Comments
I wasn't sure if this article was the sort of thing the EA Forum audience is interested in, so let me know. I figured it's better to post and get feedback than to not post and never know.
Cross-posted to my blog.
Part of a series on quantitative models for cause selection.
One major reason that effective altruists disagree about which causes to support is that they have different opinions on how strong an evidence base an intervention should have. Previously, I wrote about how we can build a formal model to calculate expected value estimates for interventions. You start with a prior belief about how effective interventions tend to be, and then adjust your naive cost-effectiveness estimates based on the strength of the evidence behind them. If an intervention has stronger evidence behind it, you can be more confident that it’s better than your prior estimate.
For a model like this to be effective, we need to choose a good prior belief. We start with a prior probability distribution P where P(x) gives the probability that a randomly chosen intervention1 has utility x (for whatever metric of utility we’re using, e.g. lives saved). To determine the posterior expected value of an intervention, we combine this prior distribution with our evidence about how much good the distribution does.
For this to work, we need to know what the prior distribution looks like. In this essay, I attempt to determine what shape the prior distribution has and then estimate the values of its parameters.
The first question we have to ask is what probability distribution describes the space of interventions.
I see three reasonable ways to figure out the distribution:
Interventions seem to have the general property that there are a lot that have little to no effect per dollar spent, and few with large effects (as GiveWell claims here and here). In particular, the probability of finding an intervention with impact X utility diminishes as X increases.
The two most reasonable-seeming distributions with this property are the log-normal distribution and the Pareto distribution2. These are by far the most common distributions that are unbounded and have long tails. If I were being more thorough I would more seriously investigate other candidate distributions, but some brief research suggests that there are no other strong contenders.
Let P(x) be a probability density function where x is a level of impact (described as a numerical utility) and P(x) gives the probability density of interventions at that level of impact. The Pareto distribution has the property that if P(x)/P(2x) = k, for some constant k, then P(ax)/P(2ax) = k for any coefficient a. This sounds like a reasonable property for the space of interventions to have.
A log-normal distribution looks similar to a Pareto distribution at some scale, but unlike a Pareto distribution, the tail diminishes increasingly quickly: for sufficiently large x,
no matter what parameters are used to define the two distributions.
Examples of real-world phenomena that follow a Pareto distribution include word frequency, webpage hits, city populations, earthquake magnitudes, and individual net worths3. The distribution of interventions feels qualitatively similar to these in a way that’s hard to describe. On the other hand, I don’t know of a mechanism for generating Pareto distributions that could plausibly generate a distribution of interventions (see Newman (2006)3). It seems more plausible that interventions could be modeled as a natural growth process (although I haven’t thought about this much and I’m not exactly sure how this model fits). Additionally, many data historically believed to follow a Pareto distribution were later shown to be log-normal4. A log-normal distribution describes such data as the lengths of internet comments, coefficients of friction for different objects, and possibly individual incomes.
How can we empirically observe interventions’ impact? Can we do a good enough job to get a strong prior?
I attempted to estimate what the distribution looks like by examining the list of cost-effectiveness estimates published by the Disease Control Priorities Project. The interventions (measured in dollars/DALY) follow an exponential curve along the range [10^0, 10^4]:
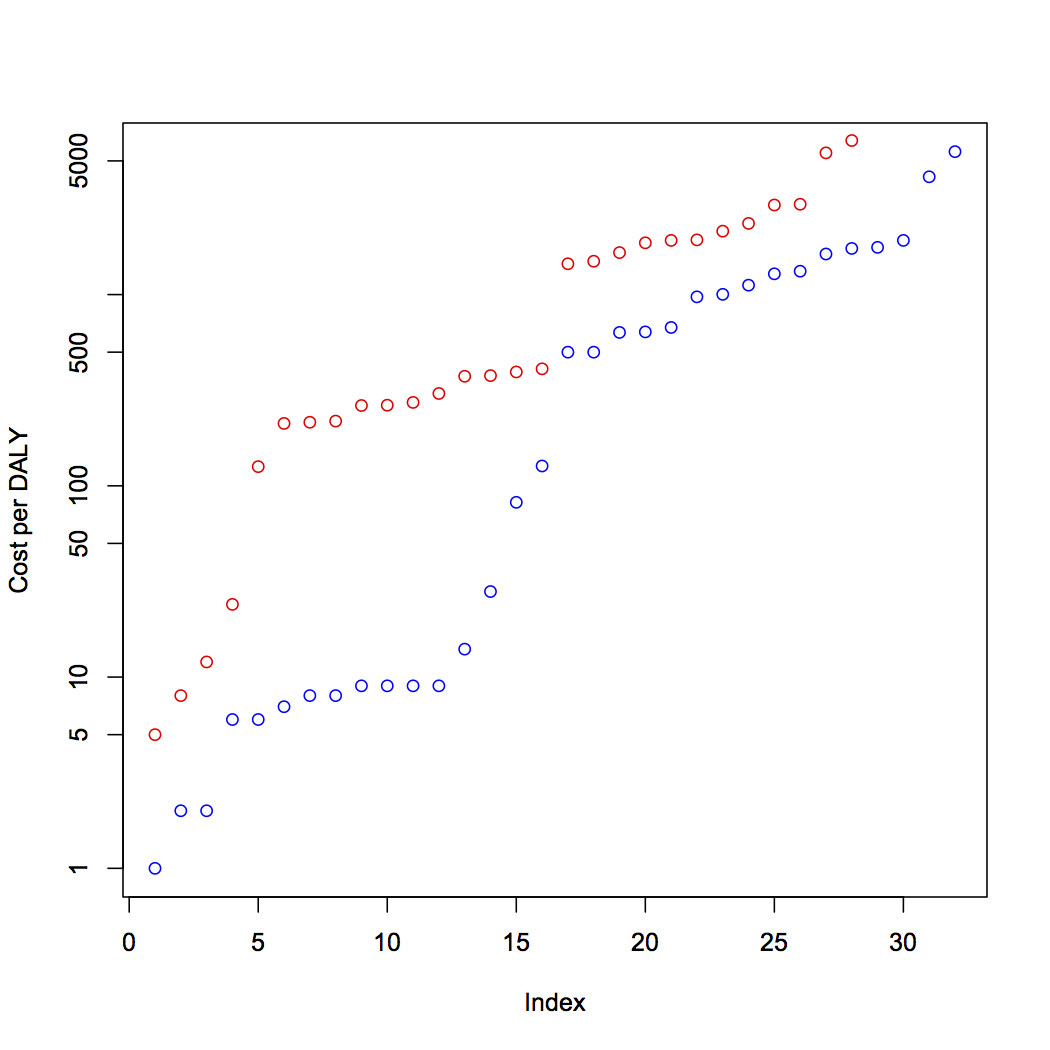
(Minimum estimates are in blue, maximum estimates are in red. Raw data available here.)
This looks sort of like what you’d get if you sampled from a log-normal distribution, but not quite. Unfortunately there are some problems with this data set:
What would it take to construct a true prior distribution? This would require having a large data set of random interventions where we have a fairly accurate idea of their cost effectiveness. It would probably take more work than compiling the DCP2 estimates since it would have to span a much wider scope. Perhaps a government or an organization like The Gates Foundation could construct such a data set if it put a team of researchers on the project for several years, but short of that, I don’t believe a project like this is feasible. So this approach is out. (Unless you want to do your PhD thesis on this topic, in which case I’m all for that and please send it to me once you’re done.)
Maybe we can build a theoretical model that tells us something about what we’d expect the distribution of interventions to look like.
At a naive first glance, an intervention could be anything you do that has an impact on the world. The universe is a big space and the space can be occupied by sentient beings that have positive or negative utility. So we can represent the universe as a vector where each element contains a real number representing the utility at the corresponding location in space.
The universe naturally changes over time. We can represent this change by multiplying the universe vector by a square matrix.
An intervention changes your little localized part of space and then potentially has effects that propagate throughout the universe. We can represent an intervention by adding 1 to some element of the vector.
We can find a theoretical prior distribution by looking at the distribution of utility differences when we change the elements of the universe vector. This distribution is the sum of a large number of uniform distributions, so it’s approximately normal. Does that mean we should use a normal distribution as the prior?
I don’t think so. This theoretical model is pretty coarse, and it covers the space of all possible actions rather than all reasonable interventions. There are lots and lots of things you could do to try to improve the world that you never will do because they’re so obviously pointless.
Let’s consider an alternative model where an action has some immediate impact, and then has effects that propagate outward multiplicatively. Here, if the effects propagate over sufficiently many steps, then by the Central Limit Theorem the final distribution will be log-normal. This is some evidence in favor of using a log-normal distribution as the prior.
One person I spoke to suggested that actions have some additive effects and some multiplicative effects, so the prior should look something like a combined normal/log-normal distribution. This is an intriguing idea worth further consideration, but I won’t discuss it more here.
None of the considerations so far have been particularly strong. At this point, I weakly prefer log-normal distributions over Pareto distributions because I find it plausible that interventions follow something like a multiplicative growth process that tends to generate log-normal distributions.
We can estimate parameters by trying to figure out what’s reasonable a priori, and by picking parameters that produce reasonable results. The latter approach begs the question a bit, but I actually think it’s reasonable to use. You probably have strong intuitions about how to compare some interventions and weak intuitions about how to compare others. You can check your model against the interventions where you have good intuitions. Then you can think of the model as a formalization of your intuitions that makes it easier to extrapolate to cases where your intuitions don’t work well.
I have decent intuitions about, for example, how to trade off between GiveDirectly and the Against Malaria Foundation (AMF). GiveWell’s latest estimate (as of this writing) suggests that AMF is 11 times more cost-effective than GiveDirectly. The evidence for GiveDirectly is stronger, so I’d be indifferent between $1 to AMF and maybe $6-$8 to GiveDirectly. So I should choose parameters that get a result close to this. But I don’t have good intuitions about how good AI safety work is compared to GiveDirectly, so if I build a good model, its results will be more useful than my intuitions.
Pareto and log-normal distributions both have two main parameters; we can call them the shape parameter and scale parameter (they correspond to α and xm for Pareto, and μ and σ for log-normal). If we know the shape parameter and the median, we can deduce the scale parameter. For either distribution, it’s probably easier to guess the median a priori than to guess the scale; so let’s consider what the median should be.
The median depends a lot on what your reference class is. Are you looking at all possible actions? Almost all actions are pretty useless. Maybe instead you should look at non-obviously-useless actions. This still includes things like PlayPumps, but I don’t expect I’ll be tempted to support most of these things.
So perhaps the reference class should be the set of all interventions that I might be tempted to support (with my money or time). It seems plausible to me that GiveDirectly is about the median for this set. I wouldn’t support anything worse than GiveDirectly on purpose, but a lot of things that I think might be effective probably aren’t that effective. Unfortunately, this decision is pretty arbitrary and I see no obvious way to make it more well-informed. Fortunately, the choice of the median doesn’t have as big an effect as the choice of the shape parameter.
Let’s look at three example interventions. Say we have GiveDirectly with an estimated utility of 1, Against Malaria Foundation with an estimated utility of 11, an animal advocacy intervention with estimated utility 2x104, and an x-risk intervention with estimated utility 1040 (these estimates come from my previous essay). Let’s look at how the posterior expected value changes as we vary the s parameter for the estimate and the parameters for the prior distribution. I chose values (0.1, 0.3, 0.8, 2.0) because I believe these are approximately the order-of-magnitude standard deviations on the estimates for GiveDirectly, AMF, animal advocacy (in particular corporate campaigns), and x-risk (in particular AI safety) respectively5.
The results for a Pareto prior scale xm such that the prior distribution has a median of 1.
The results for a log-normal prior use median 1 and vary the σ parameter. (σ in the prior represents the same thing as s in the estimate.)
α = 1.1:
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.03 | 10.77 | 1.94e+04 | 9.69e+39 |
| 0.30 | 1.22 | 9.36 | 1.50e+04 | 7.51e+39 |
| 0.80 | 2.09 | 6.67 | 2667.24 | 1.31e+39 |
| 2.00 | 4.32 | 6.60 | 45.21 | 2.98e+34 |
α = 1.5:
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.03 | 10.63 | 1.90e+04 | 9.48e+39 |
| 0.30 | 1.23 | 8.51 | 1.24e+04 | 6.21e+39 |
| 0.80 | 1.92 | 4.99 | 743.02 | 3.36e+38 |
| 2.00 | 2.83 | 3.69 | 10.10 | 6.16e+30 |
α = 2.0:
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.03 | 10.47 | 1.85e+04 | 9.24e+39 |
| 0.30 | 1.24 | 7.74 | 9780.87 | 4.89e+39 |
| 0.80 | 1.80 | 4.02 | 185.91 | 6.16e+37 |
| 2.00 | 2.25 | 2.74 | 5.23 | 1.53e+26 |
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.03 | 10.21 | 1.75e+04 | 8.76e+39 |
| 0.30 | 1.25 | 6.78 | 6076.03 | 3.03e+39 |
| 0.80 | 1.68 | 3.24 | 33.64 | 2.07e+36 |
| 2.00 | 1.88 | 2.19 | 3.42 | 9.42e+16 |
σ = 0.5:
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.00 | 10.03 | 1.37e+04 | 2.89e+38 |
| 0.30 | 1.00 | 5.83 | 1453.86 | 2.58e+29 |
| 0.80 | 1.00 | 1.96 | 16.15 | 1.72e+11 |
| 2.00 | 1.00 | 1.15 | 1.79 | 225.39 |
σ = 1.0:
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.00 | 10.74 | 1.81e+04 | 4.02e+39 |
| 0.30 | 1.00 | 9.02 | 8828.75 | 4.98e+36 |
| 0.80 | 1.00 | 4.32 | 419.35 | 2.46e+24 |
| 2.00 | 1.00 | 1.62 | 7.25 | 1.00e+08 |
σ = 1.5:
| s | GiveDirectly | AMF | animals | x-risk |
|---|---|---|---|---|
| 0.10 | 1.00 | 10.88 | 1.91e+04 | 6.65e+39 |
| 0.30 | 1.00 | 10.03 | 1.37e+04 | 2.89e+38 |
| 0.80 | 1.00 | 6.47 | 2231.27 | 1.39e+31 |
| 2.00 | 1.00 | 2.37 | 35.35 | 2.51e+14 |
s increases, posterior EV drops very suddenly on a log scale (e.g. 1039, then 1039, then 1037, then 1026). Under a log-normal distribution, as s increases, posterior EV drops fairly smoothly. I have a sense that the log-normal behavior is better here but I don’t really know.This all assumes that we’re using a single prior for all interventions. But perhaps global poverty and x-risk are sufficiently different that we should use different prior distributions for them.
Now, I’m somewhat wary of using different priors for different interventions because it makes it easier to tweak the model to get the results you want, but I believe we can avoid this if we’re careful. Instead of changing priors based on whatever seems reasonable, which leaves lots of room for biases to creep in, we can change priors in a systematic way.
I believe the following system is defensible:
To expand on point 2: most people with power6 care about other people in the developed world more than people in the developing world, because people in the developed world tend to have more power and they care more about themselves and people around them. Even within the developed world, rich people are harder to help than poor people because rich people already have a lot of resources.
People care even less about non-human animals, beings in the far future, and sentient computer simulations. So we should expect on priors that these groups are easier to help.
Even without knowing anything about particular animal advocacy interventions, I would expect that the best ones are better than the best global poverty interventions, because I believe most people with power irrationally discount non-human animals in the same way they irrationally discount humans in the developing world.
GiveWell’s estimates suggest that it’s more than an order of magnitude more expensive to help humans in America than humans in the developing world.It’s probably reasonable to assume that it’s 10 times easier to help non-human animals than humans, since philanthropists care much less about non-human animals than about humans and animal advocacy receives far less funding than global poverty. We could use something like the following medians for prior distributions in different categories:
| Category | Median |
|---|---|
| developed-world poor | 0.1 |
| global poor | 1 |
| factory-farmed animals | 10 |
| far future humans | 10 |
| wild animals (now and far future) | 100 |
| sentient computer programs | 100 |
People will inevitably disagree on these priors. I’m sympathetic to the case for making all the priors the same, but I’m also sympathetic to the case for making the differences in priors a lot wider.
I have an intuition that the probability of observing an intervention with expected value 2X is a constant fraction of the probability of observing an intervention with expected value X, no matter the value of X. The only distribution with this property is a Pareto distribution. When I first wrote this post I felt that a Pareto distribution described the prior well, but after looking at the data more, I believe a log-normal distribution works better. I don’t find it plausible that I should be indifferent between $1 to AI safety and $94,200,000,000,000,000 to GiveDirectly7, as a Pareto prior suggests. And because of the shape of a Pareto distribution, you can’t fix this by reducing the variance of the prior unless you reduce it to an absurdly small number. On the other hand, this isn’t great reasoning and I have a lot of uncertainty here.
For a log-normal prior, choosing parameter σ = 0.5 and putting GiveDirectly at the median produces more reasonable results than other obvious parameter values. I will use σ = 0.5 in future essays that require using a prior distribution. Once it’s more polished, I will provide the spreadsheet I used to do these calculations; if you believe σ = 0.5 produces results that penalize high-variance interventions too much or too little, you can increase or decrease σ accordingly.
I believe the most difficult and important choice here is what distribution shape to use for the prior, and I do not believe any of the evidence I presented here is particularly strong. I’m interested in hearing any arguments for why we should use Pareto, log-normal, or something else.
Thanks to Gabe Bankman-Fried and Claire Zabel for providing feedback on this essay.
This raises the question, randomly chosen how? This is a difficult question. I think a plausible way to do this is to suppose you’re choosing interventions uniformly at random over the space of all interventions that are plausibly the best intervention at first glance. In the end we only want to fund the best intervention (until it receives sufficient marginal funding that it’s no longer the best), so we’re only considering interventions where it’s somewhat plausible that they could turn out to be the best. ↩
Rather than use a Pareto distribution, it actually makes more sense to use a Lomax distribution, which is just a Pareto distribution centered at -1 instead of 0; that means the probability density function starts at 0 instead of 1. I’ll continue referring to this as a Pareto distribution. ↩
M. E. J. Newman. Power laws, Pareto distributions and Zipf’s law (2006). http://arxiv.org/pdf/cond-mat/0412004v3.pdf ↩ ↩2
Benguigui, L., and M. Marinov. “A classification of natural and social distributions Part one: the descriptions.” arXiv preprint arXiv:1507.03408 (2015). https://arxiv.org/ftp/arxiv/papers/1507/1507.03408.pdf
Singer, Phillipp. “Not every long tail is a power law!” (2013). http://www.philippsinger.info/?p=247
h/t Andres Gomez Emilsson for pointing me to these sources. ↩
Previously I had put the s values at (0.25, 0.5, 1, 4). I believe I was substantially overestimating the variances. I was taking cost-effectiveness estimates and expanding them by a lot to account for the outside-view argument that the estimates are probably inaccurate. But I believe this was a mistake, since the expectation that the estimates are too high is already accounted for by using a prior distribution. So I was effectively double-counting this uncertainty. I have changed the s values to more closely reflect the actual variances of the estimates, with some adjustment to account for overconfidence. ↩
“Power” here more or less means the ability to effect change, e.g. by donating a lot to charity, producing high economic output, etc. ↩
This only considers GiveDirectly’s direct effects and not its flow-through effects, but I still find it implausible that GiveDirectly’s direct effects could matter so much less in expectation than AI safety work. ↩
I wasn't sure if this article was the sort of thing the EA Forum audience is interested in, so let me know. I figured it's better to post and get feedback than to not post and never know.
I am very much in favor of posts like this and would love there to be a lot more posts like this.
I'm very interested in this sort of stuff, though a bit of the maths is beyond me at the moment!
I'd suggest looking at Carl and Toby's comments on this GiveWell post if you're interested in formulating priors.
Also note that whereas Holden rejected the Charity Doomsday Argument, clarifying he was talking about relative standing of charities including all flow-through effects (where a big future increases the impact of most interventions astronomically, although some more than others), Dickens embraces it:
I don’t find it plausible that I should be indifferent between $1 to AI safety and $94,200,000,000,000,000 to GiveDirectly...This only considers GiveDirectly’s direct effects and not its flow-through effects, but I still find it implausible that GiveDirectly’s direct effects could matter so much less in expectation than [the flow-through effects of] AI safety work
The specific interventions are a red herring here, it's saying the future won't be big and subject to any effect of our actions (like asteroid defense, or speeding up colonization by 1 day).
This post is also relevant.
I chose values (0.1, 0.3, 0.8, 2.0) because I believe these are approximately the order-of-magnitude standard deviations on the estimates for GiveDirectly, AMF, animal advocacy (in particular corporate campaigns), and x-risk (in particular AI safety) respectively
I'm probably just bad at math, but does a 2.0 SD vs. a 0.1 SD imply that GD is ~20x more robust than AI safety?
Can you elaborate more on how these values are set?
It depends on what you mean by "robust".
I chose 0.8 by writing cost-effectiveness estimates of corporate campaigns using 80% credence intervals for the inputs and then calculating the standard deviation of the result. I didn't quite do it that way for GD and AMF; I tried to estimate the standard deviation from looking at GiveWell's historical estimates and its the variation in its employees' current estimates. This was a somewhat rough process but I believe 0.1 and 0.3 are approximately correct.
Also, in your model, QALY improvement is a particularly important cell, but I don't see much quantitative discussion (though there is some qualitative discussion) in the OpenPhil posts. How did you arrive at your number of 0.5 to 1.5, normally distributed? Do you give any credence to Hsiung's view that cage-free is net negative toward hens (though disputed heavily by Bollard)? Do you give any credence to the anti-welfarist argument that cage-free has bad long-term effects on creating a society complacent to some level of harm toward animals?
I give some credence to both those things, yes. The anti-welfarist argument doesn't affect this calculation because this calculation only looks at the direct effects of cage-free campaigns, but it does affect my estimate of the long-term value of the campaigns.
The number for QALY improvement is mostly based on my best guess and other people's best guesses; it's hard to say with high accuracy what number we should use.
Thanks. Can you elaborate on what a 1 QALY improvement means in this context? Each chicken's overall life is improved by 1 QALY?
It means that the chicken's life is 1 chicken-QALY better per year. There's a separate figure to adjust chicken sentience to human sentience, where I assume that 1 chicken QALY is worth about 0.3 human QALYs.
What does 1 QALY per year mean? Isn't 1 QALY per year already the difference between non-existence and an ideal, healthy life?
Yes, so that means if the difference between cage-free and caged is 1 QALY then it's as big a difference as between non-existence and healthy life. So like if I were living on a factory farm for a year, and you gave me the option to reduce my lifespan by 1 year but I get to spend my year on a factory farm without a battery cage, that seems like a reasonable deal to me.
How does the estimate go above 1 QALY/year? Isn't that the maximum possible?
No. 1 QALY/year is how good a normal life is. But a life could be better than that, and a life could be more bad than a good life is good. If I'd be willing to give up 10 years of normal life to avert 1 year on a factory farm, then that means a year on a factory farm is worth -10 QALYs.
I can see your model of cage-free campaigns here, how do you translate that standard deviation (37K on one run, 80K on another) into 0.8?
The Guesstimate model isn't great, you should look at the one on my spreadsheet instead. My most up-to-date estimate actually has a sigma of 0.56. It's not actually a standard deviation, it's the standard deviation of the log-base-10 of the distribution, which means the difference between the mean and one standard deviation above the mean is 0.56 orders of magnitude.
Seems like you ought to conduct the analysis with all of the reasonable priors to see how robust your conclusions are, huh?
Yeah, I've done some sensitivity analysis to see how the choice of prior affects results. I talk about this some in this essay. In my spreadsheet (which I haven't published yet but will soon), I calculate posteriors for both log-normal and Pareto priors.
The included estimates might not actually be that accurate, so it might not make sense to use them to construct a prior.
My understanding was that the DCPP estimates were very rough, (for example, one of the estimates for deworming was way off in terms of education benefits, wasn't it) so it wouldn't really make sense to call it a prior based on empirical/field observation.
Yep, that's part of the reason why I'm not using those results.


Outside the model, your inchoate 'prior' has to include credence in all the models you could be convinced of by evidence.
A model that fixes the distribution of effectiveness by assumption is unable to accommodate evidence that the distribution is otherwise.
For example, evidence that the Earth is old and will be habitable for hundreds of millions of years is evidence that many kinds of impacts on the world may have big long-run effects. Likewise for astronomical evidence of the resources of the Solar System and other stars.
When you take that into account it increases the expected impact of almost every action, e.g. increasing GDP by $1 has astronomical waste implications. It also has implications for the relative effects of different interventions.
To represent this you need to have a model with uncertainty over the shape of the distribution, e.g. a mixture model of multiple candidate distributions whose weights are updated with evidence.
Likewise, neglectedness of different areas is subject to empirical inquiry, and much of the evidence we collect in prioritization and evaluation bears on it.
This framework treats a certain subset of evidence about neglectedness very differently from other evidence about neglectedness, or other charity features. All other kinds of evidence, including other evidence about neglectedness (market inefficiencies, biases, taboos, new discoveries, whatever) are discounted severely for top performers, becoming negligible after a certain point, while these differences go undiscounted.
Someone else might make a framework with different priors for direct intervention spending, vs lobbying, vs scientific research, which would similarly favor evidence about intervention type over other evidence for top performers.
Couple of important points you're making here.
On your first point, instead of using a single prior distribution I could do a weighted combination of multiple distributions. There are two ways to do this: either have a prior be a combination distribution, or compute multiple posteriors with different distributions and take their weighted average. Not sure which one correctly handles this uncertainty. I haven't done the math but I'd expect that either way, a formulation with distribution probabilities 90% log-normal/10% Pareto will give much more credence to high cost-effectiveness estimates than a pure log-normal. I don't believe it would change the results much to assign small probability to distributions with thinner tails than log-normal (e.g. normal or exponential).
On your second point, yeah I'm including some extra information in the prior, which is kinda wishy-washy. I realize this is suboptimal, but it's better than anything else I've come up with, and probably better than not using a quantitative model at all. Do you know a better way to handle this?
Not sure what you mean by a 'combination distribution', but I think something like Carl's suggestion is correct: have a hierarchical model where the type of distribution over effectiveness that you will use is itself a random variable, which the distribution over effectiveness has as a 'hyperparameter'. You could also add a level to the hierarchy by having a distribution over the probabilities for each type of distribution. That being said, it might be convenient to fix these probabilities since it's difficult to put all the evidence you have access to in the model. Probabilistic programming languages are a convenient way to handle such hierarchical models, if you're interested, I recommend checking out this tutorial for an introduction focussing on applications in psychology.
I mean that your prior probability density is given by $P(X) = w_{Pareto} P_{Pareto}(X) + w_{lognorm} P_{lognorm}(X)$ for weights $w$. (You can read LaTeX right?)
Sure. I think a better thing to do (which I think what Carl is suggesting) is to have a prior distribution over x (the effectiveness of a randomly chosen intervention), and interventionDistribution (a categorical distribution over different shapes you think the space of interventions might have). So P(x, 'Pareto') = P('Pareto') P(x | 'Pareto') = w_{Pareto} P_{Pareto}(x) and P(x, 'logNormal') = P('logNormal') P(x | 'logNormal') = w_{logNormal} P_{logNormal}(x). Then, for the first intervention you see, your prior density over effectiveness is indeed P(x) = w_{Pareto} P_{Pareto}(x) + w_{logNormal} P_{logNormal}(x), but after measuring a bunch of interventions, you can update your beliefs about the empirical distribution of effectivenesses.