Comments
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...

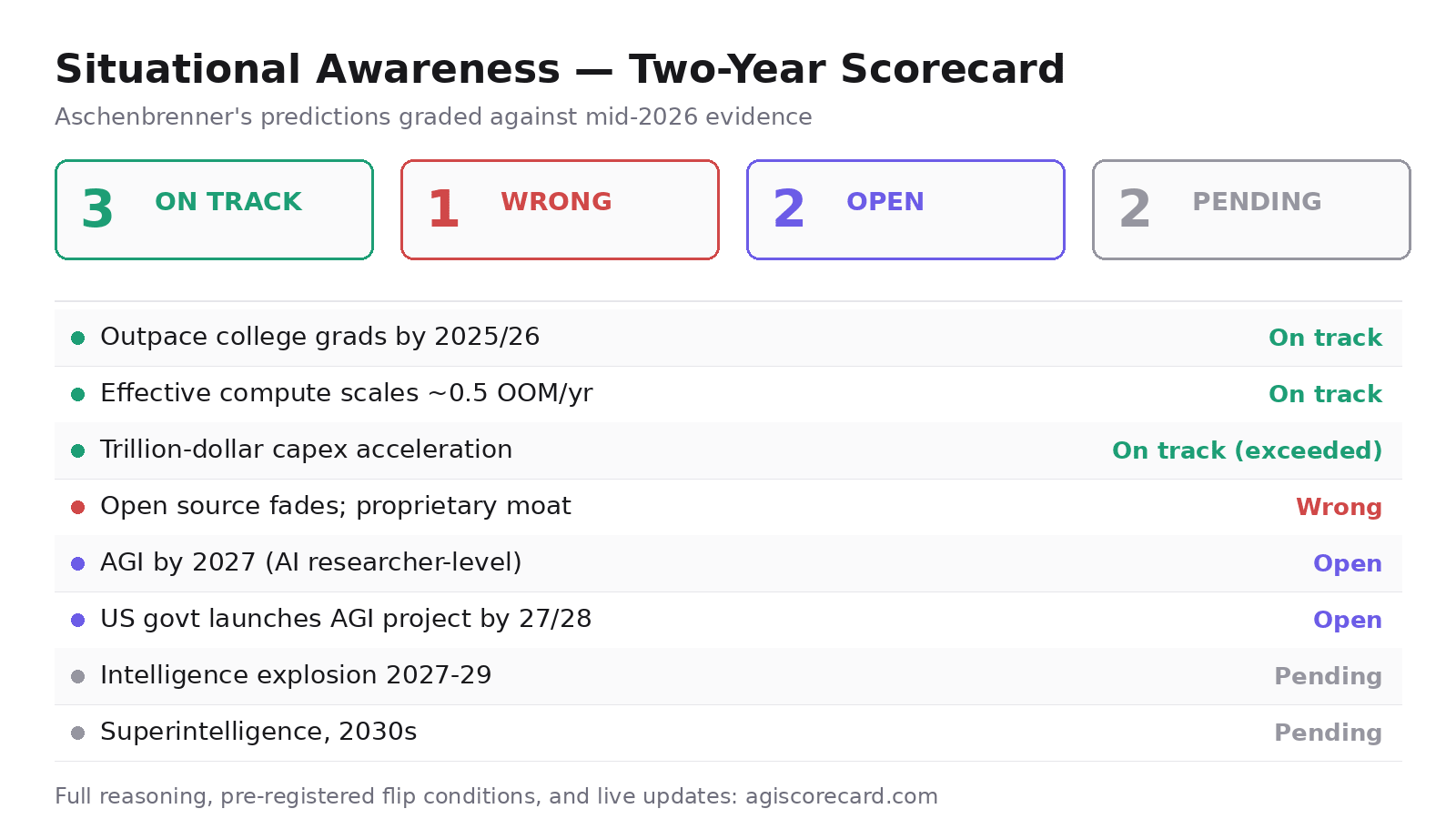
tl;dr: Two years after Situational Awareness predicted AGI by 2027, I graded its major predictions against mid-2026 evidence: 3 on track, 1 clearly wrong, 2 open, 2 too early to grade. The clearest miss — open-source models fading — has underappreciated implications for the essay's geopolitical core. I also pre-register what evidence would flip each verdict, and maintain a continuously-updated version at agiscorecard.com. I'd value scrutiny of the grading.
(This expands on a comment I left on Jamie's evaluation last week — several replies there pushed me to write up the full reasoning.)
Two excellent evaluations already exist: Nathan Delisle's one-year quantitative audit (June 2025), which checked the OOM math driver-by-driver, and Jamie Harris's two-year evaluation on the EA Forum (March 2026), which covered the full breadth of claims.
Both are point-in-time snapshots. This post tries to add three things: (1) a verdict-level scorecard at the exact two-year mark (the essay was published June 2024), (2) explicit, pre-registered criteria for what would change each verdict, and (3) calibration context — where Aschenbrenner's timeline sits relative to other public forecasters.
Disclosure: I built and maintain the scorecard site linked above, so I have an obvious interest in it being seen. The verdicts below are the substance; the site is just where they get updated.
Each prediction gets one of four grades:
A note on charity: where the essay's claim is ambiguous, I grade the reading that I believe a careful 2024 reader would have taken away, not the most defensible retreat available in hindsight. This choice does real work in the one "Wrong" verdict, and I flag it there.
| Prediction | Evidence as of mid-2026 | Verdict |
|---|---|---|
| Models outpace college graduates across knowledge work by 2025/26 | Frontier models score ~83% on knowledge-work benchmarks (GPT-5.4 on GDPval); agentic coding ~80% on SWE-Bench Pro (Claude Fable 5); agent products in production use | On track |
| Effective compute scales ~0.5 OOM/yr (compute) + ~0.5 OOM/yr (algorithms) | Delisle's audit found the pace "roughly supported," with individual launches scattered ±0.5 OOM around the trendline | On track |
| Massive capex acceleration toward trillion-dollar scale | Investment has run ahead of his projections; this is his most clearly vindicated claim | On track (exceeded) |
| Open source fades; proprietary algorithms create a durable US moat | DeepSeek V4 and Qwen 3.7 Max sit ~3–6 months behind the proprietary frontier, at a fraction of the price, with genuine architectural innovation | Wrong |
| AGI by 2027: models do the work of an AI researcher/engineer | Agentic coding is strong, but autonomous end-to-end research remains undemonstrated; 18 months left on the clock | Open |
| US government launches a formal AGI project by 27/28 | National-security involvement is growing; no Project; deadline not yet elapsed | Open |
| Intelligence explosion 2027–29 | — | Pending |
| Superintelligence and decisive advantage, 2030s | — | Pending |
Two claims I'm deliberately not grading as wins despite favorable headlines: AI revenue (tracking meaningfully behind his ~$100B-run-rate sketch — Harris's March 2026 evaluation put the most generous figure at ~$60B, while spring-2026 lab reporting has OpenAI at ~$25B+ and Anthropic at ~$19–20B annualized; behind on any of these accountings) and the "shocking qualitative leap" framing (benchmarks were met, but Harris's evaluation notes the felt discontinuity hasn't landed as described). Both cut against grade inflation in his favor.
The open-source verdict is the one I expect the most pushback on, so here is the reasoning in full.
The essay's geopolitical architecture rests on a specific premise: algorithmic secrets and model weights are the crown jewels; whoever locks them down converts compute concentration into durable national advantage. "Lock Down the Labs" is a third of the essay's policy program.
What happened instead: capable AI diffused. DeepSeek shipped genuine architectural advances (Epoch characterizes MLA and fine-grained MoE as real innovations, not just distillation), open-weight models compressed the frontier gap to months, and pricing collapsed. Distillation allegations are credible and muddy the attribution — but they strengthen rather than rescue the original claim, because a world where frontier capability can be cheaply distilled is precisely a world where the proprietary moat doesn't hold.
The downstream implication: if intelligence is cheap and diffuse, compute concentration buys less geopolitical advantage than the essay's model assumes, and the arms-race logic that motivates The Project weakens. Commenters on Jamie's thread here (huw, JoshYou) have pushed on this from both directions, and I think it's the most underexplored consequence of how the last two years actually went.
The steelman against my grade: Aschenbrenner's claim could be read narrowly — that the very frontier stays proprietary, which remains true. I grade against the broader reading because the essay's policy conclusions (security as national priority, weights as state secrets) depend on the broader version. If you think that's miscalibrated, that's exactly the argument I want to have.
| Forecaster | AGI timeline | Note |
|---|---|---|
| Elon Musk (xAI) | By end of 2026 | Most aggressive public claim |
| Leopold Aschenbrenner | 2027 "strikingly plausible" | The subject of this scorecard |
| Demis Hassabis (DeepMind) | ~50% by 2030 | Cautious lab leader |
| Samotsvety | ~28% by 2030 | Strongest forecasting track record |
| Metaculus community | 25% by 2029 · 50% by 2033 | Feb 2026 update, ~2,000 forecasters |
| Andrej Karpathy | ~A decade out | Architecture skeptic |
| AI researcher survey (n=2,778) | 50% by 2040 | Academic median |
Definitions vary enough that this is approximate. The meta-observation: expert medians have compressed from roughly 2060 to roughly 2033 in six years. Aschenbrenner sits well inside the aggressive tail, but the whole distribution has been moving toward him.
To keep myself honest, the conditions under which I'd change grades:
Verdict-level grading compresses real uncertainty; reasonable people can draw the On-track/Open line differently. My evidence base is public reporting and the two prior evaluations, not lab-internal data. And there's an unavoidable selection effect: the predictions easiest to grade are the ones that were most concrete, which biases any scorecard toward the quantitative claims and away from the strategic ones that may matter more.
The scorecard updates as models ship and verdicts change, with a changelog: agiscorecard.com. If you disagree with a grade, the comments here are the right venue — the grading only has value if it survives scrutiny from this forum.
Disclosure on process, in the same spirit as Harris's evaluation: research and drafting were substantially assisted by Claude, including the evidence-gathering behind each verdict. I directed the framing, reviewed the sources, and I'm responsible for the grades as published — if one is wrong, that's on me, and I'll change it.


I think you could argue that "open source fades, propreitary moat" is a miss but not a clear miss. Yes there is a proliferation of decent open source models, but they are waaaaaay behind the fronteir and considering the money that's pouring into the frontier companies, investors clearly think propreitary has a moat.
If the arms race argument is the central argument, I would argue that there is a clear moat. The open source models are not close enough to the frontier to reduce the urgency of an arms race.
This is a fair push, and it splits into two questions that I think have different answers.
On "miss vs clear miss": I take the point. My "Wrong" is graded against the specific claim that open source would fade — and 3-6 months behind frontier, with the pricing collapse, is the opposite of fading. But you're right that "fade" and "no durable moat" aren't the same proposition, and a reader could reasonably hold that the first is wrong while the second is open. I'd defend "clear miss" on the narrow wording but I won't pretend the margin is huge — which is exactly why it's the one verdict with an explicit flip condition (back to Open if the gap re-widens past ~18 months for two straight generations).
On the arms-race / moat point — this is the more interesting one, and I think we're partly talking past each other. "Investors think proprietary has a moat" and "there is a moat that reduces arms-race urgency" can both be true or both be false independently. Capex pouring in is consistent with a capability lead (frontier labs ship first) without implying a diffusion moat (the lead staying scarce). Aschenbrenner's geopolitical argument needs the second, not the first — the worry was that locking down weights/algorithms denies adversaries the capability. If a near-frontier open model is downloadable months later, the lockdown buys time, not denial. So I'd actually frame your closing line as the open question rather than the settled one: are the open models close enough to change arms-race urgency? I think mid-2026 evidence leans yes more than the 2024 essay assumed, but I hold that loosely and it's the part I'd most like to be wrong about.
Where would you put the gap that would make you say the moat is real — months, or capability tiers?