I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
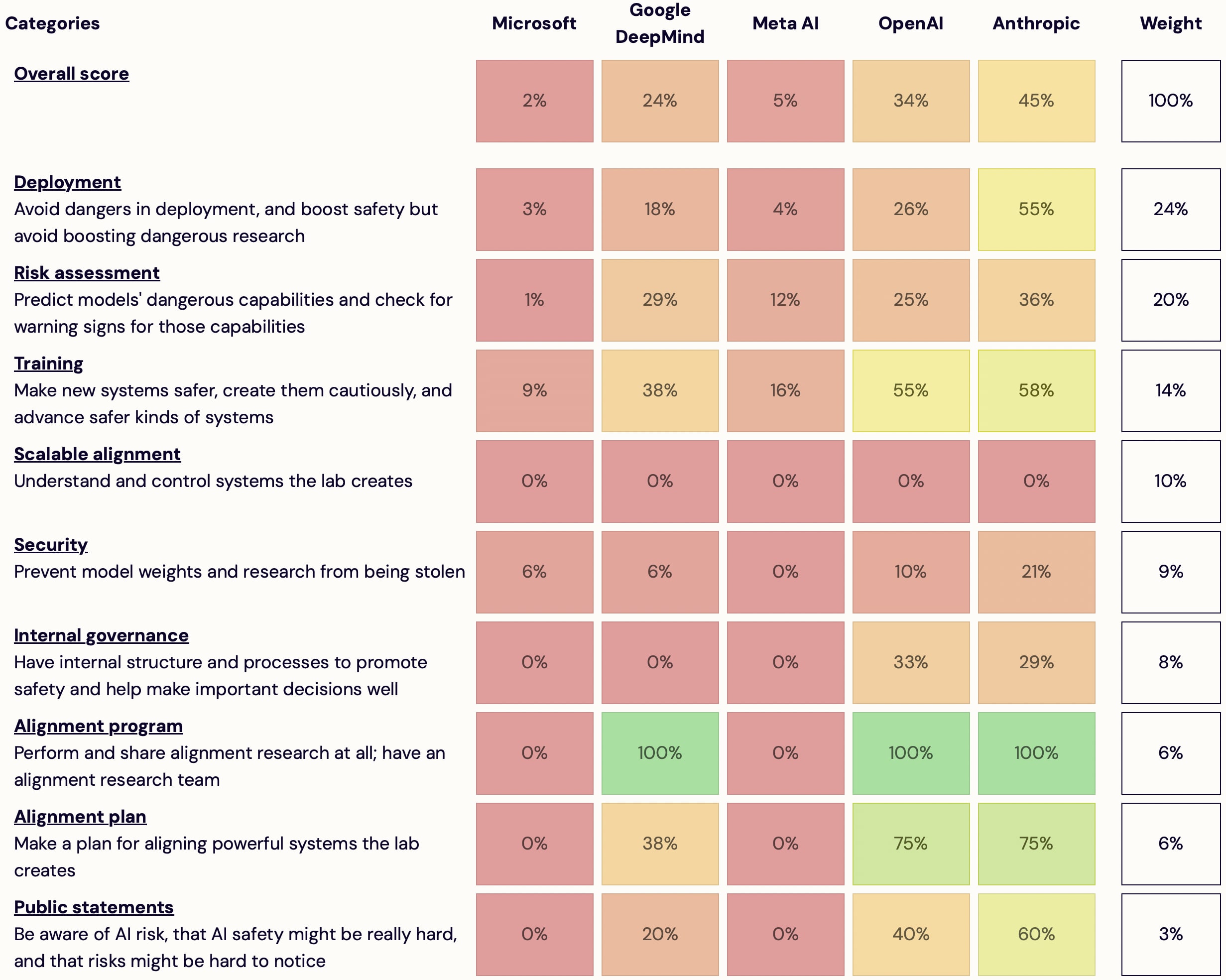
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources on what labs should do or what they are doing
- Suggest better evaluation criteria
- Share this
- Help me find an institutional home for the project
- Offer expertise on a relevant topic
- Offer to collaborate
- Volunteer your webdev skills
- (Pitch me on new projects or offer me a job)
- (Want to help and aren't sure how to? Get in touch!)
I think this project is the best existing resource for several kinds of questions, but I think it could be a lot better. I'm hoping to receive advice (and ideally collaboration) on taking it in a more specific direction. Also interested in finding an institutional home. Regardless, I plan to keep it up to date. Again, I'm interested in help but not sure what help I need.
I could expand the project (more categories, more criteria per category, more labs); I currently expect that it's more important to improve presentation stuff but I don't know how to do that; feedback will determine what I prioritize. It will also determine whether I continue spending most of my time on this or mostly drop it.
I just made a twitter account. I might use it to comment on stuff labs do.
Thanks to many friends for advice and encouragement. Thanks to Michael Keenan for doing most of the webdev. These people don't necessarily endorse this project.



Ilya is no longer on the Superalignment team?