Cross-posted to LessWrong here.
Introduction
As in 2016, 2017 and 2018, I have attempted to review the research that has been produced by various organisations working on AI safety, to help potential donors gain a better understanding of the landscape. This is a similar role to that which GiveWell performs for global health charities, and somewhat similar to a securities analyst with regards to possible investments.
My aim is basically to judge the output of each organisation in 2019 and compare it to their budget. This should give a sense of the organisations' average cost-effectiveness. We can also compare their financial reserves to their 2019 budgets to get a sense of urgency.
I’d like to apologize in advance to everyone doing useful AI Safety work whose contributions I may have overlooked or misconstrued. As ever I am painfully aware of the various corners I have had to cut due to time constraints from my job, as well as being distracted by 1) another existential risk capital allocation project, 2) the miracle of life and 3) computer games.
How to read this document
This document is fairly extensive, and some parts (particularly the methodology section) are the same as last year, so I don’t recommend reading from start to finish. Instead, I recommend navigating to the sections of most interest to you.
If you are interested in a specific research organisation, you can use the table of contents to navigate to the appropriate section. You might then also want to Ctrl+F for the organisation acronym in case they are mentioned elsewhere as well.
If you are interested in a specific topic, I have added a tag to each paper, so you can Ctrl+F for a tag to find associated work. The tags were chosen somewhat informally so you might want to search more than one, especially as a piece might seem to fit in multiple categories.
Here are the un-scientifically-chosen hashtags:
- Agent Foundations
- AI_Theory
- Amplification
- Careers
- CIRL
- Decision_Theory
- Ethical_Theory
- Forecasting
- Introduction
- Misc
- ML_safety
- Other_Xrisk
- Overview
- Philosophy
- Politics
- RL
- Security
- Shortterm
- Strategy
New to Artificial Intelligence as an existential risk?
If you are new to the idea of General Artificial Intelligence as presenting a major risk to the survival of human value, I recommend this Vox piece by Kelsey Piper.
If you are already convinced and are interested in contributing technically, I recommend this piece by Jacob Steinheart, as unlike this document Jacob covers pre-2019 research and organises by topic, not organisation.
Research Organisations
FHI: The Future of Humanity Institute
FHI is an Oxford-based Existential Risk Research organisation founded in 2005 by Nick Bostrom. They are affiliated with Oxford University. They cover a wide variety of existential risks, including artificial intelligence, and do political outreach. Their research can be found here.
Their research is more varied than MIRI's, including strategic work, work directly addressing the value-learning problem, and corrigibility work.
In the past I have been very impressed with their work.
Research
Drexler's Reframing Superintelligence: Comprehensive AI Services as General Intelligence is a massive document arguing that superintelligent AI will be developed for individual discrete services for specific finite tasks, rather than as general-purpose agents. Basically the idea is that it makes more sense for people to develop specialised AIs, so these will happen first, and if/when we build AGI these services can help control it. To some extent this seems to match what is happening - we do have many specialised AIs - but on the other hand there are teams working directly on AGI, and often in ML 'build an ML system that does it all' ultimately does better than one featuring hand-crafted structure. While most books are full of fluff and should be blog posts, this is a super dense document - a bit like Superintelligence in this regard - and even more than most research I struggle to summarize it here - so I recommend reading it. See also Scott's comments here. It also admirably hyperlinked so one does not have to read from start to finish. #Forecasting
Aschenbrenner's Existential Risk and Economic Growth builds a model for economic growth, featuring investment in consumption and safety. As time goes on, diminishing marginal utility of consumption means that more and more is invested in safety over incremental consumption. It derives some neat results, like whether or not we almost certainly go extinct depends on whether safety investments scale faster than the risk from consumption, and that generally speeding things up is better, because if there is a temporary risky phase it gets us through it faster - whereas if risk never converges to zero we will go extinct anyway. Overall I thought this was an excellent paper. #Strategy
Carey's How useful is Quantilization for Mitigating Specification-Gaming extends and tests Taylor's previous work on using quantisation to reduce overfitting. The paper first proves some additional results and then runs some empirical tests with plausible real-life scenarios, showing that the technique does a decent job improving true performance (by avoiding excessive optimisation on the imperfect proxy). However, the fact that they sometimes underperformed the imitator baseline makes me worry that maybe the optimisation algorithms were just not well suited to the task. Overall I thought this was an excellent paper. #ML_safety
O'Keefe's Stable Agreements in Turbulent Times: A Legal Toolkit for Constrained Temporal Decision Transmission provides an introduction to the various ways current law allows contracts to be cancelled or adjusted after they have been made. For example, if subsequent circumstances have changed so dramatically that the fundamental nature of the contract has changed. The idea is that this helps promote stability by getting closer to 'what we really meant' than the literal text of the agreement. It is interesting but I am sceptical it is very helpful for AI Alignment, where forcing one group / AI that has suddenly become much more powerful to abide by their previous commitments seems like more of a challenge; post hoc re-writing of contracts seems like a recipe for the powerful to seize from the left behind. #Politics
Armstrong's Research Agenda v0.9: Synthesising a human's preferences into a utility function lays out what Stuart thinks is a promising direction for safe AGI development. To avoid the impossibility of deducing values from behaviour, we build agents with accurate models of the way human minds represent the world, and extract (partial) preferences from there. This was very interesting, and I recommend reading it in conjunction with this response from Steiner. #AI_Theory
Kenton et al.'s Generalizing from a few environments in Safety-Critical Reinforcement Learning runs an experiment on how well some ML algorithms can generalise to avoid catastrophes. This aimed to get at the risk of agents doing something catastrophic when exposed to new environments after testing. I don't really understand how it is getting at this though - the hazard (lava) is the same in train and test, and the poor catastrophe-avoidance seems to simply be the result of the weak penalty placed on it during training (-1). #ML_safety
Cihon's Standards for AI Governance: International Standards to Enable Global Coordination in AI Research & Development advocates for the inclusion of safety-related elements into international standards (like those created by the IEEE). I'm not sure I see how these are directly helpful for the long-term problem while we don't yet have a technical solution - I generally think of these sorts of standards as mandating best practices, but in this case we need to develop those best practices. #Politics
Garfinkel & Dafoe's How does the offense-defense balance scale? discuss and model the way that military effectiveness various with investment in offence and defence. They discuss a variety of conflict modes, including invasions, cyber, missiles and drones. It seems that, in their model, cyberhacking is basically the same as invasions with varying sparse defences (due to the very large number of possible zero-day 'attack beaches'. #Misc
FHI also produced several pieces of research on bioengineered pathogens which are likely of interest to many readers – for example Nelson here – but which I have not had time to read.
FHI researchers contributed to the following research led by other organisations:
- Hubinger et al.'s Risks from Learned Optimization in Advanced Machine Learning Systems
- Greaves & Cotton-Barratt's A bargaining-theoretic approach to moral uncertainty
- Snyder-Beattie et al.'s An upper bound for the background rate of human extinction
- Zhang & Dafoe's Artificial Intelligence: American Attitudes and Trends
- Evans et al.'s Machine Learning Projects for Iterated Distillation and Amplification
Finances
FHI didn’t reply to my emails about donations, and seem to be more limited by talent than by money.
If you wanted to donate to them anyway, here is the relevant web page.
CHAI: The Center for Human-Aligned AI
CHAI is a UC Berkeley based AI Safety Research organisation founded in 2016 by Stuart Russell.. They do ML-orientated safety research, especially around inverse reinforcement learning, and cover both near and long-term future issues.
As an academic organisation their members produce a very large amount of research; I have only tried to cover the most relevant below. It seems they do a better job engaging with academia than many other organisations.
Rohin Shah, now with additional help, continue to produce the AI Alignment Newsletter, covering in detail a huge number of interesting new developments, especially new papers.
They are expanding somewhat to other universities outside Berkeley.
Research
Shah et al.'s On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference argues that learning human values and biases at the same time, while impossible in theory, is actually possible in practice. Attentive readers will recall Armstrong and Mindermann's paper arguing that it is impossible to co-learn human bias and values because any behaviour is consistent with any values - if we can freely vary the biases - and vice versa. This paper basically argues that, like the No Free Lunch theorem, in practice this just doesn't matter that much, basically by assuming that the agent is close-to-optimal. (They also discuss the potential of using some guaranteed-optimal behaviour as ground truth, but I am sceptical this would work, as I think humans are often at their most irrational when it comes to the most important topics, e.g. love). Empirically, in their gridworld tests their agent did a decent job learning - for reasons I didn't really understand. Overall I thought this was an excellent paper. #CIRL
Turner et al.'s Conservative Agency attempts to prevent agents from doing irreversible damage by making them consider a portfolio of randomly generated utility functions - for which irreversible damage is probably bad for at least one of them. Notably, this portfolio did *not* include the true utility function. I find the result a little hard to understand - I initially assumed they were relying on clustering of plausible utility functions, but it seems that they actually sampled at random from the entire space of possible functions! I don't really understand how they avoid Armstrong + Mindermann type problems, but apparently they did! It seems like this line of attack pushes us towards Universal Drives, as something many utility functions will have in common. Overall I thought this was an excellent paper. #ML_safety
Carroll et al.'s On the Utility of Learning about Humans for Human-AI Coordination discusses the differences between competitive versus collaborative learning. If you just want to be really good at a competitive game, self-play is great, because you get better by playing better and better versions of yourself. However, if you have to collaborate with a human this is bad because your training doesn't feature flawed partners (in the limit) and min-maxing doesn't work. They do an experiment showing that an agent taught about how humans act does better than one which learnt collaborating with itself. This seems useful if you think that CIRL/amplification approaches will be valuable, and also promotes teaching AIs to understand human values. There is also a blog post here #CIRL
Chan et al.'s The Assistive Multi-Armed Bandit attempts to do value learning with humans who are themselves value learning. They do this by having the agent sometimes 'intercept' on a multi-armed bandit problem, and show that this sometimes improves performance if the agent understands how the human is learning. #CIRL
Russell's Human Compatible; Artificial Intelligence and the Problem of Control is an introductory book aimed at the intelligent layman. As befits the author, it begins with a lot of good framing around intelligence and agency. The writing style is good. #Overview
Shah et al.'s Preferences Implicit in the State of the World attempts to use the fact that human environments are already semi-optimised to extract additional evidence about human preferences. Practically, this basically means simulating many paths the humans could have taken prior to t=0 and using these as evidence as to the human's values. The core of the paper is a good insight - "it is easy to forget these preferences, since these preferences are already satisfied in our environment." #CIRL
CHAI researchers contributed to the following research led by other organisations:
- Agrawal et al.'s Scaling up Psychology via Scientific Regret Minimization:A Case Study in Moral Decision-Making
Finances
They have been funded by various EA organisations including the Open Philanthropy Project and recommended by the Founders Pledge.
They spent $1,450,000 in 2018 and $2,000,000 in 2019, and plan to spend around $2,150,000 in 2020. They have around $4650000 in cash and pledged funding, suggesting (on a very naïve calculation) around 2.2 years of runway.
If you wanted to donate to them, here is the relevant web page.
MIRI: The Machine Intelligence Research Institute
MIRI is a Berkeley based independent AI Safety Research organisation founded in 2000 by Eliezer Yudkowsky and currently led by Nate Soares. They were responsible for much of the early movement building for the issue, but have refocused to concentrate on research for the last few years. With a fairly large budget now, they are the largest pure-play AI alignment shop. Their research can be found here. Their annual summary can be found here.
In general they do very ‘pure’ mathematical work, in comparison to other organisations with more ‘applied’ ML or strategy focuses. I think this is especially notable because of the irreplaceability of the work. It seems quite plausible that some issues in AI safety will arise early on and in a relatively benign form for non-safety-orientated AI ventures (like autonomous cars or Minecraft helpers) – however the work MIRI does largely does not fall into this category. I have also historically been impressed with their research.
Their agent foundations work is basically trying to develop the correct way of thinking about agents and learning/decision making by spotting areas where our current models fail and seeking to improve them. This includes things like thinking about agents creating other agents.
In their annual write-up they suggest that progress was slower than expected in 2019. However I assign little weight to this as I think most of the cross-sectional variation in organisation reported subjective effectiveness comes from variance in how optimistic/salesy/aggressive they are, rather than actually indicating much about object-level effectiveness.
MIRI, in collaboration with CFAR, runs a series of four-day workshop/camps, the AI Risk for Computer Scientists workshops, which gather mathematicians/computer scientists who are potentially interested in the issue in one place to learn and interact. This sort of workshop seems very valuable to me as an on-ramp for technically talented researchers, which is one of the major bottlenecks in my mind. In particular they have led to hires for MIRI and other AI Risk organisations in the past. I don’t have any first-hand experience however.
They also support MIRIx workshops around the world, for people to come together to discuss and hopefully contribute towards MIRI-style work.
Research
Hubinger et al.'s Risks from Learned Optimization in Advanced Machine Learning Systems introduces the idea of a Mesa-Optimizer - a sub-agent of an optimizer that is itself an optimizer. A vague hand-wave of an example might be for-profit corporations rewarding their subsidiaries based on segment PnL, or indeed evolution creating humans, which then go on to create AI. Necessarily theoretical, the paper motivates the idea, introduces a lot of terminology, and describes conditions that might make mesa-optimisers more or less likely - for example, more diverse environments make mesa-optimisation more likely. In particular, they distinguish between different forms of mis-alignment - e.g. between meta, object-level and mesa, vs between mesa and behavioural objectives. There is a sequence on the forum about it here. Overall I thought this was an excellent paper. Researchers from FHI, OpenAI were also named authors on the paper. #Agent Foundations
Kosoy's Delegative Reinforcement Learning: Learning to Avoid Traps with a Little Help produces an algorithm that deviates only boundedly from optimal with a human intervening to prevent it stumbling into irrevocably bad actions. The idea is basically that the human intervenes to prevent the really bad actions, but because the human has some chance of selecting the optimal action afterwards, the loss of exploration value is limited. This attempts to avoid the problem that 'ideal intelligence' AIXI has whereby it might drop an anvil on its head. I found the proof a bit hard to follow, so I'm not sure how tight the bound is in practice. Notably, this doesn't protect us if the agent tries to prevent the human from intervening. Related. #ML_safety
There were two analyses of FDT from academic philosophers this year (reviewed elsewhere in this document). In both cases I felt their criticisms rather missed the mark, which is a positive for the MIRI approach. However, they did convincingly argue that MIRI researchers hadn’t properly understood the academic work they were critiquing, an isolation which has probably gotten worse with MIRI’s current secrecy. MIRI suggested I point out that Cheating Death In Damascus had recently been accepted in The Journal of Philosophy, a top philosophy journal, as evidence of (hopefully!) mainstream philosophical engagement.
MIRI researchers contributed to the following research led by other organisations:
- Macaskill & Demski's A Critique of Functional Decision Theory
Non-disclosure policy
Last year MIRI announced their policy of nondisclosure-by-default:
[G]oing forward, most results discovered within MIRI will remain internal-only unless there is an explicit decision to release those results, based usually on a specific anticipated safety upside from their release.
I wrote about this at length last year, and my opinion hasn’t changed significantly since then, so I will just recap briefly.
On the positive side we do not want people to be pressured into premature disclosure for the sake of funding. This space is sufficiently full of infohazards that secrecy might be necessary, and in its absence researchers might prudently shy away from working on potentially risky things - in the same way that no-one in business sends sensitive information over email any more. MIRI are in exactly the sort of situation that you would expect might give rise to the need for extreme secrecy. If secret research is a necessary step en route to saving the world, it will have to be done by someone, and it is not clear there is anyone very much better.
On the other hand, I don’t think we can give people money just because they say they are doing good things, because of the risk of abuse. There are many other reasons for not publishing anything. Some simple alternative hypothesis include “we failed to produce anything publishable” or “it is fun to fool ourselves into thinking we have exciting secrets” or “we are doing bad things and don’t want to get caught.” The fact that MIRI’s researchers appear intelligent suggest they at least think they are doing important and interesting issues, but history has many examples of talented reclusive teams spending years working on pointless stuff in splendid isolation.
Additionally, by hiding the highest quality work we risk impoverishing the field, making it look unproductive and unattractive to potential new researchers.
One possible solution would be for the research to be done by impeccably deontologically moral people, whose moral code you understand and trust. Unfortunately I do not think this is the case with MIRI. (I also don’t think it is the case with many other organisations, so this is not a specific criticism of MIRI, except insomuch as you might have held them to a higher standard than others).
Finances
They spent $3,750,000 in 2018 and $6,000,000 in 2019, and plan to spend around $6,800,000 in 2020. They have around $9,350,000 in cash and pledged funding, suggesting (on a very naïve calculation) around 1.4 years of runway.
They have been supported by a variety of EA groups in the past, including OpenPhil
If you wanted to donate to MIRI, here is the relevant web page.
GCRI: The Global Catastrophic Risks Institute
GCRI is a globally-based independent Existential Risk Research organisation founded in 2011 by Seth Baum and Tony Barrett. They cover a wide variety of existential risks, including artificial intelligence, and do policy outreach to governments and other entities. Their research can be found here. Their annual summary can be found here.
In 2019 they ran an advising program where they gave guidance to people from around the world who wanted to help work on catastrophic risks.
In the past I have praised them for producing a remarkably large volume of research; this slowed down somewhat during 2019 despite taking on a second full-time staff member, which they attributed partly to timing issues (e.g. pieces due to be released soon), and partly to focusing on quality over quantity.
Research
Baum et al.'s Lessons for Artificial Intelligence from Other Global Risks analogises AI risk to several other global risks: biotech, nukes, global warming and asteroids. In each case it discusses how action around the risk progressed, in particular the role of gaining expert consensus and navigating vested interests. #Strategy
Baum's The Challenge of Analyzing Global Catastrophic Risks introduces the idea of catastrophic risks and discusses some general issues. It argues for the need to quantify various risks, and ways to present these to policymakers. #Other_Xrisk
Baum's Risk-Risk Tradeoff Analysis of Nuclear Explosives for Asteroid Deflection discusses how to compare the protection from asteroids that nukes offer vs their potential to exacerbate war. #Other_Xrisk
Finances
During December 2018 they received a $250,000 donation from Gordon Irlam.
They spent $140,000 in 2018 and $250,000 in 2019, and plan to spend around $250,000 in 2020. They have around $310,000 in cash and pledged funding, suggesting (on a very naïve calculation) around 1.2 years of runway.
If you want to donate to GCRI, here is the relevant web page.
CSER: The Center for the Study of Existential Risk
CSER is a Cambridge based Existential Risk Research organisation founded in 2012 by Jaan Tallinn, Martin Rees and Huw Price, and then established by Seán Ó hÉigeartaigh with the first hire in 2015. They are currently lead by Catherine Rhodes and are affiliated with Cambridge University. They cover a wide variety of existential risks, including artificial intelligence, and do political outreach. Their research can be found here. Their annual summary can be found here and here.
CSER also participated in a lot of different outreach events, including to the UK parliament and by hosting various workshops, as well as submitting (along with other orgs) to the EU’s consultation, as summarised in this post. I’m not sure how to judge the value of these.
CSER’s researchers seem to select a somewhat widely ranging group of research topics, which I worry may reduce their effectiveness.
Catherine Rhodes co-edited a volume of papers on existential risks, including many by other groups mentioned in this review.
Research
Kaczmarek & Beard's Human Extinction and Our Obligations to the Past presents an argument that even people who hold person-affecting views should think extinction is bad because it undermines the sacrifices of our ancestors. My guess is that most readers are not in need of persuading that extinction is bad, but I thought this was an interesting additional argument. The core idea is that if someone makes a large sacrifice to enable some good, we have a pro tanto reason not to squander that sacrifice. I'm not sure how many people will be persuaded by this idea, but as a piece of philosophy I thought this was a clever idea, and it is definitely good to promote the idea that past generations have value (speaking as a future member of a past generation). Carl Shulman also offered related arguments here. #Philosophy
Beard's Perfectionism and the Repugnant Conclusion argues against one supposed rejection of the Repugnant Conclusion, namely that some goods are lexicographically superior to ordinary welfare. The paper makes the clever argument that the very large, barely-worth-living group might actually have more of these goods if they were offset by (lexicographically secondary) negative welfare. It was also the first time (to my recollection) that I've come across the Ridiculous Conclusion. #Philosophy
Avin's Exploring Artificial Intelligence Futures lists and discusses different ways of introducing people to the future of AI. These include fiction, games, expert analysis, polling and workshops. He also provides various pros and cons of the different techniques, which seemed generally accurate to me. #Strategy
Belfield's How to respond to the potential malicious uses of artificial intelligence? introduces AI and AI risk. This short article focuses mainly on short-term risks. #Introduction
Weitzdörfer & Beard's Law and Policy Responses to Disaster-Induced Financial Distress discusses the problem of indebtedness following the destruction of collateral in the 2011 earthquake in Japan. They explain the specifics of the situation in extreme detail, and I was pleasantly surprised by their final recommendations, which mainly concerned removing barriers to insurance penetration. #Politics
Kemp's Mediation Without Measures: Conflict Resolution in Climate Diplomacy discusses the lack of formal decision-making procedure for international climate change treaties. Unfortunately I wasn't able to access the article. #Other_Xrisk
Avin & Amadae's Autonomy and machine learning at the interface of nuclear weapons, computers and people discusses the potential dangers of incorporating narrow AI into nuclear weapon systems. #Shortterm
CSER's Policy series Managing global catastrophic risks: Part 1 Understand introduces the idea of Xrisk for policymakers. This is the first report in a series, and as such is quite introductory. It mainly focuses on non-AI risks. #Politics
Tzachor's The Future of Feed: Integrating Technologies to Decouple Feed Production from Environmental Impacts discusses a new technology for producing animal feedstock to replace soybeans. This could be Xrisk relevant if some non-AI risk made it hard to feed animals. However, I am somewhat sceptical of the presentation of this as a *likely* risk as both a future shortage of soybeans and a dramatically more efficient technology for feeding livestock would both presumably be of interest to private actors, and show up in soybean future prices. #Other_Xrisk
Beard's What Is Unfair about Unequal Brute Luck? An Intergenerational Puzzle discusses Luck Egalitarianism. #Philosophy
Quigley's Universal Ownership in the Anthropocene argues that because investors own diversified portfolios they effectively internalise externalities, and hence should push for various political changes. The idea is basically that even though polluting might be in a company's best interest, it hurts the other companies the investor owns, so it is overall against the best interests of the investor. As such, investors should push companies to pollute less and so on. The paper seems to basically assume that such 'universal investors' would be incentivised to support left-wing policies on a wide variety of issues. However, it somehow fails to mention even cursorily the fact that the core issue has been well studied by economists: when all the companies in an industry try to coordinate for mutual benefit, it is called a cartel, and the #1 way of achieving mutual benefit is raising prices to near-monopoly levels. It would be extremely surprising to me if someone, acting as a self-interested owner of all the world's shoe companies (for example) found it more profitable to protect biodiversity than to raise the price of shoes. Fortunately, in practice universal investors are quite supportive of competition. #Other_Xrisk
CSER researchers contributed to the following research led by other organisations:
- Colvin et al.'s Learning from the Climate Change Debate to Avoid Polarisation on Negative Emissions
- Hernandez-Orallo et al.'s Surveying Safety-relevant AI Characteristics
- Cave & Ó hÉigeartaigh's Bridging near- and long-term concerns about AI
- Lewis et al.'s Assessing contributions of major emitters' Paris‐era decisions to future temperature extremes
Finances
They spent £789,000 in 2017-2018 and £801,000 in 2018-2019, and plan to spend around £1,100,000 in 2019-20 and £880,000 in 2020-21. It seems that similar to GPI maybe ‘runway’ is not that meaningful - they suggested it begins to decline from early 2021 and all their current grants end by mid-2024.
If you want to donate to them, here is the relevant web page.
Ought
Ought is a San Francisco based independent AI Safety Research organisation founded in 2018 by Andreas Stuhlmüller. They research methods of breaking up complex, hard-to-verify tasks into simple, easy-to-verify tasks - to ultimately allow us effective oversight over AIs. This includes building computer systems and recruiting test subjects. I think of them as basically testing Paul Christiano's ideas. Their research can be found here. Their annual summary can be found here.
Last year they were focused on factored generation – trying to break down questions so that distributed teams could produce the answer. They have moved on to factored evaluation – using similar distributed ideas to try to evaluate existing answers, which seems a significantly easier task (by analogy to P<=NP). It seems to my non-expert eye that factored generation did not work as well as they expected – they mention the required trees being extremely large, and my experience is that organising volunteers and getting them to actually do what they said they would has historically been a great struggle for many organisations. However I don’t think we should hold negative results in investigations against organisations; negative results are valuable, and it might be the case that all progress in this difficult domain comes from ex ante longshots. If nothing else, even if Paul is totally wrong about the whole idea it would be useful to discover this sooner rather than later!
They provided an interesting example of what their work looks like in practice here, and a detailed presentation on their work here.
They also worked on using ML, rather than humans, as the agent who answered the broken-down questions, in this case by using GPT-2, which seems like a clever idea.
Paul Christiano wrote a post advocating donating to them here.
Research
Evans et al.'s Machine Learning Projects for Iterated Distillation and Amplification provides three potential research projects for people who want to work on Amplification, as well as an introduction to Amplification. The projects are mathematical decomposition (which seems very natural), decomposition computer programs (similar to how all programs can be decomposed into logic gates, although I don't really understand this one) and adaptive computation, where you figure out how much computation to dedicate to different issues. In general I like outlining these sorts of 'shovel-ready' projects, as it makes it easier for new researchers, and seems relatively under-appreciated. Researchers from FHI were also named authors on the paper. #Amplification
Roy's AI Safety Open Problems provides a list of lists of 'shovel-ready' projects for people to work on. If you like X (which I do in this case), meta-X is surely even better! #Ought
Finances
They spent $500,000 in 2018 and $1,000,000 in 2019, and plan to spend around $2,500,000 in 2020. They have around $1,800,000 in cash and pledged funding, suggesting (on a very naïve calculation) around 0.7 years of runway.
They have received funding from a variety of EA sources, including the Open Philanthropy Project.
OpenAI
OpenAI is a San Francisco based independent AI Research organisation founded in 2015 by Sam Altman. They are one of the leading AGI research shops, with a significant focus on safety.
Earlier this year they announced GPT 2, a language model that was much better at ‘understanding’ human text than previous attempts, that was notably good at generating text that seemed human-generated - good enough that it was indistinguishable to humans who weren’t concentrating. This was especially notable because OpenAI chose not to immediately release GPT 2 due to the potential for abuse. I thought this was a noble effort to start conversations among ML researchers about release norms, though my impression is that many thought OpenAI was just grandstanding, and I personally was sceptical of the harm potential - though a GPT 2 based intelligence did go on to almost take over LW, proving that the ‘being a good LW commenter’ is a hard goal. Outside researchers were able to (partly?) replicate it, but in a surprisingly heartening turn of events were persuaded not to release their reconstruction by researchers from OpenAI and MIRI. OpenAI eventually released a much larger version of their system - you can see it and read their follow-up report on the controlled release process here.
You can play with (one version of) the model here.
Research
Clark & Hadfield's Regulatory Markets for AI Safety suggests a model for the privatisation of AI regulation. Basically the idea is that governments will contract with and set outcomes for a small number of private regulators, which will then devise specific rules that need to be observed by ML shops. This allows the ex-ante regulation to be more nimble than if it was done publicly, while retaining the ex-post outcome guarantees. It reminded me of the system of auditors for public companies to ensure accounting accuracy) or David Friedman's work on polycentric law. I can certainly see why private companies might be more effective as regulators than government bodies. However, I'm not sure how useful this would be in an AGI scenario, where the goals and ex-post measurement for the private regulators are likely to become outdated and irrelevant. I'm also sceptical that governments would be willing to progressively give up regulatory powers; I suspect that if this system was to be adopted it would have to pre-empt government regulation. #Politics
Christiano's What failure looks like provides two scenarios that Paul thinks represent reasonably likely outcomes of Alignment going wrong. Notably neither exactly match the classic recursively self-improving FOOM case. The first is basically that we develop better and better optimisation techniques, but due to our inability to correctly specify what we want, we end up with worse and worse Goodheart's Law situations, ending up in Red-Queen style Moloch scenario. The second is that we create algorithms that try to increase their influence (as per the fundamental drives). At first they do so secretly, but eventually (likely in response to some form of catastrophe reducing humanity's capability to suppress them) their strategy abruptly changes towards world domination. I thought this was an insightful post, and recommend readers also read the comments by Dai and Shulman, as well as this post. #Forecasting
Christiano's AI alignment landscape is a talk Paul gave at EA Global giving an overview of the issue. It is interesting both for seeing how he maps out all the different components of the problem and which he thinks are tractable and important, and also for how his Amplification approach falls out from this. #Overview
Irving & Askell's AI Safety Needs Social Scientists raise the issue of AI alignment requiring better understanding of humans as well as ML knowledge. Because humans are biased, etc., the more accurate our model of human preferences the better we can design AIs to align with it. It is quite focused on Amplification as a way of making human preferences more legible. I thought the article could have been improved with more actionable research projects for social scientists. Additionally, the article makes the need for social scientists seem somewhat tired to a Debate-style approach, whereas it seems to me potentially more broad. #Strategy
OpenAI Researchers also contributed to the following papers lead by other organisations:
Finances
OpenAI was initially funded with money from Elon Musk as a not-for-profit. They have since created an unusual corporate structure including a for-profit entity, in which Microsoft is investing a billion dollars.
Given the strong funding situation at OpenAI, as well as their safety team’s position within the larger organisations, I think it would be difficult for individual donations to appreciably support their work. However it could be an excellent place to apply to work.
Google Deepmind
Deepmind is a London based AI Research organisation founded in 2010 by Demis Hassabis, Shane Legg and Mustafa Suleyman and currently lead by Demis Hassabis. They are affiliated with Google. As well as being arguably the most advanced AI research shop in the world, Deepmind has a very sophisticated AI Safety team, covering both ML safety and AGI safety.
This year Deepmind build an agent that could beat humans at Starcraft II. This is impressive because it is a complex, incomplete information game that humans are very competitive at. However, the AI did have some advantages over humans by having direct API access.
Research
Everitt & Hutter's Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective discusses the problem of agents wireheading in an RL setting, along with several possible solutions. They use causal influence diagrams to highlight the difference between 'good' ways for agents to increase their reward function and 'bad' ways, and have a nice toy gridworld example. The solutions they discuss seemed to me to often be fairly standard ideas from the AI safety community - thinks like teaching the AI to maximise the goal instantiated by its reward function at the start, rather than whatever happens to be in that box later, or using indifference results - but they introduce them to an RL setting, and the paper does a good job covering a lot of ground. There is more discussion of the paper here. Overall I thought this was an excellent paper. #RL
Everitt et al.'s Modeling AGI Safety Frameworks with Causal Influence Diagrams introduces the idea of using Causal Influence Diagrams to clarify thinking around AI safety proposals and make it easier to compare proposals with different conceptual backgrounds in a standard way. They introduce the idea, and show how to represent ideas like RL, CIRL, Counterfactual Oracles and Debate. Causal Influence Diagrams have been used in several other papers this year, like Categorizing Wireheading in Partially Embedded Agents. #AI_Theory
Everitt et al.'s Understanding Agent Incentives using Causal Influence Diagrams. Part I: Single Action Settings discusses using causal influence diagrams to distinguish things agents want to observe vs things they want to control. They use this to show the safety improvement from counterfactual oracles. It also presents a natural link between near-term and long-term safety concerns. #AI_Theory
Sutton's The Bitter Lesson argues that history suggests massive amounts of computer and relatively general structures perform better than human-designed specialised systems. He uses examples like the history of vision and chess, and it seems fairly persuasive, though I wonder a little if these are cherry-picked - e.g. in finance we generally do have to make considerable use of human-comprehensible features. This is not directly an AI safety paper, but it does have clear implications. #Forecasting
Uesato et al.'s Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures attempt to make it easier to find catastrophic failure cases. They do this adversarially with previous versions of the algorithm, based on the idea that it is cheaper to find disasters there, but they will be related to the failure modes of the later instantiations. This seems like an interesting idea, but seems like it would struggle with cases where increasing agent capabilities lead to new failure modes - e.g. the Treacherous Turn we are worried about. #ML_safety
Ngo's Technical AGI safety research outside AI provides a list of technically useful topics for people who are not ML researchers to work on. The topics selected look good - many similar to work AIImpacts or Ought do. I think lists like this are very useful for opening the field up to new researchers. #Overview
Researchers from Deepmind were also named on the following papers:
Finances
Being part of Google, I think it would be difficult for individual donors to directly support their work. However it could be an excellent place to apply to work.
AI Safety camp
AISC is an internationally based independent residential research camp organisation founded in 2018 by Linda Linsefors and currently lead by Colin Bested. They bring together people who want to start doing technical AI research, hosting a 10-day camp aiming to produce publishable research. Their research can be found here.
To the extent they can provide an on-ramp to get more technically proficient researchers into the field I think this is potentially very valuable. But I obviously haven’t personally experienced the camps, or even spoken to anyone who has.
Research
Majha et al.'s Categorizing Wireheading in Partially Embedded Agents discusses the wireheading problem for agents who can mess with their reward channel or beliefs. They model this using causal agent diagrams, suggest a possible solution (making rewards a function of world-beliefs, not observations) and show that this does not work using very simple gridworld AIXIjs implementations. #AI_Theory
Kovarik et al.'s AI Safety Debate and Its Applications discusses using adversarially Debating AIs as a method for alignment. It provides a very accessible introduction to Debating AIs, and implements some extensions to the practical MNIST work from the original paper. #Amplification
Mancuso et al.'s Detecting Spiky Corruption in Markov Decision Processes suggests that we can address corrupted reward signals for RL by removing 'spikey' rewards. This is an attempt to get around impossibility results by identifying a subclass where they don't hold. I can see this being useful in some cases like reward tampering, where the reward from fiddling with $AGENT_UTILITY is likely to be very spiky. However if human values are fragile then it seems plausible that the 'True' reward signal should also be spikey. #ML_safety
Perry & Uuk's AI Governance and the Policymaking Process: Key Considerations for Reducing AI Risk introduces the field of AI governance, and discusses issues about how policy is implemented in practice, like the existence of windows in time for institutional change. #Politics
Finances
Their website suggests they are seeking donations, but they did not reply when I enquired with the ‘contact us’ email.
They are run by volunteers, and were funded by the LTFF.
If you want to donate the web page is here.
FLI: The Future of Life Institute
FLI is a Boston-based independent existential risk organization, focusing on outreach, founded in large part to help organise the regranting of $10m from Elon Musk.
They have a podcast on AI Alignment here, and ran the Beneficial AI conference in January.
One of their big projects this year has been promoting the stigmatisation of, and ultimately the banning of, Lethal Autonomous Weapons. As well as possibly being good for its own sake, this might help build institutional capacity to ban potentially dangerous technologies that transfer autonomous away from humans. You can read their statement on the subject to the UN here. On the other hand, the desirability of this policy is not entirely uncontroversial – see for example Bogosian’s On AI Weapons. There is also lengthy discussion by Sterbenz and Trager here.
Krakovna's ICLR Safe ML Workshop Report summarises the results from a workshop on safety that Victoria co-ran at ICLR. You can see a list of all the papers here. #ML_safety
AIImpacts
AIImpacts is a Berkeley based AI Strategy organisation founded in 2014 by Katja Grace. They are affiliated with (a project of, with independent financing from) MIRI. They do various pieces of strategic background work, especially on AI Timelines - it seems their previous work on the relative rarity of discontinuous progress has been relatively influential. Their research can be found here.
Research
Katja impressed upon me that most of their work this year went into as-yet-unpublished work, but this is what is public:
Long & Davis's Conversation with Ernie Davis is an interview transcript with Davis, an NYU computer science professor who is an AI risk sceptic. Unfortunately I didn't think they quite got into the heart of the disagreement - they seem to work out the cruz is how much power superior intelligence gives you, but then move on. #Forecasting
Long & Bergal's Evidence against current methods leading to human level artificial intelligence lists a variety of arguments for why current AI techniques are insufficient for AGI. It's basically a list of 'things AI might need that we don't have yet', a lot of which coming from Marcus's Critical Appraisal. #Forecasting
Korzekwa's The unexpected difficulty of comparing AlphaStar to humans analyses AlphaStar's performance against human StarCraft players. It convincingly, in my inexpert judgement, argues that the 'unfair' advantages of AlphaStar - like the clicks-per-minute rate, and lack of visibility restrictions - we significant contributors to AlphaStar's success. As such, on an apples-to-apples basis it seems that humans have not yet been defeated at Starcraft. #Misc
AI Impacts's Historical Economic Growth Trends argues that historically economic growth has been super-linear in population size. As such we should expect accelerating growth 'by default' - "Extrapolating this model implies that at a time when the economy is growing 1% per year, growth will diverge to infinity after about 200 years". This is very interesting to me as it contradicts what I suggested here. Notably growth has slowed since 1950, perhaps for anthropic reasons. #Forecasting
AI Impacts's AI Conference Attendance plots attendance at the major AI conferences over time to show the recent rapid growth in the field using a relatively stable measure. #Forecasting
Finances
They spent $316,398 in 2019, and plan to spend around $325,000 in 2020. They have around $269,590 in cash and pledged funding, suggesting (on a very naïve calculation) around 0.8 years of runway.
In the past they have received support from EA organisations like OpenPhil and FHI.
MIRI administers their finances on their behalf; donations can be made here.
GPI: The Global Priorities Institute
GPI is an Oxford-based Academic Priorities Research organisation founded in 2018 by Hilary Greaves and part of Oxford University. They do work on philosophical issues likely to be very important for global prioritisation, much of which is, in my opinion, relevant to AI Alignment work. Their research can be found here.
Research
Macaskill (article) & Demski (extensive comments)'s A Critique of Functional Decision Theory gives some criticisms of FDT. He makes a variety of arguments, though I generally found them unconvincing. For example, the 'Bomb' example seemed to be basically question-begging on Newcomb's problem, and his Scots vs English example (where Scottish people choose to one-box because of their ancestral memory of the Darien scheme) seems to me to be a case of people not actually employing FDT at all. And some of his arguments - like that it is too complicated for humans to actually calculate - seem like the same arguments he would reject as criticisms of utilitarianism, and not relevant to someone working on AGI. I listed this as co-written by Abram Demski because he is acknowledged in the post, and his comments at the bottom are as detailed as worthy as the main post itself, and I recommend reading the two together. Researchers from MIRI were also named authors on the paper. #Decision_Theory
Greaves & Cotton-Barratt's A bargaining-theoretic approach to moral uncertainty lays out formalism and discusses using Nash Equilibrium between 'negotiating' moral values as an alternative approach to moral uncertainty. It discusses some subtle points about the selection of the BATNA outcome. One interesting section was on small vs grand worlds - whether splitting the world up into sub-dilemmas made a difference. For expected-value type approaches the answer is no, but for negotiating strategies the answer is yes, because the different moral theories might trade so as to influence the dilemmas that mattered most to them. This reminded me of an argument from Wei Dai that agents who cared about total value, finding themselves in a small world, might acausally trade with average value agents in large worlds. Presumably a practical implication might be that EAs should adhere to conventional moral standards with even higher than usual moral fidelity, in exchange for shutting up and multiplying on EA issues. The paper also makes interesting points about the fanaticism objection and the difference between moral and empirical risk. Researchers from FHI were also named authors on the paper. #Decision_Theory
MacAskill et al.'s The Evidentialist's Wager argues that Decision-Theoretic uncertainty in a large universe favours EDT over CDT. This is because your decision only has local causal implications, but global evidential implications. The article then goes into detail motivating the idea and discussing various complications and objections. It seems to push EDT in an FDT-direction, though presumably they still diverge on smoking lesion questions. Researchers from FHI, FRI were also named authors on the paper. #Decision_Theory
Mogensen's ‘The only ethical argument for positive 𝛿 ’? argues that positive pure time preference could be justified through agent-relative obligations. This was an interesting paper to me, and suggests some interesting (extremely speculative) questions - e.g. can we, by increasing out relatedness to our ancestors, acausally influence them into treating us better? #Philosophy
Mogensen's Doomsday rings twice attempts to salvage the Doomsday argument by suggesting we should update using SSA twice. He argues the second such update - on the fact that the present-day seems unusually influential - cannot be 'cancelled out' by SIA. #Philosophy
Finances
They spent £600,000 in 2018/2019 (academic year), and plan to spend around £1,400,000 in 2019/2020. They suggested that as part of Oxford University ‘cash on hand’ or ‘runway’ were not really meaningful concepts for them, as they need to fully-fund all employees for multiple years.
If you want to donate to GPI, you can do so here.
FRI: The Foundational Research Institute
FRI is a London (previously Germany) based Existential Risk Research organisation founded in 2013 currently lead by Stefan Torges and Jonas Vollmer. They are part of the Effective Altruism Foundation (EAF) and do research on a number of fundamental long-term issues, some related how to reduce the risks of very bad AGI outcomes.
In general they adopt what they refer to as ‘suffering-focused’ ethics, which I think is a quite misguided view. However, they seem to have approached this thoughtfully.
Apparently this year they are more focused on research, vs movement-building and donation-raising in previous years.
Research
FRI researchers were not lead author on any work directly relevant to AI Alignment (unlike last year, where they had four papers).
FRI researchers contributed to the following research led by other organisations:
Finances
EAF (of which they are a part) spent $836,622 in 2018 and $1,125,000 in 2019, and plan to spend around $995,000 in 2020. They have around $1,430,000 in cash and pledged funding, suggesting (on a very naïve calculation) around 1.4 years of runway.
According to their website, their finances are not separated from those of the EAF, and it is not possible to ear-mark donations. In the past this has made me worry about fungibility; donations funding other EAF work. However apparently EAF basically doesn’t do anything other than FRI now.
If you wanted to donate to FRI, you could do so here.
Median Group
Median is a Berkeley based independent AI Strategy organisation founded in 2018 by Jessica Taylor, Bryce Hidysmith, Jack Gallagher, Ben Hoffman, Colleen McKenzie, and Baeo Maltinsky. They do research on various risks, including AI timelines. Their research can be found here.
Research
Maltinsky et al.'s Feasibility of Training an AGI using Deep RL:A Very Rough Estimate build a model for how plausible one method of achieving AGI is. The theory is that you could basically simulate a bunch of people and have them work on the problem. Their model suggests this is not a credible way of producing AGI in the near term. I like the way they included their code in the actual report. #Forecasting
Taylor et al.'s Revisiting the Insights model improved their Insights model from last year. If you recall this basically used a pareto distribution for of many genius insights were required to get us to AGI. #Forecasting
The following was written by Jessica but not as an official Median piece:
Taylor's The AI Timelines Scam argues that there are systematic biases that lead people to exaggerate how short AI timelines are. One is that people who espouse short timelines tend to also argue for some amount of secrecy due to Infohazards, which makes their work hard for outsiders to audit. A second is that capital allocators tend to fund those who dream BIG, leading to systematic exaggeration of your field's potential. I think both are reasonable points, but I think she is too quick to use the term 'scam' - as in Scott's Against Lie Inflation. Specifically, while it is true that secrecy is a great cover for mediocrity, it is unfortunately also exactly what a morally virtuous agent would have to do in the presence of infohazards. Indeed, such people might be artificially limited in what they can say, making short time horizons appear artificially devoid of credible arguments. I am more sympathetic to her second argument, but even there to the extent that 1) fields select for people who believe in them and 2) people believe what is useful for them to believe I think it is a bit harsh to call it a 'scam'. #Forecasting
Finances
They spent ~$0 in 2018 and 2019, and plan to spend above $170000 in 2020. They have around $170000 in cash and pledged funding, suggesting (on a very naïve calculation) under 1 years of runway.
Median doesn’t seem to be soliciting donations from the general public at this time.
CSET: The Center for Security and Emerging Technology
CSET is a Washington based Think Tank founded in 2019 by Jason Matheny (ex IARPA), affiliated with the University of Georgetown. They analyse new technologies for their security implications and provide advice to the US government. At the moment they are mainly focused on near-term AI issues. Their research can be found here.
As they apparently launched with $55m from the Open Philanthropy Project, and subsequently raised money from the Hewlett Foundation, I am assuming they do not need more donations at this time.
Leverhulme Center for the Future of Intelligence
Leverhulme is a Cambridge based Research organisation founded in 2015 and currently lead by Stephen Cave. They are affiliated with Cambridge University and closely liked to CSER. They do work on a variety of AI related causes, mainly on near-term issues but also some long-term. You can find their publications here.
Research
Leverhulme-affiliated researchers produced work on a variety of topics; I have only here summarised that which seemed the most relevant.
Hernandez-Orallo et al.'s Surveying Safety-relevant AI Characteristics provides a summary of the properties of AI systems that are relevant for safety. This includes both innate properties of the system (like ability to self-modify or influence its reward signal) and of the environment. Some of these characteristics are relatively well-established in the literature, but others seemed relatively new (to me at least). A few but not most seemed only really relevant to near-time safety issues (like the need for spare batteries). Researchers from CSER, Leverhulme were also named authors on the paper. #Overview
Cave & Ó hÉigeartaigh's Bridging near- and long-term concerns about AI attempt to unify short-term and long-term AI risk concerns. For example, they argue that solving short-term issues can help with long-term ones, and that long-term issues will eventually become short-term issues. However, I am inclined to agree with the review here by Habryka that a lot of the work here is being done by categorising unemployment and autonomous vehicles as long-term, and then arguing that they share many features with short-term issues. I agree that they have a lot in common; however this seems to be because unemployment and cars are also short-term issues - or short-term non-issues in my mind. The paper does not present a compelling argument for why short-term issues have a lot in common with existential risk work, which is what we care about. But perhaps this is being too harsh, and the paper is better understood performatively; it is not attempting to argue that the two camps are naturally allied, but rather attempting to make them allies. Researchers from CSER, Leverhulme were also named authors on the paper. #Strategy
Whittlestone et al.'s The Role and Limits of Principles in AI Ethics: Towards a Focus on Tensions points out that many of the 'values' that laypeople say AI systems should observe, like 'fairness', are frequently in conflict. This is certainly a big improvement over the typical article on the subject. #Shortterm
Leverhulme researchers contributed to the following research led by other organisations:
- Ovadya & Whittlestone's Reducing Malicious Use of Synthetic Media Research: Considerations and Potential Release Practices for Machine Learning
BERI: The Berkeley Existential Risk Initiative
BERI is a Berkeley-based independent Xrisk organisation, founded and lead by Andrew Critch. They provide support to various university-affiliated (FHI, CSER, CHAI) existential risk groups to facilitate activities (like hiring engineers and assistants) that would be hard within the university context, alongside other activities - see their FAQ for more details.
Grants
BERI used to run a grant-making program where they helped Jaan Tallinn allocate money to Xrisk causes. Midway through this year, BERI decided to hand this off to the Survival and Flourishing Fund, a donor-advised fund currently advised by the same team who run BERI.
In this time period (December 2018-November 2019) BERI granted $1,615,933, mainly to large Xrisk organisations. The largest single grant was $600,000 to MIRI.
Research
A number of papers we reviewed this year were supported by BERI, for example:
- Turner et al.'s Conservative Agency
- O'Keefe's Stable Agreements in Turbulent Times: A Legal Toolkit for Constrained Temporal Decision Transmission
- Cihon's Standards for AI Governance: International Standards to Enable Global Coordination in AI Research & Development
Because this support tended not to be mentioned on the front page of the article (unlike direct affiliation) it is quite possible that I missed other papers they supported also.
Finances
BERI have told me they are not seeking public support at this time. If you wanted to donate anyway their donate page is here.
AI Pulse
The Program on Understanding Law, Science, and Evidence (PULSE) is part of the UCLA School of Law, and contains a group working on AI policy. They were founded in 2017 with a $1.5m grant from OpenPhil.
Their website lists a few pieces of research, generally on more near-term AI policy issues. A quick read suggested they were generally fairly well done. However, they don’t seem to have uploaded anything since February.
Research
Sterbenz & Trager's Autonomous Weapons and Coercive Threats discusses the impact of Lethal Autonomous Weapons on diplomacy. #Shortterm
Grotto's Genetically Modified Organisms: A Precautionary Tale for AI Governance discusses the history of GMO regulation in the US and EU. He brings up some interesting points about the highly contingent history behind the different approaches taken. However, I am somewhat sceptical GMOs are that good a comparison, given their fundamentally different nature. #Strategy
Other Research
I would like to emphasize that there is a lot of research I didn't have time to review, especially in this section, as I focused on reading organisation-donation-relevant pieces. So please do not consider it an insult that your work was overlooked!
Naude & Dimitri's The race for an artificial general intelligence: implications for public policy extends the model in Racing to the Precipice (Armstrong et al.) After a lengthy introduction to AI alignment, they make a formal model, concluding that a winner-take-all contest will have very few teams competing (which is good) Interestingly if the teams are concerned about cost minimisation this result no longer holds, as the 'best' team might not invest 100%, so the second-best team still has a chance, but the presence of intermediate prizes is positive, as they incentivise more investment. They suggest public procurement to steer AI development in a safe direction, and an unsafety-tax. (as a very minor aside, I was a little surprised to see the AIImpacts survey cited as a source for expected Singularity timing given that it does not mention the word.) Overall I thought this was an excellent paper. #Strategy
Steinhardt's AI Alignment Research Overview provides a detailed account of the different components of AI Alignment work. I think this probably takes over from Amodei et al.'s Concrete Problems (on which Jacob was a co-author) as my favour introduction to technical work, for helping new researchers locate themselves, with the one proviso that it is only in Google Docs form at the moment. He provides a useful taxonomy, goes into significant detail on the different problems, and suggests possible avenues of attack. The only area that struck me as a little light was on some of the MIRI-style agent foundations issues. Overall I thought this was an excellent paper. #Overview
Piper's The case for taking AI seriously as a threat to humanity is an introduction to AI safety for Vox readers. In my opinion it is the best non-technical introduction to the issue I have seen. It has become my go-to for linking people and reading groups. The article does a good job introducing the issues in a persuasive and common-sense way without much loss of fidelity. My only gripe is the article unquestioningly repeats an argument about criminal justice 'discrimination' which has, in my opinion, been debunked (see here and the Washington Post article linked at the bottom), but perhaps this is a necessary concession when writing for Vox, and is only a very small part of the article. Overall I thought this was an excellent paper. #Introduction
Cohen et al.'s Asymptotically Unambitious Artificial General Intelligence ambitiously aims to provide an aligned AI algorithm. They do this by basically using an extremely myopic form of boxed oracle AIXI, that doesn't care about any rewards after the box has been opened - so all it cares about is getting rewards for answering the question well inside the box. It is indifferent to what the human does with the reward once outside the box. This assumes the AIXI cannot influence the world without detectably opening the box. This also aims to avoid the reward-hacking problems of AIXI. You might also enjoy the comments here. #AI_Theory
Snyder-Beattie et al.'s An upper bound for the background rate of human extinction uses a Laplace's law of succession-style approach to bound non-anthropogenic Xrisk. Given how long mankind has survived so far, they conclude that this is extremely unlikely to be greater than 1/14000, and probably much lower. Notably, they argue that these estimates are not significantly biased by anthropic issues, because high base extinction rates mean lucky human observers would be clustered in worlds where civilisation also developed very quickly, and hence also observe short histories. Obviously they can only provide an upper bound using such methods, so I see the paper as mainly providing evidence we should instead focus on anthropogenic risks, for which no such bound can exist. Researchers from FHI were also named authors on the paper. #Forecasting
Dai's Problems in AI Alignment that philosophers could potentially contribute to provides a list of open philosophical questions that matter for AI safety. This seems useful insomuch as there are people capable of working on many different philosophical issues and willing to be redirected to more useful ones. #Overview
Dai's Two Neglected Problems in Human-AI Safety discusses two danger modes for otherwise benign-seeming approval-orientated AIs. I thought this was good as it is potentially a very 'sneeky' way in which human value might be lost, at the hands of agents which otherwise appeared extremely corrigible etc. #Forecasting
Agrawal et al.'s Scaling up Psychology via Scientific Regret Minimization:A Case Study in Moral Decision-Making suggests that, in cases with large amounts data plus noise, human-interpretable models could be evaluated relative to ML predictions rather than the underlying data directly. In particular, they do this with the big Moral Machine dataset, comparing simple human-interpretable rules (like humans are worth more than animals, or criminals are worth less) with their NN. This suggests a multi-step program for friendliness: 1) gather data 2) train ML on data 3) evaluate simple human-evaluable rules on ML 4) have humans evaluate these rules. Researchers from CHAI were also named authors on the paper. #Ethical_Theory
Krueger et al.'s Misleading Meta-Objectives and Hidden Incentives for Distributional Shift discusses the danger of RL agents being incentivised to induce distributional shift. This is in contrast to what I think of as the 'standard' worry about distributional shift, namely arising as a side effect of increasing agent optimisation power. They then introduce a model to demonstrate this behaviour, but I had a little trouble understanding exactly how this bit was meant to work. Researchers from Deepmind were also named authors on the paper. #ML_safety
Zhang & Dafoe's Artificial Intelligence: American Attitudes and Trends surveys the views of ordinary people about AI. They used YouGov, who I generally regard as one of the best polling agencies. The survey did a good job of showing that the general public is generally very ignorant and susceptible to framing effects. Respondents basically thought that everyone potential AI 'problem' was roughly equally important. When reading this I think it is worth keeping the general literature on voter irrationality in mind - e.g. Bryan Caplan's The Myth of the Rational Voter or Scott’s Noisy Poll Results and Reptilian Muslim Climatologists from Mars. Researchers from FHI were also named authors on the paper. #Politics
Cottier & Shah's Clarifying some key hypotheses in AI alignment is a map of the connections between different ideas in AI safety. Researchers from CHAI were also named authors on the paper. #Overview
Ovadya & Whittlestone's Reducing Malicious Use of Synthetic Media Research: Considerations and Potential Release Practices for Machine Learning discusses various ways of improving the safety of ML research release. While synth media is the titular subject, most of it is more general, with fairly detailed descriptions of various strategies. While I don't think synth media is very important, it could be useful for building norms in ML that would apply to AGI work also. The paper discusses bioethics at length, e.g. how they use IRBs. My personal impression of IRBs is they are largely pointless and have little to do with ethics, functioning mainly to slow things down and tick boxes, but then again that might be desirable for AI research! Researchers from CSER, Leverhulme were also named authors on the paper. #Security
Schwarz's On Functional Decision Theory is a blog post by one of the philosophers who reviewed Eliezer and Nate's paper on FDT. It explains his objections, and why the paper was rejected from the philosophy journal he was a reviewer for. The key thing I took away from it was that MIRI did not do a good job of locating their work within the broader literature - for example, he argues that FDT seems like it might actually be a special case of CDT as construed by some philosophers, which E&N should have addressed, and elsewhere he suggests E&N's criticisms of CDT and EDT present strawmen. He also made some interesting points, for example that it seems 'FDT will sometimes recommend choosing a particular act because of the advantages of choosing a different act in a different kind of decision problem'. However most of the substantive criticisms were not very persuasive to me. Some seemed to almost beg the question, and at other times he essentially faulted FDT for addressing directly issues which any decision theory will ultimately have to address, like logical counterfactuals, or what is a 'Fair' scenario. He also presented a scenario, 'Procreation', as an intended Reductio of FDT that actually seems to me like a scenario where FDT works better than CDT does. #Decision_Theory
LeCun et al.'s Debate on Instrumental Convergence between LeCun, Russell, Bengio, Zador, and More was a public debate on Facebook between major figures in AI on the AI safety issue. Many of these have been prominently dismissive in the past, so this was good to see. Unfortunately a lot of the debate was not at a very high level. It seemed that the sceptics generally agreed it was important to work on AI safety, just that this work was likely to happen by default. #Misc
Dai's Problems in AI Alignment that philosophers could potentially contribute to provides a list of issues for philosophers who want to work on the cause without math backgrounds. I think this is potentially very useful if brought to the notice of the relevant people, as the topics on the list seem useful things to work on, and I can easily imagine people not being aware of all of them. #Overview
Walsh's End Times: A Brief Guide to the End of the World is a popular science book on existential risk. AI risk is one of the seven issues addressed, in an extended and well-researched chapter. While I might quibble with one or two points, overall I thought this was a good introduction. The main qualifier for your opinion here is how valuable you think outreach to the educated layman is. #Introduction
Szlam et al.'s Why Build an Assistant in Minecraft? suggest a research program for building an intelligent assistant for Minecraft. The program doesn't appear to be directly motivated by AI alignment, but it does seem unusual in the degree to which alignment-type-issues would have to be solved for it to succeed - thereby hopefully incentivising mainstream ML guys to work on them. In particular, they want the agent to be able to work out 'what you wanted' from a natural language text channel, which is clearly linked to the Value Alignment problem, and similar issues like the higher optimisation power of the agent are likely to occur. The idea that the agent should be 'fun' is also potentially relevant! The authors also released an environment to make making these assistants easier. #Misc
Kumar et al.'s Failure Modes in Machine Learning is a Microsoft document discussing a variety of ways ML systems can go wrong. It includes both intentional (e.g. hacking) and unintentional (e.g. the sort of thing we worry about). #Misc
Sevilla & Moreno's Implications of Quantum Computing for Artificial Intelligence Alignment Research examines whether Quantum Computing would be useful for AI Alignment. They consider three relevant properties of QC and several approaches to AI Alignment, and conclude that QC is not especially relevant. #Forecasting
Collins's Principles for the Application of Human Intelligence analyses the problems of biased and non-transparent decision making by natural intelligence systems. #Shortterm
Capital Allocators
One of my goals with this document is to help donors make an informed choice between the different organisations. However, it is quite possible that you regard this as too difficult, and wish instead to donate to someone else who will allocate on your behalf. This is of course much easier; now instead of having to solve the Organisation Evaluation Problem, all you need to do is solve the dramatically simpler Organisation Evaluator Organisation Evaluation Problem.
A helpful map from Issa Rice shows how at the moment the community has only managed to achieve delegative funding chains 6 links long. If you donate to Patrick Brinich-Langlois, we can make this chain significantly longer! In reality this is a quite misleading way of phrasing the issue of course, as for most of these organisations the ‘flow-through’ is a relatively small fraction. I do think it is valid to be concerned about sub-optimally high levels of intermediation however, which if nothing else reduces donor control. This seems to me to be a weak argument against delegating donations.
LTFF: Long-term future fund
LTFF is a globally based EA grantmaking organisation founded in 2017, currently lead by Matt Wage and affiliated with CEA. They are one of four funds set up by CEA to allow individual donors to benefit from specialised capital allocators; this one focuses on long-term future issues, including a large focus on AI Alignment. Their website is here. There are write-ups for their first two grant rounds in 2019 here and here, and comments here and here. Apparently they have done another $400,000 round since then but the details are not yet public.
In the past I have been sceptical of the fund, as it was run by someone who already had access to far more capital (OpenPhil), and the grants were both infrequent and relatively conservative – giving to large organisations that individual donors are perfectly capable of evaluating themselves. Over the last year, however, things have significantly changed. The fund is now run by four people, and the grants have been to a much wider variety of causes, many of which would simply not be accessible to individual donors.
The fund managers are:
- Matt Wage
- Helen Toner
- Oliver Habryka
- Alex Zhu
Oliver Habryka especially has been admirably open with lengthy write-ups about his thoughts on the different grants, and I admire his commitment to intellectual integrity (you might enjoy his comments here). I am less familiar with the other fund managers. All the managers are, to my knowledge, unpaid.
In general most of the grants seem at least plausibly valuable to me, and many seemed quite good indeed. As there is extensive discussion in the links above I shan't discuss my opinions of individual grants in detail.
I attempted to classify the recommended (including those not accepted by CEA) by type and geography. Note that ‘training’ means paying an individual to self-study. I have deliberately omitted the exact percentages because this is an informal classification.
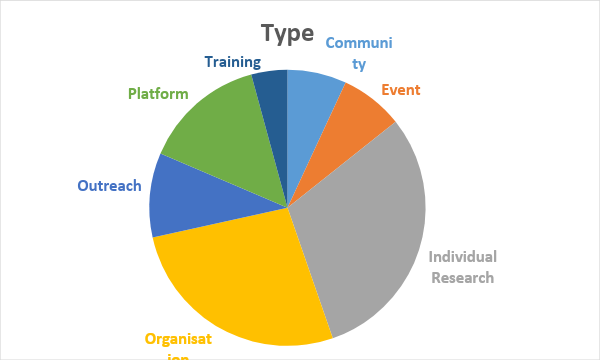
Of these categories, I am most excited by the Individual Research, Event and Platform projects. I am generally somewhat sceptical of paying people to ‘level up’ their skills.
I can understand why the fund managers gave over a quarter of the funds to major organisations – they thought these organisations were a good use of capital! However, to my mind this undermines the purpose of the fund. (Many) individual donors are perfectly capable of evaluating large organisations that publicly advertise for donations. In donating to the LTFF, I think (many) donors are hoping to be funding smaller projects that they could not directly access themselves. As it is, such donors will probably have to consider such organisation allocations a mild ‘tax’ – to the extent that different large organisations are chosen then they would have picked themselves.
For a similar analysis, see Gaensbauer’s comment here. I think his ‘counterfactually unique’ (73%) roughly maps onto my ‘non-organisation’.
CFAR, which the fund managers recommended $300,000, was the largest single intended beneficiary with just over 20% of the recommendations.
All grants have to be approved by CEA before they are made; historically they have approved almost all. In general I think these rejections improved the process. In every instance they were subsequently funded by private donors anyway, but this does not seem to be a problem for donors to the LTFF whose capital is protected. Notably this means the funds only paid out $150,000 to CFAR (10%), as the balance was made up by a private donor after CEA did not approve the second grant.
I was not impressed that one grant that saw harsh and accurate criticism on the forum after the first round was re-submitted for the second round. Ex post this didn’t matter as CEA rejected it on substantive grounds the second time, but it makes me somewhat concerned about a risk of some of the capital going towards giving sinecures to people who are in the community, rather than objective merit. But if CEA will consistently block this waste maybe this is not such a big issue, and the grant in question only represented 1.3% of the total for the year.
If you wish to donate to the LTFF you can do so here.
OpenPhil: The Open Philanthropy Project
The Open Philanthropy Project (separated from Givewell in 2017) is an organisation dedicated to advising Cari and Dustin Moskovitz on how to give away over $15bn to a variety of causes, including existential risk. They have made extensive donations in this area and probably represent both the largest pool of EA-aligned capital and the largest team of EA capital allocators.
They also recently announced they would be working with Ben Delo as well.
This year they implemented a special committee for determining grants to EA-related organisations.
Grants
You can see their grants for AI Risk here. It lists only made four AI Risk grants in 2019, though I think that their $500k grant to ESPR (The European Summer Program on Rationality) should be considered an AI Risk relevant grant also.:
- OpenPhil AI Fellowship: $2.3m (write-up)
- MIRI: $2.7m (write-up)
- CSET: $55m (write-up)
- BERI / CHAI: $250k (write-up)
In contrast there are 11 AI Risk grants listed for 2018, though the total dollar value is lower.
The OpenPhil AI Fellowship basically fully funds AI PhDs for students who want to work on the long term impacts of AI. One thing that I had misunderstood previously was these fellowships are not intended to be specific to AI safety, though presumably their recipients are more likely to work on safety than the average ML PhD student. They funded 7 scholarships in 2018 and 8 in 2019
Due to a conflict of interest I cannot make any evaluation of their effectiveness.
Research
Most of their research concerns their own granting, and in an unusual failure of nominative determinism is non-public except for the short write-ups linked above.
Zabel & Muehlhauser's Information security careers for GCR reduction argue that working in InfoSec could be a useful career for reducing Xrisks, especially AI and Bio. This is partly to help prevent AGI/synth bio knowledge falling into the hands of malicious hackers (though most ML research seems to be very open), and partly because the field teaches various skills that are useful for AI safety, both high-level like Eliezer's Security Mindset and technical like crypto. They suggested that there was a shortage of such people willing to work on Xrisk right now, and perhaps in the future, due to lucrative alternative employment options. Researchers from Google Brain were also named authors on the paper. #Careers
Finances
To my knowledge they are not currently soliciting donations from the general public, as they have a lot of money from Dustin and Cari, so incremental funding is less of a priority than for other organisations. They could be a good place to work however!
SFF: The Survival and Flourishing Fund
SFF is a donor advised fund, advised by the people who make up BERI’s Board of Directors. SFF was initially funded in 2019 by a grant of approximately $2 million from BERI, which in turn was funded by donations from philanthropist Jaan Tallinn.
Grants
In its grantmaking SFF used an innovative allocation process to combine the views of many grant evaluators (described here). SFF has run two grant rounds thus far. The first ($880k in total) focused on large organisations:
- 80,000 Hours: $280k
- CFAR: $110k
- CSER: $40k
- FLI: $130k
- GCRI: $60k
- LessWrong: $260k
The second round, requiring written applications, distributed money to a much wider variety of projects. The website lists 28 recipients, of which many but not all were AI relevant. The largest grant was for $300k to the Longevity Research Institute.
Due to a conflict of interest I cannot evaluate the effectiveness of their grantmaking.
Other News
80,000 Hours's AI/ML safety research job board collects various jobs that could be valuable for people interested in AI safety. At the time of writing it listed 35 positions, all of which seemed like good options that it would be valuable to have sensible people fill. I suspect most people looking for AI jobs would find some on here they hadn't heard of otherwise, though of course for any given person many will not be appropriate. They also have job boards for other EA causes. #Careers
Brown & Sandholm's Superhuman AI for multiplayer poker present an AI that can beat professionals in non-limit Texas hold'em. My understanding was that this was seen as significantly harder than limit poker, so this represents something of a milestone. Unlike various Deepmind victories at classic games, this doesn't seem to have required much compute. #Misc
Chivers's The AI Does Not Hate You: Superintelligence, Rationality and the Race to Save the World is a journalistic examination of the rationalist community and the existential risk argument. I confess I haven't actually read the book, and have very low expectations for journalists in this regard, though Chivers is generally very good, and by all accounts this is a very fair and informative book. I've heard people recommend it as an explainer to their parents. #Introduction
EU's Ethics Guidelines for Trustworthy Artificial Intelligence is a series of ethics guidelines for AI in the EU. They received input from many groups, including CSER and Jaan Tallinn. They are (at this time) optional guidelines, and presumably will not apply to UK AI companies like Deepmind after Brexit. The guidelines seemed largely focused on banal statements about non-discrimination etc.; I could not find any mention of existential risk in the guidelines. In general I am not optimistic about political solutions and this did not change my mind. #Politics
Kaufman's Uber Self-Driving Crash convincingly argues that Uber was grossly negligent when their car hit and killed Elaine Herzberg last year. #Shortterm
Schmidt et al.'s National Security Commission on Artificial Intelligence Interim Report surveys AI from a US defence perspective. It contains a few oblique references to AI risk. #Politics
Cummings's On the referendum #31: Project Maven, procurement, lollapalooza results & nuclear/AGI safety discusses various important trends, including a sophisticated discussion of AGI safety. This is mainly noteworthy because the author is the mastermind of Brexit and the recent Conservative landslide in the UK, and perhaps the most influential man in the UK as a result. #Strategy
Methodological Thoughts
Inside View vs Outside View
This document is written mainly, but not exclusively, using publicly available information. In the tradition of active management, I hope to synthesise many pieces of individually well known facts into a whole which provides new and useful insight to readers. Advantages of this are that 1) it is relatively unbiased, compared to inside information which invariably favours those you are close to socially and 2) most of it is legible and verifiable to readers. The disadvantage is that there are probably many pertinent facts that I am not a party to! Wei Dai has written about how much discussion now takes place in private google documents – for example this Drexler piece apparently; in most cases I do not have access to these. If you want the inside scoop I am not your guy; all I can supply is exterior scooping.
Many capital allocators in the bay area seem to operate under a sort of Great Man theory of investment, whereby the most important thing is to identify a guy who is really clever and ‘gets it’. I think there is some merit in this; however, I think I believe in it much less than they do. Perhaps as a result of my institutional investment background, I place a lot more weight on historical results. In particular, I worry that this approach leads to over-funding skilled rhetoricians and those the investor/donor is socially connected to.
Judging organisations on their historical output is naturally going to favour more mature organisations. A new startup, whose value all lies in the future, will be disadvantaged. However, I think that this is the correct approach for donors who are not tightly connected to the organisations in question. The newer the organisation, the more funding should come from people with close knowledge. As organisations mature, and have more easily verifiable signals of quality, their funding sources can transition to larger pools of less expert money. This is how it works for startups turning into public companies and I think the same model applies here. (I actually think that even those with close personal knowledge should use historical results more, to help overcome their biases.)
This judgement involves analysing a large number of papers relating to Xrisk that were produced during 2019. Hopefully the year-to-year volatility of output is sufficiently low that this is a reasonable metric; I have tried to indicate cases where this doesn’t apply. I also attempted to include papers during December 2018, to take into account the fact that I'm missing the last month's worth of output from 2019, but I can't be sure I did this successfully.
This article focuses on AI risk work. If you think other causes are important too, your priorities might differ. This particularly affects GCRI, FHI and CSER, who both do a lot of work on other issues which I attempt to cover but only very cursorily.
We focus on papers, rather than outreach or other activities. This is partly because they are much easier to measure; while there has been a large increase in interest in AI safety over the last year, it’s hard to work out who to credit for this, and partly because I think progress has to come by persuading AI researchers, which I think comes through technical outreach and publishing good work, not popular/political work.
Politics
My impression is that policy on most subjects, especially those that are more technical than emotional is generally made by the government and civil servants in consultation with, and being lobbied by, outside experts and interests. Without expert (e.g. top ML researchers in academia and industry) consensus, no useful policy will be enacted. Pushing directly for policy seems if anything likely to hinder expert consensus. Attempts to directly influence the government to regulate AI research seem very adversarial, and risk being pattern-matched to ignorant technophobic opposition to GM foods or other kinds of progress. We don't want the 'us-vs-them' situation that has occurred with climate change, to happen here. AI researchers who are dismissive of safety law, regarding it as an imposition and encumbrance to be endured or evaded, will probably be harder to convince of the need to voluntarily be extra-safe - especially as the regulations may actually be totally ineffective.
The only case I can think of where scientists are relatively happy about punitive safety regulations, nuclear power, is one where many of those initially concerned were scientists themselves. Given this, I actually think policy outreach to the general population is probably negative in expectation.
If you’re interested in this, I’d recommend you read this blog post from last year.
Openness
I think there is a strong case to be made that openness in AGI capacity development is bad. As such I do not ascribe any positive value to programs to ‘democratize AI’ or similar.
One interesting question is how to evaluate non-public research. For a lot of safety research, openness is clearly the best strategy. But what about safety research that has, or potentially has, capabilities implications, or other infohazards? In this case it seems best if the researchers do not publish it. However, this leaves funders in a tough position – how can we judge researchers if we cannot read their work? Maybe instead of doing top secret valuable research they are just slacking off. If we donate to people who say “trust me, it’s very important and has to be secret” we risk being taken advantage of by charlatans; but if we refuse to fund, we incentivize people to reveal possible infohazards for the sake of money. (Is it even a good idea to publicise that someone else is doing secret research?)
With regard to published research, in general I think it is better for it to be open access, rather than behind journal paywalls, to maximise impact. Reducing this impact by a significant amount in order for the researcher to gain a small amount of prestige does not seem like an efficient way of compensating researchers to me. Thankfully this does not occur much with CS papers as they are all on arXiv, but it is an issue for some strategy papers.
Similarly, it seems a bit of a waste to have to charge for books – ebooks have, after all, no marginal cost – if this might prevent someone from reading useful content. There is also the same ability for authors to trade off public benefit against private gain – by charging more for their book, they potentially earn more, but at the cost of lower reach. As a result, I am inclined to give less credit for market-rate books, as the author is already compensated and incentised by sales revenue.
More prosaically, organisations should make sure to upload the research they have published to their website! Having gone to all the trouble of doing useful research it is a constant shock to me how many organisations don’t take this simple step to significantly increase the reach of their work. Additionally, several times I have come across incorrect information on organisation’s websites.
Research Flywheel
My basic model for AI safety success is this:
- Identify interesting problems
- As a byproduct this draws new people into the field through altruism, nerd-sniping, apparent tractability
- Solve interesting problems
- As a byproduct this draws new people into the field through credibility and prestige
- Repeat
One advantage of this model is that it produces both object-level work and field growth.
There is also some value in arguing for the importance of the field (e.g. Bostrom’s Superintelligence) or addressing criticisms of the field.
Noticeably absent are strategic pieces. I find that a lot of these pieces do not add terribly much incremental value. Additionally, my suspicion strategy research is, to a certain extent, produced exogenously by people who are interested / technically involved in the field. This does not apply to technical strategy pieces, about e.g. whether CIRL or Amplification is a more promising approach.
There is somewhat of a paradox with technical vs ‘wordy’ pieces however: as a non-expert, it is much easier for me to understand and evaluate the latter, even though I think the former are much more valuable.
Differential AI progress
There are many problems that need to be solved before we have safe general AI, one of which is not producing unsafe general AI in the meantime. If nobody was doing non-safety-conscious research there would be little risk or haste to AGI – though we would be missing out on the potential benefits of safe AI.
There are several consequences of this:
- To the extent that safety research also enhances capabilities, it is less valuable.
- To the extent that capabilities research re-orientates subsequent research by third parties into more safety-tractable areas it is more valuable.
- To the extent that safety results would naturally be produced as a by-product of capabilities research (e.g. autonomous vehicles) it is less attractive to finance.
One approach is to research things that will make contemporary ML systems safer, because you think AGI will be a natural outgrowth from contemporary ML. This has the advantage of faster feedback loops, but is also more replaceable (as per the previous section).
Another approach is to try to reason directly about the sorts of issues that will arise with superintelligent AI. This work is less likely to be produced exogenously by unaligned researchers, but it requires much more faith in theoretical arguments, unmoored from empirical verification.
Near-term safety AI issues
Many people want to connect AI existential risk issues to ‘near-term’ issues; I am generally sceptical of this. For example, autonomous cars seem to risk only localised tragedies, and private companies should have good incentives here. Unemployment concerns seem exaggerated to me, as they have been for most of history (new jobs will be created), at least until we have AGI, at which point we have bigger concerns. Similarly, I generally think concerns about algorithmic bias are essentially political - I recommend this presentation - though there is at least some connection to the value learning problem there.
Financial Reserves
Charities like having financial reserves to provide runway, and guarantee that they will be able to keep the lights on for the immediate future. This could be justified if you thought that charities were expensive to create and destroy, and were worried about this occurring by accident due to the whims of donors. Unlike a company which sells a product, it seems reasonable that charities should be more concerned about this.
Donors prefer charities to not have too much reserves. Firstly, those reserves are cash that could be being spent on outcomes now, by either the specific charity or others. Valuable future activities by charities are supported by future donations; they do not need to be pre-funded. Additionally, having reserves increases the risk of organisations ‘going rogue’, because they are insulated from the need to convince donors of their value.
As such, in general I do not give full credence to charities saying they need more funding because they want much more than a 18 months or so of runway in the bank. If you have a year’s reserves now, after this December you will have that plus whatever you raise now, giving you a margin of safety before raising again next year.
I estimated reserves = (cash and grants) / (2020 budget). In general I think of this as something of a measure of urgency. However despite being prima facie a very simple calculation there are many issues with this data. As such these should be considered suggestive only.
Donation Matching
In general I believe that charity-specific donation matching schemes are somewhat dishonest, despite my having provided matching funding for at least one in the past.
Ironically, despite this view being espoused by GiveWell (albeit in 2011), this is essentially of OpenPhil’s policy of, at least in some cases, artificially limiting their funding to 50% or 60% of a charity’s need, which some charities have argued effectively provides a 1:1 match for outside donors. I think this is bad. In the best case this forces outside donors to step in, imposing marketing costs on the charity and research costs on the donors. In the worst case it leaves valuable projects unfunded.
Obviously cause-neutral donation matching is different and should be exploited. Everyone should max out their corporate matching programs if possible, and things like the annual Facebook Match continue to be great opportunities.
Poor Quality Research
Partly thanks to the efforts of the community, the field of AI safety is considerably more well respected and funded than was previously the case, which has attracted a lot of new researchers. While generally good, one side effect of this (perhaps combined with the fact that many low-hanging fruits of the insight tree have been plucked) is that a considerable amount of low-quality work has been produced. For example, there are a lot of papers which can be accurately summarized as asserting “just use ML to learn ethics”. Furthermore, the conventional peer review system seems to be extremely bad at dealing with this issue.
The standard view here is just to ignore low quality work. This has many advantages, for example 1) it requires little effort, 2) it doesn’t annoy people. This conspiracy of silence seems to be the strategy adopted by most scientific fields, except in extreme cases like anti-vaxers.
However, I think there are some downsides to this strategy. A sufficiently large milieu of low-quality work might degrade the reputation of the field, deterring potentially high-quality contributors. While low-quality contributions might help improve Concrete Problems’ citation count, they may use up scarce funding.
Moreover, it is not clear to me that ‘just ignore it’ really generalizes as a community strategy. Perhaps you, enlightened reader, can judge that “How to solve AI Ethics: Just use RNNs” is not great. But is it really efficient to require everyone to independently work this out? Furthermore, I suspect that the idea that we can all just ignore the weak stuff is somewhat an example of typical mind fallacy. Several times I have come across people I respect according respect to work I found clearly pointless. And several times I have come across people I respect arguing persuasively that work I had previously respected was very bad – but I only learnt they believed this by chance! So I think it is quite possible that many people will waste a lot of time as a result of this strategy, especially if they don’t happen to move in the right social circles.
Having said all that, I am not a fan of unilateral action, and am somewhat selfishly conflict-averse, so will largely continue to abide by this non-aggression convention. My only deviation here is to make it explicit. If you’re interested in this you might enjoy this by 80,000 Hours.
The Bay Area
Much of the AI and EA communities, and especially the EA community concerned with AI, is located in the Bay Area, especially Berkeley and San Francisco. This is an extremely expensive place, and is dysfunctional both politically and socially. Aside from the lack of electricity and aggressive homelessness, it seems to attract people who are extremely weird in socially undesirable ways – and induces this in those who move there - though to be fair the people who are doing useful work in AI organisations seem to be drawn from a better distribution than the broader community. In general I think the centralization is bad, but if there must be centralization I would prefer it be almost anywhere other than Berkeley. Additionally, I think many funders are geographically myopic, and biased towards funding things in the Bay Area. As such, I have a mild preference towards funding non-Bay-Area projects. If you’re interested in this topic I recommend you read this or this or this.
Conclusions
The size of the field continues to grow, both in terms of funding and researchers. Both make it increasingly hard for individual donors. I’ve attempted to subjectively weigh the productivity of the different organisations against the resources they used to generate that output, and donate accordingly.
My constant wish is to promote a lively intellect and independent decision-making among readers; hopefully my laying out the facts as I see them above will prove helpful to some readers. Here is my eventual decision, rot13'd so you can do come to your own conclusions first (which I strongly recommend):
Qrfcvgr univat qbangrq gb ZVEV pbafvfgragyl sbe znal lrnef nf n erfhyg bs gurve uvtuyl aba-ercynprnoyr naq tebhaqoernxvat jbex va gur svryq, V pnaabg va tbbq snvgu qb fb guvf lrne tvira gurve ynpx bs qvfpybfher. Nqqvgvbanyyl, gurl nyernql unir n dhvgr ynetr ohqtrg.
SUV unir pbafvfgragyl cebqhprq fbzr bs gur uvturfg dhnyvgl erfrnepu. Ubjrire, V nz abg pbaivaprq gurl unir n uvtu arrq sbe nqqvgvbany shaqvat.
V pbagvahr gb or vzcerffrq jvgu PUNV’f bhgchg, naq guvax gurl cbgragvnyyl qb n tbbq wbo vagrenpgvat jvgu znvafgernz ZY erfrnepuref. Gurl unir n ybg bs pnfu erfreirf, juvpu frrzf yvxr vg zvtug erqhpr gur hetrapl bs shaqvat fbzrjung, naq n pbafvqrenoyr cbegvba bs gur jbex vf ba zber arne-grez vffhrf, ohg gurer ner eryngviryl srj bccbeghavgvrf gb shaq grpuavpny NV fnsrgl jbex, fb V vagraq gb qbangr gb PUNV ntnva guvf lrne.
Qrrczvaq naq BcraNV obgu qb rkpryyrag jbex ohg V qba’g guvax vg vf ivnoyr sbe (eryngviryl) fznyy vaqvivqhny qbabef gb zrnavatshyyl fhccbeg gurve jbex.
Va gur cnfg V unir orra irel vzcerffrq jvgu TPEV’f bhgchg ba n ybj ohqtrg. Qrfcvgr vagraqvat 2019 vagraqvat gb or gurve lrne bs fpnyvat hc, bhgchg unf npghnyyl qrpernfrq. V fgvyy vagraq gb znxr n qbangvba, va pnfr guvf vf whfg na hasbeghangr gvzvat vffhr, ohg qrsvavgryl jbhyq jnag gb frr zber arkg lrne.
PFRE’f erfrnepu vf whfg abg sbphfrq rabhtu gb jneenag qbangvbaf sbe NV Evfx jbex va zl bcvavba.
V jbhyq pbafvqre qbangvat gb gur NV Fnsrgl Pnzc vs V xarj zber nobhg gurve svanaprf.
Bhtug frrzf yvxr n irel inyhnoyr cebwrpg, naq yvxr PUNV ercerfragf bar bs gur srj bccbeghavgvrf gb qverpgyl shaq grpuavpny NV fnsrgl jbex. Nf fhpu V guvax V cyna gb znxr n qbangvba guvf lrne.
V gubhtug NV Vzcnpgf qvq fbzr avpr fznyy cebwrpgf guvf lrne, naq ba n abg ynetr ohqtrg. V guvax V jbhyq yvxr gb frr gur erfhygf sebz gurve ynetr cebwrpgf svefg ubjrire.
Va n znwbe qvssrerapr sebz cerivbhf lrnef, V npghnyyl cyna gb qbangr fbzr zbarl gb gur Ybat Grez Shgher Shaq. Juvyr V unira’g nterrq jvgu nyy gurve tenagf, V guvax gurl bssre fznyy qbabef npprff gb n enatr bs fznyy cebwrpgf gung gurl pbhyq abg bgurejvfr shaq, juvpu frrzf irel inyhnoyr pbafvqrevat gur fgebat svanapvny fvghngvba bs znal bs gur orfg ynetre betnavfngvbaf (BcraNV, Qrrczvaq rgp.)
Bar guvat V jbhyq yvxr gb frr zber bs va gur shgher vf tenagf sbe CuQ fghqragf jub jnag gb jbex va gur nern. Hasbeghangryl ng cerfrag V nz abg njner bs znal jnlf sbe vaqvivqhny qbabef gb cenpgvpnyyl fhccbeg guvf.
However, I wish to emphasize that all the above organisations seem to be doing good work on the most important issue facing mankind. It is the nature of making decisions under scarcity that we must prioritize some over others, and I hope that all organisations will understand that this necessarily involves negative comparisons at times.
Thanks for reading this far; hopefully you found it useful. Apologies to everyone who did valuable work that I excluded!
If you found this post helpful, and especially if it helped inform your donations, please consider letting me and any organisations you donate to as a result know.
If you are interested in helping out with next year’s article, please get in touch, and perhaps we can work something out.
Disclosures
I have not in general checked all the proofs in these papers, and similarly trust that researchers have honestly reported the results of their simulations.
I was a Summer Fellow at MIRI back when it was SIAI and volunteered briefly at GWWC (part of CEA). I have conflicts of interest with the Survival and Flourishing Fund and OpenPhil so have not evaluated them. I have no financial ties beyond being a donor and have never been romantically involved with anyone who has ever worked at any of the other organisations.
I shared drafts of the individual organisation sections with representatives from FHI, CHAI, MIRI, GCRI, BERI, Median, CSER, GPI, AISC, BERI, AIImpacts, FRI and Ought.
My eternal gratitude to Greg Lewis, Jess Riedel, Hayden Wilkinson, Kit Harris and Jasmine Wang for their invaluable reviewing. Any remaining mistakes are of course my own. I would also like to thank my wife and daughter for tolerating all the time I have spent/invested/wasted on this.
Sources
80,000 Hours - AI/ML safety research job board - 2019-09-29 - https://80000hours.org/job-board/ai-ml-safety-research/
Agrawal, Mayank; Peterson, Joshua; Griffiths, Thomas - Scaling up Psychology via Scientific Regret Minimization:A Case Study in Moral Decision-Making - 2019-10-16 - https://arxiv.org/abs/1910.07581
AI Impacts - AI Conference Attendance - 2019-03-06 - https://aiimpacts.org/ai-conference-attendance/
AI Impacts - Historical Economic Growth Trends - 2019-03-06 - https://aiimpacts.org/historical-growth-trends/
Alexander, Scott - Noisy Poll Results And Reptilian Muslim Climatologists from Mars - 2013-04-12 - https://slatestarcodex.com/2013/04/12/noisy-poll-results-and-reptilian-muslim-climatologists-from-mars/
Armstrong, Stuart - Research Agenda v0.9: Synthesising a human's preferences into a utility function - 2019-06-17 - https://www.lesswrong.com/posts/CSEdLLEkap2pubjof/research-agenda-v0-9-synthesising-a-human-s-preferences-into#comments
Armstrong, Stuart; Bostrom, Nick; Shulman, Carl - Racing to the precipice: a model of artificial intelligence development - 2015-08-01 - https://link.springer.com/article/10.1007%2Fs00146-015-0590-y
Armstrong, Stuart; Mindermann, Sören - Occam's razor is insufficient to infer the preferences of irrational agents - 2017-12-15 - https://arxiv.org/abs/1712.05812
Aschenbrenner, Leopold - Existential Risk and Economic Growth - 2019-09-03 - https://leopoldaschenbrenner.github.io/xriskandgrowth/ExistentialRiskAndGrowth050.pdf
Avin, Shahar - Exploring Artificial Intelligence Futures - 2019-01-17 - https://www.shaharavin.com/publication/pdf/exploring-artificial-intelligence-futures.pdf
Avin, Shahar; Amadae, S - Autonomy and machine learning at the interface of nuclear weapons, computers and people - 2019-05-06 - https://www.sipri.org/sites/default/files/2019-05/sipri1905-ai-strategic-stability-nuclear-risk.pdf
Baum, Seth - Risk-Risk Tradeoff Analysis of Nuclear Explosives for Asteroid Deflection - 2019-06-13 - https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3397559
Baum, Seth - The Challenge of Analyzing Global Catastrophic Risks - 2019-07-15 - https://higherlogicdownload.s3.amazonaws.com/INFORMS/f0ea61b6-e74c-4c07-894d-884bf2882e55/UploadedImages/2019_July.pdf#page=20
Baum, Seth; de Neufville, Robert; Barrett, Anthony; Ackerman, Gary - Lessons for Artificial Intelligence from Other Global Risks - 2019-11-21 - http://gcrinstitute.org/papers/lessons.pdf
Beard, Simon - Perfectionism and the Repugnant Conclusion - 2019-03-05 - https://link.springer.com/article/10.1007/s10790-019-09687-4
Beard, Simon - What Is Unfair about Unequal Brute Luck? An Intergenerational Puzzle - 2019-01-21 - https://www.cser.ac.uk/resources/brute-luck-intergenerational-puzzle/
Belfield, Haydn - How to respond to the potential malicious uses of artificial intelligence? - 2019-09-19 - https://www.cser.ac.uk/resources/how-respond-potential-malicious-uses-artificial-intelligence/
Bogosian, Kyle - On AI Weapons - 2019-11-13 - https://forum.effectivealtruism.org/posts/vdqBn65Qaw77MpqXz/on-ai-weapons
Brown, Noam; Sandholm, Tuomas - Superhuman AI for multiplayer poker - 2019-07-17 - https://www.cs.cmu.edu/~noamb/papers/19-Science-Superhuman.pdf
Caplan, Bryan - The Myth of the Rational Voter - 2008-08-24 - https://www.amazon.com/Myth-Rational-Voter-Democracies-Policies/dp/0691138737
Carey, Ryan - How useful is Quantilization for Mitigating Specification-Gaming - 2019-05-06 - https://www.fhi.ox.ac.uk/wp-content/uploads/SafeML2019_paper_40.pdf
Carroll, Micah; Shah Rohin; Mark K Ho, Griffiths, Tom; Seshia,Sanjit; Abbeel,Pieter; Dragan, Anca - On the Utility of Learning about Humansfor Human-AI Coordination - 2019-10-22 - http://papers.nips.cc/paper/8760-on-the-utility-of-learning-about-humans-for-human-ai-coordination.pdf
Cave, Stephen; Ó hÉigeartaigh, Seán - Bridging near- and long-term concerns about AI - 2019-01-07 - https://www.nature.com/articles/s42256-018-0003-2
Chan, Lawrence; Hadfield-Menell, Dylan; Srinivasa, Siddhartha; Dragan, Anca - The Assistive Multi-Armed Bandit - 2019-01-24 - https://arxiv.org/abs/1901.08654
Chivers, Tom - The AI Does Not Hate You: Superintelligence, Rationality and the Race to Save the World - 2019-06-13 - https://www.amazon.com/Does-Not-Hate-You-Superintelligence-ebook/dp/B07K258VCV
Christiano, Paul - AI alignment landscape - 2019-10-12 - https://ai-alignment.com/ai-alignment-landscape-d3773c37ae38
Christiano, Paul - What failure looks like - 2019-03-17 - https://www.alignmentforum.org/posts/HBxe6wdjxK239zajf/what-failure-looks-like
Cihon, Peter - Standards for AI Governance: International Standards to Enable Global Coordination in AI Research & Development - 2019-05-16 - https://www.fhi.ox.ac.uk/wp-content/uploads/Standards_-FHI-Technical-Report.pdf
Clark, Jack; Hadfield, Gillian - Regulatory Markets for AI Safety - 2019-05-06 - https://drive.google.com/uc?export=download&id=1bFPiwLrZc7SQTMg2_bW4gt0PaS5NyqOH
Cohen, Michael; Vellambi, Badri; Hutter, Marcus - Asymptotically Unambitious Artificial General Intelligence - 2019-05-29 - https://arxiv.org/abs/1905.12186
Collins, Jason - Principles for the Application of Human Intelligence - 2019-09-30 - https://behavioralscientist.org/principles-for-the-application-of-human-intelligence/
Colvin, R; Kemp, Luke; Talberg, Anita; De Castella, Clare ; Downie, C; Friel, S; Grant, Will; Howden, Mark; Jotzo, Frank; Markham, Francis; Platow, Michael - Learning from the Climate Change Debate to AvoidPolarisation on Negative Emissions - 2019-07-25 - https://sci-hub.tw/10.1080/17524032.2019.1630463
Cottier, Ben; Shah, Rohin - Clarifying some key hypotheses in AI alignment - 2019-08-15 - https://www.lesswrong.com/posts/mJ5oNYnkYrd4sD5uE/clarifying-some-key-hypotheses-in-ai-alignment
CSER - Policy series Managing global catastrophic risks: Part 1 Understand - 2019-08-13 - https://www.gcrpolicy.com/understand-overview
Cummings, Dominic - On the referendum #31: Project Maven, procurement, lollapalooza results & nuclear/AGI safety - 2019-03-01 - https://dominiccummings.com/2019/03/01/on-the-referendum-31-project-maven-procurement-lollapalooza-results-nuclear-agi-safety/
Dai, Wei - Problems in AI Alignment that philosophers could potentially contribute to - 2019-08-17 - https://www.lesswrong.com/posts/rASeoR7iZ9Fokzh7L/problems-in-ai-alignment-that-philosophers-could-potentially
Dai, Wei - Problems in AI Alignment that philosophers could potentially contribute to - 2019-08-17 - https://www.lesswrong.com/posts/rASeoR7iZ9Fokzh7L/problems-in-ai-alignment-that-philosophers-could-potentially
Dai, Wei - Two Neglected Problems in Human-AI Safety - 2018-12-16 - https://www.alignmentforum.org/posts/HTgakSs6JpnogD6c2/two-neglected-problems-in-human-ai-safety
Drexler, Eric - Reframing Superintelligence: Comprehensive AI Services as General Intelligence - 2019-01-08 - https://www.fhi.ox.ac.uk/wp-content/uploads/Reframing_Superintelligence_FHI-TR-2019-1.1-1.pdf?asd=sa
EU - Ethics Guidelines for Trustworthy Artificial Intelligence - 2019-04-08 - https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai
Everitt, Tom; Hutter, Marcus - Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective - 2019-08-13 - https://arxiv.org/abs/1908.04734
Everitt, Tom; Kumar, Ramana; Krakovna, Victoria; Legg, Shane - Modeling AGI Safety Frameworks with Causal Influence Diagrams - 2019-06-20 - https://arxiv.org/abs/1906.08663
Everitt, Tom; Ortega, Pedro; Barnes, Elizabeth; Legg, Shane - Understanding Agent Incentives using Causal Influence Diagrams. Part I: Single Action Settings - 2019-02-26 - https://arxiv.org/abs/1902.09980
Friedman, David D - Legal Systems Very Different from Ours - 1970-01-01 - https://www.amazon.com/Legal-Systems-Very-Different-Ours/dp/1793386722
Garfinkel, Ben & Dafoe, Allan - How does the offense-defense balance scale? - 2019-08-22 - https://www.tandfonline.com/doi/full/10.1080/01402390.2019.1631810
Greaves, Hilary; Cotton-Barratt, Owen - A bargaining-theoretic approach to moral uncertainty - 2019-08-09 - https://globalprioritiesinstitute.org/wp-content/uploads/2019/Greaves_Cotton-Barratt_bargaining_theoretic_approach.pdf
Grotto, Andy - Genetically Modified Organisms: A Precautionary Tale for AI Governance - 2019-01-24 - https://aipulse.org/genetically-modified-organisms-a-precautionary-tale-for-ai-governance-2/
Hernandez-Orallo, Jose; Martınez-Plumed, Fernando; Avin, Shahar; Ó hÉigeartaigh, Seán - Surveying Safety-relevant AI Characteristics - 2019-01-20 - http://ceur-ws.org/Vol-2301/paper_22.pdf
Hubinger, Evan; van Merwijk, Chris; Mikulik, Vladimir; Skalse, Joar; Garrabrant, Scott - Risks from Learned Optimization in Advanced Machine Learning Systems - 2019-06-05 - https://arxiv.org/abs/1906.01820
Irving, Geoffrey; Askell, Amanda - AI Safety Needs Social Scientists - 2019-02-19 - https://distill.pub/2019/safety-needs-social-scientists/
Irving, Geoffrey; Christiano, Paul; Amodei, Dario - AI Safety via Debate - 2018-05-02 - https://arxiv.org/abs/1805.00899
Kaczmarek, Patrick; Beard, Simon - Human Extinction and Our Obligations to thePast - 2019-11-05 - https://sci-hub.tw/https://www.cambridge.org/core/journals/utilitas/article/human-extinction-and-our-obligations-to-the-past/C29A0406EFA2B43EE8237D95AAFBB580
Kaufman, Jeff - Uber Self-Driving Crash - 2019-11-07 - https://www.jefftk.com/p/uber-self-driving-crash
Kemp, Luke - Mediation Without Measures: Conflict Resolution in Climate Diplomacy - 2019-05-15 - https://www.cser.ac.uk/resources/mediation-without-measures/
Kenton, Zachary; Filos, Angelos; Gal, Yarin; Evans, Owain - Generalizing from a few enviroments in Safety-Critical Reinforcement Learning - 2019-07-02 - https://arxiv.org/abs/1907.01475
Korzekwa, Rick - The unexpected difficulty of comparing AlphaStar to humans - 2019-09-17 - https://aiimpacts.org/the-unexpected-difficulty-of-comparing-alphastar-to-humans/
Kosoy, Vanessa - Delegative Reinforcement Learning: Learning to Avoid Traps with a Little Help - 2019-07-19 - https://arxiv.org/abs/1907.08461
Kovarik, Vojta; Gajdova, Anna; Lindner, David; Finnveden, Lukas; Agrawal, Rajashree - AI Safety Debate and Its Applications - 2019-07-23 - https://www.lesswrong.com/posts/5Kv2qNfRyXXihNrx2/ai-safety-debate-and-its-applications
Krakovna, Victoria - ICLR Safe ML Workshop Report - 2019-06-18 - https://futureoflife.org/2019/06/18/iclr-safe-ml-workshop-report/
Kruegar, David; Maharaj, Tegan; Legg, Shane; Leike, Jan - Misleading Meta-Objectives and Hidden Incentives for Distributional Shift - 2019-01-01 - https://drive.google.com/uc?export=download&id=1k93292JCoIHU0h6xVO3qmeRwLyOSlS4o
Kumar, Ram Shankar Siva; O'Brien, David; Snover, Jeffrey; Albert, Kendra; Viloen, Salome - Failure Modes in Machine Learning - 2019-11-10 - https://docs.microsoft.com/en-us/security/failure-modes-in-machine-learning
LeCun, Yann; Russell, Stuart; Bengio, Yoshua; Olds, Elliot; Zador, Tony; Rossi, Francesca; Mallah, Richard; Barzov, Yuri - Debate on Instrumental Convergence between LeCun, Russell, Bengio, Zador, and More - 2019-10-04 - https://www.lesswrong.com/posts/WxW6Gc6f2z3mzmqKs/debate-on-instrumental-convergence-between-lecun-russell
Lewis, Sophie; Perkins-Kirkpatrick, Sarah; Althor, Glenn; King, Andrew; Kemp, Luke - Assessing contributions of major emitters' Paris‐era decisions to future temperature extremes - 2019-03-20 - https://www.cser.ac.uk/resources/assessing-contributions-extremes/
Long, Robert; Bergal, Asya - Evidence against current methods leading to human level artificial intelligence - 2019-08-12 - https://aiimpacts.org/evidence-against-current-methods-leading-to-human-level-artificial-intelligence/
Long, Robert; Davis, Ernest - Conversation with Ernie Davis - 2019-08-23 - https://aiimpacts.org/conversation-with-ernie-davis/
Macaskill, Will; Demski, Abram - A Critique of Functional Decision Theory - 2019-09-13 - https://www.lesswrong.com/posts/ySLYSsNeFL5CoAQzN/a-critique-of-functional-decision-theory
MacAskill, William; Vallinder, Aron; Oesterheld, Caspar; Shulman, Carl; Treutlein, Johannes - The Evidentialist's Wager - 2019-11-19 - https://globalprioritiesinstitute.org/the-evidentialists-wager/
Majha, Arushi; Sarkar, Sayan; Zagami, Davide - Categorizing Wireheading in Partially Embedded Agents - 2019-06-21 - https://arxiv.org/abs/1906.09136
Maltinsky, Baeo; Gallagher, Jack; Taylor, Jessica - Feasibility of Training an AGI using Deep RL:A Very Rough Estimate - 2019-03-24 - http://mediangroup.org/docs/Feasibility%20of%20Training%20an%20AGI%20using%20Deep%20Reinforcement%20Learning,%20A%20Very%20Rough%20Estimate.pdf
Mancuso, Jason; Kisielewski, Tomasz; Lindner, David; Singh, Alok - Detecting Spiky Corruption in Markov Decision Processes - 2019-06-30 - https://arxiv.org/abs/1907.00452
Marcus, Gary - Deep Learning: A Critical Appraisal - 2018-01-02 - https://arxiv.org/ftp/arxiv/papers/1801/1801.00631.pdf
McCaslin, Tegan - Investigation into the relationship between neuron count and intelligence across differing cortical architectures - 2019-02-11 - https://aiimpacts.org/investigation-into-the-relationship-between-neuron-count-and-intelligence-across-differing-cortical-architectures/
Mogensen, Andreas - ‘The only ethical argument for positive 𝛿 ’? - 2019-01-01 - https://globalprioritiesinstitute.org/andreas-mogensen-the-only-ethical-argument-for-positive-delta-2/
Mogensen, Andreas - Doomsday rings twice - 2019-01-01 - https://globalprioritiesinstitute.org/andreas-mogensen-doomsday-rings-twice/
Naude, Wim; Dimitri, Nicola - The race for an artificial general intelligence: implications for public policy - 2019-04-22 - https://link.springer.com/article/10.1007%2Fs00146-019-00887-x
Ngo, Richard - Technical AGI safety research outside AI - 2019-10-18 - https://forum.effectivealtruism.org/posts/2e9NDGiXt8PjjbTMC/technical-agi-safety-research-outside-ai
O'Keefe, Cullen - Stable Agreements in Turbulent Times: A Legal Toolkit for Constrained Temporal Decision Transmission - 2019-05-01 - https://www.fhi.ox.ac.uk/wp-content/uploads/Stable-Agreements.pdf
Ovadya, Aviv; Whittlestone, Jess - Reducing Malicious Use of Synthetic Media Research: Considerations and Potential Release Practices for Machine Learning - 2019-07-29 - https://arxiv.org/abs/1907.11274
Owain, Evans; Saunders, William; Stuhlmüller, Andreas - Machine Learning Projects for Iterated Distillation and Amplification - 2019-07-03 - https://owainevans.github.io/pdfs/evans_ida_projects.pdf
Perry, Brandon; Uuk, Risto - AI Governance and the Policymaking Process: Key Considerations for Reducing AI Risk - 2019-05-08 - https://www.mdpi.com/2504-2289/3/2/26/pdf
Piper, Kelsey - The case for taking AI seriousl as a threat to humanity - 2018-12-21 - https://www.vox.com/future-perfect/2018/12/21/18126576/ai-artificial-intelligence-machine-learning-safety-alignment
Quigley, Ellen - Universal Ownership in the Anthropocene - 2019-05-13 - https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3457205
Roy, Mati - AI Safety Open Problems - 2019-11-02 - https://docs.google.com/document/d/1J2fOOF-NYiPC0-J3ZGEfE0OhA-QcOInhlvWjr1fAsS0/edit
Russell, Stuart - Human Compatible; Artificial Intelligence and the Problem of Control - 2019-10-08 - https://www.amazon.com/Human-Compatible-Artificial-Intelligence-Problem/dp/0525558616/ref=sr_1_2?keywords=Stuart+Russell&qid=1565996574&s=books&sr=1-2
Schwarz, Wolfgang - On Functional Decision Theory - 2018-12-27 - https://www.umsu.de/blog/2018/688
Sevilla, Jaime; Moreno, Pablo - Implications of Quantum Computing for Artificial Intelligence alignment research - 2019-08-19 - https://arxiv.org/abs/1908.07613
Shah, Rohin; Gundotra, Noah; Abbeel, Pieter; Dragan, Anca - On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference - 2019-06-23 - https://arxiv.org/abs/1906.09624
Shah, Rohin; Krasheninnikov, Dmitrii; Alexander Jordan; Abbeel, Pieter; Dragan, Anca - Preferences Implicit in the State of the World - 2019-02-12 - https://arxiv.org/abs/1902.04198
Shulman, Carl - Person-affecting views may be dominated by possibilities of large future populations of necessary people - 2019-11-30 - http://reflectivedisequilibrium.blogspot.com/2019/11/person-affecting-views-may-be-dominated.html
Snyder-Beattie, Andrew; Ord, Toby; Bonsall, Michael - An upper bound for the background rate of human extinction - 2019-07-30 - https://www.nature.com/articles/s41598-019-47540-7
Steiner, Charlie - Some Comments on Stuart Armstrong's "Research Agenda v0.9" - 2019-08-08 - https://www.lesswrong.com/posts/GHNokcgERpLJwJnLW/some-comments-on-stuart-armstrong-s-research-agenda-v0-9
Steinhardt, Jacob - AI Alignment Research Overview - 2019-10-14 - https://rohinshah.us18.list-manage.com/track/click?u=1d1821210cc4f04d1e05c4fa6&id=1a148ef72c&e=1e228e7079
Sterbenz, Ciara; Trager, Robert - Autonomous Weapons and Coercive Threats - 2019-02-06 - https://aipulse.org/autonomous-weapons-and-coercive-threats/
Sutton, Rich - The Bitter Lesson - 2019-03-13 - http://www.incompleteideas.net/IncIdeas/BitterLesson.html
Szlam et al. - Why Build an Assistant in Minecraft? - 2019-07-19 - https://arxiv.org/abs/1907.09273
Taylor, Jessica - - 1900-01-00 - https://www.aaai.org/ocs/index.php/WS/AAAIW16/paper/view/12613
Taylor, Jessica - The AI Timelines Scam - 2019-07-11 - https://unstableontology.com/2019/07/11/the-ai-timelines-scam/
Taylor, Jessica; Gallagher, Jack; Maltinsky, Baeo - Revisting the Insights model - 2019-07-20 - http://mediangroup.org/insights2.html
The AlphaStar Team - AlphaStar: Mastering the Real-Time Strategy Game StarCraft II - 2019-01-24 - https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
Turner, Alexander; Dadfield-Menell, Dylan; Tadepalli, Prasad - Conservative Agency - 2019-02-26 - https://arxiv.org/abs/1902.09725
Tzachor, Asaf - The Future of Feed: Integrating Technologies to Decouple Feed Production from Environmental Impacts - 2019-04-23 - https://www.liebertpub.com/doi/full/10.1089/ind.2019.29162.atz
Useato, Jonathan; Kumar, Ananya; Szepesvari, Csaba; Erex, Tom; Ruderman, Avraham; Anderson, Keith; Dvijotham, Krishmamurthy; Heess, Nicolas; Kohli, Pushmeet - Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures - 2018-12-04 - https://arxiv.org/abs/1812.01647
USG - National Security Commission on Artificial Intelligence Interim Report - 2019-11-01 - https://drive.google.com/file/d/153OrxnuGEjsUvlxWsFYauslwNeCEkvUb/view
Walsh, Bryan - End Times: A Brief Guide to the End of the World - 2019-08-27 - https://smile.amazon.com/End-Times-Brief-Guide-World-ebook/dp/B07J52NW99/ref=tmm_kin_swatch_0?_encoding=UTF8&qid=&sr=
Weitzdörfer & Julius, Beard & Simon - Law and Policy Responses to Disaster-Induced Financial Distress - 2019-11-24 - https://sci-hub.tw/10.1007/978-981-13-9005-0
Whittlestone, Jess; Nyrup, Rune; Alexandrova, Anna; Cave, Stephen - The Role and Limits of Principles in AI Ethics: Towards a Focus on Tensions - 2019-01-27 - http://lcfi.ac.uk/media/uploads/files/AIES-19_paper_188_Whittlestone_Nyrup_Alexandrova_Cave_OcF7jnp.pdf
Zabel, Claire; Muehlhauser, Luke - Information security careers for GCR reduction - 2019-06-20 - https://forum.effectivealtruism.org/posts/ZJiCfwTy5dC4CoxqA/information-security-careers-for-gcr-reduction
Zhang, Baobao; Dafoe, Allan - Artificial Intelligence: American Attitudes and Trends - 2019-01-15 - https://governanceai.github.io/US-Public-Opinion-Report-Jan-2019/
My commendations on another detailed and thoughtful review. A few reactions (my views, not GCRI's):
Actually, a lot of scientists & engineers in nuclear power are not happy about the strict regulations on nuclear power. Note, I've been exposed to this because my father worked as an engineer in the nuclear power industry, and I've had other interactions with it through my career in climate change & risk analysis. Basically, widespread overestimation of the medical harms from radiation has caused nuclear power to be held to a much higher standard than other sources, especially fossil fuels.
A better example would be recombinant DNA - see Katja Grace's very nice study of it. The key point is the importance of the scientists/engineers buying into the regulation. This is consistent with other work I'm familiar with on risk regulation etc., and with work I've published, e.g. this and this.
More precisely, the distinction is between issues that matter to voters in elections (plus campaign donors etc.) and issues that fly more under the radar. For now at least, AI still flies under the radar, creating more opportunity for expert insiders (like us) to have significant impact, as do most other global catastrophic risks. The big exception is climate change. (I'm speaking in terms of US politics/policy. I don't know about other countries.)
This depends on the policy. A lot of policy is not about restricting AI, but instead about coordination, harmonizing standards, ensuring quality applications, setting directions for the field, etc. That said, it is definitely important to factor the reactions of AI communities into policy outreach efforts. (As I have been pushing for in e.g. the work referenced above.)
It varies from case to case. For a lot of research, the primary audience is other researchers/experts in the field. They generally have access to paywall journals and place significant weight on journal quality/prestige. Also open access journals typically charge author publication fees, generally in the range of hundreds to thousands of dollars. That raises the question of whether it's a good use of funds. I'm not at all against open access (I like open access!); I only mean to note that there are other factors that may make it not always the best option.
Again it depends. Mass-market books typically get a lot more attention when they're from a major publisher. These books are more than just books - they are platforms for a lot of attention and discussion. If e.g. Bostrom had self-published Superintelligence, it probably wouldn't have gotten nearly the same attention. Also good publishers have editors who improve the books, and that costs money. I see a stronger case for self-publishing technical reports that have a narrower audience, especially if the author and/or their organization have the resources to do editing, page layout, promotion, etc.
Yes, definitely! I for one frequent the websites of peer organizations, and often wish they were more up to date.
I might worry that this could bias the field away from more senior people who may have larger financial responsibilities (family, mortgage, etc.) and better alternative opportunities for income. There's no guarantee that future donations will be made, which creates a risk for the worker even if they're doing excellent work.
Peer review should filter out bad/unoriginal research, sort it by topic (journal X publishes on topic X etc.), and improve papers via revision requests. Good journals do this. Not all journals are good. Overall I for one find significantly better quality work in peer reviewed journals (especially good journals) than outside of peer review.
I can't speak to concerns about the Bay Area, but I can say that GCRI has found a lot of value in connecting with people outside the usual geographic hubs, and that this is something ripe for further investment in (whether via GCRI or other entities). See e.g. this on GCRI's 2019 advising/collaboration program, which we're continuing in 2020.
A bit of a tangent. I am confused by SFF's grant to OAK (Optimizing Awakening and Kindness). Could any recommender comment on its purpose or at least briefly describe what OAK is about as the hyperlink is not very informative.
OAK intends to train people who are likely to have important impacts on AI, to help them be kinder or something like that. So I see a good deal of overlap with the reasons why CFAR is valuable.
I attended a 2-day OAK retreat. It was run in a professional manner that suggests they'll provide a good deal of benefit to people who they train. But my intuition is that the impact will be mainly to make those people happier, and I expect that OAK's impact will have less effect on peoples' behavior than CFAR has.
I considered donating to OAK as an EA charity, but have decided it isn't quite effective enough for me to treat it that way.
I believe that the person who promoted that grant at SFF has more experience with OAK than I do.
I'm surprised that SFF gave more to OAK than to ALLFED.
Peter, thank you! I am slightly confused by your phrasing.
To benchmark, would you say that
Nearly all of CFAR's activity is motivated by their effects on people who are likely to impact AI. As a donor, I don't distinguish much between the various types of workshops.
There are many ways that people can impact AI, and I presume the different types of workshop are slightly optimized for different strategies and different skills, and differ a bit in how strongly they're selecting for people who have a high probability of doing AI-relevant things. CFAR likely doesn't have a good prediction in advance about whether any individual person will prioritize AI, and we shouldn't expect them to try to admit only those with high probabilities of working on AI-related tasks.
Thank you, Peter. If you are curious Anna Salamon connected various types of activities with CFAR's mission in the recent Q&A.
I was a recommender for the round, but did not recommend a grant to OAK, so I sadly can't speak to it. I think to get more detailed reasoning on this, you would have to get an answer from the specific recommenders who made that grant. However, if you can't get ahold of them, I can probably give a somewhat bad summary of their views, though I think it would be better to hear things directly from them.
You listed important considerations; here are some additional points to consider:
1. As suggested in SethBaum's comment, a short runway may deter people from joining the org (especially people with larger personal financial responsibilities and opportunity cost).
2. It seems likely that—all other things being equal—orgs with a longer runway are "less vulnerable to Goodhart's law" and generally less prone to optimize for short-term impressiveness in costly ways. Selection effects alone seem sufficient to justify this belief: Orgs with a short runway that don't optimize for short-term impressiveness seem less likely to keep on existing.
Some minor clarifications for the Long Term Future Fund section (Larks did reach out to us and ask for feedback, though it looks like not all of our corrections made it into the final version). [Correction: We hadn't actually send the relevant corrections back yet, so this is not Lark's fault. Sorry for that!]
The thing as written is correct, but I want to clarify that CEA did not reject the grant, but was still in the process of deciding whether to approve the grant, when a private donor stepped in. I expect that CEA would have eventually approved this grant, though there is definitely still some uncertainty in that.
This is correct as written, but I think I want to clarify what is meant by resubmission here:
We’ve had a few grants that have run into logistical difficulties (like there not being a clear way to make this grant compatible with CEA’s charitable objectives), and in cases like this we’ve worked with the potential grantee to resolve those issues. I think that support we provide should be independent from the evaluations of grants that we make, and I don’t think we should reject grants because of logistical issues like that, if they are easily fixable.
The Lauren Lee grant ran into some issues in this space that took a while to resolve, so CEA ended up only properly evaluating the grant in the round following the one in which we recommended it, and then subsequently rejected it. The “resubmission” in that sense shouldn’t be seen as an additional strong endorsement of the grant, but is just a thing that could happen to any grant and I think doesn’t say much about how good we thought the grant was, after we had made the decision to recommend the grant.
We were about to send Larks an updated version of the geography data before this post went up. Here is a graph with my best guesses (this includes all recommendations we made, even for grants that didn't end up going through):
And here is one excluding the three grants that ended up being covered by private donors:
[Edit Note: I briefly had a version of the comment up that showed the geographic distribution by count instead of by grant amount. This is now fixed.]
Also, obviously. Thank you a lot for writing this review. As someone with a strong interest in having good public discourse around AI Alignment, I am deeply grateful for all of your work on this, and deeply appreciate the care and effort that goes into these reviews and the effects it has on people trying to successfully navigate the growing AI Alignment landscape.
If I'm understanding the categories correctly, I agree here.
I agree. I think part of the equation is that peer review does not just filter papers "in" or "out" - it accepts them to a journal of a certain quality. Many bad papers will get into weak journals, but will usually get read much less. Researchers who read these papers cite them, also taking into account to their quality, thereby boosting the readership of good papers. Finally, some core of elite researchers bats down arguments that due to being weirdly attractive yet misguided, manage to make it through the earlier filters. I think this process works okay in general, and can also work okay in AI safety.
I do have some ideas for improving our process though, basically to establish a steeper incentive gradient for research quality (in the dimensions of quality that we care about): (i) more private and public criticism of misguided work, (ii) stronger filters on papers being published in safety workshops, probably by agreeing to have fewer workshops, with fewer papers, and by largely ignoring any extra workshops from "rogue" creators, and (iii) funding undersupervised talent-pipeline projects a bit more carefully.
Svygrevat ~100 nccyvpnagf qbja gb n srj npprcgrq fpubynefuvc erpvcvragf vf abg gung qvssrerag gb jung PUNV naq SUV nyernql qb va fryrpgvat vagreaf. Gur rkcrpgrq bhgchgf frrz ng yrnfg pbzcnenoyl-uvtu. Fb V guvax pubbfvat fpubynefuvc erpvcvragf jbhyq or fvzvyneyl tbbq inyhr va grezf bs rinyhngbef' gvzr, naq nyfb n cerggl tbbq hfr bs shaqf.
--
It's an impressive effort as in previous years! One meta-thought: if you stop providing this service at some point, it might be worth reaching out to the authors of the alignment newsletter, to ask whether they or anyone they know would jump in to fill the breach.
Thanks for writing this up Larks! A highlight of the year, as always.
Why isn't there a GiveWell-style evaluator for longtermist (or specifically AI safety) orgs?
I'd guess it's because it's very hard to apply a GiveWell approach (i.e. explicit quantitative modeling based on a substantial body of empirical evidence) to many long-termist orgs (whose impacts will often definitionally be unknown for the foreseeable future, and around which there is large and pervasive uncertainty). Open Philanthropy describes an evaluation methodology that seems more suited to long-termist orgs.
Do you have a take about why universal investors tend to support competition, in practice?
Want to signal-boost this. It's a big, big deal. Probably the most important EA / rationalist thing that happened this decade (in terms of discrete events, harder to say for trends).
See also Cummings' High-performance government.
Worth noting the changes that are apparently going to be made in the UK civil service, likely by Cummings' design, and which seem quite compatible with a lot of rationalist thinking.
https://twitter.com/JohnRentoul/status/1212486981713899520
More on this, hot off the presses: https://dominiccummings.com/2020/01/02/two-hands-are-a-lot-were-hiring-data-scientists-project-managers-policy-experts-assorted-weirdos/ (a)
Curious why CFAR wasn't included in the review as a standalone org, given your high opinion of AIRCS workshops?
Some more context in this comment.
On MIRI's finances:
I was surprised to see such a big increase between 2018 & 2019.
Also, $6M for 18 staff seems quite high in absolute terms (~$333,000 per capita).
But I don't have complete information here + have pretty coarse models about all the costs concomitant with administering a nonprofit research org.
Do you have any more information about their finances, why they increased so much from 2018 to 2019, and where the money is going?
(I'm COO at MIRI.)
Just wanted to provide some info that might be helpful:
Thanks!
Were most of the 12 new staff onboarded early enough in 2019 such that it makes sense to include them in a 2019 per capita expenditure estimate?
Thanks for the pointer – this is helpful.
It includes things like, rent, utilities, general office expenses, furnishings/equipment, bank/processing fees, software/services, insurance, bookkeeping/accounting, visas/legal. The largest expense that makes up the estimated ~$0.8M is rent, which accounts for just over half.
No, that will be an over estimate for a few reasons:
We added 8 new staff in 2019. When I make our spending estimates, I assume new staff are added evenly throughout the year, i.e., I assume the spending on all new staff in a given year will be ~50% of their total annual cost. In practice given that we aren't talking about very large numbers here the accuracy of that estimate varies quite a bit. The distributions of when new staff were added in 2019 was pretty centered on the middle of the year, though salary level of those staff will likely complicate things here (I haven't run those numbers.)
Got it. Is ~$142,000 per employee closer to what MIRI is estimating for 2020 compensation expenditure?
(Removing the $0.51M term entirely, removing $0.56M from the Research Personnel estimate to account for interns & contractors, and adding one new ops employee to the denominator gives ($3M + $1.4M) / 31 employees = $142k per employee)
Yeah, that should be a reasonably good estimate.
Ought recently published a technical progress update on their recent research.
Thanks for this - this seems a very valuable service, and will inform my donations. (Though it's harder to say what counterfactual influence it'll have, given I was already likely to donate to some of the organisations/funders you speak highly of and suggest you'll likely donate to.)
One question/nit-pick: In the discussion of Zabel & Muehlhauser's post, you write "Researchers from Google Brain were also named authors on the paper." Is that accurate? It seems to me that only Zabel & Muehlhauser are listed as authors of that post, and Google Brain itself (as opposed to Google more generally) isn't mentioned anywhere in the post. (But maybe I'm missing/misunderstanding something.)