Comments

One potential reason for the observed difference in expert and superforecaster estimates: even though they're nominally participating in the same tournament, for the experts, this is a much stranger choice than it is for the superforecasters, who presumably have already built up an identity where it makes sense to spend a ton of time and deep thought on a forecasting tournament, on top of your day job and other life commitments. I think there's some evidence for this in the dropout rates, which were 19% for the superforecasters but 51% (!) for the experts, suggesting that experts were especially likely to second-guess their decision to participate. (Also, see the discussion in Appendix 1 of the difficulties in recruiting experts - it seems like it was pretty hard to find non-superforecasters who were willing to commit to a project like this.)
So, the subset of experts who take the leap and participate in the study anyway are selected for something like "openness to unorthodox decisions/beliefs," roughly equivalent to the Big Five personality trait of openness (or other related traits). I'd guess that each participant's level of openness is a major driver (maybe even the largest driver?) of whether they accept or dismiss arguments for 21st-century x-risk, especially from AI.
Ways you could test this:
- Test the big five personality traits of all participants. My guess is that the experts would have a higher average openness than the superforcasters - but the difference would be even greater if comparing the average openness of the "AI-concerned" group (highest) to the "AI skeptics" (lowest). These personality-level differences seem to match well with the groups' object-level disagreements on AI risk, which mostly didn't center on timelines and instead centered on disagreements about whether to take the inside or outside view on AI.
- I'd also expect the "AI-concerned" to have higher neuroticism than the "AI skeptics," since I think high/low neuroticism maps closely to something like a strong global prior that the world is/isn't dangerous. This might explain the otherwise strange finding that "although the biggest area of long-run disagreement was the probability of extinction due to AI, there were surprisingly high levels of agreement on 45 shorter-run indicators when comparing forecasters most and least concerned about AI risk."
- When trying to compare the experts and superforecasters to the general population, don't rely on a poll of random people, since completing a poll is much less weird than participating in a forecasting tournament. Instead, try to recruit a third group of "normal" people who are neither experts nor superforecasters, but have a similar opportunity cost for their time, to participate in the tournament. For example, you might target faculty and PhD candidates at US universities working on non-x-risk topics. My guess is that the subset of people in this population who decide "sure, why not, I'll sign up to spend many hours of my life rigorously arguing with strangers about the end of the world" would be pretty high on openness, and thus pretty likely to predict high rates of x-risk.
I bring all this up in part because, although Appendix 1 includes a caveat that "those who signed up cannot be claimed to be a representative of [x-risk] experts in each of these fields," I don't think there was discussion of specific ways they are likely to be non-representative. I expect most people to forget about this caveat when drawing conclusions from this work, and instead conclude there must be generalizable differences between superforecaster and expert views on x-risk.
Also, I think it would be genuinely valuable to learn the extent to which personality differences do or don't drive differences in long-term x-risk assessments in such a highly analytical environment with strong incentives for accuracy. If personality differences really are a large part of the picture, it might help resolve the questions presented at the end of the abstract:
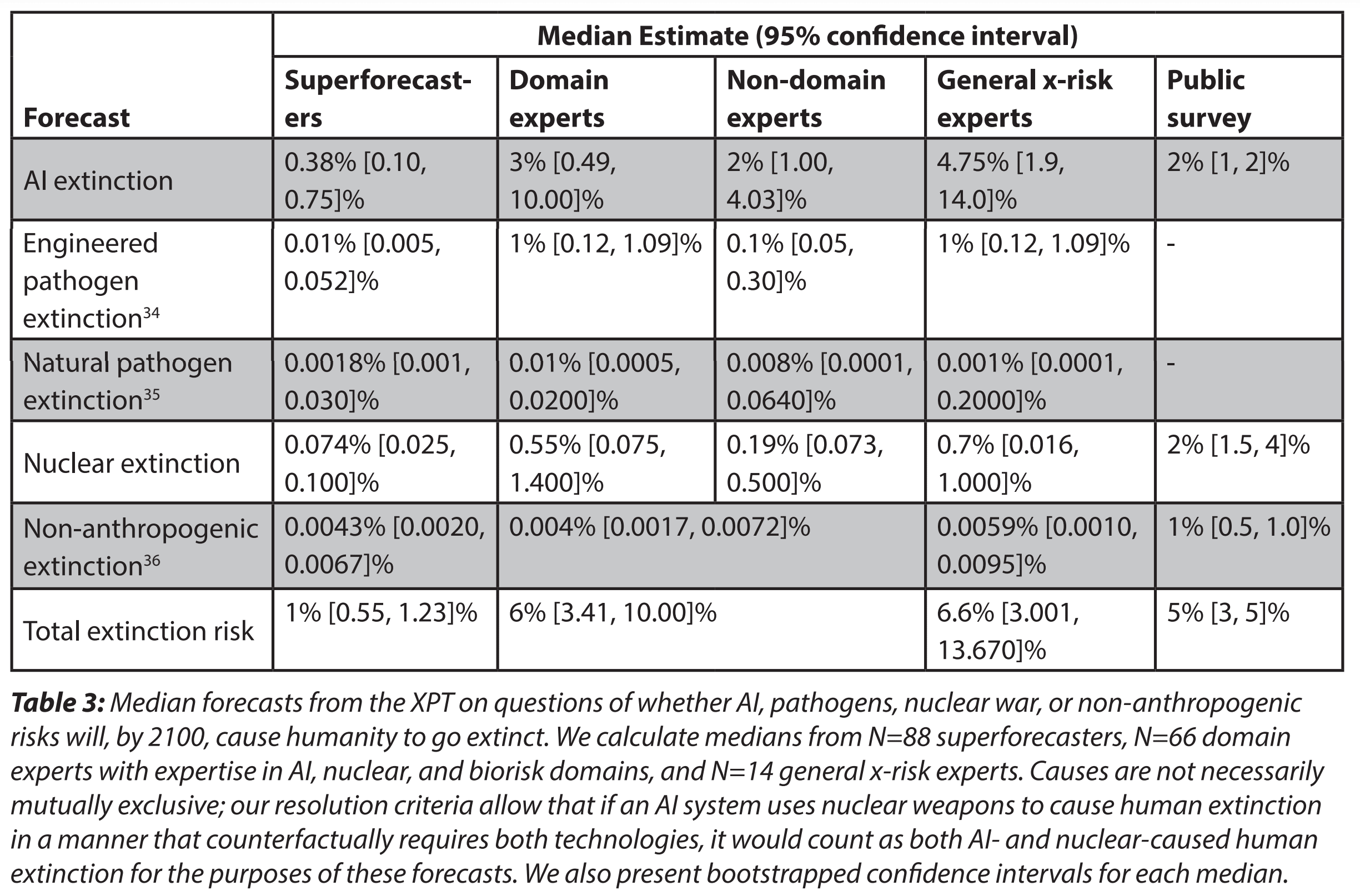
"The most pressing practical question for future work is: why were superforecasters so unmoved by experts’ much higher estimates of AI extinction risk, and why were experts so unmoved by the superforecasters’ lower estimates? The most puzzling scientific question is: why did rational forecasters, incentivized by the XPT to persuade each other, not converge after months of debate and the exchange of millions of words and thousands of forecasts?"
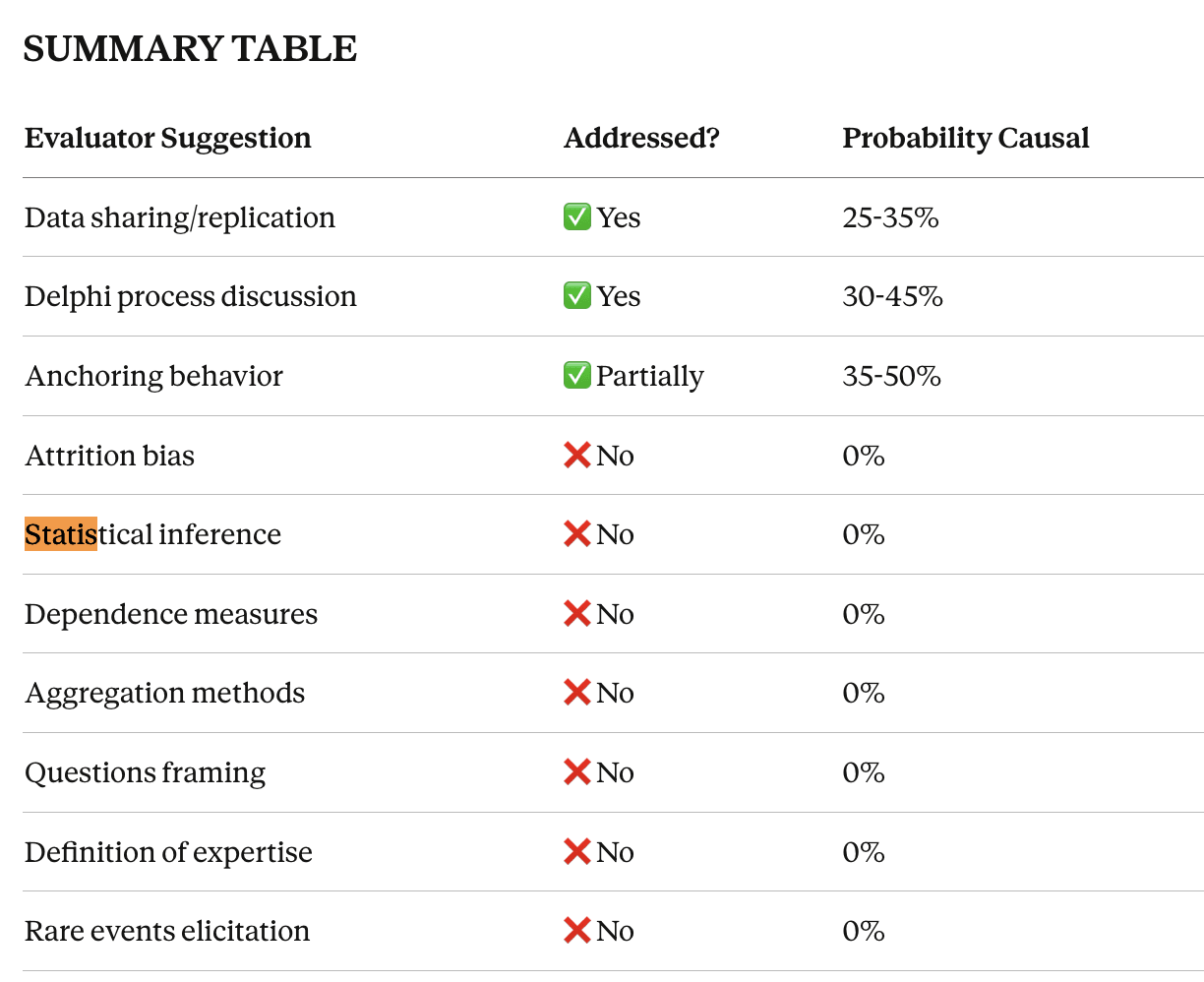



Theres a very interesting passage in here, showing that asking the public extinction questions in terms of odds rather than percentages made the estimates of risk six orders of magnitude lower:
This seems like incredibly strong evidence of anchoring bias in answers to this question, and it goes both ways (if you see percentages, you anchor to the 1-99 range). What I want to know is whether this effect would show up for superforecasters and domain experts as well. Are the high risk estimates of AI extinction merely an anchoring bias artifact?
(I'm an FRI employee, but responding here in my personal capacity.)
Yeah, in general we thought about various types of framing effects a lot in designing the tournament, but this was one we hadn't devoted much time to. I think we were all pretty surprised by the magnitude of the effect in the public survey.
Personally, I think this likely affected our normal tournament participants less than it did members of the public. Our "expert" sample mostly had considered pre-existing views on the topics, so there was less room for the elicitation of their probabilities to affect things. And superforecasters should be more fluent in probabilistic reasoning than educated members of the public, so should be less caught out by probability vs. odds.
In any case, forecasting low probabilities is very little studied, and an FRI project to remedy that is currently underway.
I agree, in that I predict that the effect would be lessened for experts and lessened still more for superforecasters.
However, that doesn't tell us how much less. A six order of magnitude discrepancy leaves a lot of room! If switching to odds only dropped superforecasters by three orders of magnitude and experts by four orders of magnitude, everything you said above would be true, but it would still make a massive difference to risk estimates. The people in EA may already have a (P|Doom) before going in, but everyone else won't. Being an AI expert does not make one immune to anchoring bias.
I think it's very important to follow up on this for domain experts. I often see "median AI expert thinks thinks there is 2% chance AI x-risk" used as evidence to take AI risk seriously, but is there an alternate universe where the factoid is "median AI expert thinks there is 1 in 50,000 odds of AI x-risk" ? We really need to find out.
Hmm, naively the anchoring bias from having many very low-probability examples would be larger than the anchoring bias from using odds vs probabilities.
Happy to make a small bet here in case FRI or others run followup studies.
I would expect the effect to persist even with minimal examples. In everyday life when, we encounter probability in terms of odds, it's in the context of low probabilities ( like the chances of winning the lottery being 1 in a million), whereas when we encounter percentage probabilities it's usually regarding events in the 5-95% probability range, like whether one party will win an election.
Just intuitively, saying there is a 0.1% chance of extinction feels like a "low" estimate, whereas saying there is a 1 in a thousand chance of extinction feels like a high estimate, even though they both refer to the exact same probability. I think there a subset of people who want to say "AI extinction is possible, but extremely unlikely", and are expressing this opinion with wildly different numbers depending on whether asked in terms of odds or percentages.
Yeah this is plausible but my intuitions go the other way. Would be interested in a replication that looks like
50% Probability a flip of a fair coin will be Tails
0.0003%: Lifetime probability of dying from lightning
0.00001%: Probability a random newborn becomes a U.S. president
vs
1 in 2: Probability a flip of a fair coin will be Tails
1 in 6: Probability a fair die will land on 5
1 in 9: Probability that in a room with 10 people, 2 of them have the same birthday.
1 in 14: Probability a randomly selected adult in America self-identifies as lesbian, gay, bisexual, or transgender
1 in 100: lifetime risk of dying from a car accident
I would also find this experiment interesting!