The Happier Lives Institute (HLI) is a non-profit research institute that seeks to find the best ways to improve global wellbeing, then share what we find. Established in 2019, we have pioneered the use of subjective wellbeing measures (aka ‘taking happiness seriously’) to work out how to do the most good.
HLI is currently funding constrained and needs to raise a minimum of 205,000 USD to cover operating costs for the next 12 months. We think we could usefully absorb as much as 1,020,000 USD, which would allow us to expand the team, substantially increase our output, and provide a runway of 18 months.
This post is written for donors who might want to support HLI’s work to:
- identify and promote the most cost-effective marginal funding opportunities at improving human happiness.
- support a broader paradigm shift in philanthropy, public policy, and wider society, to put people’s wellbeing, not just their wealth, at the heart of decision-making.
- improve the rigour of analysis in effective altruism and global priorities research more broadly.
A summary of our progress so far:
- Our starting mission was to advocate for taking happiness seriously and see if that changed the priorities for effective altruists. We’re the first organisation to look for the most cost-effective ways to do good, as measured in WELLBYs (Wellbeing-adjusted life years)[1]. We didn’t invent the WELLBY (it’s also used by others e.g. the UK Treasury) but we are the first to apply it to comparing which organisations and interventions do the most good.
- Our focus on subjective wellbeing (SWB) was initially treated with a (understandable!) dose of scepticism. Since then, many of the major actors in effective altruism’s global health and wellbeing space seem to have come around to it (e.g., see these comments by GiveWell, Founders Pledge, Charity Entrepreneurship, GWWC). [Paragraph above edited 10/07/2023 to replace 'all' with 'many' and remove a name (James Snowden) from the list. See below]
- We’ve assessed several top-regarded interventions for the first time in terms of WELLBYs: cash transfers, deworming, psychotherapy, and anti-malaria bednets. We found treating depression is several times more cost-effective than either cash transfers or deworming. We see this as important in itself as well as a proof of concept: taking happiness seriously can reveal new priorities. We've had some pushback on our results, which was extremely valuable. GiveWell’s own analysis concludes treating depression is 2x as good as cash transfers (see here, which includes our response to GiveWell).
- We strive to be maximally philosophically and empirically rigorous. For instance, our meta-analysis of cash transfers has since been published in a top academic journal. We’ve shown how important philosophy is for comparing life-improving against life-extending interventions. We’ve won prizes: our report re-analysing deworming led GiveWell to start their “Change Our Mind” competition. Open Philanthropy awarded us money in their Cause Exporation Prize.
- Our work has an enormous global scope for doing good by influencing philanthropists and public policy-makers to both (1) redirect resources to the top interventions we find and (2) improve prioritisation in general by nudging decision-makers to take a wellbeing approach (leading to resources being spent better, even if not ideally).
- Regarding (1), we estimate that just over the period of Giving Season 2022, we counterfactually moved around $250,000 to our top charity, StrongMinds; this was our first campaign to directly recommend charities to donors[2].
- Regarding (2), the Mental Health Funding Circle started in late 2022 and has now disbursed $1m; we think we had substantial counterfactual impact in causing them to exist. In a recent 80k podcast, GiveWell mention our work has influenced their thinking (GiveWell, by their count, influences $500m a year)[3].
- We’ve published over 25 reports or articles. See our publications page.
- We’ve achieved all this with a small team. Presently, we’re just five (3.5 FTE researchers). We believe we really 'punch above our weight', doing high impact research at a low cost.
- However, we are just getting started. It takes a while to pioneer new research, find new priorities, and bring people around to the ideas. We’ve had some impact already, but really we see that traction as evidence we’re on track to have a substantial impact in the future.
What’s next?
Our vision is a world where everyone lives their happiest life. To get there, we need to work out (a) what the priorities are and (b) have decision-makers in philanthropy and policy-making (and elsewhere) take action. To achieve this, the key pieces are:-
- conducting research to identify different priorities compared to the status quo approaches (both to do good now and make the case)
- developing the WELLBY methodology, which includes ethical issues such as moral uncertainty and comparing quality to quantity of life
- promoting and educating decision-makers on WELLBY monitoring and evaluation
- building the field of academic researchers taking a wellbeing approach, including collecting data on interventions.
Our organisational strategy is built around making progress towards these goals. We've released, today, a new Research Agenda for 2023-4 which covers much of the below in more depth.
In the next six months, we have two priorities:
Build the capacity and professionalism of the team:
- We’re currently recruiting a communications manager. We’re good at producing research, but less good at effectively telling people about it. The comms manager will be crucial to lead the charge for Giving Season this year.
- We’re about to open applications for a Co-Director. They’ll work with me and focus on development and management; these aren’t my comparative advantage and it’ll free me up to do more research and targeted outreach.
- We’re likely to run an open round for board members too.
And, to do more high-impact research, specifically:
- Finding two new top recommended charities. Ideally, at least one will not be in mental health.
- To do this, we’re currently conducting shallow research of several causes (e.g., non-mood related mental health issues, child development effects, fistula repair surgery, and basic housing improvements) with the aim of identifying promising interventions.
- Alongside that, we’re working on wider research agenda, including: an empirical survey to better understand how much we can trust happiness surveys; summarising what we’ve learnt about WELLBY cost-effectiveness so we can share it with others; revise working papers on the nature and measurement of wellbeing; a book review Will MacAskill’s ‘What We Owe The Future’.
The plan for 2024 is to continue developing our work by building the organisation, doing more good research, and then telling people about it. In particular:
- Investigate 4 or 5 more cause areas, with the aim of adding a further three top charities by the end of 2024.
- Develop the WELLBY methodology, exploring, for instance, the social desirability bias in SWB scales
- Explore wider global priorities/philosophical issues, e.g. on the badness of death and longtermism.
- For a wider look at these plans, see our Research Agenda for 2023-4, which we’ve just released.
- If funding permits, we want to grow the team and add three researchers (so we can go faster) and a policy expert (so we can better advocate for WELLBY priorites with governments)
- (maybe) scale up providing technical assistance to NGOs and researchers on how to assess impact in terms of WELLBYs (we do a tiny amount of this now)
- (maybe) launch a ‘Global Wellbeing Fund’ for donors to give to.
- (maybe) explore moving HLI inside a top university.
We need you!
We think we’ve shown we can do excellent, important research and cause outsized impact on a limited budget. We want to thank those who’ve supported us so far. However, our financial position is concerning: we have about 6 months’ reserves and need to raise a minimum of 205,000 USD to cover our operational costs for the next 12 months. This is even though our staff earn about ½ what they would in comparable roles in other organisations. At most, we think we could usefully absorb 1,020,000 USD to cover team expansion to 11 full time employees over the next 18 months.
We hope the problem is that donors believe the “everything good is fully funded” narrative and don’t know that we need them. However, we’re not fully-funded and we do need you! We don’t get funding from the two big institutional donors, Open Philanthropy and the EA Infrastructure fund (the former doesn’t fund research in global health and wellbeing; we didn’t get feedback from the latter). So, we won’t survive, let alone grow, unless new donors come forward and support us now and into the future.
Whether or not you’re interested in supporting us directly, we would like donors to consider funding our recommended charities; we aim to add two more to our list by the end of 2023. We expect these will be able to absorb millions or tens of dollars, and this number will expand as we do more research.
We think that helping us ‘keep the lights on’ for the next 12-24 months represents an unusually large counterfactual opportunity for donors as we expect our funding position to improve. We’ll explore diversifying our funding sources by:
- Seeking support from the wider world of philanthropy (where wellbeing and mental health are increasing popular topics)
- Acquiring conventional academic funding (we can’t access this yet as we’re not UKRI registered, but we’re working on this; we are also in discussions about folding HLI into a university)
- Providing technical consultancy on wellbeing-based monitoring and evaluation of projects (we’re having initial conversations about this too).
To close, we want to emphasise that taking happiness seriously represents a huge opportunity to find better ways to help people and reallocate enormous resources to those things, both in philanthropy and in public-policymaking. We’re the only organisation we know of focusing on finding the best ways to measure and improve the quality of lives. We sit between academia, effective altruism and policy-making, making us well-placed to carry this forward; if we don’t, we don’t know who else will.
If you’re considering funding us, I’d love to speak with you. Please reach out to me at michael@happierlivesinstitute.org and we’ll find time to chat. If you’re in a hurry, you can donate directly here.
Appendix 1: HLI budget
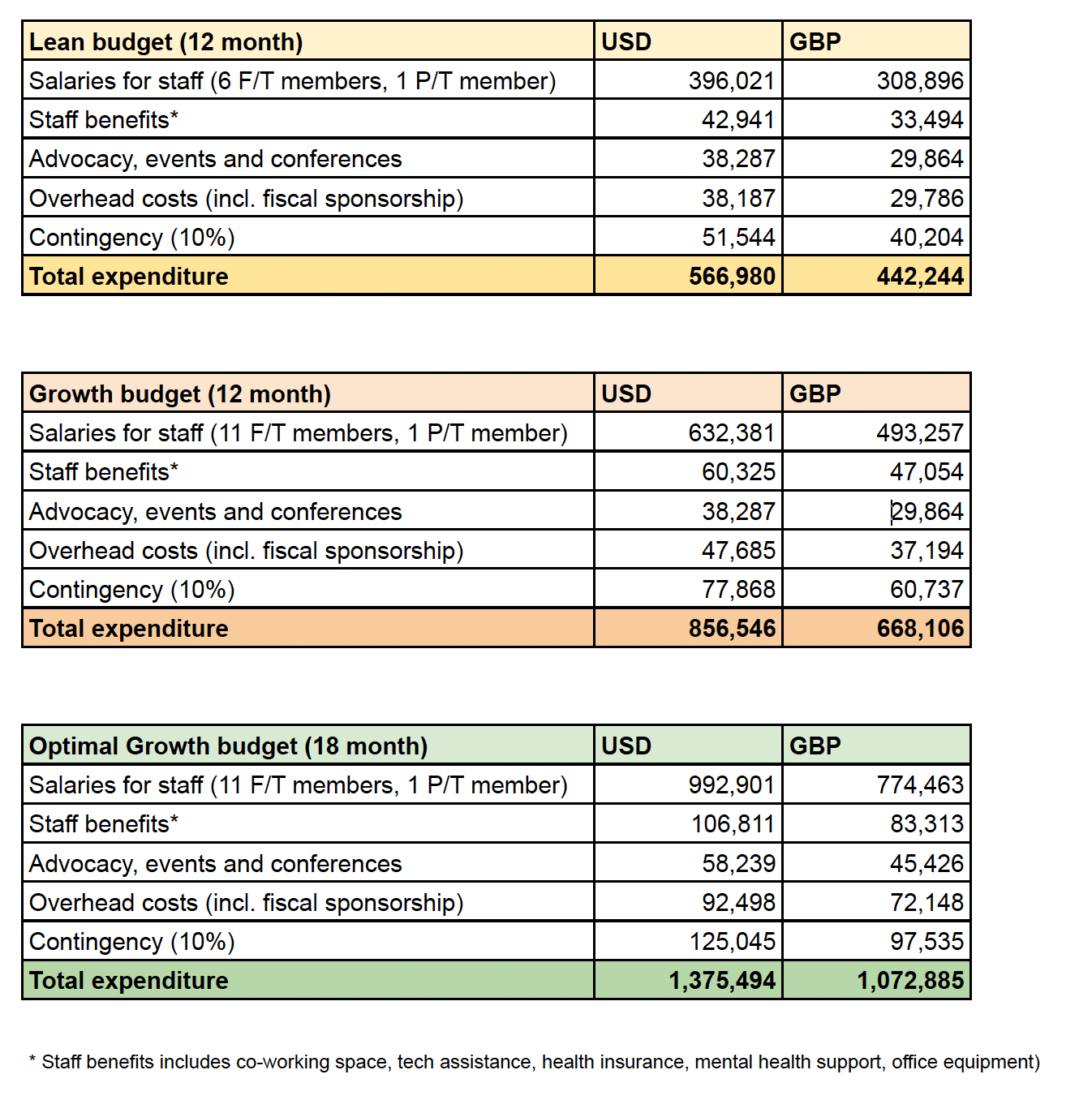
- ^
One WELLBY is equivalent to a 1-point increase on a 0-10 life satisfaction scale for one year
- ^
The total across two matching campaigns at the Double-Up Drive, the Optimus Foundation as well as donations via three effective giving organisations (Giving What We Can, RC Forward, and Effectiv Spenden) was $447k. Note not all this data is public and some public data is out of date. The sum donated be larger as donations may have come from other sources. We encourage readers to take this with a pinch of salt and how to do more accurate tracking in future.
- ^
Some quotes about HLI’s work from the 80k podcast:
[Elie Hassenfeld] ““I think the pro of subjective wellbeing measures is that it’s one more angle to use to look at the effectiveness of a programme. It seems to me it’s an important one, and I would like us to take it into consideration[Elie] “…I think one of the things that HLI has done effectively is just ensure that this [using WELLBYs and how to make tradeoffs between saving and improving lives] is on people’s minds. I mean, without a doubt their work has caused us to engage with it more than we otherwise might have. […] it’s clearly an important area that we want to learn more about, and I think could eventually be more supportive of in the future.”
[Elie] “Yeah, they went extremely deep on our deworming cost-effectiveness analysis and pointed out an issue that we had glossed over, where the effect of the deworming treatment degrades over time. […] we were really grateful for that critique, and I thought it catalysed us to launch this Change Our Mind Contest. ”


I think your last sentence is critical -- coming up with ways to improve epistemic practices and legibility is a lot easier where there are no budget constraints! It's hard for me to assess cost vs. benefit for suggestions, so the suggestions below should be taken with that in mind.
For any of HLI's donors who currently have it on epistemic probation: Getting out of epistemic probation generally requires additional marginal resources. Thus, it generally isn't a good idea to reduce funding based on probationary status. That would make about as much sense as "punishing" a student on academic probation by taking away their access to tutoring services they need to improve.
The suggestions below are based on the theory that the main source of probationary status -- at least for individuals who would be willing to lift that status in the future -- is the confluence of the overstated 2022 communications and some issues with the SM CEA. They lean a bit toward "cleaner and more calibrated public communication" because I'm not a statistican, but also because I personally value that in assessing the epistemics of an org that makes charity recommendations to the general public. I also lean in that direction because I worry that setting too many substantive expectations for future reports will unduly suppress the public release of outputs.
I am concerned that HLI is at risk of second-impact syndrome and would not, as a practical matter, survive a set of similar mistakes on the re-analysis of SM or on its next few major recommendations. For that reason, I have not refrained from offering suggestions based on my prediction that they could slow down HLI's plans to some extent, or incur moderately significant resource costs.
All of these come from someone who wants HLI to succeed. I think we need to move future conversations about HLI in a "where do we go from here" direction rather than spending a lot of time and angst re-litigating the significance and import of previously-disclosed mistakes.[1] I'm sure this thread has already consumed a lot of HLI's limited time; I certainly do not expect a reply.
A: Messaging Calibration
For each research report, you could score and communicate the depth/thoroughness of the research report, the degree of uncertainty, and the quality of the available evidence. For the former, the scale could be something like 0 = Don't spend more than $1 of play money on this; 10 = We have zero hesitation with someone committing > $100MM on this without further checking. For the materials you put out (website materials, Forum posts, reports), the material should be consistent with your scores. Even better, you could ask a few outside people to read draft materials (without knowing the scores) and tell you what scores the material implies to them.
I think it's perfectly OK for an org to put out material that has some scores of 4 or 5 due to resource constraints, deprioritization due to limited room for funding or unpromising results, etc. Given its resources, its scope of work, the areas it is researching, and the state of other work in those areas, I don't think HLI can realistically aim for scores of 9 or a 10 across the board in the near future. But the messaging needs to match the scores. In fact, I might aim for messaging that is slightly below the scores. I say that because the 2022 Giving Season materials suggest HLI's messaging "scale" may be off, and adding a tare weight could serve as an interim fix.
I think HLI is in a challenging spot given GiveWell's influence and resources. I further think that most orgs in HLI's position would feel a need to "compete" with GiveWell, and that some of the 2022 messaging suggests that may be the case. I think that pressure would put most orgs at risk of projecting more confidence and certainty than the data allow, and so it's particularly important that orgs facing that kind of pressure carefully calibrate their messaging.
B: Identification of Major Hinges
For each recommendation, there could be a page on major hinges, assumptions, methodological critical points, and the like. It should be legible to well-educated generalists, and there should be a link to this page on the main recommendation page, in Forum posts, etc. For bonus points, you could code an app that allows the user to see how the results change based on various hinges. For example, for the SM recommendation, I would have liked to see things like the material below. (Note that some examples are based on posted criticisms of the SM CEA, but the details are not meant to be taken literally.)
Presumably you would already know where the hinges and critical values were, so listing them in lay-readable form shouldn't require too much effort. But doing so protects against people getting the impression that the overall conclusion isn't appropriately caveated, that you didn't make it clear enough how much role study A or factor B played, etc. Of course, this section could list positive factors too (e.g., we used the Rohan correction even though it was a close call and the Gondor correction would have boosted impact 11%).
C: Red-Teaming and Technical Appendix
In my field (law), we're taught that you do not want the court to learn about unfavorable facts or law only from your opponents' brief. Displaying up front that you saw an issue rules out two possible unfavorable inferences a reader could draw: that you didn't see the issue, or that you saw the issue and hoped neither the court nor the other side's lawyer would notice. Likewise, more explicit recognition of certain statistical information in a separate document may be appropriate, especially in an epistemic-probation situation. I do recognize that this could incur some costs.
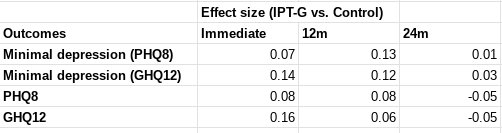
I'm not a statistican by any means, but to the extent that you would might expect an opposition research team to express significant concern about a finding -- such as the pre-registered reports showing much lower effect sizes than the unregistered ones -- I think it would be helpful to acknowledge and respond to that concern upfront. I recognize that potentially calls for a degree of mind-reading, and that this approach may not work if the critics dig for more arcane stuff. But even if the critics find something that the red team didn't, the disclosure of some issues in a technical appendix still legibly communicates a commitment to self-critical analysis.
D: Correction Listing and Policy
For each recommendation, there could be a page for issues, corrections, subsequent developments, and the like. It should be legible to well-educated generalists, and there should be a link to this page on the main recommendation page, in Forum posts, etc. There could also be a policy that explains what sorts of issues will trigger an entry on that page and the timeframe in which information will be added, as well as trigger criteria for conspiciously marking the recommendation/report as under review, withdrawing it pending further review, and so on. The policy should be in effect for as long as there is a recommendation based on the report, or for a minimum of G years (unless the report and any recommendation are formally withdrawn).
The policy would need to include a definition of materiality and clearly specified claims. Claims could be binary (SM cost-effectiveness > GiveDirectly) or quantitative (SM cost-effectiveness = 7.5X GiveDirectly). A change could be defined as material if it changed the probability of a binary claim more than Y% or changed a quantitative claim more than Z%. It could provide that any new issue will be added to the issues page within A days of discovery unless it is determined that the issue is not reasonably likely (at least Q% chance) to be material. It could provide that there will be a determination of materiality (and updated credences or estimates as necessary) within B days. The policy could describe which website materials, etc. would need to be corrected based on the degree of materiality.
If for some reason the time limit for full adjudication cannot be met, then all references to that claim on HLI's website, the Forum, etc. need to be clearly marked as [UNDER REVIEW] or pulled so that the reader won't be potentially mislead by the material. In addition, all materials need to be marked [UNDER REVIEW] if at any time there is a substantial possibility (at least J%) that the claim will ultimately be withdrawn.
This idea is ultimately intended to be about calibration and clear communication. If an org commits, in advance, to certain clear claims and a materiality definition, then the reader can compare those commitments against the organization's public-facing statements and read them accordingly. For instance, if the headline number is 8X cash, but the org will only commit to following correction procedures if that dips below 4X cash, that tells the reader something valuable.
This is loosely akin to a manufacturer's warranty, which can be as important as a measure of the manufacturer's confidence in the product as anything else. I recognize that larger orgs will find it easier to make corrections in a timely manner, and the community needs to give HLI more grace (both in terms of timelines and probably materiality thresholds) than it would give a larger organization.
Likewise, a policy stated in advance provides a better way to measure whether the organization is dealing appropriately with issues versus digging in its heels. It can commit the organization to make concrete adjustments to its claims or to affirm a position that any would-be changes do not meet pre-determined criteria. Hopefully, this would avoid -- or at least focus -- any disputes about whether the organization is inappropriately maintaining its position. Planting the goalposts in advance also cuts off any disputes about whether the org is moving the goalposts in response to criticism.
[two more speculative paragraphs here!] Finally, the policy could provide for an appeal of certain statistical/methodological issues to a independent non-EA expert panel by a challenger who found the HLI's application of its correction policy incorrect. Costs would be determined by the panel based on its ruling. HLI would update its materials with any adverse finding, and prominently display any finding by the panel that it had made an unreasonable application under its policy (which is not the same as the panel agreeing with the challenger).
This might be easier to financially justify than a bounty program because it only creates exposure if there is a material error, HLI swings and misses on the opportunity to correct it, and the remaining error is clear enough for a challenger to risk money. I am generally skeptical of "put your own money at risk" elements in EA culture for various reasons, but I don't think the current means of dispute resolution are working well for either HLI or the community.
This is not meant to discourage discussions of any new issues with the recommendation or underlying analysis that may be found.
I think this is the fairest way to report this -- because the studies were outliers, they may have been hingier than their level of credence.