Did you know that you're more likely to die from a catastrophe than in a car crash? The odds that a typical US resident will die from a catastrophic event—for example, nuclear war, bioterrorism, or out-of-control artificial intelligence—have been estimated at 1 in 6. That's fifteen times more likely than a fatal car crash and thirty-one times more likely than being murdered. In What's the Worst That Could Happen?, Andrew Leigh looks at catastrophic risks and how to mitigate them, arguing provocatively that the rise of populist politics makes catastrophe more likely.
Technical note: I think we need to be careful to note the difference in meaning between extinction and existential catastrophe. When Joseph Carlsmith talks about existential catastrophe, he doesn't necessarily mean all humans dying; in this report, he's mainly concerned about the disempowerment of humanity. Following Toby Ord in The Precipice, Carlsmith defines an existential catastrophe as "an event that drastically reduces the value of the trajectories along which human civilization could realistically develop". It's not straightforward to translate his estimates of existential risk to estimates of extinction risk.
Of course, you don't need to rely on Joseph Carlsmith's report to believe that there's a ≥7.9% chance of human extinction conditioning on AGI.
I face enormous challenges convincing people of this. Many people don't see, for example, widespread AI-empowered human rights infringements as an 'existential catastrophe' because it doesn't directly kill people, and as a result it falls between the cracks of AI safety definitions - despite being a far more plausable threat than AGI considering it's already happening. Severe curtailments to humanity's potential still firmly count as an existential risk in my opinion.
Thanks for calling this out, whoever you are. This is another reason why, for the last ~5 years or so, I've been pushing for the terminology "AI x-risk" and "AI x-safety" to replace "(long-term) AI risk" and "(long-term) AI safety". For audiences not familiar with the "x" or "existential" terminology, one can say "large scale risk" to point the large stakes, rather than always saying "long term".
(Also, the fact that I don't know who you are is actually fairly heartening :)
I find this post really uncomfortable. I thought I'd mention that, even though I'm having a hard time putting my finger on why. I'll give a few guesses as a reply to this comment so they can be discussed separately.
I personally feel queasy about telling people that they might die in some detail as an epistemic move, even when it's true. I'm worried that this will move people to be less playful and imaginative in their thinking, and make worse intellectual, project, or career decisions overall, compared to more abstract/less concrete considerations of "how can I, a comfortable and privileged person with most of my needs already met, do the most good."
(I'm not saying my considerations here are overwhelming, or even that well-thought-out).
I am inclined to agree, but to take the other side for a minute, if I imagine being very confident it was true, I feel like there would be important truths that I would only realize if I communicated that knowledge deep into my System 1.
I'm also confused about this. One framing I sometimes have is
If I were a general in a war, or a scientist on the Manhattan project, will I act similarly?
And my guess is that I won't act the same way. Like I'd care less about work-life balance, be more okay with life not going as well, be more committed with x-risk stuff always being the top of my mind, etc. And framed that way, I feel more attuned to the change of S1 "getting it" being positive.
I'm worried that this will move people to be less playful and imaginative in their thinking, and make worse intellectual, project, or career decisions overall, compared to more abstract/less concrete considerations of "how can I, a comfortable and privileged person with most of my needs already met, do the most good."
Interesting, can you say more? I have the opposite intuition, though here this stems from the specific failure mode of considering AI Safety as weird, speculative, abstract, and only affecting the long-term future - I think this puts it at a significant disadvantage compared to more visceral and immediate forms of doing good, and that this kind of post can help partially counter that bias.
Hmm I want to say that I'm not at all certain what my all-things-considered position on this is.
But I think there are several potential cruxes that I'm framing the question around:
In general, is it good for "the project of doing good," or AI safety in particular, for people to viscerallyfeel (rather than just intellectually manipulate) the problems?
Is the feeling that you personally will die (or otherwise you have extremely direct incentives for the outcome) net beneficial or negative for thinking or action around AI safety?
What are the outreach/epistemics benefits and costs of thinking about AI killing everyone on a visceral level?
I have a bunch of thoughts on each of those, but they're kinda jumbled and not very coherent at the moment.
One possible related framing is "what types of people/thinking styles/archetypes does the EA or AI safety community most need*?" Do we need:
Soldiers?
Rough definition: People who're capable and willing to "do what needs to be done." Can be pointed along a well-defined goal and execute well according to it.
In this world, most of the problems are well-known. We may not be strong enough enough to solve the problems, but we know what the problems are. It just takes grit and hardened determination and occasionally local knowledge to solve the problems well.
What I like about this definition: Emphasizes grit. Emphasizes that often it just requires people willing to do the important grunt work, and sacrifice prestige games to do the most important thing (control-F for "enormous amounts of shit")
Potential failure modes: Intellectual stagnation. "Soldier mindset" in the bad sense of the term.
Philosophers?
Rough definition: Thinkers willing to play with and toy around with lots of possibilities. Are often bad at keeping their "eye on the ball," and perhaps general judgement, but good at spontaneous and creative intellectual jumps.
In this world, we may have dire problems, but the most important ones are poorly understood. We have a lot of uncertainty over what the problems are even there, never mind how to solve them.
What I like about this definition: Emphasizes the uncertain nature of the problems, and the need for creativity in thought to fix the issues.
Potential failure modes: Focusing on interesting problems over important problems. Too much abstraction or "meta."
Rough definition: Thinkers/strategists willing to consider a large range of abstractions in the service of a (probably) just goal.
In this world, we have moral problems in the world, and we have a responsibility to fix it. This can't entirely be solved on pure grit, and requires careful judgements of risk, morale, logistics, ethics, etc. But still there's clear goals in mind, and "eye on the ball" is really important to achieving such goals. There's also a lot of responsibilities (if you fail, your people die. Worse, your side might lose the war and fascists/communists/whatever might take over).
What I like about this definition: Emphasizes a balance between thoughtfulness and determination.
Potential failure modes: Fighting the "wrong" war (most wars are probably bad). Prematurely abdicating responsibility for higher-level questions in favor of what's needed to win.
Something else?
This is my current guess of what we need. "Generals" is an appealing aesthetic, but I think the problems aren't well-defined enough, and our understanding of how to approach them too ill-formed, that thinking of us as generals in a moral war is too premature.
In the above archetypes, I feel good about "visceralness" for soldiers and maybe generals, but not for philosophers. I think I feel bad about "contemplating your own death" for all three, but especially philosophers and generals (A general who obsesses over their own death probably will make more mistakes because they aren't trying as hard to win).
Perhaps I'm wrong. Other general-like archetypes I've considered is "scientists on the Manhattan Project," and I feel warmer about Manhattan Project scientists having a visceral sense of their own death than for generals. Perhaps I'd be interested in reading about actual scientists trying to solve problems that have a high probability of affecting them one day (e.g. aging, cancer and heart disease researchers). Do they find the thought that their failures may be causally linked to their own death motivating or just depressing?
One reason I might be finding this post uncomfortable is that I'm pretty concerned about the mental health of many young EAs, and frankly for some people I met I'm more worried about the chance of them dying from suicide or risky activities over the next decade than from x-risks. Unfortunately I think there is also a link between people who are very focused on death by x-risk and poor mental health. This is an intuition, nothing more.
I share this concern, and this was my biggest hesitation to making this post. I'm open to the argument that this post was pretty net bad because of that.
If you're finding things like existential dread concerning, I'll flag that the numbers in this post are actually fairly low in the grand scheme of total risks to you over your life - 3.7% just isn't that high. Dying young just isn't that likely.
One reason I might be finding this post uncomfortable is the chart it's centered around.
The medical information is based on real people who have died recently. It's a forecast based on counting. We can have a lot of confidence in those numbers.
In contrast, the AI numbers are trying to predict something that's never happened before. It's worth trying to predict, but the numbers are very different, and we can't have much confidence in them especially for one particular year.
It feels kind of misleading to try to put these two very different kinds of numbers side by side as if they're directly comparable.
I fairly strongly disagree with this take on two counts:
The life expectancy numbers are not highly robust. They're naively extrapolating out the current rate of death in the UK to the future. This is a pretty dodgy methodology! I'm assuming that medical technology won't expand, that AI won't accelerate biotech research, that longevity research doesn't go anywhere, that we don't have disasters like a much worse pandemic or nuclear war, that there won't be new major public health hazards that disproportionately affect young people, that climate change won't substantially affect life expectancy in the rich world, that there won't be major enough wars to affect life expectancy in the UK, etc. The one thing that we know won't happen in the future is the status quo.
I agree that it's less dodgy than the AI numbers, but it's still on a continuum, rather than some ontological difference between legit numbers and non-legit numbers.
Leaving that aside, I think it's extremely reasonable to compare high confidence and low confidence numbers so long as they're trying to measure the same thing. The key thing is that low confidence numbers aren't low confidence in any particular direction (if they were, we'd change to a different estimate). Maybe the AI x-risk numbers are way higher, maybe they're way lower. They're definitely noisier, but the numbers mean fundamentally the same thing, and are directly comparable. And comparing numbers like this is part of the process of understanding the implications of your models of the future, even if they are fairly messy and uncertain models.
Of course, it's totally reasonable to disagree with the models used for these questions and think that eg they have major systematic biases towards exaggerating AI probabilities. That should just give you different numbers to put into this model.
As a concrete example, I'd like governments to be able to compare the risks of a nuclear war to their citizens lives, vs other more mundane risks, and to figure out cost-effectiveness accordingly. Nuclear wars have never happened in something remotely comparable to today's geopolitical climate, so any models here will be inherently uncertain and speculative, but it seems pretty important to be able to answer questions like this regardless.
I disagree because I think error bounds over probabilities are less principled than a lot of people assume, and they can add a bunch of false confidence.
Yes. Quantitive expressions of credal resilience is complicated, there isn't a widely-shared-upon formulation, and a lot of people falsely assume that error bounds on made-up probabilities are more "rigorous" or "objective" than the probabilities themselves.
The issue is that by putting together high-confidence (relatively) and low-confidence estimates in your calculation, your resulting numbers should be low-confidence. For example, if your error bounds for AI risk vary by an order of magnitude each way (which is frankly insanely small for something this speculative) then the error bounds in your relative risk estimate would give you a value between 0.6% and 87%. With an error range like this, I don't think the statement "my most likely reason to die young is AI x-risk" is justified.
Hmm. I agree that these numbers are low confidence. But for the purpose of acting and forming conclusions from this, I'm not sure what you think is a better approach (beyond saying that more resources should be put into becoming more confident, which I broadly agree with).
Do you think I can never make statements like "low confidence proposition X is more likely than high confidence proposition Y"? What would feel like a reasonable criteria for being able to say that kind of thing?
More generally, I'm not actually sure what you're trying to capture with error bounds - what does it actually mean to say that P(AI X-risk) is in [0.5%, 50%] rather than 5%? What is this a probability distribution over? I'm estimating a probability, not a quantity. I'd be open to the argument that the uncertainty comes from 'what might I think if I thought about this for much longer'.
I'll also note that the timeline numbers are a distribution over years, which is already implicitly including a bunch of uncertainty plus some probability over AI never. Though obviously it could include more. The figure for AI x-risk is a point estimate, which is much dodgier.
And I'll note again that the natural causes numbers are at best medium confidence, since they assume the status quo continues!
would give you a value between 0.6% and 87%
Nitpick: I think you mean 6%? (0.37/(0.37+5.3) = 0.06). Obviously this doesn't change your core point.
Do you think I can never make statements like "low confidence proposition X is more likely than high confidence proposition Y"? What would feel like a reasonable criteria for being able to say that kind of thing?
Honestly, yeah, I think it is a weird statement to definitively state that X wildly speculative thing is more likely than Y well known and studied thing (or to put it differently, when the error bounds of X are orders of magnitude different from the error bounds in Y). It might help if you provided a counterexample here? I think my objections here might be partially on the semantics, saying "X is more likely than Y" seems like a smuggling of certainty into a very uncertain proposition.
what does it actually mean to say that P(AI X-risk) is in [0.5%, 50%] rather than 5%
I think it elucidates more accurately the state of knowledge about the situation, which is that you don't know much at all.
I don't disagree with the premise that agreeing on empirical beliefs about AI probably matters more for whether someone does AI safety work than philosophical beliefs. I've made that argument before!
My personal take is that the numbers used are too low, and this matches my sense of the median AI Safety researchers opinion. My personal rough guess would be 25% x-risk conditional on making AGI, and median AGI by 2040, which sharply increase the probability of death from AI to well above natural causes.
I agree that your risk of dying from misaligned AI in an extinction event in the next 30 years is much more than 3.7%. Actually, Carlsmith would too -- he more than doubled his credence in AI existential catastrophe by 2070 since sharing the report (see, e.g., the "author's note" at the end of the arxiv abstract).
Current AI projects will easily accelerate present trends toward a far higher likelihood of existential catastrophic events. Risks are multiplied by the many uncoordinated global AI projects and their various experimental applications, particularly genetic engineering in less fastidiously scientific jurisdictions; but also the many social, political, and military applications of misaligned AI. AI safety work would be well-intentioned but irrelevant as these genies won't be put back into every AI 'safety bottle'. Optimistically, as we have survived our existential risks for quite some time, we may yet find a means to survive the Great Filter of Civilizations challenge presented by Fermi's Paradox.
Thank you for writing this. I've been repeating this point to many people and now I can point them to this post.
For context, for college-aged people in the US, the two most likely causes of death in a given year are suicide and vehicle accidents, both at around 1 in 6000. Estimates of global nuclear war in a given year are comparable to both of these. Given a AGI timeline of 50% by 2045, it's quite hard to distribute that 50% over ~20 years and assign much less than 1 in 6000 to the next 365 days. Meaning that even right now, in 2022, existential risks are high up on the list of most probable causes of death for college aged-people. (assuming P(death|AGI) is >0.1 in the next few years)
One project I've been thinking about is making (or having someone else make) a medical infographic that takes existential risks seriously, and ranks them accurately as some of the highest probability causes of death (per year) for college-aged people. I'm worried about this seeming too preachy/weird to people who don't buy the estimates though.
One project I've been thinking about is making (or having someone else make) a medical infographic that takes existential risks seriously, and ranks them accurately as some of the highest probability causes of death (per year) for college-aged people. I'm worried about this seeming too preachy/weird to people who don't buy the estimates though.
I'd be excited to see this, though agree that it could come across as too weird, and wouldn't want to widely and publicly promote it.
If you do this, I recommend trying to use as reputable and objective a source as you can for the estimates.
The infographic could perhaps have a 'today' and a 'in 2050' version, with the bubbles representing the risks being very small for AI 'today' compared to eg suicide, or cancer or heart disease, but then becoming much bigger in the 2050 version, illustrating the trajectory. Perhaps the standard medical cause of death bubbles shrink by 2050 illustrating medical progress.
Yes, that's true for an individual. Sorry, I was more meaning the 'today' infographic would be for a person born in say 2002, and the 2050 one for someone born in eg 2030. Some confusion because I was replying about 'medical infographic for x-risks' generally rather than specifically your point about personal risk.
Mod note: I've enabled agree-disagree voting on this thread. This is still in the experimental phase, see the first time we did so here. Still very interested in feedback.
For experimentation purposes, I think the agree-disagree voting should probably be enabled right after the post is published. Otherwise you get noisy data: some of the upvotes/downvotes will just reflect the fact that the option wasn't enabled back when those votes were cast.
There are person-affecting views according to which future beings still matter substantially, e.g. wide or asymmetric ones. I don't personally find narrow symmetric person-affecting views very plausible, since they would mean causing someone to come to exist and have a life of pure torture and misery wouldn't be bad for that person (although later preventing their suffering after they exist would be good, if possible), and significantly discounting such harms just because the individual doesn't yet exist seems really wrong to me. So, it's hard to me to justify discounting all of the possible sources of (dis)value in the far future, except to the extent that predictably improving things in the far future is hard.
While promoting AI safety on the basis of wrong values may increase AI safety work, it may also increase the likelihood that AI will have wrong values (plausibly increasing the likelihood of quality risks), and shift the values in the EA community towards wrong values. It's very plausibly worth the risks, but these risks are worth considering.
While promoting AI safety on the basis of wrong values may increase AI safety work, it may also increase the likelihood that AI will have wrong values (plausibly increasing the likelihood of quality risks), and shift the values in the EA community towards wrong values. It's very plausibly worth the risks, but these risks are worth considering.
I'm personally pretty unconvinced of this. I conceive of AI Safety work as "solve the problem of making AGI that doesn't kill everyone" more so than I conceive of it as "figure out humanity's coherent extrapolated vision and load it into a sovereign that creates a utopia". To the degree that we do explicitly load a value system into an AGI (which I'm skeptical of), I think that the process of creating this value system will be hard and messy and involve many stakeholders, and that EA may have outsized influence but is unlikely to be the deciding voice.
Having outsized influence could be enough, when we're considering the (dis)value in the far future at stake, which is still much larger than from the deaths of everyone killed by AI. What ratio of probabilities between influencing values in a better direction vs preventing extinction would you assign? Is the ratio small enough to give less overall weight to the expected far future impact than the reduction in risk of everyone killed by AI?
(FWIW, I don't think it's strictly necessary to explicitly "load" a value system to influence the kinds of values an AI system might have.)
My brother was recently very freaked out when I asked him to pose a set of questions that he thinks an AI wouldn’t be able to answer, and GPT-3 gave excellent-sounding responses to his prompts.
Thanks for writing this--even though I've been familiar with AI x-risk for a while, it didn't really hit me on an emotional level that dying from misaligned AI would happen to me too, and not just "humanity" in the abstract. This post changed that.
Might eventually be useful to have one of these that accounts for biorisk too, although biorisk "timelines" aren't as straightforward as trying to estimate the date that humanity builds the first AGI.
You should also consider the impacts on nonhuman animals (farmed and wild), which could easily dominate, but may not have the same sign as the impacts on humans. Plus, animal welfare interventions may look more promising overall.
On the other hand, there's also a possibility that humans alive today will live extremely long lives, because of AI going well.
Thanks for the post, this is definitely a valuable framing.
But I'm a bit concerned that the post creates a misleading impression that the whole catastrophic/ speculative risk field is completely overwhelmed by AI x-risk.
Assuming you don't believe that other catastrophic risks are completely negligible compared to AI x-risk, I'd recommend adding a caveat that this is only comparing AI x-risk and existing/ non-speculative risks. If you do think AI x-risk overwhelms other catastrophic risks, you should probably mention that too.
I didn't vote on your comment on either scale, but FWIW my guess is that the disagreement is due to quite a few people having the view that AI x-risk does swamp everything else.
I suspected that, but it didn't seem very logical. AI might swamp x-risk, but seems unlikely to swamp our chances of dying young, especially if we use the model in the piece.
Although he says that he's more pessimistic on AI than his model suggests, in the model, his estimates are definitely within the bounds that other catastrophic risks would seriously change his estimates.
I did a rough estimate with nuclear war vs. natural risk (using his very useful spreadsheet, and loosely based on Rodriguez' estimates) (0.39% annual chance of US-Russia nuclear exchange, 50% chance of a Brit dying in it; I know some EAs have made much lower estimates, but this seems in line with the general consensus). In this model, nuclear risk comes out a bit higher than 'natural' over 30 years.
Even if you're particularly optimistic about other GCRs, if you add all the other potential catastrophic/ speculative risks together (pandemics, non-existential AI risk, nuclear, nano, other), I can't imagine them not shifting the model.
Huh, I appreciate you actually putting numbers on this! I was suprised at nuclear risk numbers being remotely competitive with natural causes (let alone significantly dominating over the next 20 years), and I take this as an at least mild downwards update on AI dominating all other risks (on a purely personal level). Probably I had incorrect cached thoughts from people exclusively discussing extinction risk rather than just catastrophic risks, but from a purely personal perspective this distinction matters much less.
I'd tell everyone because presumably it would mean people should strongly update their credence of human extinction in 10 years, e.g. from something like 0.5%-2% to 10%-50%, since the current probability that I die as part of an extinction event in exactly 10 years time (assuming I die then in some event) is approximately 10-50%.
We can quibble over the numbers but I think the point here is basically right, and if not right for AI then probably right for biorisk or some other risks. That point being even if you only look at probabilities in the next few years and only care about people alive today, then these issues appear to be the most salient policy areas. I've noted in a recent draft that the velocity of increase in risk (eg from some 0.0001% risk this year, to eg 10% per year in 50 years) results in issues with such probability trajectories being invisible to eg 2-year national risk assessments at present even though area under curve is greater in aggregate than every other risk. But in a sense potentially 'inevitable' (for the demonstration risk profiles I dreamed up) over a human lifetime. This then begs the question of how to monitor the trajectory (surely this is one role of national risk assessment, to invest in 'fire alarms', but this then requires these risks to be included in the assessment so the monitoring can be prioritized). Persuading policymakers is definitely going to be easier by leveraging decade long actuarial tables than having esoteric discussions about total utilitarianism.
Additionally, in the recent FLI 'World Building Contest' the winning entry from Mako Yass made quite a point of the fact that in the world he built the impetus for AI safety and global cooperation on this issue came from the development of very clear and very specific scenario development of how exactly AI could come to kill everyone. This is analogous to Carl Sagan/Turco's work on nuclear winter in the early 1980s , a specific picture changed minds. We need this for AI.
We can quibble over the numbers but I think the point here is basically right, and if not right for AI then probably right for biorisk or some other risks.
This can be taken further - if your main priority is people alive today (or yourself) - near term catastrophic risks that aren't x-risks become as important. So, for example, while it may be improbable for a pandemic to kill everyone, I think it's much more probable that one kills, say, at least 90% of people. On the other hand I'm not sure the increase in probability from AI killing everyone to AI killing at least 90% of people is that big.
Then again, AI can be misused much worse than other things. So maybe the chance that it doesn't kill me but still, for example, lets a totalitarian government enslave me, is pretty big?
Great post! Thanks for writing it! I'm not great at probability so just trying to understand the methodology.
The cumulative probability of death should always sum up to 100% and P(Death|AGI) + P(Death|OtherCauses) = 100% (100% here being 100% of P(Death) i.e. all causes of death should be accounted for in P(Death) as opposed to 100% being equal to P(Death) + P(Life) sorry for the ambiguous wording ), so to correct for this would you scale natural death down as P(Death|AGI) increases i.e P(Death|OtherCauses) = (100-P(Death|AGI)) * Unscaled P(Death|OtherCauses)?(This assumes P(Death|OtherCauses) already sums up to 100 but maybe it doesn't?).
I expect the standard deviation of P(Death|AGI) to be much higher than P(Death|Other) since AGI doesn't exist yet. What's the best way to take this into account?
If you happen to have data on this, could you add an additional series with other Global Catastrophic Risks taken into account? It would be nice to see how risk of death from AGI compares with other GCRs that are already possible. I'd expect intuitively the standard deviation of other GCRs that exist to be lower.
One of my pet peeves is people calling AI Safety a longtermist cause area. It is entirelyreasonable to consider AI Safety a high priority cause area without putting significant value on future generations, let alone buying things like total utilitarianism or the astronomical waste arguments. Given fairly mainstream (among EAs) models of AI timelines and AI X-Risk, it seems highly likely that we get AGI within my lifetime, and that this will be a catastrophic/existential risk.
I think this misconception is actively pretty costly - I observe people introducing x-risk concerns via longtermism (eg in an EA fellowship) getting caught up in arguments over whether future people matter, total utilitarianism, whether expected value is the correct decision theory when using tiny probabilities and large utilities, etc. And people need to waste time debunking questions like ‘Is AI Safety a Pascal’s Mugging’. And yet, even if you convince people of these questions around longtermism, you still need to convince them of arguments around AI x-risk to get them to work on it.
I further think this is damaging, because the label ‘longtermist’ makes AI Safety seem like an abstract, far off thing. Probably not relevant to the world today, but maybe important to future generations, at some point, in the long-term future. And I think this is wildly incorrect. AI x-risk is a directly personal thing that will plausibly affect me, my loved ones, my community, and most people alive today. I think this is a pretty important motivator to some people to work on this - this is not some philosophical thought experiment that you only decide to work on if you buy into some particular philosophical assumptions. Instead, it entirely follows from common sense morality, so long as you buy a few empirical beliefs
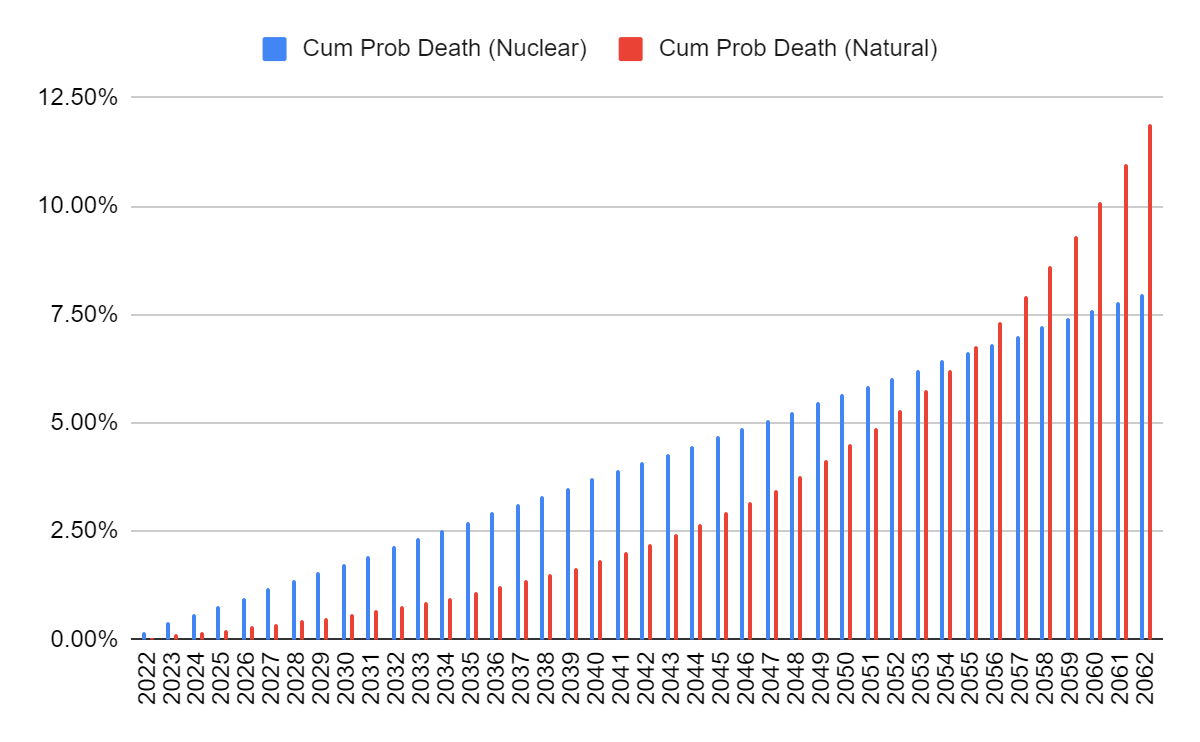
To put this into perspective, I’m going to compare my probability of dying young from AI X-Risk to my probability of dying from other causes (operationalised as ‘probability of dying in the next 30 years). My headline result is that, as a 23 year old man living in the UK, conditional on dying in the next 30 years, the probability that I die due to AI x-risk is 41% (3.7% from AI, 5.3% from natural causes)
Analysis
The main point I want to make in this post is that ‘AI x-risk is a pressing concern for people alive today’ is an obvious consequence of mainstream EA beliefs. Accordingly, rather than using my personal models of this, I try to combine Ajeya Cotra’s timelines report and Joseph Carlsmith’s report on AI X-risk (the best research I know of on AGI timelines and AGI x-risk respectively) to get the probability.
To get the probability of dying from any other cause, I use UK actuarial tables (giving the probability of death from all-cause mortality in each year of life). Ideally I’d have taken the probability of death by cause, but that’s much harder to find data for. Any one cause is <=25% of all-cause mortality, so showing that AI x-risk is roughly competitive with all-cause mortality shows that it’s by far the most likely cause of death.
Concretely, I take the distribution of the probability of AGI in each year from Ajeya’s spreadsheet (column B in sheet 2); the probability of AI x-risk from Joseph’s report (section 8) - this is 7.9% conditioning on AGI happening; and the probability of dying each year from natural causes starting from my current age (in the UK). To get my headline result of 41%, I take the ratio of the cumulative probabilities in 2052
Over the next 40 years, this gets the following chart:
The biggest caveat is that these numbers are plausibly biased pretty far upwards - I’ve seen basically no one outside of the EA community do a serious analysis on the question of AGI timelines or AGI x-risk, so the only people who do it are people already predisposed towards taking the issue seriously
Another big caveat is that the numbers are juiced up heavily by the fact that I am conditioning on dying young - if I extend the timelines long enough, then probability of dying naturally goes to 100% while probability of dying from AI X-risk goes to 7.9%
Is this enough to justify working on AI X-risk from a purely selfish perspective?
Probably not - in the same way that it’s not selfish to work on climate change. The effect any one person can have on the issue is tiny, even if the magnitude that it affects any individual is fairly high.
But this does help it appeal to my deontological/virtue ethics side - I am directly working on one of the world’s most pressing problems. This isn’t some abstract nerdy problem that’s an indulgence to work on over bednets, it’s a real danger to most people alive today, and something worthy and valuable to work on.
My personal take is that the numbers used are too low, and this matches my sense of the median AI Safety researchers opinion. My personal rough guess would be 25% x-risk conditional on making AGI, and median AGI by 2040, which sharply increase the probability of death from AI to well above natural causes.
If you take Yudkowsky-style numbers you end up with even more ridiculous results, though IMO that take is wildly overblown and overly pessimistic.
I’ve taken the 7.9% number from Joseph Carlsmith’s report, and assumed it’s the same, regardless of the year we get AGI. I expect it’s actually substantially higher with short timelines as we have less time to solve alignment.
I’ve used actuarial tables for probability of death at each age today. I expect probability of death to go down over time with medical advances. In particular, if we do get close to AGI, I expect the rate of biotech advances to significantly accelerate.
Does this mean that AI Safety is obviously the most important cause area even under a person-affecting view?
Eh, probably not. You also need to think through tractability, cost effectiveness, what fraction of people alive today are alive by each time, etc. But I do expect it goes through if you just put some value on the long-term future (eg 2-10x the value of today), rather than 10^30 times more value.
EDIT: This assumes all other forms of catastrophic risk (bio, nuclear, climate change, etc) are negligible. As pointed out by Jack_S, this is (depressingly) a pretty suspect assumption!
In particular, just because AI is the dominant existential risk does not mean that it's significantly higher in terms of a personal risk of death, and I was incorrectly anchored on existential risk estimates. It's notably more plausible to me that future GCBRs kill, eg, 10-50% of the world population than that they kill 100%, which is still pretty substantial in terms of a personal risk of death.
This doesn't really change the core point of 'AI Safety is important in a visceral, current-day sense', but does mean that this post shouldn't be taken as an argument for prioritising AI x-risk over over GCRs.
Meta: I wrote this under a pseudonym because I mildly prefer this kind of post to not come up when you Google my name - I don’t expect it to be hard to de-anonymise me, but would rather people didn’t!
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...


Andrew Leigh (Australian MP) has a 2021 book called What's the Worst That Could Happen?.
The book blurb starts as follows:
Book review EA Forum post here
This estimate is taken from Toby Ord's The Precipice, right? I remember 1/6 from there.
Yes