Comments
AI energy forecasts may be missing large-scale inference demand

Update after publication: Mo Putera pointed me to SemiAnalysis data on real Opus 4.7 agentic workflows, which pushed my central estimates for both token usage and blended token price substantially downward. The original version used ~140M tokens per 8-hour workday-equivalent and ~$5 per 1M tokens; I now use assumptions closer to ~10M tokens and ~$1 per 1M tokens, but still with wide probability distributions. This makes the energy bottleneck look less immediate for modest levels of labor-equivalent AI use, but still potentially important for very rapid, large-scale deployment. For example, I now focus more on scenarios like 50% global labor-equivalent output (I previously used closer to 3%), including both replacement and additional AI-generated work, where the updated model now estimates much smaller but still significant electricity requirements.
If AI systems are deployed at the scale implied by serious labor-substitution scenarios, inference energy demand could perhaps become larger than training-focused or current-data-center-growth-based AI energy estimates suggest. Whether this happens depends on a less measured variable: how many tokens are required per unit of economically useful AI work.
A useful benchmark to track going forward is whether future systems can keep average token usage around the low millions to low tens of millions of tokens per human-workday-equivalent. Some current agentic analyst/SWE-type workflows seem to be in this range, which makes the energy bottleneck look less immediate for modest deployment.
The key crux is whether token usage stays in that range as AI moves beyond currently automated tasks which might be the first to be automated due to them being low-hanging-fruits. Thus, if broader labor-equivalent deployment requires more context-heavy, less decomposable, or more judgment-intensive work, average token usage could rise into the tens or hundreds of millions of tokens per workday-equivalent. In that case, inference energy could become a major bottleneck.
This is an initial, simple model. I am not trying to make a confident point forecast. I am trying to explore whether large-scale AI inference could plausibly become a major energy constraint, and which assumptions drive that possibility.
Instead of starting from current data-center buildout, chip deployment, or training-run energy use, I start from hypothetical levels of AI labor-equivalent work and ask what inference energy demand would follow under different assumptions about token use, token prices, inference delivery costs, electricity cost shares, etc.
The core question is not “what will AI energy demand be?” but “what range of inference energy demand follows if AI systems are used for economically meaningful labor-equivalent work at scale?”
Token counts are not the whole story. Energy per unit of useful AI work can also fall through lower FLOPs per token, better hardware efficiency, higher utilization, better scaffolding, or more specialized models. The broader question is whether the full inference-efficiency stack can improve fast enough to keep up with large-scale AI deployment.
My motivation for this model was that public training-energy estimates seemed too small to explain how seriously frontier AI actors appear to be treating power, siting, and dedicated energy infrastructure. Large power deals, behind-the-meter generation, nuclear arrangements, and more speculative ideas such as floating or orbital data centers did not make sense given the current, “modest” estimates of future AI energy use.
There are three levels of uncertainty in this piece. First, there is parameter uncertainty: token use per workday-equivalent output, future token prices, delivery-cost shares, electricity-cost shares, and electricity prices are all uncertain. I use probability distributions to reflect this.
Second, for each major parameter, I discuss what would update me toward pushing these distributions higher or lower; what evidence might I not have seen that would change my mind.
Third, there is model uncertainty. The whole framing may be wrong or incomplete. AI systems may map poorly onto human-workday-equivalent units; token prices may not reliably reveal underlying compute or electricity costs; future AI work may be dominated by specialized systems rather than frontier agents; and economic value may be better measured per completed task, per dollar of output, per model-hour, or per successful research step rather than per labor-equivalent workday.
I still think the model is useful because it makes one question more explicit: if ambitious AI deployment scenarios involve very large amounts of useful inference, what energy demand might that imply? The model should therefore be read less as a forecast and more as an initial exploration of whether large-scale inference-driven energy demand could become increasingly binding.
Lastly, my expertise lies in engineering and energy. I am more of a newcomer to compute and AI infrastructure. As such, I might have missed important technical details in this analysis, or made basic errors in my interpretation and use of various metrics etc. I thus value all and any criticism that can make this analysis stronger.
Most AI energy forecasts I have seen start from the supply side: current data-center growth, projected chip deployment or training-run energy use. Epoch, RAND, IEA, and others have already done useful work along these lines, and this work has helped start making sense of AI energy demand. In this post I try a complementary calculation. Instead of starting with current data centers and extrapolating forward, I start with ambitious AI adoption scenarios — for example, AI systems doing work equivalent to some fraction of the global workforce — and ask what inference energy demand might follow from such assumptions.
Part of what made me interested in this is the apparent mismatch between AI-sector behavior and energy-sector normalcy. Frontier AI actors seem to be treating power, siting, and infrastructure as strategically important: large power deals, nuclear arrangements, behind-the-meter generation, and even more speculative (?) ideas such as floating or orbital data centers keep appearing. These more unusual ideas do not seem motivated by current training-run energy estimates alone. While they may be hype, PR, or option value, it is also possible that they make sense if frontier labs and their investors are planning against a much larger demand picture: large-scale inference compute energy requirements.
The reason inference matters is that many of the largest claims about AI’s future impact are about replacing or augmenting large amounts of human labor, creating very large economic value, or running large numbers of agents. If those scenarios happen, energy use may become dominated by inference rather than training.
This post therefore uses a simple top-down model. I start with labor-equivalent AI adoption scenarios and ask what energy demand follows under different assumptions about token usage, token price, compute cost, and electricity cost. The point is to start a discussion around the energy implications of large-scale AI adoption. Moreover, the model also highlights a currently poorly measured variable: how many tokens are needed per unit of useful work.
If that number is low, energy may be much less constraining. But if that number is high, inference energy could become a serious bottleneck. Other factors that could indicate a lower inference energy demand are lower FLOPs per token or improved compute energy efficiency. Thus, this is more than just a claim about token counts: It is a question about the full inference efficiency stack.
I use “energy” rather than only “electricity” because the relevant constraints may include not just grid electricity, but also on-site gas turbines, nuclear plants and their associated upstream supply chains.
If inference energy turns out to be much larger than training energy, then energy may be worth investigating not only as an infrastructure constraint, but possibly also as a policy-relevant pacing or governance surface. I am less confident in that governance claim than in the narrower claim that inference-energy demand deserves more attention. A follow-up piece could explore those possible intervention points in more detail.
The calculations in this article are made using Guesstimate, meaning uncertainty is baked into the final projections. In the sections below I give an overview of the main calculation steps, the uncertainty around each and what would update my prediction to be lower or higher. Guesstimate is a user-friendly, online Monte Carlo simulation calculator. Instead of adding, multiplying, etc. specific numbers, these numbers are generated randomly from probability distributions. This is appropriate for this task where there is a large uncertainty around each of the model parameters. Thus, I do not need to determine a specific number but can instead say things like “I think the tokens used per human workday equivalent task will be somewhere between 45 and 490 million tokens”. The calculator will now calculate the final energy estimate hundreds of times, each time using a different number in the 45-490 million range. In the end, the different final energy estimates is used to calculate median, 25th, 90th, etc. percentile estimates of energy demand from AI inference.
A simplified example of Monte Carlo might be an estimate of how many muffins you need for your birthday party. You do not know:
The estimate of the total number of muffins needed, M_tot, is then:
M_tot = G * M_i
This simplified Monte Carlo does 3 runs, pulling numbers based on your defined distributions for each variable:
So, the median number is 16 muffins, and the “75th percentile” (I know, not proper stats but for illustration!) is 18. So maybe (ignoring many simplifications) if you want to be 90% sure you have enough muffins, you get 20 (~~10% chance of not having enough, but this is very from the hip – actual Monte Carlo simulations use hundreds of such runs for better statistical calculations).
Note that as Guesstimate continuously pulls numbers from our defined distributions, the numbers the model give will move around from time to time. Therefore, the numbers for energy consumption herein are rounded and approximate but should be close to the numbers you will find in the Guesstimate model.
Here is the Guesstimate model: https://www.getguesstimate.com/models/26731
Here is an overview over the calculation steps that are explained in more detail in this section:
| Model step | Input / assumption | Current central value |
|---|---|---|
| AI work scale | Workdays-equivalent per year | Scenario input |
| Tokens per workday-equivalent | PERT(5, 700, 2)*100000 | ~12M tokens |
| Token price | exp(PERT(log(0.05), log(9), log(1))) | ~$1.4 / 1M tokens |
| Delivery cost share of token revenue | PERT(0.2, 1.2, 0.6) | ~60% |
| Electricity share of delivery cost | PERT(0.05, 0.2, 0.11) | ~12% |
| Electricity price | PERT(0.04, 0.08, 0.06) | ~$0.06/kWh |
| Output | Inference electricity use | TWh/year |
One uncertainty in my model is whether human-workday-equivalent output is the right unit to use at all. Still, I chose this unit because it gives a rough bridge between two things that otherwise do not obviously connect:
But AI systems may not come in human-shaped units. They can be copied, specialized, run in parallel, combined into larger systems, or used in workflows that do not map cleanly onto jobs or workers. This could make the human-equivalent framing wrong in either direction.
Some of these issues also affect token usage per unit of work. I discuss those mechanisms more directly in the token-usage section below.
In summary, I use human-workday-equivalent output only as a crude but intuitive parameter that also lets other research such as labor replacement or economic activity plug more directly into this model. The point is not that AI systems will literally replace humans in neat worker-sized units. The point is that ambitious AI adoption scenarios imply large amounts of economically useful AI work, and we need some way to translate that work into inference demand. The correct unit may eventually be something else entirely — perhaps tokens per completed task, tokens per dollar of useful output, tokens per successful research step, or model-hours of economically useful cognition. For now, human-equivalent work is a useful way to make the scale of the energy question visible.
After choosing human-equivalent output as a rough scaling unit, the next question is what time granularity to anchor on:
Instead, I use an 8-hour human-workday-equivalent as a middle ground. It is long enough to feel closer to economically meaningful independent work than a short benchmark task, but not so long that I need to model fully autonomous multi-day or multi-month projects with changing goals, accumulated context, feedback loops, coordination between agents, and unclear boundaries between one task and the next.
Token usage probably does not scale linearly with task length.
Eight 1-hour tasks are not necessarily equivalent to one 8-hour task. Shorter tasks will usually require fewer tokens. But a single longer task may require more context, planning, tool use, verification, backtracking, and ability to recover from mistakes. So lower token counts per hour seem more plausible at shorter time horizons, while longer tasks with more context and complexity may push token usage up nonlinearly.
This means task horizon and token usage are not independent variables. The token distribution I would use for a 1-hour task is not the same distribution I would use for an 8-hour task, and neither is the same as the distribution I would use for a week-long project. Token usage is conditional on the chosen work unit.
The next section estimates token usage conditional on this 8-hour anchor.
Shorter task horizons would be more appropriate if economically useful AI work mostly happens through many small, well-scaffolded tasks.
I would update toward a shorter task-time anchor if:
- substantial labor substitution happens through short tasks that can be chained together without much long-horizon overhead;
- useful AI work looks less like “one agent works for a day” and more like many small task completions coordinated by tools, workflow software, retrieval systems, tests, or humans;
- external memory, scaffolding, and verification systems carry most of the continuity that a human worker would normally keep in their head;
- short task benchmarks turn out to predict real economic usefulness better than longer-horizon benchmarks;
- systems of smaller or more specialized AIs can collaborate cheaply enough that long single-agent task horizons become less relevant.
If this is right, the 8-hour anchor may be too demanding, and the token-usage estimate would likely move downward — unless coordination between short tasks adds back much of the saved token use.
Longer task horizons would be more appropriate if economically important AI work requires sustained context, sequential reasoning, or persistent planning across longer arcs.
I would update toward a longer task-time anchor if:
- useful AI work looks more like multi-day debugging, research, strategy, architecture, or planning than discrete workday-sized tasks;
- the economically valuable part is not doing many subtasks, but maintaining coherent direction across them;
- long-horizon agentic systems show large gains from keeping context, memory, and plans active over time;
- real-world deployment requires many cycles of testing, critique, revision, and verification before useful output is accepted;
- future AI systems look less like task-by-task tools and more like persistent AI workers, teams, or organizations.
If this is right, the 8-hour anchor may be too short, and token usage could rise nonlinearly because longer tasks may require larger context windows, more retrieval, more self-checking, more tool use, more failed branches, and more coordination.
METR-style time-horizon evaluations are useful because they already compare AI performance to human task-completion time, especially in software-related domains where AI is currently most visibly useful and where benchmarks are more developed.
But I do not want to overinterpret them. A measured long time horizon on a benchmark suite does not necessarily mean broad real-world labor substitution. Some tasks that take humans a long time may be decomposable, scaffold-friendly, or routine once the right process is found. Conversely, some short tasks may be hard because they require unusual judgment, tacit knowledge, or a hard conceptual leap.
This matters because time horizon is a lossy proxy. It may mix very different kinds of difficulty: persistence, decomposition, tool use, context length, verification burden, and actual reasoning depth.
For now, I use 8 hours because it is intuitive, close to the workday language used in labor-substitution discussions, more economically meaningful than very short tasks, and easier to model than week- or month-long autonomous projects. Future work should probably model several task horizons separately — for example 1-hour, 8-hour, and multi-day tasks — instead of pretending there is one universal token cost for economically useful AI work.
After fixing the work unit at an 8-hour human-workday-equivalent, the next step is to estimate how many tokens such a “work package” might require.
This is the most important and least certain part of the model. In the Guesstimate sensitivity analysis, token usage per workday-equivalent is the largest driver of the final energy result. It is also the parameter where better real-world data would most change my view.
The most useful evidence I have found so far comes from real agentic workflows. Mo Putera pointed me to SemiAnalysis examples of Opus 4.7 being used for analyst-type work: converting Excel models into dashboards, creating charts, building financial models, analyzing company earnings, and similar tasks. Mo’s rough read is that around 8 hours of analyst-type work costs roughly $7–30 in Opus 4.7 token spend. Using SemiAnalysis’ estimated blended price of roughly $1 per 1M tokens, this suggests roughly 7–30M tokens per 8-hour workday-equivalent for these workflows. Mo suggested a center around 15M tokens as a plausible read from these examples.
I use this as my main anchor, but with a wide range. Current analyst/SWE-style workflows may be relatively low-hanging fruit: decomposable, scaffoldable, cache-heavy, and easier to verify than many other kinds of economically important work. Leadership-level work, entrepreneurial work, high-context judgment, taste-heavy decisions, or harder R&D tasks could require substantially more tokens per useful workday-equivalent. Mo also noted this uncertainty explicitly.
Token usage is not just a function of how long a task takes a human. As discussed above, this estimate is conditional on the 8-hour workday-equivalent anchor. For a given time anchor, token usage still depends on task type, decomposability, model choice, scaffold, tool use, context length, retries, verification requirements, and what counts as an accepted output. This last point matters because time-horizon studies often use a 50% success threshold, while real deployments may care more about tokens per accepted output.
The available evidence is still narrow. Both SemiAnalysis-style workflow data and METR-style evaluations try to connect AI effort to human-time-equivalent work, but they do so in different ways. SemiAnalysis-style data comes from real deployed workflows with economic pressure to make the work useful and cost-effective. METR-style data comes from benchmark evaluations with explicit task-horizon measurement under controlled scaffolds.
I treat SemiAnalysis-style data as the better central anchor because it is closer to actual deployed agentic workflows. But I still use METR-style data as a cautionary source for the upper tail. In the METR plots, longer measured time horizons appear to require much larger token budgets; for example, GPT-5.1-Codex-Max seems to require on the order of tens of millions of allowed tokens to reach only a few hours of measured time horizon. This makes me hesitant to assume that current analyst/SWE-style workflow token usage will generalize cleanly to harder, longer, less decomposable work.
One possible interpretation is that benchmark settings push toward higher token usage than economically optimized real-world workflows. Another is that current deployed analyst/SWE-style tasks are relatively low-hanging fruit compared with broader future labor-equivalent AI work. Both seem plausible. So I treat the current distribution as a rough best guess rather than a stable forecast, and keep a significant upper tail for harder, less decomposable, or more context-heavy work. I do not treat the METR plot as direct evidence for real-world token usage, since it is benchmark-based, scaffold-dependent, and reports allowed token budgets rather than minimum deployed token use.
For the current Guesstimate model, I use:
=PERT(5, 700, 2)*100000This puts the central estimate around the low tens of millions of tokens, while allowing a wide range from sub-million-token workflows to around 100M tokens for harder or less decomposable work.
This distribution is intended to do three things:
I would update toward lower token usage per 8-hour workday-equivalent if:
In that world, the current token distribution might skew too high, and the final energy estimates would fall substantially.
I would update toward higher token usage per 8-hour workday-equivalent if:
In that world, the model’s current median token estimate could be too low, and inference energy would become more constraining.
One further caveat is that METR-style time horizons often use a 50% success threshold. In this model, I implicitly treat the 8-hour workday-equivalent as something like a 50%-success task unit.
This is not obviously unreasonable. Human work also often involves review, feedback, rework, and failed attempts. But for deployed AI systems, the relevant unit may be tokens per accepted output, not tokens per attempt. If a model needs several attempts before producing something that is actually accepted by users or organizations, then real token usage per useful output could be higher than benchmark token usage per run.
The next step is to convert token usage into dollars. For this I use an effective blended price per 1M tokens. This is not the physical cost of inference; it is the price paid for tokens, which I later convert into inference delivery cost and electricity cost.
I looked at release prices for frontier models over time:
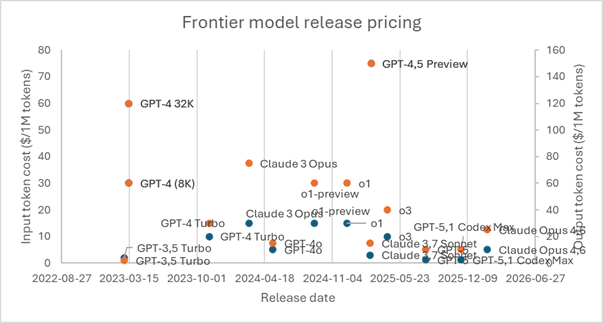
These release prices might show a downward trend, but they are not enough on their own. They usually distinguish between input and output tokens, and may not reflect the effective blended price of agentic workflows. In particular, agentic workflows can have very high input-to-output ratios and high cache hit rates, meaning most tokens may be much cheaper than the headline output-token price.
I have not deeply modelled token accounting. Providers may distinguish between input, output, cached, and sometimes reasoning/thinking tokens, and these can be priced differently. Cached tokens may be cheaper, while internal reasoning/thinking tokens may be billed even when not visible to the user. For simplicity, I use one blended effective price per 1M tokens.
Mo Putera pointed to SemiAnalysis’ estimate that Opus 4.7 agentic workflows may have an effective blended price of around $1 per 1M tokens, despite higher sticker prices. This is because their reported agentic workloads have very high input-to-output ratios and high cache hit rates. I therefore use $1 per 1M tokens as the central value.
For the lower end, I use $0.05 per 1M tokens. This represents a world with very cheap models, strong competition, high cache use, better hardware utilization, lower compute cost per token, or subsidized pricing.
For the upper end, I use $9 per 1M tokens. This represents a world where relevant models remain expensive on a blended per-token basis. Possible reasons include larger models, higher output-token shares, lower cache hit rates, lower utilization, or other serving-cost factors. Some of these may instead show up as more tokens per task rather than a higher price per token; I do not model that distinction in detail.
In Guesstimate, I use:
=exp(PERT(log(0.05), log(9), log(1)))This gives a central value around $1 per 1M tokens, skewed toward lower prices but with a meaningful upper tail.
I would update lower if cache-heavy agentic workflows dominate future usage, if cheaper specialized or open-source models do much of the work, if hardware utilization improves, or if pricing competition continues to push effective token prices down.
I would update higher if economically useful work requires expensive frontier models, higher output-token shares, lower cache rates, expensive reasoning/thinking tokens, or if effective prices stop falling.
For this parameter, I estimate what share of token revenue is spent on delivering inference. This is not the same as electricity cost; it is an intermediate step used to move from token price to the cost base that electricity is part of.
Gross margin is useful here as a rough proxy. If a company has a 40% gross margin, then roughly 60% of revenue is spent delivering the service. This is not a clean measure of compute cost, since it can include other items and accounting practices. But it is one of the few public anchors available. The numbers used to build intuition behind the below distribution are as follows:
Source | URL | Evidence | Implied cost ratio | Role in model |
| OpenAI (H1 2025) | https://www.reuters.com/commentary/breakingviews/how-infer-method-to-openais-madness-2025-10-15/ | $4.3B revenue vs $2.5B cost to deliver | 58% | Lower bound of credible central range |
| OpenAI (adjusted) | https://www.reuters.com/technology/openai-sees-compute-spend-around-600-billion-by-2030-cnbc-reports-2026-02-20/ | Adjusted gross margin ~33% | 67% | Upper bound of credible central range |
| Anthropic | https://www.investing.com/news/stock-market-news/anthropic-trims-profit-margin-outlook-as-ai-operating-costs-rise--the-information-4459316 | Gross margin ~40% | 60% | Independent confirmation |
| DeepSeek | https://www.reuters.com/technology/chinas-deepseek-claims-theoretical-cost-profit-ratio-545-per-day-2025-03-01/ | $87k cost vs $562k theoretical revenue | 15.5% | Lower-bound / skew anchor |
Based on the above, I use the following distribution in Guesstimate:
=PERT(0.2, 1.2, 0.6)This gives a central value around 60%, while allowing values above 100%. I include values above 100% because some inference usage may be subsidized or priced below cost, especially under subscription pricing or aggressive user-acquisition strategies.
I would update this lower if providers show sustained high gross margins. I would update it higher if there is new evidence that frontier inference is subsidized.
With an estimate for inference delivery cost as a share of token revenue, I next estimate what share of that delivery cost is electricity.
By “delivery cost,” I mean the cost of actually running and delivering model outputs to users, excluding things like R&D and marketing. This includes building the data centers, computer hardware, data-center operation, networking, provider overhead, and electricity.
The public anchors I found are sparse, but suggest electricity is material while still being a minority of total delivery cost:
Source | Key numbers | Implied electricity share of full compute TCO | |
| https://www.businessinsider.com/why-nvidia-worth-5-trillion-inside-35-billion-ai-datacenter-2025-10?utm_source=chatgpt.com | 1 GW AI data center: $35B capex, $1.3B/year electricity | ~10–16% (if amortized over 3–5 years, before other O&M) | |
| https://en.wikipedia.org/wiki/Data_center?utm_source=chatgpt.com#cite_note-112 | Electricity is >10% of total data center TCO (general baseline) | Establishes floor ≳10% in many cases | |
Based on the above, I use:
=PERT(0.05, 0.2, 0.11)This gives a central value around 11%, with a range from 5% to 20%.
I would update this lower if hardware capex, construction, networking, cloud/provider overhead, or other non-electricity costs dominate more than assumed. I would update it higher if electricity prices are indeed higher (including cost of building on-site gas turbines).
One point to note is that electricity can be a small share of total cost and still be a binding constraint, because availability, interconnection, siting, permitting, and power-project timelines can matter more than cost share. That said, the chips on which AI is trained and run is recognized as another likely constraint on AI development.
To convert electricity cost into kWh, I use Texas electricity prices as a rough proxy for low-cost regions where large AI data centers seem to be deployed.
As a baseline, I use EIA table 4, which indicates roughly $0.06–$0.08/kWh. Large data-center customers may sometimes face lower effective prices through power contracts, wholesale exposure, or behind-the-meter generation.
For the model, I use:
=PERT(0.04, 0.08, 0.06)This gives a central value of $0.06/kWh, with a range from $0.04 to $0.08/kWh.
I would update lower if AI data centers mostly use very cheap power, and higher if the marginal cost of reliable AI power is above ordinary industrial electricity prices because of grid constraints, dedicated power projects, or interconnection scarcity.
With the numbers above, we can estimate future energy usage due to inference. With ~1bn human worker equivalents we get an average of ~5000 TWh, representing ~15% of current, global electrical consumption.
Note that the number of workers here was chosen in order to generate an interesting trade-off. We can also look at energy usage at 10%, 100% and 500% of human work force, giving central estimates of around 2000TWh, 20 000TWh and 100 000TWh.
Current, total global electricity consumption is ~32 000TWh per year.
Source of total world consumption: https://ourworldindata.org/grapher/electricity-prod-source-stacked
Let us assume we want to look at what is required to get to 50% labor replacement by 2030. We next set the increase in global electricity production to 1000 TWh/year (1500 TWh being the largest addition historically). This means (2026 at the time of writing), that we allow for 4 years of such additions, totaling 4000 TWh. Trying different numbers, at 15M tokens per human work day equivalent gives us a central estimate of 11 000TWh, close to our target. This means, holding hardware energy efficiency and all other constant, we need to, on average across all tasks, keep token usage to around 10M tokens for a human workday equivalent in order to have even a chance of such labor replacement rates by 2030.


SemiAnalysis' recent newsletter provides some data points on token spend vs labor cost ROIs for actual 1-20 hour tasks.
Eyeballing, it looks like 8 hours of analyst-type work costs them $7-30 in Opus 4.7 token spend, so (very roughly) 7-30M tokens at their true blended price of ~$1 per M tokens, in contrast with the post's 40-1,300M token estimate, and already squarely here. I expect token usage to drop further for a given task with more advanced models, and also to vary a lot depending on (essentially) how much the big AI companies prioritise RLVR-ing them and on model jaggedness, but also for doable tasks to get much more complicated, like this and more.
Epoch BOTEC-ed a related question last year, prior to Claude Code: How many digital workers could OpenAI deploy? My main takeaway was "worker equivalents is probably more misleading than helpful if people just skim headline numbers" (which everyone does, speaking as someone who sometimes needs to produce headline numbers).
Thanks so much Mo! I am tempted to make the following updates already - does this seem roughly right? Or is this still too high?
At the same time, I also feel like these numbers might still be too high - especially token price. The reason is that the super helpful links you sent point at pretty steep downward trends on token cost and point well taken on cache tokens being much cheaper.
(I'm not at all an expert on any of this, please discount appropriately)