We are excited to share a summary of our 2025 strategy, which builds on our work in 2024 and provides a vision through 2027 and beyond!
Background
Giving What We Can (GWWC) is working towards a world without preventable suffering or existential risk, where everyone is able to flourish. We do this by making giving effectively and significantly a cultural norm.
Focus on pledges
Based on our last impact evaluation[1], we have made our pledges – and in particular the 🔸10% Pledge – the core focus of GWWC’s work.[2] We know the 🔸10% Pledge is a powerful institution, as we’ve seen almost 10,000 people take it and give nearly $50M USD to high-impact charities annually. We believe it could become a norm among at least the richest 1% — and likely a much wider segment of the population — which would cumulatively direct an enormous quantity of financial resources towards tackling the world’s most pressing problems.
We initiated this focus on pledges in early 2024, and are doubling down on it in 2025. In line with this, we are retiring various other initiatives we were previously running and which are not consistent with our new strategy.
Introducing our BHAG
We are setting ourselves a long-term Big Hairy Audacious Goal (BHAG) of 1 million pledgers donating $3B USD to high-impact charities annually, which we will start working towards in 2025.
1 million pledgers donating $3B USD to high-impact charities annually would be roughly equivalent to ~100x GWWC’s current scale, and could be achieved by 1% of the world’s richest 1% pledging and giving effectively. Achieving this would imply the equivalent of nearly 1 million lives being saved[3] every year.
See the BHAG FAQ for more info.
Working towards our BHAG
Over the coming years, we expect to test various growth pathways and interventions that could get us to our BHAG, including digital marketing, partnerships with aligned organisations, community advocacy, media/PR, and direct outreach to potential pledgers. We thin
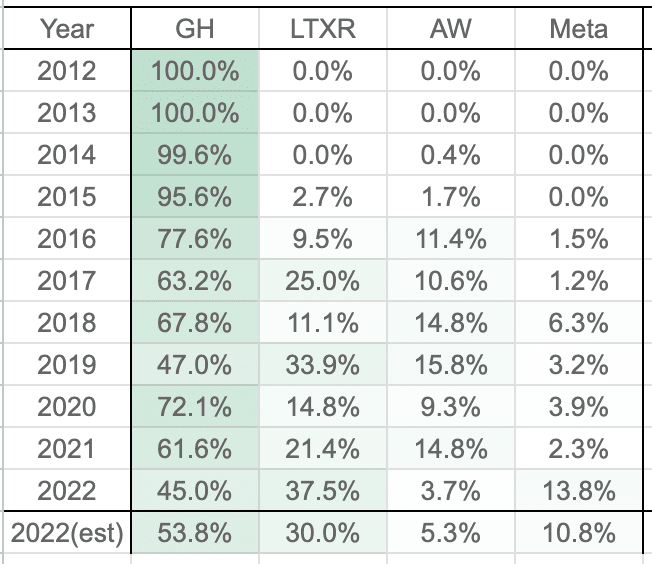



We can do that in the future too?