Comments
I was excited to hear about this "Claude Corps" initiative for NGOs, which helps orgs supercharge their benefits from AI then gutted to hear that its only going to be in the USA. Apparently they want to extend it overseas later, but the impact an intern li this could have right now for orgnisations like us at OneDay Health in Uganda would be mind-blowing. I hope they can expand the program overseas sooner rather than later!
- 150 million dollar program
- Intern works for 12 months with the NGO to supercharge AI use
- $85,000 payment to intern for the year
https://www.anthropic.com/news/claude-corps
Has anyone talked with/lobbied the Gates Foundation on factory farming? I was concerned to read this in Gates Notes.
"On the way back to Addis, we stopped at a poultry farm established by the Oromia government to help young people enter the poultry industry. They work there for two or three years, earn a salary and some start-up money, and then go off to start their own agriculture businesses. It was a noisy place—the farm has 20,000 chickens! But it was exciting to meet some aspiring farmers and businesspeople with big dreams."
It seems a disaster that the Gates foundation are funding and promoting the rapid scale up of factory farming in Africa, and reversing this seems potentially tractable to me. Could individuals, Gates insiders or the big animal rights orgs take this up?
The positive media storm for Anthropic is bigger than I thought it would be.
Almost every major news network has featured them and almost all of it puts a halo on Amodei (which feels a bit icky but hey).
And every 4th post on my linkedin is along the lines of
"Claude hits no. 1 on App store"
"the idea that no big tech has morals is dead,"
"my 3 year love affair with GPT Is over"
"I made the switch to Claude and I'll never look back"
As much as refusing the govt. contact might delay their IPO and give their valuation a temporary hit, they could hardly have hoped for a better PR flood. Every new user that switches more only helps them but hurts their biggest competitor. It's also good timing for them because right now their product is probably better than Open AI's which wasn't the case a year ago and might not be the case 6 months from now.
It's still unclear whether this will be a good business decision as well as a "moral" one but I suspect it will.
Dean Ball's commentary on this refamed the issue for me https://www.hyperdimensional.co/p/clawed
The big difference, however, is that Anthropic is essentially using the contractual vehicle to impose what feel less like technical constraints and more like policy constraints on the military. Think of the difference between “this fighter jet is not certified for flight above such-and-such an altitude, and if you fly above that altitude, you’ve breached your warranty,” and “you may not fly this jet above such-and-such an altitude”). It is probably the case that the military should not agree to terms like this, and private firms should not try to set them.
But the Biden Administration did agree to those terms, and so did the Trump Administration, until it changed its mind. That alone should make one thing clear: terms like this are not some ridiculous violation of the norms of defense contracting...
The contract was not illegal, just perhaps unwise, and even that probably only in retrospect. Note that this is true even if you agree with the underlying substance of the limitations. You can support restrictions on mass domestic surveillance and lethal autonomous weapons, but disagree that a defense contract is the optimal vehicle to achieve that policy outcome. The way you achieve new policy outcomes, under the usual rules of our republic, is to pass a law...
I agree that there's something iffy/non-democratic in theory about putting that kind of constraint around the Pentagon, and that it would have been prudent for them to decline it in the first place. An analogy I read on Substack: if an epidural manufacturer told a government hospital "you're welcome to use our drug so long as you don't use it in any abortions," it would probably be prudent to decline that contract (too much overhead).
Anyway this reframing put one sentence in particular by Dario into a new light: "To the extent that such surveillance is currently legal, this is only because the law has not yet caught up with the rapidly growing capabilities of AI." In other words, because we know what the law should be and what it's probably going to be, we should implement that policy today. I think many of us can think of examples where we'd be uncomfortable with a billionaire tech CEO saying that.
Surely you could phrase things the other way round?
"We're pretty sure this will be made illegal in 10 years time, as the law catches up to our technology advances. However, it's not illegal now, so feel free to buy it from us and use it!"
I'd be really uncomfortable with a billionaire tech CEO openly saying that.
I'm not sure democracy arguments work that well for military stuff. The people who military actions are going to be deployed against are extremely obvious stakeholders, but they get no input into any feasible "democratic" process that determines what the US military does, and procedural democracy is compatible with the US doing literally anything to non-citizens to advance US interests. Given that, attempting to restrain the US military in ways that are legal and non-deceptive doesn't seem that procedurally dubious to me.
An analogy I read on Substack: if an epidural manufacturer told a government hospital "you're welcome to use our drug so long as you don't use it in any abortions," it would probably be prudent to decline that contract (too much overhead).
This is a great intuition pump.
People interested in global health will benefit from subscribing to @David Nash's amazing monthly Roundup of the best writing on global development. He has an uncanny knack of selecting quality stuff, and I always find an interesting article I wouldn't have seen otherwise.
He also does a great job of breaking the topics up so we can focus on our own area of interest (aid/growth/governance/trade/health/education etc.)
https://gdea.substack.com/subscribe
My only criticism might be that there's a slightly disproportionate focus on economic growth, but hey we've all got our hobby horses ;)
Completely unsolicited plug BTW. Even when I did meet up with David in person he didn't even pay for my coffee ;)
100% agree with this!
My experience here has been that animal welfare forum people don't receive criticism quite as well as GHW people or AI safety people. In many cases a comment which pushes against a pro animal welfare argument will take a bit of a hit. This isn't always the case - some comments do get well received.
When i make reasonable criticisms/comments on animal welfare posts, i often get karma downvoted more heavily than i think (at least) makes sense.
This could of course just be due to poor quality comments and my poor judgement, but my data point against this is that i have found the opposite to be the case in GHW and AI safety discussions, where people seem less prone to karma downvote me even when they disagree.
Edit: As a side note thanks to @mal_graham🔸 for great engagement on my comments on their post after I wrote this. Not sure if they karma knocked me or not though ;) :D.
Given your expertise is in global health, I do think it's likely that you're less well-calibrated on how reasonable your animal welfare comments are relative to your global health ones! So you may think it's a reasonable critique but someone who is a die-hard animal person may have already thought about your comment and know there is a common counterpoint that negates it (which you haven't heard yet). Obviously, the inverse could be true for global health comments.
But I agree that this shouldn't have been downvoted on karma grounds!
(Also, sometimes your comments do give me "I am sceptical of most things animal welfare" vibes, so people might be reacting to a real or perceived difference in values about how much animals matter).
"Also, sometimes your comments do give me "I am sceptical of most things animal welfare" vibes, so people might be reacting to a real or perceived difference in values about how much animals matter)."
i think this seems part of my point/the problem. i probably do have a difference in values? (maybe) about how much animals matter, but I would still be in the top 1 -5 percent of humans on the "caring about animals" front. If I'm giving you "skeptical of most things animal welfare vibes" then i think it might help to recalibrate to appreciate perspectives outside of an animal welfare bubble at it were.
Someone commenting at all in an animal welfare thread on the EA forum means they are likely to be extremely high on the "cares about animals" axis, unless they are trolling or downright abusive. Even someone who seems highly sceptical about animal welfare by your lights.
But even someone who doesn't think animals matter at all should be able to make reasonable-ish comments without necessarily getting karma downvoted. The less echo chamber the better.
haha I can confirm I did not karma knock you and I was kind of surprised you had gotten so downvoted! I actually upvoted when I saw that to counteract.
One random thought I'll add is that since you are most experienced (afaict?) in ghd, I'd expect your arguments to be at their best in that context, so you getting upvoted on GHD and downvoted on AW is at least consistent with having more expertise in one than the other, so not necessarily evidence that AW folks are more sensitive. Although I'm not ruling that out!
The other thing I'm not sure I understand is how much weight a single individual's downvote can have - is there any chance that a few AW people have a ton of karma here, so that just a few people downvoting can take you negative in a way that wouldn't happen as much in GHD?
Yes my GHW comments are surely better, but i doubt that accounts for much of the issue. getting little attention because of low quality comments is one thing, getting a bunch of active down voting is another.
thanks @mal_graham🔸 I've been part off a bunch of animal welfare discussions, and it has been a consistent pattern over the last couple of years. And not only for my comments but others too - if someone pushes back there's a good chance they will get knocked even if they make a fair point. I'm a bit more belligerent than most, to but i think the consequence is that animal welfare discussions become more echo chambery than the average on the forum because it can be pretty discouraging to have a contrarian view
The karma vote strength hierarchy is explained here. If you go here and sort by karma, you can see who on the forum has the most. The most karma anybody has is in the 25,000 to 50,000 bracket — and that's just one person, Linch, with around 27,600. So, Linch's strong karma votes are worth 10 points (or -10). Most of the "karma bourgeois" are in the 8 point and 9 point brackets.[1]
Something I only just learned yesterday is that you hover over the karma on a comment or post (on desktop) or tap it (on mobile), it tells you how many people actually voted!
- ^
Although I do see there is an option in settings to hide yourself from the people directory, so I guess it's possible some karma rich people are hiding themselves.
The other thing I'm not sure I understand is how much weight a single individual's downvote can have - is there any chance that a few AW people have a ton of karma here, so that just a few people downvoting can take you negative in a way that wouldn't happen as much in GHD?
It's probably the strong downvote of one single user (especially given that there were only two disagree votes and one of them was mine). If I strongly downvote the same comment, it goes from 0 to -5 karma! (and I don't think I'm a gigantic outlier karma monster).
Just wanted to say, as someone from the animal side of things, that if this is indeed the case (no strong opinion either way), I'm sorry this happened to you and I appreciate that you're pointing this out. Separating agreement from post quality is something I deeply value in the discourse here, and we should police the correct use of voting.
As a (wild) animal welfare person, I am disappointed to see this. Your comment was thoughtful and well-intentioned.
It doesn't apply here, but in general I expect animal welfare people are more likely to disapprove of certain views, or take more of a combative attitude to public debates, because so much of normal discourse sneaks in speciesist assumptions and is actively harmful to animals. But I don't think that's the explanation here - I largely agree with your comment.
To respond to your original comment, I think with a bit of creativity you will be able to find politically tractable interventions. For example, people tend to view humane management of animals in cities quite positively. There's also a growing movement for compassionate conservation. It's more focused on doing no harm than actively helping wild animals, but at least it is a movement towards thinking about the welfare of wild animals. I do think that there will often be a tradeoff between effectiveness and political tractability though, and it may be worth pursuing sub-optimal interventions for a while in order to gain greater political momentum towards helping wild animals.
I have no idea how much this kind of voting behaviour varies from discussions about one cause area to another, but I can confirm that this happens a lot in various discussions on multiple different topics. People seem keen to karma downvote/strongly downvote posts or comments they disagree with, regardless of quality. I surmise this is probably just people being mad and having a knee-jerk reaction, in a lot of cases.
I recently had an experience where someone was using a technical term incorrectly, and I left two comments trying to correct the use of this term. These comments didn't get responded to, but they did get strongly downvoted. It was enough that it triggered me getting rate limited from commenting on the forum! This just seems like a case where someone felt spiteful that I pointed out they made a mistake.
That's one example, but people do this all the time. Another recent example is here, where I didn't notice or complain about the downvoting, but someone else noticed it and complained about it on my behalf.
People in this community are only human, and we're affected by the same impulses as anybody else. We have the same cognitive/psychological biases as anyone else and the same problems with emotional self-regulation as anyone else. It takes a certain amount of discipline for me to remain judicious about my downvotes (or, on rare occasions, quickly undo a downvote I made in a moment of irritation).
To the extent it's a real problem, it's a problem where it's not a one-off spar between two people (or a few), but where it's systemic around certain ideas or topics. I get the impression people sort of knee-jerk/undiscerningly upvote posts and comments that support the narrative that near-term AGI is likely, and downvote posts and comments that challenge this narrative, even when the actual content is narrow in scope, e.g. pointing out a mistake in something that promotes a near-term AGI narrative.
If you want to express mainstream North American liberal/progressive views on social justice-related topics, forget about it. The downvotes will fall like a cloud of daggers. (The Overton window of the EA Forum is a bit skewed in that regard — and it's extremely skewed for the LessWrong users who come over here — where some people will defend views they concede are or might be offensive and wrong, such as scientific racism or white nationalism, on the grounds of free speech or neutrality or intellectual freedom or whatever, but do not extend the same defense to the sort of bog standard social justice views that mainstream liberal or progressive politicians or academics generally affirm. I think Kamala Harris or Barack Obama might get downvoted on the EA Forum talking about systemic racism, sexism, or trans rights in the ways they already do in public appearances, and an authoritarian white nationalist like Curtis Yarvin — who many people on LessWrong seem to be a fan of — might get upvoted for some edgy take about Black-on-Black crime or race and IQ or something.)
I find the ways that I see people on the EA Forum circle the wagons around near-term AGI and social justice quite demented — sorry to be so blunt. Someone can make a post that says we should try to contact aliens to warn them about AGI and that gets +27 karma, but if you point out someone used a term from machine learning incorrectly that gets 0 or negative karma, and if you get into arguments about social justice you will get negative karma about the half the time, seemingly regardless of what you say (at least, I can't figure out the pattern, if there is one). It just seems like if you are willing to entertain really strange ideas like the aliens thing, you should also be willing to entertain mainstream ideas that many experts endorse — I mean specifically things that don't go against EA's core principles and haven't been discussed to death already, about which there isn't already a consensus within the community.
I guess it doesn't surprise me that people might knee-jerk downvote entirely reasonable comments about the limited market potential for humane insecticides or things of that nature, since that's similar. Maybe it's an example of in-group polarization, where people want to fiercely defend an opinion that's extreme relative to the general population or out-group.
I also thought your comment didn't deserve to get downvoted :'(, even though I disagreed and thought it partly missed my point (I ofc didn't downvote it, tho). Even the number of upvotes of Mal's comment responding to yours feels a bit violent, actually. I think people should maybe hold off from upvoting when it's not necessary. They can just agree-vote.
I think Mal's, James', and Tristan's potential explanations for why this happened are pretty plausible.
But, also, as I suggest in response to Mal, it's probably just one single person, so :shrug:, I guess. :)
While reading the economist yesterday, an article in their fantastic "The Africa gap" series felt strangely familiar - I'd read these ideas last year in @Karthik Tadepalli's fantastic series on economic growth in LMIC's. I appreciated this section
Instead of many large firms with salaried staff, Africa has lots of micro-enterprises and informal workers. More than 80% of employment in Africa is informal, according to the International Labour Organisation. Roughly half of informal workers in cities are self-employed, doing everything from crafting Instagram advertising to fixing roofs. Many Africans mix formal work with informal hustles, which are often poorly paid. Most would love a steady job. Mr Tadepalli suggests that many of the “self-employed” may just be the unemployed “in disguise”
I shouldn't have been surprised to see Karthik's quotes and research directly referred to in the article itself! Nice work Karthik and great to see your work get recognised in the mainstream as well as on the neglected global development corners of the EA forum ;).
This is a small appreciation post for the deep and prompt community engagement from the 80k team after their announcement of their new strategic direction.
No organization is under any obligation to respond to comments and criticisms about their strategy, and I've been impressed by the willingness of so many 80k staff members to engage in both debate and reassurance - at least 5 people from the organization have weighed in.
It has both helped me understand their decision better and made the organization feel more caring and kind then if they had just dropped the announcement without follow up. Although engaging to this degree has costs, I think this shows that if this kind of engagement is done well it might help both the reputation of the org and smooth over misunderstandings as well.
I broadly agree with this!
At the same time, I'd flag that I'm not quite sure how to frame this.
If I were a donor to 80k, I'd see this action as less "80k did something nice for the EA community that they themselves didn't benefit from" and more "80k did something that was a good bet in terms of expected value." In some ways, this latter thing can be viewed as more noble, even though it might be seen as less warm.
Basically, I think that traditional understandings of "being thankful" sort of break down when organizations are making intentional investments that optimize for expected value.
I'm not at all saying that this means that these posts are less valuable or noble or whatever. Just that I'd hope we could argue that they make sense strictly through the lens of EV optimization, and thus don't need to rely as much on the language of appreciation.
(I've been thinking about this with other discussions)
There's truth there and I would agree its better EV to engage too. There could be many different motives. Higher EV, damage control reaction, kindness, community building, nostalgia for those old days when they were global health people too ;).
Regardless though I like to frame things in more human and interpersonal terms and will continue to do so :)
Change in strategic direction?
Can we call it the Meat EatING problem?
The currently labelled "meat eater problem" has been referred to a number of times during debate week. The forum wiki on the “meat eater” problem summarises it like this.
“Saving human lives, and making humans more prosperous, seem to be obviously good in terms of direct effects. However, humans consume animal products, and these animal products may cause considerable animal suffering. Therefore, improving human lives may lead to negative effects that outweigh the direct positive effects.”
I think this an important issue to discuss, although I think we should be extremely sensitive and cautious while discussing it.
On this note I think we should re-label this the meat eating problem, as I think there are big upsides with minimal downside.
- Accuracy: I don’t think the core problem actually the people who’s lives we are saving, its that they then eat meat and cause suffering. I think its important to separate the people from the core problem as this better helps us consider possible solutions
- Persuasion: I think we’re more able to persuade if we discuss the problem separated from the people. I can talk about the “meat eating problem” with non-EA friends and it will be hard but they might understand, but if through the very name of the issue I make the people themselves the problem, that can easily make me seem callous, and people can switch off.
- Fairness: Even if you disagree with me on accuracy and double down that the core problem is the people, I think its pretty unfair to lump the label of a serious philosophical problem on the poorest people on earth - people with little education who are often just trying to survive and have never had the chance to consider this issue.
It seems to me that this problem was mainly thought up and developed by the EA community (which is great), and we could probably just decide to call it something different from here on out. I’m asking the forum team to consider changing the name on the wiki as well.
NB: @JWS 🔸 proposed this name change a couple of months ago, which got me thinking about it again.
It's true that meat eating is closer to what we actually care about, but it's worth singling out causal pathways from saving lives and increasing incomes/wealth, as potential backfire effects. "Meat eating problem" seems likely to be understood too generally as the problem of animal consumption, without explanation. I'd prefer a more unique expression to isolate the specific causal pathways.
Some other ideas:
- meat eating backfire (problem)
- more meat backfire/problem
- meat backfire (problem)
- (more) animal product backfire (problem)
(Eggs and other animal products besides meat matter, too.)
Yep I'm happy with any of these, I especially like the "meat eating backfire" because it kind of implies we're shooting in the right direction in the first place. Also you are right that in terms of suffering (especially here in Uganda) its probably the eggs that might be a bigger problem even than the meat.
Of course, there are other ways meat (and other animal product) consumption could increase from well-intentioned EA interventions than just by saving lives or increasing incomes/wealth. For example, interventions that involve subsidizing animal welfare improvements can carry this backfire risk.
I'm less worried about confusion with other problems, because they don't come up as often, and researchers are more likely to account for them in animal welfare research anyway. All effects on nonhuman animals are usually omitted from analyses of interventions aimed specifically at helping humans, including GHD and CGRs. It's worth reminding people of these backfire risks.
When we were talking about this in 2012 we called it the "poor meat-eater problem", which I think is clearer.
I think it is clearer yes, but I don't really like about it for my reasons 2 and 3 above, and I still think the direct problem isn't about the people existing, but they fact they are eating meat after their lives are "saved". Labeling it the "poor meat eater" problem could potentially be even worse in that it could be perceived to be sounding like its blaming poor people (although I know that's not the intent).
And if people in high-income countries die from pandemics, nukes or AI, that's also good for farmed animals. It's not just poor people.
I think 'meat-eating problem' > 'meat-eater problem' came in my comment and associated discussion here, but possibly somewhere else.[1]
- ^
(I still stand by the comment, and I don't think it's contradictory with my current vote placement on the debate week question)
I think it's totally fair name of the problem, as its "unfairness" comes from the problem statement, not its name. "I think its pretty unfair to lump the label of a serious philosophical problem on the poorest people on earth" here for example, it's meat eater problem being morally icky, not its name.
- Accuracy: I don’t think the core problem actually the people who’s lives we are saving, its that they then eat meat and cause suffering. I think its important to separate the people from the core problem as this better helps us consider possible solutions
The main takeaway of the 'meat eater problem' (sorry!) is to reassess the cost-effectiveness of saving human lives, not necessarily to argue that we should focus on reducing animal consumption in lower-income countries. While reducing animal consumption is important, that’s not typically the central takeaway from this specific 'problem'.
In this sense, the saving lives aspect is more central to the problem than the meat consumption aspect, though both are pivotal. So, in a purely logical sense, the term 'meat eater problem' might actually be more accurate.
You can argue that, but even then can points 2 and 3 not still make it better to use a different name?
Depends if there’s a better option. I agree with MichaelStJules when he says "’Meat eating problem’ seems likely to be understood too generally as the problem of animal consumption.” The other proposed options don’t seem that great to me because they seem to abstract too far away from the issue of saving lives which is at the core of the problem.
It’s worth noting there is a cost to changing the name of something. You’ll then have the exact same thing referred to by different names in different places which can lead to confusion. Also it’s very hard to get a whole community to change the way they refer to something that has been around for a while.
With regards to the “persuasion” point - I think the issue is that the problem we are talking about is inherently uncomfortable. We’re talking about how saving human lives may not be as good as we think it is because humans cause suffering to animals. This is naturally going to be hard for a lot of people to swallow the second you explain it to them, and I don’t think putting a nicer name on it is going to change that.
With regard to fairness…this is my personal view but this doesn’t bother me much. I don’t see evidence of individuals in lower income countries caring about the language we use on the EA Forum which is what would ultimately influence me on this point.
I'm aware I'm in the extreme minority here and I might be wrong. I fully expect to get further downvotes but if people disagree I would welcome pushback in the form of replies.
Me: "Well at least this study shows no association beteween painted houses and kids' blood lead levels. That's encouraging!"
Wife: "Nothing you have said this morning is encouraging NIck. Everything that I've heard tells me that our pots, our containers and half of our hut are slowly poisoning our baby"
Yikes touche...
(Context we live in Northern Uganda)
Thanks @Lead Research for Action (LeRA) for this unsettling but excellently written report. Our house is full of aluminium pots and green plastic food containers. Now to figure out what to do about it!
https://drive.google.com/file/d/1pqRUeejiRCX2bXekeZnL0zGi34zbK23w/view
Thanks so much for reading, Nick.
It really is nearly impossible as an individual consumer to figure out which of the many products we interact with everyday are safe, and which might be contaminated, unfortunately... so hoping we can collectively make progress on these things at a systems level soon!
On a related topic, I'm curious whether you see any geophagia (soil consumption) among pregnant women, or other people, in Northern Uganda? It's fairly common in Kenya and Malawi and we've unfortunately seen that the soils (which are often compacted, so they look like small stones) frequently contain lead levels well above what you'd want to see in something that's being directly consumed.
-- Isabel Arjmand (cofounder)
Thanks Isabel! I still think you could perhaps have some soft recommendations? We are thinking of ditching our red and green plastic containers (which bits of plastic are often flaking off from) and replacing them with aluminium ones. I figure if the water is not hot that's surely safer? I think consumers can do something here to lower risk. We can't figure out what is contaminated but we can know which is more likely at least?
Yeah pregnant women eating soil a thing and some people do but I honestly don't know how much is ingested here so can't help you I'm afraid. That won't be the easiest question to answer. I would have thought the best way to answer directly would just be to take blood lead levels of say 100 women late in pregnancy and compare that with 100 not-pregnant woman to directly see if there's a difference. That wouldn't prove causality but if there was no difference you could discount the problem.
Sure – it's a good point about striking a balance between being willing to take action even with imperfect information, while also not wanting to overclaim. In that vein: We think that it may often be coming from lead chromate (high-lead plastics often also read high in chromium), which is a bright yellow-orange pigment, so most likely to be found in yellow/orange/green plastics; we saw it most in orange and bright green, which are both very popular colors in Malawi. We also saw high lead levels in at least one white plastic, which we suspect is coming from a different compound.
We have some testing underway at a lab to try to assess what drives leaching – heat, acid, fat/oil, and time are the variables we hypothesize might drive it. So juice could be worse than plain water, fatty stew worse than something leaner, etc -- hopefully we'll know more soon about which of these factors are most important though. It's also still possible that despite the high lead levels in some of these plastics, not much of the lead is actually getting into food/drink, which would be great news.
And to speculate a bit more -- it makes sense to me that a plastic that is flaking/fragmenting would pose a greater risk than one that is intact, though I don't have much of a guess of the order of magnitude. On the other hand, we also think it's possible that plastics may leach more on the first use than on subsequent uses, if that first use sheds a lot of the most 'available' lead...
Something I suspect may not be a good proxy is price. Again, we haven't done any research in Uganda, but in Malawi we saw that branded and unbranded pots/pans were similarly likely to be contaminated, whereas we'd initially suspected that informally produced pots and pans would be much riskier. But other countries may vary.
And thanks for the thoughts on geophagia! We're designing a study right now that will take BLLs of pregnant women who are geophagic, and those who aren't, and compare BLLs across those two groups.
- Isabel
This article gave me 5% more energy today. I love the no fear, no bull#!@$, passionate approach. I hope this kindly packaged "get off your ass priveleged people" can spur some action, and great to see these sentiments front and center in a newspaper like the Guardian!
https://www.theguardian.com/lifeandstyle/2025/apr/19/no-youre-not-fine-just-the-way-you-are-time-to-quit-your-pointless-job-become-morally-ambitious-and-change-the-world?CMP=Share_AndroidApp_Other
I knew the 80k video was that good. I didn't know it would do this well.
2.5 million views and right now the most watched deep AI explainer video in the Internet, congratulations 80,000 hours! After shrimp on Daily show and a few less-negative articles, I can't help but think there's a bit of a purple patch for EA-In-Public at the moment.
I wonder if community builders and organizers are seeing positives signs as well?
This is incredibly impressive for a first video on a new channel. Great work 80kh!
I feel like 5% of EA directed funding is a high bar to clear to agree with the statement "“AI welfare should be an EA priority”. I would have maybe pitched for maybe 1% 2% as the "priority" bar, which would still be 10 million dollars a year even under quite conservative assumptions as to what would be considered unrestricted EA funding.
This would mean that across all domains (X-risk, animal welfare, GHD) a theoretical maximum of 20 causes, more realistically maybe 5-15 causes (assuming some causes warrant 10-30% of funding) would be considered EA Priorities. 80,000 hours doesn't have AI welfare in their top 8 causes but it is in their top 16, so I doubt it would clear the "5%" bar, even though they list it under their "Similarly pressing but less developed areas", which feels priorityish to me (perhaos they could share their perspective?)
It could also depend how broadly we characterise causes. Is "Global Health and development" one cause, or are Mosquito nets, deworming and cash transfers all their own causes? I would suspect the latter.
Many people could therefore consider AI welfare an important cause area in their eyes but disagree with the debate statement because they don't think it warrants a large 5%+ of EA funding despite its importance.
Or I could be wrong and many could consider 5% a reasonable or even low bar. Its clearly a subjective question and not the biggest deal but hey :D.
In ordinary language, I wouldn't generally consider something that gets 1% of resources to be a "priority." Applying your reasoning above, that would create a theoretical maximum of 100 "priorities" and a more realistic range of perhaps 10-40. As we move beyond the low teens, the idea of a "priority" gets pretty watered down in my book.
As i sat opposite my wife and our newborn child, chapter 34 of Steinbeck's "East of Eden" absolutely clapped me - especially that no matter what changes us humans impose on our environment, the question remains.
"A child may ask, “What is the world’s story about?” And a grown man or woman may wonder, “What way will the world go? How does it end and, while we’re at it, what’s the story about?”
I believe that there is one story in the world, and only one, that has frightened and inspired us, so that we live in a Pearl White serial of continuing thought and wonder. Humans are caught–in their lives, in their thoughts, in their hungers and ambitions, in their avarice and cruelty, and in their kindness and generosity too–in a net of good and evil. I think this is the only story we have and that it occurs on all levels of feeling and intelligence. Virtue and vice were warp and woof of our first consciousness, and they will be the fabric of our last, and this despite any changes we impose on field and river and mountain, on economy and manners. There is no other story.
A man, after he has brushed off the dust and chips of his life, will have left only the hard, clean questions: Was it good or was it evil? Have I done well–or ill?"
Does this mean you recently had a baby? If so, congratulations!
Is there any possibility of the forum having an AI-writing detector in the background which perhaps only the admins can see, but could be queried by suspicious users? I really don't like AI writing and have called it out a number of times but have been wrong once. I imagine this has been thought about and there might even be a form of this going on already.
In saying this my first post on LessWrong was scrapped because they identified it as AI written even though I have NEVER used AI in online writing not even for checking/polishing. So that system obviously isnt' perfect.
I feel mixed about ai-writing detection for a few reasons. I have very few issues with someone putting the bullet points of their argument into ai and then reading/editing/discussing a few times the response and letting the ai write it. I also think there is value in just putting your messy thoughts out as you have them and not having everything polished, but it depends on the situation.
Also separately I'm worried ai-writing detector proliferation will just speed up "immunity". I don't think there is something deep and fundamental that stops ai from writing e.g. exactly what I have written to this point. You can already download all your writing, ask ai to summarize it, make a text file that precisely describes your style and then ask the ai to write something in your voice. I've done this and yes they still have a bit of that vanilla llm feel but if there is actual market demand for solutions it doesn't seem like this is an insurmountable problem.
I think people should say when they used ai and to what degree and there should be an expectation that just because polished writing is cheaper than it used to be you will not pollute the forum with things that you have not thought an appropriate amount about.
Wow I'm almost polar opposite I think - the writing world you envisage feels sad and a bit scary to me. I would want close to zero AI involvement in the final draft. I think there's far far more value in messy thoughts out there, than bullet points which an AI "expands" on to a polished final product. AI in its current state inevitably changes or measures arguments. It also makes writing feel more "voiceless" and samey.
I want to engage with humans here on the forum. Someone's voice is an extention of them. When we type on the keyboard its coming almost directly from our brains. Brains to hands to brains. Sure we're not face to face or on zoom but when its just my words and your words I like that the conversation is direct. There is soul there. The more AI gets in the way, the less I feel we have a deep discourse.
I'm very OK with people using AI for brainstorming, researching, and testing arguments. But let every word of your final draft come straight from you. Your heart, your voice with all your quirks and problems.
I might do a poll to see what people think about this. I might be in the minority.
Curious to see that poll. I'm in that minority too.
But I do wonder how much the "someone's voice is an extension of them" view is mediated by the privilege of being effortlessly able to articulate one's thoughts in public, especially in a forum that invites scrutiny such as this one, and reliably get positive engagement. You and Brad seem to be on opposite ends of this spectrum (?). Your combination of prolificity, quality, and the fact that you do this despite having an obscenely busy day job reminds me of Scott Alexander, cf. this AMA exchange from back when he was a full-time psychiatrist:
How do you write so quickly? I find it takes me a dozen or more hours to write anything as thorough as one of your blog posts. (It's possible that I'm just unusually slow).
Scott: I guess I don't really understand why it takes so many people so long to write. They seem to be able to talk instantaneously, and writing isn't that different from speech. Why can't they just say what they want to say, but instead of speaking it aloud, write it down?
(Yeah, that level of clear thinking to clear writing translation is an insane privilege.)
On the other hand Brad's reply to you reminds me of my younger self. I was horrible at this, and worked my rear off for years to get to essentially the starting point of my more innately articulate peers who sailed through job interviews, scholarship interviews etc I kept bombing out of. You can tell how much I care about this by the fact that I could link to a throwaway comment above from deep within the chat threads of an 8-year old reddit AMA by someone mentioning a thing they had that I didn't. I can definitely see younger me being in the majority of your poll.
I think this has to do with the fact that I think mostly nonverbally, which makes the thought to writing / speech translation much harder. I suspect vast swathes of the population are similar. (The wordcel vs rotator thing is related, although I dislike the discourse around it.) This makes us, relatively speaking, voiceless in public fora, so discourse gets dominated by verbal thinkers which skews the intellectual environment and culture.
So when Brad said
Going back and forth with AI, reviewing, and drafting can turn a writing process that might take several days to a week or more, into an hour or two, or less
I went "yeah definitely for nonverbal-ish thinkers, and I think this has the potential to reduce the skew and improve intellectual variety in discourse and culture, and separately I expect verbal-ish thinkers won't appreciate this benefit" and sure enough your reply confirmed the latter.
That said, I do mostly agree with you that I haven't been very impressed by the heavily AI-assisted writings I've seen, and like you I really dislike "AI voice", so to me this has been more potential than realised benefit so far. Some guesses:
- I'm wrong about the above
- AI isn't good enough yet to properly bridge the translation gap between heavily nonverbal-infused thinking and and writing. (Or it is but people aren't using the paid versions)
- Nonverbal-ish thinkers just don't reason as clearly as they think they do, and they never noticed this because unlike verbal-ish thinkers they hadn't often translated their thoughts into writing which exposes thinking gaps, and AI-assisted writeups of their half-baked thoughts fill in those gaps with slop
- The written word isn't the right translation target for nonverbal-ish thinking, it's something else, and (more advanced than today's) AI can potentially assist with this too. I'm thinking of Bret Victor's humane dynamic medium, dangit I should've just quoted these sections instead of subjecting you to my rambling:
A way in which people conceive and share thoughts. An idea might be expressed as a speech, a song, a drawing, a video, an essay, an equation, a tweet... These are different media.
Certain media open up new threads of thought that are otherwise inconceivable. Greek drama was made possible by writing; Shakespearean drama was made possible by print; Newtonian physics was made possible by equations.
The deepest effects are realized when a medium is diffused throughout a culture, not in the hands of a select few. A literate society is one in which all people participate in the exchange of written ideas, where the visual organization of words is second nature in the cultural consciousness. Societies with designated scribes do not enjoy the most significant benefits of literacy.
What do you mean by “dynamic medium”?
The conceiving and sharing of ideas represented computationally.
Computers can be used for efficiently distributing static media, as when reading an article or watching a video. But by “dynamic medium”, we mean the representation of ideas in which computation is essential, by enabling active exploration of implications and possibilities.
The modern world is shaped by vast complex systems — technical systems, environmental systems, societal systems — which cannot be clearly seen nor deeply understood via non-dynamic media. The dynamic medium may enable humanity to grasp and grapple with this century’s most critical ideas.
What do you mean by “humane dynamic medium”?
A dynamic medium which is communal, gives all people full agency, and is part of the real world. [more]
By “communal”, we mean bringing people together in the same physical space, with a medium that supports and strengthens face-to-face interaction, shared hands-on work, tacit knowledge, mutual context, and generally being present in the same reality.
By “agency”, we mean a person’s ability and confidence to view, change, extend, and remake every aspect of a system that they rely on, especially for fluently exploring new ideas and improvising solutions in unique situations. In the case of computing systems, this implies top-to-bottom programmability and composability, in a form that is accessible and human-scale.
By “real world”, we mean that material in the medium physically exists, and all of our human abilities and human senses can be applied to it. People are free to make use of their whole selves, every feature of their physical body and of the physical world, instead of interacting with a simulation through an interface.
“Real world” also refers to being situated in reality — understanding what’s actually happening and how things actually work instead of just abstractions; awareness of larger contexts — and especially the local reality of local needs and local knowledge rather than top-down centralized mass-produced solutions.
I think the problem is fundamentally the lack of care and attention to the content being created, not whether or not AI is used. If it is in people's incentives to produce polished, thoughtless, drivel on LinkedIn and they can do it in 10 seconds, they will.
This is very different from an iterative process in which the human is carefully examining the output and refining to optimize the exploration and explanation of an idea.
I think folks should be free to choose what level of AI use they're comfortable with, without fear of being shamed or outed inherently for using AI. Those who don't approve are free to downvote or 'x' to show their discontent. If enough people feel the same way then the incentives will do their job.
As I said on LinkedIn, you are still engaging with a human... a human that's using AI.
I see AI as an interesting leveller of the playing field. It gives people less room to dismiss a point of view for being conveyed haphazardly in writing.
Writing well is a skill, built on the existential privilege of intelligence. If you don't have it, does it mean you have less right to be heard?
We're actually currently working on updating our policy on AI-generated content, so this thread (and follow up poll) is helpful! :)
I disagree pretty strongly with this.
Although there are tradeoffs associated with AI writing, mostly being able to produce content that can appear polished and well-considered when it is not, I think AI's enabling the proliferation of good thoughts and ideas that would otherwise just never happen far outweighs this.
Going back and forth with AI, reviewing, and drafting can turn a writing process that might take several days to a week or more, into an hour or two, or less. This enables me, and I'm sure others, to share content and ideas that otherwise we would not be able to.
Removing the barriers to people sharing their thoughts quickly and effectively is probably how we get more new and impactful ideas out there. I've been pretty sad at the sort of witch-huntery I've been seeing about AI generated content.
I agree that It may enable you to share ideas a little faster (although I'm not sure by how much). Most individual good ideas could be expressed in a couple of paragraphs if need be.
I don't buy though that you "wouldn't be able to share them" otherwise. I'm happy for AI to help with your thoughts and ideas (brainstorming, ideating, research), just not with your final writing. I'm not convinced at all yet that AI is "enabling the proliferation of good thoughts and ideas" in a significant way. Can you share any evidence of that? I've not been very impresses with posts on the forum here that heavily use AI
I don't think writing the final draft without AI is a huge barrier to sharing thoughts quickly and effectively. Insofar as it might be, I'd take the tradeoff the other way.
Its interesting that this is so polarising. I'm certainly one of those witch hunters at the moment at least. A year ago I was more OK with AI writing but I'm now vehemently against it after seeing Linkedin, which 2 years ago was a pretty interesting platform, deteriorate to low quality discourse full of AI slop in both the posts and the comments. On that platform at least it has lowered the quality of ideas and discourse, not improved them. I hope Substack doesn't go the same way.
I have experience writing things with and without AI. At least for me, it can be a very difficult process trying to convey things as clearly and effectively as I can. Perhaps I am being unreasonable in putting that much time into the process and perhaps other people are just much better at writing clearly and effectively without AI. But I can say that I would not produce a lot of the content that I produce without AI being able to shorten the process significantly.
my first post on LessWrong was scrapped because they identified it as AI written
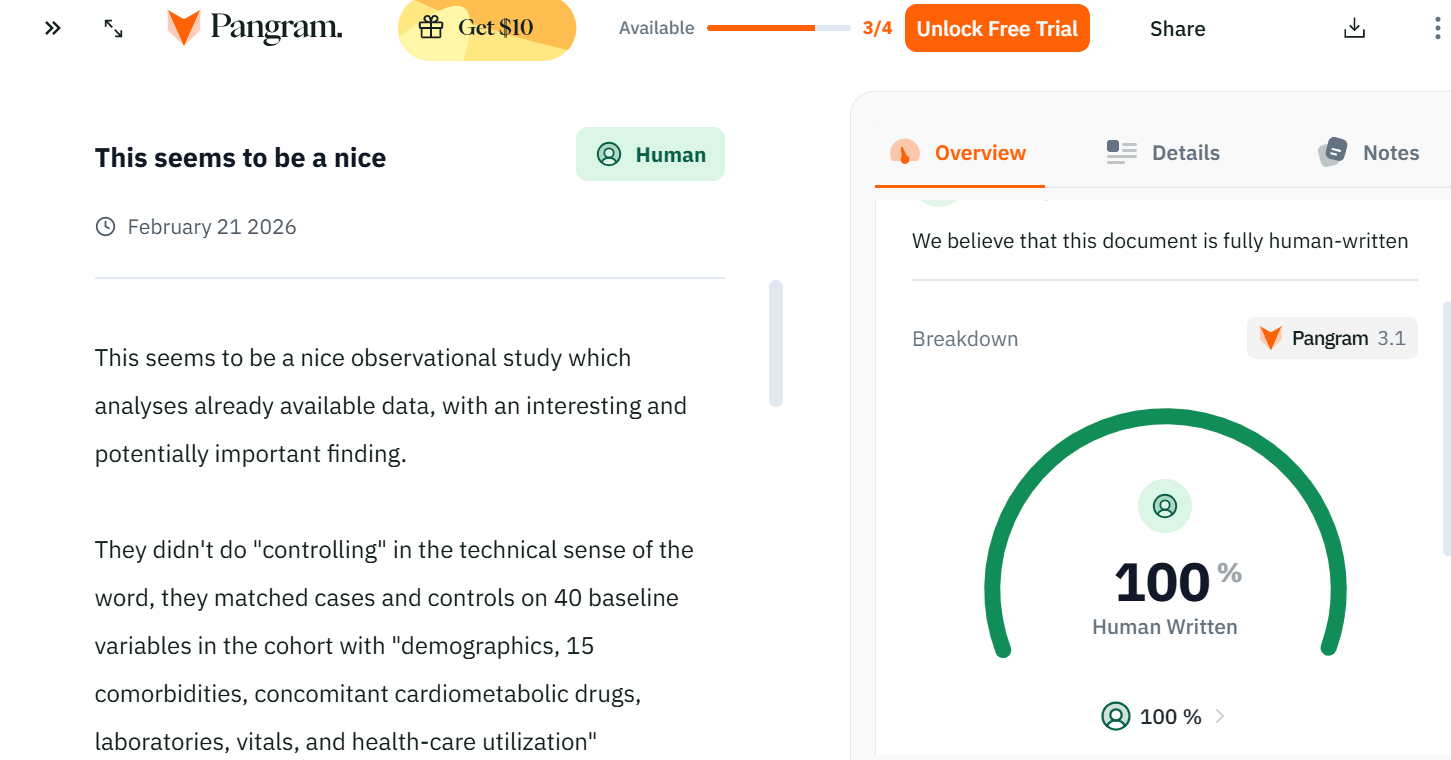
I'm surprised to read this, can you check your post on https://www.pangram.com/ ?
It wasn't a very well written comment, was a bit benign and generic which is maybe why it ot flaggerd. Here it is below To their credit though they reinstated it.
"This seems to be a nice observational study which analyses already available data, with an interesting and potentially important finding.
They didn't do "controlling" in the technical sense of the word, they matched cases and controls on 40 baseline variables in the cohort with "demographics, 15 comorbidities, concomitant cardiometabolic drugs, laboratories, vitals, and health-care utilization"
The big caveat here is that these impressive observational findings often disappear, or become much smaller when a randomised controlled trial is done. Observational studies can never prove causation. Usually that is because there is some silent feature about the kind of people that use melatonin to sleep, that couldn't be matched for or was missed in the matching. A speculative example here could be that some silent, unknown illnesses could have caused people to have poor sleep - which lead to melatonin use. Also what if poor sleep itself led to poor cardiovascular health not the melatonin itself?
This might be enough initial data to trigger a randomised placebo control trial using melatonin. It might be hard to sign enough people up to detect an effect on mortality - although a smaller study could still at least pick up if melatonin caused cardiovascular disease.
I agree with their conclusion which I think is a great takeaway
"These findings challenge the perception of melatonin as a benign chronic therapy and underscore the need for randomized trials to clarify its cardiovascular safety profile."
"
This is the pangram result
This was the lesswong rejection.

Literally just cranked out a 2 minute average quality comment and got accused of being a bot lol. Great introduction to the forum. To be fair they followed up well and promptly, but it was a bit annoying because it was days later and by that stage the thread had passed ant the comment was irrelevent.
Thanks for sharing! I'd have guessed they would be using something at least as good as pangram, but maybe it has too many false negatives for them, or it was rejected for other reasons and the wrong rejection message was shown.
Literally just cranked out a 2 minute average quality comment and got accused of being a bot lol. Great introduction to the forum. To be fair they followed up well and promptly, but it was a bit annoying because it was days later and by that stage the thread had passed ant the comment was irrelevent.
As an ex forum moderator I can sympathize with them, not a fun job!
Who said EA was dying?
I have 1400 contacts on my EAG London spreadsheet!
Yeah I know it's a bit of a lame datapoint and this is more of a tweet than a forum post but hey.... 😘
Rutger Bregman is taking the world by storm at the moment, promoting his book and concept "Moral Ambition". Yesterday he was on the Daily show!. It might be the biggest wave of publicity of largely EA ideas since FTX? Most of what he says is an attractive repackaging, or perhaps an evolution of largely EA ideas. He's striking a chord with the mainstream media, in a way that I'm not sure Effective altruism ever really has (but I wasn't there in the early days). I would also hazard a guess that his approach might resonate especially well with left-leaning people.
I was wondering if there's anything EA's could be DOING at the moment to take advantage of/leverage this unexpected wave of EA-Adjacent publicity. Things like...
1. Help with funding advertising, or anything else he might needs to ride the wave - these opportunities don't come often. He may well not need money though...
2. Using his videos and ideas as "ins" or advertising to university EA groups or other outreach. I know he's going to talk at Harvard uni soon - what is the group there's response?
3. Incorporating some of his language and ideas into how EA presents itself. Phrases like "Moral ambition", and the "Bermuda triangle of talent" seem like great phrases to adopt into our "lexicon" as it were.
Thoughts?
Yes it's quite exciting! One quick thought: I don't think SMA/Bregman would be very pleased if EAs regularly started using SMA's videos and ideas in their outreach (because they want to keep themselves quite separate). Maybe he's changed his view on that (they're organising an event with Singer and GWWC shortly), but it was certainly the case a year or so ago. If anyone's considering doing this on a significant scale, I'd suggest checking with them first.
I think there's merit in discussing and collaborating, and even keepign something seperate.I do think though that even if they do manage to gather a significant "movement" or "community" around SMA it will end up overlapping/melding with the EA community in significant ways. The concepts are just so aligned that it would be hard to keep the communities separate. Percent overlap will be high especially after a few years.
Perhaps in his homeland the Netherlands this might be possible though as most likely there will be more uptake there.
Also he's praising AMF, collaborating with AIM and doing events with Singer and GWWC so it would be a little odd for them to use what EA has generated to big up themselves, wile not wanting EA to do the same the other way around at all? This seems unlikely they would want this but maybe I'm missing something.
Yup, I largely agree, I'm not sure why people are disagree voting with you.
I recently attended his book launch in London, where he was asked about EA. I was surprised by how positive his response was. His main criticism was that EA feels “nerdy,” and that these ideas deserve a much wider audience. I got the impression he sees SMA as at least somewhat aligned with EA, but aimed at a broader audience.
He mentioned Ambitious Impact twice during the talk and profiles them in a chapter in the book. He also shouted out Rob Mather (who was in attendance), and includes at least two chapters on founding and running the Against Malaria Foundation in the book.
I haven’t seen other interviews, but it already seems to me like he’s promoting certain EA areas.
He expresses similar views in his recent interview with Peter Singer:
RUTGER: I see myself as a pluralist. It's fine to rely on the full spectrum of human emotions and motivations. Humans are a mixed bag, right? So, we are partially motivated sometimes by things such as compassion, empathy, and altruism, which is wonderful. But we can't solely rely on that to make this world a wildly better place.
Peter, you're obviously the founder of the Effective Altruism movement, a movement that I admire. At the same time, though, I feel it's a bit limited in its reach because many of the effective altruists I've spoken to are a bit strange and weird. They're mainly motivated by this yearning to do good and help others. They are born altruists. A lot of them became vegan when they were very young. Many of them reacted instantly when they read your essay, Famine, Affluence and Morality, and I think what happened in the years around 2010 is that these people discovered one another on social media, and they realised, “Hey, I'm not alone.” But they've always been quite weird, which is fine, don't get me wrong. I'm happy for them to do their work, but at the same time, I thought, perhaps there's also a place for a broader movement for more “neurotypical people” that relies on other sources of motivation.
That's good!
Yes, he references quite a few EA case studies in the book and in his talks. From chats I’ve had with people involved, I think they’re being thoughtful about how they relate to the EA brand - trying to reach a broader audience without getting pulled into existing perceptions.
So that's why I say if you’re thinking of using their work in EA outreach at a significant scale, I’d suggest checking in with them first.
Worth noting: Peter Singer and Rutger Bregman’s School for Moral Ambition are co-hosting a Profit for Good conference in Amsterdam on 11 June—a concrete EA-adjacent collaboration that channels Bregman’s “moral ambition” into effective-charity business models. Another good touchpoint for anyone looking to ride this wave.
https://www.moralambition.org/profit-for-good-conference-live-stream
I think for most people applying to their fellowships would be the best way to collaborate with SMA to do good (as he mentions in the video)
I think the fellowships look great, but as paid internships I would have thought they would have been the best way to collaborate with them for a pretty small number of people?
I think many people can/should apply, but of course I expect only few will get in.
I also don't know if "paid internship" is a good description, I think it's probably closer to Ambitious Impact programs than to a typical internship (the "founding to give" program is made in collaboration with AIM)
I appreciate the curation at the top (fantastic post), but the forum is becoming a little thin on the ground for us Global Health Folks... If you've got a global health thought whether deep or shallow, please share it, at least I'll do my best to comment and engage :D.

I'm also very keen to get more global health content! One thing people can do to help is suggest bloggers/ substackers etc... who write on global health topics relevant to EA. I can talk to them and offer them automated crossposting and support.
GiveWell posts a lot of interesting stuff on their blog and on their website, but in the past year they only reposted hiring announcements on the EA Forum.
E.g. I don't think that USAID Funding Cuts: Our Response and Ways to Help from 10 days ago was cross-posted here, but I think many readers would have found it interesting
Thanks for the suggestion! I reached out to them last week about their USAID content, and I expect to see something here from them soon. :)
If you see content you like from GiveWell in the future, I encourage you to to reach out to them and suggest that they crosspost it! You can also flag it to myself or Toby and we can reach out, though that may take longer.
The value of re-directing non-EA funding to EA orgs might still be under-appreciated. While we obsess over (rightly so) where EA funding should be going, shifting money from one EA cause to another "better" ne might often only make an incremental difference, while moving money from a non-EA pool to fund cost-effective interventions might make an order of magnitude difference.
There's nothing new to see here. High impact foundations are being cultivated to shift donor funding to effective causes, the “Center for effective aid policy” was set up (then shut down) to shift governement money to more effective causes, and many great EAs work in public service jobs partly to redirect money. The Lead exposure action fund spearheaded by OpenPhil is hopefully re-directing millions to a fantastic cause as we speak.
I would love to see an analysis (might have missed it) which estimates the “cost-effectiveness” of redirecting a dollar into a 10x or 100x more cost-effective intervention, How much money/time would it be worth spending to redirect money this way? Also I'd like to get my head around how much might the working "cost-effectiveness" of an org improve if its budget shifted from 10% non-EA funding to 90% non- EA funding.
There are obviously costs to roping in non-EA funding. From my own experience it often takes huge time and energy. One thing I’ve appreciated about my 2 attempts applying for EA adjacent funding is just how straightforward It has been – probably an order of magnitude less work than other applications.
Here’s a few practical ideas to how we could further redirect funds
- EA orgs could put more effort into helping each other access non-EA money. This is already happening through the AIM cluster, but I feel the scope could be widened to other orgs, and co-ordination could be improved a lot without too much effort. I’m sure pools of money are getting missed all the time. For example I sure hope we're doing whatever we can through our networks to help EA gender based violence orgs / family planning orgs to get hold of some of this 250 million dollars from Melinda.
- When assessing cost-effectiveness of new interventions and charities (especially global health), I think potential to access non-EA future funding could be taken into account. If a new charity has a relatively smooth path to millions of dollars of external funding, should our cost-effectiveness bar be lower? Again this might well be happening already.
- We might have a blind spot missing cause areas where cost-effectiveness might initially look sub-optimal, but huge available non-EA money-pools might shift the calculus. One example is climate mitigation, where Billions of dollars slosh around, wasted on ineffective interventions. Many “mitigation activities” I see here in northern Uganda might as well be burning money (in a carbon neutral way of course). GiveDirectly have made a great play here re-directing millions of climate mitigations funds to cash transfers. Could other “climate mitigation orgs” be set up to utilise this money better even if the end point of the money wasn't strictly climate related?
I would imagine far smarter people have thought about this far more deeply, but there might still be room for more exploration and awareness here.
The CE of redirecting money is simply (dollars raised per dollar spent) * (difference in CE between your use of the money vs counterfactual use). So if GD raises $10 from climate mitigation for every $1 it spent, and that money would have otherwise been neutral, then that's a cost-effectiveness of 10x in GiveWell units.
There's nothing complicated about estimating the value of leverage. The problem is actually doing leverage. Everyone is trying to leverage everyone else. When there is money to be had, there are a bunch of organizations trying to influence how it is spent. Melinda French Gates is likely deluged with organizations trying to pitch her for money. The CEAP shutdown post you mentioned puts it perfectly:
The core thesis of our charity fell prey to the 1% fallacy. Within any country, much of the development budget is fixed and difficult to move. For example, most countries will have made binding commitments spanning several years to fund various projects and institutions. Another large chunk is going to be spent on political priorities (funding Ukraine, taking in refugees, etc.) which is also difficult for an outsider to influence.
What is left is fought over by hundreds, if not thousands of NGOs all looking for funding. I can’t think of any other government budget with as many entities fighting over as small a budget. The NGOs which survive in this space, are those which were best at getting grants. Like other industries dependent on government subsidies, they fight tooth and nail to ensure those subsidies stay put.
This doesn't mean that leverage is impossible. It just means that leverage opportunities tend to be specific and limited. We have to take them on opportunistically, rather than making leverage a theory of impact.
I largely agree, although I don't think we're trying to leverage money that hard in some areas areas. I do think there needs to be some strategy for leverage as well as a lot of opportunism as you say. Collaboration as I mentioned opens up opportunities as well.
Sometimes also it's not so hard to access pools of money, for example how many orgs are trying hard to access all that climate money?
On the subject of redirecting streams of money from less impactful causes to EA causes, I feel I need to beat my drum regarding the potential of Profit for Good businesses (businesses with charities in all or almost all of the shareholder position). In such cases, to the extent EA PFGs profits displace those of normal businesses, funds are diverted from the average shareholder to an effective charity.
So when a business like Humanitix (PFG helping projects in the developing world, $4mil AUD to The Life You Can Save) displaces the marketshare of Ticketmaster, funds are diverted not from charities, but from the funds of the business's competitors. This method of diversion seems less difficult because the operative actors (consumers, employees, business partners) are not deciding between a strong non-EA charity often optimized for warm fuzzies and marketing, but rather choosing between products with similar value propositions, but where engaging with one - in addition to the other value proposition - implies helping fight malaria or something instead of enriching a random investor.
If you're interested in learning more about Profit for Good, here is a reading list on the subject.
Disclaimer: I think the instant USAID cuts are very harmful, they directly affect our organisation's wonderful nurses and our patients. I'm not endorsing the cuts, I just think exaggurating numbers when communicating for dramatic effect (or out of ignorance) is unhelpful and doesn't build trust in institutions like the WHO.
Sometimes the lack of understanding, or care in calulations from leading public health bodies befuddles me.
"The head of the United Nations' programme for tackling HIV/AIDS told the BBC the cuts would have dire impacts across the globe.
"AIDS related deaths in the next five years will increase by 6.3 million" if funding is not restored, UNAIDS executive director Winnie Byanyima said."
https://www.bbc.com/news/articles/cdd9p8g405no
There just isn't a planet on which AIDS related deaths would increase that much. In 2023 an estimated 630,000 people were estimated to have died from AIDS related deaths. The WHO estimates about 21 million Africans on HIV treatment. Maybe 5 million of these in South Africa aren't funded by USAID. Other countries like Kenya and Botswana also contribute to their own HIV treatment.
So out of those 16ish million on USAID funded treatment, over 1/3 of those would have to die in the next 3 years for that figure would be correct. The only scenario where this could happen is if all of these people went completely untreated, which means that no local government would come in at any stage. This scenario is impossible
I get that the UN HIV program want to put out scary numbers to put the pressure on the US and try and bring other funding in, but it still important to represent reality. Heads of public health institutions and their staff who do this kind of modelling should learn what a counterfactual is.
"AIDS related deaths in the next five years will increase by 6.3 million" if funding is not restored, UNAIDS executive director Winnie Byanyima said.
This is a quote from a BBC news article, mainly about US political and legal developments. We don't know what the actual statement from the ED said, but I don't think there's enough here to infer fault on her part.
For all we know, the original quote could have been something like predicting that deaths will increase by 6.3 million if we can't get this work funded -- which sounds like a reasonable position to take. Space considerations being what they are, I could easily see a somewhat more nuanced quote being turned into something that sounded unaware of counterfactual considerations.
There's also an inherent limit to how much fidelity can be communicated through a one-sentence channel to a general audience. We can communicate somewhat more in a single sentence here on the Forum, but the ability to make assumptions about what the reader knows helps. For example, in the specific context here, I'd be concerned that many generalist readers would implicitly adjust for other funders picking up some of the slack, which could lead to double-counting of those effects. And in a world that often doesn't think counterfactually, other readers' points of comparison will be with counterfactually-unadjusted numbers. Finally, a fair assessment of counterfactual impact would require the reader to understand DALYs or something similar, because at least a fair portion of the mitigation is likely to come from pulling public-health resources away from conditions that do not kill so much as they disable.
So while I would disagree with a statement from UNAIDS that actually said if the U.S. doesn't fund PEPFAR, 6.3MM more will die, I think there would be significant drawbacks and/or limitations to other ways of quantifying the problem in this context, and think using the 6.3MM number in a public statement could be appropriate if the actual statement were worded appropriately.
Thanks Jason - those are really good points. In general maybe this wasn't such a useful thing to bring up at this point in time, and in general its good that she is campaigning for funding to be restored. I do think the large exaggeration though means this a bit more than a nitpick.
I've been looking for her saying the actual quote, and have struggled to find it. A lot of news agencies have used the same quote I used above with similar context. Mrs. Byanyima even reposted on her twitter the exact quote above...
"AIDS-related deaths in the next 5 years will increase by 6.3 million"
I also didn't explain properly but even at the most generous reading of something like After 5 years deaths will increase by 6.3 million if we get zero funding for HIV medication, the number is still wildly exaggurated. Besides the obvious point that many people would self fund the medications if there was zero funding available (I would guess 30%-60%), and that even short periods of self funded treatment (a few months) would greatly increase their lifespan, the 6.3 million is still incorrect at least by a factor of 2.
Untreated HIV in adults in the pre HAART era in Africa had something like an 80% survival rate (maybe even a little higher) 5 years after seroconversion, which would bring a mortality figure of 3.2 million dying in 5 years assuming EVERYONE on PEPFAR drugs remained untreated - about half the 6.3 million figure quoted. Here's a graph of mortality over time in the Pre HAART era. Its worth keeping in mind that our treatment of AIDS defining infections is far superior to what it was back then, which would keep people alive longer as well.
https://pmc.ncbi.nlm.nih.gov/articles/PMC5784803/
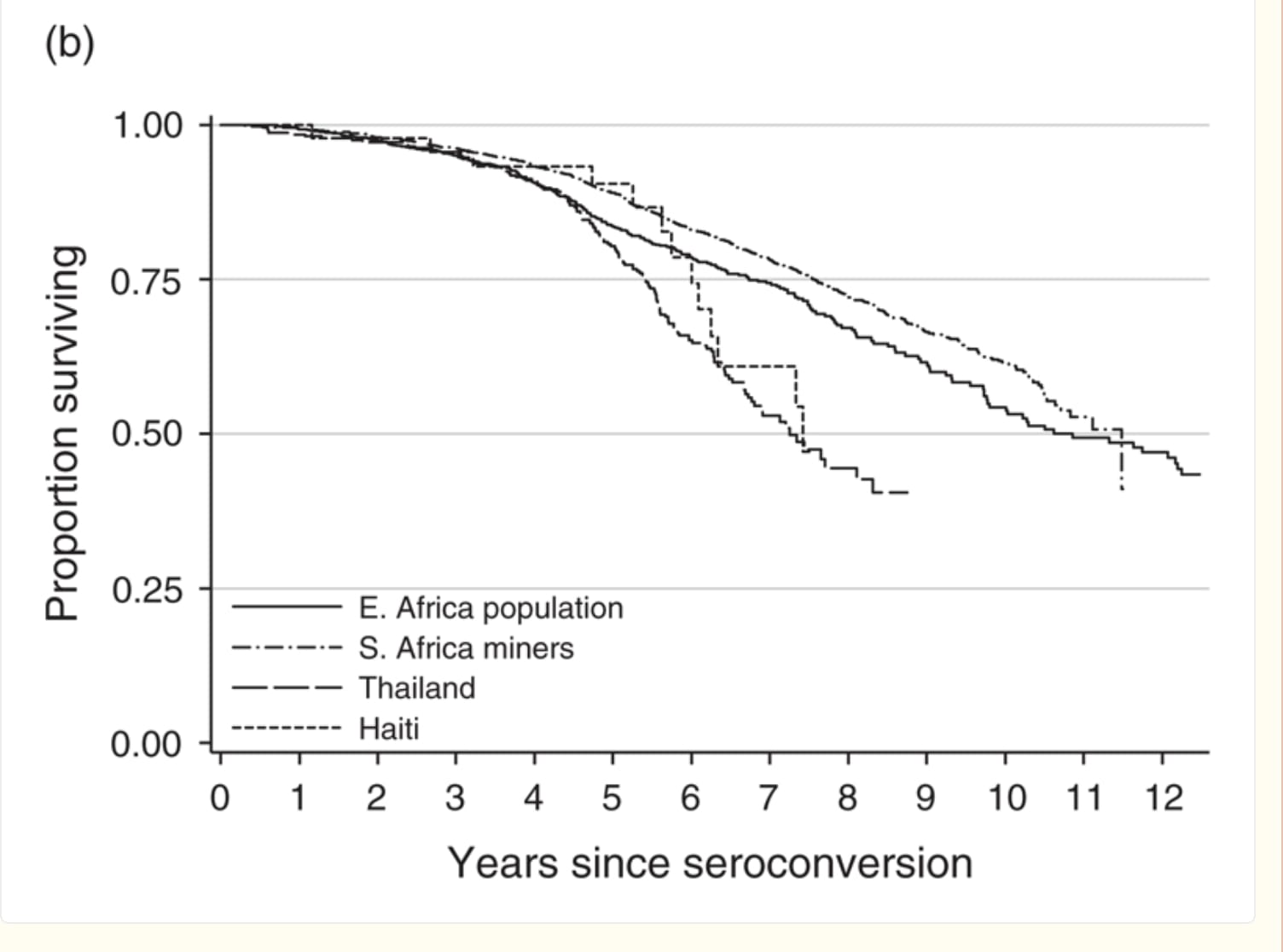
And my 3.2 million figure doesn't take into account the not-insignificant number of people who would die within 5 years even while on ARVs which further reduces the extra deaths figure.
Also many countries like Uganda have about 1 years supply of medications left, so we should perhaps be considering the 10% mortality after 4 years of no medications rather than 20% at 5 in this calculation, which would halve the death numbers again.
So I still think the statement remains a long way off being accurate, even if we allow some wiggle room for wording like you rightly say we should.
The only scenario where this could happen is if all of these people went completely untreated, which means that no local government would come in at any stage. This scenario is impossible
Can you elaborate why this is impossible, or at least unlikely?
The idea that no (or even few) Sub-Saharan African countres would stand in the gap for their most vulnerable people with HIV, abandoning them to horrendous sickness and death from HIV that would overwhelm their health systems shows lack of insight.
Countries simply can't afford to leave people with HIV completely high and dry, economically and politcally. HIV medication would be a priority for most African countries - either extra fundng would be allocated or money switched from other funds to HIV treatment. As much as governments aren't utilitarian, they know the disaster that would ensue if HIV medications were not given and their heallth systems were overwhelmed. AIDS is a horrible condition which lasts a long time and robs individuals and families of their productivity.
Granted care might be far worse. Funding for tests like viral load cold be cut, there might be disastrous medicaion stockouts. Hundreds of thousands or even more could die because of these USAID cuts. Funding for malaria, tuberculosis and other treatments might fall by the wayside but I believe for most countries HIV care would be a top priority.
There would be some countries that are either too poor or unstable where this might not happen. Countrie like South Sudan, DRC, Somalia - but I strongly believe that most countries would provide most people with HIV most of their treatment for free.
Besides this, given it is life saving I would estimate maybe half (uncertain) of peopl ewith HIV would buy their own medication if there was no other option - if the alternative is death their family would pool money to keep them alive.
Another minor point is that I think drug companies would likely hugely drop the cost of medication as well - otherwise they wouldn't be able to sell much of it.
AI risk in Depth, in the mainstream!
Perhaps the most popular British Podcast, the Rest is Politics has just spent 23 minutes in one of the most compelling and straightforward explanations of AI risk I've heard anywhere, let alone in the mainstream media. The first 5 minutes of the discussion is especially good as an explainer and then there's a more wide ranging discussion after that.
Recommended sharing with non-EA friends, especially in England as this is a respected mainstream podcasts that not many people will find weird - Minute 16 to 38. He also discusses (near the end) his personal journey of how he became scared of AI which is super cool.
I don't love his solution of England and EU building their own "honest" models, but hey most of it is great.
Also a shoutout as well to any of you in the background who might have played a part in helping Rory Stewart think about this more deeply.
I'm a little confused as to why we consider the leaders of AI companies (Altman, Hassabis, Amodei etc.) to be "thought leaders" in the field of AI safety in particular. Their job descriptions are to grow the company and increase shareholder value, so their public persona and statements has to reflect that. Surely they are far too compromised for their opinions to be taken too seriously, they couldn't make strong statements against AI growth and development even if they wanted to, because of their job and position.
The recent post "Sam Altman's chip ambitions undercut OpenAI's safety strategy" seems correct and important, while also almost absurdly obvious - the guy is trying to grow his company and they need more and better chips. We don't seriously listen to big tobacco CEOs about the dangers of smoking, or Oil CEOs about the dangers of climate change, or Factory Farming CEOs about animal suffering, so why do we seem to take the opinions of AI bosses about safety even in moderate good faith? The past is often the best predictor of the future, and the past here says that CEOs will grow their companies, while trying however possible to maintain public goodwill as to minimise the backlash.
I agree that these CEOs could be considered thought leaders in AI in general and the Future and potential of AI, and their statements about safety and the future are critically practically important and should be engaged with seriously. But I don't really see the point of engaging with them as thought leaders in the AI safety discussion, it would make more sense to me to rather engage with intellectuals and commentators who can fully and transparently share their views without crippling levels of compromisation.
I'm interested to hear though arguments in favour of taking their thoughts more seriously.
Who is considering Altman and Hassabis thought leaders in AI safety? I wouldn't even consider Altman a thought leader in AI - his extraordinary skill seems mostly social and organizational. There's maybe an argument for Amodei, as Anthropic is currently the only one of the company whose commitment to safety over scaling is at least reasonably plausible.
Thanks that's a helpful perspective and I would be happy if it was true that they weren't considered AI safety thought leaders. I do feel like they are often seen this way though in the public sphere, and sometimes here on the forum too.
I realize that my question sounded rethorical, but I'm actually interested in your sources or reasons for your impression. I certainly don't have a good idea of the general opinion and the media I consume is biased towards what I consider reasonable takes. That being said, I haven't encountered the position you're concerned about very much and would be interested to be hear where you did. Regarding this forum, I imagine one could read into some answers, but overall I don't get the impression that the AI CEO's are seen as big safety proponents.
POLL: Is it OK to eat honey[1]?
I've appreciated the Honey wars. We've seen the kind of earnest inquiry that makes EA pretty great.
I'm interested to see where the community stands here. I have so much uncertainty that I'm close to the neutral point, but I've been updated towards it maybe not being OK - I previously slurped the honey without a thought. What do you think[2]?
- ^
This is a non-specific question. "OK" could mean a number of things (you choose). It could mean you think eating net honey is "net positive" (My pleasure/health > small chance of bee suffering), or could mean "does no harm at all", or even "Morally acceptable" - which might mean you think it does harm but you can offset it, or that the harm isn't bad enough for you to stop or anything along those lines.
- ^
@Toby Tremlett🔹 said it was inappropriate for a poll not to have 2 footnotes so here it is...
I'm reading "OK" as "morally permissible" rather than "not harmful". E.g., I think it's also "OK" to eat meat, even though I think it's causing harm.
(Not saying you should clarify the poll, it's clear enough and will probably produce interesting results either way!)
Nice one! Read it as you will sir :D - perhaps I should have been more specific, but there are trade-offs to specificity on polls like this too.
Personally, I think no poll is complete without at least two footnotes.
It's not OK to eat honey
My best guess is that eating honey is pretty bad, because I buy that bees have non-negligible moral weight, and the arguments for bee-lives being net-negative seem plausible too.
I'm far less wedded to bee lives being net-negative, so it could be that I'll be convinced that eating honey isn't just good, but extremely good—that eating honey is one of the best things modern humans do, because it allows for the existence of many flourishing bees.
It's OK to eat honey
I am quite uncertain because I am unsure to what extend a consumption boycott affects production; however, I lean slightly on the disagree side because boycotting animal-based foods is important for:
- Establishing pro-animal cultural norms
- Incentivizing plant-based products (like Honee) that already face an uphill climb towards mass adoption
It's OK to eat honey
I try to avoid it, but it's hard for me to believe it's as bad or worse than most animal products. Especially in the quantities it's usually consumed. Who eats a kg of honey per year? I do think the treatment of bees is very unclear. But I've also heard that some non-animal products involve a lot of insects, like avocados, so I'm curious how it compares.
It's OK to eat honey
I plead clueless
The Happier Lives Institute have helped many people (including me) open their eyes to Subjective Wellbeing and perhaps even update us to the potential value of SWB. The recent heavy discussion (60+ comments) on their fundraising thread disheartened me. Although I agree with much of the criticism against them, the hammering they took felt at best rough and perhaps even unfair. I'm not sure exactly why I felt this way, but here are a few ideas.
- (High certainty) HLI have openly published their research and ideas, posted almost everything on the forum and engaged deeply with criticism which is amazing - more than perhaps any other org I have seen. This may (uncertain) have hurt them more than it has helped them.
- (High certainty) When other orgs are criticised or asked questions, they often don't reply at all, or get surprisingly little criticism for what I and many EAs might consider poor epistemics and defensiveness in their posts (for charity I'm not going to link to the handful I can think of). Why does HLI get such a hard time while others get a pass? Especially when HLI's funding is less than many of orgs that have not been scrutinised as much.
- (Low certainty) The degree of scrutiny and analysis of some development orgs in general like HLI seems to exceed that of AI orgs, Funding orgs and Community building orgs. This scrutiny has been intense- more than one amazing statistician has picked apart their analysis. This expert-level scrutiny is fantastic, I just wish it could be applied to other orgs as well. Very few EA orgs (at least that have been posted on the forum) produce full papers with publishable level deep statistical analysis like HLI have at least attempted to do. Does there need to be a "scrutiny rebalancing" of sorts. I would rather other orgs got more scrutiny, rather than development orgs getting less.
Other orgs might see threads like the HLI funding thread hammering and compare it with other threads where orgs are criticised and don't engage, so the thread falls off the frontpage. Orgs might reasonably decide that high degrees of transparency and engagement might do them net harm rather than good. This might not be good for anyone
Do you agree/disagree? And what could we do to make the situation better?
I think it's fairest to compare HLI's charity analysis with other charity evaluators like Givewell, ACE, and Giving Green.
Giving Green has been criticised regularly and robustly (just look up any of their posts). Givewell publish their analysis and engage with criticism; HLI themselves have actually criticised them pretty robustly! I don't know about ACE because I don't stay up to date on animals but I bet it's similar there.
The dynamics are quite different for example in charitable foundations where they don't need to convince anyone to donate differently, or charities that deliver a service who only need to convince their funders to continue donating.
Thanks Kristen for this clear and concise reply. This comparison with the experience of other charity evaluators has shifted my opinion on this somewhat nice one.
It seems a bit of a pity that they should receive significantly more scrutiny than charities or foundations though. In an ideal world everyone should be transparent and heavily scrutinised but it does make sense that the incentives might not be there for other orgs...
I agree that more orgs should get this kind of scrutiny. I agree that we are likely to blindly trust orgs that don't transparently discuss their inst workings, which is super sad.
Interesting reflection on Mental health providers too, be that's not a world I know!
This argument I struggle with...
"I don't think the problem is that HLI got too much hate for fucking up, it's that everyone else gets too little hate for being opaque"
I realize you are probably beinga bit tongue in cheek, but I think we could criticise and discuss while being more encouraging and positive. We are all human, to and I'm not sure piling on the "hate" will necessarily lead to improvement in epistemics and rigorous analysis.
[This comment is no longer endorsed by its author]
I don't know about ACE because I don't stay up to date on animals but I bet it's similar there.
I am a bit more familiar with ACE, and my impression is that you are right.
HLI fucked up their analysis, but because it was public we found out about it. Most EAs are too fearful to expose their work to scrutiny. Compare them to others who work on mental health within EA...
Most coaches and therapists in EA don't do any rigorous testing of whether what they are doing actually works. They don't even allow you to leave public reviews for them. I think we're the only organisation to even have a TrustPilot!!!
I don't think the problem is that HLI got too much hate for fucking up, it's that everyone else gets too little hate for being opaque.
Now HLI have been dragged through the mud, you can bet your ass they won't be making the same mistakes again. So long as they keep being transparent, they'll keep learning and growing as an org. Others will keep making the same mistakes indefinitely, only we'll never know about it and will continue blindly trusting them.
I agree that more orgs should get this kind of scrutiny. I agree that we are likely to blindly trust orgs that don't transparently discuss their inst workings, which is super sad.
Interesting reflection on Mental health providers too, be that's not a world I know!
This argument I struggle with...
"I don't think the problem is that HLI got too much hate for fucking up, it's that everyone else gets too little hate for being opaque"
I realize you are probably beinga bit tongue in cheek, but I think we could criticise and discuss while being more encouraging and positive. We are all human, to and I'm not sure piling on the "hate" will necessarily lead to improvement in epistemics and rigorous analysis.
Although I agree with much of the criticism against them, the hammering they took felt at best rough and perhaps even unfair.
One general problem with online discourse is that even if each individual makes a fair critique, the net effect of a lot of people doing this can be disproportionate, since there's a coordination problem. That said, a few things make me think the level of criticism leveled at HLI was reasonable, namely:
- HLI was asking for a lot of money ($200k-$1 million).
- The critiques people were making seemed (generally) unique, specific, and fair.
- The critiques came after some initial positive responses to the post, including responses to the effect of "I'm persuaded by this; how can I donate?"
Does there need to be a "scrutiny rebalancing" of sorts. I would rather other orgs got more scrutiny, rather than development orgs getting less.
I agree with you that GHD organizations tend to be scrutinized more closely, in large part because there is more data to scrutinize. But there is also some logic to balancing scrutiny levels within cause areas. When HLI solicits donations via Forum post, it seems reasonable to assume that donations they receive more likely come out of GiveWell's coffers than MIRI's. This seems like an argument for holding HLI to the GiveWell standard of scrutiny, rather than the MIRI standard (at least in this case).
That said, I do think it would be good to apply stricter standards of scrutiny to other EA organizations, without those organizations explicitly opening themselves up to evaluation by posting on the Forum. I wonder if there might be some way to incentivize this kind of review.
When HLI solicits donations via Forum post, it seems reasonable to assume that donations they receive more likely come out of GiveWell's coffers than MIRI's. This seems like an argument for holding HLI to the GiveWell standard of scrutiny, rather than the MIRI standard (at least in this case).
I am concerned that rationale would unduly entrench established players and stifle innovation. Young orgs on a shoestring budget aren't going to be able to withstand 2023 GiveWell-level scrutiny . . . and neither could GiveWell at the young-org stage of development.
Yeah, I should've probably been more precise: the criticism of HLI has mainly been leveled against their evaluation of a single organization's single intervention, whereas GW has evaluated 100+ programs, so my gut instinct is that it's fair to hold HLI's StrongMinds evaluation to the same ballpark level of scrutiny we'd hold a single GW evaluation to (and deworming certainly has been held to that standard). It might be unfair to expect an HLI evaluation to be at the level as a GW evaluation per dollar invested/hour spent (given that there's a learning curve associated with doing such evaluations and there's value associated with having multiple organizations do them), but this seems like—if anything—an argument for scrutinizing HLI's work more closely, since HLI is trying to climb a learning curve, and feedback facilitates this.
I think another factor is that HLI's analysis is not just below the level of Givewell, but below a more basic standard. If HLI had performed at this basic standard, but below Givewell, I think strong criticism would have been unreasonable, as they are still a young and small org with plenty of room to grow. But as it stands the deficiencies are substantial, and a major rethink doesn't appear to be forthcoming, despite being warranted.
Probably a stupid question (probably just missed), can someone point me to where Givewell do a meta-analysis or similar depth of analysis as this HLI one. I can't seem to find it and I would be keen to do a quick compare myself.
I'm not aware of a GW analysis quite like this one, although I didn't go back and look at all its prior work.
In a situation like this, where GiveWell was considering StrongMinds as a top charity recommendation, it's almost certain that it would have first funded a bespoke RCT designed to address key questions for which the available literature was mixed or inconclusive. HLI doesn't have that luxury, of course. Moreover, what HLI is trying to measure is significantly harder to tease out than "how well do bednets work at saving lives" and similar questions.
I think those are relevant considerations that make comparing HLI's work to the "GiveWell standard" inappropriate. However, to acknowledge Ben's point, HLI's critics are alleging that the stuff that was missed was pretty obvious and that HLI hasn't responded appropriately when the missed stuff was pointed out. I lack the technical background and expertise to fully evaluate those claims.
Which GiveWell evaluation(s) though? The ones on that spreadsheet range from the evaluations used to justify Top Charity status to decisions to deprioritize a potential program after a shallow review. Two deworming charities were until recently GiveWell Top Charities, and I believe Open Phil still makes significant grants to them (presumably in reliance on GiveWell's work).
In this post, HLI explicitly compares its evaluation of StrongMinds to GiveWell's evaluation of AMF, and says:
"At one end, AMF is 1.3x better than StrongMinds. At the other, StrongMinds is 12x better than AMF. Ultimately, AMF is less cost-effective than StrongMinds under almost all assumptions.
Our general recommendation to donors is StrongMinds."
This seems like an argument for scrutinizing HLI's evaluation of StrongMinds just as closely as we'd scrutinize GiveWell's evaluation of AMF (i.e., closely). I apologize for the trite analogy, but: if every year Bob's blueberry pie wins the prize for best pie at the state fair, and this year Jim, a newcomer, is claiming that his blueberry pie is better than Bob's, this isn't an argument for employing a more lax standard of judging for Jim's pie. Nor do I see how concluding that Jim's pie isn't the best pie this year—but here's a lot of feedback on how Jim can improve his pie for next year—undermines Jim's ability to win pie competitions going forward.
This isn't to say that we should expect the claims in HLI's evaluation to be backed by the same level of evidence as GiveWell's, but we should be able to take a hard look at HLI's report and determine that the strong claims made on its basis are (somewhat) justified.
Yes, agree that the language re: AMF justifies a higher level of scrutiny than would be warranted in its absence. Also, the AMF-related claim makes more moderate changes in the CEA bottom-line material than if the claims had been limited to stuff like: SM is more cost-effective than other predominately life-enhancing charities like GiveDirectly.
My read is it wasn't the statistics they got hammered on misrepresenting other people's views of them as endorsements e.g. James Snowden's views. I will also say the AI side does get this criticism but not on cost-effectiveness but on things like culture war (AI Ethics vs. AI Safety) and dooming about techniques (e.g. working in a big company vs. more EA aligned research group and RLHF discourse).
Thanks for the AI perspective!
Yes in that post the misrepresentation was part of the criticism they receive (which they engaged with and was at least partially corrected which is impressive) but I think the statistical analysis bore the most heavy overall criticism in that post, and in other earlier posts.
"Fair" and "unfair" are tricky words to nail down.
I think there are a wide range of factors that explain why HLI has been treated differently than other orgs -- some "fair" under most definitions of the word, some less so. Some of those reasons are adjacent to questions of funding and influence, but I'm not sure they provide much room to criticize HLI's critics.
- HLI is running in a lane -- global health/development/wellbeing -- where the evidentiary standards are much higher than in longtermist areas. Part of this is the nature of the work; asking a biosecurity program how many pandemics it has prevented is not workable. Part of it is that there is a very well-funded organization that has been doing CEAs that conensus views as high-quality. Yet another aspect is that GHDW work has been much more limited by funding constraints, which has incentivized GHDW funders to adopt higher standards.
- I think people generally need to be kinder to smaller-scale, early-stage efforts . . . but see point 3 below.
- HLI is a charity recommender, a significant portion of whose focus currently involves making recommendations to ordinary people (not megadonors, foundations, etc.) I do think the level of scrutiny should ordinarily be higher for charity recommenders, especially those making recommendations to the general public. The purpose of a charity recommender is to evaluate the relative merits of various charities, and for ordinary donors their recommendations may be seen as near-authoritative. A sense that the community needs to carefully scrutinize the recommender's work destroys much of a recommender's value proposition in the first place. And while it's not very utilitarian of me, I do feel more protective of small donors who don't have an in-house staff to pick up on a recommender's mistakes.
- I think an overconfident marketing campaign in 2022 did play a major role in how much grace people are willing to extend on the CEA. I haven't been around that long, but this does seem to significantly distinguish HLI from other orgs. I believe that HLI has expressed regret for certain statements, but a framework that compares statements made at that time (that have not been clearly and explicitly retracted) to what the data actually support strikes me as on the "fair" side of the ledger.
- This was HLI's first major recommendation; people would be less prone to draw negative inferences about (e.g.) an org whose first four analyses/recommendations were fine but whose fifth had some significant issues.
- StrongMinds spends (and could potentially fundraise) enough money to make a significant dive into its cost-effectiveness worthwhile for critics, but probably not so much as to justify an airtight multi-million dollar workup (including by commissioning our own studies to fill any major holes in the data that would have a big effect on the CEA). So it's an awkward-size program to evaluate.
- Pretty much all skeptical analysis is done by volunteers on their own time, and so the volume/quality of that work will heavily depend on who is interested in and available to doing it. It's plausible to me that having a controversial and/or novel framework could motivate more critics to volunteer for duty.
- There could also be a snowball effect; the detection of one significant weakness in a CEA may motivate others to start looking.
- HLI asked Forum users to contribute money. Although I take a wide stance on "standing" to criticize organizations, one could reasonably characterize asking users for action as opening the door to some extent. Having an active fundraising ask may also provide a more concrete payoff/impact for criticism, by preventing users from taking an action the critic found undesirable.
- HLI has been unusually transparent with data and responsive to criticism, which has made such criticism easier and kept it up longer. I think you're right to be concerned about the ferocity of criticism disincentivizing trransparency and opennness on the margin.
- The barriers to criticizing HLI are much lower. Because HLI has little power, no one is concerned about blowback. Compare that to the recent Omega criticisms of AI labs, which were posted psuedonymously and which had to rely on undisclosed data. Criticism from established community members who sign their work and can show their work carries more weight, and there's a disincentive to writing anonymous criticism (you'll never get any credit for it).
Several of these points are at least adjacent to questions of funding and power, and they cumulatively make me feel at least somewhat uncomfortable, e.g.:
- It's unlikely an organization with more secure funding would have made a fundraising appeal at this time. Rather, it likely would have laid low until it had produced a new CEA for SM and until more time had passed since the prior harsh posts.
- HLI may have felt pressure to be particularly transparent and responsive than a more established org. It's unlikely HLI would have been taken seriously if it didn't show its receipts, and it doesn't have the power/prestige needed for a "no real comment" approach to criticism to have a good shot at working.
That being said, I find it challenging to assign much fault for those factors to the Forum user community on those. For example, in point 10, the unfairness is not that HLI is being criticized by named users who have built up a reputation, but that the criticism of other orgs is disincentivized and psuedonymous.
I think you're right that the response to HLI may discourage transparency and responsiveness on the margin, and that this is a problem. As a practical matter, I think there are two factors that mitigate this to some extent. One is that I think the criticism of HLI reflects a convergence of a number of factors as listed above, and I'm not sure how much marginal effect comes from their good transparency and responsiveness. Second, I think any startup org trying to pursue HLI-like goals has to be transparent and responsive to get a hearing from the community, so I think it less likely that knowledge of current events will change another org's stance to a materially less open and responsive one.
I'm undecided on the net effect of all of this. My hope is that it will ultimately result in adoption of better epistemic safeguards and communications management -- both at HLI and elsewhere in the ecosystem. (Cf. my recent post on the HLI thread). That would be a good result, although I'd still wish we had gotten there with a lot less rancor.
Quite right. Far too much scrutiny was applied to HLI. Five thousand words autistic debunkings, though highly entertaining to read and no doubt equally entertaining to their authors, should not have been necessary. Any reasonable model of how the world works would not perhaps not quite rule the idea of group therapy in poor countries out of court, but require an incredibly high standard of evidence to even begin discussing it somewhat politely.
On the subject of scrutinizing other orgs, I note that some hardworking but anonymous EAs have done their best to scrutizine EA's various AI research orgs, but of course this is much more specialized endeavour requiring deeper expertise and is also entirely pointless because OpenPhil will probably fund them anyway.
We've banned Sol3:2 for 3 weeks. This comment is uncivil and was reported multiple times. Other comments have been reported in the past for similar reasons.
I want to note that criticism can be extremely valuable, and we have a slightly higher bar for taking mod action against criticism. But referring to analyses of HLI's work as "autistic" clearly violates core Forum norms and is above that bar. I think it’s possible to outline strong disagreements while still following our norms, and we’d want to see this from Sol3:2 in the future.
If Sol3:2 thinks that this is not right, they can appeal.
At Risk of violating @Linch's principle "Assume by default that if something is missing in EA, nobody else is going to step up.", I think it would be valuable to have a well researched estimate of the counterfactual value of getting investment from different investors (whether for profit or donors).
For example in global health, we could make GiveWell the baseline, as I doubt whether there is a ll funding source where switching as less impact, as the money will only ever be shifted from something slightly less effective. For example if my organisation received funding from GiveWell, we might only make slightly better use of that money than where it would otherwise have gone, and we're not going to be increasing the overall donor pool either.
Who knows, for-profit investment dollars could be 10x -100x more counterfactually impactful than GiveWell, which could mean a for-profit company trying to do something good could plausibly be 10-100x less effective than a charity and still doing as much counterfactual good overall? Or is this a stretch?
This would be hard to estimate but doable, and must have been done at least on a casual scale by some people.
Examples ( and random guesses) of counterfactual comparisons of the value of each dollar given by a particular source might be something like....
1. GiveWell 1x
2. Gates Foundation 3x
3. Individual donors NEW donations 10x
4. Indivudal donors SHIFTING donations. 5x
5. Non EA-Aligned foundations 8x
6. Climate funding 5x
7. For-profit investors. 20x
Or this might be barking up the wrong tree, not sure (and I have mentioned it before)
I'm admittedly a bit more confused by your fleshed-out example with random guesses than I was when I read your opening sentence, as it went in a different direction than I expected (using multipliers instead of subtracting the value of the next-best alternative use of funds), so maybe we're thinking about different things. I also didn't understand what you meant by this when I tried to flesh it out myself with some (made-up) numbers:
Who knows, for-profit investment dollars could be 10x -100x more counterfactually impactful than GiveWell, which could mean a for-profit company trying to do something good could plausibly be 10-100x less effective than a charity and still doing as much counterfactual good overall?
If it helps, GiveWell has a spreadsheet summarising their analysis of the counterfactual value of other actors' spending. From there and a bit of arithmetic, you can figure out their estimates of the value generated by $1 million in spending from the following sources, expressed in units of doubling consumption for one person for a year:
- Government social security spending: 2,625 units
- Government education spending: 2,834 units
- Donating to GiveDirectly's cash transfer program (1x cash for reference): 3,355 units
- Government spending on deworming: 3,525 units
- Government spending on malaria, VAS, and immunization programs: 5,057 units (this is also what GW uses as their counterfactual value by domestic governments in assessing SMC)
- Government health spending: 5,639 units (this is also GW's assumed value generated by philanthropic actors's spending on VAS and vitamin A capsule procurement in other countries)
- Gavi spending (US allocations to Gavi and Maternal and Child Health): 6,952 units
- Global Fund (calculations here): 15,433 units
- HKI spending on vitamin A supplementation in Kenya, before final adjustments: ~19,000 units
- GW's 10x cash bar for reference: 33,545 units
- AMF spending on ITN distribution in DRC, before final adjustments: ~36,800 units
- Open Phil's current 2,100x bar: very naively ~70,000 units (21x GiveDirectly to oversimplify, using OP's 100x ≈ 1x cash to GD)
Suppose there's an org ("EffectiveHealth") that could create 50k units worth of benefits given $1M in funding. If it came from GW with their 33.5k units counterfactual value, then a grant to EffectiveHealth from GW would be creating 16.5k more units of benefits than otherwise, while if it came from domestic govt spending (7.5x lower value at 5k per $1M) it'd create 45k more units of benefits. A hypothetical for-profit investor whose funding generates 10x less good than domestic govt spending (500 units) would get you not 10 x 45k = 450k more units of benefits, but 49.5k units. And if EffectiveHealth got funding from OP it would actually be net-negative by -20k units.
(maybe you meant something completely different, in which case apologies!)
I think this kind of investigation would be valuable, but I'm not sure what concrete questions you'd imagine someone answering to figure this out.
I was a bit worried for the last 3 weeks that the Forum had gone quiet...
Then I come back after a 5 day Ugandan internet blackout and there are lots of fantastic front page posts great job everyone!!!
Im intrigued where people stand on the threshold where farmed animal lives might become net positive? I'm going to share a few scenarios i'm very unsure about and id love to hear thoughts or be pointed towards research on this.
-
Animals kept in homesteads in rural Uganda where I live. Often they stay inside with the family at night, then are let out during the day to roam free along the farm or community. The animals seem pretty darn happy most of the time for what it's worth, playing and galavanting around. Downsides here include poor veterinary care so sometimes parasites and sickness are pretty bad and often pretty rough transport and slaughter methods (my intuition net positive).
-
Grass fed sheep in New Zealand, my birth country. They get good medical care, are well fed on grass and usually have large roaming areas (intuition net positive)
-
Grass fed dairy cows in New Zealand. They roam fairly freely and will have very good vet care, but have they calves taken away at birth, have constantly uncomfortably swollen udders and are milked at least twice daily. (Intuition very unsure)
-
Free range pigs. Similar to the above except often space is smaller but they do get little houses. Pigs are far more intelligent than cows or sheep and might have more intellectual needs not getting met. (Intuition uncertain)
Obviously these kind of cases make up a small proportion of farmed animals worldwide, with the predominant situation - factory farmed animals likely having net negative lives.
I know that animals having net positive lives far from justifies farming animals on it's own, but it seems important for my own decision making and for standing on solid ground while talking with others about animal suffering.
Thanks for your input.
It's really hard to judge whether a life is net positive. I'm not even sure when my own life is net positive—sometimes if I'm going through a difficult moment, as a mental exercise I ask myself, "if the rest of my life felt exactly like this, would I want to keep living?" And it's genuinely pretty hard to tell. Sometimes it's obvious, like right at this moment my life is definitely net positive, but when I'm feeling bad, it's hard to say where the threshold is. If I can't even identify the threshold for myself, I doubt I can identify it in farm animals.
If I had to guess, I'd say the threshold is something like
- if the animals spend most of their time outdoors, their lives are net positive
- if they spend most of their time indoors (in crowded factory farm conditions, even if "free range"), their lives are net negative
it seems important for my own decision making and for standing on solid ground while talking with others about animal suffering.
To this point, I think the most important things are
- whatever the threshold is, factory-farmed animals clearly don't meet it
- 99% of animals people eat are factory-farmed (in spite of people's insistence that they only eat meat from their uncle's farm where all of the animals are treated like their own children etc)
That's really interesting on your own life. Even in the midst of my worst emotional states (emotional not physical pain,) I would still feelI'm on the positive side of the ledger.
Yes I agree on your list 2 points, those are the most important in general
In Northern Uganda here though. the majority of animals people eat (not often, many people eat meat once or twice a month) have lives from my first example. In New Zealand almost all beef and sheep meat is from something like options 2 and 3, so I think the question has some relevance to a decent number of people.
Just adding: the discussion of dairy cows, here and elsewhere, tends to focus on the experience of the adult cattle & the suffering for them of being milked, deprived of their babies, etc.
But it's not implausible to me that the majority of the disvalue from dairy is in the lives of the calves born to dairy cows. In typical milk-producing operations, adult cows have 1 calf every 18 months or so; 50% of them are male, and so are killed within a few hours to a few months after birth.
(& these lives more likely to be net negative because they have less time to experience positive things to outweigh the terror and pain of death. Undoubtedly, some of their deaths will be quite quick, but others are slow and brutal.)
(Also, veal calves are treated very badly - intense confinement to reduce movement to keep the meat tender, dietary restriction to keep the meat pale, individual confinement in a tiny 'hutch', etc.)
(& let's not forget the fetal calves who are still gestating when their mothers go to slaughter. They're killed slowly, if they ever get purposefully slaughtered at all rather than just left to asphyxiate. Obviously, it's unclear whether they're conscious, but I've read accounts of them moving, opening eyes, trying to breathe, etc.).
Thanks for this. My view is the same as yours. The first two strike me as "net positive." I'm also unsure about what pigs and dairy cows need. I wouldn't be hugely surprised if they have either "net positive" or "net negative" lives, but I think it's most likely (80%+ chance) they are "net positive."
(Qualifying discussion of net value of existence with " " because I find such valuations always so fraught with uncertainty and I feel I owe other beings tremendous humility in this!)
I’m always surprised to see sheep get lumped in with cows in discussions of farmed animal welfare (ex. the SSC Adversarial Collaboration). Sure, it’s not a terrible proxy, but sheep are often freer, need to be regularly shorn to avoid overheating, and usually die of natural causes. There are definitely some practices which are awful, but sheep are quite hard to optimise in the same way we’ve done with pigs & chickens, or even cows.
However, we eat them when they’re babies so maybe it swings in the absolute other direction.
Nice point Huw, I agree. I wasn't trying to lump them together exactly, I agree its very different. Does eating them when they are babies necessarily mean a net negative life though, if the slaughter is humane? It does seem like a weird question though...
The idea behind why eating babies is more likely to be net negative is that there's a shorter lifespan of positive experiences to balance out the terror and pain of death.
From my experience watching lots of slaughterhouse footage and reading accounts from workers, even the best humane conditions still involve, routinely, a (shorter or longer) period in which the animal goes through the process of dying. This is probably pretty bad. If they only lived for a few weeks before that, it's harder to imagine it's a good deal overall.
Under some frameworks, you’d be depriving them of many years of happy life; but then again, if you didn’t kill them as children they probably would never have been born for food. Here we’d be getting too deep into the moral philosophy for me to have a confident take 😅. Interesting nonetheless.
"but it seems important for my own decision making and for standing on solid ground while talking with others about animal suffering."
I'm highly skeptical of this - why do you think it is important for your own moral decision making? It seems to me that whether farmed animals lives are worth living or not is irrelevant - either way we should try to improve their conditions, and the best ways of doing that seem to be: a boycott & political pressure (I would argue that the two work well together).
By analogy, no one raises the question of whether the lives of people living in extreme poverty, or working in sweatshops and so on, are worth living, because it's simply irrelevant.
This seems relevant to any intervention premised on "it's good to reduce the amount of net-negative lives lived."
If factory-farmed chickens have lives that aren't worth living, then one might support an intervention that reduces the number of factory-farmed chickens, even if it doesn't improve the lives of any chickens that do come to exist. (It seems to me this would be the primary effect of boycotts, for instance, although I don't know empirically how true that is.)
I agree that this is irrelevant to interventions that just seek to improve conditions for animals, rather than changing the number of animals that exist. Those seem equally good regardless of where the zero point is.
I suppose I agree with this. And I've been mulling over why it still seems like the wrong way to think about it to me, and I think it's that I find it rather short-termist. In the short term if farms shut down they might be replaced with nature, with even less happy animals, it's true. But in the long term opposing speciesism is the only way to achieve a world with happy beings. Clearly the kinds of farms @NickLaing is talking about, with lives worth living but still pretty miserable, are not optimal. Figuring out whether they are worth living or not seems only relevant to trying to reduce suffering in the short term, but not so much in the long term, because in the long term this isn't what we want anyway.
Applying my global health knowledge to the animal welfare realm, I'm requesting 1,000,000 dollars to launch this deep net positive (Shr)Impactful charity. I'll admit the funding opportunity is pretty marginal...
Thanks @Toby Tremlett🔹 for bringing this to life. Even though she doesn't look so happy I can assure you this intervention nets a 30x welfare range improvement for this shrimp, so she's now basically a human.
Look I know I'm on the forum too much @Toby Tremlett🔹 , but I don't think its necessary to put "reading limit" controls on me....
Lol, maybe you've just read them all (I'll ping the dev)
Wanted to give a shoutout to Ajeya Cotra (from OpenPhil), for her great work explaining AI stuff on a recent Freakonomics podcast series. Her explanations about both her work on the development of AI, and her easy to understand predictions of how AI might progress from here were great, she was my favourite expert on the series.
People have been looking for more high quality public communicators to get EA/AI safety stuff out there, perhaps Ajeya could be a candidate if she's keen?
Ajeya is already doing that with Kelsey Piper over at their blog Planned Obsolescence :)
Are big Orgs better than individuals/small orgs at achieving things?
This is a response to @Mo Putera's quick take - on the notion that Big, elite, established orgs are more likely to succeed compared with individuals and smaller orgs. He looked at Scott Alexander's grants and saw that individuals were more likely to fail compared with bigger orgs. "One disappointing result was that grants to legibly-credentialled people operating in high-status ways usually did better than betting on small scrappy startups (whether companies or nonprofits)."
First, yes on a basic level Individuals and small startups will have a lower probability of making their thing work than bigger organisations, for a few reasons.
- Less leverage on the issue they are trying to on (less relationships/connections built)
- Lack of institutional knowledge and experience
- Less organisational/relational cushions to lean on or fall back on when there are setbacks- either the individual has the skills/drive/luck to make it work or they don't
- Sometimes small orgs are going for bigger/moonshotty stuff that will have a high baseline failure rate no matter who is doing at it.
This is why I love Charity Entrepreneurship's approach to starting new things, which mitigates many of these disadvantages
1. A team of researchers who pre-select causes/issues that are likely to be tractable.
2. Careful selection process looking for ability/resilience/commitment etc.
3. A 2 month incubation process learning about org building, M@E, operations etc.
4. Ongoing formal support both from the CE team and wider community after getting started
Many of the individuals/small orgs Scott Alexander gives to don't have that support.
BUT Big Orgs may Lie more and Look the other way.
I also think that bigger organisations are FAR MORE likely to exaggerate their success than EA aligned individuals and small orgs. Big orgs fail ALL THE TIME on their projects (I see it all the time here in Uganda), and you almost never hear about it.
Admitting failures is unfortunately A huge negative for big orgs as it will attract media attention and donors will stop giving. Incentives are so wired against admitting even small shreds of failure
So they usually don't tell us.
Some evidence for this is the standout Give Directly, who carefully outline their problems, mistakes and failures. including over a million dollars stolen in DRC. And I'm sure they still miss plenty. GiveDirectly are one of the least corruption/failure prone orgs due to their simple model of just sending people money, and yet still have plenty of failures/fraud to report. So what about all the other big orgs which will have far higher levels of failure/corruption than GiveDirectly? They either cover it up or don't look. World Vision, Care, Save the children etc. fail at likely most of what they do and have big corruption issues, yet where are the reports? Even GiveWell funded orgs AMF and Malaria Consortium don't report their no-doubt-many failures and corruption issues as far as I know.
I've seen enormous failure/corruption from big orgs in just my tiny patch of Northern Uganda but you'll very rarely see these reported. In some cases when I expose corruption/uselessness to big NGOs I agreed to stay quiet on it so at least they would fix some of their issues.
Also big orgs often overstate how much difference more marginal money can make - there are many forms of subtle/soft" double counting that occur, through telling everyone who gives them money that they are funding the highest impact stuff, but that's a whole 'nother mini-essay...
So yes, the variance is far higher with individuals/small orgs and they do probably fail more, but don't just trust the rhetoric of big orgs either.
This is one of the first times I have seen lead poisoning make front page news!
https://www.bbc.com/news/articles/cy4n7wn8l58o
Could this be an opportunity for the new lead alliance, or even just one of the lead orgs to help China do better on lead? Maybe there will be a window where they are more open to external help? It seems China has new "maximum" lead levels regulations in paint from 2020 but there are obviously still issues...
Could well still not be worth it though if there are other "lower hanging fruit" on the lead front.
We've been vibing on shrimp a bit recently, and particularly liked this short video where JD manages to break through to his mum that shrimp might be worth something. Maybe we're sometimes underestimate the Overton window?
I think a small team of people should focus on shrimp, I doubt, it's the most efficient way. I'm vegan yet....I think it's not the best idea ever. I can't believe people use linkedin, non-ironically.
Is there a world where 30% Tariffs on Chinese goods going into America is net positive for the world?
Could the Tariff reduce consumption and carbon emissions a little in the USA, while China puts more focus more on selling goods to lower income countries? Could this perhaps result in a tiny boost in growth in low income countries?
Could the improved wellbeing/welfare stemming from growth in low income countries + reduced American consumption offset the harms caused by economic slowdown in America/China?
Probably not - I'm like 75% sure the answer is no, but thought the question might be worth asking...
I was encouraged to read this Economist article, "The demise of foreign aid offers an opportunity Donors should focus on what works. Much aid currently does not" which I would say has at least some EA adjacent ideas.
They mention health spending, which by the nature of all 4 of GiveWell's top charities can often be more cost effective than other options, plus pandemic prevention.
"What should they do? One answer is to stop spending on programmes that do not work, and to focus on the things that might, such as health spending. Even here, however, governments must be vigilant that they are putting their money to its best use. Three principles should guide them.
The first is to act in areas where governments (or the UN agencies they fund) have special co-ordinating power, say because they have the security apparatus to reach disaster or conflict zones. Another is to get involved if they have information the public will struggle to assess, about adapting to climate change, say, or a new pandemic. Last, are they funding causes that generate positive spillovers, such as preventing the global spread of infectious diseases?"
Not exactly ITN, but not a bad take either!
Although I'm enamoured as a mostly-neartermist that the front page (for the first time in my experience) is devoid of AI content, I really would like to hear the job experience and journey of a few AI safety/policy workers for this jobs week. The first 10ish wonderful people who shared are almost all neartermist focused, which probably doesn't represent the full experience of the community.
I'm genuinely interested to understand how your AI safety job works and how you wonderful people motivate yourselves on a day to day basis, when seeing clear progress and wins must be hard a lot of the time. I find it hard enough some days working in Global health!
Or maybe your work is so important, neglected and urgent that your can't spare a couple of hours to write a post ;).
I've been on the forum for maybe 9 months now, and I've been intrigued by the idea of "hits based" giving, explained well in this 2016 article by Holden Karnofsky. The idea that "we will sometimes bet on ideas that contradict conventional wisdom, contradict some expert opinion, and have little in the way of clear evidential support."
1) Is there a database with a list of donations considered "hits based"by Openphil? If not that would be a helpful and transparent way of tracking success on these. I had a quick look through their donations but its not clear which ones are considered "hits based"
2) Are there any donations considered "hits based" since that 2016 post which have clearly turned out really well, i.e. been winners? We might have seen some these hit based donations resolve positively or negatively, although 6 years is a short timeline so most would remain unresolved. Is there any official or unofficial info on that?
Thanks!
The net net effect could be positive or negative. Let me untangle it for you.
In favour of net positivity is the net positive human lives saved through net negative, negative net effects on mosquitos and malaria causing a net positive effect on humans. The insecticides positively embed these bed net, net positive effects.
However there’s a catch in favour of net negativity - as nets are positively dragged to net fish, the netted fish suffer net negative net negativity.
While caught between the net positive net positivity to humans and net negative net negativity to fish, we are enmeshed in a net of uncertainty as we struggle to net a clear positive net answer.
Hopefully I didn’t tie you in knots as I strung you along.
In response to @David Mathers ;).


I've been mulling over this quote from Naomi Klein over the last couple of days. I think its a strong summary of one of the best ethical arguments against the top AI labs.
My argument against this might be that the actual purpose of commercial application is to improve human wellbeing and prosperity overall, not to eliminate jobs. Jobs may or may not be eliminated, but either option could be fine if the prosperity is shared (at least somewhat) throughout humanity.
Then there are orgs like Mechanize, which are explicitly trying to eliminate jobs...
Besides that on the "theft" of creativity front, I think this is broadly true but I'm not sure what can be done at this point. To generalise (even with coding) AI feeds of the best that humanity has to offer then produces worse-than-the-best output much faster, at a fraction of the cost. Without the best of human IP, AI wouldn't be very good. Newer models may be starting to be better than the best humans in niche areas, but this isn't the norm.
I talk a lot about how AI helps us provide healthcare to some of the poorest people, but I still don't have the greatest response to these kind of criticisms from many of my friends. I wonder how others respond to people when they bring arguments like this?
A lot of modern training data isn’t stolen, though. There are organisations which recruit people to do their jobs normally and screen share, or provide worked-through examples of their work, and this is increasingly making up the bulk of the data that’s used to pull frontier models ahead of others on work benchmarks. People are being paid for this and do it willingly, usually with knowledge of where their labour outputs are going!
So really, the problem is a subset of workers in each field are ‘defecting’ (to use a rat term I kinda loathe). How do you create solidarity among groups of workers to prevent a small number of them from putting the others out of work? Or, if technological progress is to be necessary, how do those groups of workers politically agitate for a welfare state and good ongoing education?
The left solved this problem two hundred years ago, but I suspect EA won’t like the solution…
In general it's okay for a person to look at a dozen different paintings and then make a new painting that's kind of like those paintings. This seems pretty analogous to what AI is doing and I'm not sure why it becomes not OK if it's done by a corporation training an AI model. Perhaps there are specific violations of IP laws, and those can be discussed (and some of them are being adjudicated in court as we speak), and of course there is a separate question of whether those IP laws are just. However, what AI models doing to me seems mostly like it's the sort of behavior we would be OK with individual people doing: i.e closer to the remixing/synthesizing end of the spectrum than the copying/"stealing" end.