Last summer I was thinking about what I wanted to do after finishing grad school. While I had several career options in the back of my mind, I only had a good sense of two of them (quantitative finance and academia). It struck me that the amount of exploration I had done so far had been woefully inadequate for making a decision about how I’d spend 80,000 hours of my life. Shortly thereafter, I decided that I would take a year off to try various potential careers. I’ll be kicking off this adventure in a month; some things I might try are AI alignment theory, empirical alignment work, philosophy, forecasting, and politics.
Sometime in 2023, I plan to make a career decision. When doing so, what will I be optimizing for? The EA answer is that I should pick the career that would allow me to have the most positive impact on the world. This will be part of my calculation, but it won’t be everything. I intrinsically value enjoying my life and career – not just as a means to the end of generating impact, but for its own sake.
Many people in EA depart from me here: they see choices that do not maximize impacts as personal mistakes. Imagine a button that, if you press it, would cause you to always take the impact-maximizing action for the rest of your life, even if it entails great personal sacrifice. Many (most?) longtermist EAs I talk to say they would press this button – and I believe them. That’s not true of me; I’m partially aligned with EA values (since impact is an important consideration for me), but not fully aligned.
I like to think about this in terms of an elliptical cloud. Each point in the ellipse represents a plausible outcome of my career. The x-coordinate represents the impact I have on the world; the y-coordinate represents how good the career is according to my utility function (what I believe to be my extrapolated volition, to be more precise), which you can think of as combining an altruistic component (to the extent I care about impact) with a selfish component (to the extent that I want to prioritize my own happiness as part of my career choice).
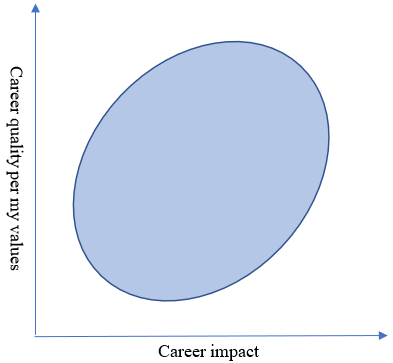
(Why an ellipse? Data drawn from a bivariate normal distribution will form an elliptical cloud. This is a simplified model in that vein; most of what I’ll be saying will also be true for other natural shape choices.)
Note that this is my personal ellipse; you have your own, and it might be shaped pretty differently from mine. If you would want to press the button in my thought experiment, then your ellipse is probably pretty close to a line.
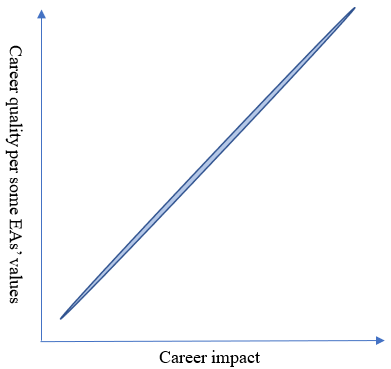
People whose ellipse looks like this are a perfect fit for the EA community. EA is geared toward giving people the resources to maximize their impact, which is exactly what some people are looking for.
On the other hand, many EAs deliberately make choices that significantly reduce their impact, and endorse these choices. For wealthy earners-to-give, giving away only 10% (or even only 50%?) of their wealth often constitutes such a choice. For some (but not all) EAs, having kids is such a choice. Such people often have ellipses that are shaped similarly to mine.
I love the EA community, but the shape of my ellipse complicates my relationship with it. My “default” career trajectory (i.e., what I probably would have done if not for exposure to the EA community) is being a professor in a non-impactful area; it might be represented by this red point.
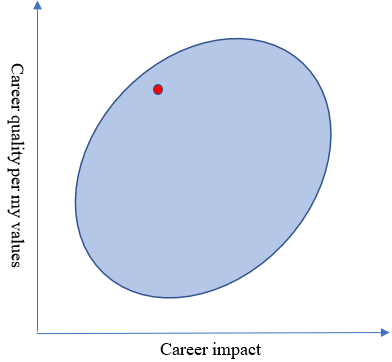
Pretty good in terms of my values – not so much in terms of impact. EA would rather I do something very different; indeed, according to EA values, the optimal place for me to be is as far to the right as possible.
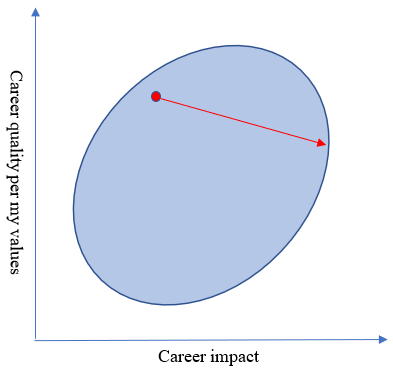
(What is this point that’s all the way to the right? It might be working on AI alignment theory, exhausting myself every day, working just at the threshold where I don’t get burned out but do a few more hours of work than I’d enjoy. Or maybe not quite this, because of secondary effects, but probably something in this direction.)
On the other hand, I’d be unhappy with this outcome. I look at this arrow and think “that arrow goes down.” That’s not what I want; I want to move up.
But observe: the best (highest) point according to my values is also to the right of the “default” red circle! This is true for a couple reasons. First, I do care about impact, even if it’s not the only consideration. Second, I really enjoy socializing and working with other EAs, more so than with any other community I’ve found. The career outcomes that are all the way up (and pretty far to the right) are ones where I do cool work at a longtermist office space, hanging out with the awesome people there during lunch and after work.[1]
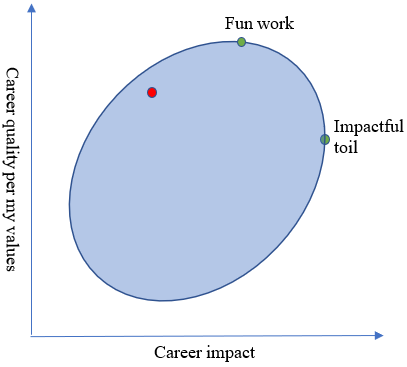
It’s natural to conceptualize this situation in terms of an implicit bargain, where my counterparty is what I might call the “EA machine”. That’s my term for the infrastructure that’s set up to nudge people into high-impact careers and provide them with the resources they need to pursue these careers. We each have something to give to the other: I can give “impact” (e.g. through AI safety research), while the EA machine can give me things that make me happy: primarily social community and good working conditions, but also things like housing, money, status, and career capital. Both the EA machine and I want my career to end up on the Pareto frontier, between the two green points. I’m only willing to accept a bargain that would allow me to attain a higher point than what I would attain by default – but besides that, anything is on the table.
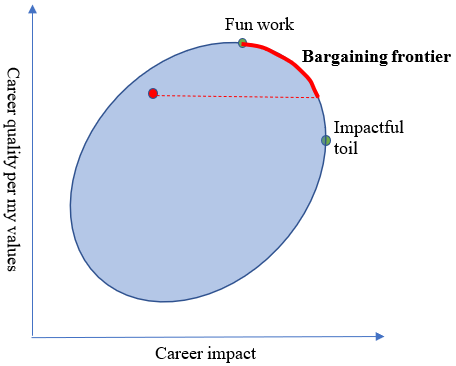
(I don’t have a full model of what exactly the bargaining looks like. A fleshed-out model might involve the EA machine expending resources to change the shape of the ellipse and then me choosing the point. But the bargaining metaphor feels appropriate to me even in the absence of a complete model.)
What’s the “fair” point along this frontier? This is an interesting question that I don’t really know how to approach, so I’ll leave it to the side.
A more pressing concern for me is: how do I make sure that I don’t end up all the way to the right, at the “impactful toil” point? The naïve answer is that I wouldn’t end up there: if offered a job that would make me much less happy, I wouldn’t take it. But I don’t think it’s that straightforward, because part of the bargain with the EA machine is that the EA machine can change your values. During my year off, I’ll be surrounded by people who care deeply about maximizing their impact, to the exclusion of everything else. People change to be more similar to the people around them, and I’m no exception.
Do I want my values changed to be more aligned with what’s good for the world? This is a hard philosophical question, but my tentative answer is: not inherently – only to the extent that it lets me do better according to my current values. This means that I should be careful – and being careful involves noticing when my values are changing. I’m not really scared of starting to value impact more, but I am scared of valuing less the things I currently care about. It seems pretty bad for me if the EA machine systematically makes things that currently bring me joy stop bringing me joy.
If you’d like, you can think about this hypothetical situation as the EA machine cutting off the top of the ellipse (thanks to Drake Thomas for this framing). If they do that, I guess I might as well move all the way to the right:
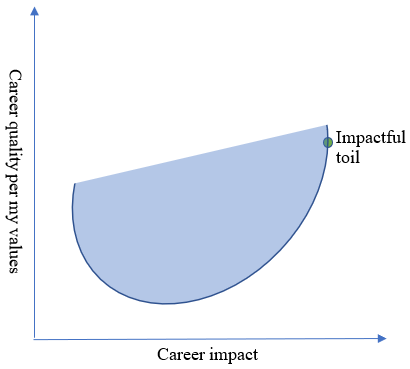
I don’t think anyone has anything like this as their goal. EAs are super nice and would be pretty sad if they discovered that becoming part of the EA community had this effect on me. But sometimes organizations of people have outcomes that no one in particular desires or intends, and to the extent that the EA machine is oriented toward the “goal” of maximizing impact, it seems plausible that mechanisms such as “cutting off the top of the ellipse” would arise, by the fault of no one in particular.
To prevent this outcome, I’ve made a list of non-EA things I currently care a lot about:
- My family and non-EA friends
- Puzzles and puzzle hunts
- Spending time in nature
- Doing random statistical analysis on things that don’t matter at all, such as marble racing
My plan is to periodically reflect on how much I care about these things – to notice if I start caring about them less. If I start caring about my family less, that’s a red flag; for the other bullet points, interests come and go, so I wouldn’t say that waning interest is a red flag. But maybe it’s a yellow flag: something to notice and reflect on.
I don’t expect the EA machine to dramatically change my values in a way that current-me wouldn’t endorse, because I’m pretty good at not being pressured into beliefs. But social pressure can be a strong force, which is why I’d like to be careful.
(What are some other plans that might be helpful? Ben Pace suggested scheduling breaks from the EA community. Duncan Sabien suggested doing occasional sanity checks with people outside the EA community that I’m not making bad decisions. Vael Gates suggested applying techniques like internal double crux or focusing to introspect about my feelings. These all seem like great suggestions, and I welcome others in the comments.)
Most top EA community builders who I talk to are surprised to learn that I wouldn’t press the button. I think I’m pretty normal in this regard, and that it’s useful for community builders to know that many EAs who can and want to do productive work have ellipses that look like mine.
The fact that such people exist may have implications for community building and EA/longtermist spaces more broadly. Concretely, in many conversations in EA circles, especially at longtermist retreats I’ve been to, there is an unstated assumption that everyone’s goal is to maximize their impact. This assumption has benefits, such as setting high expectations and creating an atmosphere in which EAs are expected to act on their moral beliefs. But it also sometimes makes me (and I imagine others) a bit uncomfortable or excluded. To the extent that EA wants to get people (including people who aren’t fully aligned) excited about working on important causes, this may be a substantial drawback. X-risk is an all-hands-on-deck issue, and EA may be well-served by being more inclusive of such people. I’m not saying that this is one of the most important ways for the EA community to improve, but I thought it might be useful to flag anyway.
Thanks to Sam Marks, Aaron Scher, Ben Pace, Drake Thomas, Duncan Sabien, and Vael Gates for thoughts and comments!
- ^
If an EA org generously pays someone who cares a lot about money to do impactful work, they are essentially creating an opportunity for the person to move up by moving to the right. I’m not super motivated by money, so this isn’t a big deal to me, but I see this as one potentially positive effect of EA having lots of money.
This is an interesting post! I agree with most of what you write. But when I saw the graph, I was suspicious. The graph is nice, but the world is not.
I tried to create a similar graph to yours:
In this case, fun work is pretty close to impactful toll. In fact, the impact value for it is only about 30% less than the impact value of impactful toll. This is definitely sizable, and creates some of the considerations above. But mostly, everywhere on the pareto frontier seems like a pretty reasonable place to be.
But there's a problem: why is the graph so nice? To be more specific: why are the x and y axes so similarly scaled?
Why doesn't it look like this?
Here I just replaced x in the ellipse equation with log(x). It seems pretty intuitive that our impact would be power law distributed, with a small number of possible careers making up the vast majority of our possible impact. A lot of the time when people are trying to maximize something it ends up power law distributed (money donated, citations for researchers, lives saved, etc.). Multiplicative processes, as Thomas Kwa alluded to, will also make something power law distributed. This doesn't really look power law distributed quite yet though. Maybe I'll take the log again:
Now, fun work is unfortunately 100x less impactful than impactful toll. That would be unfortunate. Maybe the entire pareto frontier doesn't look so good anymore.
I think this is an inherently fatal flaw with attempts to talk about trading off impact and other personal factors in making choices. If your other personal factors are your ability to have fun, have good friendships, etc., you now have to make the claim that those things are also power-law distributed, and that your best life with respect to those other values is hundreds of times better than your impact maximizing life. If you don't make that claim, then either you have to give your other values an extremely high weight compared with impact, or you have to let impact guide every decision.
In my view, the numbers for most people are probably pretty clear that impact should be the overriding factor. But I think there can be problems with thinking that way about everything. Some of those problems are instrumental: if you think impact is all that matters, you might try to do the minimum of self-care, but that's dangerous.
I think people should think in the frame of the original graph most of the time, because the graph is nice, and a reminder that you should be nice to yourself. If you had one of the other graphs in your head, you wouldn't really have any good reason to be nice to yourself that isn't arbitrary or purely instrumental.
But every so often, when you face down a new career decision with fresh eyes, it can help to remember that the world is not so nice.
Great comment, I think that's right.
I know that "give your other values an extremely high weight compared with impact" is an accurate description of how I behave in practice. I'm kind of tempted to bite that same bullet when it comes to my extrapolated volition -- but again, this would definitely be biting a bullet that doesn't taste very good (do I really endorse caring about the log of my impact?). I should think more about this, thanks!
This isn't a well thought-out argument, but something is bugging me in your claim. The real impact for your work may have some distribution, but I think the expected impact given career choices can be distributed very differently. Maybe, for example, the higher you aim, the more uncertainty you have, so your expectation doesn't grow as fast.
I find it hard to believe that in real life you face choices that are reflected much better by your graph than Eric's.
I share some of that intuition as well, but I have trouble conveying it numerically. Suppose that among realistic options that we might consider, we think ex post impact varies by 9 OOMs (as Thomas' graph implies). Wouldn't it be surprising if we have so little information that we only have <10^-9 confidence that our best choice is better than our second best choice?
I'm not very confident in my argument, but the particular scenario you describe sounds plausible to me.
Trying to imagine it in a simpler, global health setting - you could ask which of many problems to try to solve (e.g. malaria, snake bites, cancer), some of which may cause several orders of magnitude more suffering than others every year. If the solutions require things that are relatively straightforward - funding, scaling up production of something, etc. - it could be obvious which one to pick. But if the solutions require more difficult things, like research, or like solving decades-old distribution problems in Africa, then maybe the uncertainty can be strong enough to influence your decision noticeably.
This is tricky, because it's really an empirical claim for which we need empirical evidence. I don't currently have such evidence about anyone's counterfactual choices. But I think even if you zoom in on the top 10% of a skewed distribution, it's still going to be skewed. Within the top 10% (or even 1%) of researchers, nonprofits, it's likely only a small subset are making most of the impact.
I think it's true that "the higher we aim, the higher uncertainty we have" but you make it seem as if that uncertainty always washes out. I don't think it does. I think higher uncertainty often is an indicator that you might be able to make it into the tails. Consider the monetary EV of starting a really good startup or working at a tech company. A startup has more uncertainty, but that's because it creates the possibility of tail gains.
Anecdotally I think that certain choices I've made have changed the EV of my work by orders of magnitude. It's important to note that I didn't necessarily know this at the time, but I think it's true retrospectively. But I do agree it's not necessarily true in all cases.
I had similar thoughts, discussed here after I tweeted about this post and somebody replied mentioning this comment.
(Apologies for creating a circular link loop, as my tweet links to this post, which now has a comment linking to my tweet)
Fittingly, this comment is in the tail of comments I've written on the forum:
Did you plot this manually or is there a tool for this? :O
Looks to me like it was created with one of the popular R plotting libraries.
Oh sorry I was more referring to the data.
I just copied the data manually since I don't have that many comments, doesn't seem like it would be too hard to throw together a scraper for it though.
The following GraphQL query gives a score for all of your comments in JSON form[1].
The same query for Linch.
Issa Rice's post and his thoughtful design of providing raw queries from his website (mentioned in that post) are very helpful to quickly generate these queries.
Note that
userIdis trivially publicly available and should offer no utility or access.I'm confused about how to square this with specific counterexamples. Say theoretical alignment work: P(important safety progress) probably scales with time invested, but not 100x by doubling your work hours. Any explanations here?
Idk if this is because uncertainty/ probabilistic stuff muddles the log picture. E.g. we really don't know where the hits are, so many things are 'decent shots'. Maybe after we know the outcomes, the outlier good things would be quite bad on the personal-liking front. But that doesn't sound exactly correct either
Another complication: we want to select for people who are good fits for our problems, e.g. math kids, philosophy research kids, etc. To some degree, we're selecting for people with personal-fun functions that match the shape of the problems we're trying to solve (where what we'd want them to do is pretty aligned with their fun)
I think your point applies with cause selection, "intervention strategy", or decisions like "moving to Berkeley". Confused more generally
I want to point out two things that I think work in Eric's favor in a more sophisticated model like the one you described.
First, I like the model that impact follows an approximately log distribution. But I would draw a different conclusion from this.
It seems to me that there is some set of current projects, S (this includes the project of "expand S"). They have impact given by some variable that I agree is closer to log normal than normal. Now one could posit two models: one idealized model in which people know (and agree on) magnitue of impacts and a second, more realistic model, where impact is extremely uncertain, with standard deviation on the same order as the potential impact. In the idealized model, you would maximize impact by working on the most impactful project, and get comparatively much less impact by working on a random project you happen to enjoy. But in the realistic world with very large uncertainty, you would maximize expected value by working on a project on the fuzzy Pareto frontier of "potentially very impactful projects", but within this set you would prioritize projects that you have the largest competitive advantage in (which I think is also log distributed to a large extent). Presumably "how much you enjoy a subject" is correlated to "how much log advantage you have over the average person", which makes me suspicious of the severe impact/enjoyment trade-off in your second graph.
I think a strong argument against this point would be to claim that the log difference between individual affinities is much less than the log difference between impacts. I intuitively think this is likely, but the much greater knowledge people have of their comparative strengths over the (vastly uncertain) guesses about impact will counteract this. Here I would enjoy an analysis of a model of impact vs. personal competitive advantage that takes both of these things into account.
Another point, which I think is somewhat orthogonal to the discussion of "how enjoyable is the highest-impact job", and which I think is indirectly related to Eric's point, is nonlinearity of effort.
Namely, there is a certain amount of nonlinearity in how "amount of time dedicated to cause X" correlates with "contribution to X". There is some superlinearity at low levels (where at first most of your work goes into gaining domain knowledge and experience), and some sublinearity at high levels (where you run the risk of burnout as well as saturation potential if you chose a narrow topic). Because of the sublinearity at high levels, I think it makes sense for most people to have at least two "things" they do.
If you buy this I think it makes a lot of sense to make your second "cause" some version of "have fun" (or related things like "pursue personal growth for its own sake"). There are three reasons I believe this. First, this is a neglected cause: unless you're famous or rich, no one else will work on it, which means that no one else will even try to pick the low-hanging fruit. Second, it's a cause where you are an expert and, from your position, payoff is easy to measure and unambiguous. And third, if you are genuinely using a large part of your energy to have a high-impact career, being someone who has fun (and on a meta level, being a community that actively encourages people to have fun) will encourage others to be more likely to follow your career path.
I should caveat the third point: there are bad/dangerous arguments that follow similar lines, that result in people convincing themselves that they are being impactful by being hedonistic, or pursuing their favorite pet project. People are rationalizers and love coming up with stories that say "making myself happy is also the right thing to do". But while this is something to be careful of, I don't think it makes arguments of this type incorrect.
See also: Altruism as a central purpose for the converse perspective
Bravo. I think diagrams are underused as crisp explanations, and this post gives an excellent demonstration of their value (among many other merits).
A minor point (cf. ThomasWoodside's remarks): I'd be surprised if one really does (or really should) accept no trade-offs between "career quality" for "career impact". The 'isoquoise ' may not slant all the way down from status quo to impactful toil, but I think it should slant down at least a little (contrariwise, you might also be willing to trade less impact for higher QoL etc).
One motivation for having a flat line is to avoid (if the opportunity is available) feeling obliged to trade all the quality for (in)sufficiently large increases in impact. But maybe you can capture similar intuitions by using curved lines: at low levels of quality, the line is flat/almost flat, meaning you are unwilling to trade down further no matter the potential impact on the table, but at higher levels you are, so the slope is steeper at higher qualities. Maybe the 'isoquioses' would look something like this:
I appreciate 'just set a trade-off function' might be the first step down the totalising path you want to avoid, but one (more wonky than practical) dividend of such a thing is it would tell you where to go on the bargaining frontier (graphically, pick the point on the ellipse which touches the biggest isoquoise line). With the curved line story above, if you're available options all lie below the floor (~horizontal line) you basically pick the best quality option, whereas if the option frontier only has really high quality options (so the slope is very steep), you end up close to the best impact option.
This actually surprises me, but maybe I'm talking to a different subset of community builders that you are referring to - most are extremely aware of this fact, and it's a fairly common topic of discussion (e.g. not being willing to relocate for a more impactful opportunity)
If it helps clarify, the community builders are talking about are some of the Berkeley(-adjacent) longtermist ones. As some sort of signal that I'm not overstating my case here, one messaged me to say that my post helped them plug a "concept-shaped hole", a la https://slatestarcodex.com/2017/11/07/concept-shaped-holes-can-be-impossible-to-notice/
I may have misinterpreted what exactly the concept-shaped hole was. I still think I'm right about them having been surprised, though.
A perhaps-relevant concept for this discussion: Ikigai
One "classic internet essay" analyzing this phenomenon is Geeks, MOPs, and sociopaths in subculture evolution. A phrase commonly used in EA would be "keep EA weird". The point is that adding too many people like Eric would dillute EA, and make the social incentive gradients point to places we don't want them to point to.
My understanding is that this is a common desire. I'm not sure what proportion of harcore EAs vs chill people would be optimal, and I could imagine it being 100% hardcore EAs.
I guess I have two reactions. First, which of the categories are you putting me in? My guess is you want to label me as a mop, but "contribute as little as they reasonably can in exchange" seems an inaccurate description of someone who's strongly considering devoting their career to an EA cause; also I really enjoy talking about the weird "new things" that come up (like idk actually trade between universes during the long reflection).
My second thought is that while your story about social gradients is a plausible one, I have a more straightforward story about who EA should accept which I like more. My story is: EA should accept/reward people in proportion to (or rather, in a monotone increasing fashion of) how much good they do.* For a group that tries to do the most good, this pretty straightforwardly incentivizes doing good! Sure, there are secondary cultural effects to consider-- but I do think they should be thought of as secondary to doing good.
*You can also reward trying to do good to the best of each's ability. I think there's a lot of merit to this approach, but might create some not-great incentives of the form "always looking like you're trying" (regardless of whether you really are trying effectively).
I think an interesting related question is how much our social (and other incentive) gradients should prioritize people whose talents or dispositions are naturally predisposed to doing relevant EA work, versus people who are not naturally inclined for this but are morally compelled to "do what needs to be done."
I think in one sense it feels more morally praiseworthy for people to be willing to do hard work. But in another sense, it's (probably?) easier to recruit people for whom the pitch and associated sacrifices to do EA work is lower, and for a lot of current longtermist work (especially in research), having a natural inclination/aptitude/interest probably makes you a lot better at the work than grim determination
I'm curious how true this is.
I think this would work if one actually did it, but not if impact is distributed with long tails (e.g., power law) and people take offense to being accepted very little.
I don't think this is an important question, it's not like "tall people" and "short people" are a distinct cluster. There is going to be a spectrum, and you would be somewhere in the middle. But still using labels is a convenient shorthand.
So the thing that worries me is that if someone is optimizing for something different, they might reward other people for doing the same thing. The case has been on my mind recently where someone is a respected member of the community, but what they are doing is not optimal, and it would be awkward to point that out. But still necessary, even if it looses one brownie points socially.
Overall, I don't really read minds, and I don't know what you would or wouldn't do.
As usual, it would be great to see downvotes accompanied by reasons for downvoting, especially in the case of NegativeNuno's comments, since it's an account literally created to provide frank criticism with a clear disclaimer in its bio.
I think there are people (e.g. me) that value things besides impact and would also press the button because of golden-rule type reasoning. Many people optimize for impact to the point where it makes them less happy.
I would be interested in what people think qualifies as "great personal sacrifice." Some would say it would mean things like becoming a priest, volunteering for the military during a war, going to prison for something you believe in, etc. The things that many EAs do, such as giving 10% or 50%, being vegetarian or vegan, choosing a lower pay career, relocating to a less preferred city or country, choosing a somewhat less satisfying/prestigious career, or working or volunteering a total of 60 or 70 hours a week (while maintaining good sleep, nutrition, exercise and stress levels), might be described as "significant sacrifice." But maybe if an EA were doing extreme versions of many of these things, it could be considered great personal sacrifice?
Any update on where you have landed now, on the other side of this process?
Thanks for asking! The first thing I want to say is that I got lucky in the following respect. The set of possible outcomes isn't the interior of the ellipse I drew; rather, it is a bunch of points that are drawn at random from a distribution, and when you plot that cloud of points, it looks like an ellipse. The way I got lucky is: one of the draws from this distribution happened to be in the top-right corner. That draw is working at ARC theory, which has just about the most intellectually interesting work in the world (for my interests) and is also just about the most impactful place for me to work (given my skills and my models of what sort of work is impactful). I interned there for 4-5 months and I'll be starting there full-time soon!
Now for my report card, as for how well I checked in (in the ways listed in the post):
I'd say that this looks pretty good.
I do think that there are a couple of yellow flags, though:
I haven't figured out how to navigate this. These may be genuine trade-offs -- a case where I can't both work at ARC and be immune from these downsides -- or maybe I'll learn to deal with the downsides over time. I do think that the benefits of my decision to work at ARC are worth the costs for me, though.
I think there's a lot more thinking to be done about how to balance altruism and other personal goals in career choice, where – unlike donations – you have to pursue both types of goal at the same time. So I was happy to see this post!
This isn't a post about careers, it's about moral philosophy! I have been toying with a thought like this for years, but never had the wherewithal to coherently graph it. I'm glad and jealous that someone's finally done it!
No-one 'is a utilitarian' or similar, we're all just optimising for some function of at least two variables, at least one of which we can make a meaningful decision about. I genuinely think this sort of reasoning resolves a lot of problems posed by moral philosophers (eg the demandingness objection), not to mention helps map abstractions about moral philosophy to something a lot more like the real world.
I enjoyed this post and the novel framing, but I'm confused as to why you seem to want to lock in your current set of values—why is current you morally superior to future you?
Speaking for myself personally, my values have changed quite a bit in the past ten years (by choice). Ten-years-ago-me would likely be doing something much different right now, but that's not a trade that the current version of myself would want to make. In other words, it seems like in the case where you opt for 'impactful toil', that label no longer applies (it is more like 'fun work' per your updated set of values).
I think this is a great post! It addresses a lot of my discomfort with the EA point of view, while retaining the value of the approach. Commenting in the spirit of this post.
Why an ellipse? I understand why the pure EA position might be the Y=X line depicted, a line from bottom-left to top-right. But surely the opposite ought to be considered too, there must be some whose anti-EA perspective would be the Y = -X line, a diagonal from top-left to bottom right.
Yup -- that would be the limiting case of an ellipse tilted the other way!
The idea for the ellipse is that what EA values is correlated (but not perfectly) with my utility function, so (under certain modeling assumptions) the space of most likely career outcomes is an ellipse, see e.g. here.
You might also be interested in this post https://slatestarcodex.com/2018/09/25/the-tails-coming-apart-as-metaphor-for-life/
I appreciate the honesty and thoughtfulness of the post, and I think the diagram illustrates your point beautifully. I do worry, however, that thinking of human will in this diagrammatic sense understates the human ability to affect their own will. None of us act in manners that are 100% EA; this point is obvious and needs not be rationalized. All we can do is constantly strive to be more like true EAs. My psychological intuition is that this has to be a gradual, in-the-moment process, where we take EA opportunities when they come up instead of planning which opportunities we think are consistent with our will. Taking your will as a given which you then need to act around could in this way be counterproductive.
Note that the y-axis is extrapolated volition, i.e. what I endorse/strive for. Extrapolated volition can definitely change -- but I think by definition we prefer ours not to?
In that case I'm going to blame Google for defining volition as "the faculty or power of using one's will." Or maybe that does mean "endorse"? Honestly I'm very confused, feel free to ignore my original comment.