This is a linkpost for "Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament," accessible here: https://forecastingresearch.org/s/XPT.pdf
Today, the Forecasting Research Institute (FRI) released "Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament", which describes the results of the Existential-Risk Persuasion Tournament (XPT).
The XPT, which ran from June through October of 2022, brought together forecasters from two groups with distinctive claims to knowledge about humanity’s future — experts in various domains relevant to existential risk, and "superforecasters" with a track record of predictive accuracy over short time horizons. We asked tournament participants to predict the likelihood of global risks related to nuclear weapon use, biorisks, and AI, along with dozens of other related, shorter-run forecasts.
Some major takeaways from the XPT include:
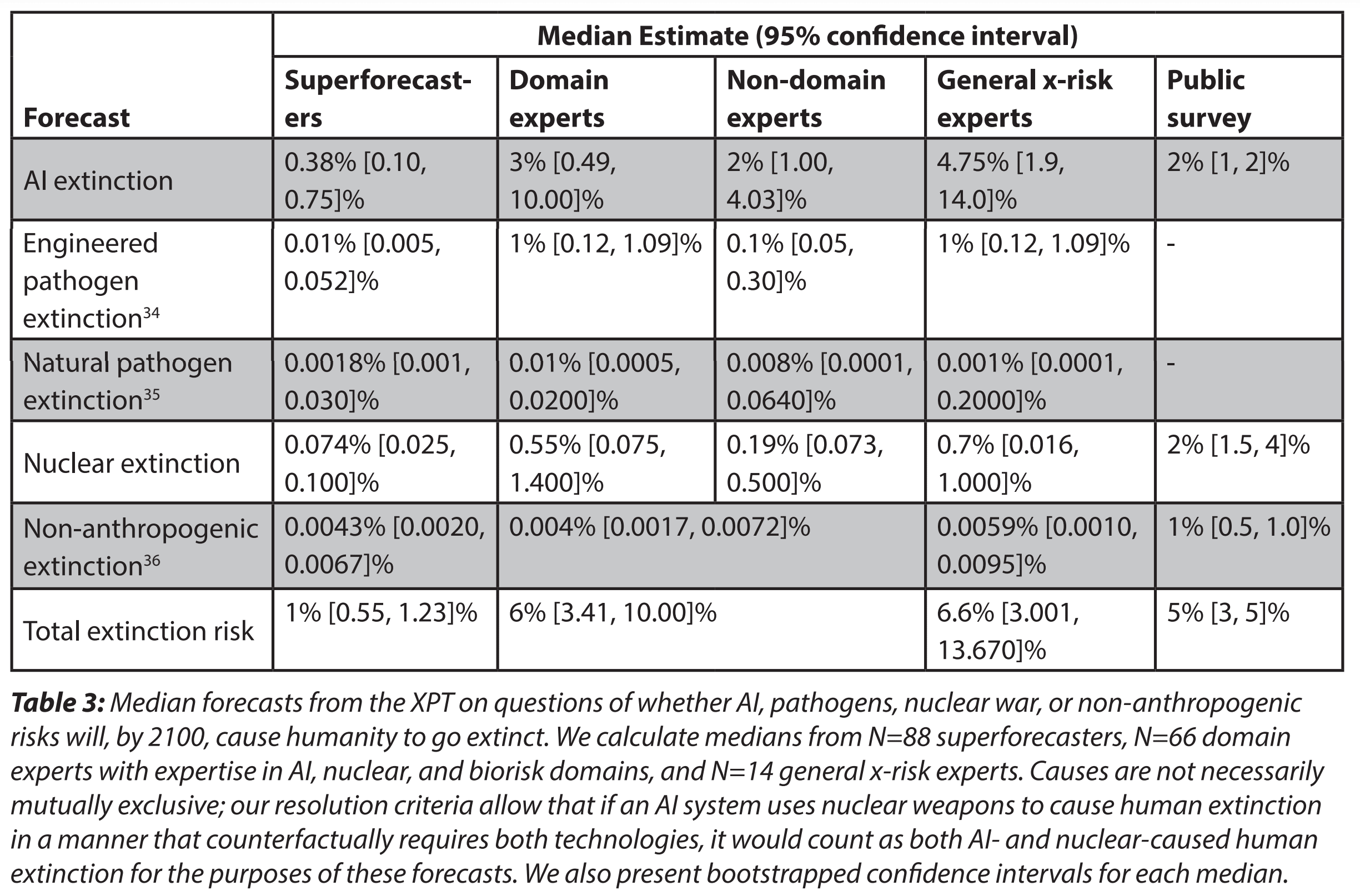
- The median domain expert predicted a 20% chance of catastrophe and a 6% chance of human extinction by 2100. The median superforecaster predicted a 9% chance of catastrophe and a 1% chance of extinction.
- Superforecasters predicted considerably lower chances of both catastrophe and extinction than did experts, but the disagreement between experts and superforecasters was not uniform across topics. Experts and superforecasters were furthest apart (in percentage point terms) on AI risk, and most similar on the risk of nuclear war.
- Predictions about risk were highly correlated across topics. For example, participants who gave higher risk estimates for AI also gave (on average) higher risk estimates for biorisks and nuclear weapon use.
- Forecasters with higher “intersubjective accuracy”—i.e., those best at predicting the views of other participants—estimated lower probabilities of catastrophic and extinction risks from all sources.
- Few minds were changed during the XPT, even among the most active participants, and despite monetary incentives for persuading others.
See the full working paper here.
FRI hopes that the XPT will not only inform our understanding of existential risks, but will also advance the science of forecasting by:
- Collecting a large set of forecasts resolving on a long timescale, in a rigorous setting. This will allow us to measure correlations between short-run (2024), medium-run (2030) and longer-run (2050) accuracy in the coming decades.
- Exploring the use of bonus payments for participants who both 1) produced persuasive rationales and 2) made accurate “intersubjective” forecasts (i.e., predictions of the predictions of other participants), which we are testing as early indicators of the reliability of long-range forecasts.
- Encouraging experts and superforecasters to interact: to share knowledge, debate, and attempt to persuade each other. We plan to explore the value of these interactions in future work.
As a follow-up to our report release, we are producing a series of posts on the EA Forum that will cover the XPT's findings on:
- AI risk (in 6 posts):
- Overview
- Details on AI risk
- Details on AI timelines
- XPT forecasts on some key AI inputs from Ajeya Cotra's biological anchors report
- XPT forecasts on some key AI inputs from Epoch's direct approach model
- Consensus on the expected shape of development of AI progress [Edited to add: We decided to cut this post from the series]
- Overview of findings on biorisk (1 post)
- Overview of findings on nuclear risk (1 post)
- Overview of findings from miscellaneous forecasting questions (1 post)
- FRI's planned next steps for this research agenda, along with a request for input on what FRI should do next (1 post)
I agree, in that I predict that the effect would be lessened for experts and lessened still more for superforecasters.
However, that doesn't tell us how much less. A six order of magnitude discrepancy leaves a lot of room! If switching to odds only dropped superforecasters by three orders of magnitude and experts by four orders of magnitude, everything you said above would be true, but it would still make a massive difference to risk estimates. The people in EA may already have a (P|Doom) before going in, but everyone else won't. Being an AI expert does not make one immune to anchoring bias.
I think it's very important to follow up on this for domain experts. I often see "median AI expert thinks thinks there is 2% chance AI x-risk" used as evidence to take AI risk seriously, but is there an alternate universe where the factoid is "median AI expert thinks there is 1 in 50,000 odds of AI x-risk" ? We really need to find out.