"Part one of our challenge is to solve the technical alignment problem, and that’s what everybody focuses on, but part two is: to whose values do you align the system once you’re capable of doing that, and that may turn out to be an even harder problem", Sam Altman, OpenAI CEO (Link).
In this post, I argue that:
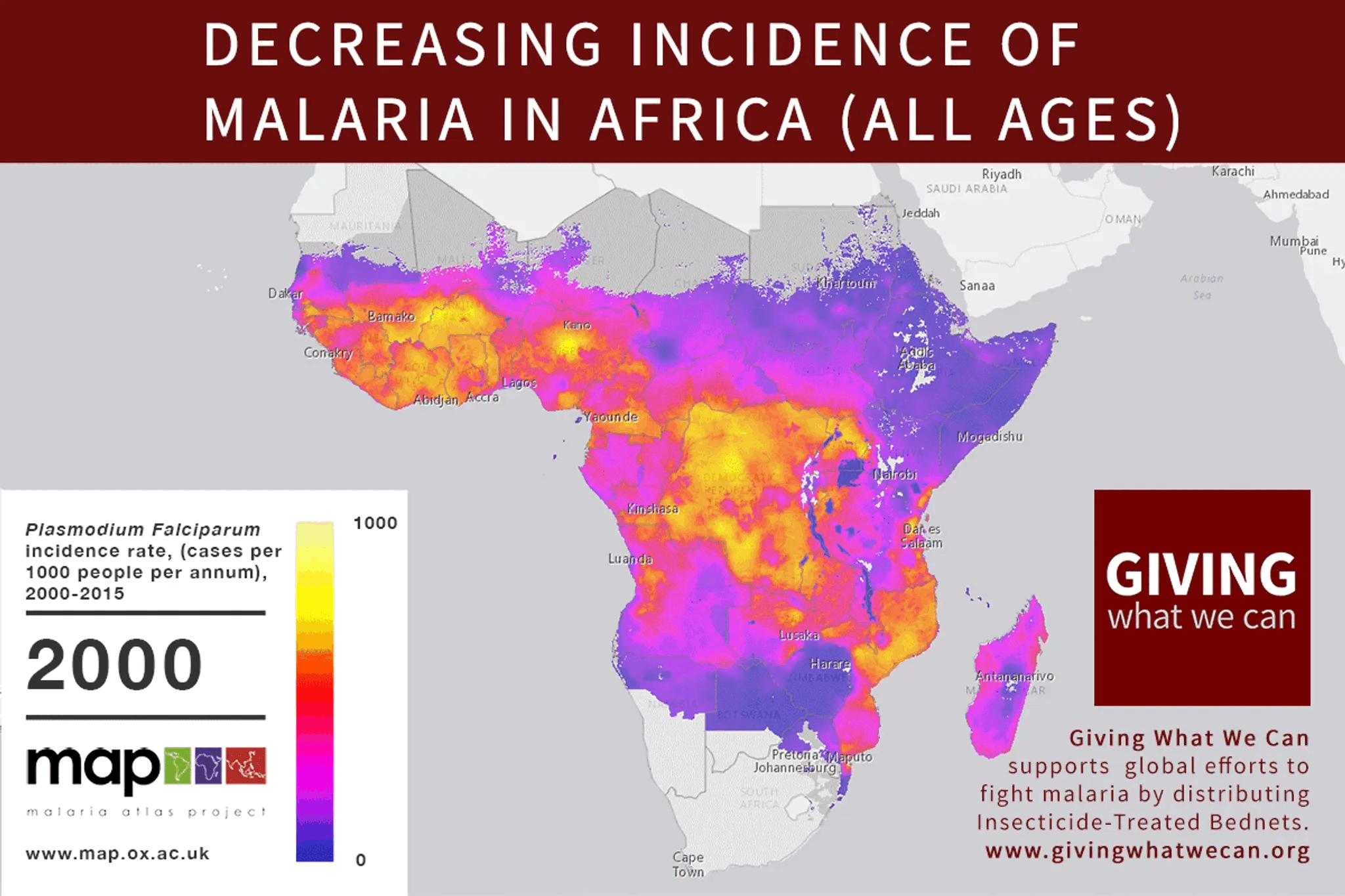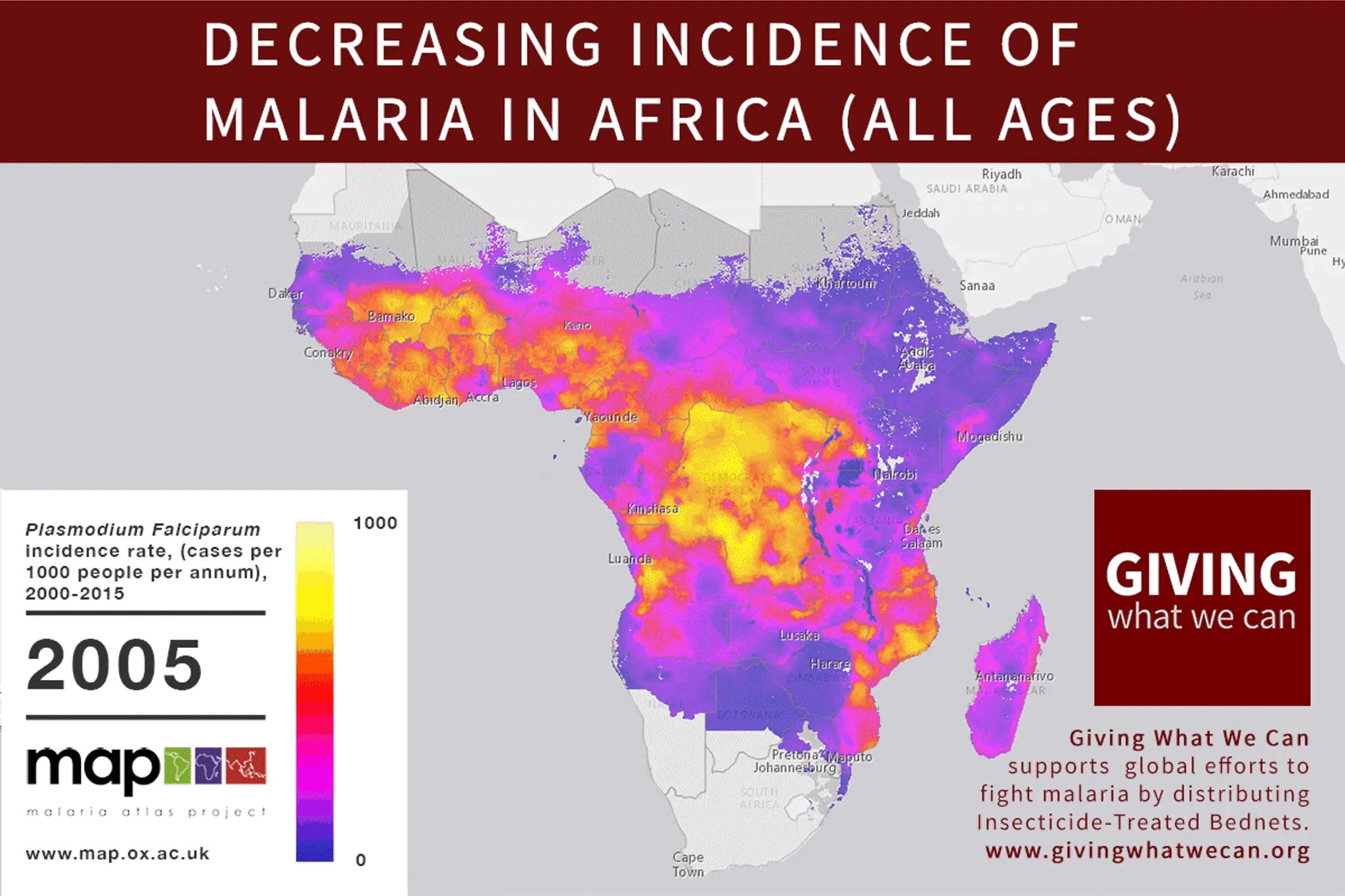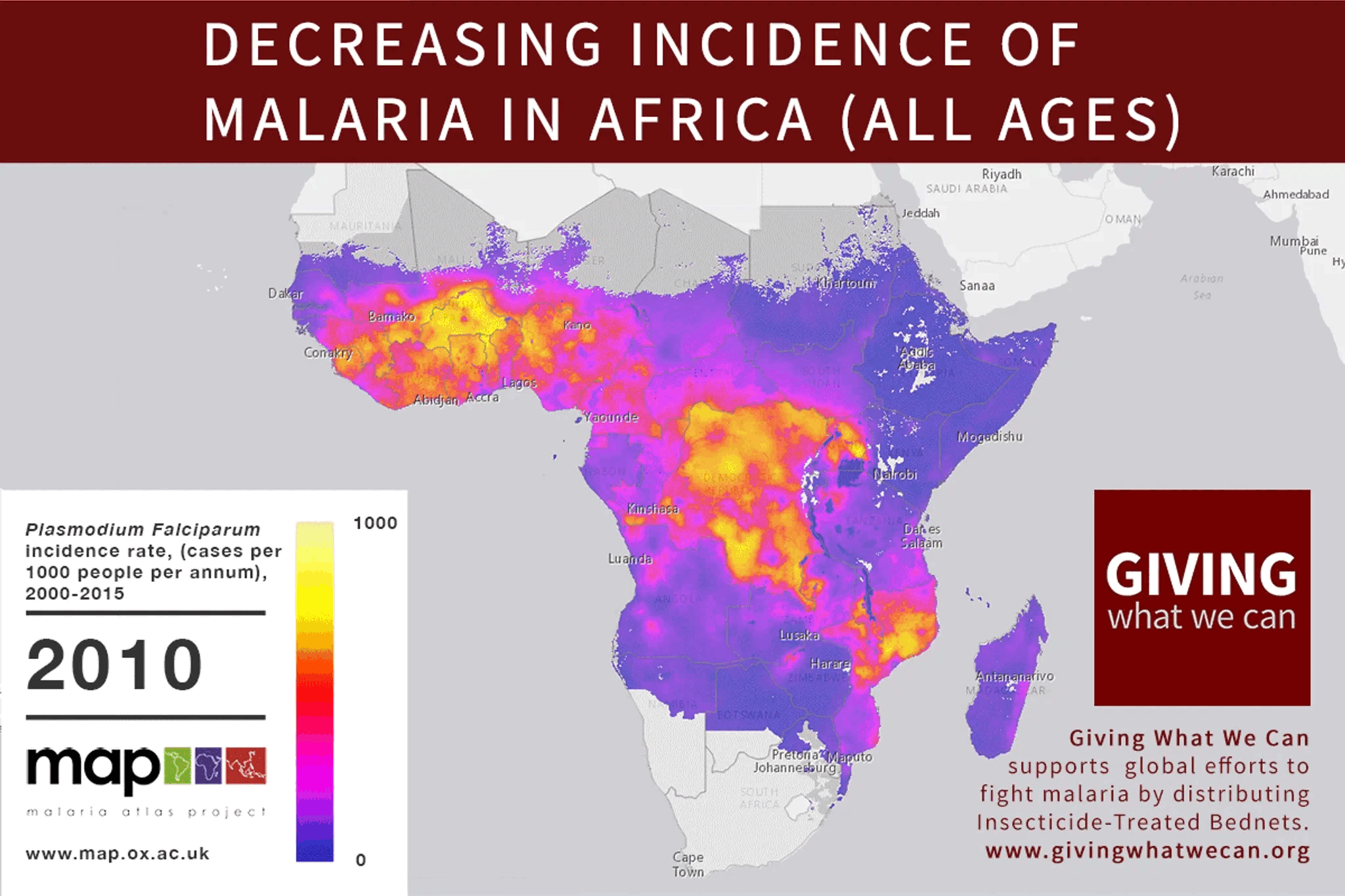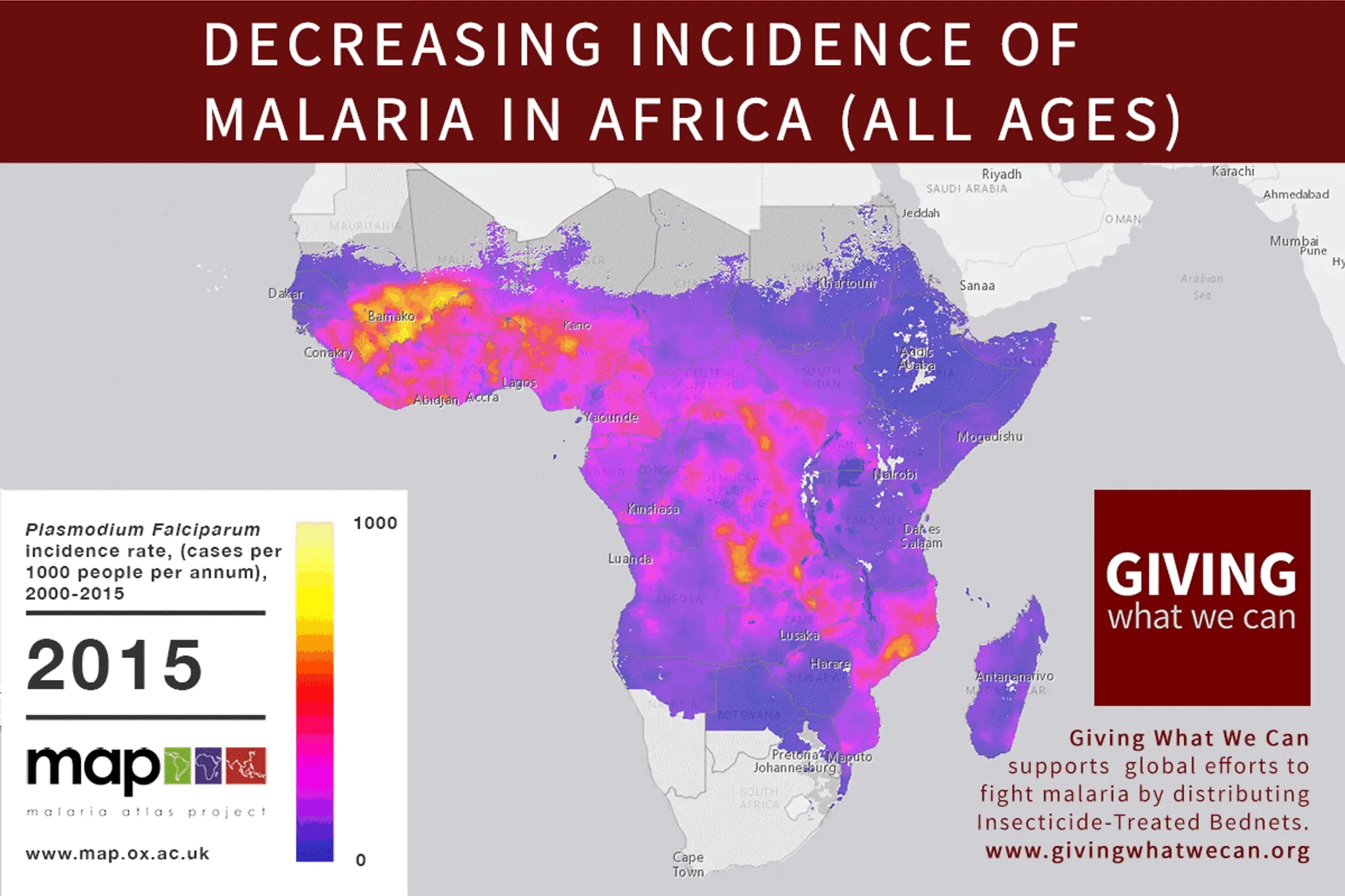
1. "To whose values do you align the system" is a critically neglected space I termed “Moral Alignment.” Only a few organizations work for non-humans in this field, with a total budget of 4-5 million USD (not accounting for academic work). The scale of this space couldn’t be any bigger - the intersection between the most revolutionary technology ever and all sentient beings. While tractability remains uncertain, there is some promising positive evidence (See “The Tractability Open Question” section).
2. Given the first point, our movement must attract more resources, talent, and funding to address it. The goal is to value align AI with caring about all sentient beings: humans, animals, and potential future digital minds. In other words, I argue we should invest much more in promoting a sentient-centric AI.
The problem
What is Moral Alignment?
AI alignment focuses on ensuring AI systems act according to human intentions, emphasizing controllability and corrigibility (adaptability to changing human preferences). However, traditional alignment often ignores the ethical implications for all sentient beings. Moral Alignment, as part of the broader AI alignment and AI safety spaces, is a field focused on the values we aim to instill in AI. I argue that our goal should be to ensure AI is a positive force for all sentient beings.
Currently, as far as I know, no overarching organization, terms, or community unifies Moral Alignment (MA) as a field with a clear umbrella identity. While specific groups focus individually on animals, humans, or digital minds, such as AI for Animals, which does excellent community-building work around AI and animal welfare while


I agree that uncertainty alone doesn't warrant separate treatment, and risk aversion is key.
(Before I get into the formal stuff, risk aversion to me just means placing a premium on hedging. I say this in advance because conversations about risk aversion vs risk neutrality tend to devolve into out-there comparisons like the St Petersburg paradox, and that's never struck me as a particularly resonant way to think about it. I am risk averse for the same reason that most people are: it just feels important to hedge your bets.)
By risk aversion I mean a utility function that satisfies u(E[X])>E[u(X)]. Notably, that means that you can't just take the expected value of lives saved across worlds when evaluating a decision – the distribution of how those lives are saved across worlds matters. I describe that more here.
For example, say my utility function over lives saved x is u(x)=√x. You offer me a choice between a charity that has a 10% chance to save 100 lives, and a charity that saves 5 lives with certainty. The utility of the former option to me is u(x)=0.1⋅√100=1, while the utility of the latter option is u(x)=1⋅√5. Thus, I choose the latter, even though it has lower expected lives saved (E[x]=0.1⋅100=10 for the former, E[x]=5 for the latter). What's going on is that I am valuing certain impact over higher expected lives saved.
Apply this to the meat eater problem, where we have the choices
If you're risk neutral, 1) or 2) are the way to go – pick animals if your best bet is that animals are worth more (accounting for efficacy, room for funding, etc etc), and pick development if your best bet is that humans are worth more. But both options leave open the possibility that you are terribly wrong and you've wasted $10 or caused harm. Option 3) guarantees that you've created some positive value, regardless of whether animals or humans are worth more. If you're risk-averse, that certain positive value is worth more than a higher expected value.