"Part one of our challenge is to solve the technical alignment problem, and that’s what everybody focuses on, but part two is: to whose values do you align the system once you’re capable of doing that, and that may turn out to be an even harder problem", Sam Altman, OpenAI CEO (Link).
In this post, I argue that:
1. "To whose values do you align the system" is a critically neglected space I termed “Moral Alignment.” Only a few organizations work for non-humans in this field, with a total budget of 4-5 million USD (not accounting for academic work). The scale of this space couldn’t be any bigger - the intersection between the most revolutionary technology ever and all sentient beings. While tractability remains uncertain, there is some promising positive evidence (See “The Tractability Open Question” section).
2. Given the first point, our movement must attract more resources, talent, and funding to address it. The goal is to value align AI with caring about all sentient beings: humans, animals, and potential future digital minds. In other words, I argue we should invest much more in promoting a sentient-centric AI.
The problem
What is Moral Alignment?
AI alignment focuses on ensuring AI systems act according to human intentions, emphasizing controllability and corrigibility (adaptability to changing human preferences). However, traditional alignment often ignores the ethical implications for all sentient beings. Moral Alignment, as part of the broader AI alignment and AI safety spaces, is a field focused on the values we aim to instill in AI. I argue that our goal should be to ensure AI is a positive force for all sentient beings.
Currently, as far as I know, no overarching organization, terms, or community unifies Moral Alignment (MA) as a field with a clear umbrella identity. While specific groups focus individually on animals, humans, or digital minds, such as AI for Animals, which does excellent community-building work around AI and animal welfare while
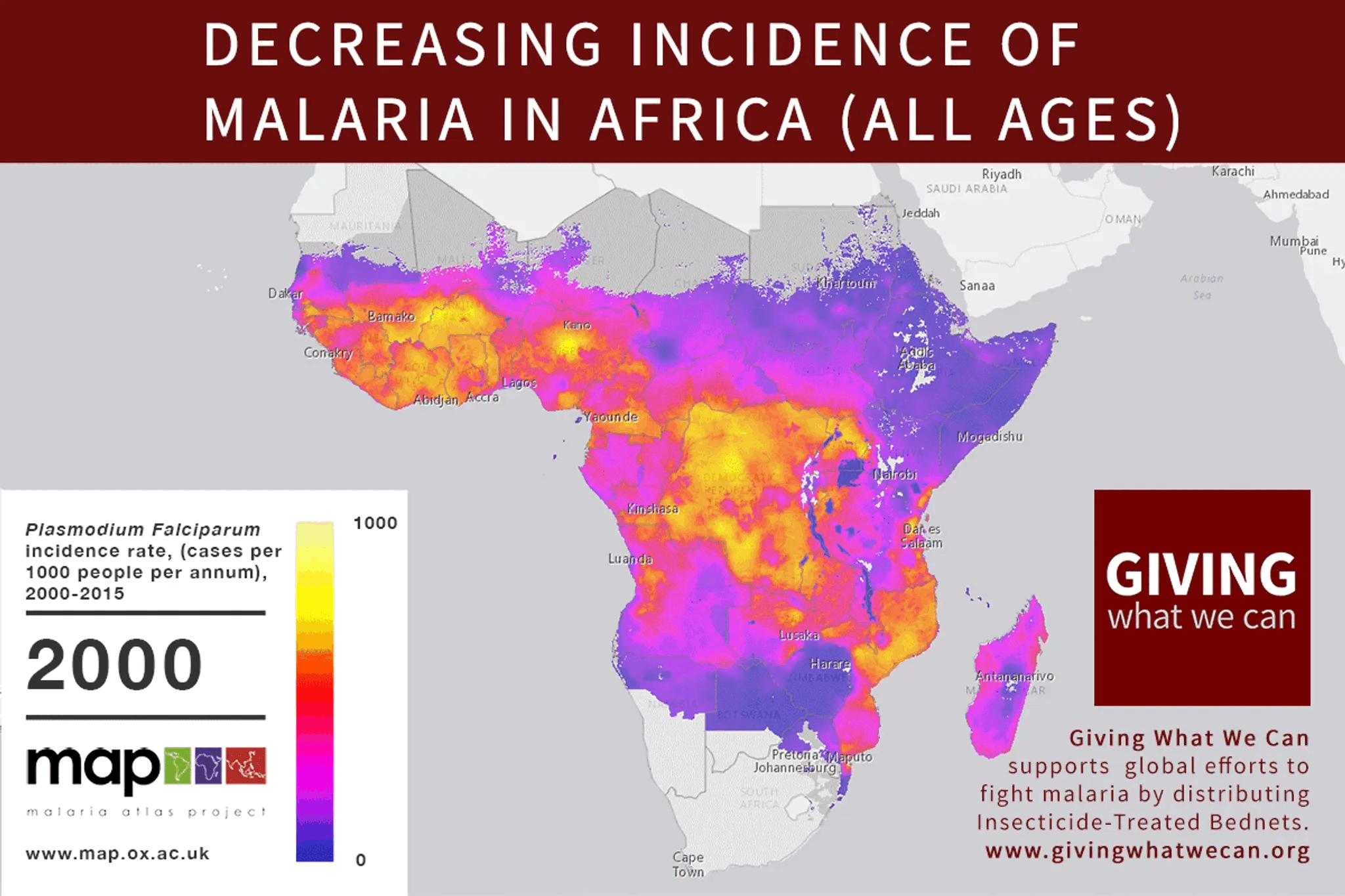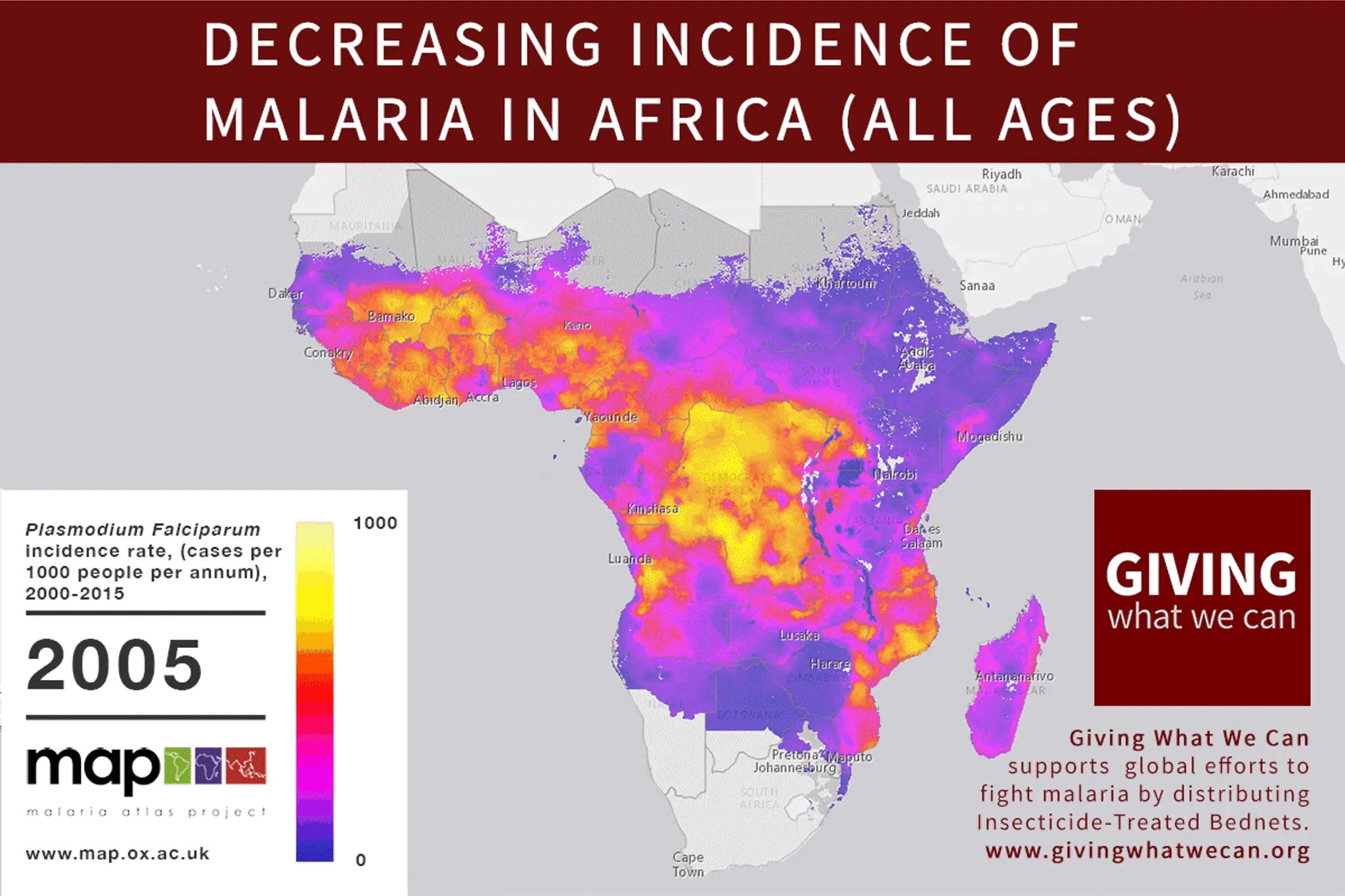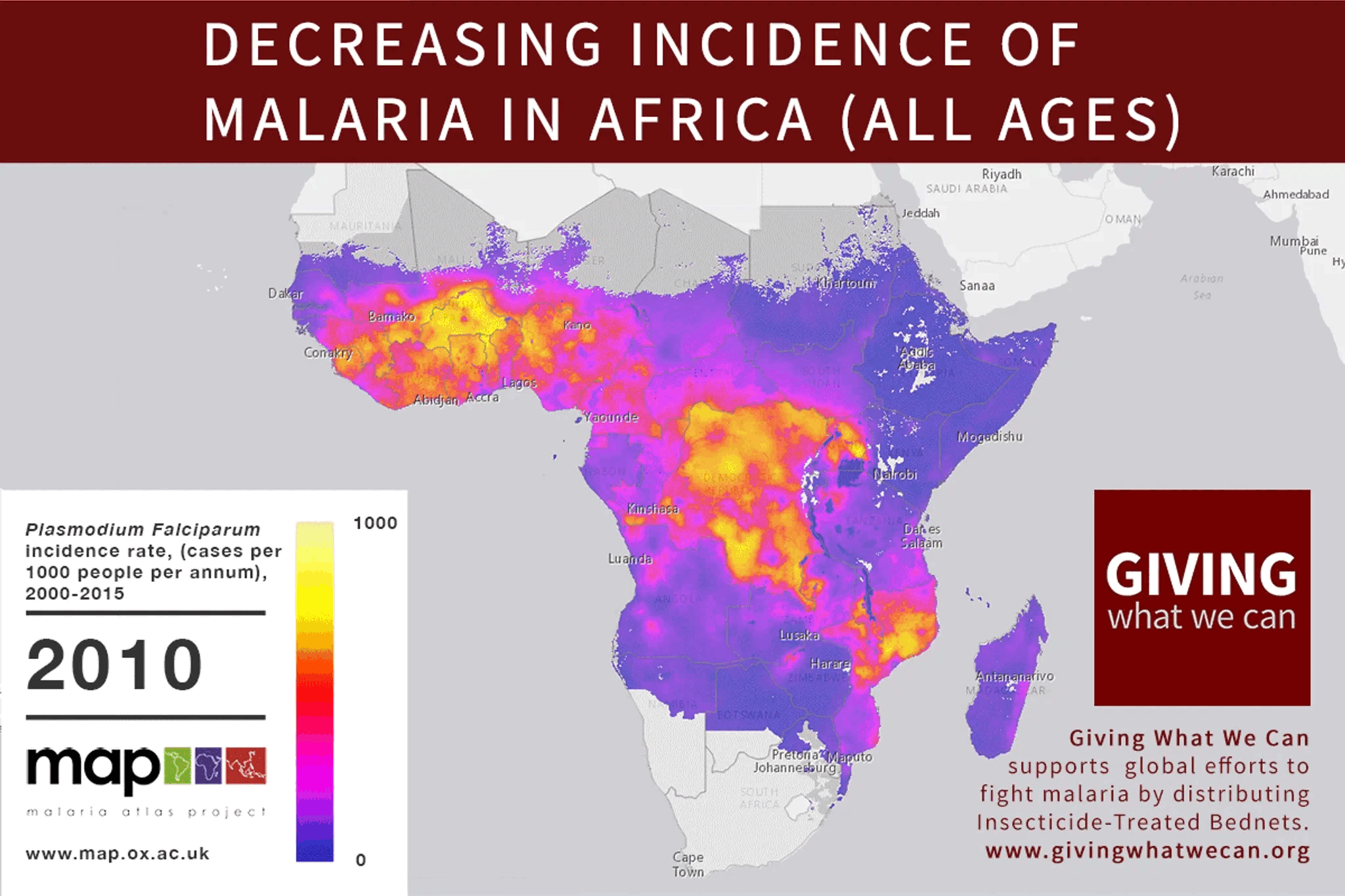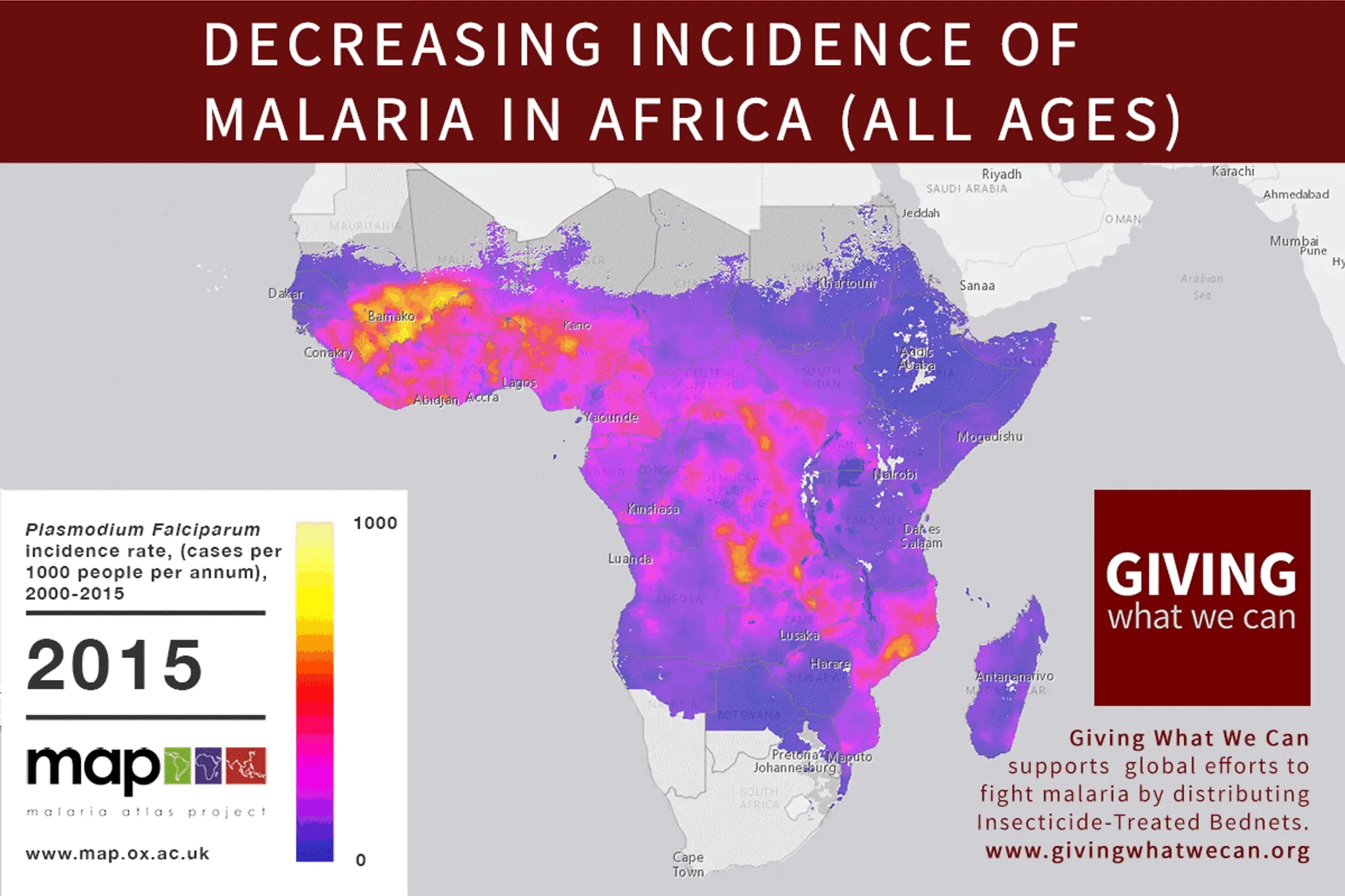


I'll bite on the invitation to nominate my own content. This short piece of mine spent little time on the front page and didn't seem to capture much attention, either positive or negative. I'm not sure why, but I'd love for the ideas in it to get a second look, especially by people who know more about the topic than I do.
Title: Leveraging labor shortages as a pathway to career impact? [note: question mark was added today to better reflect the intended vibe of the post]
Author: Ian David Moss
URL: https://forum.effectivealtruism.org/posts/xdMn6FeQGjrXDPnQj/leveraging-labor-shortages-as-a-pathway-to-career-impact
Why it's good: I think it surfaces an important and rarely-discussed point that could have significant implications for norms and practices around EA community-building and career guidance if it were determined to be valid.