The most important questions in forecasting tend to resist precise definitions — questions like, “Will we be ready for AGI when it arrives?” or “How are China’s AI capabilities trending overall?” These big-picture questions are more consequential than “How will Alibaba’s Qwen model perform on the Chatbot Arena,” but where would you even begin to operationalize a thing like AGI readiness in any rigorous way?
We’re experimenting with an idea that bypasses this issue, which we’re calling: Indexes.
An index takes a vague question, like “How ready will we be for AGI in 2030?” and gives a quantitative answer on a -100 to 100 scale. We get this quantitative answer by taking forecasts on a set of questions, identified by the index author (a person or group) as collectively pointing at a nebulous but important concept like AGI readiness, and combining them into a single dimensionless number. The index author assigns a weight to each question indicating a) how informative they are relative to one another and b) whether learning that the resolution is Yes or No should make the Index go up or down. What you see when you look at a Metaculus Index, then, is in some sense a forecast of what the Index will be when all the questions are resolved. When the index goes up, that means forecasters believe, as a whole, things are looking better for 2030 than they previously expected.
Enough theory. We’ve launched our flagship index, which you can forecast on now: AGI Readiness Index
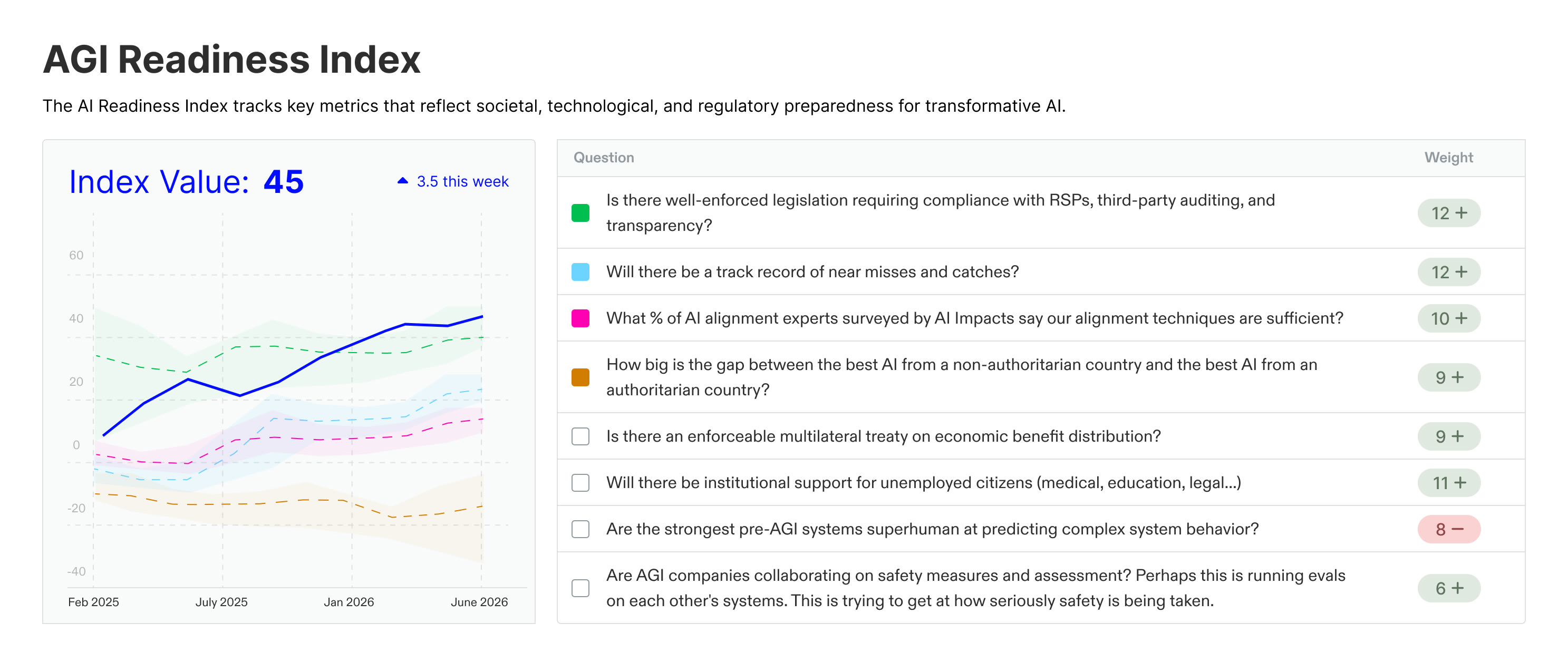
The questions and weights in this figure are the preliminary results of a workshop we conducted at The Curve in November. We asked each participant to answer the prompt:
Assume AGI arrives in 2030. If you could ask an oracle three questions about the world right before AGI arrives, what would they be?
The rest of the workshop was spent specifying and winnowing the questions until finally we had a set of eight questions that were rated most informative by participants. There was, of course, disagreement — about how likely a question was to resolve positively (after all, if you think you know what the answer will be, that would be a waste of an oracle question), about how correlated questions were with each other (i.e. you want a set of questions that are as complementary / independent from each other as possible), and about what constituted readiness. Once we had all the questions on the table, participants had the opportunity to critique and defend each other’s questions, and finally assign weights. Each participant had ten points to distribute, at which point eight questions emerged as the key axes of readiness. Tied in first were legislation requiring compliance with RSPs, third-party auditing, and transparency; and a public list of incidents related to AI safety.
We hope you disagree with these weights! It would be a sorry index that received no push-back. What questions are missing? Our dream is for indexes to be a forum to talk about the big picture. Where do we see ourselves in 2030? Are we headed in the right direction? How would we know? At the time of writing, we have two indexes in the pipeline: AI for Public Good, in collaboration with AI Palace, and a China Capabilities Index, with the Simon Institute for Longterm Governance.
Do you have an idea for an index? Get in touch!
Credits
This project is partly inspired by the Forecasting Research Institute’s report Conditional Trees: A Method for Generating Informative Questions about Complex Topics, which presents a metric and method for identifying “high-value” forecasting questions with respect to an ultimate question. Our goal here is to curate these questions quickly, without putting the index author through the exercise of conditional forecasting and without necessarily having to strictly define the ultimate question. There’s nothing stopping the question weights in an index from being based on a quantitative metric like value of information, but they can also be less rigorous, or even completely "vibes-based."
We’ve also been heavily influenced by Cultivate Labs’ Issue Decomposition approach, used by the RAND Forecasting Initiative, in which top-level questions are broken down into drivers, sub-drivers, and finally forecasting questions aka "signals." Our indexes are one way to recompose forecasting questions into something that can inform strategy and give us a look at the overall trajectory.

Executive summary: The concept of "Indexes" is introduced as a method to quantify vague yet crucial forecasting questions, such as AGI readiness, by aggregating weighted answers to a curated set of sub-questions, enabling actionable insights into nebulous topics.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.