Thanks for laying this out. My quick take is that I'm uncertain how useful such evaluations will be in practice. I could see my reaction to them being anything between "while I won't buy the bottom-line number as best-guess estimate or only input into my decision, this evaluation overall was super useful, if only to identify the most important uncertainties regarding this grant's/project's impact" and "this all feels so brittle and speculative that I don't feel comfortable using any of the numbers, and all the qualitative insights I can clean from them were sort of obvious".
But I think it'd be very worth trying.
My best guess is to agree with you that we should be doing more evaluations of roughly the kind you suggest on the margin. (At least, say, the EAIF, which is something I can speak to from my own experience. I also have a fuzzy more general sense that it would be good for many EA orgs/people to do so, but there I have a much poorer sense of the opportunity cost and the extent to which such things might happen internally.)
FWIW if you or someone else with a track record at making the required kind of quantitative estimates wanted to do some retrospective evaluations of EAIF grants in the spirit proposed here, I'd be very likely in favor of funding this.
Love the ambition, and I like that it could fail gracefully (since steps 1 and 2 are tractable and valuable on their own, and just require people to regain their courage to make up numbers, after learning Saulius' important lessons). Step 1-3 are worth millions of dollars, maybe more, even if we just do em for the empirical causes.
And longtermism needs evaluation. I have made only the most basic estimate of my own impact. (One narrow unit I've used is the 'basis point reduction in xrisk'.) It could also help precisify what 'robustly' good means (95% of mass with positive effect?).
I probably don't need to emphasise how hard step 4 is. But you don't emphasise it, so I will.
It's hard, hard like solving a chunk of philosophy. In fact the crucial considerations you list seem relatively tame: they're continuous. I take the real horror of crucial considerations to lie with the strongest ones: inverters, those that flip the sign of your evaluation (making you do the opposite action) - then another comes and flips it again - with no particular reason to think they will stop coming. This headache seems like the default situation for crazy-town (that is, strict) longtermists. And it doesn't seem easy to analyse with your heroic method.*
(I'm not suggesting that we give up - we should whack-a-mole crucial considerations, in the hope of eventually running out of moles.)
Now instead assume victory. Here's what seems likely on the user end:
An honest longtermist quantification will spit out something spanning 7+ orders of magnitude (with some chunk of it covering negative value land), all relatively flat.
This will make most people's distributions look very similar, despite them presumably being based on extremely different premises and weightings.
Struggling to manage multiple apparently uninformative intervention distributions, most people will just decide based on the mean, wasting your subtle development and philosophical work.
* You could concoct a prior on how many rungs you expect the deliberation ladder to have, and act once you've got past most of it. But this wouldn't help, because being just one rung off means you're reducing value.
I actually don't know a practical way to handle inverters. Do you slightly reduce your investment in all interventions, to hedge against causing harm? Sounds absurd.
With regards to your grim picture of victory, yeah, estimates will span multiple orders of magnitude. But at the very least, we could cut off the paths that "the market", or "the forecasting system" knows to be dead-ends from the start. Because people have a bunch of biases that better forecasting/evaluation systems could just make apparent in excruciating detail.
For example, consider Open Philanthropy's spinning off of Just Impact, "[a]fter hundreds of grants totaling more than $130 million over six years" because "we think the top global aid charities recommended by GiveWell (which we used to be part of and remain closely affiliated with) present an opportunity to give away large amounts of money at higher cost-effectiveness than we can achieve in many programs, including CJR, that seek to benefit citizens of wealthy countries".
I have some pet theories about what happened here, but I'm pretty sure that any decent forecasting/evaluation system would have seen this* coming a mile ahead.
*: this = criminal justice reform being less effective than global health.
Thanks for the thoughtful comment, Gavin. Note that the inverter problem also exists in the case where you are not quantifying at all, so quantification just brings it to the forefront.
In offline conversation, you mentioned that people are bad at overriding shitty models with their initially superior intuition, which is a problem if quantified models start out as being shitty. To this the answer from my part was that yeah, at this point, I would just posit or demand grantmakers who have the skill of combining models which have some error with their own intuitions. Otherwise, the situation would be pretty hopeless.
It's not that intuition is superior: it is broad, latent, all-things-considered (where all formal models are some-things-considered). The smell test it enables is all we have against model error. (And inverters are just a nasty kind of model error.)
I consider naming particular [AGI timeline median] years to be a cognitively harmful sort of activity; I have refrained from trying to translate my brain's native intuitions about this into probabilities, for fear that my verbalized probabilities will be stupider than my intuitions if I try to put weight on them. What feelings I do have, I worry may be unwise to voice; AGI timelines, in my own experience, are not great for one's mental health, and I worry that other people seem to have weaker immune systems than even my own. But I suppose I cannot but acknowledge that my outward behavior seems to reveal a distribution whose median seems to fall well before 2050.
Thanks for the write-up! I appreciate the orientation towards simplicity and directness of value quantification (including uncertainty) and the overall mindset and spirit of the processes that this induces in people's minds.
I am wondering why I am not actually surprised that I don't see people (esp. EAs, and including myself) doing this more. I would expect some of the (assumed) reasons to be simple to state and (in principle) overcome (e.g. lack of skills, not as valued in culture, inadequate epistemic habits, ...) and some to be complex and hard (bias towards quantifiable parts of the model, estimation issues with long-tailed distributions, various elephants in the brains or social/cultural dynamics, robustness, ..). In particular, I would expect some hard obstacles or downsides to actually exist as it seems to me that some people whose epistemics, agency and models of the world I highly respect use quantitative estimates way less they could, at least in some domains. (In particular I assume they don't lack skill or epistemics in general.)
What is your take on why people may not want to use this (or a similar) quantitative framework for speculative interventions (or some types of projects)?
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...
Currently, we can’t compare the impact of speculative interventions in a principled way. When making a decision about where to work or donate, longtermists or risk-neutral neartermists may have to choose an organization based on status, network effects, or expert opinion. This is, obviously, not ideal.
I propose a simple solution, if not an easy one. First, estimate the impact of an intervention in narrow units (such as micro-covids, or estimates of research quality). Then, convert those narrow units to more and more general units (such as QALYs, or percentage reduction in x-risk).
Quantifying the value of speculative interventions to a standard similar to GiveWell’s represents a lot of work on a messy problem. In this post, I’ll break it down to these five steps:
Create narrow units for specific types of interventions
Use narrow units to evaluate interventions
Create more general units, and conversion factors from narrow units to general units
Resolve or quantify crucial considerations in order to generalize further
Scale-up evaluations: do more evaluations, better, more cheaply, about more things.
As we make progress on these subproblems, relative value comparisons would become more robust, principled and transparent, which would improve the quality of our decision-making around funding and prioritization. Decisions about where to work or where to donate might still be informed by some subjective factors (e.g., personal fit, value differences), but they would be more grounded in research and expected utility calculations.
This proposal grew out of my frustrations with quantitatively evaluating longtermist organizations or EA projects more generally without a developed framework. Nobody has really been doing this kind of evaluation[1], so the infrastructure and know-how is just not there.
It’s not even clear what the bar for funding longtermist interventions should be–we don’t know how much good "the last longtermist dollar" will accomplish. Without that key number, funders have to make grants to the best of their abilities by using heuristics and intuitions, which naturally has limitations.
It has been argued that expected utility calculations can be misleading or counter-productive. But these calculations don't have to be perfect, they just have to be better than the alternative—whatever non-quantitative methods people would have used instead. It also doesn’t matter in practice whether one can reach expected value calculations in all their glory, as long as the efforts towards quantification end up paying off (e.g., in terms of better decisions).
So from my perspective, one of the most powerful tools in the EA arsenal has been left gathering dust, mostly for unclearreasons.
In the short term, intuition or heuristics can fill in the gap. But in the long term, as EA moves billions of additional dollars, we will need to upgrade intuition-based human factors to auditable, scalable and more powerful evaluation methods.
Step 1: Create narrow units for specific types of interventions
The simplest and cheapest way to start seems with units tailored to one particular intervention or type of intervention. I’m going to call these “narrow units”, as opposed to more general (e.g., QALYs, which could denominate many types of interventions) or abstract ones (e.g., measures of “research value”).
With narrow units, we can ask if a unit captures most of what we care about in an intervention, and evaluate a new unit on that metric. In the case of research at EA organizations, we care about how it directly influences decisions, but also about the further research it enables, the mentorship around it, the prestige that the authors attain, etc. A unit intended to capture the value of research could start by just trying to estimate its impact on decisions, and progressively become more complicated.
If we can have them, we want additive units. They allow us to easily do calculations, like summing up the estimated value of an organization and dividing it by funding raised to estimate the impact per dollar. On the other hand, non-additive units are much cheaper to create, and they still allow us to produce relative rankings, or to notice directional improvement. For instance, a 2x improvement in the Brier score (one possible “forecasting score”) is not twice as useful, but the Brier score still allows us to get a good sense of which forecasters are the most accurate.
Ideally, narrow units would refer to the end goal of an intervention, but measuring intermediary outputs is still useful. In some cases, it may be the only option. For instance, if two movement-building interventions cost the same but one produces more promising new EAs, we can still choose the second, even if we don’t know how promising new EAs cash out in terms of ultimate impact. Similarly, measuring the usefulness of forecasts is difficult, but we can measure forecast accuracy and incentivize forecasters in proportion to it if we suspect that it strongly correlates with the quality of the decisions the forecasts influence.
A narrow unit doesn't have to be perfect to be useful when comparing interventions within the same cause area. In some cases, it’s possible to show that one option vastly dominates others even when using fairly crude units. For instance, one research group might be significantly more productive or efficient than another, or the majority of forecasting questions on Metaculus might not matter. In these two cases, the units were crude estimates of research output divided by number of staff, and an index of question usefulness.
Each of these units attempts to capture something about why or how a given intervention is valuable. They can then be used to track and incentivize progress if the units are more developed, or to sanity-check intuitions if they are fairly imperfect proxies.
Step 2: Evaluate interventions using their narrow units
Intervention evaluations vary significantly by legibility, methodology, and effortfulness. Some are more like calculations, others like judgment calls; some include explicit uncertainty bounds, others implicit ones. Some are multi-million dollar months-long affairs; others are brief forum posts.
In order to quantify speculative interventions, we will want our evaluations to be composable. That is, we want evaluations of small-scale interventions to be such that they can be built upon and combined to express more complicated relationships, like the relative value of cause areas or of organizations. We also want to combine estimates of what is most valuable in the abstract with estimates of people’s comparative advantages to produce estimates of what is best for particular people to do.
For this, it would be useful to have legible evaluations with explicit uncertainty bounds. The legibility helps because to trust the end process, it helps if we can verify each of the components. Explicit uncertainty bounds helps with the mathematical manipulations needed to combine various guesses. Explicit quantification could also help catch and correct human biases.
The examples that I’m aware of that come closest to the type of evaluation that I’m talking about are Gordon Irlam’s Back of the Envelope Guide to Philanthropy and The Copenhagen Consensus’s list of most promising interventions. These two stand out because they are broad—they try to evaluate many different types of interventions, and because they are quantified—they put a number on the value of the interventions they consider. However, the Back of The Envelope Guide lacks a bit in depth and mostly stays at the general level, and the Copenhagen Consensus mostly keeps itself to mainstream interventions, and they are both a bit outdated.
The EA community also has some examples of evaluations that are somewhat similar to what I’m proposing, but which fall short in breadth, quantification, composability:
Animal Charity Evaluators, focuses on animal welfare, but their evaluations are non-quantified and thus on occasion subject to opaque judgment calls.
Larks' non-quantified evaluations of the research output of AI alignment research organizations
My own very shallow evaluations of longtermist organizations, using mostly custom or no units for each evaluation
Of course, there is GiveWell. Their method is to evaluate each organization on its own terms, using its own units (e.g., expected deaths of malaria averted, doublings of consumption, etc.). GiveWell then converts these evaluations to “doublings of consumption equivalents” (see step 3: more and more general units). This method is justifiably expensive; GiveWell spent around $8.5M in salaries and other expenses in 2020 to move hundreds of millions of dollars.
However, though widely considered a gold standard for impact evaluation, GiveWell’s evaluations lack some nice properties, such as composability and the explicit use of distributions. This means that one can’t just take GiveWell’s approach and expand it to another area, like one could with e.g., the microcovid calculator. They are also constrained to global health and development interventions.
If we are aiming, either as individuals or as a community, to do the most good we can do, we need to be able to determine what the most good actually is. For this, we need to be able to evaluate many things in a way which enables comparisons between different types of things. In this, quantified evaluation, with explicit uncertainty bounds and other bells and whistles, would really shine.
Step 3: Create more general units, and conversion factors from narrow units to general units.
From tonnes of CO2 emissions, we generalize to CO2-equivalents. From micro-covids, to micromorts. From lives saved from malaria, or people cured from blindness, to Quality-Adjusted Life Years (QALYs). These can in turn be generalized further, e.g., from QALYs to "intensity-of-consciousness adjusted QALYs". This allows us to compare human and animal interventions, or to compare different types of animal suffering interventions to each other.
To do this kind of generalization, it is necessary to have “conversion factors” from narrower to broader units [2]. Health interventions can be compared by tallying how much pain and suffering they each avert, in QALYs. Then that suffering can be compared to economic interventions by having some conversion between doubling of consumptions and QALYs. This information can be found by doing surveys of potential beneficiaries, or by studying their revealed preferences. That in turn can be compared to climate change interventions—e.g., as inthis post—by coming up with an estimate for the social cost of carbon. Then we can estimate the value of the long-term future, and come up with a (very uncertain) estimate of how much we should trade off a chance of affecting the world in the short term now vs a chance of affecting the long-term future.
As we generalize our units, our confidence intervals become wider. We might be very sure that we emitted such-and-so-many tonnes of such a gas, not exactly sure how many CO2-equivalents that is, and very unsure about how many QALYs this destroys.
It’s unclear whether this growing uncertainty will pose a practical problem. If uncertainty is extremely high, we might want to invest more time into applied global priorities research, or into revelatory grantmaking (making funding decisions not only in terms of their raw expected value, but also in terms of the expected value of the information they provide). Conversely, if each distribution is spread across many orders of magnitude, it might still be relatively clear which among many options is optimal. I’d imagine we’d find a mix of the two, but also that quantification would be much better than human intuition at differentiating the two cases[3].
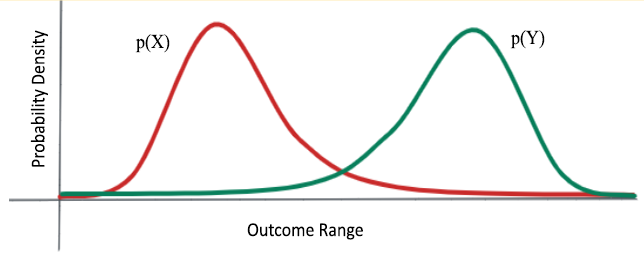
The red and the green distribution could range over many orders of magnitude, and it might still be clear which one is the better bet.
Less elegantly, we could use “willingness to pay” as a way to convert all units into money by relying on revealed preferences. This has the advantage that it is instant and easy to do, but the disadvantage is that it might capture biased or suboptimal actions. Ozzie Gooen and others have suggested using “enlightened willingness to pay” instead, an estimate of what one’s willingness to pay would be if they thought more about it and had more information.
Normally, we will have two types of uncertainty that seem worth separating. On the one hand, we have uncertainty about how much X we have (how many deaths from malaria are prevented, how many covid cases, how many percentage points in existential risk reduction). And on the other hand, we have uncertainty about how good X is compared to other things (e.g., how good is preventing deaths from malaria is in comparison to preventing other diseases, or how good human suffering interventions are compared to animal suffering interventions, or to reducing existential risk). We’ll want to capture uncertainty of the first type in narrow units, and uncertainty of the second type in the conversion factors from narrow to more general units.
We can’t observe "percentage points in existential risk reduction." But we can estimate it by forecasting the existential risk before and after an intervention. Prediction could also amplify a trusted forecaster to do this, i.e., have other forecasters, prediction markets or machine learning systems try to predict what the trusted forecaster will think. In practice, current forecasting systems are too weak to reliably do this, so improving forecasting may be another priority to improve our ability to do good evaluations.
Lastly, if other methods fail, enough comparisons between elements of interest can be enough to generate a unit, or a scale. For instance, we have a bunch of papers on a topic, we can pick one that’s about in the middle, give it a value of “1 quality adjusted paper”, and estimate the value of other papers as their relative value compared to the reference paper. This would be a rudimentary measure of quality, but might still beat the h-index in helping determine who the most valuable authors are.
Step 4: Resolve or quantify crucial considerations in order to generalize further
As two interventions grow more and more different, the relevant considerations for comparing them grow more and more abstract, philosophical, or value-dependent. These crucial considerations might include:
How easy is high-fidelity movement-building?
How valuable are different types of animals compared to humans?
How heavily should you discount the future?
How many people haven’t been born yet?
What is the return rate of the best investment opportunities that EA has access to?
Is faster economic growth good?
How valuable is reducing suffering compared to increasing happiness?
For the crucial considerations that are particularly value-dependent, quantification tooling could ask the user about their best guesses on some of these controversial parameters (e.g., the discount rate, the value drift rate, the probability of success of various interventions, the value of human vs animal lives, etc.), and then carry out calculations using those guesses. Food Impacts has such a tool for animal suffering prioritization:
Food Impacts: Which animal products should we avoid? h/t Vivian Belenky.
More sophisticated versions of this kind of tool could let users bake in different assumptions. For example, we could add in the time horizon over which greenhouse gases have a warming effect, the value of saving the life of a five-year-old child vs a ten-year-old child, or the ratio of the value of various animal lives to a human life.
As another example, GiveWell's spreadsheet allows one to tweak how valuable "a statistical life saved from malaria" is compared to "a doubling in consumption". But it doesn't allow for changing the assumption that different doublings of consumption are differently valuable.
As our tools become more sophisticated, the quantifications they output might become more modular and composable, more akin to computer programs than to excel spreadsheets or webpages. For instance, the user could set a utility-of-consumption function that isn't logarithmic, which might value doublings more at lower levels of consumption, or which takes into account the shape of possible poverty traps.
Crucial considerations could also be resolved by better long-term forecasting capabilities, increasing the importance of investing in them. This might involve creating very liquid prediction markets for topics of interest, finding out the equivalent of superforecasting techniques for time-series predictions, or other approaches, but this is out of scope for this piece.
Step 5: Scale up evaluations
If the infrastructure to quantify uncertain interventions exists and proves valuable, it can be scaled, potentially even automated.
There are three obvious ways to scale:
More conventional researchers: more people doing a larger number of more in-depth evaluations.
Crowdsourcing to larger communities: Have forecasters predict what the results of an evaluation would be, and expensive evaluations are only carried out some of the time (cf. amplification)
Automation: Use software to automate some of the evaluation steps, either by building workflows, pipelines, templates, etc., or by trying to use some machine learning approach, e.g., using Ought’s assistant. (cf. pedant, squiggle)
Consider hedge-funds, which have specialized teams of researchers, programmers, and traders, with each of these teamsi aided by research assistants, test engineers, and specialized software. Likewise, to lengthen their reach, current grantmakers could augment their abilities with computer assistance, delegate part of their work to junior people, or eventually just oversee automated processes.
Although I’ve mostly been talking about complex and expensive evaluations, we could also go in the other direction: have many more very cheap evaluations, about many more things. Purely automated measures (such as citation count), or crowdsourced measures (like Amazon Reviews) could also be cost-effective, because they will tend to be very cheap. For example, when developing Metaforecast, I implemented some crude 1-5 rankings of the quality of predictions. These are very imperfect, but still useful enough to be of practical use, and they could be automated.
Note that efficiency increases in evaluation might make very new approaches viable: if all actions or all politicians or the optimal career for a large number of people can be evaluated, this might expand the domains which can be optimized. If you’re a software engineer and this sounds like something you might want to build, I want to hear from you.
Conclusion
Cheap and simple estimation tools (non-additive units, or unitless evaluations, or intuitive evaluations) were fine and even unavoidable as EA was growing up. But as EA’s scope increases it makes sense to invest in more expensive and complicated tools. Longtermism especially faces a significant challenge. Before GiveWell got started, there was already a broader ecosystem around global health and development which could be built upon–not so in the case of longtermism.
Right now, it doesn't seem like there is that much of a central nervous system that is quantifying, prioritizing and exploring longtermist interventions. Open Philanthropy does commission occasional thorough birds-eye-view reports to inform their worldview, but overall the state of things could be much more quantified.
There is room for an organization that quantifies and compares large numbers of possible interventions to recommend the best ones. But before this, or before other quantification initiatives are possible, we need to build the tooling and the know-how, maybe by following the steps outlined above.
This is part of what we have been doing at the Quantified Uncertainty Research Institute. On the research side, we have my series on estimating value, as well as efforts to make forecasting more accessible. And on the programming and tooling side, we have Guesstimate, Foretold and most recently, Squiggle. If this sounds interesting to you, consider reaching out to work with us as a contractor or as a collaborator.
I believe that a rigorous evaluation framework for quantified uncertainty is well worth attempting. But it could easily be worth nothing if decision-makers don’t use these tools. If you’re currently working in grantmaking (and also if you don’t), I want to hear from you. Does this approach seem useful to you? Would you use these kinds of tools, or would you want your successors to? If not, why not? Please let me know in the comments, or reach out over email.
Acknowledgments
This post is a project by theQuantified Uncertainty Research Institute. It was written by Nuño Sempere. Thanks to Ozzie Gooen, Eli Lifland, Gavin Leech, Misha Yagudin, Michael Townsend, Michael Aird and Linch Zhang for their comments and suggestions, and to Vivian Belenky for thoughtful editing.
I’m not sure whether, e.g, OpenPhil has more hardcore expected value calculations in the background. On the one hand, it wouldn’t be all that surprising. But on the other hand, I am still pretty sure that they are missing a systematic approach. For instance, their division into focus areas is kind of inelegant from an expected utility perspective. They're also doing calculations from a much higher "birds-eye view", so even if OpenPhil has their expected utility calculations down-pat, there would still be room for their incorporation in smaller funders.
For instance, the IPCC estimates that one tonne of methane is as bad as thirty tonnes of CO2 over a hundred years, and GiveWell estimates that saving a life under 5 is equivalent to 117x doublings of yearly consumption (e.g., increasing the earning of someone who earns $200 a year to $400 a year, for 117 different people).
From forecasting, I have the intuition that irreducible uncertainty is actually relatively rare. That is, after deeply understanding a topic—or two topics in the case of comparisons—it seems relatively unlikely that they will have very similar expected values, rather than there being a clear best guess. Specifically, I'm expecting that for any given pair of interventions, reasonable credences about which is better will be more likely to fall in the 70-85% region than the 40-60% region





Thanks for laying this out. My quick take is that I'm uncertain how useful such evaluations will be in practice. I could see my reaction to them being anything between "while I won't buy the bottom-line number as best-guess estimate or only input into my decision, this evaluation overall was super useful, if only to identify the most important uncertainties regarding this grant's/project's impact" and "this all feels so brittle and speculative that I don't feel comfortable using any of the numbers, and all the qualitative insights I can clean from them were sort of obvious".
But I think it'd be very worth trying.
My best guess is to agree with you that we should be doing more evaluations of roughly the kind you suggest on the margin. (At least, say, the EAIF, which is something I can speak to from my own experience. I also have a fuzzy more general sense that it would be good for many EA orgs/people to do so, but there I have a much poorer sense of the opportunity cost and the extent to which such things might happen internally.)
FWIW if you or someone else with a track record at making the required kind of quantitative estimates wanted to do some retrospective evaluations of EAIF grants in the spirit proposed here, I'd be very likely in favor of funding this.