This is a linkpost to a notebook I've written which uses Squiggle to quantify uncertainty in GiveWell's estimate of cost per death averted by the Against Malaria Foundation. My goal is to test a more legible cost effectiveness analysis of the AMF—one that readers can interact with and alter. This is heavily inspired by other cost effectiveness analyses created using Squiggle, and directly employs code from Sam Nolan's Observable notebook.
I'm copying only the methodology, final result, and some thoughts on Squiggle and cost effectiveness analysis here. The entire write-up can be found in the linked notebook.
Methodology
My approach is to copy GiveWell's analysis closely, except for incorporating quantified uncertainty where relevant. For some variables, such as disease burden data, and effect sizes from academic papers, we can use the confidence intervals to incorporate uncertainty. For others, where relevant uncertainty data is either private, non-existent, or very time-consuming to properly consider, I set the probability distribution arbitrarily, e.g., by setting a 95% confidence interval with ±10% of the mean value. I mark these arbitrary changes clearly in the code.
I make the following significant omissions:
- I only examine the cost effectiveness of the Against Malaria Foundation's LLIN distributions in the Democratic Republic of Congo (DRC). GiveWell's CEA is broken down across eight regions where the AMF operates, without any explicitly-stated way I could find of aggregating them. I assume that GiveWell takes a weighted average of each region, but am unsure of the weighting.
- I ignore income effects, and hence do not calculate the total units of value (in GiveWell's terminology) produced by the intervention. Instead, I limit this analysis to the question of how many lives are saved, and state the conclusion in USD/death averted.
The two omissions described above, in addition to high likelihood of mistakes (I haven't had anyone check this over, and have some concerns I've noted in the code) means that people should not take this notebook seriously as an actual cost effectiveness analysis of the Against Malaria Foundation. Instead, this is primarily intended as a way to continue testing using Squiggle (+ Observable) as a means of explaining CEA.
It can also a) give us a rough idea of the magnitude of the uncertainty of the cost effectiveness of the AMF, b) serve as a starting point for others to input their own estimates into the model structure.
Cost per life saved, after all adjustments
The final cost per life saved is the total spending by all philanthropic actors divided by the product of the number of unadjusted deaths averted and each of the three adjustment factors.
cost_per_life_saved =
total_spending_by_all_contributors /
((total_number_of_under_5_deaths_averted + total_number_of_over_5_deaths_averted) *
total_charity_level_adjustment_factor *
total_intervention_level_adjustment_factor *
total_funging_leverage_adjustment_factor)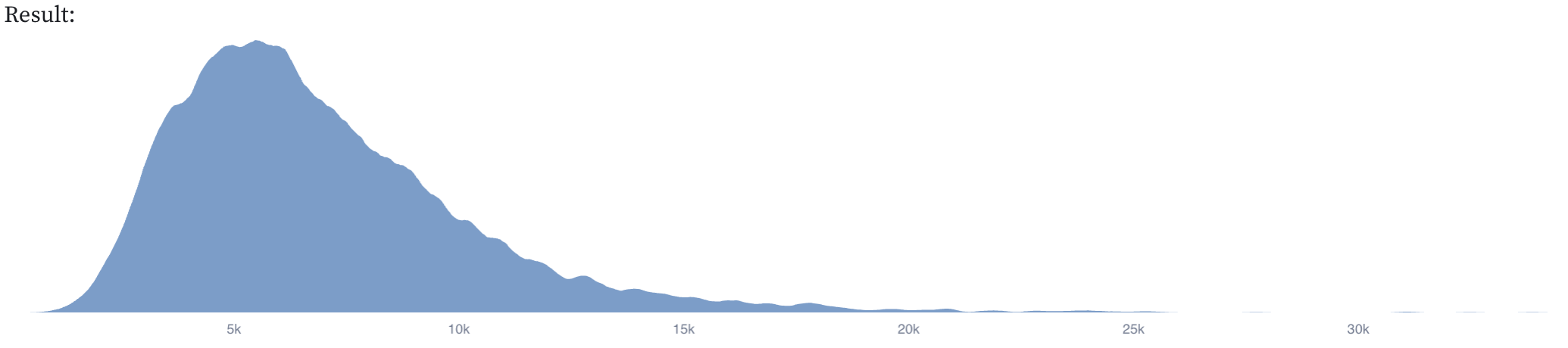
GiveWell's point estimate for the DRC is $7,759. The mean of the distribution above is $6980. To reiterate, this should not be taken seriously as an update to GiveWell's estimate. This was more of an experiment in replicating a complicated model in Squiggle, and trying to explain what was going on in a notebook.
Some notes on Squiggle
- I found the Observable + Squiggle combination easy to use, as someone with very little coding experience (besides small personal projects) and no CS background. The other options listed in this post, besides the playground, were not accessible at my level of (in)experience. If there are significant advantages for the average user in using Squiggle via a Typescript Library, for instance, it might be helpful to provide detailed steps in the style of Sam Nolan's Observable notebook.
- I haven't yet looked into conducting sensitivity analysis on a Squiggle model. Time permitting, I plan on learning about sensitivity analysis more in-depth, and figuring out how to do it in Squiggle. If anyone has useful sources for this / has solved this problem already, I'd really appreciate a comment!
- Minor issue, but when Squiggle throws an error, it is often difficult to know where I've made a typo because there is no reference to a specific line.
Some notes on explainable CEAs
- The main purpose of this notebook was to test out presenting a CEA with quantified uncertainty in a way that felt intuitive to me. I definitely didn't fully succeed in this regard, in part because there are parts of GiveWell's CEA I still don't fully understand (which is a prerequisite to presenting something intuitively). I also haven't fully gotten the hang of Observable formatting, which I think significantly detracted from the notebook's presentability.
- I think that explaining CEAs in this way is helpful in revealing some of the assumptions underpinning them. For example, I wouldn't have found it obvious by looking at a spreadsheet that GiveWell assumes the same age distributions for general population and net coverage. This might be useful for red teaming CEAs, i.e., it might both be helpful to re-code CEAs in order to scrutinise them, and re-coded CEAs may be easier to scrutinise.


I've been coming back to this model, because I've been doing some thinking on worldview diversification, and having a model like this is great for comparisons.
Two points:
Turns out that unpkg, an online service that Observable was relying on, was down yesterday (https://twitterc.om/unpkg/status/1636149026830843904), but this is fixed now. Sam Nolan thinks that it may have been cached by browsers, which is why it would show up broken for me but not for others, fixed now either way, though ¯\_(ツ)_/¯