Comments

From Reuters:
SAN FRANCISCO, Sept 25 (Reuters) - ChatGPT-maker OpenAI is working on a plan to restructure its core business into a for-profit benefit corporation that will no longer be controlled by its non-profit board, people familiar with the matter told Reuters, in a move that will make the company more attractive to investors.
I sincerely hope OpenPhil (or Effective Ventures, or both - I don't know the minutia here) sues over this. Read the reasoning for and details of the $30M grant here.
The case for a legal challenge seems hugely overdetermined to me:
- Stop/delay/complicate the restructuring, and otherwise make life appropriately hard for Sam Altman
- Settle for a large huge amount of money that can be used to do a huge amount of good
- Signal that you can't just blatantly take advantage of OpenPhil/EV/EA as you please without appropriate challenge
I know OpenPhil has a pretty hands-off ethos and vibe; this shouldn't stop them from acting with integrity when hands-on legal action is clearly warranted
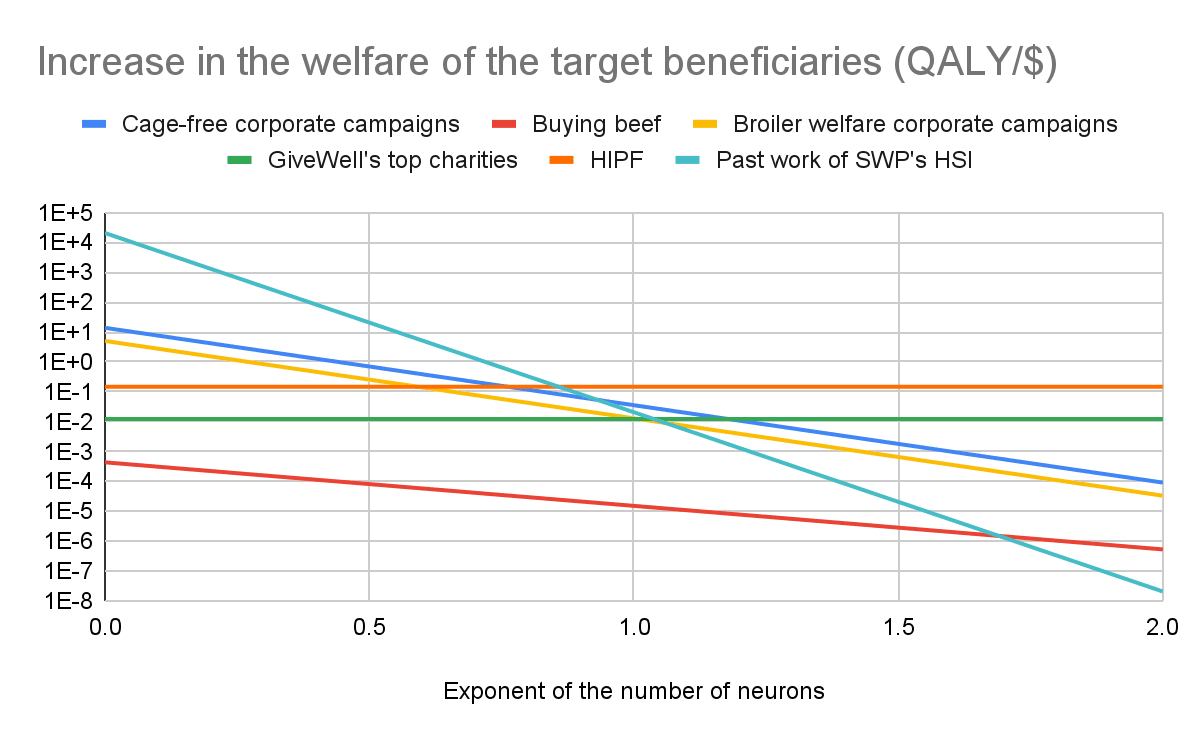
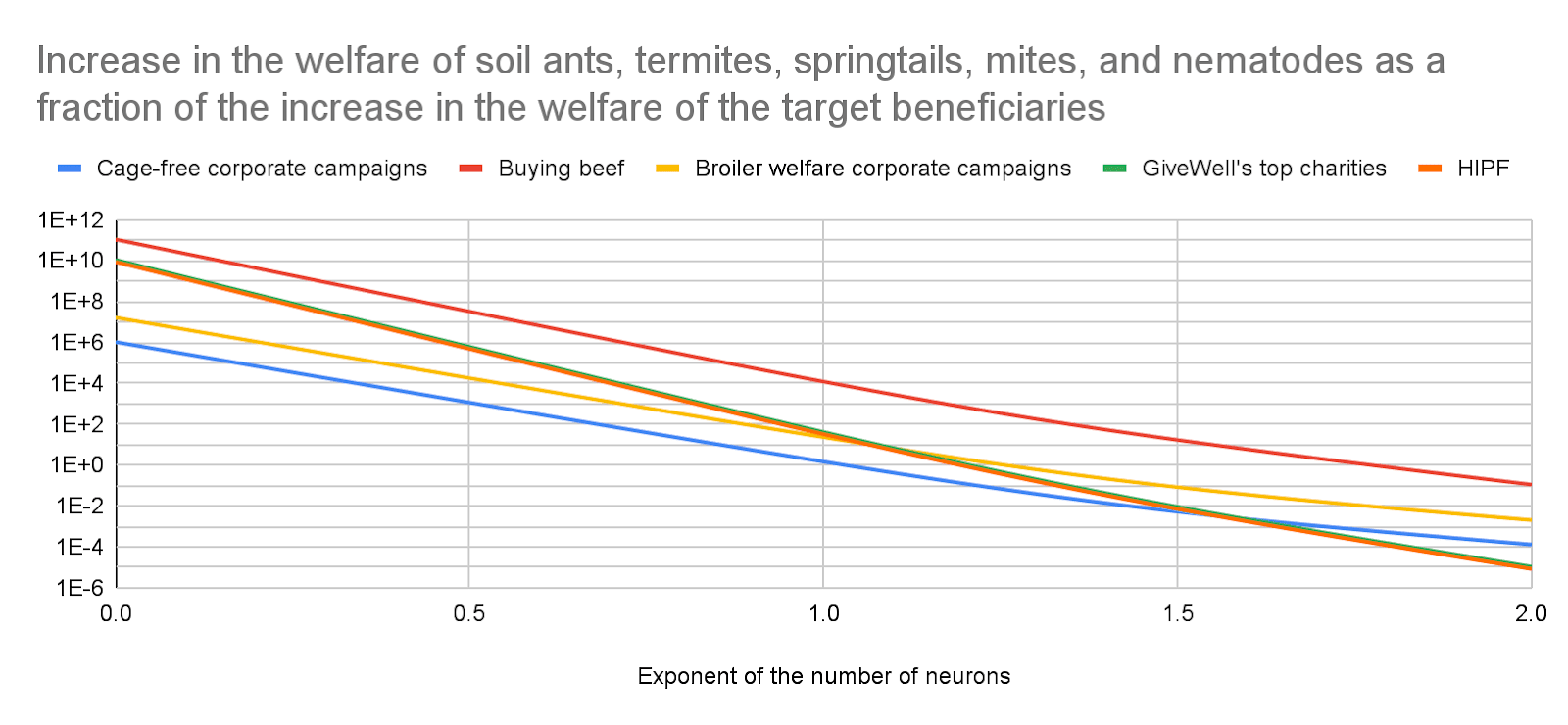
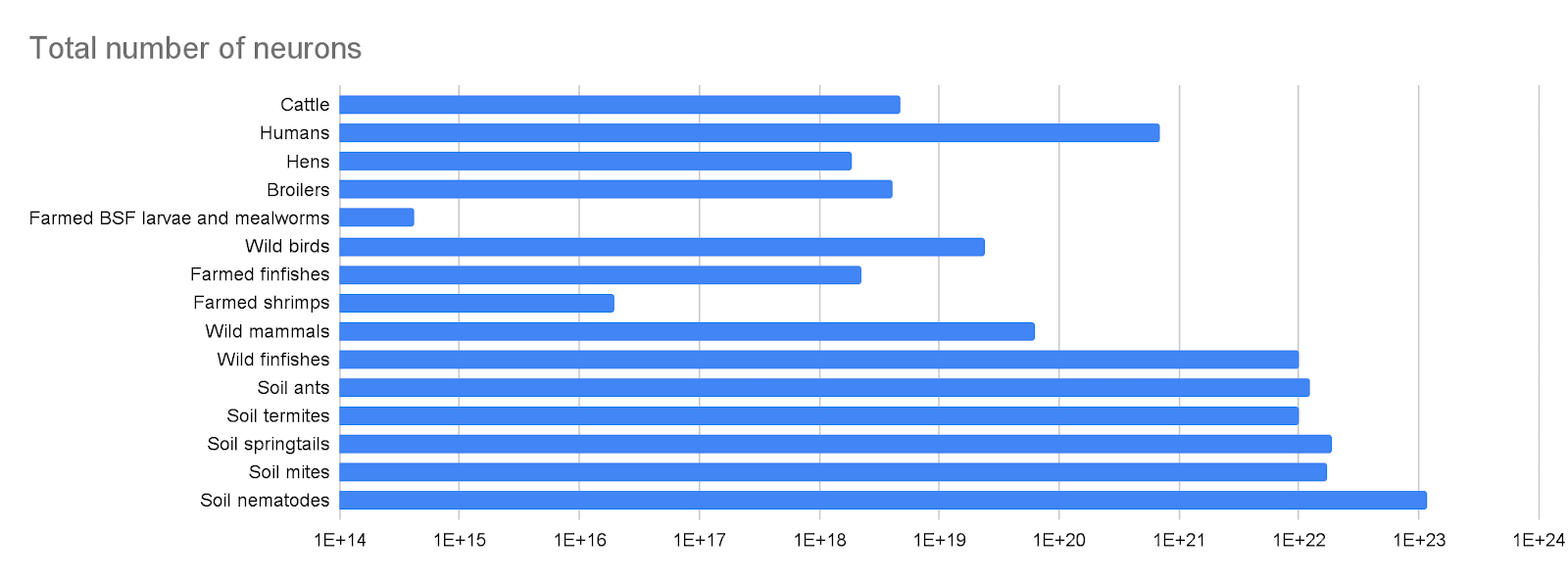
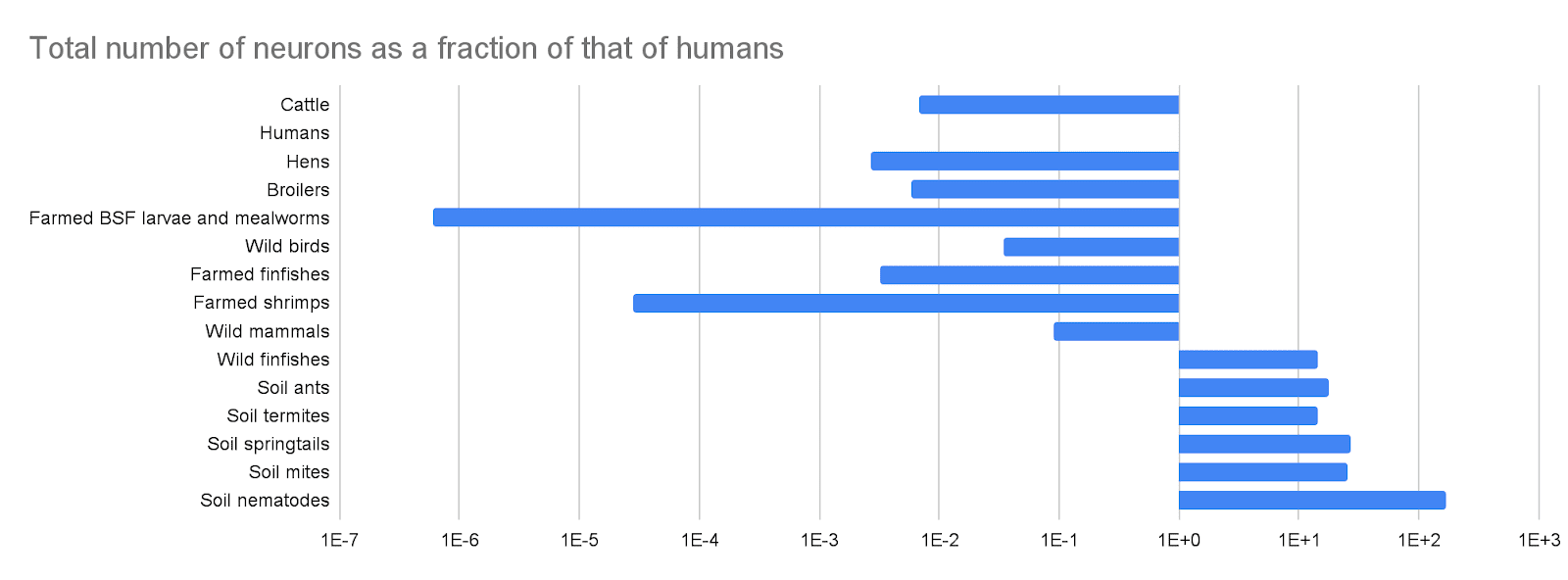

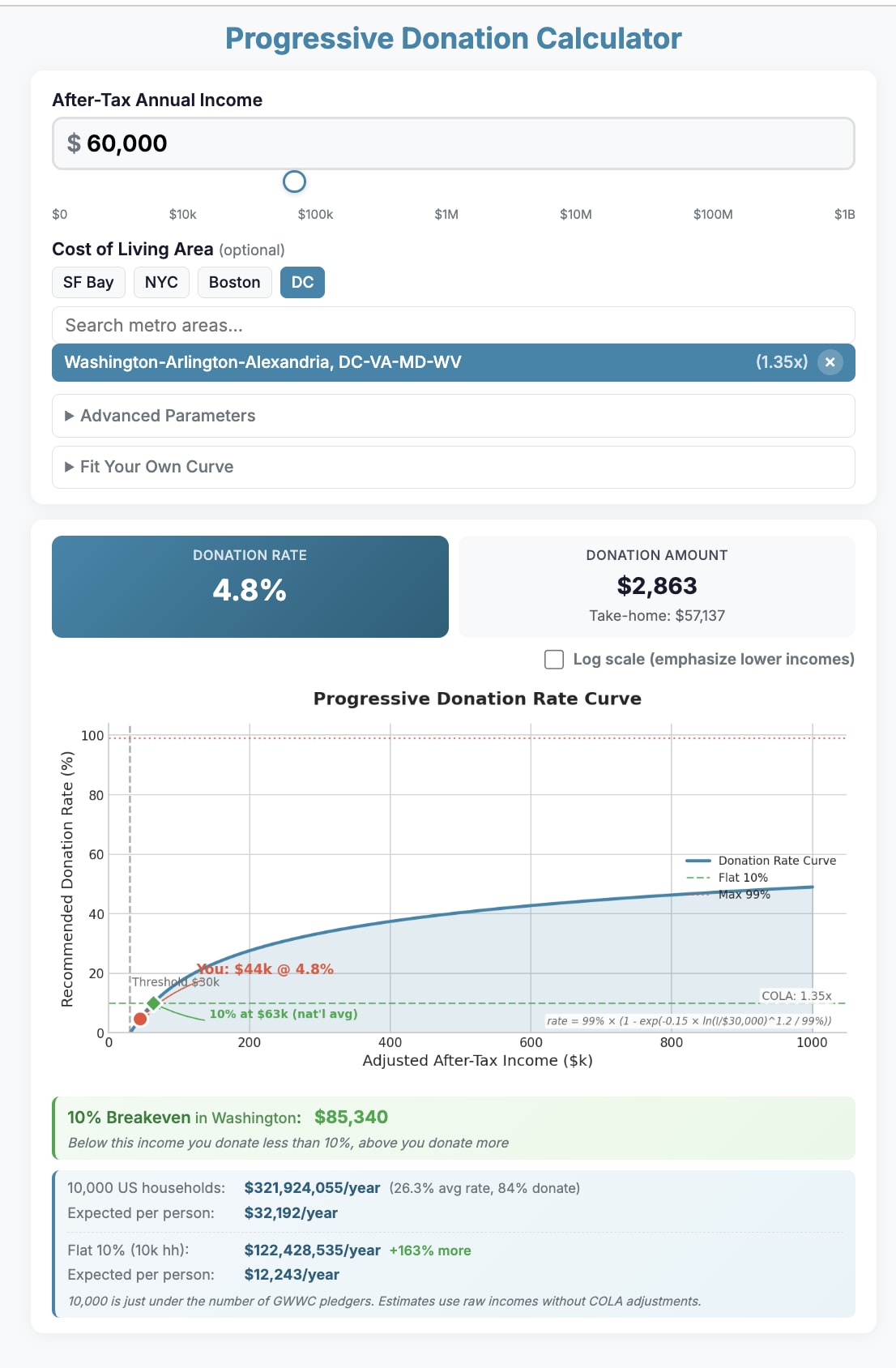





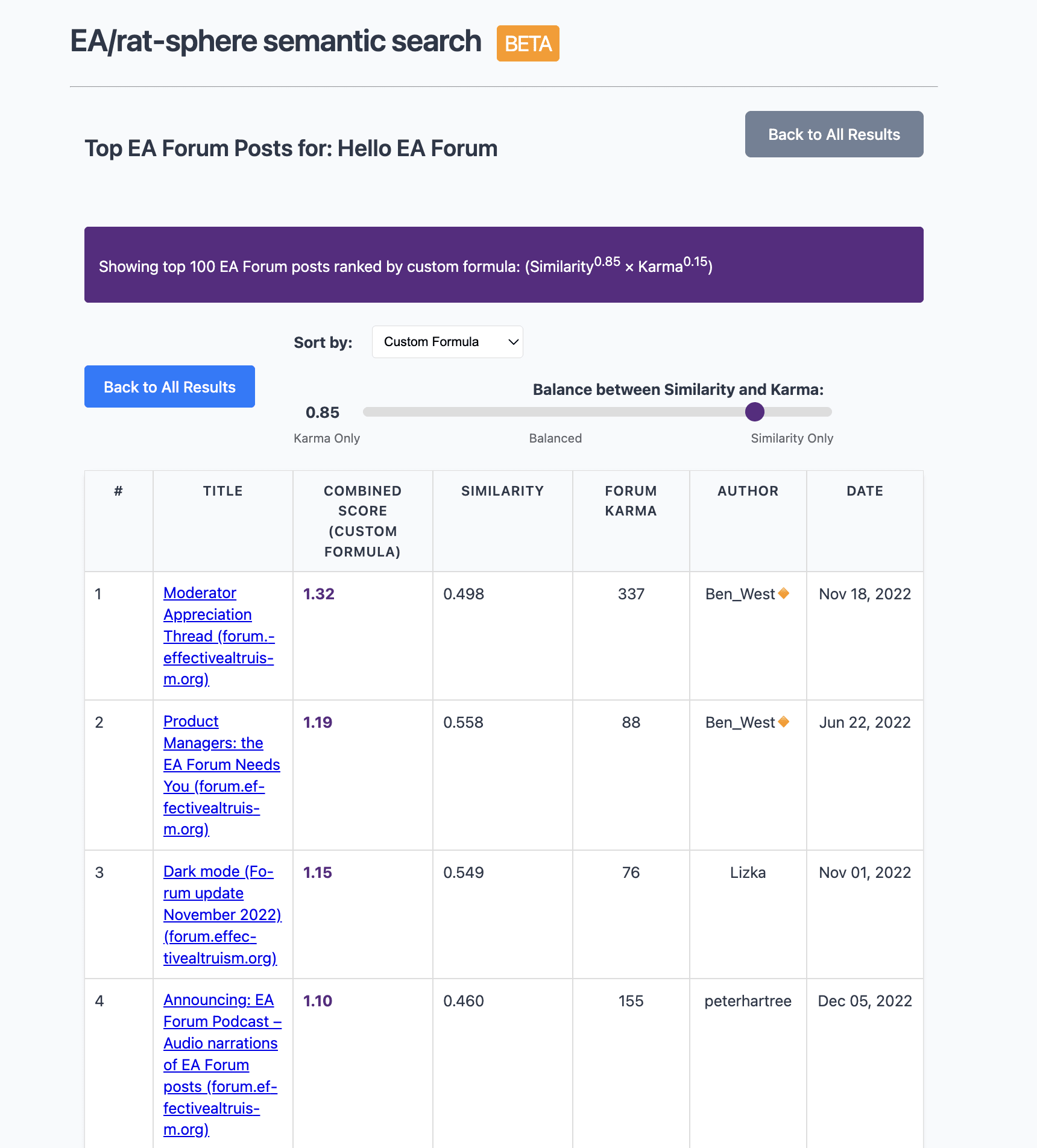
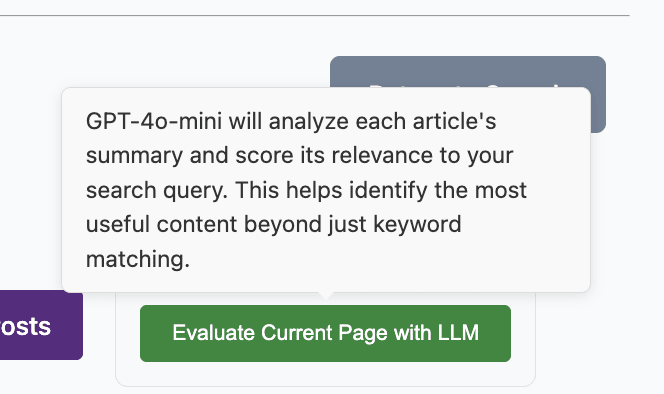
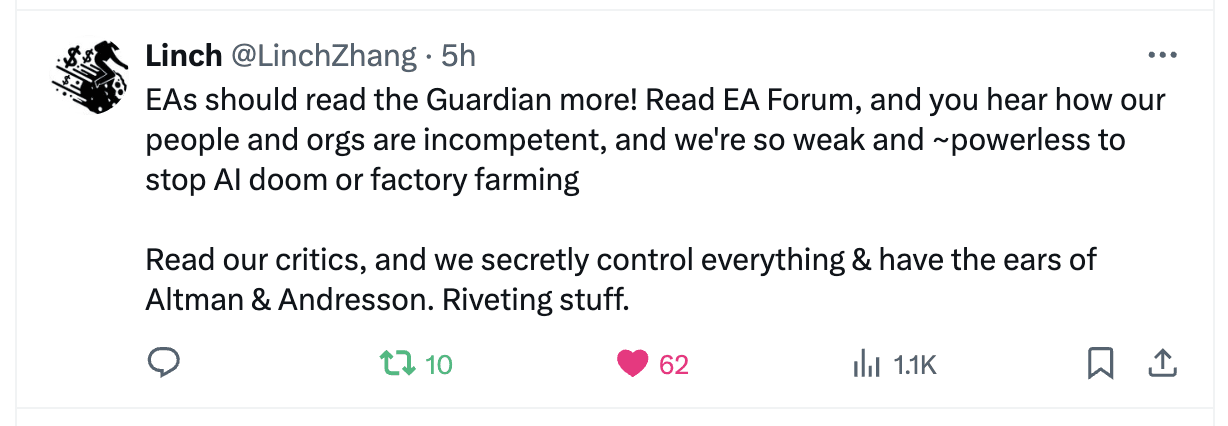

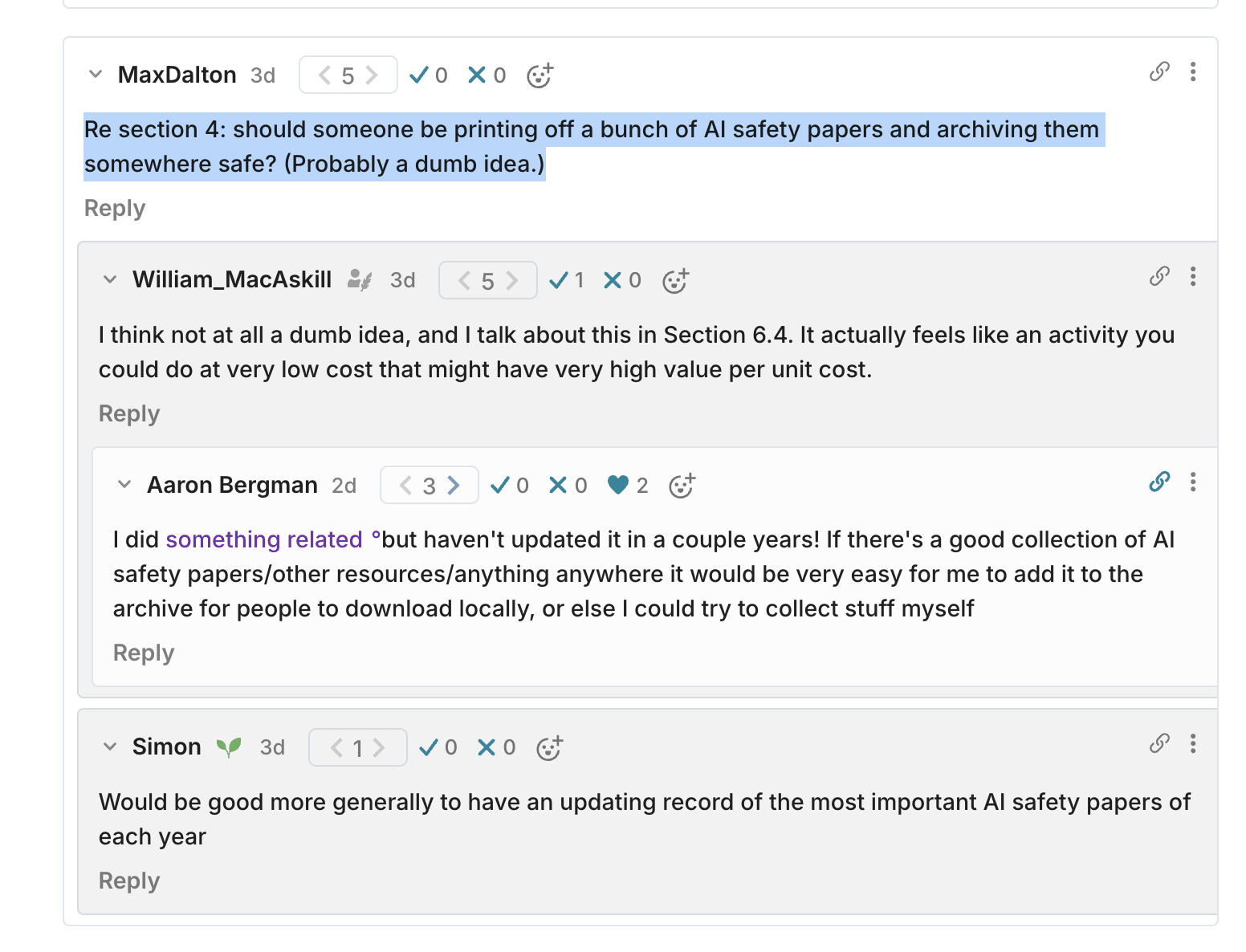


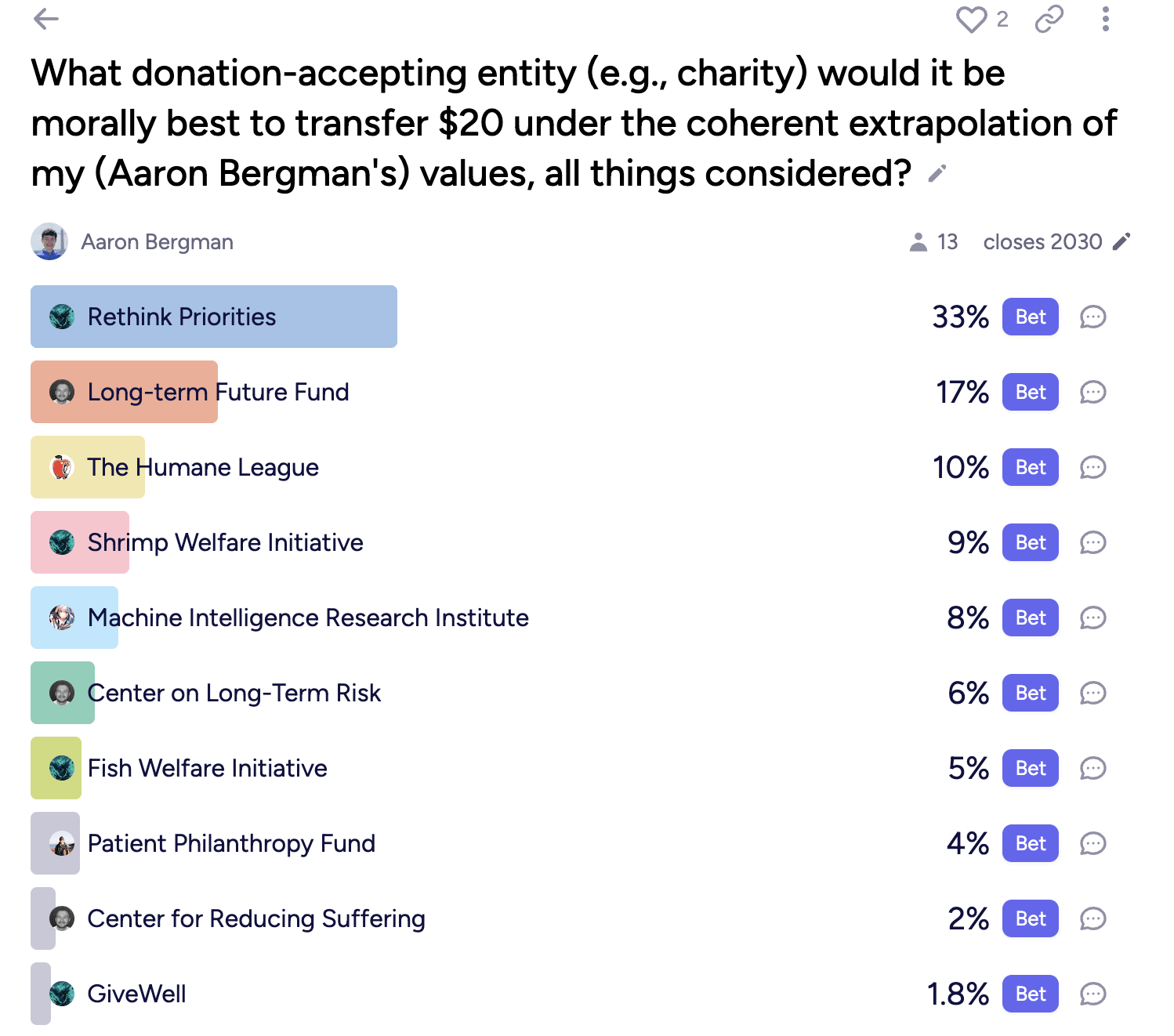
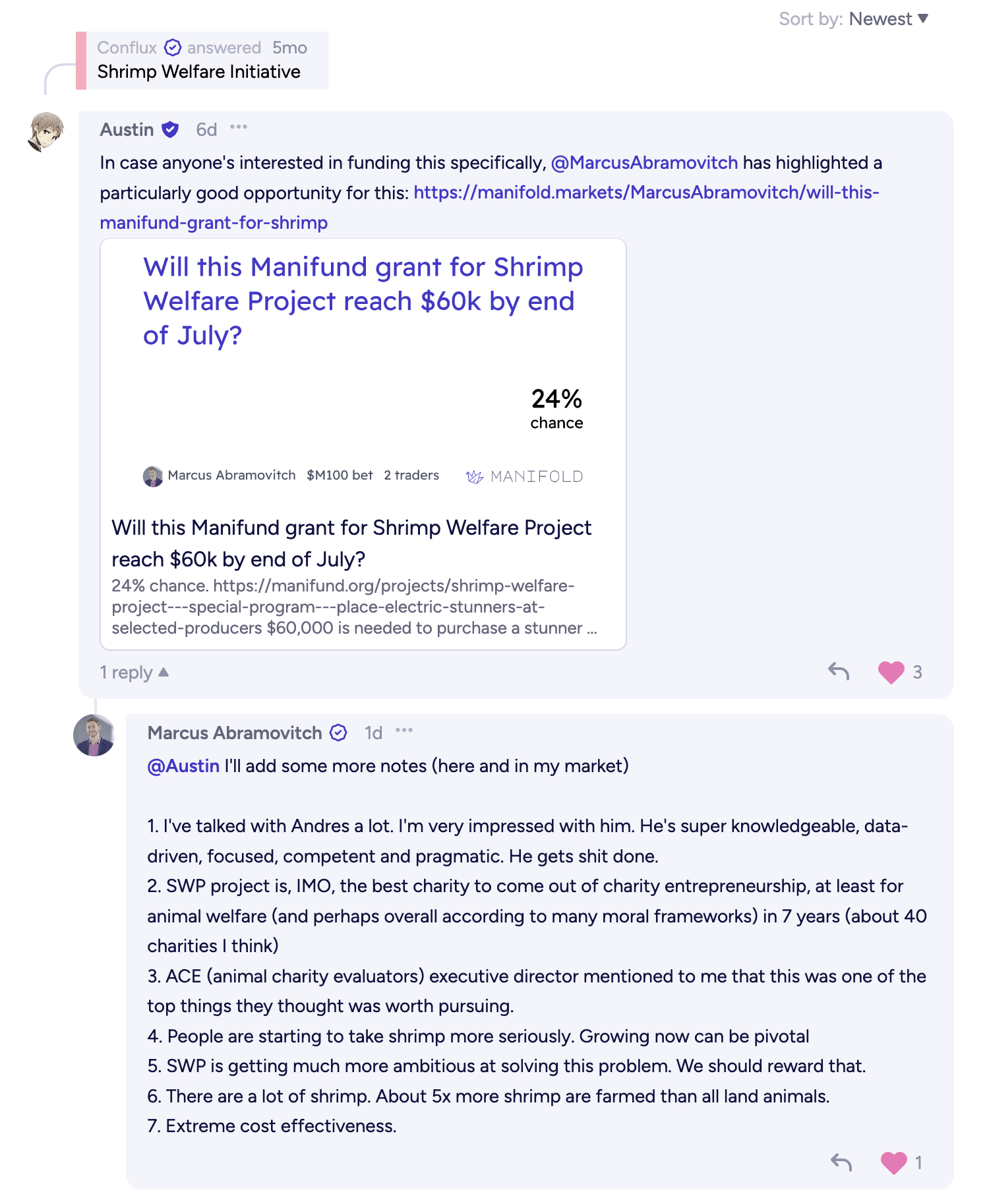





Re the grand “does individual giving/etg still matter post Anthropic IPO” question:
I think it pushes towards individuals acting more like grantmakers themselves. Anthropic billionaires don’t know about your Twitter follower who could do something great with $1k and they aren’t gonna have the capacity to find out, but you do!
There are just a lot of freedoms one has as an individual donor who isn’t a public figure:
You…
Also: the same dynamic between Anthropic ~billionaires and folks reading this as a group also holds within that latter group: there are diminishing returns even at low margins so Jane Street should look a little less good than it used to (still pretty good tbc) and “having a couple thousand bucks around and being on the lookout for one-off opportunities” should seem a bit better than it used to.
Agree with the spirit of this, but I'd flag that I think it's very important to be mindful of reputational/downside risks for the EA movement. In my view, with more money (realized and prospective), the value of community integrity becomes even higher.
An example of post-IPO retail philanthropy I'm excited about is giving a friend $5k to take time off and apply to high-impact jobs. As Aaron writes, individuals know about opportunities that large funders don't!
An example of post-IPO retail philanthropy I worry about is paying for an antagonistic media campaign against [X factory farm owner or public figure], which institutional funders could have chosen to fund but decided against due to reputational risk. If the funding is traced back to you, the movement's reputation could be damaged by association. Even if it isn't, new large funders may be dissuaded from getting involved if they see antagonistic or risky actions being funded in areas related to EA.