However, numbers are allowed to have units to the right of them. I built a syntax plugin for neovim that highlights them green. The syntax should be very self explanatory.
Then, we have the type error. Which is telling the user that they cannot add two things that are of different dimensions, and that baseline_consumption_per_capita is of dimension usdconsumedpeople−1years−1, but consumption_possible_by_funds is in dimensions usdconsumedpeople−1
This error prompts the user to think… What’s the problem here? Why am I getting this issue? The first thing the user might need to think, is whether we want both the units to be usdconsumedpeople−1years−1 or usdconsumedpeople−1. After a little thought, we would realise that baseline_consumption_per_capita certainly has a years−1 component to it, (aka, the consumption number is definitely “per year”) so the consumption_possible_by_funds must be in error.
You might realise that actually, consumption_possible_by_funds has no time component written into its calculation. However, the result of the calculation should depend on how quickly those funds are consumed. So Pedant has helped you identify a missing assumption.
You write this assumption in:
Writing in the missing assumption in Pedant.
But then you get another error:
A new error, later in the Pedant file
Here it’s complaining that the immediate increase of consumption has dimension 1 (also called dimensionless), but the rest of the expression has type years. What’s going on here?
Well, thinking about it, this pv value has to have a time component, as it is similar to the concept of a QALY. It is like quality multiplied by time, so the initial consumption must be wrong.
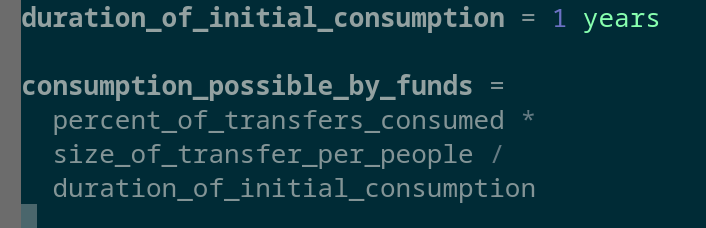
You can then correct up the immediate increase of consumption variable:
Correctly multiplying increase of initial consumption by duration
This example shows how Pedant can guide you into identifying possible errors within your model through dimensional checking.
Abstraction
The next interesting opportunity is that of abstraction. The idea that it’s possible to find similar parts of the analysis and put them into reusable components. This helps debug but also share and build on other people’s work. Pedant has both functions and modules as abstraction mechanisms.
Functions
Pedant has support for functions, functions are declared by specifying arguments after the name, similar to Haskell.
A Pedant Function. Takes three arguments. All types are inferred.
This function is a continuous version of the present value function. It is used in all of the GiveWell evaluations of effectiveness[2]. This allows you to reference and reuse this economics calculation in all the other analysis.
Although no types are declared, this function is still statically typed. All types are inferred from their usage within the body (Haskell style). This makes for a clean style of function declaration.
Modules
Modules are simply files that you can import into other files. The syntax is very simple:
common.ped:
givedirectly.ped
All variables and units are automatically exported.
This allows importing of both values and units from other modules, and therefore helps with the sharing and reuse of other evaluations.
There are two more stages left in the initial development of Pedant, uncertainty and a web interface.
Uncertainty modelling
One of the most important considerations is that of uncertainty. We are really not sure about a lot of the parameters that we use in our calculations, and that uncertainty can vary between parameters and calculations. We would like to be able to represent this uncertainty within our calculations.
The next stage will take inspiration from Ozzie’s Squiggle and Guesstimate, and allow the user to write in a distribution of possible values a parameter will have, and to run Monte Carlo simulations over the model to produce an uncertainty at the end.
There are also interesting opportunities in integrating over uncertainty measures to do things such as calculate the value of information.
Web Interface
The final stage is to create some form of web interface. Currently, Pedant exists as a simple interpreter for a textual language, with the only interface being a command line. I am very much aware that this would exist as a major roadblock to people interested in getting into evaluation.
Further, requiring you to have a command line tool to explore an evaluation given to you by a colleague would be very tedious.
As such, I would like to create a web interface that allows the user to explore an analysis, as well as input their own assumptions into the model, and explore the different assumptions made and their sources.
Problems with the Pedant approach
The approach that Pedant takes is not without issue. Some of the issues that are listed here (and hopefully, more listed in the comments).
No focus on parameter estimation
One of the most difficult problems with creating cost-effectiveness calculations is parameters. Choosing appropriate values for parameters often feels very daunting, as you have to make large guesses at values that are often not heavily researched. These parameters are also the most heavily criticised.
Pedant offers no helping hand when guessing parameters even though it could. There are a couple of ways that this could be done:
Gathering related data and studies into databases. So that people are aware of other estimations of similar analysis. Having a very large library of pedant CEAs or simply data points with uncertainties would be helpful here. This however, is extremely ambitious.
Forecasting the value of parameters. For instance, in GiveWell’s GiveDirectly model, one parameter is the amount of money spent on program costs. This could easily be forecasted and evaluated on an annual basis, which allows the uncertainty to be captured accurately, as well as parameter estimates to change, as new information is available.
I am uncertain as to whether projects such as these may be a better use of time over a language such as Pedant. However, it may be valuable to have a standard portable form of cost effectiveness calculations through Pedant, that can then have systems such as these plugged into them. Pedant is an appropriate exploration in creating this standard.
Too Technical
In my communications with GiveWell and others about Pedant, the most prominent message I have is that the tool is too technical and complicated for someone interested in starting out.
I agree, as it stands, for the uninitiated, google sheets is much easier to get started with than Pedant. Further, when an analysis is complete, excel is probably more understandable and shareable than the code that Pedant provides.
Another thing of note is that Pedant, as a dimensional checker, is a very surprising and specific tool to bring to the table. It may be valuable to bring improvements to more general tools such as excel spreadsheets. This may be badly motivated, and was mainly motivated by its success in identifying possible errors in the GiveDirectly CEAs.
It is my hope that this barrier to entry will be lowered and it’s applicability made more general on the third stage of this project.
Why do we need another language?
Another common objection is that, “Oh, dimensional checking? X can do that!”, where X is Julia, Rust, F#, Insect etc.
Pedant is not designed to be a programming language, it’s a DSL (Domain Specific Language). Designing it as a custom language has the benefit of not being Turing complete and will execute predictably, never act maliciously, nor can it access external resources such as calling web endpoints or other interfaces. This has the benefit of making it very portable, and that you can parse and use pedant files for many other purposes, such as performing automatic sensitivity analysis over parameters.
I am yet to come across a language with similar design goals to Pedant, but would love to know of any that exist that can be used/improved upon.
That’s the current state of the work, hopefully I’ll have much more to show soon. Please feel free to ask questions or feedback. If you are interested in helping develop Pedant, please contact me on the Forum, send a pull request on GitHub, or join me at EA Public Interest Technologists to discuss it.
[1] For those curious why it’s larger than it should be for the first year. GiveDirectly’s CEA calculates wellbeing by the log of the increase in consumption. Each log increase of consumption corresponds to a certain amount of wellbeing.
Increase in consumption can come from three sources:
Increase in initial consumption (Year 1)
Increase in consumption from investment returns (Year 1-9)
Increase in consumption from end of investment (Year 10)
It should be noted that consumption is modeled to increase from both initial consumption and investment returns in the first year, so the amount of consumption in the first year, where the baselineis the amount of money that would have been consumed without the intervention, is:
baseline+consumption+investmentreturns
So the log increase of consumption for the first year is
However, due to the way that it’s modeled (the fact that the initial consumption is over the period of the first year seems to be ignored), this is calculated as:
[2] Well, the discrete version is in the CEAs, I use the continuous version because the discrete one is dimensionally confusing. I believe a continuous version also models the situation better.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...






I've often wished for something like this when doing cost-effectiveness analyses or back-of-the-envelope calculations for grantmaking. (I have perhaps more programming background than the average grantmaker.)
Something like "Guesstimate but with typechecking" would, at first blush, seem to be the most useful version. But perhaps you shouldn't trust my feedback until I've actually used it!